Zrozumienie sztucznej inteligencji
Sztuczna inteligencja obejmuje proces symulacji ludzkiej inteligencji przez maszyny i specjalne systemy komputerowe. Przykłady sztucznej inteligencji obejmują uczenie się, rozumowanie i autokorektę. Zastosowania sztucznej inteligencji obejmują rozpoznawanie mowy, systemy eksperckie oraz rozpoznawanie obrazu i widzenie maszynowe.
Uczenie maszynowe to gałąź sztucznej inteligencji, która zajmuje się systemami i algorytmami, które mogą uczyć się nowych danych i wzorców danych.
Skoncentrujmy się na poniższym diagramie Venna, aby zrozumieć koncepcje uczenia maszynowego i uczenia głębokiego.
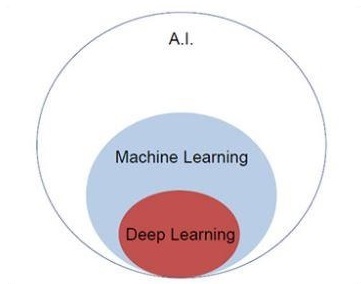
Uczenie maszynowe obejmuje sekcję uczenia maszynowego, a uczenie głębokie jest częścią uczenia maszynowego. Zdolność programu podążającego za koncepcjami uczenia maszynowego polega na poprawie wydajności obserwowanych danych. Głównym motywem transformacji danych jest pogłębianie wiedzy w celu osiągnięcia lepszych wyników w przyszłości, dostarczanie wyników bliższych pożądanym wynikom dla tego konkretnego systemu. Uczenie maszynowe obejmuje „rozpoznawanie wzorców”, które obejmuje zdolność rozpoznawania wzorców w danych.
Wzorce należy trenować, aby pokazywały wyniki w pożądany sposób.
Uczenie maszynowe można trenować na dwa różne sposoby -
- Szkolenie nadzorowane
- Szkolenie bez nadzoru
Nadzorowana nauka
Uczenie nadzorowane lub szkolenie nadzorowane obejmuje procedurę, w której zbiór uczący jest podawany jako dane wejściowe do systemu, przy czym każdy przykład jest oznaczony żądaną wartością wyjściową. Trening tego typu realizowany jest z wykorzystaniem minimalizacji określonej funkcji straty, która reprezentuje błąd wyjściowy w odniesieniu do żądanego układu wyjściowego.
Po zakończeniu uczenia dokładność każdego modelu jest mierzona w odniesieniu do rozłącznych przykładów ze zbioru uczącego, zwanego także zbiorem walidacyjnym.
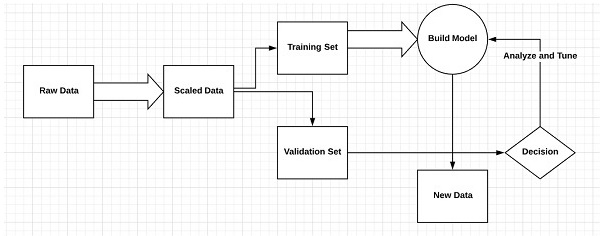
Najlepszym przykładem ilustrującym „Uczenie się nadzorowane” jest kilka zdjęć z zawartymi w nich informacjami. Tutaj użytkownik może wytrenować model do rozpoznawania nowych zdjęć.
Uczenie się bez nadzoru
W uczeniu się nienadzorowanym lub szkoleniu nienadzorowanym uwzględnij przykłady szkoleń, które nie są oznaczone przez system, do którego należą. System wyszukuje dane, które mają wspólne cechy, i zmienia je w oparciu o wewnętrzne cechy wiedzy. Ten typ algorytmów uczenia się jest zasadniczo używany w problemach klastrowych.
Najlepszym przykładem ilustrującym „Uczenie się nienadzorowane” jest zbiór zdjęć bez dołączonych informacji, a użytkownik trenuje model z klasyfikacją i grupowaniem. Ten typ algorytmu uczącego działa z założeniami, ponieważ nie są podawane żadne informacje.
