Adaptive Resonanztheorie
Dieses Netzwerk wurde 1987 von Stephen Grossberg und Gail Carpenter entwickelt. Es basiert auf Wettbewerb und verwendet ein unbeaufsichtigtes Lernmodell. Netzwerke der adaptiven Resonanztheorie (ART) sind, wie der Name schon sagt, immer offen für neues Lernen (adaptiv), ohne die alten Muster zu verlieren (Resonanz). Grundsätzlich ist das ART-Netzwerk ein Vektorklassifizierer, der einen Eingabevektor akzeptiert und ihn in eine der Kategorien klassifiziert, je nachdem, welchem der gespeicherten Muster er am ähnlichsten ist.
Betriebsleiter
Die Hauptoperation der ART-Klassifizierung kann in die folgenden Phasen unterteilt werden:
Recognition phase- Der Eingabevektor wird mit der Klassifizierung verglichen, die an jedem Knoten in der Ausgabeschicht dargestellt wird. Die Ausgabe des Neurons wird "1", wenn sie am besten mit der angewendeten Klassifizierung übereinstimmt, andernfalls wird sie "0".
Comparison phase- In dieser Phase wird ein Vergleich des Eingabevektors mit dem Vergleichsschichtvektor durchgeführt. Die Bedingung für das Zurücksetzen ist, dass der Ähnlichkeitsgrad geringer als der Wachsamkeitsparameter ist.
Search phase- In dieser Phase sucht das Netzwerk nach dem Zurücksetzen sowie nach der Übereinstimmung, die in den obigen Phasen durchgeführt wurde. Wenn es also keinen Reset geben würde und die Übereinstimmung ziemlich gut ist, ist die Klassifizierung beendet. Andernfalls würde der Vorgang wiederholt und das andere gespeicherte Muster muss gesendet werden, um die richtige Übereinstimmung zu finden.
ART1
Es ist eine Art von ART, die entwickelt wurde, um binäre Vektoren zu gruppieren. Wir können dies anhand der Architektur verstehen.
Architektur von ART1
Es besteht aus den folgenden zwei Einheiten -
Computational Unit - Es besteht aus folgenden -
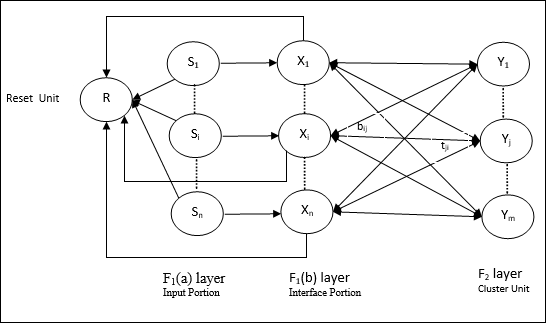
Input unit (F1 layer) - Es hat weiterhin die folgenden zwei Teile -
F1(a) layer (Input portion)- In ART1 würde in diesem Abschnitt keine Verarbeitung stattfinden, anstatt nur die Eingabevektoren zu haben. Es ist mit der Schicht F 1 (b) (Schnittstellenabschnitt) verbunden.
F1(b) layer (Interface portion)- Dieser Teil kombiniert das Signal vom Eingangsabschnitt mit dem der F 2 -Schicht. Die Schicht F 1 (b) ist durch Bottom-Up-Gewichte mit der Schicht F 2 verbundenbijund die F 2 -Schicht ist durch Top-Down-Gewichte mit der F 1 (b) -Schicht verbundentji.
Cluster Unit (F2 layer)- Dies ist eine Wettbewerbsschicht. Die Einheit mit der größten Nettoeingabe wird ausgewählt, um das Eingabemuster zu lernen. Die Aktivierung aller anderen Cluster-Einheiten wird auf 0 gesetzt.
Reset Mechanism- Die Arbeit dieses Mechanismus basiert auf der Ähnlichkeit zwischen dem Top-Down-Gewicht und dem Eingabevektor. Wenn der Grad dieser Ähnlichkeit geringer als der Wachsamkeitsparameter ist, darf der Cluster das Muster nicht lernen, und es würde eine Pause stattfinden.
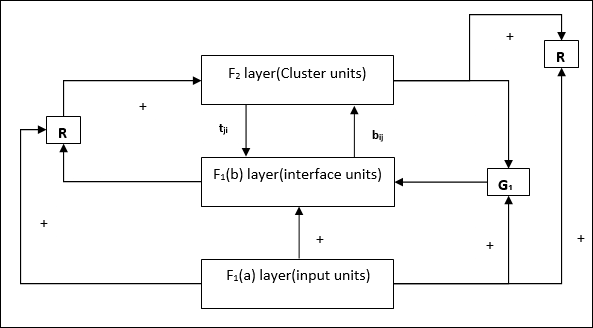
Supplement Unit - Eigentlich ist das Problem mit dem Reset-Mechanismus, dass die Ebene F2muss unter bestimmten Bedingungen gehemmt werden und muss auch verfügbar sein, wenn etwas gelernt wird. Deshalb zwei ergänzende Einheiten, nämlichG1 und G2 wird zusammen mit der Rücksetzeinheit hinzugefügt, R. Sie heißengain control units. Diese Einheiten empfangen und senden Signale an die anderen im Netzwerk vorhandenen Einheiten.‘+’ zeigt ein anregendes Signal an, während ‘−’ zeigt ein inhibitorisches Signal an.
Verwendete Parameter
Folgende Parameter werden verwendet -
n - Anzahl der Komponenten im Eingabevektor
m - Maximale Anzahl von Clustern, die gebildet werden können
bij- Gewicht von F 1 (b) bis F 2 -Schicht, dh Bottom-Up-Gewichte
tji- Gewicht von F 2 bis F 1 (b), dh Gewichte von oben nach unten
ρ - Wachsamkeitsparameter
||x|| - Norm des Vektors x
Algorithmus
Step 1 - Initialisieren Sie die Lernrate, den Wachsamkeitsparameter und die Gewichte wie folgt: -
$$ \ alpha \:> \: 1 \: \: und \: \: 0 \: <\ rho \: \ leq \: 1 $$
$$ 0 \: <\: b_ {ij} (0) \: <\: \ frac {\ alpha} {\ alpha \: - \: 1 \: + \: n} \: \: und \: \: t_ {ij} (0) \: = \: 1 $$
Step 2 - Fahren Sie mit Schritt 3-9 fort, wenn die Stoppbedingung nicht erfüllt ist.
Step 3 - Fahren Sie für jede Trainingseingabe mit Schritt 4-6 fort.
Step 4- Stellen Sie die Aktivierungen aller F 1 (a) - und F 1 -Einheiten wie folgt ein
F2 = 0 and F1(a) = input vectors
Step 5- Eingangssignal von F 1 (a) bis F 1 (b) Schicht muss verschickt werden
$$ s_ {i} \: = \: x_ {i} $$
Step 6- Für jeden gesperrten F 2 -Knoten
$ y_ {j} \: = \: \ sum_i b_ {ij} x_ {i} $ die Bedingung ist yj ≠ -1
Step 7 - Führen Sie Schritt 8-10 aus, wenn der Reset wahr ist.
Step 8 - Finden J zum yJ ≥ yj für alle Knoten j
Step 9- Berechnen Sie die Aktivierung von F 1 (b) erneut wie folgt
$$ x_ {i} \: = \: sitJi $$
Step 10 - Nun nach der Berechnung der Vektornorm x und Vektor smüssen wir den Rücksetzzustand wie folgt überprüfen:
Wenn ||x||/ ||s|| <Wachsamkeitsparameter ρ, Dann hemmen Sie den Knoten J und fahren Sie mit Schritt 7 fort
Sonst wenn ||x||/ ||s|| ≥ Wachsamkeitsparameter ρ, dann weiter.
Step 11 - Gewichtsaktualisierung für Knoten J kann wie folgt durchgeführt werden -
$$ b_ {ij} (neu) \: = \: \ frac {\ alpha x_ {i}} {\ alpha \: - \: 1 \: + \: || x ||} $$
$$ t_ {ij} (neu) \: = \: x_ {i} $$
Step 12 - Die Stoppbedingung für den Algorithmus muss überprüft werden und kann wie folgt sein: -
- Keine Gewichtsveränderung.
- Für Einheiten wird kein Reset durchgeführt.
- Maximale Anzahl von Epochen erreicht.