Überwachtes Lernen
Wie der Name schon sagt, supervised learningfindet unter der Aufsicht eines Lehrers statt. Dieser Lernprozess ist abhängig. Während des Trainings von ANN unter überwachtem Lernen wird der Eingabevektor dem Netzwerk präsentiert, das einen Ausgabevektor erzeugt. Dieser Ausgabevektor wird mit dem gewünschten / Ziel-Ausgabevektor verglichen. Ein Fehlersignal wird erzeugt, wenn zwischen dem tatsächlichen Ausgang und dem gewünschten / Ziel-Ausgangsvektor ein Unterschied besteht. Auf der Grundlage dieses Fehlersignals würden die Gewichte angepasst, bis die tatsächliche Ausgabe mit der gewünschten Ausgabe übereinstimmt.
Perceptron
Perzeptron wurde von Frank Rosenblatt unter Verwendung des McCulloch- und Pitts-Modells entwickelt und ist die grundlegende Betriebseinheit künstlicher neuronaler Netze. Es verwendet eine überwachte Lernregel und kann die Daten in zwei Klassen einteilen.
Funktionsmerkmale des Perzeptrons: Es besteht aus einem einzelnen Neuron mit einer beliebigen Anzahl von Eingaben und einstellbaren Gewichten, aber die Ausgabe des Neurons beträgt je nach Schwellenwert 1 oder 0. Es besteht auch aus einer Vorspannung, deren Gewicht immer 1 beträgt. Die folgende Abbildung zeigt eine schematische Darstellung des Perzeptrons.
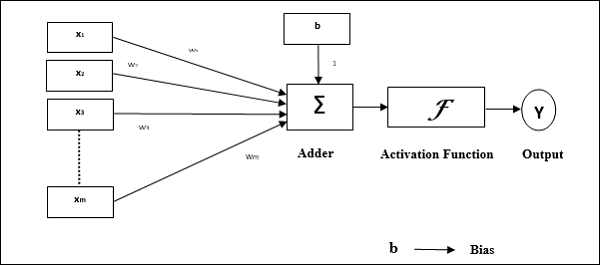
Perceptron hat also die folgenden drei Grundelemente:
Links - Es hätte eine Reihe von Verbindungsgliedern, die ein Gewicht einschließlich einer Vorspannung tragen, die immer das Gewicht 1 hat.
Adder - Es fügt die Eingabe hinzu, nachdem sie mit ihren jeweiligen Gewichten multipliziert wurden.
Activation function- Es begrenzt die Ausgabe von Neuronen. Die grundlegendste Aktivierungsfunktion ist eine Heaviside-Schrittfunktion mit zwei möglichen Ausgängen. Diese Funktion gibt 1 zurück, wenn der Eingang positiv ist, und 0 für jeden negativen Eingang.
Trainingsalgorithmus
Das Perceptron-Netzwerk kann sowohl für eine Ausgabeeinheit als auch für mehrere Ausgabeeinheiten trainiert werden.
Trainingsalgorithmus für eine einzelne Ausgabeeinheit
Step 1 - Initialisieren Sie Folgendes, um das Training zu starten -
- Weights
- Bias
- Lernrate $ \ alpha $
Zur einfachen Berechnung und Vereinfachung müssen Gewichte und Vorspannung auf 0 und die Lernrate auf 1 gesetzt werden.
Step 2 - Fahren Sie mit Schritt 3-8 fort, wenn die Stoppbedingung nicht erfüllt ist.
Step 3 - Fahren Sie für jeden Trainingsvektor mit Schritt 4-6 fort x.
Step 4 - Aktivieren Sie jede Eingabeeinheit wie folgt: -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: bis \: n) $$
Step 5 - Erhalten Sie nun den Nettoeingang mit der folgenden Beziehung -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i}. \: w_ {i} $$
Hier ‘b’ ist Voreingenommenheit und ‘n’ ist die Gesamtzahl der Eingangsneuronen.
Step 6 - Wenden Sie die folgende Aktivierungsfunktion an, um die endgültige Ausgabe zu erhalten.
$$ f (y_ {in}) \: = \: \ begin {case} 1 & if \: y_ {in} \:> \: \ theta \\ 0 & if \: - \ theta \: \ leqslant \ : y_ {in} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {in} \: <\: - \ theta \ end {case} $$
Step 7 - Stellen Sie das Gewicht und die Vorspannung wie folgt ein -
Case 1 - wenn y ≠ t dann,
$$ w_ {i} (neu) \: = \: w_ {i} (alt) \: + \: \ alpha \: tx_ {i} $$
$$ b (neu) \: = \: b (alt) \: + \: \ alpha t $$
Case 2 - wenn y = t dann,
$$ w_ {i} (neu) \: = \: w_ {i} (alt) $$
$$ b (neu) \: = \: b (alt) $$
Hier ‘y’ ist die tatsächliche Ausgabe und ‘t’ ist die gewünschte / Zielausgabe.
Step 8 - Prüfen Sie den Stoppzustand, der auftreten würde, wenn sich das Gewicht nicht ändert.
Trainingsalgorithmus für mehrere Ausgabeeinheiten
Das folgende Diagramm zeigt die Architektur von Perzeptron für mehrere Ausgabeklassen.
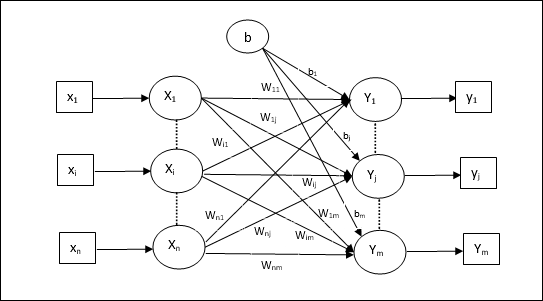
Step 1 - Initialisieren Sie Folgendes, um das Training zu starten -
- Weights
- Bias
- Lernrate $ \ alpha $
Zur einfachen Berechnung und Vereinfachung müssen Gewichte und Vorspannung auf 0 und die Lernrate auf 1 gesetzt werden.
Step 2 - Fahren Sie mit Schritt 3-8 fort, wenn die Stoppbedingung nicht erfüllt ist.
Step 3 - Fahren Sie für jeden Trainingsvektor mit Schritt 4-6 fort x.
Step 4 - Aktivieren Sie jede Eingabeeinheit wie folgt: -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: bis \: n) $$
Step 5 - Erhalten Sie die Nettoeingabe mit der folgenden Beziehung -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {ij} $$
Hier ‘b’ ist Voreingenommenheit und ‘n’ ist die Gesamtzahl der Eingangsneuronen.
Step 6 - Wenden Sie die folgende Aktivierungsfunktion an, um die endgültige Ausgabe für jede Ausgabeeinheit zu erhalten j = 1 to m - -
$$ f (y_ {in}) \: = \: \ begin {case} 1 & if \: y_ {inj} \:> \: \ theta \\ 0 & if \: - \ theta \: \ leqslant \ : y_ {inj} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {inj} \: <\: - \ theta \ end {case} $$
Step 7 - Stellen Sie das Gewicht und die Vorspannung für ein x = 1 to n und j = 1 to m wie folgt -
Case 1 - wenn yj ≠ tj dann,
$$ w_ {ij} (neu) \: = \: w_ {ij} (alt) \: + \: \ alpha \: t_ {j} x_ {i} $$
$$ b_ {j} (neu) \: = \: b_ {j} (alt) \: + \: \ alpha t_ {j} $$
Case 2 - wenn yj = tj dann,
$$ w_ {ij} (neu) \: = \: w_ {ij} (alt) $$
$$ b_ {j} (neu) \: = \: b_ {j} (alt) $$
Hier ‘y’ ist die tatsächliche Ausgabe und ‘t’ ist die gewünschte / Zielausgabe.
Step 8 - Prüfen Sie den Stoppzustand, der auftritt, wenn sich das Gewicht nicht ändert.
Adaptives lineares Neuron (Adaline)
Adaline, das für Adaptive Linear Neuron steht, ist ein Netzwerk mit einer einzigen linearen Einheit. Es wurde 1960 von Widrow und Hoff entwickelt. Einige wichtige Punkte über Adaline sind:
Es verwendet eine bipolare Aktivierungsfunktion.
Es verwendet eine Delta-Regel für das Training, um den mittleren quadratischen Fehler (MSE) zwischen der tatsächlichen Ausgabe und der gewünschten / Zielausgabe zu minimieren.
Die Gewichte und die Vorspannung sind einstellbar.
Die Architektur
Die Grundstruktur von Adaline ähnelt der von Perzeptron mit einer zusätzlichen Rückkopplungsschleife, mit deren Hilfe die tatsächliche Ausgabe mit der gewünschten / Zielausgabe verglichen wird. Nach dem Vergleich auf der Basis des Trainingsalgorithmus werden die Gewichte und die Vorspannung aktualisiert.
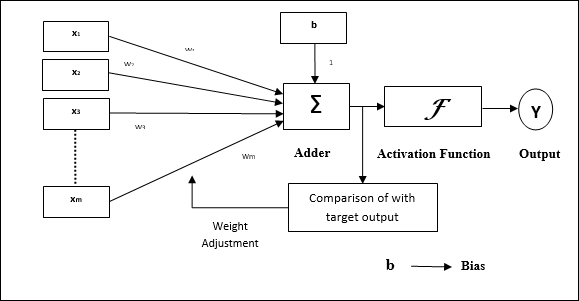
Trainingsalgorithmus
Step 1 - Initialisieren Sie Folgendes, um das Training zu starten -
- Weights
- Bias
- Lernrate $ \ alpha $
Zur einfachen Berechnung und Vereinfachung müssen Gewichte und Vorspannung auf 0 und die Lernrate auf 1 gesetzt werden.
Step 2 - Fahren Sie mit Schritt 3-8 fort, wenn die Stoppbedingung nicht erfüllt ist.
Step 3 - Fahren Sie für jedes bipolare Trainingspaar mit Schritt 4-6 fort s:t.
Step 4 - Aktivieren Sie jede Eingabeeinheit wie folgt: -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: bis \: n) $$
Step 5 - Erhalten Sie die Nettoeingabe mit der folgenden Beziehung -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {i} $$
Hier ‘b’ ist Voreingenommenheit und ‘n’ ist die Gesamtzahl der Eingangsneuronen.
Step 6 - Wenden Sie die folgende Aktivierungsfunktion an, um die endgültige Ausgabe zu erhalten -
$$ f (y_ {in}) \: = \: \ begin {case} 1 & if \: y_ {in} \: \ geqslant \: 0 \\ - 1 & if \: y_ {in} \: < \: 0 \ end {Fälle} $$
Step 7 - Stellen Sie das Gewicht und die Vorspannung wie folgt ein -
Case 1 - wenn y ≠ t dann,
$$ w_ {i} (neu) \: = \: w_ {i} (alt) \: + \: \ alpha (t \: - \: y_ {in}) x_ {i} $$
$$ b (neu) \: = \: b (alt) \: + \: \ alpha (t \: - \: y_ {in}) $$
Case 2 - wenn y = t dann,
$$ w_ {i} (neu) \: = \: w_ {i} (alt) $$
$$ b (neu) \: = \: b (alt) $$
Hier ‘y’ ist die tatsächliche Ausgabe und ‘t’ ist die gewünschte / Zielausgabe.
$ (t \: - \; y_ {in}) $ ist der berechnete Fehler.
Step 8 - Testen Sie den Stoppzustand, der auftritt, wenn sich das Gewicht nicht ändert oder die höchste Gewichtsänderung während des Trainings kleiner als die angegebene Toleranz ist.
Mehrfaches adaptives lineares Neuron (Madaline)
Madaline, das für Multiple Adaptive Linear Neuron steht, ist ein Netzwerk, das aus vielen Adalinen parallel besteht. Es wird eine einzelne Ausgabeeinheit haben. Einige wichtige Punkte über Madaline sind wie folgt:
Es ist wie bei einem mehrschichtigen Perzeptron, bei dem Adaline als verborgene Einheit zwischen dem Eingang und der Madaline-Ebene fungiert.
Die Gewichte und die Vorspannung zwischen der Eingabe- und der Adaline-Ebene sind, wie wir in der Adaline-Architektur sehen, einstellbar.
Die Adaline- und Madaline-Schichten haben feste Gewichte und eine Vorspannung von 1.
Das Training kann mit Hilfe der Delta-Regel durchgeführt werden.
Die Architektur
Die Architektur von Madaline besteht aus “n” Neuronen der Eingangsschicht, “m”Neuronen der Adaline-Schicht und 1 Neuron der Madaline-Schicht. Die Adaline-Ebene kann als verborgene Ebene betrachtet werden, da sie sich zwischen der Eingabeebene und der Ausgabeebene befindet, dh der Madaline-Ebene.
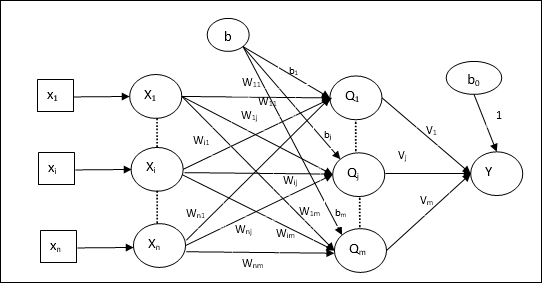
Trainingsalgorithmus
Inzwischen wissen wir, dass nur die Gewichte und Vorspannungen zwischen der Eingabe- und der Adaline-Schicht angepasst werden müssen und die Gewichte und Vorspannungen zwischen der Adaline- und der Madaline-Schicht festgelegt werden.
Step 1 - Initialisieren Sie Folgendes, um das Training zu starten -
- Weights
- Bias
- Lernrate $ \ alpha $
Zur einfachen Berechnung und Vereinfachung müssen Gewichte und Vorspannung auf 0 und die Lernrate auf 1 gesetzt werden.
Step 2 - Fahren Sie mit Schritt 3-8 fort, wenn die Stoppbedingung nicht erfüllt ist.
Step 3 - Fahren Sie für jedes bipolare Trainingspaar mit Schritt 4-6 fort s:t.
Step 4 - Aktivieren Sie jede Eingabeeinheit wie folgt: -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: bis \: n) $$
Step 5 - Erhalten Sie die Nettoeingabe für jede verborgene Schicht, dh die Adaline-Schicht mit der folgenden Beziehung -
$$ Q_ {inj} \: = \: b_ {j} \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {ij} \: \: \: j \: = \: 1 \: bis \: m $$
Hier ‘b’ ist Voreingenommenheit und ‘n’ ist die Gesamtzahl der Eingangsneuronen.
Step 6 - Wenden Sie die folgende Aktivierungsfunktion an, um die endgültige Ausgabe auf der Adaline- und der Madaline-Ebene zu erhalten. -
$$ f (x) \: = \: \ begin {Fälle} 1 & if \: x \: \ geqslant \: 0 \\ - 1 & if \: x \: <\: 0 \ end {Fälle} $ $
Ausgabe an der versteckten (Adaline) Einheit
$$ Q_ {j} \: = \: f (Q_ {inj}) $$
Endgültige Ausgabe des Netzwerks
$$ y \: = \: f (y_ {in}) $$
i.e. $ \: \: y_ {inj} \: = \: b_ {0} \: + \: \ sum_ {j = 1} ^ m \: Q_ {j} \: v_ {j} $
Step 7 - Berechnen Sie den Fehler und passen Sie die Gewichte wie folgt an -
Case 1 - wenn y ≠ t und t = 1 dann,
$$ w_ {ij} (neu) \: = \: w_ {ij} (alt) \: + \: \ alpha (1 \: - \: Q_ {inj}) x_ {i} $$
$$ b_ {j} (neu) \: = \: b_ {j} (alt) \: + \: \ alpha (1 \: - \: Q_ {inj}) $$
In diesem Fall würden die Gewichte aktualisiert Qj wo der Nettoeingang nahe 0 ist, weil t = 1.
Case 2 - wenn y ≠ t und t = -1 dann,
$$ w_ {ik} (neu) \: = \: w_ {ik} (alt) \: + \: \ alpha (-1 \: - \: Q_ {ink}) x_ {i} $$
$$ b_ {k} (neu) \: = \: b_ {k} (alt) \: + \: \ alpha (-1 \: - \: Q_ {ink}) $$
In diesem Fall würden die Gewichte aktualisiert Qk wo der Nettoeintrag positiv ist, weil t = -1.
Hier ‘y’ ist die tatsächliche Ausgabe und ‘t’ ist die gewünschte / Zielausgabe.
Case 3 - wenn y = t dann
Es würde keine Gewichtsänderung geben.
Step 8 - Testen Sie den Stoppzustand, der auftritt, wenn sich das Gewicht nicht ändert oder die höchste Gewichtsänderung während des Trainings kleiner als die angegebene Toleranz ist.
Neuronale Netze mit Rückausbreitung
Back Propagation Neural (BPN) ist ein mehrschichtiges neuronales Netzwerk, das aus der Eingangsschicht, mindestens einer verborgenen Schicht und einer Ausgangsschicht besteht. Wie der Name schon sagt, findet in diesem Netzwerk eine Rückübertragung statt. Der Fehler, der auf der Ausgabeschicht durch Vergleichen der Zielausgabe und der tatsächlichen Ausgabe berechnet wird, wird zurück in die Eingabeschicht übertragen.
Die Architektur
Wie in dem Diagramm gezeigt, weist die Architektur von BPN drei miteinander verbundene Schichten mit Gewichten auf. Sowohl die verborgene Schicht als auch die Ausgangsschicht haben eine Vorspannung, deren Gewicht immer 1 beträgt. Wie aus dem Diagramm hervorgeht, erfolgt die Arbeit von BPN in zwei Phasen. Eine Phase sendet das Signal von der Eingangsschicht an die Ausgangsschicht, und die andere Phase gibt den Fehler von der Ausgangsschicht an die Eingangsschicht zurück.

Trainingsalgorithmus
Für das Training verwendet BPN die binäre Sigmoid-Aktivierungsfunktion. Das Training von BPN wird die folgenden drei Phasen haben.
Phase 1 - Vorwärtskopplungsphase
Phase 2 - Zurück Fehlerausbreitung
Phase 3 - Aktualisierung der Gewichte
Alle diese Schritte werden im Algorithmus wie folgt abgeschlossen
Step 1 - Initialisieren Sie Folgendes, um das Training zu starten -
- Weights
- Lernrate $ \ alpha $
Nehmen Sie zur einfachen Berechnung und Vereinfachung einige kleine Zufallswerte.
Step 2 - Fahren Sie mit Schritt 3-11 fort, wenn die Stoppbedingung nicht erfüllt ist.
Step 3 - Fahren Sie für jedes Trainingspaar mit Schritt 4-10 fort.
Phase 1
Step 4 - Jede Eingabeeinheit empfängt ein Eingangssignal xi und sendet es an die versteckte Einheit für alle i = 1 to n
Step 5 - Berechnen Sie den Nettoeintrag an der versteckten Einheit unter Verwendung der folgenden Beziehung:
$$ Q_ {inj} \: = \: b_ {0j} \: + \: \ sum_ {i = 1} ^ n x_ {i} v_ {ij} \: \: \: \: j \: = \ : 1 \: to \: p $$
Hier b0j ist die Vorspannung auf versteckte Einheit, vij ist das Gewicht auf j Einheit der verborgenen Schicht aus i Einheit der Eingabeebene.
Berechnen Sie nun die Nettoleistung mit der folgenden Aktivierungsfunktion
$$ Q_ {j} \: = \: f (Q_ {inj}) $$
Senden Sie diese Ausgangssignale der Hidden-Layer-Einheiten an die Output-Layer-Einheiten.
Step 6 - Berechnen Sie die Nettoeingabe an der Ausgabeebene unter Verwendung der folgenden Beziehung:
$$ y_ {ink} \: = \: b_ {0k} \: + \: \ sum_ {j = 1} ^ p \: Q_ {j} \: w_ {jk} \: \: k \: = \ : 1 \: to \: m $$
Hier b0k Ist die Vorspannung an der Ausgabeeinheit, wjk ist das Gewicht auf k Einheit der Ausgangsschicht von j Einheit der verborgenen Schicht.
Berechnen Sie die Nettoleistung mit der folgenden Aktivierungsfunktion
$$ y_ {k} \: = \: f (y_ {ink}) $$
Phase 2
Step 7 - Berechnen Sie den Fehlerkorrekturterm in Übereinstimmung mit dem an jeder Ausgabeeinheit empfangenen Zielmuster wie folgt: -
$$ \ delta_ {k} \: = \ :( t_ {k} \: - \: y_ {k}) f ^ {'} (y_ {ink}) $$
Aktualisieren Sie auf dieser Basis das Gewicht und die Vorspannung wie folgt:
$$ \ Delta v_ {jk} \: = \: \ alpha \ delta_ {k} \: Q_ {ij} $$
$$ \ Delta b_ {0k} \: = \: \ alpha \ delta_ {k} $$
Senden Sie dann $ \ delta_ {k} $ zurück an die verborgene Ebene.
Step 8 - Jetzt ist jede versteckte Einheit die Summe ihrer Delta-Eingänge von den Ausgabeeinheiten.
$$ \ delta_ {inj} \: = \: \ displaystyle \ sum \ limit_ {k = 1} ^ m \ delta_ {k} \: w_ {jk} $$
Der Fehlerterm kann wie folgt berechnet werden:
$$ \ delta_ {j} \: = \: \ delta_ {inj} f ^ {'} (Q_ {inj}) $$
Aktualisieren Sie auf dieser Basis das Gewicht und die Vorspannung wie folgt:
$$ \ Delta w_ {ij} \: = \: \ alpha \ delta_ {j} x_ {i} $$
$$ \ Delta b_ {0j} \: = \: \ alpha \ delta_ {j} $$
Phase 3
Step 9 - Jede Ausgabeeinheit (ykk = 1 to m) aktualisiert das Gewicht und die Vorspannung wie folgt:
$$ v_ {jk} (neu) \: = \: v_ {jk} (alt) \: + \: \ Delta v_ {jk} $$
$$ b_ {0k} (neu) \: = \: b_ {0k} (alt) \: + \: \ Delta b_ {0k} $$
Step 10 - Jede Ausgabeeinheit (zjj = 1 to p) aktualisiert das Gewicht und die Vorspannung wie folgt:
$$ w_ {ij} (neu) \: = \: w_ {ij} (alt) \: + \: \ Delta w_ {ij} $$
$$ b_ {0j} (neu) \: = \: b_ {0j} (alt) \: + \: \ Delta b_ {0j} $$
Step 11 - Überprüfen Sie, ob der Stoppzustand vorliegt. Dies kann entweder die Anzahl der erreichten Epochen sein oder die Zielausgabe entspricht der tatsächlichen Ausgabe.
Verallgemeinerte Delta-Lernregel
Die Delta-Regel funktioniert nur für die Ausgabeebene. Auf der anderen Seite verallgemeinerte Delta-Regel, auch als bezeichnetback-propagation Regel ist eine Möglichkeit, die gewünschten Werte der verborgenen Ebene zu erstellen.
Mathematische Formulierung
Für die Aktivierungsfunktion $ y_ {k} \: = \: f (y_ {ink}) $ kann die Ableitung der Nettoeingabe sowohl auf der verborgenen Ebene als auch auf der Ausgabeebene durch gegeben sein
$$ y_ {ink} \: = \: \ displaystyle \ sum \ limit_i \: z_ {i} w_ {jk} $$
Und $ \: \: y_ {inj} \: = \: \ sum_i x_ {i} v_ {ij} $
Nun ist der Fehler, der minimiert werden muss,
$$ E \: = \: \ frac {1} {2} \ displaystyle \ sum \ limit_ {k} \: [t_ {k} \: - \: y_ {k}] ^ 2 $$
Mit der Kettenregel haben wir
$$ \ frac {\ partielles E} {\ partielles w_ {jk}} \: = \: \ frac {\ partielles} {\ partielles w_ {jk}} (\ frac {1} {2} \ displaystyle \ sum \ Grenzen_ {k} \: [t_ {k} \: - \: y_ {k}] ^ 2) $$
$$ = \: \ frac {\ partiell} {\ partiell w_ {jk}} \ lgroup \ frac {1} {2} [t_ {k} \: - \: t (y_ {ink})] ^ 2 \ rgroup $$
$$ = \: - [t_ {k} \: - \: y_ {k}] \ frac {\ teilweise} {\ teilweise w_ {jk}} f (y_ {Tinte}) $$
$$ = \: - [t_ {k} \: - \: y_ {k}] f (y_ {Tinte}) \ frac {\ Teil} {\ Teil w_ {jk}} (y_ {Tinte}) $$
$$ = \: - [t_ {k} \: - \: y_ {k}] f ^ {'} (y_ {ink}) z_ {j} $$
Sagen wir nun $ \ delta_ {k} \: = \: - [t_ {k} \: - \: y_ {k}] f ^ {'} (y_ {ink}) $
Die Gewichte bei Verbindungen zur versteckten Einheit zj kann gegeben werden durch -
$$ \ frac {\ partielles E} {\ partielles v_ {ij}} \: = \: - \ displaystyle \ sum \ limit_ {k} \ delta_ {k} \ frac {\ partielles} {\ partielles v_ {ij} } \ :( y_ {ink}) $$
Wenn Sie den Wert von $ y_ {ink} $ eingeben, erhalten Sie Folgendes
$$ \ delta_ {j} \: = \: - \ displaystyle \ sum \ limit_ {k} \ delta_ {k} w_ {jk} f ^ {'} (z_ {inj}) $$
Die Gewichtsaktualisierung kann wie folgt erfolgen:
Für die Ausgabeeinheit -
$$ \ Delta w_ {jk} \: = \: - \ alpha \ frac {\ partielles E} {\ partielles w_ {jk}} $$
$$ = \: \ alpha \: \ delta_ {k} \: z_ {j} $$
Für die versteckte Einheit -
$$ \ Delta v_ {ij} \: = \: - \ alpha \ frac {\ partielles E} {\ partielles v_ {ij}} $$
$$ = \: \ alpha \: \ delta_ {j} \: x_ {i} $$