Künstliches Neuronales Netz - Kurzanleitung
Neuronale Netze sind parallele Computergeräte, was im Grunde ein Versuch ist, ein Computermodell des Gehirns zu erstellen. Das Hauptziel besteht darin, ein System zu entwickeln, mit dem verschiedene Rechenaufgaben schneller als mit herkömmlichen Systemen ausgeführt werden können. Diese Aufgaben umfassen Mustererkennung und -klassifizierung, Approximation, Optimierung und Datenclustering.
Was ist ein künstliches neuronales Netzwerk?
Das künstliche neuronale Netz (ANN) ist ein effizientes Computersystem, dessen zentrales Thema der Analogie biologischer neuronaler Netze entlehnt ist. ANNs werden auch als "künstliche neuronale Systeme" oder "parallel verteilte Verarbeitungssysteme" oder "verbindungsorientierte Systeme" bezeichnet. ANN erwirbt eine große Sammlung von Einheiten, die in einem bestimmten Muster miteinander verbunden sind, um die Kommunikation zwischen den Einheiten zu ermöglichen. Diese Einheiten, auch als Knoten oder Neuronen bezeichnet, sind einfache Prozessoren, die parallel arbeiten.
Jedes Neuron ist über eine Verbindungsverbindung mit einem anderen Neuron verbunden. Jeder Verbindungsverbindung ist ein Gewicht zugeordnet, das Informationen über das Eingangssignal enthält. Dies ist die nützlichste Information für Neuronen, um ein bestimmtes Problem zu lösen, da das Gewicht normalerweise das übertragene Signal anregt oder hemmt. Jedes Neuron hat einen internen Zustand, der als Aktivierungssignal bezeichnet wird. Ausgangssignale, die nach dem Kombinieren der Eingangssignale und der Aktivierungsregel erzeugt werden, können an andere Einheiten gesendet werden.
Eine kurze Geschichte von ANN
Die Geschichte von ANN kann in die folgenden drei Epochen unterteilt werden:
ANN in den 1940er bis 1960er Jahren
Einige Schlüsselentwicklungen dieser Ära sind wie folgt:
1943 - Es wurde angenommen, dass das Konzept des neuronalen Netzwerks mit der Arbeit des Physiologen Warren McCulloch und des Mathematikers Walter Pitts begann, als sie 1943 ein einfaches neuronales Netzwerk unter Verwendung elektrischer Schaltkreise modellierten, um zu beschreiben, wie Neuronen im Gehirn funktionieren könnten .
1949- Donald Hebbs Buch The Organization of Behavior ( Die Organisation des Verhaltens) hat die Tatsache hervorgehoben, dass die wiederholte Aktivierung eines Neurons durch ein anderes seine Stärke bei jeder Verwendung erhöht.
1956 - Taylor hat ein assoziatives Speichernetzwerk eingeführt.
1958 - Eine Lernmethode für das McCulloch- und Pitts-Neuronenmodell namens Perceptron wurde von Rosenblatt erfunden.
1960 - Bernard Widrow und Marcian Hoff entwickelten Modelle mit den Namen "ADALINE" und "MADALINE".
ANN in den 1960er bis 1980er Jahren
Einige Schlüsselentwicklungen dieser Ära sind wie folgt:
1961 - Rosenblatt unternahm einen erfolglosen Versuch, schlug jedoch das "Backpropagation" -Schema für mehrschichtige Netzwerke vor.
1964 - Taylor konstruierte eine Winner-Take-All-Schaltung mit Hemmungen zwischen den Ausgabeeinheiten.
1969 - Multilayer Perceptron (MLP) wurde von Minsky und Papert erfunden.
1971 - Kohonen entwickelte assoziative Erinnerungen.
1976 - Stephen Grossberg und Gail Carpenter entwickelten die adaptive Resonanztheorie.
ANN von 1980 bis heute
Einige Schlüsselentwicklungen dieser Ära sind wie folgt:
1982 - Die Hauptentwicklung war der Energieansatz von Hopfield.
1985 - Die Boltzmann-Maschine wurde von Ackley, Hinton und Sejnowski entwickelt.
1986 - Rumelhart, Hinton und Williams führten die Generalized Delta Rule ein.
1988 - Kosko entwickelte das Binary Associative Memory (BAM) und gab das Konzept der Fuzzy Logic in ANN bekannt.
Der historische Rückblick zeigt, dass in diesem Bereich erhebliche Fortschritte erzielt wurden. Auf neuronalen Netzen basierende Chips entstehen und Anwendungen für komplexe Probleme werden entwickelt. Sicherlich ist heute eine Übergangsphase für die neuronale Netzwerktechnologie.
Biologisches Neuron
Eine Nervenzelle (Neuron) ist eine spezielle biologische Zelle, die Informationen verarbeitet. Nach einer Schätzung gibt es eine große Anzahl von Neuronen, ungefähr 10 11 mit zahlreichen Verbindungen, ungefähr 10 15 .
Schematische Darstellung
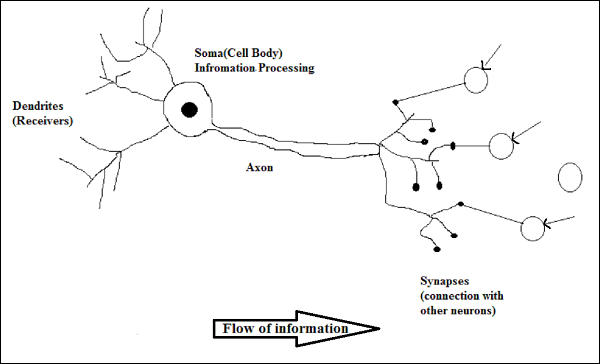
Arbeiten eines biologischen Neurons
Wie im obigen Diagramm gezeigt, besteht ein typisches Neuron aus den folgenden vier Teilen, mit deren Hilfe wir seine Funktionsweise erklären können:
Dendrites- Sie sind baumartige Zweige, die für den Empfang der Informationen von anderen Neuronen verantwortlich sind, mit denen sie verbunden sind. In einem anderen Sinne können wir sagen, dass sie wie die Ohren von Neuronen sind.
Soma - Es ist der Zellkörper des Neurons und verantwortlich für die Verarbeitung von Informationen, die sie von Dendriten erhalten haben.
Axon - Es ist wie ein Kabel, über das Neuronen die Informationen senden.
Synapses - Es ist die Verbindung zwischen dem Axon und anderen Neuronendendriten.
ANN gegen BNN
Bevor wir uns die Unterschiede zwischen dem künstlichen neuronalen Netzwerk (ANN) und dem biologischen neuronalen Netzwerk (BNN) ansehen, wollen wir uns die Ähnlichkeiten ansehen, die auf der Terminologie zwischen diesen beiden basieren.
| Biologisches Neuronales Netz (BNN) | Künstliches Neuronales Netz (ANN) |
|---|---|
| Soma | Knoten |
| Dendriten | Eingang |
| Synapse | Gewichte oder Verbindungen |
| Axon | Ausgabe |
Die folgende Tabelle zeigt den Vergleich zwischen ANN und BNN anhand einiger genannter Kriterien.
| Kriterien | BNN | ANN |
|---|---|---|
| Processing | Massiv parallel, langsam, aber überlegen als ANN | Massiv parallel, schnell, aber schlechter als BNN |
| Size | 10 11 Neuronen und 10 15 Verbindungen | 10 2 bis 10 4 Knoten (hängt hauptsächlich von der Art der Anwendung und dem Netzwerkdesigner ab) |
| Learning | Sie können Mehrdeutigkeiten tolerieren | Um Mehrdeutigkeiten zu tolerieren, sind sehr genaue, strukturierte und formatierte Daten erforderlich |
| Fault tolerance | Die Leistung verschlechtert sich bereits bei teilweisem Schaden | Es ist zu einer robusten Leistung fähig und kann daher fehlertolerant sein |
| Storage capacity | Speichert die Informationen in der Synapse | Speichert die Informationen an fortlaufenden Speicherorten |
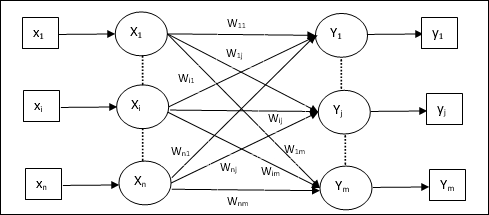
Modell eines künstlichen neuronalen Netzwerks
Das folgende Diagramm zeigt das allgemeine Modell von ANN, gefolgt von seiner Verarbeitung.
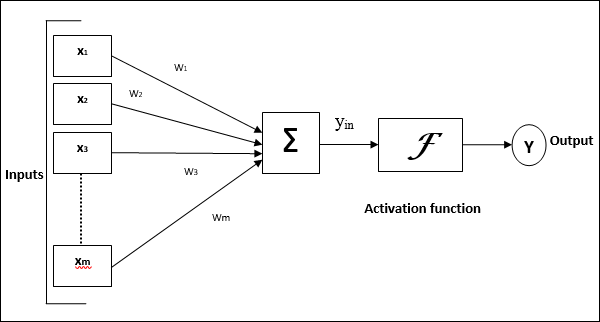
Für das obige allgemeine Modell eines künstlichen neuronalen Netzwerks kann die Nettoeingabe wie folgt berechnet werden:
$$ y_ {in} \: = \: x_ {1} .w_ {1} \: + \: x_ {2} .w_ {2} \: + \: x_ {3} .w_ {3} \: \ dotso \: x_ {m} .w_ {m} $$
dh Nettoeingabe $ y_ {in} \: = \: \ sum_i ^ m \: x_ {i} .w_ {i} $
Die Ausgabe kann berechnet werden, indem die Aktivierungsfunktion auf die Nettoeingabe angewendet wird.
$$ Y \: = \: F (y_ {in}) $$
Output = Funktion (Nettoeingang berechnet)
Die Verarbeitung von ANN hängt von den folgenden drei Bausteinen ab:
- Netzwerktopologie
- Gewichtsanpassungen oder Lernen
- Aktivierungsfunktionen
In diesem Kapitel werden wir diese drei Bausteine von ANN ausführlich diskutieren
Netzwerktopologie
Eine Netzwerktopologie ist die Anordnung eines Netzwerks zusammen mit seinen Knoten und Verbindungslinien. Entsprechend der Topologie kann ANN wie folgt klassifiziert werden:
Feedforward-Netzwerk
Es ist ein nicht wiederkehrendes Netzwerk mit Verarbeitungseinheiten / Knoten in Schichten, und alle Knoten in einer Schicht sind mit den Knoten der vorherigen Schichten verbunden. Die Verbindung hat unterschiedliche Gewichte. Es gibt keine Rückkopplungsschleife, dh das Signal kann nur in eine Richtung von Eingang zu Ausgang fließen. Es kann in die folgenden zwei Typen unterteilt werden -
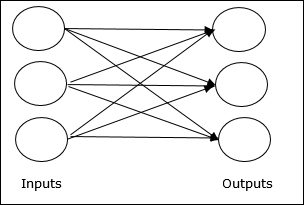
Single layer feedforward network- Das Konzept besteht darin, dass Feedforward-ANN nur eine gewichtete Schicht aufweist. Mit anderen Worten können wir sagen, dass die Eingabeschicht vollständig mit der Ausgabeschicht verbunden ist.
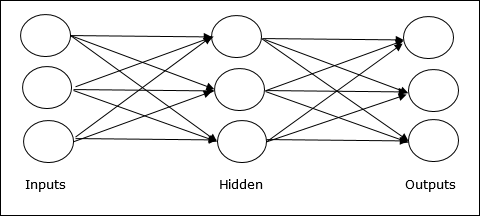
Multilayer feedforward network- Das Konzept besteht darin, dass Feedforward-ANN mehr als eine gewichtete Schicht aufweist. Da dieses Netzwerk eine oder mehrere Schichten zwischen der Eingabe- und der Ausgabeschicht hat, wird es als versteckte Schichten bezeichnet.
Feedback-Netzwerk
Wie der Name schon sagt, verfügt ein Rückkopplungsnetzwerk über Rückkopplungspfade, was bedeutet, dass das Signal mithilfe von Schleifen in beide Richtungen fließen kann. Dies macht es zu einem nichtlinearen dynamischen System, das sich kontinuierlich ändert, bis es einen Gleichgewichtszustand erreicht. Es kann in die folgenden Typen unterteilt werden:
Recurrent networks- Sie sind Rückkopplungsnetzwerke mit geschlossenen Schleifen. Im Folgenden sind die beiden Arten von wiederkehrenden Netzwerken aufgeführt.
Fully recurrent network - Dies ist die einfachste neuronale Netzwerkarchitektur, da alle Knoten mit allen anderen Knoten verbunden sind und jeder Knoten sowohl als Eingabe als auch als Ausgabe fungiert.
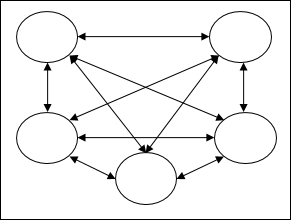
Jordan network - Es handelt sich um ein Netzwerk mit geschlossenem Regelkreis, in dem der Ausgang als Rückmeldung wieder an den Eingang geht, wie in der folgenden Abbildung dargestellt.
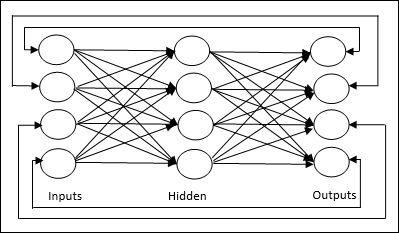
Gewichtsanpassungen oder Lernen
Lernen in einem künstlichen neuronalen Netzwerk ist die Methode zum Ändern der Verbindungsgewichte zwischen den Neuronen eines bestimmten Netzwerks. Das Lernen in ANN kann in drei Kategorien eingeteilt werden, nämlich überwachtes Lernen, unbeaufsichtigtes Lernen und verstärkendes Lernen.
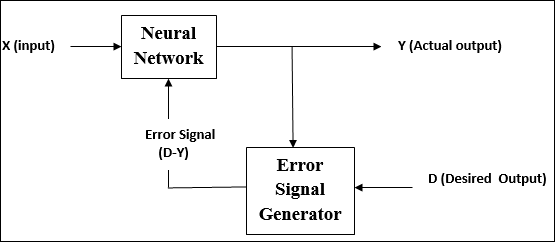
Überwachtes Lernen
Wie der Name schon sagt, wird diese Art des Lernens unter der Aufsicht eines Lehrers durchgeführt. Dieser Lernprozess ist abhängig.
Während des Trainings von ANN unter überwachtem Lernen wird der Eingabevektor dem Netzwerk präsentiert, das einen Ausgabevektor ergibt. Dieser Ausgabevektor wird mit dem gewünschten Ausgabevektor verglichen. Ein Fehlersignal wird erzeugt, wenn zwischen dem tatsächlichen Ausgang und dem gewünschten Ausgangsvektor ein Unterschied besteht. Auf der Grundlage dieses Fehlersignals werden die Gewichte angepasst, bis die tatsächliche Ausgabe mit der gewünschten Ausgabe übereinstimmt.
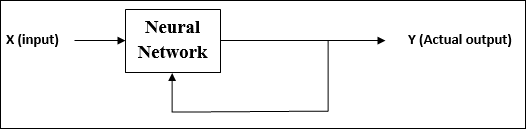
Unbeaufsichtigtes Lernen
Wie der Name schon sagt, wird diese Art des Lernens ohne Aufsicht eines Lehrers durchgeführt. Dieser Lernprozess ist unabhängig.
Während des Trainings von ANN unter unbeaufsichtigtem Lernen werden die Eingabevektoren ähnlichen Typs zu Clustern kombiniert. Wenn ein neues Eingabemuster angewendet wird, gibt das neuronale Netzwerk eine Ausgabeantwort aus, die die Klasse angibt, zu der das Eingabemuster gehört.
Es gibt keine Rückmeldung von der Umgebung, welche Ausgabe gewünscht werden soll und ob sie richtig oder falsch ist. Daher muss bei dieser Art des Lernens das Netzwerk selbst die Muster und Merkmale aus den Eingabedaten und die Beziehung für die Eingabedaten über die Ausgabe ermitteln.
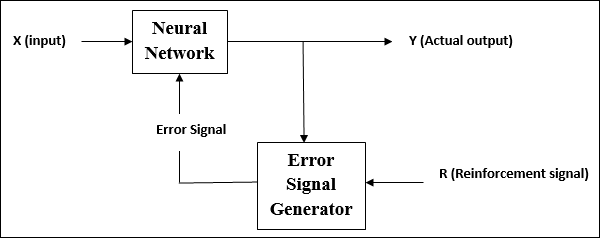
Verstärkungslernen
Wie der Name schon sagt, wird diese Art des Lernens verwendet, um das Netzwerk über einige kritische Informationen zu stärken oder zu stärken. Dieser Lernprozess ähnelt dem überwachten Lernen, wir haben jedoch möglicherweise weniger Informationen.
Während des Trainings des Netzwerks unter verstärkendem Lernen erhält das Netzwerk einige Rückmeldungen aus der Umgebung. Dies macht es dem überwachten Lernen etwas ähnlich. Das hier erhaltene Feedback ist jedoch bewertend und nicht lehrreich, was bedeutet, dass es keinen Lehrer wie beim überwachten Lernen gibt. Nach Erhalt des Feedbacks nimmt das Netzwerk Anpassungen der Gewichte vor, um in Zukunft bessere Kritikerinformationen zu erhalten.
Aktivierungsfunktionen
Es kann als die zusätzliche Kraft oder Anstrengung definiert werden, die auf die Eingabe ausgeübt wird, um eine genaue Ausgabe zu erhalten. In ANN können wir auch Aktivierungsfunktionen auf den Eingang anwenden, um den genauen Ausgang zu erhalten. Im Folgenden sind einige interessante Aktivierungsfunktionen aufgeführt:
Lineare Aktivierungsfunktion
Es wird auch als Identitätsfunktion bezeichnet, da keine Eingabebearbeitung durchgeführt wird. Es kann definiert werden als -
$$ F (x) \: = \: x $$
Sigmoid-Aktivierungsfunktion
Es ist von zwei Arten wie folgt -
Binary sigmoidal function- Diese Aktivierungsfunktion führt eine Eingabebearbeitung zwischen 0 und 1 durch. Sie ist positiver Natur. Es ist immer begrenzt, was bedeutet, dass seine Ausgabe nicht kleiner als 0 und mehr als 1 sein kann. Es nimmt auch streng an Natur zu, was bedeutet, dass mehr die höhere Ausgabe die Ausgabe wäre. Es kann definiert werden als
$$ F (x) \: = \: sigm (x) \: = \: \ frac {1} {1 \: + \: exp (-x)} $$
Bipolar sigmoidal function- Diese Aktivierungsfunktion führt eine Eingabebearbeitung zwischen -1 und 1 durch. Sie kann positiver oder negativer Natur sein. Es ist immer begrenzt, was bedeutet, dass seine Ausgabe nicht kleiner als -1 und mehr als 1 sein kann. Es nimmt auch in der Natur streng zu, wie die Sigmoidfunktion. Es kann definiert werden als
$$ F (x) \: = \: sigm (x) \: = \: \ frac {2} {1 \: + \: exp (-x)} \: - \: 1 \: = \: \ frac {1 \: - \: exp (x)} {1 \: + \: exp (x)} $$
Wie bereits erwähnt, ist ANN vollständig von der Art und Weise inspiriert, wie das biologische Nervensystem, dh das menschliche Gehirn, funktioniert. Das beeindruckendste Merkmal des menschlichen Gehirns ist das Lernen, daher wird das gleiche Merkmal von ANN erworben.
Was ist Lernen in ANN?
Lernen bedeutet im Grunde, die Veränderung an sich selbst zu tun und anzupassen, wenn sich die Umgebung ändert. ANN ist ein komplexes System, oder genauer gesagt, es ist ein komplexes adaptives System, das seine interne Struktur basierend auf den durchlaufenden Informationen ändern kann.
Warum ist es wichtig?
Als komplexes adaptives System impliziert das Lernen in ANN, dass eine Verarbeitungseinheit in der Lage ist, ihr Eingabe- / Ausgabeverhalten aufgrund der Änderung der Umgebung zu ändern. Die Bedeutung des Lernens in ANN nimmt aufgrund der festen Aktivierungsfunktion sowie des Eingabe- / Ausgabevektors zu, wenn ein bestimmtes Netzwerk aufgebaut wird. Um nun das Eingabe- / Ausgabeverhalten zu ändern, müssen wir die Gewichte anpassen.
Einstufung
Es kann als der Prozess des Lernens definiert werden, die Daten von Proben in verschiedene Klassen zu unterscheiden, indem gemeinsame Merkmale zwischen den Proben derselben Klassen gefunden werden. Um beispielsweise das Training von ANN durchzuführen, haben wir einige Trainingsbeispiele mit einzigartigen Merkmalen, und um das Testen durchzuführen, haben wir einige Testbeispiele mit anderen einzigartigen Merkmalen. Die Klassifizierung ist ein Beispiel für überwachtes Lernen.
Lernregeln für neuronale Netze
Wir wissen, dass wir während des ANN-Lernens die Gewichte anpassen müssen, um das Eingabe- / Ausgabeverhalten zu ändern. Daher ist eine Methode erforderlich, mit deren Hilfe die Gewichte modifiziert werden können. Diese Methoden werden als Lernregeln bezeichnet, bei denen es sich lediglich um Algorithmen oder Gleichungen handelt. Im Folgenden finden Sie einige Lernregeln für das neuronale Netzwerk:
Hebbische Lernregel
Diese Regel, eine der ältesten und einfachsten, wurde 1949 von Donald Hebb in seinem Buch The Organization of Behavior eingeführt . Es ist eine Art unbeaufsichtigtes Lernen.
Basic Concept - Diese Regel basiert auf einem Vorschlag von Hebb, der schrieb -
„Wenn ein Axon von Zelle A nahe genug ist, um eine Zelle B anzuregen, und wiederholt oder dauerhaft am Brennen beteiligt ist, findet in einer oder beiden Zellen ein Wachstumsprozess oder eine Stoffwechseländerung statt, so dass die Effizienz von A als eine der Zellen, die B feuern , erhöht."
Aus dem obigen Postulat können wir schließen, dass die Verbindungen zwischen zwei Neuronen verstärkt werden können, wenn die Neuronen gleichzeitig feuern, und geschwächt werden können, wenn sie zu unterschiedlichen Zeiten feuern.
Mathematical Formulation - Gemäß der hebräischen Lernregel folgt die folgende Formel, um das Gewicht der Verbindung bei jedem Zeitschritt zu erhöhen.
$$ \ Delta w_ {ji} (t) \: = \: \ alpha x_ {i} (t) .y_ {j} (t) $$
Hier ist $ \ Delta w_ {ji} (t) $ = Inkrement, um das das Gewicht der Verbindung im Zeitschritt zunimmt t
$ \ alpha $ = die positive und konstante Lernrate
$ x_ {i} (t) $ = der Eingabewert des prä-synaptischen Neurons zum Zeitpunkt t
$ y_ {i} (t) $ = die Ausgabe des prä-synaptischen Neurons im gleichen Zeitschritt t
Perceptron-Lernregel
Diese Regel ist ein Fehler, der den von Rosenblatt eingeführten überwachten Lernalgorithmus von einschichtigen Feedforward-Netzwerken mit linearer Aktivierungsfunktion korrigiert.
Basic Concept- Da dies von Natur aus überwacht wird, würde zur Berechnung des Fehlers ein Vergleich zwischen der gewünschten / Zielausgabe und der tatsächlichen Ausgabe durchgeführt. Wenn ein Unterschied festgestellt wird, müssen die Verbindungsgewichte geändert werden.
Mathematical Formulation - Um seine mathematische Formulierung zu erklären, nehmen wir an, wir haben 'n' Anzahl endlicher Eingabevektoren x (n) zusammen mit dem gewünschten / Ziel-Ausgabevektor t (n), wobei n = 1 bis N ist.
Nun kann die Ausgabe 'y' berechnet werden, wie zuvor auf der Grundlage der Nettoeingabe erläutert, und die Aktivierungsfunktion, die auf diese Nettoeingabe angewendet wird, kann wie folgt ausgedrückt werden:
$$ y \: = \: f (y_ {in}) \: = \: \ begin {case} 1, & y_ {in} \:> \: \ theta \\ 0, & y_ {in} \: \ leqslant \: \ theta \ end {case} $$
Wo θ ist Schwelle.
Die Aktualisierung des Gewichts kann in den folgenden zwei Fällen erfolgen:
Case I - wann t ≠ y, dann
$$ w (neu) \: = \: w (alt) \: + \; tx $$
Case II - wann t = y, dann
Keine Gewichtsveränderung
Delta-Lernregel (Widrow-Hoff-Regel)
Es wird von Bernard Widrow und Marcian Hoff, auch als Least Mean Square (LMS) -Methode bezeichnet, eingeführt, um den Fehler über alle Trainingsmuster hinweg zu minimieren. Es ist eine Art überwachter Lernalgorithmus mit kontinuierlicher Aktivierungsfunktion.
Basic Concept- Die Basis dieser Regel ist der Gradientenabstiegsansatz, der für immer andauert. Die Delta-Regel aktualisiert die synaptischen Gewichte, um die Nettoeingabe in die Ausgabeeinheit und den Zielwert zu minimieren.
Mathematical Formulation - Um die synaptischen Gewichte zu aktualisieren, ist die Delta-Regel gegeben durch
$$ \ Delta w_ {i} \: = \: \ alpha \:. X_ {i} .e_ {j} $$
Hier $ \ Delta w_ {i} $ = Gewichtsänderung für i th pattern;
$ \ alpha $ = die positive und konstante Lernrate;
$ x_ {i} $ = der Eingabewert des prä-synaptischen Neurons;
$ e_ {j} $ = $ (t \: - \: y_ {in}) $, die Differenz zwischen der gewünschten / Zielausgabe und der tatsächlichen Ausgabe $ y_ {in} $
Die obige Delta-Regel gilt nur für eine einzelne Ausgabeeinheit.
Die Aktualisierung des Gewichts kann in den folgenden zwei Fällen erfolgen:
Case-I - wann t ≠ y, dann
$$ w (neu) \: = \: w (alt) \: + \: \ Delta w $$
Case-II - wann t = y, dann
Keine Gewichtsveränderung
Wettbewerbsorientierte Lernregel (Winner-take-all)
Es handelt sich um unbeaufsichtigtes Training, bei dem die Ausgabeknoten versuchen, miteinander zu konkurrieren, um das Eingabemuster darzustellen. Um diese Lernregel zu verstehen, müssen wir das Wettbewerbsnetzwerk verstehen, das wie folgt angegeben ist:
Basic Concept of Competitive Network- Dieses Netzwerk ist wie ein Single-Layer-Feedforward-Netzwerk mit Rückkopplungsverbindung zwischen den Ausgängen. Die Verbindungen zwischen den Ausgängen sind hemmend und werden durch gepunktete Linien dargestellt, was bedeutet, dass sich die Konkurrenten niemals selbst unterstützen.
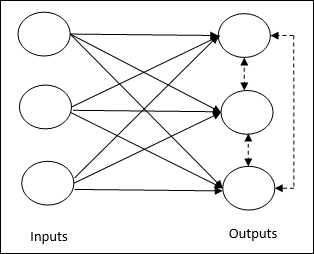
Basic Concept of Competitive Learning Rule- Wie bereits erwähnt, wird es einen Wettbewerb zwischen den Ausgabeknoten geben. Daher besteht das Hauptkonzept darin, dass während des Trainings die Ausgabeeinheit mit der höchsten Aktivierung für ein bestimmtes Eingabemuster zum Gewinner erklärt wird. Diese Regel wird auch als Winner-Takes-All bezeichnet, da nur das Gewinner-Neuron aktualisiert wird und der Rest der Neuronen unverändert bleibt.
Mathematical formulation - Im Folgenden sind die drei wichtigen Faktoren für die mathematische Formulierung dieser Lernregel aufgeführt:
Condition to be a winner - Angenommen, wenn ein Neuron $ y_ {k} $ der Gewinner sein möchte, dann gibt es die folgende Bedingung:
$$ y_ {k} \: = \: \ begin {case} 1 & if \: v_ {k} \:> \: v_ {j} \: für \: all \: j, \: j \: \ neq \: k \\ 0 & sonst \ end {Fälle} $$
Dies bedeutet, dass, wenn ein Neuron, beispielsweise $ y_ {k} $ , gewinnen möchte, sein induziertes lokales Feld (die Ausgabe der Summationseinheit), beispielsweise $ v_ {k} $, das größte unter allen anderen Neuronen sein muss im Netzwerk.
Condition of sum total of weight - Eine weitere Einschränkung gegenüber der Wettbewerbsregel besteht darin, dass die Gesamtsumme der Gewichte für ein bestimmtes Ausgangsneuron 1 beträgt. Wenn wir beispielsweise ein Neuron betrachten k dann -
$$ \ displaystyle \ sum \ limit_ {j} w_ {kj} \: = \: 1 \: \: \: \: \: \: \: \: \: für \: all \: k $$
Change of weight for winner- Wenn ein Neuron nicht auf das Eingabemuster reagiert, findet in diesem Neuron kein Lernen statt. Wenn jedoch ein bestimmtes Neuron gewinnt, werden die entsprechenden Gewichte wie folgt angepasst
$$ \ Delta w_ {kj} \: = \: \ begin {case} - \ alpha (x_ {j} \: - \: w_ {kj}), & if \: neuron \: k \: gewinnt \\ 0, & if \: neuron \: k \: Verluste \ Ende {Fälle} $$
Hier ist $ \ alpha $ die Lernrate.
Dies zeigt deutlich, dass wir das gewinnende Neuron bevorzugen, indem wir sein Gewicht anpassen. Wenn es einen Neuronenverlust gibt, müssen wir uns nicht die Mühe machen, sein Gewicht neu anzupassen.
Outstar-Lernregel
Diese von Grossberg eingeführte Regel befasst sich mit überwachtem Lernen, da die gewünschten Ergebnisse bekannt sind. Es wird auch Grossberg-Lernen genannt.
Basic Concept- Diese Regel wird auf die in einer Schicht angeordneten Neuronen angewendet. Es wurde speziell entwickelt, um die gewünschte Leistung zu erzielend der Schicht von p Neuronen.
Mathematical Formulation - Die Gewichtsanpassungen in dieser Regel werden wie folgt berechnet
$$ \ Delta w_ {j} \: = \: \ alpha \ :( d \: - \: w_ {j}) $$
Hier d ist die gewünschte Neuronenausgabe und $ \ alpha $ ist die Lernrate.
Wie der Name schon sagt, supervised learningfindet unter der Aufsicht eines Lehrers statt. Dieser Lernprozess ist abhängig. Während des Trainings von ANN unter überwachtem Lernen wird der Eingabevektor dem Netzwerk präsentiert, das einen Ausgabevektor erzeugt. Dieser Ausgabevektor wird mit dem gewünschten / Ziel-Ausgabevektor verglichen. Ein Fehlersignal wird erzeugt, wenn zwischen dem tatsächlichen Ausgang und dem gewünschten / Ziel-Ausgangsvektor ein Unterschied besteht. Auf der Grundlage dieses Fehlersignals würden die Gewichte angepasst, bis die tatsächliche Ausgabe mit der gewünschten Ausgabe übereinstimmt.
Perceptron
Perzeptron wurde von Frank Rosenblatt unter Verwendung des McCulloch- und Pitts-Modells entwickelt und ist die grundlegende Betriebseinheit künstlicher neuronaler Netze. Es verwendet eine überwachte Lernregel und kann die Daten in zwei Klassen einteilen.
Funktionsmerkmale des Perzeptrons: Es besteht aus einem einzelnen Neuron mit einer beliebigen Anzahl von Eingaben und einstellbaren Gewichten, aber die Ausgabe des Neurons beträgt je nach Schwellenwert 1 oder 0. Es besteht auch aus einer Vorspannung, deren Gewicht immer 1 beträgt. Die folgende Abbildung zeigt eine schematische Darstellung des Perzeptrons.
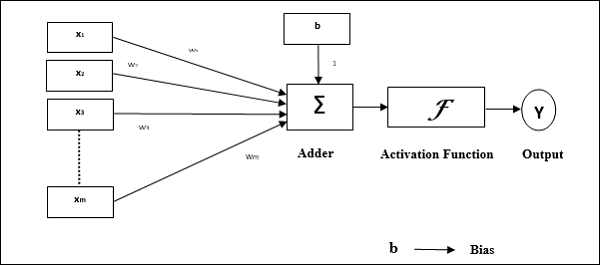
Perceptron hat also die folgenden drei Grundelemente:
Links - Es hätte eine Reihe von Verbindungsgliedern, die ein Gewicht einschließlich einer Vorspannung tragen, die immer das Gewicht 1 hat.
Adder - Es fügt die Eingabe hinzu, nachdem sie mit ihren jeweiligen Gewichten multipliziert wurden.
Activation function- Es begrenzt die Ausgabe von Neuronen. Die grundlegendste Aktivierungsfunktion ist eine Heaviside-Schrittfunktion mit zwei möglichen Ausgängen. Diese Funktion gibt 1 zurück, wenn der Eingang positiv ist, und 0 für jeden negativen Eingang.
Trainingsalgorithmus
Das Perceptron-Netzwerk kann sowohl für eine Ausgabeeinheit als auch für mehrere Ausgabeeinheiten trainiert werden.
Trainingsalgorithmus für eine einzelne Ausgabeeinheit
Step 1 - Initialisieren Sie Folgendes, um das Training zu starten -
- Weights
- Bias
- Lernrate $ \ alpha $
Zur einfachen Berechnung und Vereinfachung müssen Gewichte und Vorspannung gleich 0 und die Lernrate gleich 1 gesetzt werden.
Step 2 - Fahren Sie mit Schritt 3-8 fort, wenn die Stoppbedingung nicht erfüllt ist.
Step 3 - Fahren Sie für jeden Trainingsvektor mit Schritt 4-6 fort x.
Step 4 - Aktivieren Sie jede Eingabeeinheit wie folgt: -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: bis \: n) $$
Step 5 - Erhalten Sie nun den Nettoeingang mit der folgenden Beziehung -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i}. \: w_ {i} $$
Hier ‘b’ ist Voreingenommenheit und ‘n’ ist die Gesamtzahl der Eingangsneuronen.
Step 6 - Wenden Sie die folgende Aktivierungsfunktion an, um die endgültige Ausgabe zu erhalten.
$$ f (y_ {in}) \: = \: \ begin {case} 1 & if \: y_ {in} \:> \: \ theta \\ 0 & if \: - \ theta \: \ leqslant \ : y_ {in} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {in} \: <\: - \ theta \ end {case} $$
Step 7 - Stellen Sie das Gewicht und die Vorspannung wie folgt ein -
Case 1 - wenn y ≠ t dann,
$$ w_ {i} (neu) \: = \: w_ {i} (alt) \: + \: \ alpha \: tx_ {i} $$
$$ b (neu) \: = \: b (alt) \: + \: \ alpha t $$
Case 2 - wenn y = t dann,
$$ w_ {i} (neu) \: = \: w_ {i} (alt) $$
$$ b (neu) \: = \: b (alt) $$
Hier ‘y’ ist die tatsächliche Ausgabe und ‘t’ ist die gewünschte / Zielausgabe.
Step 8 - Prüfen Sie den Stoppzustand, der auftreten würde, wenn sich das Gewicht nicht ändert.
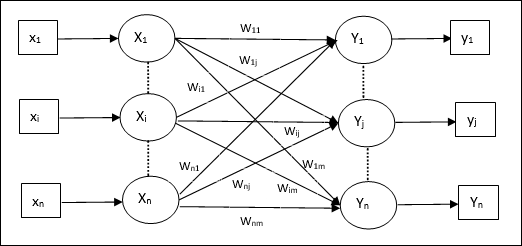
Trainingsalgorithmus für mehrere Ausgabeeinheiten
Das folgende Diagramm zeigt die Architektur von Perzeptron für mehrere Ausgabeklassen.
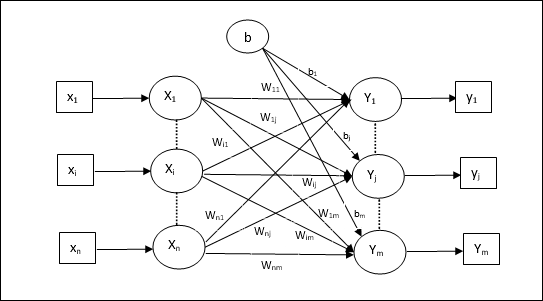
Step 1 - Initialisieren Sie Folgendes, um das Training zu starten -
- Weights
- Bias
- Lernrate $ \ alpha $
Zur einfachen Berechnung und Vereinfachung müssen Gewichte und Vorspannung gleich 0 und die Lernrate gleich 1 gesetzt werden.
Step 2 - Fahren Sie mit Schritt 3-8 fort, wenn die Stoppbedingung nicht erfüllt ist.
Step 3 - Fahren Sie für jeden Trainingsvektor mit Schritt 4-6 fort x.
Step 4 - Aktivieren Sie jede Eingabeeinheit wie folgt: -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: bis \: n) $$
Step 5 - Erhalten Sie die Nettoeingabe mit der folgenden Beziehung -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {ij} $$
Hier ‘b’ ist Voreingenommenheit und ‘n’ ist die Gesamtzahl der Eingangsneuronen.
Step 6 - Wenden Sie die folgende Aktivierungsfunktion an, um die endgültige Ausgabe für jede Ausgabeeinheit zu erhalten j = 1 to m - -
$$ f (y_ {in}) \: = \: \ begin {case} 1 & if \: y_ {inj} \:> \: \ theta \\ 0 & if \: - \ theta \: \ leqslant \ : y_ {inj} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {inj} \: <\: - \ theta \ end {case} $$
Step 7 - Stellen Sie das Gewicht und die Vorspannung für ein x = 1 to n und j = 1 to m wie folgt -
Case 1 - wenn yj ≠ tj dann,
$$ w_ {ij} (neu) \: = \: w_ {ij} (alt) \: + \: \ alpha \: t_ {j} x_ {i} $$
$$ b_ {j} (neu) \: = \: b_ {j} (alt) \: + \: \ alpha t_ {j} $$
Case 2 - wenn yj = tj dann,
$$ w_ {ij} (neu) \: = \: w_ {ij} (alt) $$
$$ b_ {j} (neu) \: = \: b_ {j} (alt) $$
Hier ‘y’ ist die tatsächliche Ausgabe und ‘t’ ist die gewünschte / Zielausgabe.
Step 8 - Prüfen Sie den Stoppzustand, der auftritt, wenn sich das Gewicht nicht ändert.
Adaptives lineares Neuron (Adaline)
Adaline, das für Adaptive Linear Neuron steht, ist ein Netzwerk mit einer einzigen linearen Einheit. Es wurde 1960 von Widrow und Hoff entwickelt. Einige wichtige Punkte über Adaline sind:
Es verwendet eine bipolare Aktivierungsfunktion.
Es verwendet eine Delta-Regel für das Training, um den mittleren quadratischen Fehler (MSE) zwischen der tatsächlichen Ausgabe und der gewünschten / Zielausgabe zu minimieren.
Die Gewichte und die Vorspannung sind einstellbar.
Die Architektur
Die Grundstruktur von Adaline ähnelt der von Perzeptron mit einer zusätzlichen Rückkopplungsschleife, mit deren Hilfe die tatsächliche Ausgabe mit der gewünschten / Zielausgabe verglichen wird. Nach dem Vergleich auf der Basis des Trainingsalgorithmus werden die Gewichte und die Vorspannung aktualisiert.
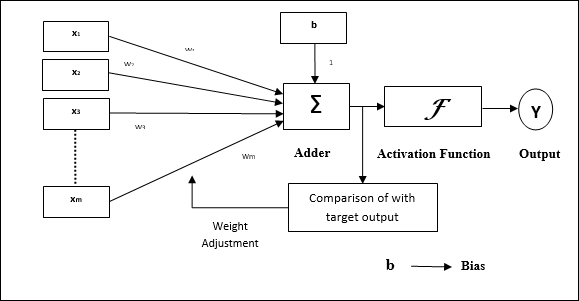
Trainingsalgorithmus
Step 1 - Initialisieren Sie Folgendes, um das Training zu starten -
- Weights
- Bias
- Lernrate $ \ alpha $
Zur einfachen Berechnung und Vereinfachung müssen Gewichte und Vorspannung gleich 0 und die Lernrate gleich 1 gesetzt werden.
Step 2 - Fahren Sie mit Schritt 3-8 fort, wenn die Stoppbedingung nicht erfüllt ist.
Step 3 - Fahren Sie für jedes bipolare Trainingspaar mit Schritt 4-6 fort s:t.
Step 4 - Aktivieren Sie jede Eingabeeinheit wie folgt: -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: bis \: n) $$
Step 5 - Erhalten Sie die Nettoeingabe mit der folgenden Beziehung -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {i} $$
Hier ‘b’ ist Voreingenommenheit und ‘n’ ist die Gesamtzahl der Eingangsneuronen.
Step 6 - Wenden Sie die folgende Aktivierungsfunktion an, um die endgültige Ausgabe zu erhalten -
$$ f (y_ {in}) \: = \: \ begin {case} 1 & if \: y_ {in} \: \ geqslant \: 0 \\ - 1 & if \: y_ {in} \: < \: 0 \ end {Fälle} $$
Step 7 - Stellen Sie das Gewicht und die Vorspannung wie folgt ein -
Case 1 - wenn y ≠ t dann,
$$ w_ {i} (neu) \: = \: w_ {i} (alt) \: + \: \ alpha (t \: - \: y_ {in}) x_ {i} $$
$$ b (neu) \: = \: b (alt) \: + \: \ alpha (t \: - \: y_ {in}) $$
Case 2 - wenn y = t dann,
$$ w_ {i} (neu) \: = \: w_ {i} (alt) $$
$$ b (neu) \: = \: b (alt) $$
Hier ‘y’ ist die tatsächliche Ausgabe und ‘t’ ist die gewünschte / Zielausgabe.
$ (t \: - \; y_ {in}) $ ist der berechnete Fehler.
Step 8 - Testen Sie den Stoppzustand, der auftritt, wenn sich das Gewicht nicht ändert oder die höchste Gewichtsänderung während des Trainings kleiner als die angegebene Toleranz ist.
Mehrfaches adaptives lineares Neuron (Madaline)
Madaline, das für Multiple Adaptive Linear Neuron steht, ist ein Netzwerk, das aus vielen Adalinen parallel besteht. Es wird eine einzelne Ausgabeeinheit haben. Einige wichtige Punkte über Madaline sind wie folgt:
Es ist wie bei einem mehrschichtigen Perzeptron, bei dem Adaline als verborgene Einheit zwischen dem Eingang und der Madaline-Ebene fungiert.
Die Gewichte und die Vorspannung zwischen der Eingabe- und der Adaline-Ebene sind, wie wir in der Adaline-Architektur sehen, einstellbar.
Die Adaline- und Madaline-Schichten haben feste Gewichte und eine Vorspannung von 1.
Das Training kann mit Hilfe der Delta-Regel durchgeführt werden.
Die Architektur
Die Architektur von Madaline besteht aus “n” Neuronen der Eingangsschicht, “m”Neuronen der Adaline-Schicht und 1 Neuron der Madaline-Schicht. Die Adaline-Ebene kann als verborgene Ebene betrachtet werden, da sie sich zwischen der Eingabe- und der Ausgabeebene befindet, dh der Madaline-Ebene.
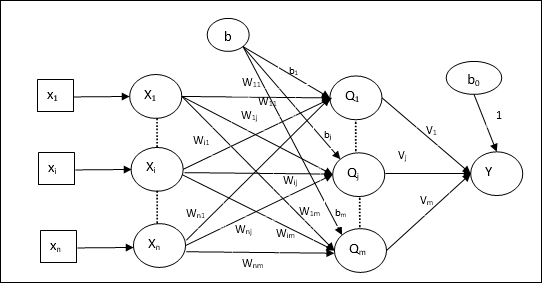
Trainingsalgorithmus
Inzwischen wissen wir, dass nur die Gewichte und Vorspannungen zwischen der Eingabe- und der Adaline-Schicht angepasst werden müssen und die Gewichte und Vorspannungen zwischen der Adaline- und der Madaline-Schicht festgelegt werden.
Step 1 - Initialisieren Sie Folgendes, um das Training zu starten -
- Weights
- Bias
- Lernrate $ \ alpha $
Zur einfachen Berechnung und Vereinfachung müssen Gewichte und Vorspannung gleich 0 und die Lernrate gleich 1 gesetzt werden.
Step 2 - Fahren Sie mit Schritt 3-8 fort, wenn die Stoppbedingung nicht erfüllt ist.
Step 3 - Fahren Sie für jedes bipolare Trainingspaar mit Schritt 4-6 fort s:t.
Step 4 - Aktivieren Sie jede Eingabeeinheit wie folgt: -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: bis \: n) $$
Step 5 - Erhalten Sie die Nettoeingabe für jede verborgene Schicht, dh die Adaline-Schicht mit der folgenden Beziehung -
$$ Q_ {inj} \: = \: b_ {j} \: + \: \ displaystyle \ sum \ limit_ {i} ^ n x_ {i} \: w_ {ij} \: \: \: j \: = \: 1 \: bis \: m $$
Hier ‘b’ ist Voreingenommenheit und ‘n’ ist die Gesamtzahl der Eingangsneuronen.
Step 6 - Wenden Sie die folgende Aktivierungsfunktion an, um die endgültige Ausgabe auf der Adaline- und der Madaline-Ebene zu erhalten. -
$$ f (x) \: = \: \ begin {Fälle} 1 & if \: x \: \ geqslant \: 0 \\ - 1 & if \: x \: <\: 0 \ end {Fälle} $ $
Ausgabe an der versteckten (Adaline) Einheit
$$ Q_ {j} \: = \: f (Q_ {inj}) $$
Endgültige Ausgabe des Netzwerks
$$ y \: = \: f (y_ {in}) $$
i.e. $ \: \: y_ {inj} \: = \: b_ {0} \: + \: \ sum_ {j = 1} ^ m \: Q_ {j} \: v_ {j} $
Step 7 - Berechnen Sie den Fehler und passen Sie die Gewichte wie folgt an -
Case 1 - wenn y ≠ t und t = 1 dann,
$$ w_ {ij} (neu) \: = \: w_ {ij} (alt) \: + \: \ alpha (1 \: - \: Q_ {inj}) x_ {i} $$
$$ b_ {j} (neu) \: = \: b_ {j} (alt) \: + \: \ alpha (1 \: - \: Q_ {inj}) $$
In diesem Fall würden die Gewichte aktualisiert Qj wo der Nettoeingang nahe 0 ist, weil t = 1.
Case 2 - wenn y ≠ t und t = -1 dann,
$$ w_ {ik} (neu) \: = \: w_ {ik} (alt) \: + \: \ alpha (-1 \: - \: Q_ {ink}) x_ {i} $$
$$ b_ {k} (neu) \: = \: b_ {k} (alt) \: + \: \ alpha (-1 \: - \: Q_ {ink}) $$
In diesem Fall würden die Gewichte aktualisiert Qk wo der Nettoeintrag positiv ist, weil t = -1.
Hier ‘y’ ist die tatsächliche Ausgabe und ‘t’ ist die gewünschte / Zielausgabe.
Case 3 - wenn y = t dann
Es würde keine Gewichtsänderung geben.
Step 8 - Testen Sie den Stoppzustand, der auftritt, wenn sich das Gewicht nicht ändert oder die höchste Gewichtsänderung während des Trainings kleiner als die angegebene Toleranz ist.
Neuronale Netze mit Rückausbreitung
Back Propagation Neural (BPN) ist ein mehrschichtiges neuronales Netzwerk, das aus der Eingangsschicht, mindestens einer verborgenen Schicht und einer Ausgangsschicht besteht. Wie der Name schon sagt, findet in diesem Netzwerk eine Rückübertragung statt. Der Fehler, der auf der Ausgabeschicht durch Vergleichen der Zielausgabe und der tatsächlichen Ausgabe berechnet wird, wird zurück in die Eingabeschicht übertragen.
Die Architektur
Wie in dem Diagramm gezeigt, weist die Architektur von BPN drei miteinander verbundene Schichten mit Gewichten auf. Sowohl die verborgene Schicht als auch die Ausgangsschicht haben eine Vorspannung, deren Gewicht immer 1 beträgt. Wie aus dem Diagramm hervorgeht, erfolgt die Arbeit von BPN in zwei Phasen. Eine Phase sendet das Signal von der Eingangsschicht an die Ausgangsschicht, und die andere Phase gibt den Fehler von der Ausgangsschicht an die Eingangsschicht zurück.

Trainingsalgorithmus
Für das Training verwendet BPN die binäre Sigmoid-Aktivierungsfunktion. Das Training von BPN wird die folgenden drei Phasen haben.
Phase 1 - Vorwärtskopplungsphase
Phase 2 - Zurück Fehlerausbreitung
Phase 3 - Aktualisierung der Gewichte
Alle diese Schritte werden im Algorithmus wie folgt abgeschlossen
Step 1 - Initialisieren Sie Folgendes, um das Training zu starten -
- Weights
- Lernrate $ \ alpha $
Nehmen Sie zur einfachen Berechnung und Vereinfachung einige kleine Zufallswerte.
Step 2 - Fahren Sie mit Schritt 3-11 fort, wenn die Stoppbedingung nicht erfüllt ist.
Step 3 - Fahren Sie für jedes Trainingspaar mit Schritt 4-10 fort.
Phase 1
Step 4 - Jede Eingabeeinheit empfängt ein Eingangssignal xi und sendet es an die versteckte Einheit für alle i = 1 to n
Step 5 - Berechnen Sie den Nettoeintrag an der versteckten Einheit unter Verwendung der folgenden Beziehung:
$$ Q_ {inj} \: = \: b_ {0j} \: + \: \ sum_ {i = 1} ^ n x_ {i} v_ {ij} \: \: \: \: j \: = \ : 1 \: to \: p $$
Hier b0j ist die Vorspannung auf versteckte Einheit, vij ist das Gewicht auf j Einheit der verborgenen Schicht aus i Einheit der Eingabeebene.
Berechnen Sie nun die Nettoleistung mit der folgenden Aktivierungsfunktion
$$ Q_ {j} \: = \: f (Q_ {inj}) $$
Senden Sie diese Ausgangssignale der Hidden-Layer-Einheiten an die Output-Layer-Einheiten.
Step 6 - Berechnen Sie die Nettoeingabe an der Ausgabeebene unter Verwendung der folgenden Beziehung:
$$ y_ {ink} \: = \: b_ {0k} \: + \: \ sum_ {j = 1} ^ p \: Q_ {j} \: w_ {jk} \: \: k \: = \ : 1 \: to \: m $$
Hier b0k Ist die Vorspannung an der Ausgabeeinheit, wjk ist das Gewicht auf k Einheit der Ausgangsschicht von j Einheit der verborgenen Schicht.
Berechnen Sie die Nettoleistung mit der folgenden Aktivierungsfunktion
$$ y_ {k} \: = \: f (y_ {ink}) $$
Phase 2
Step 7 - Berechnen Sie den Fehlerkorrekturterm in Übereinstimmung mit dem an jeder Ausgabeeinheit empfangenen Zielmuster wie folgt: -
$$ \ delta_ {k} \: = \ :( t_ {k} \: - \: y_ {k}) f ^ {'} (y_ {ink}) $$
Aktualisieren Sie auf dieser Basis das Gewicht und die Vorspannung wie folgt:
$$ \ Delta v_ {jk} \: = \: \ alpha \ delta_ {k} \: Q_ {ij} $$
$$ \ Delta b_ {0k} \: = \: \ alpha \ delta_ {k} $$
Senden Sie dann $ \ delta_ {k} $ zurück an die verborgene Ebene.
Step 8 - Jetzt ist jede versteckte Einheit die Summe ihrer Delta-Eingänge von den Ausgabeeinheiten.
$$ \ delta_ {inj} \: = \: \ displaystyle \ sum \ limit_ {k = 1} ^ m \ delta_ {k} \: w_ {jk} $$
Der Fehlerterm kann wie folgt berechnet werden:
$$ \ delta_ {j} \: = \: \ delta_ {inj} f ^ {'} (Q_ {inj}) $$
Aktualisieren Sie auf dieser Basis das Gewicht und die Vorspannung wie folgt:
$$ \ Delta w_ {ij} \: = \: \ alpha \ delta_ {j} x_ {i} $$
$$ \ Delta b_ {0j} \: = \: \ alpha \ delta_ {j} $$
Phase 3
Step 9 - Jede Ausgabeeinheit (ykk = 1 to m) aktualisiert das Gewicht und die Vorspannung wie folgt:
$$ v_ {jk} (neu) \: = \: v_ {jk} (alt) \: + \: \ Delta v_ {jk} $$
$$ b_ {0k} (neu) \: = \: b_ {0k} (alt) \: + \: \ Delta b_ {0k} $$
Step 10 - Jede Ausgabeeinheit (zjj = 1 to p) aktualisiert das Gewicht und die Vorspannung wie folgt:
$$ w_ {ij} (neu) \: = \: w_ {ij} (alt) \: + \: \ Delta w_ {ij} $$
$$ b_ {0j} (neu) \: = \: b_ {0j} (alt) \: + \: \ Delta b_ {0j} $$
Step 11 - Überprüfen Sie, ob der Stoppzustand vorliegt. Dies kann entweder die Anzahl der erreichten Epochen sein oder die Zielausgabe entspricht der tatsächlichen Ausgabe.
Verallgemeinerte Delta-Lernregel
Die Delta-Regel funktioniert nur für die Ausgabeebene. Auf der anderen Seite verallgemeinerte Delta-Regel, auch als bezeichnetback-propagation Regel ist eine Möglichkeit, die gewünschten Werte der verborgenen Ebene zu erstellen.
Mathematische Formulierung
Für die Aktivierungsfunktion $ y_ {k} \: = \: f (y_ {ink}) $ kann die Ableitung der Nettoeingabe sowohl auf der verborgenen Ebene als auch auf der Ausgabeebene durch gegeben sein
$$ y_ {ink} \: = \: \ displaystyle \ sum \ limit_i \: z_ {i} w_ {jk} $$
Und $ \: \: y_ {inj} \: = \: \ sum_i x_ {i} v_ {ij} $
Nun ist der Fehler, der minimiert werden muss,
$$ E \: = \: \ frac {1} {2} \ displaystyle \ sum \ limit_ {k} \: [t_ {k} \: - \: y_ {k}] ^ 2 $$
Mit der Kettenregel haben wir
$$ \ frac {\ partielles E} {\ partielles w_ {jk}} \: = \: \ frac {\ partielles} {\ partielles w_ {jk}} (\ frac {1} {2} \ displaystyle \ sum \ Grenzen_ {k} \: [t_ {k} \: - \: y_ {k}] ^ 2) $$
$$ = \: \ frac {\ partiell} {\ partiell w_ {jk}} \ lgroup \ frac {1} {2} [t_ {k} \: - \: t (y_ {ink})] ^ 2 \ rgroup $$
$$ = \: - [t_ {k} \: - \: y_ {k}] \ frac {\ teilweise} {\ teilweise w_ {jk}} f (y_ {Tinte}) $$
$$ = \: - [t_ {k} \: - \: y_ {k}] f (y_ {Tinte}) \ frac {\ Teil} {\ Teil w_ {jk}} (y_ {Tinte}) $$
$$ = \: - [t_ {k} \: - \: y_ {k}] f ^ {'} (y_ {ink}) z_ {j} $$
Sagen wir nun $ \ delta_ {k} \: = \: - [t_ {k} \: - \: y_ {k}] f ^ {'} (y_ {ink}) $
Die Gewichte bei Verbindungen zur versteckten Einheit zj kann gegeben werden durch -
$$ \ frac {\ partielles E} {\ partielles v_ {ij}} \: = \: - \ displaystyle \ sum \ limit_ {k} \ delta_ {k} \ frac {\ partielles} {\ partielles v_ {ij} } \ :( y_ {ink}) $$
Wenn Sie den Wert von $ y_ {ink} $ eingeben, erhalten Sie Folgendes
$$ \ delta_ {j} \: = \: - \ displaystyle \ sum \ limit_ {k} \ delta_ {k} w_ {jk} f ^ {'} (z_ {inj}) $$
Die Gewichtsaktualisierung kann wie folgt erfolgen:
Für die Ausgabeeinheit -
$$ \ Delta w_ {jk} \: = \: - \ alpha \ frac {\ partielles E} {\ partielles w_ {jk}} $$
$$ = \: \ alpha \: \ delta_ {k} \: z_ {j} $$
Für die versteckte Einheit -
$$ \ Delta v_ {ij} \: = \: - \ alpha \ frac {\ partielles E} {\ partielles v_ {ij}} $$
$$ = \: \ alpha \: \ delta_ {j} \: x_ {i} $$
Wie der Name schon sagt, wird diese Art des Lernens ohne Aufsicht eines Lehrers durchgeführt. Dieser Lernprozess ist unabhängig. Während des Trainings von ANN unter unbeaufsichtigtem Lernen werden die Eingabevektoren ähnlichen Typs zu Clustern kombiniert. Wenn ein neues Eingabemuster angewendet wird, gibt das neuronale Netzwerk eine Ausgabeantwort aus, die die Klasse angibt, zu der das Eingabemuster gehört. Dabei würde es keine Rückmeldung von der Umgebung geben, was die gewünschte Ausgabe sein sollte und ob sie richtig oder falsch ist. Daher muss bei dieser Art des Lernens das Netzwerk selbst die Muster, Merkmale aus den Eingabedaten und die Beziehung für die Eingabedaten über die Ausgabe ermitteln.
Winner-Takes-All-Netzwerke
Diese Art von Netzwerken basiert auf der wettbewerbsorientierten Lernregel und verwendet die Strategie, bei der das Neuron mit den größten Gesamteingaben als Gewinner ausgewählt wird. Die Verbindungen zwischen den Ausgangsneuronen zeigen, dass die Konkurrenz zwischen ihnen und einem von ihnen "EIN" wäre, was bedeutet, dass es der Gewinner wäre und andere "AUS" wären.
Im Folgenden sind einige der Netzwerke aufgeführt, die auf diesem einfachen Konzept basieren und unbeaufsichtigtes Lernen verwenden.
Hamming-Netzwerk
In den meisten neuronalen Netzen, die unbeaufsichtigtes Lernen verwenden, ist es wichtig, die Entfernung zu berechnen und Vergleiche durchzuführen. Diese Art von Netzwerk ist ein Hamming-Netzwerk, bei dem für jeden gegebenen Eingangsvektor verschiedene Gruppen zusammengefasst werden. Im Folgenden sind einige wichtige Funktionen von Hamming Networks aufgeführt:
Lippmann begann 1987 mit der Arbeit an Hamming-Netzwerken.
Es ist ein Single-Layer-Netzwerk.
Die Eingänge können entweder binär {0, 1} oder bipolar {-1, 1} sein.
Die Gewichte des Netzes werden durch die beispielhaften Vektoren berechnet.
Es ist ein Netzwerk mit festem Gewicht, was bedeutet, dass die Gewichte auch während des Trainings gleich bleiben.
Max Net
Dies ist auch ein Netzwerk mit fester Gewichtung, das als Subnetz für die Auswahl des Knotens mit der höchsten Eingabe dient. Alle Knoten sind vollständig miteinander verbunden, und in all diesen gewichteten Verbindungen sind symmetrische Gewichte vorhanden.
Die Architektur
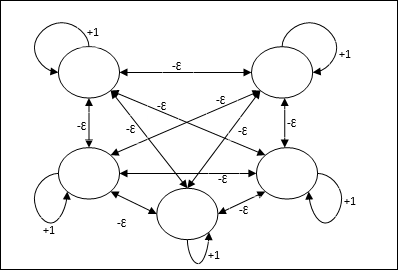
Es verwendet den Mechanismus, der ein iterativer Prozess ist, und jeder Knoten empfängt über Verbindungen hemmende Eingaben von allen anderen Knoten. Der einzelne Knoten, dessen Wert maximal ist, wäre aktiv oder Gewinner, und die Aktivierungen aller anderen Knoten wären inaktiv. Max Net verwendet die Identitätsaktivierungsfunktion mit $$ f (x) \: = \: \ begin {Fällen} x & if \: x> 0 \\ 0 & if \: x \ leq 0 \ end {Fälle} $$
Die Aufgabe dieses Netzes wird durch das Selbstanregungsgewicht von +1 und die Größe der gegenseitigen Hemmung erfüllt, die wie [0 <ɛ <$ \ frac {1} {m} $] eingestellt ist, wobei “m” ist die Gesamtzahl der Knoten.
Wettbewerbsfähiges Lernen in ANN
Es handelt sich um unbeaufsichtigtes Training, bei dem die Ausgabeknoten versuchen, miteinander zu konkurrieren, um das Eingabemuster darzustellen. Um diese Lernregel zu verstehen, müssen wir das Wettbewerbsnetz verstehen, das wie folgt erklärt wird:
Grundkonzept des Wettbewerbsnetzwerks
Dieses Netzwerk ist wie ein Single-Layer-Feed-Forward-Netzwerk mit einer Rückkopplungsverbindung zwischen den Ausgängen. Die Verbindungen zwischen den Ausgängen sind hemmend, was durch gepunktete Linien dargestellt wird, was bedeutet, dass sich die Konkurrenten niemals selbst unterstützen.
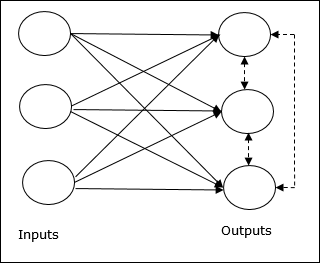
Grundkonzept der Wettbewerbsregel
Wie bereits erwähnt, würde es einen Wettbewerb zwischen den Ausgabeknoten geben, daher lautet das Hauptkonzept: Während des Trainings wird die Ausgabeeinheit, die für ein bestimmtes Eingabemuster die höchste Aktivierung aufweist, zum Gewinner erklärt. Diese Regel wird auch als Winner-Takes-All bezeichnet, da nur das Gewinner-Neuron aktualisiert wird und der Rest der Neuronen unverändert bleibt.
Mathematische Formulierung
Im Folgenden sind die drei wichtigen Faktoren für die mathematische Formulierung dieser Lernregel aufgeführt:
Voraussetzung, um ein Gewinner zu sein
Angenommen, ein Neuron yk will der Gewinner sein, dann gäbe es folgende Bedingung
$$ y_ {k} \: = \: \ begin {case} 1 & if \: v_ {k}> v_ {j} \: für \: all \: \: j, \: j \: \ neq \ : k \\ 0 & sonst \ end {Fälle} $$
Es bedeutet, dass wenn irgendein Neuron, sagen wir, yk will gewinnen, dann sein induziertes lokales Feld (die Ausgabe der Summationseinheit), sagen wir vkmuss das größte unter allen anderen Neuronen im Netzwerk sein.
Zustand der Gesamtsumme des Gewichts
Eine weitere Einschränkung gegenüber der Regel des kompetitiven Lernens besteht darin, dass die Gesamtsumme der Gewichte für ein bestimmtes Ausgangsneuron 1 beträgt. Wenn wir beispielsweise ein Neuron betrachten k dann
$$ \ displaystyle \ sum \ limit_ {k} w_ {kj} \: = \: 1 \: \: \: \: für \: all \: \: k $$
Gewichtsänderung für den Gewinner
Wenn ein Neuron nicht auf das Eingabemuster reagiert, findet in diesem Neuron kein Lernen statt. Wenn jedoch ein bestimmtes Neuron gewinnt, werden die entsprechenden Gewichte wie folgt angepasst:
$$ \ Delta w_ {kj} \: = \: \ begin {case} - \ alpha (x_ {j} \: - \: w_ {kj}), & if \: neuron \: k \: gewinnt \\ 0 & if \: neuron \: k \: Verluste \ end {Fälle} $$
Hier ist $ \ alpha $ die Lernrate.
Dies zeigt deutlich, dass wir das gewinnende Neuron bevorzugen, indem wir sein Gewicht anpassen. Wenn ein Neuron verloren geht, müssen wir uns nicht die Mühe machen, sein Gewicht neu anzupassen.
K-bedeutet Clustering-Algorithmus
K-means ist einer der beliebtesten Clustering-Algorithmen, bei denen wir das Konzept der Partitionsprozedur verwenden. Wir beginnen mit einer anfänglichen Partition und verschieben Muster wiederholt von einem Cluster in einen anderen, bis wir ein zufriedenstellendes Ergebnis erhalten.
Algorithmus
Step 1 - Wählen Sie kPunkte als die anfänglichen Schwerpunkte. Initialisierenk Prototypen (w1,…,wk)Zum Beispiel können wir sie mit zufällig ausgewählten Eingabevektoren identifizieren -
$$ W_ {j} \: = \: i_ {p}, \: \: \: wobei \: j \: \ in \ lbrace1, ...., k \ rbrace \: und \: p \: \ in \ lbrace1, ...., n \ rbrace $$
Jeder Cluster Cj ist mit dem Prototyp verbunden wj.
Step 2 - Wiederholen Sie die Schritte 3 bis 5, bis E nicht mehr abnimmt oder sich die Clustermitgliedschaft nicht mehr ändert.
Step 3 - Für jeden Eingabevektor ip wo p ∈ {1,…,n}, stellen ip im Cluster Cj* mit dem nächsten Prototyp wj* mit der folgenden Beziehung
$$ | i_ {p} \: - \: w_ {j *} | \: \ leq \: | i_ {p} \: - \: w_ {j} |, \: j \: \ in \ lbrace1, ...., k \ rbrace $$
Step 4 - Für jeden Cluster Cj, wo j ∈ { 1,…,k}, aktualisieren Sie den Prototyp wj der Schwerpunkt aller derzeit in Cj , damit
$$ w_ {j} \: = \: \ sum_ {i_ {p} \ in C_ {j}} \ frac {i_ {p}} {| C_ {j} |} $$
Step 5 - Berechnen Sie den Gesamtquantisierungsfehler wie folgt: -
$$ E \: = \: \ sum_ {j = 1} ^ k \ sum_ {i_ {p} \ in w_ {j}} | i_ {p} \: - \: w_ {j} | ^ 2 $$
Neocognitron
Es ist ein mehrschichtiges Feedforward-Netzwerk, das in den 1980er Jahren von Fukushima entwickelt wurde. Dieses Modell basiert auf überwachtem Lernen und wird zur visuellen Mustererkennung verwendet, hauptsächlich handgeschriebene Zeichen. Es handelt sich im Grunde genommen um eine Erweiterung des Cognitron-Netzwerks, das 1975 ebenfalls von Fukushima entwickelt wurde.
Die Architektur
Es ist ein hierarchisches Netzwerk, das viele Schichten umfasst, und in diesen Schichten gibt es lokal ein Konnektivitätsmuster.
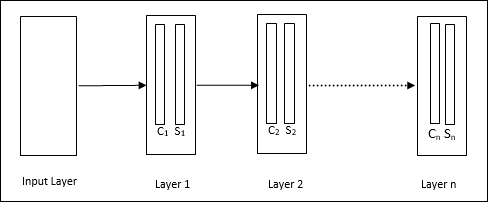
Wie wir im obigen Diagramm gesehen haben, ist Neocognitron in verschiedene verbundene Schichten unterteilt und jede Schicht hat zwei Zellen. Die Erklärung dieser Zellen ist wie folgt:
S-Cell - Es wird eine einfache Zelle genannt, die darauf trainiert ist, auf ein bestimmtes Muster oder eine Gruppe von Mustern zu reagieren.
C-Cell- Es handelt sich um eine komplexe Zelle, die die Ausgabe der S-Zelle kombiniert und gleichzeitig die Anzahl der Einheiten in jedem Array verringert. In einem anderen Sinne verdrängt die C-Zelle das Ergebnis der S-Zelle.
Trainingsalgorithmus
Es wurde festgestellt, dass das Training von Neocognitron Schicht für Schicht voranschreitet. Die Gewichte von der Eingabeebene zur ersten Ebene werden trainiert und eingefroren. Dann werden die Gewichte von der ersten Schicht zur zweiten Schicht trainiert und so weiter. Die internen Berechnungen zwischen S-Zelle und C-Zelle hängen von den Gewichten ab, die von den vorherigen Schichten stammen. Daher können wir sagen, dass der Trainingsalgorithmus von den Berechnungen für S-Zellen und C-Zellen abhängt.
Berechnungen in S-Zellen
Die S-Zelle besitzt das von der vorherigen Schicht empfangene Anregungssignal und die in derselben Schicht erhaltenen Hemmsignale.
$$ \ theta = \: \ sqrt {\ sum \ sum t_ {i} c_ {i} ^ 2} $$
Hier, ti ist das feste Gewicht und ci ist die Ausgabe von C-Zelle.
Die skalierte Eingabe der S-Zelle kann wie folgt berechnet werden:
$$ x \: = \: \ frac {1 \: + \: e} {1 \: + \: vw_ {0}} \: - \: 1 $$
Hier ist $ e \: = \: \ sum_i c_ {i} w_ {i} $
wi ist das von C-Zelle zu S-Zelle eingestellte Gewicht.
w0 ist das Gewicht, das zwischen dem Eingang und der S-Zelle einstellbar ist.
v ist die anregende Eingabe von der C-Zelle.
Die Aktivierung des Ausgangssignals ist,
$$ s \: = \: \ begin {Fälle} x, & if \: x \ geq 0 \\ 0, & if \: x <0 \ end {Fälle} $$
Berechnungen in C-Zellen
Der Nettoeingang der C-Schicht ist
$$ C \: = \: \ displaystyle \ sum \ limit_i s_ {i} x_ {i} $$
Hier, si ist die Ausgabe von S-Zelle und xi ist das feste Gewicht von S-Zelle zu C-Zelle.
Die endgültige Ausgabe lautet wie folgt:
$$ C_ {out} \: = \: \ begin {case} \ frac {C} {a + C}, & if \: C> 0 \\ 0, andernfalls \ end {case} $$
Hier ‘a’ ist der Parameter, der von der Leistung des Netzwerks abhängt.
Learning Vector Quantization (LVQ) unterscheidet sich von Vector Quantization (VQ) und Kohonen Self-Organizing Maps (KSOM) und ist im Grunde ein wettbewerbsfähiges Netzwerk, das überwachtes Lernen verwendet. Wir können es als einen Prozess zum Klassifizieren der Muster definieren, bei denen jede Ausgabeeinheit eine Klasse darstellt. Da das überwachte Lernen verwendet wird, erhält das Netzwerk eine Reihe von Trainingsmustern mit bekannter Klassifizierung sowie eine anfängliche Verteilung der Ausgabeklasse. Nach Abschluss des Trainingsprozesses klassifiziert LVQ einen Eingabevektor, indem es derselben Klasse wie die Ausgabeeinheit zugeordnet wird.
Die Architektur
Die folgende Abbildung zeigt die Architektur von LVQ, die der Architektur von KSOM sehr ähnlich ist. Wie wir sehen können, gibt es“n” Anzahl der Eingabeeinheiten und “m”Anzahl der Ausgabeeinheiten. Die Schichten sind vollständig mit Gewichten verbunden.

Verwendete Parameter
Im Folgenden sind die Parameter aufgeführt, die im LVQ-Trainingsprozess sowie im Flussdiagramm verwendet werden
x= Trainingsvektor (x 1 , ..., x i , ..., x n )
T = Klasse für Trainingsvektor x
wj = Gewichtsvektor für jth Ausgabeeinheit
Cj = Klasse, die dem zugeordnet ist jth Ausgabeeinheit
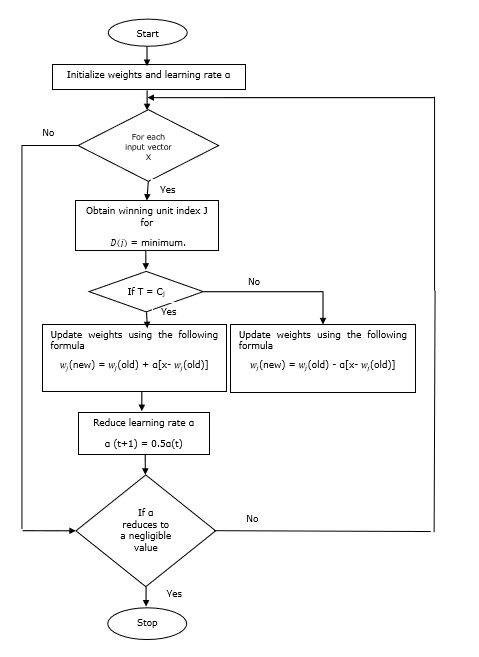
Trainingsalgorithmus
Step 1 - Referenzvektoren initialisieren, was wie folgt erfolgen kann -
Step 1(a) - Nehmen Sie aus dem angegebenen Satz von Trainingsvektoren den ersten “m”(Anzahl der Cluster) trainieren Vektoren und verwenden sie als Gewichtsvektoren. Die verbleibenden Vektoren können zum Training verwendet werden.
Step 1(b) - Weisen Sie das Anfangsgewicht und die Klassifizierung zufällig zu.
Step 1(c) - Wenden Sie die K-Mittel-Clustering-Methode an.
Step 2 - Referenzvektor $ \ alpha $ initialisieren
Step 3 - Fahren Sie mit den Schritten 4 bis 9 fort, wenn die Bedingung zum Stoppen dieses Algorithmus nicht erfüllt ist.
Step 4 - Befolgen Sie die Schritte 5 bis 6 für jeden Trainingseingabevektor x.
Step 5 - Berechnen Sie das Quadrat der euklidischen Entfernung für j = 1 to m und i = 1 to n
$$ D (j) \: = \: \ Anzeigestil \ Summe \ Grenzen_ {i = 1} ^ n \ Anzeigestil \ Summe \ Grenzen_ {j = 1} ^ m (x_ {i} \: - \: w_ {ij }) ^ 2 $$
Step 6 - Erhalten Sie die Gewinnereinheit J wo D(j) ist minimal.
Step 7 - Berechnen Sie das neue Gewicht der Gewinnereinheit anhand der folgenden Beziehung:
wenn T = Cj dann $ w_ {j} (neu) \: = \: w_ {j} (alt) \: + \: \ alpha [x \: - \: w_ {j} (alt)] $
wenn T ≠ Cj dann $ w_ {j} (neu) \: = \: w_ {j} (alt) \: - \: \ alpha [x \: - \: w_ {j} (alt)] $
Step 8 - Reduzieren Sie die Lernrate $ \ alpha $.
Step 9- Auf Stoppzustand prüfen. Es kann wie folgt sein:
- Maximale Anzahl von Epochen erreicht.
- Lernrate auf einen vernachlässigbaren Wert reduziert.
Flussdiagramm
Varianten
Drei weitere Varianten, nämlich LVQ2, LVQ2.1 und LVQ3, wurden von Kohonen entwickelt. Die Komplexität in all diesen drei Varianten ist aufgrund des Konzepts, das sowohl der Gewinner als auch der Zweitplatzierte lernen werden, größer als in LVQ.
LVQ2
Wie diskutiert, wird das Konzept anderer Varianten von LVQ oben, der Zustand von LVQ2 durch Fenster gebildet. Dieses Fenster basiert auf den folgenden Parametern:
x - der aktuelle Eingabevektor
yc - der Referenzvektor, der am nächsten liegt x
yr - der andere Referenzvektor, der am nächsten ist x
dc - die Entfernung von x zu yc
dr - die Entfernung von x zu yr
Der Eingabevektor x fällt ins Fenster, wenn
$$ \ frac {d_ {c}} {d_ {r}} \:> \: 1 \: - \: \ theta \: \: und \: \: \ frac {d_ {r}} {d_ {c }} \:> \: 1 \: + \: \ theta $$
Hier ist $ \ theta $ die Anzahl der Trainingsmuster.
Die Aktualisierung kann mit der folgenden Formel erfolgen:
$ y_ {c} (t \: + \: 1) \: = \: y_ {c} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c} (t)] $ (belongs to different class)
$ y_ {r} (t \: + \: 1) \: = \: y_ {r} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {r} (t)] $ (belongs to same class)
Hier ist $ \ alpha $ die Lernrate.
LVQ2.1
In LVQ2.1 nehmen wir nämlich die beiden nächsten Vektoren yc1 und yc2 und die Bedingung für Fenster ist wie folgt -
$$ Min \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \:> \ :( 1 \ : - \: \ theta) $$
$$ Max \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \: <\ :( 1 \ : + \: \ theta) $$
Die Aktualisierung kann mit der folgenden Formel erfolgen:
$ y_ {c1} (t \: + \: 1) \: = \: y_ {c1} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c1} (t)] $ (belongs to different class)
$ y_ {c2} (t \: + \: 1) \: = \: y_ {c2} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c2} (t)] $ (belongs to same class)
Hier ist $ \ alpha $ die Lernrate.
LVQ3
In LVQ3 nehmen wir nämlich die beiden nächsten Vektoren yc1 und yc2 und die Bedingung für Fenster ist wie folgt -
$$ Min \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \:> \ :( 1 \ : - \: \ theta) (1 \: + \: \ theta) $$
Hier $ \ theta \ ca. 0,2 $
Die Aktualisierung kann mit der folgenden Formel erfolgen:
$ y_ {c1} (t \: + \: 1) \: = \: y_ {c1} (t) \: + \: \ beta (t) [x (t) \: - \: y_ {c1} (t)] $ (belongs to different class)
$ y_ {c2} (t \: + \: 1) \: = \: y_ {c2} (t) \: + \: \ beta (t) [x (t) \: - \: y_ {c2} (t)] $ (belongs to same class)
Hier ist $ \ beta $ das Vielfache der Lernrate $ \ alpha $ und $\beta\:=\:m \alpha(t)$ für jeden 0.1 < m < 0.5
Dieses Netzwerk wurde 1987 von Stephen Grossberg und Gail Carpenter entwickelt. Es basiert auf Wettbewerb und verwendet ein unbeaufsichtigtes Lernmodell. Netzwerke der adaptiven Resonanztheorie (ART) sind, wie der Name schon sagt, immer offen für neues Lernen (adaptiv), ohne die alten Muster zu verlieren (Resonanz). Grundsätzlich ist das ART-Netzwerk ein Vektorklassifizierer, der einen Eingabevektor akzeptiert und ihn in eine der Kategorien klassifiziert, je nachdem, welchem der gespeicherten Muster er am ähnlichsten ist.
Betriebsleiter
Die Hauptoperation der ART-Klassifizierung kann in die folgenden Phasen unterteilt werden:
Recognition phase- Der Eingabevektor wird mit der Klassifizierung verglichen, die an jedem Knoten in der Ausgabeschicht dargestellt wird. Die Ausgabe des Neurons wird "1", wenn sie am besten mit der angewendeten Klassifizierung übereinstimmt, andernfalls wird sie "0".
Comparison phase- In dieser Phase wird ein Vergleich des Eingabevektors mit dem Vergleichsschichtvektor durchgeführt. Die Bedingung für das Zurücksetzen ist, dass der Ähnlichkeitsgrad geringer als der Wachsamkeitsparameter ist.
Search phase- In dieser Phase sucht das Netzwerk nach dem Zurücksetzen sowie nach der Übereinstimmung, die in den obigen Phasen durchgeführt wurde. Wenn es also keinen Reset geben würde und die Übereinstimmung ziemlich gut ist, ist die Klassifizierung beendet. Andernfalls würde der Vorgang wiederholt und das andere gespeicherte Muster muss gesendet werden, um die richtige Übereinstimmung zu finden.
ART1
Es ist eine Art von ART, die entwickelt wurde, um binäre Vektoren zu gruppieren. Wir können dies anhand der Architektur verstehen.
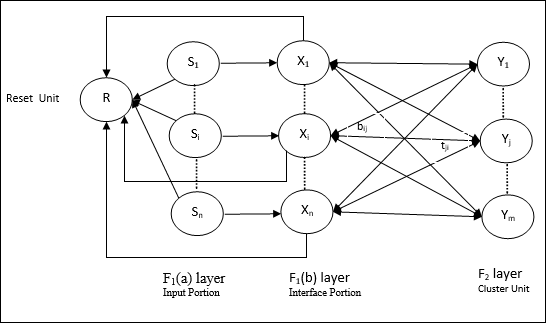
Architektur von ART1
Es besteht aus den folgenden zwei Einheiten -
Computational Unit - Es besteht aus folgenden -
Input unit (F1 layer) - Es hat weiterhin die folgenden zwei Teile -
F1(a) layer (Input portion)- In ART1 würde in diesem Abschnitt keine Verarbeitung stattfinden, anstatt nur die Eingabevektoren zu haben. Es ist mit der Schicht F 1 (b) (Schnittstellenabschnitt) verbunden.
F1(b) layer (Interface portion)- Dieser Teil kombiniert das Signal vom Eingangsabschnitt mit dem der F 2 -Schicht. Die Schicht F 1 (b) ist durch Bottom-Up-Gewichte mit der Schicht F 2 verbundenbijund die F 2 -Schicht ist durch Top-Down-Gewichte mit der F 1 (b) -Schicht verbundentji.
Cluster Unit (F2 layer)- Dies ist eine Wettbewerbsschicht. Die Einheit mit der größten Nettoeingabe wird ausgewählt, um das Eingabemuster zu lernen. Die Aktivierung aller anderen Cluster-Einheiten wird auf 0 gesetzt.
Reset Mechanism- Die Arbeit dieses Mechanismus basiert auf der Ähnlichkeit zwischen dem Top-Down-Gewicht und dem Eingabevektor. Wenn der Grad dieser Ähnlichkeit geringer als der Wachsamkeitsparameter ist, darf der Cluster das Muster nicht lernen, und es würde eine Pause stattfinden.
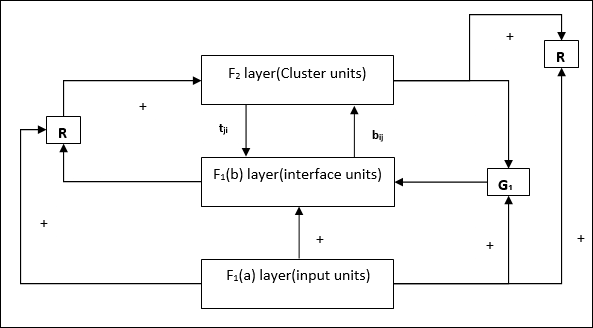
Supplement Unit - Eigentlich ist das Problem mit dem Reset-Mechanismus, dass die Ebene F2muss unter bestimmten Bedingungen gehemmt werden und muss auch verfügbar sein, wenn etwas gelernt wird. Deshalb zwei ergänzende Einheiten, nämlichG1 und G2 wird zusammen mit der Rücksetzeinheit hinzugefügt, R. Sie heißengain control units. Diese Einheiten empfangen und senden Signale an die anderen im Netzwerk vorhandenen Einheiten.‘+’ zeigt ein anregendes Signal an, während ‘−’ zeigt ein inhibitorisches Signal an.
Verwendete Parameter
Folgende Parameter werden verwendet -
n - Anzahl der Komponenten im Eingabevektor
m - Maximale Anzahl von Clustern, die gebildet werden können
bij- Gewicht von F 1 (b) bis F 2 -Schicht, dh Bottom-Up-Gewichte
tji- Gewicht von F 2 bis F 1 (b), dh Gewichte von oben nach unten
ρ - Wachsamkeitsparameter
||x|| - Norm des Vektors x
Algorithmus
Step 1 - Initialisieren Sie die Lernrate, den Wachsamkeitsparameter und die Gewichte wie folgt: -
$$ \ alpha \:> \: 1 \: \: und \: \: 0 \: <\ rho \: \ leq \: 1 $$
$$ 0 \: <\: b_ {ij} (0) \: <\: \ frac {\ alpha} {\ alpha \: - \: 1 \: + \: n} \: \: und \: \: t_ {ij} (0) \: = \: 1 $$
Step 2 - Fahren Sie mit Schritt 3-9 fort, wenn die Stoppbedingung nicht erfüllt ist.
Step 3 - Fahren Sie für jede Trainingseingabe mit Schritt 4-6 fort.
Step 4- Stellen Sie die Aktivierungen aller F 1 (a) - und F 1 -Einheiten wie folgt ein
F2 = 0 and F1(a) = input vectors
Step 5- Eingangssignal von F 1 (a) bis F 1 (b) Schicht muss verschickt werden
$$ s_ {i} \: = \: x_ {i} $$
Step 6- Für jeden gesperrten F 2 -Knoten
$ y_ {j} \: = \: \ sum_i b_ {ij} x_ {i} $ die Bedingung ist yj ≠ -1
Step 7 - Führen Sie Schritt 8-10 aus, wenn der Reset wahr ist.
Step 8 - Finden J zum yJ ≥ yj für alle Knoten j
Step 9- Berechnen Sie die Aktivierung von F 1 (b) erneut wie folgt
$$ x_ {i} \: = \: sitJi $$
Step 10 - Nun nach der Berechnung der Vektornorm x und Vektor smüssen wir den Rücksetzzustand wie folgt überprüfen:
Wenn ||x||/ ||s|| <Wachsamkeitsparameter ρ, Dann hemmen Sie den Knoten J und fahren Sie mit Schritt 7 fort
Sonst wenn ||x||/ ||s|| ≥ Wachsamkeitsparameter ρ, dann weiter.
Step 11 - Gewichtsaktualisierung für Knoten J kann wie folgt durchgeführt werden -
$$ b_ {ij} (neu) \: = \: \ frac {\ alpha x_ {i}} {\ alpha \: - \: 1 \: + \: || x ||} $$
$$ t_ {ij} (neu) \: = \: x_ {i} $$
Step 12 - Die Stoppbedingung für den Algorithmus muss überprüft werden und kann wie folgt sein: -
- Keine Gewichtsveränderung.
- Für Einheiten wird kein Reset durchgeführt.
- Maximale Anzahl von Epochen erreicht.
Angenommen, wir haben ein Muster mit beliebigen Dimensionen, benötigen sie jedoch in einer oder zwei Dimensionen. Dann wäre der Prozess der Merkmalszuordnung sehr nützlich, um den breiten Musterraum in einen typischen Merkmalsraum umzuwandeln. Nun stellt sich die Frage, warum wir eine selbstorganisierende Feature-Map benötigen. Der Grund dafür ist, dass neben der Fähigkeit, die beliebigen Dimensionen in 1-D oder 2-D umzuwandeln, auch die Fähigkeit zur Beibehaltung der Nachbartopologie erhalten bleiben muss.
Nachbartopologien in Kohonen SOM
Es kann verschiedene Topologien geben, jedoch werden die folgenden zwei Topologien am häufigsten verwendet -
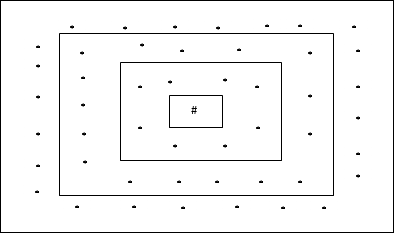
Rechteckige Gittertopologie
Diese Topologie hat 24 Knoten im Distanz-2-Gitter, 16 Knoten im Distanz-1-Gitter und 8 Knoten im Distanz-0-Gitter, was bedeutet, dass die Differenz zwischen jedem rechteckigen Gitter 8 Knoten beträgt. Die Gewinnereinheit wird durch # angezeigt.
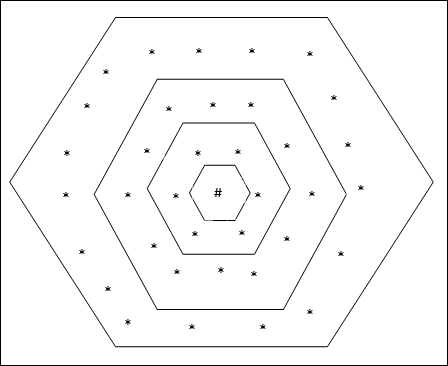
Hexagonale Gittertopologie
Diese Topologie hat 18 Knoten im Raster der Entfernung 2, 12 Knoten im Raster der Entfernung 1 und 6 Knoten im Raster der Entfernung 0, was bedeutet, dass die Differenz zwischen jedem rechteckigen Gitter 6 Knoten beträgt. Die Gewinnereinheit wird durch # angezeigt.
Die Architektur
Die Architektur von KSOM ähnelt der des Wettbewerbsnetzwerks. Mit Hilfe der zuvor diskutierten Nachbarschaftsprogramme kann das Training über die erweiterte Region des Netzwerks stattfinden.
Algorithmus für das Training
Step 1 - Initialisieren Sie die Gewichte, die Lernrate α und das nachbarschaftstopologische Schema.
Step 2 - Fahren Sie mit Schritt 3-9 fort, wenn die Stoppbedingung nicht erfüllt ist.
Step 3 - Fahren Sie für jeden Eingabevektor mit Schritt 4-6 fort x.
Step 4 - Berechnen Sie das Quadrat der euklidischen Entfernung für j = 1 to m
$$ D (j) \: = \: \ Anzeigestil \ Summe \ Grenzen_ {i = 1} ^ n \ Anzeigestil \ Summe \ Grenzen_ {j = 1} ^ m (x_ {i} \: - \: w_ {ij }) ^ 2 $$
Step 5 - Erhalten Sie die Gewinnereinheit J wo D(j) ist minimal.
Step 6 - Berechnen Sie das neue Gewicht der Gewinnereinheit anhand der folgenden Beziehung:
$$ w_ {ij} (neu) \: = \: w_ {ij} (alt) \: + \: \ alpha [x_ {i} \: - \: w_ {ij} (alt)] $$
Step 7 - Aktualisieren Sie die Lernrate α durch die folgende Beziehung -
$$ \ alpha (t \: + \: 1) \: = \: 0.5 \ alpha t $$
Step 8 - Reduzieren Sie den Radius des topologischen Schemas.
Step 9 - Überprüfen Sie, ob das Netzwerk gestoppt ist.
Diese Arten von neuronalen Netzen arbeiten auf der Basis der Musterassoziation, was bedeutet, dass sie verschiedene Muster speichern können und zum Zeitpunkt der Ausgabe eine der gespeicherten Muster erzeugen können, indem sie sie mit dem gegebenen Eingabemuster abgleichen. Diese Arten von Erinnerungen werden auch genanntContent-Addressable Memory(NOCKEN). Der assoziative Speicher führt eine parallele Suche mit den gespeicherten Mustern als Datendateien durch.
Im Folgenden sind die beiden Arten von assoziativen Erinnerungen aufgeführt, die wir beobachten können:
- Autoassoziativer Speicher
- Heteroassoziatives Gedächtnis
Autoassoziativer Speicher
Dies ist ein einschichtiges neuronales Netzwerk, in dem der Eingabe-Trainingsvektor und die Ausgabe-Zielvektoren gleich sind. Die Gewichte werden so bestimmt, dass das Netzwerk eine Reihe von Mustern speichert.
Die Architektur
Wie in der folgenden Abbildung gezeigt, hat die Architektur des Auto Associative Memory Network ‘n’ Anzahl der eingegebenen Trainingsvektoren und ähnliches ‘n’ Anzahl der Ausgabezielvektoren.
Trainingsalgorithmus
Für das Training verwendet dieses Netzwerk die Hebb- oder Delta-Lernregel.
Step 1 - Initialisieren Sie alle Gewichte auf Null als wij = 0 (i = 1 to n, j = 1 to n)
Step 2 - Führen Sie die Schritte 3-4 für jeden Eingabevektor aus.
Step 3 - Aktivieren Sie jede Eingabeeinheit wie folgt: -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: bis \: n) $$
Step 4 - Aktivieren Sie jede Ausgabeeinheit wie folgt: -
$$ y_ {j} \: = \: s_ {j} \ :( j \: = \: 1 \: bis \: n) $$
Step 5 - Stellen Sie die Gewichte wie folgt ein -
$$ w_ {ij} (neu) \: = \: w_ {ij} (alt) \: + \: x_ {i} y_ {j} $$
Testalgorithmus
Step 1 - Stellen Sie die Gewichte ein, die während des Trainings für Hebbs Regel erhalten wurden.
Step 2 - Führen Sie die Schritte 3 bis 5 für jeden Eingabevektor aus.
Step 3 - Stellen Sie die Aktivierung der Eingabeeinheiten gleich der des Eingabevektors ein.
Step 4 - Berechnen Sie den Nettoeingang für jede Ausgabeeinheit j = 1 to n
$$ y_ {inj} \: = \: \ displaystyle \ sum \ limit_ {i = 1} ^ n x_ {i} w_ {ij} $$
Step 5 - Wenden Sie die folgende Aktivierungsfunktion an, um die Ausgabe zu berechnen
$$ y_ {j} \: = \: f (y_ {inj}) \: = \: \ begin {case} +1 & if \: y_ {inj} \:> \: 0 \\ - 1 & if \: y_ {inj} \: \ leqslant \: 0 \ end {case} $$
Heteroassoziatives Gedächtnis
Ähnlich wie beim Auto Associative Memory-Netzwerk handelt es sich auch hier um ein einschichtiges neuronales Netzwerk. In diesem Netzwerk sind jedoch der Eingabe-Trainingsvektor und die Ausgabe-Zielvektoren nicht gleich. Die Gewichte werden so bestimmt, dass das Netzwerk eine Reihe von Mustern speichert. Das heteroassoziative Netzwerk ist statischer Natur, daher würde es keine nichtlinearen Operationen und Verzögerungsoperationen geben.
Die Architektur
Wie in der folgenden Abbildung gezeigt, hat die Architektur des Hetero Associative Memory-Netzwerks ‘n’ Anzahl der eingegebenen Trainingsvektoren und ‘m’ Anzahl der Ausgabezielvektoren.
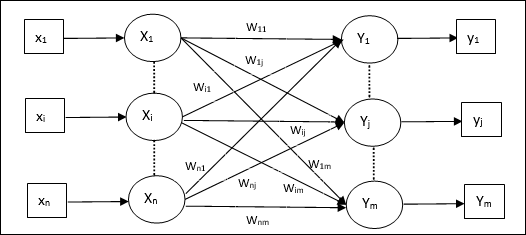
Trainingsalgorithmus
Für das Training verwendet dieses Netzwerk die Hebb- oder Delta-Lernregel.
Step 1 - Initialisieren Sie alle Gewichte auf Null als wij = 0 (i = 1 to n, j = 1 to m)
Step 2 - Führen Sie die Schritte 3-4 für jeden Eingabevektor aus.
Step 3 - Aktivieren Sie jede Eingabeeinheit wie folgt: -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: bis \: n) $$
Step 4 - Aktivieren Sie jede Ausgabeeinheit wie folgt: -
$$ y_ {j} \: = \: s_ {j} \ :( j \: = \: 1 \: bis \: m) $$
Step 5 - Stellen Sie die Gewichte wie folgt ein -
$$ w_ {ij} (neu) \: = \: w_ {ij} (alt) \: + \: x_ {i} y_ {j} $$
Testalgorithmus
Step 1 - Stellen Sie die Gewichte ein, die während des Trainings für Hebbs Regel erhalten wurden.
Step 2 - Führen Sie die Schritte 3 bis 5 für jeden Eingabevektor aus.
Step 3 - Stellen Sie die Aktivierung der Eingabeeinheiten gleich der des Eingabevektors ein.
Step 4 - Berechnen Sie den Nettoeingang für jede Ausgabeeinheit j = 1 to m;
$$ y_ {inj} \: = \: \ displaystyle \ sum \ limit_ {i = 1} ^ n x_ {i} w_ {ij} $$
Step 5 - Wenden Sie die folgende Aktivierungsfunktion an, um die Ausgabe zu berechnen
$$ y_ {j} \: = \: f (y_ {inj}) \: = \: \ begin {case} +1 & if \: y_ {inj} \:> \: 0 \\ 0 & if \ : y_ {inj} \: = \: 0 \\ - 1 & if \: y_ {inj} \: <\: 0 \ end {case} $$
Das neuronale Hopfield-Netzwerk wurde 1982 von Dr. John J. Hopfield erfunden. Es besteht aus einer einzelnen Schicht, die ein oder mehrere vollständig verbundene wiederkehrende Neuronen enthält. Das Hopfield-Netzwerk wird üblicherweise für automatische Zuordnungs- und Optimierungsaufgaben verwendet.
Diskretes Hopfield-Netzwerk
Bei einem Hopfield-Netzwerk, das diskret arbeitet, oder mit anderen Worten, kann gesagt werden, dass die Eingabe- und Ausgabemuster diskrete Vektoren sind, die entweder binärer (0,1) oder bipolarer (+1, -1) Natur sein können. Das Netzwerk hat symmetrische Gewichte ohne Selbstverbindungen, dhwij = wji und wii = 0.
Die Architektur
Im Folgenden sind einige wichtige Punkte aufgeführt, die Sie beim diskreten Hopfield-Netzwerk beachten sollten:
Dieses Modell besteht aus Neuronen mit einem invertierenden und einem nicht invertierenden Ausgang.
Die Ausgabe jedes Neurons sollte die Eingabe anderer Neuronen sein, aber nicht die Eingabe des Selbst.
Gewicht / Verbindungsstärke wird dargestellt durch wij.
Verbindungen können sowohl anregend als auch hemmend sein. Es wäre anregend, wenn der Ausgang des Neurons der gleiche ist wie der Eingang, sonst hemmend.
Gewichte sollten symmetrisch sein, dh wij = wji
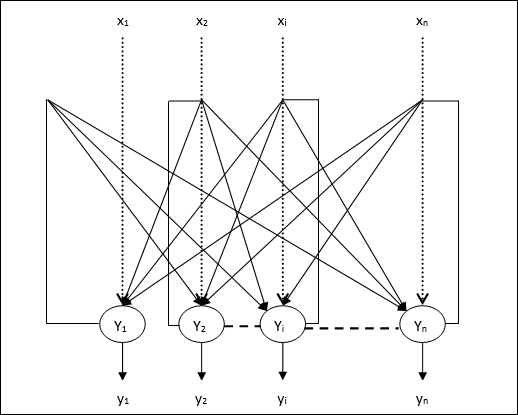
Die Ausgabe von Y1 gehe zu Y2, Yi und Yn habe die Gewichte w12, w1i und w1nbeziehungsweise. Ebenso haben andere Bögen die Gewichte.
Trainingsalgorithmus
Während des Trainings des diskreten Hopfield-Netzwerks werden die Gewichte aktualisiert. Wie wir wissen, können wir sowohl binäre Eingangsvektoren als auch bipolare Eingangsvektoren haben. Daher können in beiden Fällen Gewichtsaktualisierungen mit der folgenden Beziehung durchgeführt werden
Case 1 - Binäre Eingabemuster
Für eine Reihe von binären Mustern s(p), p = 1 to P
Hier, s(p) = s1(p), s2(p),..., si(p),..., sn(p)
Die Gewichtsmatrix ist gegeben durch
$$ w_ {ij} \: = \: \ sum_ {p = 1} ^ P [2s_ {i} (p) - \: 1] [2s_ {j} (p) - \: 1] \: \: \: \: \: für \: i \: \ neq \: j $$
Case 2 - Bipolare Eingabemuster
Für eine Reihe von binären Mustern s(p), p = 1 to P
Hier, s(p) = s1(p), s2(p),..., si(p),..., sn(p)
Die Gewichtsmatrix ist gegeben durch
$$ w_ {ij} \: = \: \ sum_ {p = 1} ^ P [s_ {i} (p)] [s_ {j} (p)] \: \: \: \: \: for \ : i \: \ neq \: j $$
Testalgorithmus
Step 1 - Initialisieren Sie die Gewichte, die aus dem Trainingsalgorithmus nach dem Hebbschen Prinzip erhalten werden.
Step 2 - Führen Sie die Schritte 3 bis 9 aus, wenn die Aktivierungen des Netzwerks nicht konsolidiert sind.
Step 3 - Für jeden Eingabevektor XFühren Sie die Schritte 4 bis 8 aus.
Step 4 - Stellen Sie die anfängliche Aktivierung des Netzwerks gleich dem externen Eingangsvektor X wie folgt -
$$ y_ {i} \: = \: x_ {i} \: \: \: für \: i \: = \: 1 \: bis \: n $$
Step 5 - Für jede Einheit YiFühren Sie die Schritte 6-9 aus.
Step 6 - Berechnen Sie den Nettoeingang des Netzwerks wie folgt: -
$$ y_ {ini} \: = \: x_ {i} \: + \: \ displaystyle \ sum \ limit_ {j} y_ {j} w_ {ji} $$
Step 7 - Wenden Sie die Aktivierung wie folgt auf den Nettoeingang an, um den Ausgang zu berechnen. -
$$ y_ {i} \: = \ begin {case} 1 & if \: y_ {ini} \:> \: \ theta_ {i} \\ y_ {i} & if \: y_ {ini} \: = \: \ theta_ {i} \\ 0 & if \: y_ {ini} \: <\: \ theta_ {i} \ end {case} $$
Hier ist $ \ theta_ {i} $ der Schwellenwert.
Step 8 - Senden Sie diese Ausgabe yi zu allen anderen Einheiten.
Step 9 - Testen Sie das Netzwerk auf Verbindung.
Bewertung der Energiefunktion
Eine Energiefunktion ist definiert als eine gebundene Funktion und eine nicht zunehmende Funktion des Systemzustands.
Energiefunktion Ef, auch angerufen Lyapunov function bestimmt die Stabilität des diskreten Hopfield-Netzwerks und ist wie folgt charakterisiert:
$$ E_ {f} \: = \: - \ frac {1} {2} \ Anzeigestil \ Summe \ Grenzen_ {i = 1} ^ n \ Anzeigestil \ Summe \ Grenzen_ {j = 1} ^ n y_ {i} y_ {j} w_ {ij} \: - \: \ Anzeigestil \ Summe \ Grenzen_ {i = 1} ^ n x_ {i} y_ {i} \: + \: \ Anzeigestil \ Summe \ Grenzen_ {i = 1} ^ n \ theta_ {i} y_ {i} $$
Condition - In einem stabilen Netzwerk nimmt die obige Energiefunktion ab, wenn sich der Zustand des Knotens ändert.
Angenommen, wenn Knoten i hat den Zustand von $ y_i ^ {(k)} $ in $ y_i ^ {(k \: + \: 1)} $ geändert, wenn die Energieänderung $ \ Delta E_ {f} $ durch die folgende Beziehung gegeben ist
$$ \ Delta E_ {f} \: = \: E_ {f} (y_i ^ {(k + 1)}) \: - \: E_ {f} (y_i ^ {(k)}) $$
$$ = \: - \ left (\ begin {array} {c} \ displaystyle \ sum \ limit_ {j = 1} ^ n w_ {ij} y_i ^ {(k)} \: + \: x_ {i} \: - \: \ theta_ {i} \ end {array} \ right) (y_i ^ {(k + 1)} \: - \: y_i ^ {(k)}) $$
$$ = \: - \ :( net_ {i}) \ Delta y_ {i} $$
Hier $ \ Delta y_ {i} \: = \: y_i ^ {(k \: + \: 1)} \: - \: y_i ^ {(k)} $
Die Änderung der Energie hängt davon ab, dass jeweils nur eine Einheit ihre Aktivierung aktualisieren kann.
Kontinuierliches Hopfield-Netzwerk
Im Vergleich zum diskreten Hopfield-Netzwerk hat ein kontinuierliches Netzwerk Zeit als kontinuierliche Variable. Es wird auch bei Problemen mit der automatischen Zuordnung und Optimierung verwendet, z. B. bei Problemen mit reisenden Verkäufern.
Model - Das Modell oder die Architektur kann durch Hinzufügen elektrischer Komponenten wie Verstärker aufgebaut werden, die die Eingangsspannung über eine Sigmoid-Aktivierungsfunktion auf die Ausgangsspannung abbilden können.
Bewertung der Energiefunktion
$$ E_f = \ frac {1} {2} \ displaystyle \ sum \ limit_ {i = 1} ^ n \ sum _ {\ substack {j = 1 \\ j \ ne i}} ^ n y_i y_j w_ {ij} - \ Anzeigestil \ Summe \ Grenzen_ {i = 1} ^ n x_i y_i + \ frac {1} {\ lambda} \ Anzeigestil \ Summe \ Grenzen_ {i = 1} ^ n \ Summe _ {\ Teilstapel {j = 1 \\ j \ ne i}} ^ n w_ {ij} g_ {ri} \ int_ {0} ^ {y_i} a ^ {- 1} (y) dy $$
Hier λ ist Verstärkungsparameter und gri Eingangsleitfähigkeit.
Dies sind stochastische Lernprozesse mit wiederkehrender Struktur, die die Grundlage für die in ANN verwendeten frühen Optimierungstechniken bilden. Die Boltzmann-Maschine wurde 1985 von Geoffrey Hinton und Terry Sejnowski erfunden. Mehr Klarheit lässt sich mit den Worten von Hinton über die Boltzmann-Maschine feststellen.
„Ein überraschendes Merkmal dieses Netzwerks ist, dass es nur lokal verfügbare Informationen verwendet. Die Gewichtsänderung hängt nur vom Verhalten der beiden Einheiten ab, die sie verbindet, obwohl die Änderung ein globales Maß optimiert “- Ackley, Hinton 1985.
Einige wichtige Punkte zu Boltzmann Machine -
Sie verwenden eine wiederkehrende Struktur.
Sie bestehen aus stochastischen Neuronen, die einen der beiden möglichen Zustände haben, entweder 1 oder 0.
Einige der Neuronen in diesem sind adaptiv (freier Zustand) und andere sind geklemmt (gefrorener Zustand).
Wenn wir simuliertes Tempern auf ein diskretes Hopfield-Netzwerk anwenden, wird es zu Boltzmann-Maschine.
Ziel der Boltzmann-Maschine
Der Hauptzweck von Boltzmann Machine ist die Optimierung der Problemlösung. Es ist die Arbeit von Boltzmann Machine, die Gewichte und Mengen zu optimieren, die mit diesem speziellen Problem verbunden sind.
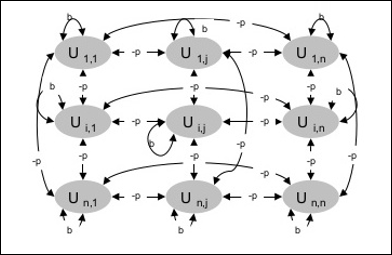
Die Architektur
Das folgende Diagramm zeigt die Architektur der Boltzmann-Maschine. Aus dem Diagramm geht hervor, dass es sich um eine zweidimensionale Anordnung von Einheiten handelt. Hier sind Gewichte für Verbindungen zwischen Einheiten–p wo p > 0. Die Gewichte der Selbstverbindungen sind gegeben durchb wo b > 0.
Trainingsalgorithmus
Da wir wissen, dass Boltzmann-Maschinen feste Gewichte haben, gibt es keinen Trainingsalgorithmus, da wir die Gewichte im Netzwerk nicht aktualisieren müssen. Um das Netzwerk zu testen, müssen wir jedoch die Gewichte einstellen und die Konsensfunktion (CF) finden.
Die Boltzmann-Maschine verfügt über eine Reihe von Einheiten Ui und Uj und hat bidirektionale Verbindungen auf ihnen.
Wir betrachten das feste Gewicht sagen wij.
wij ≠ 0 wenn Ui und Uj sind verbunden.
Es gibt auch eine Symmetrie in der gewichteten Verbindung, dh wij = wji.
wii existiert auch, dh es würde die Selbstverbindung zwischen Einheiten geben.
Für jede Einheit Ui, sein Zustand ui wäre entweder 1 oder 0.
Das Hauptziel von Boltzmann Machine ist die Maximierung der Konsensfunktion (CF), die durch die folgende Beziehung gegeben werden kann
$$ CF \: = \: \ Anzeigestil \ Summe \ Grenzen_ {i} \ Anzeigestil \ Summe \ Grenzen_ {j \ leqslant i} w_ {ij} u_ {i} u_ {j} $$
Wenn sich der Zustand von 1 auf 0 oder von 0 auf 1 ändert, kann die Änderung des Konsenses durch die folgende Beziehung gegeben werden:
$$ \ Delta CF \: = \ :( 1 \: - \: 2u_ {i}) (w_ {ij} \: + \: \ displaystyle \ sum \ limit_ {j \ neq i} u_ {i} w_ { ij}) $$
Hier ui ist der aktuelle Stand von Ui.
Die Variation des Koeffizienten (1 - 2ui) ist gegeben durch die folgende Beziehung -
$$ (1 \: - \: 2u_ {i}) \: = \: \ begin {Fällen} +1, & U_ {i} \: ist \: aktuell \: aus \\ - 1, & U_ {i } \: ist \: aktuell \: am \ Ende {Fälle} $$
Im Allgemeinen Einheit Uiändert seinen Status nicht, aber wenn dies der Fall ist, befinden sich die Informationen lokal im Gerät. Mit dieser Änderung würde sich auch der Konsens des Netzwerks erhöhen.
Die Wahrscheinlichkeit, dass das Netzwerk die Änderung des Zustands der Einheit akzeptiert, ergibt sich aus der folgenden Beziehung:
$$ AF (i, T) \: = \: \ frac {1} {1 \: + \: exp [- \ frac {\ Delta CF (i)} {T}]} $$
Hier, Tist der steuernde Parameter. Sie nimmt ab, wenn CF den Maximalwert erreicht.
Testalgorithmus
Step 1 - Initialisieren Sie Folgendes, um das Training zu starten -
- Gewichte, die die Einschränkung des Problems darstellen
- Steuerparameter T.
Step 2 - Fahren Sie mit den Schritten 3-8 fort, wenn die Stoppbedingung nicht erfüllt ist.
Step 3 - Führen Sie die Schritte 4-7 aus.
Step 4 - Nehmen Sie an, dass einer der Status das Gewicht geändert hat, und wählen Sie die Ganzzahl I, J als zufällige Werte zwischen 1 und n.
Step 5 - Berechnen Sie die Konsensänderung wie folgt: -
$$ \ Delta CF \: = \ :( 1 \: - \: 2u_ {i}) (w_ {ij} \: + \: \ displaystyle \ sum \ limit_ {j \ neq i} u_ {i} w_ { ij}) $$
Step 6 - Berechnen Sie die Wahrscheinlichkeit, dass dieses Netzwerk die Zustandsänderung akzeptiert
$$ AF (i, T) \: = \: \ frac {1} {1 \: + \: exp [- \ frac {\ Delta CF (i)} {T}]} $$
Step 7 - Akzeptieren oder lehnen Sie diese Änderung wie folgt ab: -
Case I - wenn R < AF, akzeptiere die Änderung.
Case II - wenn R ≥ AF, lehne die Änderung ab.
Hier, R ist die Zufallszahl zwischen 0 und 1.
Step 8 - Reduzieren Sie den Steuerparameter (Temperatur) wie folgt -
T(new) = 0.95T(old)
Step 9 - Prüfen Sie auf folgende Stoppbedingungen: -
- Die Temperatur erreicht einen bestimmten Wert
- Für eine bestimmte Anzahl von Iterationen gibt es keine Statusänderung
Das neuronale Brain-State-in-a-Box-Netzwerk (BSB) ist ein nichtlineares autoassoziatives neuronales Netzwerk und kann auf eine Heteroassoziation mit zwei oder mehr Schichten erweitert werden. Es ähnelt auch dem Hopfield-Netzwerk. Es wurde 1977 von JA Anderson, JW Silverstein, SA Ritz und RS Jones vorgeschlagen.
Einige wichtige Punkte, die Sie bei BSB Network beachten sollten -
Es ist ein vollständig verbundenes Netzwerk mit der maximalen Anzahl von Knoten in Abhängigkeit von der Dimensionalität n des Eingaberaums.
Alle Neuronen werden gleichzeitig aktualisiert.
Neuronen nehmen Werte zwischen -1 bis +1 an.
Mathematische Formulierungen
Die im BSB-Netzwerk verwendete Knotenfunktion ist eine Rampenfunktion, die wie folgt definiert werden kann:
$$ f (net) \: = \: min (1, \: max (-1, \: net)) $$
Diese Rampenfunktion ist begrenzt und kontinuierlich.
Da wir wissen, dass jeder Knoten seinen Zustand ändern würde, kann dies mit Hilfe der folgenden mathematischen Beziehung erfolgen:
$$ x_ {t} (t \: + \: 1) \: = \: f \ left (\ begin {array} {c} \ displaystyle \ sum \ limit_ {j = 1} ^ n w_ {i, j } x_ {j} (t) \ end {array} \ right) $$
Hier, xi(t) ist der Zustand der ith Knoten zur Zeit t.
Gewichte von ith Knoten zu jth Knoten kann mit der folgenden Beziehung gemessen werden -
$$ w_ {ij} \: = \: \ frac {1} {P} \ Anzeigestil \ sum \ limit_ {p = 1} ^ P (v_ {p, i} \: v_ {p, j}) $$
Hier, P ist die Anzahl der Trainingsmuster, die bipolar sind.
Optimierung ist eine Aktion, um etwas wie Design, Situation, Ressource und System so effektiv wie möglich zu gestalten. Mit einer Ähnlichkeit zwischen der Kostenfunktion und der Energiefunktion können wir stark miteinander verbundene Neuronen verwenden, um Optimierungsprobleme zu lösen. Eine solche Art von neuronalem Netzwerk ist das Hopfield-Netzwerk, das aus einer einzelnen Schicht besteht, die ein oder mehrere vollständig verbundene wiederkehrende Neuronen enthält. Dies kann zur Optimierung verwendet werden.
Wichtige Punkte bei der Verwendung des Hopfield-Netzwerks zur Optimierung -
Die Energiefunktion muss ein Minimum des Netzwerks sein.
Es wird eine zufriedenstellende Lösung finden, anstatt eines aus den gespeicherten Mustern auszuwählen.
Die Qualität der vom Hopfield-Netzwerk gefundenen Lösung hängt wesentlich vom Ausgangszustand des Netzwerks ab.
Problem mit dem reisenden Verkäufer
Das Finden der kürzesten vom Verkäufer zurückgelegten Route ist eines der Rechenprobleme, die mithilfe des neuronalen Hopfield-Netzwerks optimiert werden können.
Grundkonzept von TSP
Travelling Salesman Problem (TSP) ist ein klassisches Optimierungsproblem, bei dem ein Verkäufer reisen muss nStädte, die miteinander verbunden sind, halten sowohl die Kosten als auch die zurückgelegte Strecke auf ein Minimum. Zum Beispiel muss der Verkäufer eine Reihe von 4 Städten A, B, C, D bereisen. Ziel ist es, die kürzeste Rundreise ABC - D zu finden, um die Kosten zu minimieren, zu denen auch die Reisekosten gehören die letzte Stadt D zur ersten Stadt A.
Matrixdarstellung
Tatsächlich kann jede Tour durch n-city TSP ausgedrückt werden als n × n Matrix, deren ith Zeile beschreibt die ithLage der Stadt. Diese Matrix,Mkönnen für 4 Städte A, B, C, D wie folgt ausgedrückt werden:
$$ M = \ begin {bmatrix} A: & 1 & 0 & 0 & 0 \\ B: & 0 & 1 & 0 & 0 \\ C: & 0 & 0 & 1 & 0 \\ D: & 0 & 0 & 0 & 1 \ end {bmatrix} $$
Lösung von Hopfield Network
Bei der Betrachtung der Lösung dieses TSP durch das Hopfield-Netzwerk entspricht jeder Knoten im Netzwerk einem Element in der Matrix.
Berechnung der Energiefunktion
Um die optimierte Lösung zu sein, muss die Energiefunktion minimal sein. Auf der Grundlage der folgenden Einschränkungen können wir die Energiefunktion wie folgt berechnen:
Einschränkung-I
Die erste Einschränkung, auf deren Grundlage wir die Energiefunktion berechnen, besteht darin, dass ein Element in jeder Matrixzeile gleich 1 sein muss M und andere Elemente in jeder Zeile müssen gleich sein 0weil jede Stadt in der TSP-Tour nur an einer Position auftreten kann. Diese Einschränkung kann mathematisch wie folgt geschrieben werden:
$$ \ displaystyle \ sum \ limit_ {j = 1} ^ n M_ {x, j} \: = \: 1 \: für \: x \: \ in \: \ lbrace1, ..., n \ rbrace $ $
Nun enthält die zu minimierende Energiefunktion basierend auf der obigen Einschränkung einen Term proportional zu -
$$ \ displaystyle \ sum \ limit_ {x = 1} ^ n \ left (\ begin {array} {c} 1 \: - \: \ displaystyle \ sum \ limit_ {j = 1} ^ n M_ {x, j } \ end {array} \ right) ^ 2 $$
Einschränkung-II
Wie wir wissen, kann in TSP eine Stadt an jeder Position der Tour auftreten, also in jeder Matrixspalte Mmuss ein Element gleich 1 sein und andere Elemente müssen gleich 0 sein. Diese Einschränkung kann mathematisch wie folgt geschrieben werden:
$$ \ displaystyle \ sum \ limit_ {x = 1} ^ n M_ {x, j} \: = \: 1 \: für \: j \: \ in \: \ lbrace1, ..., n \ rbrace $ $
Nun enthält die zu minimierende Energiefunktion basierend auf der obigen Einschränkung einen Term proportional zu -
$$ \ displaystyle \ sum \ limit_ {j = 1} ^ n \ left (\ begin {array} {c} 1 \: - \: \ displaystyle \ sum \ limit_ {x = 1} ^ n M_ {x, j } \ end {array} \ right) ^ 2 $$
Kostenfunktionsberechnung
Nehmen wir eine quadratische Matrix von (n × n) bezeichnet durch C bezeichnet die Kostenmatrix von TSP für n Städte, in denen n > 0. Im Folgenden sind einige Parameter bei der Berechnung der Kostenfunktion aufgeführt:
Cx, y - Das Element der Kostenmatrix bezeichnet die Reisekosten von der Stadt x zu y.
Die Adjazenz der Elemente von A und B kann durch die folgende Beziehung gezeigt werden:
$$ M_ {x, i} \: = \: 1 \: \: und \: \: M_ {y, i \ pm 1} \: = \: 1 $$
Wie wir wissen, kann in Matrix der Ausgabewert jedes Knotens entweder 0 oder 1 sein, daher können wir für jedes Städtepaar A, B der Energiefunktion die folgenden Begriffe hinzufügen:
$$ \ displaystyle \ sum \ limit_ {i = 1} ^ n C_ {x, y} M_ {x, i} (M_ {y, i + 1} \: + \: M_ {y, i-1}) $$
Auf der Grundlage der obigen Kostenfunktion und des Beschränkungswerts wird die endgültige Energiefunktion E kann wie folgt angegeben werden -
$$ E \: = \: \ frac {1} {2} \ Anzeigestil \ Summe \ Grenzen_ {i = 1} ^ n \ Anzeigestil \ Summe \ Grenzen_ {x} \ Anzeigestil \ Summe \ Grenzen_ {y \ neq x} C_ {x, y} M_ {x, i} (M_ {y, i + 1} \: + \: M_ {y, i-1}) \: + $$
$$ \: \ begin {bmatrix} \ gamma_ {1} \ displaystyle \ sum \ limit_ {x} \ left (\ begin {array} {c} 1 \: - \: \ displaystyle \ sum \ limit_ {i} M_ {x, i} \ end {array} \ right) ^ 2 \: + \: \ gamma_ {2} \ displaystyle \ sum \ limit_ {i} \ left (\ begin {array} {c} 1 \: - \ : \ displaystyle \ sum \ limit_ {x} M_ {x, i} \ end {array} \ right) ^ 2 \ end {bmatrix} $$
Hier, γ1 und γ2 sind zwei Wägekonstanten.
Iterierte Gradientenabstiegstechnik
Der Gradientenabstieg, auch als steilster Abstieg bekannt, ist ein iterativer Optimierungsalgorithmus, um ein lokales Minimum einer Funktion zu finden. Während wir die Funktion minimieren, sind wir besorgt über die Kosten oder Fehler, die minimiert werden müssen (Remember Travelling Salesman Problem). Es wird häufig beim Deep Learning verwendet, was in einer Vielzahl von Situationen nützlich ist. Der Punkt, an den man sich erinnern sollte, ist, dass es um lokale Optimierung und nicht um globale Optimierung geht.
Hauptarbeitsidee
Mit Hilfe der folgenden Schritte können wir die Hauptarbeitsidee des Gradientenabstiegs verstehen:
Beginnen Sie zunächst mit einer ersten Vermutung der Lösung.
Nehmen Sie dann den Gradienten der Funktion an diesem Punkt.
Wiederholen Sie den Vorgang später, indem Sie die Lösung in die negative Richtung des Gradienten bewegen.
Wenn Sie die obigen Schritte ausführen, konvergiert der Algorithmus schließlich dort, wo der Gradient Null ist.
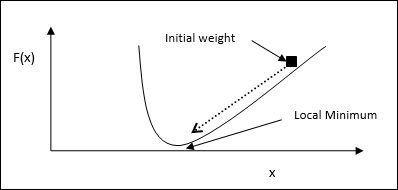
Mathematisches Konzept
Angenommen, wir haben eine Funktion f(x)und wir versuchen, das Minimum dieser Funktion zu finden. Im Folgenden finden Sie die Schritte, um das Minimum von zu findenf(x).
Geben Sie zunächst einen Anfangswert $ x_ {0} \: für \: x $ an
Nehmen Sie nun den Gradienten $ \ nabla f $ der Funktion mit der Intuition, dass der Gradient dabei die Steigung der Kurve ergibt x und seine Richtung zeigt auf die Zunahme der Funktion, um die beste Richtung herauszufinden, um sie zu minimieren.
Ändern Sie nun x wie folgt -
$$ x_ {n \: + \: 1} \: = \: x_ {n} \: - \: \ theta \ nabla f (x_ {n}) $$
Hier, θ > 0 ist die Trainingsrate (Schrittgröße), die den Algorithmus zu kleinen Sprüngen zwingt.
Schätzung der Schrittgröße
Eigentlich eine falsche Schrittweite θerreicht möglicherweise keine Konvergenz, daher ist eine sorgfältige Auswahl derselben sehr wichtig. Folgende Punkte müssen bei der Auswahl der Schrittweite beachtet werden
Wählen Sie keine zu große Schrittgröße, da dies sonst negative Auswirkungen hat, dh eher divergiert als konvergiert.
Wählen Sie keine zu kleine Schrittgröße, da die Konvergenz sonst viel Zeit in Anspruch nimmt.
Einige Optionen zur Auswahl der Schrittgröße -
Eine Möglichkeit besteht darin, eine feste Schrittgröße zu wählen.
Eine andere Möglichkeit besteht darin, für jede Iteration eine andere Schrittgröße zu wählen.
Simuliertes Tempern
Das Grundkonzept des Simulierten Glühens (SA) ist durch das Glühen in Festkörpern motiviert. Wenn wir beim Tempern ein Metall über seinen Schmelzpunkt erhitzen und abkühlen, hängen die strukturellen Eigenschaften von der Abkühlgeschwindigkeit ab. Wir können auch sagen, dass SA den metallurgischen Prozess des Glühens simuliert.
Verwendung in ANN
SA ist eine stochastische Berechnungsmethode, die von der Annealing-Analogie inspiriert ist, um die globale Optimierung einer bestimmten Funktion zu approximieren. Wir können SA verwenden, um vorwärtsgerichtete neuronale Netze zu trainieren.
Algorithmus
Step 1 - Generieren Sie eine zufällige Lösung.
Step 2 - Berechnen Sie die Kosten mit einer Kostenfunktion.
Step 3 - Generieren Sie eine zufällige benachbarte Lösung.
Step 4 - Berechnen Sie die neuen Lösungskosten mit derselben Kostenfunktion.
Step 5 - Vergleichen Sie die Kosten einer neuen Lösung mit denen einer alten Lösung wie folgt: -
Wenn CostNew Solution < CostOld Solution Wechseln Sie dann zur neuen Lösung.
Step 6 - Testen Sie den Stoppzustand, bei dem es sich möglicherweise um die maximal erreichte Anzahl von Iterationen handelt, oder erhalten Sie eine akzeptable Lösung.
Die Natur war schon immer eine großartige Inspirationsquelle für die ganze Menschheit. Genetische Algorithmen (GAs) sind suchbasierte Algorithmen, die auf den Konzepten der natürlichen Selektion und Genetik basieren. GAs sind eine Teilmenge eines viel größeren Berechnungszweigs, der als bekannt istEvolutionary Computation.
GAs wurde von John Holland und seinen Studenten und Kollegen an der University of Michigan, insbesondere David E. Goldberg, entwickelt und seitdem mit großem Erfolg an verschiedenen Optimierungsproblemen getestet.
In GAs haben wir einen Pool oder eine Population möglicher Lösungen für das gegebene Problem. Diese Lösungen werden dann rekombiniert und mutiert (wie in der natürlichen Genetik), wodurch neue Kinder entstehen, und der Prozess wird über verschiedene Generationen wiederholt. Jeder Person (oder Kandidatenlösung) wird ein Fitnesswert zugewiesen (basierend auf ihrem objektiven Funktionswert), und den fitteren Individuen wird eine höhere Chance gegeben, sich zu paaren und mehr "fitter" Individuen hervorzubringen. Dies steht im Einklang mit der darwinistischen Theorie des „Überlebens der Stärkeren“.
Auf diese Weise „entwickeln“ wir über Generationen hinweg immer bessere Individuen oder Lösungen, bis wir ein Stoppkriterium erreichen.
Genetische Algorithmen sind von Natur aus ausreichend randomisiert, bieten jedoch eine viel bessere Leistung als die zufällige lokale Suche (bei der wir nur verschiedene zufällige Lösungen ausprobieren und die bisher besten verfolgen), da sie auch historische Informationen nutzen.
Vorteile von GAs
GAs haben verschiedene Vorteile, die sie sehr beliebt gemacht haben. Dazu gehören -
Benötigt keine abgeleiteten Informationen (die für viele reale Probleme möglicherweise nicht verfügbar sind).
Ist schneller und effizienter als die herkömmlichen Methoden.
Hat sehr gute parallele Fähigkeiten.
Optimiert sowohl kontinuierliche als auch diskrete Funktionen sowie Probleme mit mehreren Objektiven.
Bietet eine Liste mit „guten“ Lösungen und nicht nur eine einzige Lösung.
Erhält immer eine Antwort auf das Problem, das mit der Zeit besser wird.
Nützlich, wenn der Suchraum sehr groß ist und eine große Anzahl von Parametern beteiligt ist.
Einschränkungen von GAs
Wie jede Technik leiden auch GAs unter einigen Einschränkungen. Dazu gehören -
GAs sind nicht für alle Probleme geeignet, insbesondere für Probleme, die einfach sind und für die abgeleitete Informationen verfügbar sind.
Der Fitnesswert wird wiederholt berechnet, was bei einigen Problemen rechenintensiv sein kann.
Da es stochastisch ist, gibt es keine Garantie für die Optimalität oder die Qualität der Lösung.
Bei nicht ordnungsgemäßer Implementierung konvergiert GA möglicherweise nicht zur optimalen Lösung.
GA - Motivation
Genetische Algorithmen haben die Fähigkeit, eine "gut genug" -Lösung "schnell genug" zu liefern. Dies macht Gas attraktiv für die Lösung von Optimierungsproblemen. Die Gründe, warum GAs benötigt werden, sind folgende:
Schwierige Probleme lösen
In der Informatik gibt es eine Vielzahl von Problemen NP-Hard. Dies bedeutet im Wesentlichen, dass selbst die leistungsstärksten Computersysteme sehr lange (sogar Jahre!) Brauchen, um dieses Problem zu lösen. In einem solchen Szenario erweisen sich GAs als effizientes Instrumentusable near-optimal solutions in kurzer Zeit.
Versagen gradientenbasierter Methoden
Traditionelle kalkülbasierte Methoden beginnen an einem zufälligen Punkt und bewegen sich in Richtung des Gradienten, bis wir die Spitze des Hügels erreichen. Diese Technik ist effizient und funktioniert sehr gut für Zielfunktionen mit einem Peak wie die Kostenfunktion bei der linearen Regression. In den meisten realen Situationen haben wir jedoch ein sehr komplexes Problem, das als Landschaften bezeichnet wird und aus vielen Gipfeln und vielen Tälern besteht. Dies führt dazu, dass solche Methoden fehlschlagen, da sie unter der inhärenten Tendenz leiden, wie gezeigt an den lokalen Optima hängen zu bleiben in der folgenden Abbildung.
Schnelle Lösung
Einige schwierige Probleme wie das Travelling Salesman Problem (TSP) haben reale Anwendungen wie Pfadfindung und VLSI-Design. Stellen Sie sich nun vor, Sie verwenden Ihr GPS-Navigationssystem und es dauert einige Minuten (oder sogar einige Stunden), um den „optimalen“ Pfad von der Quelle zum Ziel zu berechnen. Eine Verzögerung in solchen realen Anwendungen ist nicht akzeptabel, und daher ist eine „ausreichend gute“ Lösung erforderlich, die „schnell“ geliefert wird.
Wie verwende ich GA für Optimierungsprobleme?
Wir wissen bereits, dass Optimierung eine Aktion ist, um etwas wie Design, Situation, Ressource und System so effektiv wie möglich zu gestalten. Der Optimierungsprozess ist in der folgenden Abbildung dargestellt.

Stufen des GA-Mechanismus für den Optimierungsprozess
Das Folgende sind die Stufen des GA-Mechanismus, wenn er zur Optimierung von Problemen verwendet wird.
Generieren Sie die anfängliche Population zufällig.
Wählen Sie die ursprüngliche Lösung mit den besten Fitnesswerten.
Kombinieren Sie die ausgewählten Lösungen mithilfe von Mutations- und Crossover-Operatoren neu.
Fügen Sie Nachkommen in die Population ein.
Wenn nun die Stoppbedingung erfüllt ist, geben Sie die Lösung mit dem besten Fitnesswert zurück. Andernfalls fahren Sie mit Schritt 2 fort.
Bevor wir die Bereiche untersuchen, in denen ANN ausgiebig verwendet wurde, müssen wir verstehen, warum ANN die bevorzugte Wahl für die Anwendung ist.
Warum künstliche neuronale Netze?
Wir müssen die Antwort auf die obige Frage anhand eines Beispiels eines Menschen verstehen. Als Kind haben wir die Dinge mit Hilfe unserer Ältesten gelernt, einschließlich unserer Eltern oder Lehrer. Später lernen wir dann durch Selbstlernen oder Üben unser ganzes Leben lang. Wissenschaftler und Forscher machen die Maschine ebenso intelligent wie ein Mensch, und ANN spielt dabei aus folgenden Gründen eine sehr wichtige Rolle:
Mit Hilfe neuronaler Netze können wir die Lösung solcher Probleme finden, für die algorithmische Verfahren teuer sind oder nicht existieren.
Neuronale Netze können anhand von Beispielen lernen, daher müssen wir sie nicht in großem Umfang programmieren.
Neuronale Netze haben die Genauigkeit und die deutlich höhere Geschwindigkeit als herkömmliche Geschwindigkeiten.
Anwendungsbereiche
Es folgen einige Bereiche, in denen ANN verwendet wird. Es legt nahe, dass ANN in seiner Entwicklung und Anwendung einen interdisziplinären Ansatz verfolgt.
Spracherkennung
Die Sprache spielt eine herausragende Rolle in der Mensch-Mensch-Interaktion. Daher ist es für Menschen selbstverständlich, Sprachschnittstellen mit Computern zu erwarten. In der heutigen Zeit benötigt der Mensch für die Kommunikation mit Maschinen immer noch anspruchsvolle Sprachen, die schwer zu lernen und zu verwenden sind. Um diese Kommunikationsbarriere zu beseitigen, könnte eine einfache Lösung darin bestehen, in einer gesprochenen Sprache zu kommunizieren, die die Maschine verstehen kann.
Auf diesem Gebiet wurden große Fortschritte erzielt, doch sind solche Systeme immer noch mit dem Problem des begrenzten Wortschatzes oder der begrenzten Grammatik konfrontiert, zusammen mit dem Problem der Umschulung des Systems für verschiedene Sprecher unter verschiedenen Bedingungen. ANN spielt in diesem Bereich eine wichtige Rolle. Folgende ANNs wurden zur Spracherkennung verwendet -
Multilayer-Netzwerke
Mehrschichtige Netzwerke mit wiederkehrenden Verbindungen
Selbstorganisierende Feature-Map von Kohonen
Das nützlichste Netzwerk hierfür ist die Kohonen Self-Organizing Feature Map, deren Eingabe als kurze Segmente der Sprachwellenform erfolgt. Es werden die gleichen Phoneme wie das Ausgabearray abgebildet, die als Merkmalsextraktionstechnik bezeichnet werden. Nach dem Extrahieren der Merkmale mit Hilfe einiger akustischer Modelle als Back-End-Verarbeitung wird die Äußerung erkannt.
Zeichenerkennung
Es ist ein interessantes Problem, das unter den allgemeinen Bereich der Mustererkennung fällt. Viele neuronale Netze wurden zur automatischen Erkennung handgeschriebener Zeichen, entweder Buchstaben oder Ziffern, entwickelt. Im Folgenden sind einige ANNs aufgeführt, die zur Zeichenerkennung verwendet wurden.
- Mehrschichtige neuronale Netze wie z. B. neuronale Backpropagation-Netze.
- Neocognitron
Obwohl neuronale Netze mit Rückausbreitung mehrere verborgene Schichten aufweisen, ist das Verbindungsmuster von einer Schicht zur nächsten lokalisiert. In ähnlicher Weise hat Neocognitron auch mehrere verborgene Schichten und sein Training wird Schicht für Schicht für solche Arten von Anwendungen durchgeführt.
Antrag auf Überprüfung der Unterschrift
Signaturen sind eine der nützlichsten Methoden, um eine Person bei Rechtsgeschäften zu autorisieren und zu authentifizieren. Die Technik zur Überprüfung der Signatur ist eine nicht auf dem Sehen basierende Technik.
Für diese Anwendung besteht der erste Ansatz darin, das Merkmal bzw. den geometrischen Merkmalssatz zu extrahieren, der die Signatur darstellt. Mit diesen Funktionssätzen müssen wir die neuronalen Netze mithilfe eines effizienten Algorithmus für neuronale Netze trainieren. Dieses trainierte neuronale Netzwerk klassifiziert die Signatur in der Überprüfungsphase als echt oder gefälscht.
Erkennung des menschlichen Gesichts
Es ist eine der biometrischen Methoden, um das gegebene Gesicht zu identifizieren. Dies ist eine typische Aufgabe aufgrund der Charakterisierung von Bildern ohne Gesicht. Wenn ein neuronales Netzwerk jedoch gut trainiert ist, kann es in zwei Klassen unterteilt werden, nämlich Bilder mit Gesichtern und Bilder ohne Gesichter.
Zunächst müssen alle Eingabebilder vorverarbeitet werden. Dann muss die Dimensionalität dieses Bildes reduziert werden. Und schließlich muss es unter Verwendung eines Trainingsalgorithmus für neuronale Netze klassifiziert werden. Folgende neuronale Netze werden zu Trainingszwecken mit vorverarbeitetem Bild verwendet -
Vollständig verbundenes mehrschichtiges neuronales Feed-Forward-Netzwerk, das mithilfe eines Back-Propagation-Algorithmus trainiert wurde.
Zur Reduzierung der Dimensionalität wird die Hauptkomponentenanalyse (PCA) verwendet.