วงจรดิจิทัล - วิธี K-Map
ในบทก่อนหน้านี้เราได้ทำให้ฟังก์ชันบูลีนง่ายขึ้นโดยใช้สมมติฐานและทฤษฎีบทบูลีน เป็นกระบวนการที่ใช้เวลานานและเราต้องเขียนนิพจน์แบบง่ายอีกครั้งหลังจากแต่ละขั้นตอน
เพื่อเอาชนะความยากลำบากนี้ Karnaughแนะนำวิธีการลดความซับซ้อนของฟังก์ชันบูลีนด้วยวิธีง่ายๆ วิธีนี้เรียกว่า Karnaugh map method หรือ K-map method เป็นวิธีการแบบกราฟิกซึ่งประกอบด้วย 2 nเซลล์สำหรับตัวแปร 'n' เซลล์ที่อยู่ติดกันจะแตกต่างกันในตำแหน่งบิตเดียวเท่านั้น
K-Maps สำหรับ 2 ถึง 5 ตัวแปร
วิธี K-Map เหมาะสมที่สุดสำหรับการลดฟังก์ชันบูลีนของ 2 ตัวแปรให้เหลือ 5 ตัวแปร ตอนนี้ให้เราพูดคุยเกี่ยวกับ K-Maps สำหรับ 2 ถึง 5 ตัวแปรทีละตัว
K-Map 2 ตัวแปร
จำนวนเซลล์ใน 2 ตัวแปร K-map คือสี่เนื่องจากจำนวนตัวแปรคือสอง รูปต่อไปนี้แสดง2 variable K-Map.
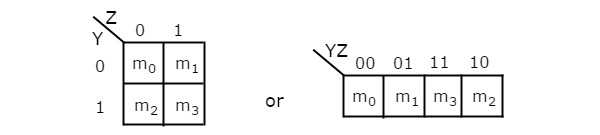
มีความเป็นไปได้เพียงอย่างเดียวในการจัดกลุ่ม 4 เทอมขั้นต่ำที่อยู่ติดกัน
การรวมกันที่เป็นไปได้ของการจัดกลุ่มคำต่ำสุด 2 คำที่อยู่ติดกันคือ {(m 0 , m 1 ), (m 2 , m 3 ), (m 0 , m 2 ) และ (m 1 , m 3 )}
3 ตัวแปร K-Map
จำนวนเซลล์ใน 3 ตัวแปร K-map คือแปดเนื่องจากจำนวนตัวแปรคือสาม รูปต่อไปนี้แสดง3 variable K-Map.
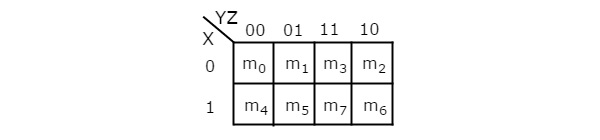
มีความเป็นไปได้เพียงอย่างเดียวในการจัดกลุ่มคำศัพท์ขั้นต่ำที่อยู่ติดกัน 8 คำ
การรวมกันที่เป็นไปได้ของการจัดกลุ่ม 4 เทอมขั้นต่ำที่อยู่ติดกัน ได้แก่ {(ม. 0 , ม. 1 , ม. 3 , ม. 2 ), (ม. 4 , ม. 5 , ม. 7 , ม. 6 ), (ม. 0 , ม. 1 , ม. 4 , ม. 5 ), (ม. 1 , ม. 3 , ม. 5 , ม. 7 ), (ม. 3 , ม. 2 , ม. 7 , ม. 6 ) และ (ม. 2 , ม. 0 , ม. 6 , ม. 4 )}.
การรวมกันที่เป็นไปได้ของการจัดกลุ่ม 2 เทอมขั้นต่ำที่อยู่ติดกันคือ {(m 0 , m 1 ), (m 1 , m 3 ), (m 3 , m 2 ), (m 2 , m 0 ), (m 4 , m 5 ) , (ม. 5 , ม. 7 ), (ม. 7 , ม. 6 ), (ม. 6 , ม. 4 ), (ม. 0 , ม. 4 ), (ม. 1 , ม. 5 ), (ม. 3 , ม. 7 ) และ ( ม. 2 , ม. 6 )}.
ถ้า x = 0 ดังนั้น 3 ตัวแปร K-map จะกลายเป็น 2 ตัวแปร K-map
4 ตัวแปร K-Map
จำนวนเซลล์ใน 4 ตัวแปร K-map คือสิบหกเนื่องจากจำนวนตัวแปรคือสี่ รูปต่อไปนี้แสดง4 variable K-Map.
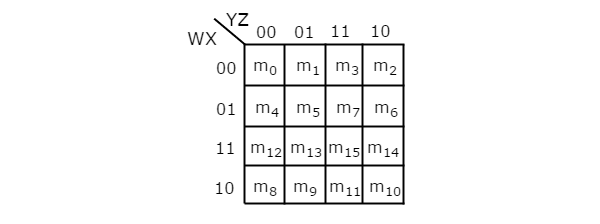
มีความเป็นไปได้เพียงอย่างเดียวในการจัดกลุ่มคำศัพท์ขั้นต่ำ 16 คำที่อยู่ติดกัน
ให้ R 1 , R 2 , R 3และ R 4แทนพจน์ต่ำสุดของแถวแรกแถวที่สองแถวที่สามและแถวที่สี่ตามลำดับ ในทำนองเดียวกัน C 1 , C 2 , C 3และ C 4แทนเงื่อนไขขั้นต่ำของคอลัมน์แรกคอลัมน์ที่สองคอลัมน์ที่สามและคอลัมน์ที่สี่ตามลำดับ การรวมกันที่เป็นไปได้ของการจัดกลุ่มคำศัพท์ขั้นต่ำที่อยู่ติดกัน 8 คำคือ {(R 1 , R 2 ), (R 2 , R 3 ), (R 3 , R 4 ), (R 4 , R 1 ), (C 1 , C 2 ) , (C 2 , C 3 ), (C 3 , C 4 ), (C 4 , C 1 )}
ถ้า w = 0 ดังนั้น 4 ตัวแปร K-map จะกลายเป็น 3 ตัวแปร K-map
5 ตัวแปร K-Map
จำนวนเซลล์ใน 5 ตัวแปร K-map คือสามสิบสองเนื่องจากจำนวนตัวแปรเท่ากับ 5 รูปต่อไปนี้แสดงให้เห็น 5 variable K-Map.

มีความเป็นไปได้เพียงอย่างเดียวในการจัดกลุ่มคำศัพท์ขั้นต่ำที่อยู่ติดกัน 32 คำ
มีความเป็นไปได้สองประการในการจัดกลุ่มคำศัพท์ขั้นต่ำที่อยู่ติดกัน 16 คำ เช่นการจัดกลุ่มของคำนาทีจากม. 0ม15และม. 16ม31
ถ้า v = 0 ดังนั้น 5 ตัวแปร K-map จะกลายเป็น 4 ตัวแปร K-map
ในแผนที่ K ข้างต้นทั้งหมดเราใช้เฉพาะสัญลักษณ์ขั้นต่ำ ในทำนองเดียวกันคุณสามารถใช้สัญกรณ์เงื่อนไขสูงสุดเท่านั้น
การย่อขนาดของฟังก์ชันบูลีนโดยใช้ K-Maps
หากเราพิจารณาการรวมกันของอินพุตที่ฟังก์ชันบูลีนเป็น '1' เราจะได้ฟังก์ชันบูลีนซึ่งอยู่ใน standard sum of products แบบฟอร์มหลังจากทำให้ K-map ง่ายขึ้น
ในทำนองเดียวกันถ้าเราพิจารณาการรวมกันของอินพุตที่ฟังก์ชันบูลีนเป็น '0' เราจะได้ฟังก์ชันบูลีนซึ่งอยู่ใน standard product of sums แบบฟอร์มหลังจากทำให้ K-map ง่ายขึ้น
ทำตามสิ่งเหล่านี้ rules for simplifying K-maps เพื่อให้ได้รูปแบบผลรวมมาตรฐานของผลิตภัณฑ์
เลือก K-map ตามลำดับตามจำนวนตัวแปรที่มีอยู่ในฟังก์ชันบูลีน
ถ้าฟังก์ชันบูลีนถูกกำหนดให้เป็นผลรวมของรูปแบบเงื่อนไขขั้นต่ำให้วางฟังก์ชันไว้ที่เซลล์ระยะต่ำสุดใน K-map หากฟังก์ชันบูลีนถูกกำหนดให้เป็นผลรวมของรูปแบบผลิตภัณฑ์ให้วางฟังก์ชันในเซลล์ที่เป็นไปได้ทั้งหมดของ K-map ซึ่งข้อกำหนดผลิตภัณฑ์ที่ระบุนั้นถูกต้อง
ตรวจสอบความเป็นไปได้ในการจัดกลุ่มจำนวนสูงสุดที่อยู่ติดกัน มันควรจะเป็นสองพลัง เริ่มจากกำลังสูงสุดของสองและไม่เกินกำลังสอง กำลังสูงสุดเท่ากับจำนวนตัวแปรที่พิจารณาใน K-map และกำลังน้อยที่สุดคือศูนย์
การจัดกลุ่มแต่ละรายการจะให้คำศัพท์ตามตัวอักษรหรือหนึ่งคำผลิตภัณฑ์ เป็นที่รู้จักกันในชื่อprime implicant. นัยสำคัญก็คือessential prime implicantถ้าอย่างน้อยรายการเดียว '1' ไม่ครอบคลุมกับการจัดกลุ่มอื่น ๆ แต่จะครอบคลุมเฉพาะการจัดกลุ่มเท่านั้น
จดนัยสำคัญทั้งหมดและนัยสำคัญเฉพาะที่สำคัญ ฟังก์ชันบูลีนที่เรียบง่ายประกอบด้วยนัยสำคัญเฉพาะที่จำเป็นทั้งหมดและเฉพาะนัยเฉพาะที่จำเป็นเท่านั้น
Note 1 - หากไม่ได้กำหนดเอาต์พุตสำหรับอินพุตบางชุดค่าเอาต์พุตเหล่านั้นจะถูกแสดงด้วย don’t care symbol ‘x’. นั่นหมายความว่าเราสามารถพิจารณาได้ว่าเป็น '0' หรือ '1'
Note 2- หากไม่สนใจเงื่อนไขก็แสดงว่าไม่ต้องสนใจ 'x' ในเซลล์ที่เกี่ยวข้องของ K-map พิจารณาเฉพาะ 'x' ที่ไม่สนใจซึ่งเป็นประโยชน์สำหรับการจัดกลุ่มจำนวนสูงสุดที่อยู่ติดกัน ในกรณีดังกล่าวให้ถือว่าค่า don't care เป็น "1"
ตัวอย่าง
ขอให้เรา simplify ฟังก์ชันบูลีนต่อไปนี้ f(W, X, Y, Z)= WX’Y’ + WY + W’YZ’ ใช้ K-map
ฟังก์ชันบูลีนที่กำหนดเป็นผลรวมของรูปแบบผลิตภัณฑ์ มันมีตัวแปร 4 ตัวคือ W, X, Y & Z ดังนั้นเราต้องการ4 variable K-map. 4 variable K-map กับคำที่สอดคล้องกับเงื่อนไขของผลิตภัณฑ์ที่ระบุจะแสดงในรูปต่อไปนี้
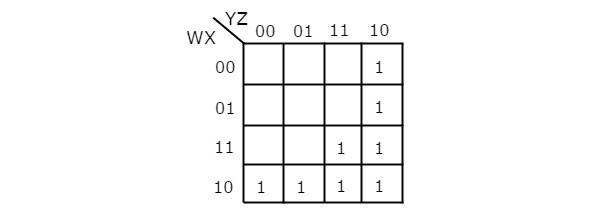
ที่นี่ 1s จะอยู่ในเซลล์ต่อไปนี้ของ K-map
เซลล์ซึ่งมักจะเป็นจุดตัดของ Row 4 และคอลัมน์ 1 & 2 จะตรงกับคำศัพท์ผลิตภัณฑ์ WX’Y’.
เซลล์ซึ่งโดยทั่วไปจะเป็นจุดตัดของแถว 3 & 4 และคอลัมน์ 3 & 4 จะตรงกับคำศัพท์ผลิตภัณฑ์ WY.
เซลล์ซึ่งมักจะเป็นจุดตัดของแถว 1 และ 2 และคอลัมน์ 4 จะตรงกับคำศัพท์ผลิตภัณฑ์ W’YZ’.
ไม่มีความเป็นไปได้ในการจัดกลุ่ม 16 อันที่อยู่ติดกันหรือ 8 อันที่อยู่ติดกัน มีความเป็นไปได้สามประการในการจัดกลุ่ม 4 รายการที่อยู่ติดกัน หลังจากการจัดกลุ่มทั้งสามนี้จะไม่มีการจัดกลุ่มที่เหลือเพียงรายการเดียว ดังนั้นเราจึงไม่จำเป็นต้องตรวจสอบการจัดกลุ่ม 2 รายการที่อยู่ติดกัน 4 variable K-map กับสามคนนี้ groupings แสดงดังรูปต่อไปนี้

ที่นี่เรามีนัยสำคัญสามประการคือ WX ', WY & YZ' นัยสำคัญทั้งหมดนี้คือessential เนื่องจากเหตุผลดังต่อไปนี้
สองคน (m8 & m9)การจัดกลุ่มแถวที่สี่จะไม่ครอบคลุมโดยการจัดกลุ่มอื่น ๆ การจัดกลุ่มแถวที่สี่เท่านั้นที่จะครอบคลุมสองแถวนั้น
หนึ่งเดียว (m15)ของการจัดกลุ่มรูปทรงสี่เหลี่ยมจะไม่ครอบคลุมโดยการจัดกลุ่มอื่น ๆ เฉพาะการจัดกลุ่มรูปทรงสี่เหลี่ยมเท่านั้นที่ครอบคลุมสิ่งนั้น
สองคน (m2 & m6)ของการจัดกลุ่มคอลัมน์ที่สี่ไม่ครอบคลุมโดยการจัดกลุ่มอื่น ๆ การจัดกลุ่มคอลัมน์ที่สี่เท่านั้นที่ครอบคลุมสองคอลัมน์นั้น
ดังนั้นไฟล์ simplified Boolean function คือ
f = WX’ + WY + YZ’
ทำตามสิ่งเหล่านี้ rules for simplifying K-maps เพื่อให้ได้ผลิตภัณฑ์มาตรฐานของรูปแบบผลรวม
เลือก K-map ตามลำดับตามจำนวนตัวแปรที่มีอยู่ในฟังก์ชันบูลีน
ถ้าฟังก์ชันบูลีนถูกกำหนดให้เป็นผลคูณของรูปแบบเงื่อนไขสูงสุดให้วางศูนย์ที่เซลล์ระยะสูงสุดตามลำดับใน K-map ถ้าฟังก์ชันบูลีนถูกกำหนดให้เป็นผลคูณของรูปแบบผลรวมให้วางศูนย์ในเซลล์ที่เป็นไปได้ทั้งหมดของ K-map ซึ่งเงื่อนไขผลรวมที่กำหนดนั้นถูกต้อง
ตรวจสอบความเป็นไปได้ของการจัดกลุ่มจำนวนศูนย์สูงสุดที่อยู่ติดกัน มันควรจะเป็นสองพลัง เริ่มจากกำลังสูงสุดของสองและไม่เกินกำลังสอง กำลังสูงสุดเท่ากับจำนวนตัวแปรที่พิจารณาใน K-map และกำลังน้อยที่สุดคือศูนย์
การจัดกลุ่มแต่ละครั้งจะให้ผลรวมตามตัวอักษรหรือหนึ่งเทอม เป็นที่รู้จักกันในชื่อprime implicant. นัยสำคัญก็คือessential prime implicantถ้าอย่างน้อยรายการเดียว '0' ไม่ครอบคลุมกับการจัดกลุ่มอื่น ๆ แต่จะครอบคลุมเฉพาะการจัดกลุ่มเท่านั้น
จดนัยสำคัญทั้งหมดและนัยสำคัญเฉพาะที่สำคัญ ฟังก์ชันบูลีนที่เรียบง่ายประกอบด้วยนัยสำคัญเฉพาะที่จำเป็นทั้งหมดและเฉพาะนัยเฉพาะที่จำเป็นเท่านั้น
Note- หากไม่สนใจเงื่อนไขก็แสดงว่าไม่ต้องสนใจ 'x' ในเซลล์ที่เกี่ยวข้องของ K-map พิจารณาเฉพาะ 'x' ที่ไม่สนใจซึ่งเป็นประโยชน์สำหรับการจัดกลุ่มจำนวนศูนย์สูงสุดที่อยู่ติดกัน ในกรณีดังกล่าวให้ถือว่าค่า don't care เป็น "0"
ตัวอย่าง
ขอให้เรา simplify ฟังก์ชันบูลีนต่อไปนี้ $ f \ left (X, Y, Z \ right) = \ prod M \ left (0,1,2,4 \ right) $ โดยใช้ K-map
ฟังก์ชันบูลีนที่กำหนดอยู่ในผลคูณของรูปแบบเงื่อนไขสูงสุด มันมี 3 ตัวแปร X, Y & Z ดังนั้นเราต้องการ K-map 3 ตัวแปร เงื่อนไขแม็กซ์ให้เป็น M 0 , M 1 , M 2 & M 4 3variable K-map ด้วยศูนย์ที่สอดคล้องกับเงื่อนไขสูงสุดที่กำหนดจะแสดงในรูปต่อไปนี้

ไม่มีความเป็นไปได้ในการจัดกลุ่มทั้ง 8 ศูนย์ที่อยู่ติดกันหรือ 4 ศูนย์ที่อยู่ติดกัน มีความเป็นไปได้สามประการในการจัดกลุ่ม 2 ศูนย์ที่อยู่ติดกัน หลังจากการจัดกลุ่มทั้งสามนี้จะไม่มีศูนย์เดียวที่เหลืออยู่ในขณะที่ไม่ได้จัดกลุ่ม 3 variable K-map กับสามคนนี้ groupings แสดงดังรูปต่อไปนี้

ที่นี่เรามีนัยสำคัญสามประการคือ X + Y, Y + Z & Z + X นัยสำคัญทั้งหมดนี้คือ essential เนื่องจากศูนย์หนึ่งในการจัดกลุ่มแต่ละกลุ่มไม่ครอบคลุมโดยการจัดกลุ่มอื่น ๆ ยกเว้นการจัดกลุ่มแต่ละกลุ่ม
ดังนั้นไฟล์ simplified Boolean function คือ
f = (X + Y).(Y + Z).(Z + X)
ด้วยวิธีนี้เราสามารถลดความซับซ้อนของฟังก์ชันบูลีนได้อย่างง่ายดายถึง 5 ตัวแปรโดยใช้วิธี K-map สำหรับตัวแปรมากกว่า 5 ตัวการลดความซับซ้อนของฟังก์ชันโดยใช้ K-Maps เป็นเรื่องยาก เพราะจำนวนcells ใน K-map ได้รับ doubled โดยรวมตัวแปรใหม่
เนื่องจากการตรวจสอบและการจัดกลุ่มของคำที่อยู่ติดกัน (เงื่อนไขขั้นต่ำ) หรือเลขศูนย์ที่อยู่ติดกัน (เงื่อนไขสูงสุด) จะมีความซับซ้อน เราจะหารือTabular method ในบทต่อไปเพื่อเอาชนะความยากลำบากของวิธี K-map