Computergrafik - Kurzanleitung
Computergrafik ist eine Kunst, mit Hilfe der Programmierung Bilder auf Computerbildschirmen zu zeichnen. Es beinhaltet Berechnungen, Erstellung und Manipulation von Daten. Mit anderen Worten, wir können sagen, dass Computergrafik ein Rendering-Tool für die Erzeugung und Bearbeitung von Bildern ist.
Kathodenstrahlröhre
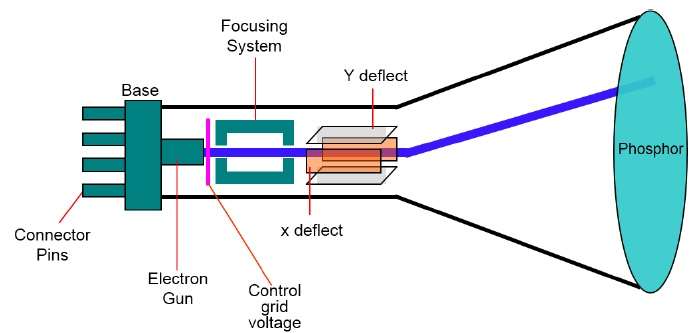
Das primäre Ausgabegerät in einem grafischen System ist der Videomonitor. Das Hauptelement eines Videomonitors ist dasCathode Ray Tube (CRT), in der folgenden Abbildung gezeigt.
Die Bedienung der CRT ist sehr einfach -
Die Elektronenkanone sendet einen Elektronenstrahl (Kathodenstrahlen) aus.
Der Elektronenstrahl durchläuft Fokussierungs- und Ablenksysteme, die ihn zu bestimmten Positionen auf dem phosphorbeschichteten Bildschirm lenken.
Wenn der Strahl auf den Bildschirm trifft, sendet der Leuchtstoff an jeder Position, die vom Elektronenstrahl berührt wird, einen kleinen Lichtpunkt aus.
Es zeichnet das Bild neu, indem es den Elektronenstrahl schnell über dieselben Bildschirmpunkte zurücklenkt.
Es gibt zwei Möglichkeiten (Zufallsscan und Raster-Scan), mit denen wir ein Objekt auf dem Bildschirm anzeigen können.
Raster-Scan
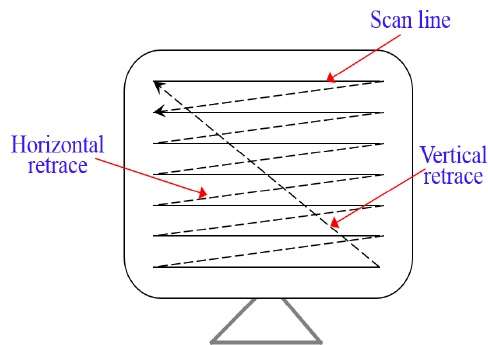
In einem Raster-Scan-System wird der Elektronenstrahl zeilenweise von oben nach unten über den Bildschirm geführt. Wenn sich der Elektronenstrahl über jede Reihe bewegt, wird die Strahlintensität ein- und ausgeschaltet, um ein Muster aus beleuchteten Punkten zu erzeugen.
Die Bilddefinition wird im Speicherbereich gespeichert, der als bezeichnet wird Refresh Buffer oder Frame Buffer. Dieser Speicherbereich enthält die Intensitätswerte für alle Bildschirmpunkte. Gespeicherte Intensitätswerte werden dann aus dem Aktualisierungspuffer abgerufen und zeilenweise (Scanlinie) auf dem Bildschirm „gemalt“, wie in der folgenden Abbildung gezeigt.
Jeder Bildschirmpunkt wird als bezeichnet pixel (picture element) oder pel. Am Ende jeder Abtastzeile kehrt der Elektronenstrahl zur linken Seite des Bildschirms zurück, um mit der Anzeige der nächsten Abtastzeile zu beginnen.
Zufallsscan (Vektorscan)
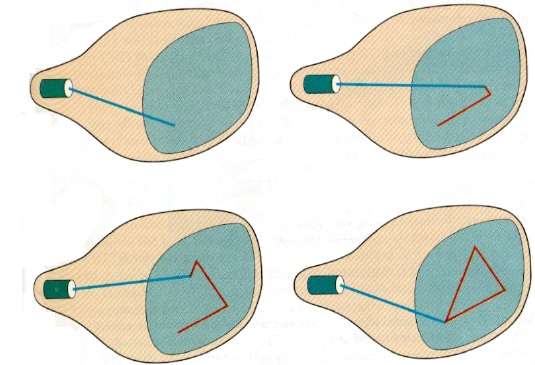
Bei dieser Technik wird der Elektronenstrahl nur auf den Teil des Bildschirms gerichtet, auf dem das Bild gezeichnet werden soll, anstatt wie beim Raster-Scan von links nach rechts und von oben nach unten zu scannen. Es wird auch genanntvector display, stroke-writing display, oder calligraphic display.
Die Bilddefinition wird als Satz von Strichzeichnungsbefehlen in einem Speicherbereich gespeichert, der als bezeichnet wird refresh display file. Um ein bestimmtes Bild anzuzeigen, durchläuft das System die Befehle in der Anzeigedatei und zeichnet nacheinander jede Komponentenlinie. Nachdem alle Strichzeichnungsbefehle verarbeitet wurden, kehrt das System zum ersten Zeilenbefehl in der Liste zurück.
Random-Scan-Anzeigen zeichnen alle Komponentenlinien eines Bildes 30 bis 60 Mal pro Sekunde.
Anwendung von Computergrafiken
Computergrafik hat zahlreiche Anwendungen, von denen einige unten aufgeführt sind -
Computer graphics user interfaces (GUIs) - Ein grafisches, mausorientiertes Paradigma, mit dem der Benutzer mit einem Computer interagieren kann.
Business presentation graphics - "Ein Bild sagt mehr als tausend Worte".
Cartography - Karten zeichnen.
Weather Maps - Echtzeit-Mapping, symbolische Darstellungen.
Satellite Imaging - Geodätische Bilder.
Photo Enhancement - Schärfe Fotos schärfen.
Medical imaging - MRTs, CAT-Scans usw. - Nicht-invasive interne Untersuchung.
Engineering drawings - mechanisch, elektrisch, zivil usw. - Ersetzen der Blaupausen der Vergangenheit.
Typography - Die Verwendung von Zeichenbildern beim Veröffentlichen - ersetzt den harten Typ der Vergangenheit.
Architecture - Baupläne, Außenskizzen - Ersetzen der Blaupausen und Handzeichnungen der Vergangenheit.
Art - Computer bieten Künstlern ein neues Medium.
Training - Flugsimulatoren, computergestützte Anweisungen usw.
Entertainment - Filme und Spiele.
Simulation and modeling - Ersetzen von physischen Modellen und Enactments
Eine Linie verbindet zwei Punkte. Es ist ein Grundelement in Grafiken. Um eine Linie zu zeichnen, benötigen Sie zwei Punkte, zwischen denen Sie eine Linie zeichnen können. In den folgenden drei Algorithmen bezeichnen wir den einen Linienpunkt als$X_{0}, Y_{0}$ und der zweite Linienpunkt als $X_{1}, Y_{1}$.
DDA-Algorithmus
Der Digital Differential Analyzer (DDA) -Algorithmus ist der einfache Zeilengenerierungsalgorithmus, der hier Schritt für Schritt erläutert wird.
Step 1 - Holen Sie sich die Eingabe von zwei Endpunkten $(X_{0}, Y_{0})$ und $(X_{1}, Y_{1})$.
Step 2 - Berechnen Sie die Differenz zwischen zwei Endpunkten.
dx = X1 - X0
dy = Y1 - Y0Step 3- Basierend auf der berechneten Differenz in Schritt 2 müssen Sie die Anzahl der Schritte zum Einfügen von Pixeln ermitteln. Wenn dx> dy, benötigen Sie weitere Schritte in der x-Koordinate. sonst in y-Koordinate.
if (absolute(dx) > absolute(dy))
Steps = absolute(dx);
else
Steps = absolute(dy);Step 4 - Berechnen Sie das Inkrement in x-Koordinate und y-Koordinate.
Xincrement = dx / (float) steps;
Yincrement = dy / (float) steps;Step 5 - Setzen Sie das Pixel, indem Sie die x- und y-Koordinaten erfolgreich entsprechend erhöhen, und vervollständigen Sie das Zeichnen der Linie.
for(int v=0; v < Steps; v++)
{
x = x + Xincrement;
y = y + Yincrement;
putpixel(Round(x), Round(y));
}Bresenhams Liniengenerierung
Der Bresenham-Algorithmus ist ein weiterer inkrementeller Scan-Konvertierungsalgorithmus. Der große Vorteil dieses Algorithmus besteht darin, dass nur ganzzahlige Berechnungen verwendet werden. Bewegen Sie sich in Einheitsintervallen über die x-Achse und wählen Sie bei jedem Schritt zwischen zwei verschiedenen y-Koordinaten.
Wie in der folgenden Abbildung gezeigt, müssen Sie beispielsweise an Position (2, 3) zwischen (3, 3) und (3, 4) wählen. Sie möchten den Punkt, der näher an der ursprünglichen Linie liegt.
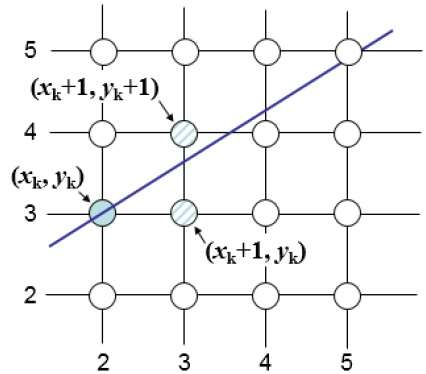
An der Probenposition $X_{k}+1,$ Die vertikalen Abstände von der mathematischen Linie sind mit gekennzeichnet $d_{upper}$ und $d_{lower}$.
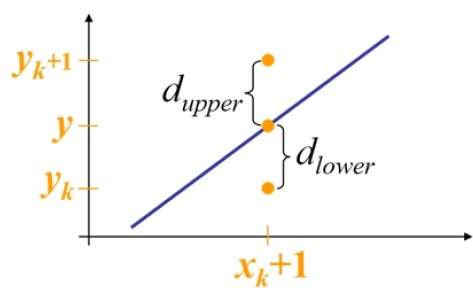
Aus der obigen Abbildung ergibt sich die y-Koordinate auf der mathematischen Linie bei $x_{k}+1$ ist -
Y = m ($X_{k}$+1) + b
Damit, $d_{upper}$ und $d_{lower}$ sind wie folgt angegeben -
$$d_{lower} = y-y_{k}$$
$$= m(X_{k} + 1) + b - Y_{k}$$
und
$$d_{upper} = (y_{k} + 1) - y$$
$= Y_{k} + 1 - m (X_{k} + 1) - b$
Mit diesen können Sie einfach entscheiden, welches Pixel näher an der mathematischen Linie liegt. Diese einfache Entscheidung basiert auf der Differenz zwischen den beiden Pixelpositionen.
$$d_{lower} - d_{upper} = 2m(x_{k} + 1) - 2y_{k} + 2b - 1$$
Ersetzen wir m durch dy / dx, wobei dx und dy die Unterschiede zwischen den Endpunkten sind.
$$dx (d_{lower} - d_{upper}) =dx(2\frac{\mathrm{d} y}{\mathrm{d} x}(x_{k} + 1) - 2y_{k} + 2b - 1)$$
$$ = 2dy.x_{k} - 2dx.y_{k} + 2dy + 2dx(2b-1)$$
$$ = 2dy.x_{k} - 2dx.y_{k} + C$$
Also ein Entscheidungsparameter $P_{k}$für den k- ten Schritt entlang einer Linie ist gegeben durch -
$$p_{k} = dx(d_{lower} - d_{upper})$$
$$ = 2dy.x_{k} - 2dx.y_{k} + C$$
Das Vorzeichen des Entscheidungsparameters $P_{k}$ ist das gleiche wie das von $d_{lower} - d_{upper}$.
Wenn $p_{k}$ ist negativ, dann wählen Sie das untere Pixel, andernfalls wählen Sie das obere Pixel.
Denken Sie daran, dass die Koordinatenänderungen entlang der x-Achse in Einheitsschritten erfolgen, sodass Sie alles mit ganzzahligen Berechnungen ausführen können. In Schritt k + 1 wird der Entscheidungsparameter als - angegeben
$$p_{k +1} = 2dy.x_{k + 1} - 2dx.y_{k + 1} + C$$
Subtrahieren $p_{k}$ daraus bekommen wir -
$$p_{k + 1} - p_{k} = 2dy(x_{k + 1} - x_{k}) - 2dx(y_{k + 1} - y_{k})$$
Aber, $x_{k+1}$ ist das gleiche wie $x_{k+1}$. Also -
$$p_{k+1} = p_{k} + 2dy - 2dx(y_{k+1} - y_{k})$$
Wo, $Y_{k+1} – Y_{k}$ ist entweder 0 oder 1, abhängig vom Vorzeichen von $P_{k}$.
Der erste Entscheidungsparameter $p_{0}$ wird bewertet bei $(x_{0}, y_{0})$ wird angegeben als -
$$p_{0} = 2dy - dx$$
Unter Berücksichtigung aller oben genannten Punkte und Berechnungen ist hier der Bresenham-Algorithmus für die Steigung m <1 -
Step 1 - Geben Sie die beiden Endpunkte der Linie ein und speichern Sie den linken Endpunkt in $(x_{0}, y_{0})$.
Step 2 - Zeichnen Sie den Punkt $(x_{0}, y_{0})$.
Step 3 - Berechnen Sie die Konstanten dx, dy, 2dy und (2dy - 2dx) und erhalten Sie den ersten Wert für den Entscheidungsparameter als -
$$p_{0} = 2dy - dx$$
Step 4 - Bei jedem $X_{k}$ Führen Sie entlang der Linie ab k = 0 den folgenden Test durch:
Wenn $p_{k}$ <0, der nächste zu zeichnende Punkt ist $(x_{k}+1, y_{k})$ und
$$p_{k+1} = p_{k} + 2dy$$ Andernfalls,
$$(x_{k}, y_{k}+1)$$
$$p_{k+1} = p_{k} + 2dy - 2dx$$
Step 5 - Wiederholen Sie Schritt 4 (dx - 1) Mal.
Finden Sie für m> 1 heraus, ob Sie x inkrementieren müssen, während Sie y jedes Mal inkrementieren.
Nach dem Lösen der Gleichung für Entscheidungsparameter $P_{k}$ wird sehr ähnlich sein, nur das x und y in der Gleichung wird vertauscht.
Mittelpunkt-Algorithmus
Der Mittelpunktalgorithmus geht auf Bresenham zurück, das von Pitteway und Van Aken modifiziert wurde. Angenommen, Sie haben den Punkt P bereits auf die (x, y) -Koordinate gesetzt und die Steigung der Linie ist 0 ≤ k ≤ 1, wie in der folgenden Abbildung gezeigt.
Nun müssen Sie entscheiden, ob der nächste Punkt bei E oder N platziert werden soll. Dies kann durch Identifizieren des Schnittpunkts Q gewählt werden, der dem Punkt N oder E am nächsten liegt. Wenn der Schnittpunkt Q dem Punkt N am nächsten liegt, wird N als betrachtet der nächste Punkt; sonst E.
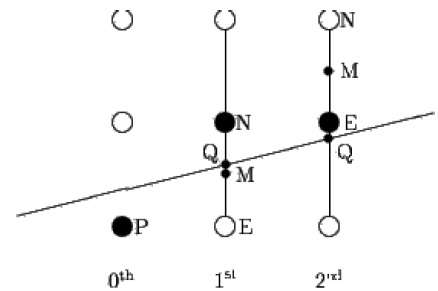
Um dies zu bestimmen, berechnen Sie zuerst den Mittelpunkt M (x + 1, y + ½). Wenn der Schnittpunkt Q der Linie mit der vertikalen Linie zwischen E und N unter M liegt, nehmen Sie E als nächsten Punkt. Andernfalls nehmen Sie N als nächsten Punkt.
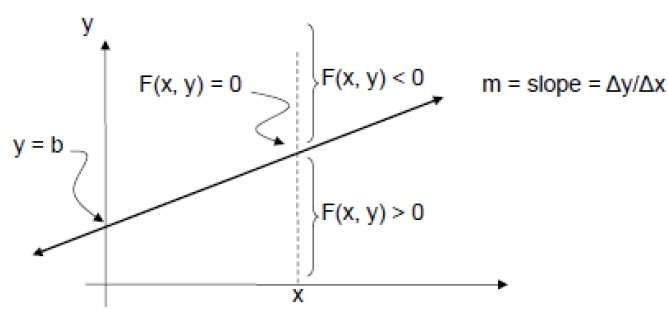
Um dies zu überprüfen, müssen wir die implizite Gleichung berücksichtigen -
F (x, y) = mx + b - y
Für positives m bei jedem gegebenen X,
- Wenn y in der Zeile steht, ist F (x, y) = 0
- Wenn y über der Linie liegt, ist F (x, y) <0
- Wenn y unter der Linie liegt, ist F (x, y)> 0
Das Zeichnen eines Kreises auf dem Bildschirm ist etwas komplexer als das Zeichnen einer Linie. Es gibt zwei beliebte Algorithmen zum Erzeugen eines Kreises -Bresenham’s Algorithm und Midpoint Circle Algorithm. Diese Algorithmen basieren auf der Idee, die nachfolgenden Punkte zu bestimmen, die zum Zeichnen des Kreises erforderlich sind. Lassen Sie uns die Algorithmen im Detail diskutieren -
Die Kreisgleichung lautet $X^{2} + Y^{2} = r^{2},$ wobei r der Radius ist.
Bresenhams Algorithmus
Wir können keinen kontinuierlichen Bogen auf der Rasteranzeige anzeigen. Stattdessen müssen wir die nächste Pixelposition auswählen, um den Bogen zu vervollständigen.
Aus der folgenden Abbildung können Sie ersehen, dass wir das Pixel an der Position (X, Y) platziert haben und nun entscheiden müssen, wo das nächste Pixel platziert werden soll - bei N (X + 1, Y) oder bei S (X + 1, Y-1).
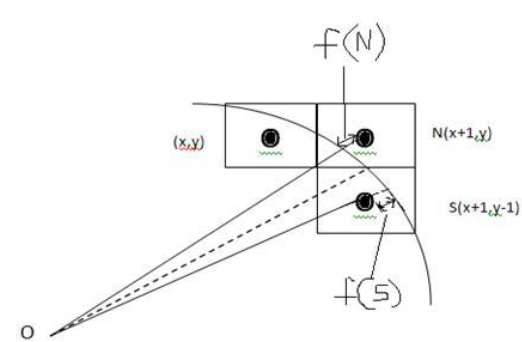
Dies kann durch den Entscheidungsparameter entschieden werden d.
- Wenn d <= 0 ist, ist N (X + 1, Y) als nächstes Pixel zu wählen.
- Wenn d> 0 ist, ist S (X + 1, Y-1) als nächstes Pixel zu wählen.
Algorithmus
Step 1- Ermitteln Sie die Koordinaten des Kreismittelpunkts und des Radius und speichern Sie sie in x, y bzw. R. Setze P = 0 und Q = R.
Step 2 - Entscheidungsparameter D = 3 - 2R einstellen.
Step 3 - Wiederholen Sie Schritt 8, während P ≤ Q ist.
Step 4 - Zeichnen Sie Kreis zeichnen (X, Y, P, Q).
Step 5 - Erhöhen Sie den Wert von P.
Step 6 - Wenn D <0, dann ist D = D + 4P + 6.
Step 7 - Andernfalls setzen Sie R = R - 1, D = D + 4 (PQ) + 10.
Step 8 - Zeichnen Sie Kreis zeichnen (X, Y, P, Q).
Draw Circle Method(X, Y, P, Q).
Call Putpixel (X + P, Y + Q).
Call Putpixel (X - P, Y + Q).
Call Putpixel (X + P, Y - Q).
Call Putpixel (X - P, Y - Q).
Call Putpixel (X + Q, Y + P).
Call Putpixel (X - Q, Y + P).
Call Putpixel (X + Q, Y - P).
Call Putpixel (X - Q, Y - P).Mittelpunkt-Algorithmus
Step 1 - Eingaberadius r und Kreismittelpunkt $(x_{c,} y_{c})$ und erhalten Sie den ersten Punkt auf dem Umfang des Kreises, der auf dem Ursprung zentriert ist als
(x0, y0) = (0, r)Step 2 - Berechnen Sie den Anfangswert des Entscheidungsparameters als
$P_{0}$ = 5/4 - r (Zur Vereinfachung dieser Gleichung siehe die folgende Beschreibung.)
f(x, y) = x2 + y2 - r2 = 0
f(xi - 1/2 + e, yi + 1)
= (xi - 1/2 + e)2 + (yi + 1)2 - r2
= (xi- 1/2)2 + (yi + 1)2 - r2 + 2(xi - 1/2)e + e2
= f(xi - 1/2, yi + 1) + 2(xi - 1/2)e + e2 = 0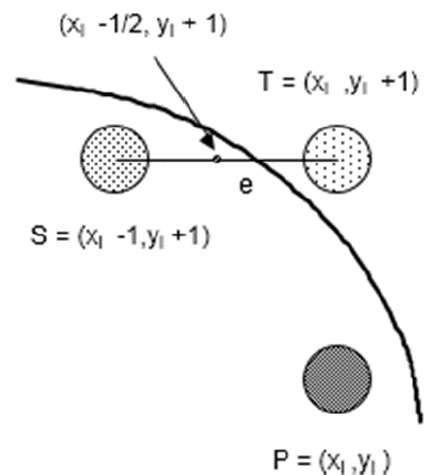
Let di = f(xi - 1/2, yi + 1) = -2(xi - 1/2)e - e2
Thus,
If e < 0 then di > 0 so choose point S = (xi - 1, yi + 1).
di+1 = f(xi - 1 - 1/2, yi + 1 + 1) = ((xi - 1/2) - 1)2 + ((yi + 1) + 1)2 - r2
= di - 2(xi - 1) + 2(yi + 1) + 1
= di + 2(yi + 1 - xi + 1) + 1
If e >= 0 then di <= 0 so choose point T = (xi, yi + 1)
di+1 = f(xi - 1/2, yi + 1 + 1)
= di + 2yi+1 + 1
The initial value of di is
d0 = f(r - 1/2, 0 + 1) = (r - 1/2)2 + 12 - r2
= 5/4 - r {1-r can be used if r is an integer}
When point S = (xi - 1, yi + 1) is chosen then
di+1 = di + -2xi+1 + 2yi+1 + 1
When point T = (xi, yi + 1) is chosen then
di+1 = di + 2yi+1 + 1Step 3 - Bei jedem $X_{K}$ Position beginnend bei K = 0, führen Sie den folgenden Test durch -
If PK < 0 then next point on circle (0,0) is (XK+1,YK) and
PK+1 = PK + 2XK+1 + 1
Else
PK+1 = PK + 2XK+1 + 1 – 2YK+1
Where, 2XK+1 = 2XK+2 and 2YK+1 = 2YK-2.Step 4 - Bestimmen Sie die Symmetriepunkte in anderen sieben Oktanten.
Step 5 - Verschieben Sie jede berechnete Pixelposition (X, Y) auf die zentrierte Kreisbahn $(X_{C,} Y_{C})$ und zeichnen Sie die Koordinatenwerte.
X = X + XC, Y = Y + YCStep 6 - Wiederholen Sie die Schritte 3 bis 5, bis X> = Y.
Polygon ist eine geordnete Liste von Scheitelpunkten, wie in der folgenden Abbildung dargestellt. Um Polygone mit bestimmten Farben zu füllen, müssen Sie die Pixel bestimmen, die auf den Rand des Polygons fallen, und diejenigen, die in das Polygon fallen. In diesem Kapitel werden wir sehen, wie wir Polygone mit verschiedenen Techniken füllen können.

Scan Line Algorithmus
Dieser Algorithmus schneidet die Scanlinie mit Polygonkanten und füllt das Polygon zwischen Schnittpaaren. Die folgenden Schritte zeigen, wie dieser Algorithmus funktioniert.
Step 1 - Ermitteln Sie Ymin und Ymax aus dem angegebenen Polygon.
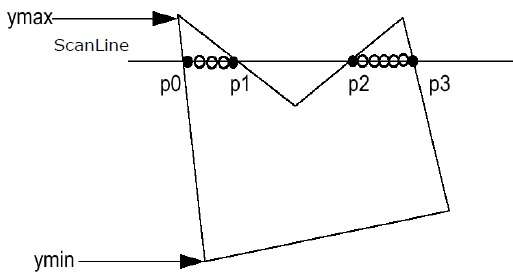
Step 2- ScanLine schneidet mit jeder Kante des Polygons von Ymin nach Ymax. Benennen Sie jeden Schnittpunkt des Polygons. Gemäß der oben gezeigten Figur werden sie als p0, p1, p2, p3 bezeichnet.
Step 3 - Sortieren Sie den Schnittpunkt in aufsteigender Reihenfolge der X-Koordinaten, dh (p0, p1), (p1, p2) und (p2, p3).
Step 4 - Füllen Sie alle Koordinatenpaare innerhalb der Polygone aus und ignorieren Sie die alternativen Paare.
Hochwasserfüllalgorithmus
Manchmal stoßen wir auf ein Objekt, bei dem wir den Bereich und seine Grenze mit verschiedenen Farben füllen möchten. Wir können solche Objekte mit einer bestimmten Innenfarbe malen, anstatt nach einer bestimmten Grenzfarbe wie beim Grenzfüllungsalgorithmus zu suchen.
Anstatt sich auf die Grenze des Objekts zu verlassen, stützt es sich auf die Füllfarbe. Mit anderen Worten, es ersetzt die Innenfarbe des Objekts durch die Füllfarbe. Wenn keine Pixel mehr der ursprünglichen Innenfarbe vorhanden sind, ist der Algorithmus abgeschlossen.
Wiederum basiert dieser Algorithmus auf der Four-Connect- oder Eight-Connect-Methode zum Ausfüllen der Pixel. Anstatt nach der Grenzfarbe zu suchen, werden alle benachbarten Pixel gesucht, die Teil des Innenraums sind.
Grenzfüllungsalgorithmus
Der Boundary-Fill-Algorithmus arbeitet als Name. Dieser Algorithmus wählt einen Punkt innerhalb eines Objekts aus und beginnt zu füllen, bis er die Grenze des Objekts erreicht. Die Farbe der Grenze und die Farbe, die wir füllen, sollten unterschiedlich sein, damit dieser Algorithmus funktioniert.
In diesem Algorithmus nehmen wir an, dass die Farbe der Grenze für das gesamte Objekt gleich ist. Der Grenzfüllungsalgorithmus kann durch 4 verbundene Pixel oder 8 verbundene Pixel implementiert werden.
4-verbundenes Polygon
Bei dieser Technik werden 4 verbundene Pixel verwendet, wie in der Figur gezeigt. Wir platzieren die Pixel über, unter, rechts und links von den aktuellen Pixeln. Dieser Vorgang wird fortgesetzt, bis wir eine Grenze mit einer anderen Farbe finden.
Algorithmus
Step 1 - Initialisieren Sie den Wert von Seed Point (Seedx, Seedy), Fcolor und Dcol.
Step 2 - Definieren Sie die Grenzwerte des Polygons.
Step 3 - Überprüfen Sie, ob der aktuelle Startpunkt die Standardfarbe hat, und wiederholen Sie die Schritte 4 und 5, bis die Grenzpixel erreicht sind.
If getpixel(x, y) = dcol then repeat step 4 and 5Step 4 - Ändern Sie die Standardfarbe mit der Füllfarbe am Startpunkt.
setPixel(seedx, seedy, fcol)Step 5 - Folgen Sie dem Verfahren rekursiv mit vier Nachbarschaftspunkten.
FloodFill (seedx – 1, seedy, fcol, dcol)
FloodFill (seedx + 1, seedy, fcol, dcol)
FloodFill (seedx, seedy - 1, fcol, dcol)
FloodFill (seedx – 1, seedy + 1, fcol, dcol)Step 6 - Beenden
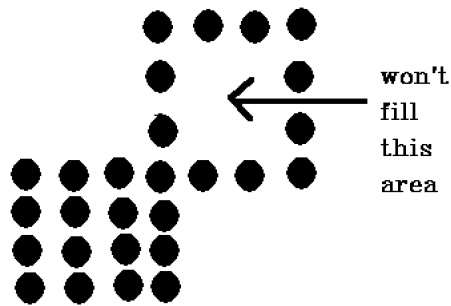
Bei dieser Technik gibt es ein Problem. Betrachten Sie den unten gezeigten Fall, in dem wir versucht haben, die gesamte Region zu füllen. Hier wird das Bild nur teilweise ausgefüllt. In solchen Fällen kann die 4-verbundene Pixel-Technik nicht verwendet werden.
8-verbundenes Polygon
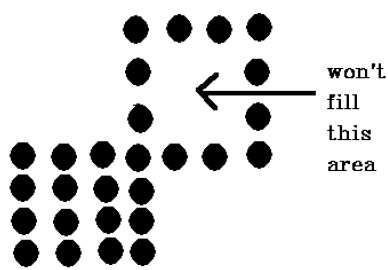
Bei dieser Technik werden 8 verbundene Pixel verwendet, wie in der Figur gezeigt. Wir platzieren Pixel über, unter, rechts und links von den aktuellen Pixeln, wie wir es in 4-verbundener Technik getan haben.
Darüber hinaus setzen wir Pixel in Diagonalen, sodass der gesamte Bereich des aktuellen Pixels abgedeckt wird. Dieser Prozess wird fortgesetzt, bis wir eine Grenze mit einer anderen Farbe finden.

Algorithmus
Step 1 - Initialisieren Sie den Wert von Seed Point (Seedx, Seedy), Fcolor und Dcol.
Step 2 - Definieren Sie die Grenzwerte des Polygons.
Step 3 - Überprüfen Sie, ob der aktuelle Startpunkt die Standardfarbe hat, und wiederholen Sie die Schritte 4 und 5, bis die Grenzpixel erreicht sind
If getpixel(x,y) = dcol then repeat step 4 and 5Step 4 - Ändern Sie die Standardfarbe mit der Füllfarbe am Startpunkt.
setPixel(seedx, seedy, fcol)Step 5 - Folgen Sie dem Verfahren rekursiv mit vier Nachbarschaftspunkten
FloodFill (seedx – 1, seedy, fcol, dcol)
FloodFill (seedx + 1, seedy, fcol, dcol)
FloodFill (seedx, seedy - 1, fcol, dcol)
FloodFill (seedx, seedy + 1, fcol, dcol)
FloodFill (seedx – 1, seedy + 1, fcol, dcol)
FloodFill (seedx + 1, seedy + 1, fcol, dcol)
FloodFill (seedx + 1, seedy - 1, fcol, dcol)
FloodFill (seedx – 1, seedy - 1, fcol, dcol)Step 6 - Beenden
Die 4-verbundene Pixel-Technik konnte den in der folgenden Abbildung markierten Bereich nicht ausfüllen, was bei der 8-verbundenen Technik nicht der Fall ist.
Innen-Außen-Test
Diese Methode ist auch bekannt als counting number method. Beim Füllen eines Objekts müssen wir häufig feststellen, ob sich ein bestimmter Punkt innerhalb oder außerhalb des Objekts befindet. Es gibt zwei Methoden, mit denen wir feststellen können, ob sich ein bestimmter Punkt innerhalb oder außerhalb eines Objekts befindet.
- Ungerade-Gerade-Regel
- Wicklungsnummernregel ungleich Null
Ungerade-Gerade-Regel
Bei dieser Technik zählen wir den Kantenübergang entlang der Linie von einem beliebigen Punkt (x, y) bis unendlich. Wenn die Anzahl der Wechselwirkungen ungerade ist, ist der Punkt (x, y) ein innerer Punkt. Wenn die Anzahl der Wechselwirkungen gerade ist, ist Punkt (x, y) ein äußerer Punkt. Hier ist das Beispiel, um Ihnen eine klare Vorstellung zu geben:
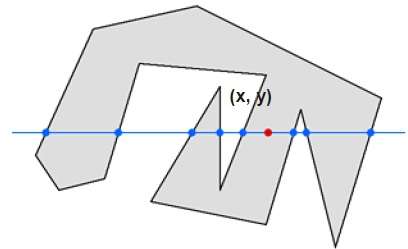
Aus der obigen Abbildung können wir ersehen, dass ab dem Punkt (x, y) die Anzahl der Interaktionspunkte auf der linken Seite 5 und auf der rechten Seite 3 beträgt. Die Gesamtzahl der Interaktionspunkte beträgt also 8, was ungerade ist . Daher wird der Punkt innerhalb des Objekts berücksichtigt.
Wicklungsnummernregel ungleich Null
Diese Methode wird auch mit den einfachen Polygonen verwendet, um zu testen, ob der angegebene Punkt innen liegt oder nicht. Es kann einfach mit Hilfe eines Stifts und eines Gummibands verstanden werden. Befestigen Sie den Stift an einer der Kanten des Polygons, binden Sie das Gummiband darin fest und dehnen Sie das Gummiband entlang der Kanten des Polygons.
Wenn alle Kanten des Polygons vom Gummiband bedeckt sind, überprüfen Sie den Stift, der an der zu testenden Stelle befestigt wurde. Wenn wir mindestens einen Wind am Punkt finden, betrachten Sie ihn innerhalb des Polygons, andernfalls können wir sagen, dass der Punkt nicht innerhalb des Polygons liegt.
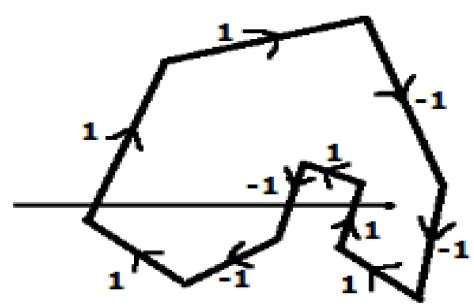
Geben Sie bei einer anderen alternativen Methode allen Kanten des Polygons Anweisungen. Zeichnen Sie eine Scanlinie vom zu testenden Punkt ganz links in der X-Richtung.
Geben Sie allen Kanten, die nach oben weisen, den Wert 1 und allen anderen -1 den Wert als Richtungswert.
Überprüfen Sie die Kantenrichtungswerte, von denen die Scanlinie verläuft, und fassen Sie sie zusammen.
Wenn die Gesamtsumme dieses Richtungswerts ungleich Null ist, ist dieser zu testende Punkt ein interior point, sonst ist es ein exterior point.
In der obigen Abbildung fassen wir die Richtungswerte zusammen, aus denen die Scanlinie verläuft, dann beträgt die Summe 1 - 1 + 1 = 1; das ist nicht Null. Der Punkt soll also ein innerer Punkt sein.
Die Hauptanwendung des Ausschnitts in Computergrafiken besteht darin, Objekte, Linien oder Liniensegmente zu entfernen, die sich außerhalb des Anzeigebereichs befinden. Die Betrachtungstransformation ist unempfindlich gegenüber der Position von Punkten relativ zum Betrachtungsvolumen - insbesondere den Punkten hinter dem Betrachter - und es ist erforderlich, diese Punkte vor dem Generieren der Ansicht zu entfernen.
Punktausschnitt
Das Ausschneiden eines Punktes aus einem bestimmten Fenster ist sehr einfach. Betrachten Sie die folgende Abbildung, in der das Rechteck das Fenster angibt. Das Abschneiden von Punkten gibt an, ob der angegebene Punkt (X, Y) innerhalb des angegebenen Fensters liegt oder nicht. und entscheidet, ob wir die minimalen und maximalen Koordinaten des Fensters verwenden.
Die X-Koordinate des gegebenen Punktes liegt innerhalb des Fensters, wenn X zwischen Wx1 ≤ X ≤ Wx2 liegt. Ebenso befindet sich die Y-Koordinate des angegebenen Punkts innerhalb des Fensters, wenn Y zwischen Wy1 ≤ Y ≤ Wy2 liegt.

Zeilenausschnitt
Das Konzept des Linienschneidens ist dasselbe wie das Punktschneiden. Beim Beschneiden von Linien schneiden wir den Teil der Linie, der sich außerhalb des Fensters befindet, und behalten nur den Teil bei, der sich innerhalb des Fensters befindet.
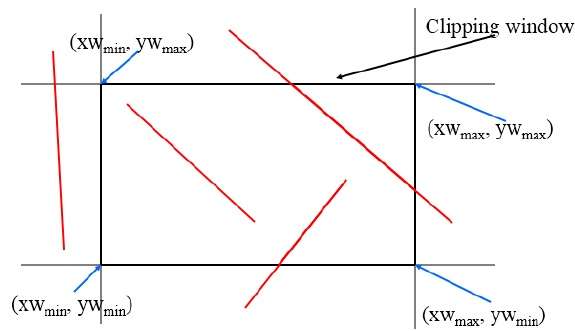
Cohen-Sutherland-Linienausschnitte
Dieser Algorithmus verwendet das Beschneidungsfenster wie in der folgenden Abbildung gezeigt. Die minimale Koordinate für den Beschneidungsbereich ist$(XW_{min,} YW_{min})$ und die maximale Koordinate für den Beschneidungsbereich ist $(XW_{max,} YW_{max})$.
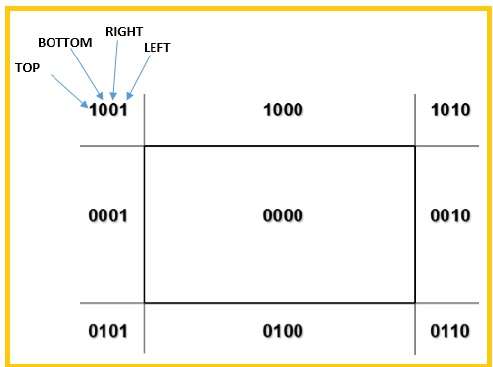
Wir werden 4-Bit verwenden, um die gesamte Region zu teilen. Diese 4 Bits repräsentieren den oberen, unteren, rechten und linken Bereich der Region, wie in der folgenden Abbildung gezeigt. Hier dasTOP und LEFT Bit wird auf 1 gesetzt, weil es das ist TOP-LEFT Ecke.
Es gibt 3 Möglichkeiten für die Linie -
Die Linie kann sich vollständig im Fenster befinden (Diese Linie sollte akzeptiert werden).
Die Linie kann sich vollständig außerhalb des Fensters befinden (Diese Linie wird vollständig aus der Region entfernt).
Die Linie kann sich teilweise innerhalb des Fensters befinden (wir finden den Schnittpunkt und zeichnen nur den Teil der Linie, der sich innerhalb des Bereichs befindet).
Algorithmus
Step 1 - Weisen Sie jedem Endpunkt einen Regionalcode zu.
Step 2 - Wenn beide Endpunkte einen Regionalcode haben 0000 dann akzeptiere diese Zeile.
Step 3 - Andernfalls führen Sie die logische ANDBetrieb für beide Regionalcodes.
Step 3.1 - Wenn das Ergebnis nicht ist 0000, dann lehnen Sie die Zeile ab.
Step 3.2 - Sonst brauchst du Clipping.
Step 3.2.1 - Wählen Sie einen Endpunkt der Linie außerhalb des Fensters.
Step 3.2.2 - Suchen Sie den Schnittpunkt an der Fenstergrenze (basierend auf dem Regionalcode).
Step 3.2.3 - Ersetzen Sie den Endpunkt durch den Schnittpunkt und aktualisieren Sie den Regionalcode.
Step 3.2.4 - Wiederholen Sie Schritt 2, bis Sie eine abgeschnittene Zeile finden, die entweder trivial akzeptiert oder trivial abgelehnt wurde.
Step 4 - Wiederholen Sie Schritt 1 für andere Zeilen.
Cyrus-Beck-Zeilenbeschneidungsalgorithmus
Dieser Algorithmus ist effizienter als der Cohen-Sutherland-Algorithmus. Es verwendet eine parametrische Liniendarstellung und einfache Punktprodukte.
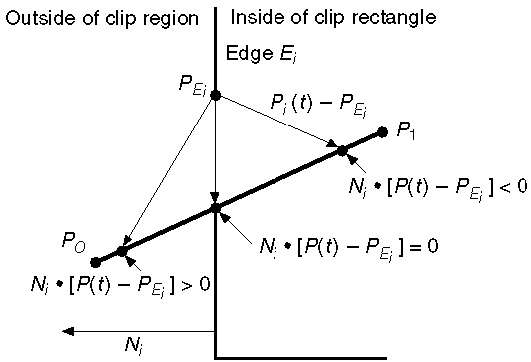
Die parametrische Liniengleichung lautet -
P0P1:P(t) = P0 + t(P1-P0)Sei N i die äußere Normalkante E i . Wählen Sie nun einen beliebigen Punkt P Ei an der Kante E i, dann bestimmt das Punktprodukt N i ∙ [P (t) - P Ei ], ob der Punkt P (t) „innerhalb der Clipkante“ oder „außerhalb“ der Clipkante oder liegt "An" der Clipkante.
Der Punkt P (t) liegt innerhalb, wenn N i . [P (t) - P Ei ] <0 ist
Der Punkt P (t) liegt außerhalb, wenn N i . [P (t) - P Ei ]> 0 ist
Der Punkt P (t) liegt am Rand, wenn N i . [P (t) - P Ei ] = 0 (Schnittpunkt)
N i . [P (t) - P Ei ] = 0
N i . [P 0 + t (P 1 -P 0 ) - P Ei ] = 0 (Ersetzen von P (t) durch P 0 + t (P 1 -P 0 ))
N i . [P 0 - P Ei ] + N i. T [P 1 -P 0 ] = 0
N i . [P 0 - P Ei ] + N i ∙ tD = 0 (Ersetzen von [P 1 -P 0 ] durch D )
N i . [P 0 - P Ei ] = - N i ∙ tD
Die Gleichung für t wird,
$$t = \tfrac{N_{i}.[P_{o} - P_{Ei}]}{{- N_{i}.D}}$$
Es gilt für folgende Bedingungen:
- N i ≠ 0 (Fehler kann nicht auftreten)
- D ≤ 0 (P 1 ≤ P 0 )
- N i ∙ D ≠ 0 (P 0 P 1 nicht parallel zu E i )
Polygon-Clipping (Sutherland-Hodgman-Algorithmus)
Ein Polygon kann auch durch Angabe des Beschneidungsfensters abgeschnitten werden. Der Sutherland Hodgeman-Polygon-Clipping-Algorithmus wird für das Polygon-Clipping verwendet. Bei diesem Algorithmus werden alle Scheitelpunkte des Polygons gegen jede Kante des Beschneidungsfensters abgeschnitten.
Zuerst wird das Polygon gegen den linken Rand des Polygonfensters abgeschnitten, um neue Scheitelpunkte des Polygons zu erhalten. Diese neuen Scheitelpunkte werden verwendet, um das Polygon gegen die rechte Kante, die obere Kante und die untere Kante des Beschneidungsfensters zu schneiden, wie in der folgenden Abbildung gezeigt.
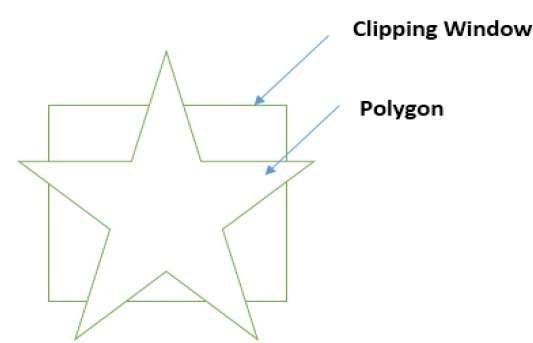
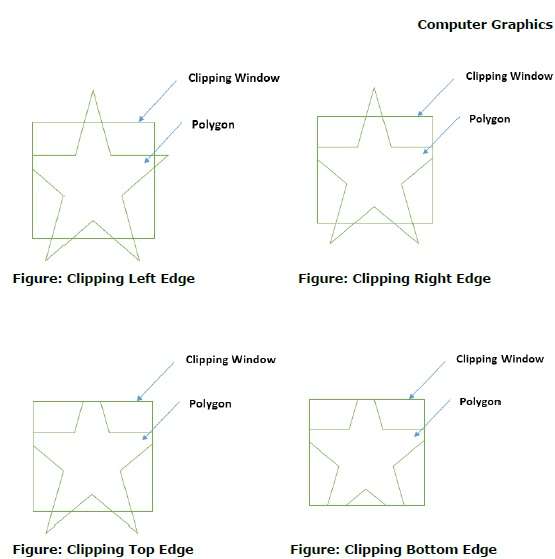
Während der Verarbeitung einer Kante eines Polygons mit einem Beschneidungsfenster wird ein Schnittpunkt gefunden, wenn sich die Kante nicht vollständig innerhalb des Beschneidungsfensters befindet und eine Teilkante vom Schnittpunkt zur Außenkante abgeschnitten wird. Die folgenden Abbildungen zeigen Ausschnitte am linken, rechten, oberen und unteren Rand -
Textausschnitt
Verschiedene Techniken werden verwendet, um Textausschnitte in einer Computergrafik bereitzustellen. Dies hängt von den Methoden zum Generieren von Zeichen und den Anforderungen einer bestimmten Anwendung ab. Es gibt drei Methoden zum Ausschneiden von Text, die unten aufgeführt sind:
- Alle oder keine String-Clipping
- Alle oder keine Zeichenausschnitte
- Textausschnitt
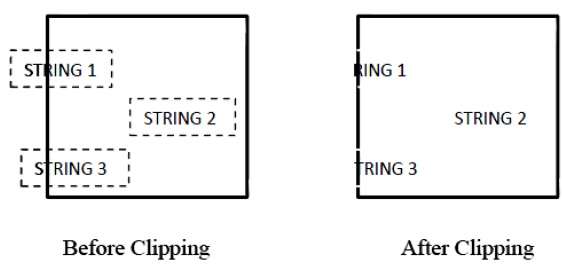
Die folgende Abbildung zeigt das Beschneiden aller oder keiner Zeichenfolgen -
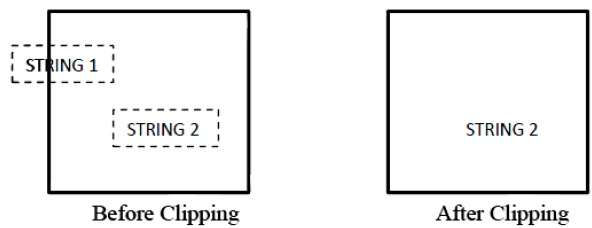
Bei der Beschneidungsmethode für alle oder keine Zeichenfolgen behalten wir entweder die gesamte Zeichenfolge bei oder lehnen die gesamte Zeichenfolge basierend auf dem Beschneidungsfenster ab. Wie in der obigen Abbildung gezeigt, befindet sich STRING2 vollständig im Beschneidungsfenster, sodass wir es behalten und STRING1 nur teilweise im Fenster ist, was wir ablehnen.
Die folgende Abbildung zeigt alle oder keine Zeichenausschnitte -
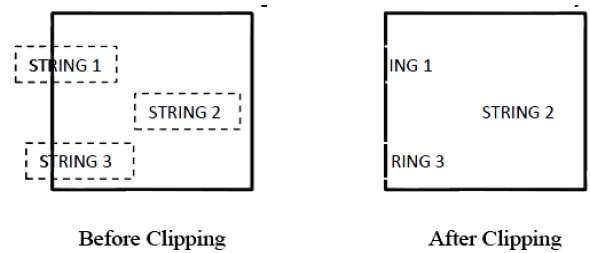
Diese Beschneidungsmethode basiert eher auf Zeichen als auf der gesamten Zeichenfolge. Wenn sich die Zeichenfolge bei dieser Methode vollständig im Beschneidungsfenster befindet, behalten wir sie bei. Wenn es teilweise außerhalb des Fensters ist, dann -
Sie lehnen nur den Teil der Zeichenfolge ab, der sich außerhalb befindet
Befindet sich das Zeichen an der Grenze des Beschneidungsfensters, verwerfen wir das gesamte Zeichen und behalten die restliche Zeichenfolge bei.
Die folgende Abbildung zeigt Textausschnitte -
Diese Beschneidungsmethode basiert eher auf Zeichen als auf der gesamten Zeichenfolge. Wenn sich die Zeichenfolge bei dieser Methode vollständig im Beschneidungsfenster befindet, behalten wir sie bei. Wenn es sich teilweise außerhalb des Fensters befindet, dann
Sie lehnen nur den Teil der Zeichenfolge ab, der sich außerhalb befindet.
Befindet sich das Zeichen an der Grenze des Beschneidungsfensters, verwerfen wir nur den Teil des Zeichens, der sich außerhalb des Beschneidungsfensters befindet.
Bitmap-Grafiken
Eine Bitmap ist eine Sammlung von Pixeln, die ein Bild beschreiben. Es handelt sich um eine Art Computergrafik, mit der der Computer Bilder speichert und anzeigt. Bei dieser Art von Grafiken werden Bilder Stück für Stück gespeichert und daher als Bitmap-Grafik bezeichnet. Betrachten wir zum besseren Verständnis das folgende Beispiel, in dem wir ein Smiley mit Bitmap-Grafiken zeichnen.

Jetzt werden wir sehen, wie dieses Smiley-Gesicht Stück für Stück in der Computergrafik gespeichert wird.
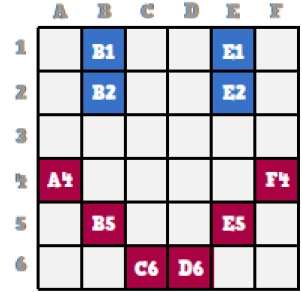
Wenn wir das ursprüngliche Smiley-Gesicht genau betrachten, können wir sehen, dass es zwei blaue Linien gibt, die in der obigen Abbildung als B1, B2 und E1, E2 dargestellt sind.
Auf die gleiche Weise wird der Smiley unter Verwendung der Kombinationsbits von A4, B5, C6, D6, E5 bzw. F4 dargestellt.
Die Hauptnachteile von Bitmap-Grafiken sind -
Wir können die Größe des Bitmap-Bildes nicht ändern. Wenn Sie versuchen, die Größe zu ändern, werden die Pixel unscharf.
Farbige Bitmaps können sehr groß sein.
Transformation bedeutet, einige Grafiken durch Anwenden von Regeln in etwas anderes zu verwandeln. Wir können verschiedene Arten von Transformationen durchführen, z. B. Translation, Skalieren oder Verkleinern, Drehen, Scheren usw. Wenn eine Transformation in einer 2D-Ebene stattfindet, wird sie als 2D-Transformation bezeichnet.
Transformationen spielen in der Computergrafik eine wichtige Rolle, um die Grafiken auf dem Bildschirm neu zu positionieren und ihre Größe oder Ausrichtung zu ändern.
Homogene Koordinaten
Um eine Transformationssequenz wie Translation gefolgt von Rotation und Skalierung durchzuführen, müssen wir einem sequentiellen Prozess folgen -
- Übersetzen Sie die Koordinaten,
- Drehen Sie die übersetzten Koordinaten und dann
- Skalieren Sie die gedrehten Koordinaten, um die zusammengesetzte Transformation abzuschließen.
Um diesen Prozess zu verkürzen, müssen wir eine 3 × 3-Transformationsmatrix anstelle einer 2 × 2-Transformationsmatrix verwenden. Um eine 2 × 2-Matrix in eine 3 × 3-Matrix umzuwandeln, müssen wir eine zusätzliche Dummy-Koordinate W hinzufügen.
Auf diese Weise können wir den Punkt durch 3 Zahlen anstelle von 2 Zahlen darstellen, was aufgerufen wird Homogenous CoordinateSystem. In diesem System können wir alle Transformationsgleichungen in der Matrixmultiplikation darstellen. Jeder kartesische Punkt P (X, Y) kann durch P '(X h , Y h , h) in homogene Koordinaten umgewandelt werden .
Übersetzung
Eine Übersetzung verschiebt ein Objekt an eine andere Position auf dem Bildschirm. Sie können einen Punkt in 2D übersetzen, indem Sie der ursprünglichen Koordinate (X, Y) eine Übersetzungskoordinate (t x , t y ) hinzufügen , um die neue Koordinate (X ', Y') zu erhalten.
Aus der obigen Abbildung können Sie Folgendes schreiben:
X’ = X + tx
Y’ = Y + ty
Das Paar (t x , t y ) wird als Translationsvektor oder Verschiebungsvektor bezeichnet. Die obigen Gleichungen können auch unter Verwendung der Spaltenvektoren dargestellt werden.
$P = \frac{[X]}{[Y]}$ p '= $\frac{[X']}{[Y']}$T = $\frac{[t_{x}]}{[t_{y}]}$
Wir können es schreiben als -
P’ = P + T
Drehung
Bei der Drehung drehen wir das Objekt um einen bestimmten Winkel θ (Theta) von seinem Ursprung. Aus der folgenden Abbildung ist ersichtlich, dass der Punkt P (X, Y) im Winkel φ von der horizontalen X-Koordinate mit dem Abstand r vom Ursprung liegt.
Nehmen wir an, Sie möchten es um den Winkel θ drehen. Nachdem Sie es an eine neue Position gedreht haben, erhalten Sie einen neuen Punkt P '(X', Y ').

Unter Verwendung der Standardtrigonometrie kann die ursprüngliche Koordinate des Punktes P (X, Y) als - dargestellt werden
$X = r \, cos \, \phi ...... (1)$
$Y = r \, sin \, \phi ...... (2)$
Genauso können wir den Punkt P '(X', Y ') darstellen als -
${x}'= r \: cos \: \left ( \phi \: + \: \theta \right ) = r\: cos \: \phi \: cos \: \theta \: − \: r \: sin \: \phi \: sin \: \theta ....... (3)$
${y}'= r \: sin \: \left ( \phi \: + \: \theta \right ) = r\: cos \: \phi \: sin \: \theta \: + \: r \: sin \: \phi \: cos \: \theta ....... (4)$
Wenn wir die Gleichungen (1) und (2) in (3) und (4) einsetzen, erhalten wir
${x}'= x \: cos \: \theta − \: y \: sin \: \theta $
${y}'= x \: sin \: \theta + \: y \: cos \: \theta $
Darstellung der obigen Gleichung in Matrixform,
$$[X' Y'] = [X Y] \begin{bmatrix} cos\theta & sin\theta \\ −sin\theta & cos\theta \end{bmatrix}OR $$
P '= P ∙ R.
Wobei R die Rotationsmatrix ist
$$R = \begin{bmatrix} cos\theta & sin\theta \\ −sin\theta & cos\theta \end{bmatrix}$$
Der Drehwinkel kann positiv und negativ sein.
Für einen positiven Drehwinkel können wir die obige Drehmatrix verwenden. Bei einer Drehung mit negativem Winkel ändert sich die Matrix jedoch wie unten gezeigt -
$$R = \begin{bmatrix} cos(−\theta) & sin(−\theta) \\ -sin(−\theta) & cos(−\theta) \end{bmatrix}$$
$$=\begin{bmatrix} cos\theta & −sin\theta \\ sin\theta & cos\theta \end{bmatrix} \left (\because cos(−\theta ) = cos \theta \; and\; sin(−\theta ) = −sin \theta \right )$$
Skalierung
Um die Größe eines Objekts zu ändern, wird die Skalierungstransformation verwendet. Während des Skalierungsprozesses erweitern oder komprimieren Sie die Abmessungen des Objekts. Die Skalierung kann erreicht werden, indem die ursprünglichen Koordinaten des Objekts mit dem Skalierungsfaktor multipliziert werden, um das gewünschte Ergebnis zu erhalten.
Nehmen wir an, dass die ursprünglichen Koordinaten (X, Y), die Skalierungsfaktoren (S X , S Y ) und die erzeugten Koordinaten (X ', Y') sind. Dies kann mathematisch wie unten dargestellt dargestellt werden -
X' = X . SX and Y' = Y . SY
Der Skalierungsfaktor S X , S Y skaliert das Objekt in X- bzw. Y-Richtung. Die obigen Gleichungen können auch in Matrixform wie folgt dargestellt werden:
$$\binom{X'}{Y'} = \binom{X}{Y} \begin{bmatrix} S_{x} & 0\\ 0 & S_{y} \end{bmatrix}$$
ODER
P’ = P . S
Wobei S die Skalierungsmatrix ist. Der Skalierungsprozess ist in der folgenden Abbildung dargestellt.
Wenn wir dem Skalierungsfaktor S Werte unter 1 geben, können wir die Größe des Objekts reduzieren. Wenn wir Werte größer als 1 angeben, können wir die Größe des Objekts erhöhen.
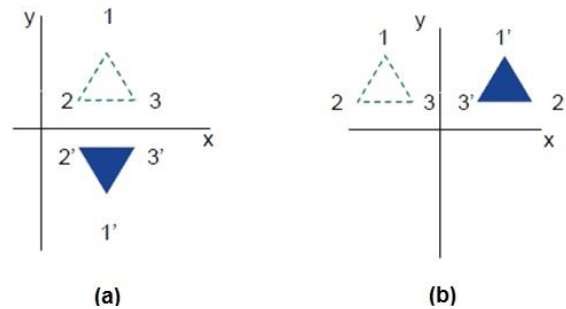
Reflexion
Reflexion ist das Spiegelbild des Originalobjekts. Mit anderen Worten können wir sagen, dass es sich um eine Rotationsoperation mit 180 ° handelt. Bei der Reflexionstransformation ändert sich die Größe des Objekts nicht.
Die folgenden Abbildungen zeigen Reflexionen in Bezug auf die X- und Y-Achse bzw. über den Ursprung.
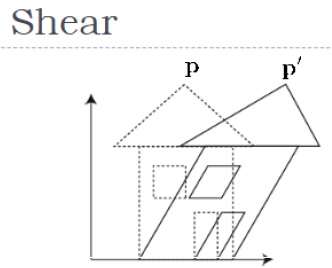
Scheren
Eine Transformation, die die Form eines Objekts neigt, wird als Schertransformation bezeichnet. Es gibt zwei ScherumwandlungenX-Shear und Y-Shear. Man verschiebt X-Koordinatenwerte und andere verschiebt Y-Koordinatenwerte. Jedoch; In beiden Fällen ändert nur eine Koordinate ihre Koordinaten und die andere behält ihre Werte bei. Scheren wird auch als bezeichnetSkewing.
X-Shear
Die X-Scherung behält die Y-Koordinate bei und es werden Änderungen an den X-Koordinaten vorgenommen, wodurch die vertikalen Linien nach rechts oder links geneigt werden (siehe Abbildung unten).
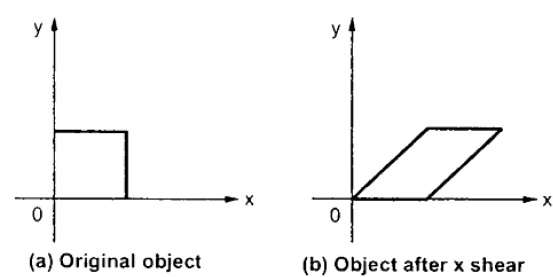
Die Transformationsmatrix für X-Shear kann wie folgt dargestellt werden:
$$X_{sh} = \begin{bmatrix} 1& shx& 0\\ 0& 1& 0\\ 0& 0& 1 \end{bmatrix}$$
Y '= Y + Sh y . X.
X '= X.
Y-Shear
Die Y-Scherung behält die X-Koordinaten bei und ändert die Y-Koordinaten, wodurch sich die horizontalen Linien in Linien verwandeln, die wie in der folgenden Abbildung gezeigt nach oben oder unten geneigt sind.
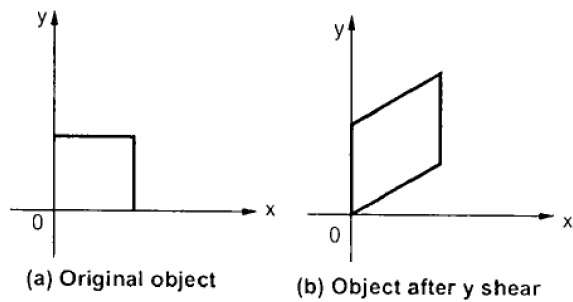
Die Y-Scherung kann in der Matrix dargestellt werden als -
$$Y_{sh} \begin{bmatrix} 1& 0& 0\\ shy& 1& 0\\ 0& 0& 1 \end{bmatrix}$$
X '= X + Sh x . Y.
Y '= Y.
Zusammengesetzte Transformation
Wenn auf eine Transformation der Ebene T1 eine Transformation der zweiten Ebene T2 folgt, kann das Ergebnis selbst durch eine einzelne Transformation T dargestellt werden, die die Zusammensetzung von T1 und T2 in dieser Reihenfolge darstellt. Dies wird geschrieben als T = T1 ∙ T2.
Eine zusammengesetzte Transformation kann durch Verketten von Transformationsmatrizen erreicht werden, um eine kombinierte Transformationsmatrix zu erhalten.
Eine kombinierte Matrix -
[T][X] = [X] [T1] [T2] [T3] [T4] …. [Tn]
Wobei [Ti] eine beliebige Kombination von ist
- Translation
- Scaling
- Shearing
- Rotation
- Reflection
Die Änderung der Transformationsreihenfolge würde zu unterschiedlichen Ergebnissen führen, da die Matrixmultiplikation im Allgemeinen nicht kumulativ ist, dh [A]. [B] ≠ [B]. [A] und die Reihenfolge der Multiplikation. Der Hauptzweck des Zusammenstellens von Transformationen besteht darin, Effizienz zu erzielen, indem eine einzelne zusammengesetzte Transformation auf einen Punkt angewendet wird, anstatt eine Reihe von Transformationen nacheinander anzuwenden.
Um beispielsweise ein Objekt um einen beliebigen Punkt (X p , Y p ) zu drehen , müssen drei Schritte ausgeführt werden:
- Verschieben Sie den Punkt (X p , Y p ) in den Ursprung.
- Drehen Sie es um den Ursprung.
- Verschieben Sie schließlich das Rotationszentrum dorthin zurück, wo es hingehört.
Im 2D-System verwenden wir nur zwei Koordinaten X und Y, in 3D wird jedoch eine zusätzliche Koordinate Z hinzugefügt. 3D-Grafiktechniken und ihre Anwendung sind für die Unterhaltungs-, Spiele- und computergestützte Designbranche von grundlegender Bedeutung. Es ist ein fortlaufendes Forschungsgebiet in der wissenschaftlichen Visualisierung.
Darüber hinaus sind 3D-Grafikkomponenten mittlerweile Teil fast jedes PCs und werden, obwohl sie traditionell für grafikintensive Software wie Spiele gedacht sind, zunehmend von anderen Anwendungen verwendet.
Parallele Projektion
Parallele Projektion verwirft Z-Koordinaten und parallele Linien von jedem Scheitelpunkt auf dem Objekt werden verlängert, bis sie die Ansichtsebene schneiden. Bei der Parallelprojektion geben wir eine Projektionsrichtung anstelle des Projektionszentrums an.
Bei der Parallelprojektion ist der Abstand vom Projektionszentrum zur Projektebene unendlich. Bei dieser Art der Projektion verbinden wir die projizierten Scheitelpunkte durch Liniensegmente, die Verbindungen auf dem ursprünglichen Objekt entsprechen.
Parallele Projektionen sind weniger realistisch, eignen sich jedoch für genaue Messungen. Bei dieser Art von Projektionen bleiben parallele Linien parallel und Winkel bleiben nicht erhalten. In der folgenden Hierarchie werden verschiedene Arten von parallelen Projektionen gezeigt.
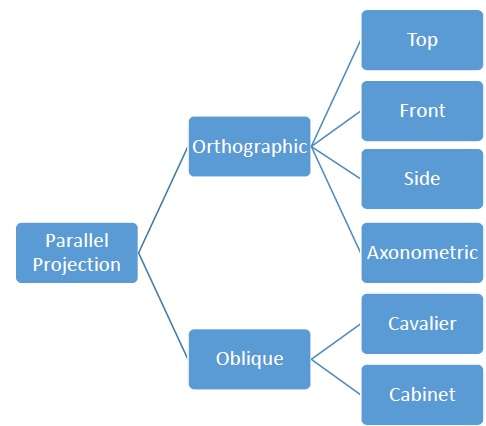
Orthographische Projektion
Bei der orthografischen Projektion ist die Projektionsrichtung normal zur Projektion der Ebene. Es gibt drei Arten von orthografischen Projektionen:
- Frontprojektion
- Top Projektion
- Seitenprojektion
Schrägprojektion
Bei der Schrägprojektion ist die Projektionsrichtung nicht normal zur Projektion der Ebene. Bei der Schrägprojektion können wir das Objekt besser betrachten als bei der orthografischen Projektion.
Es gibt zwei Arten von Schrägprojektionen - Cavalier und Cabinet. Die Cavalier-Projektion bildet mit der Projektionsebene einen Winkel von 45 °. Die Projektion einer Linie senkrecht zur Ansichtsebene hat die gleiche Länge wie die Linie selbst in der Cavalier-Projektion. In einer Kavalierprojektion sind die Verkürzungsfaktoren für alle drei Hauptrichtungen gleich.
Die Schrankprojektion bildet mit der Projektionsebene einen Winkel von 63,4 °. Bei der Schrankprojektion werden Linien senkrecht zur Betrachtungsfläche auf die Hälfte ihrer tatsächlichen Länge projiziert. Beide Projektionen sind in der folgenden Abbildung dargestellt -

Isometrische Projektionen
Orthografische Projektionen, die mehr als eine Seite eines Objekts zeigen, werden aufgerufen axonometric orthographic projections. Die häufigste axonometrische Projektion ist eineisometric projectionwobei die Projektionsebene jede Koordinatenachse im Modellkoordinatensystem in gleichem Abstand schneidet. In dieser Projektion bleibt die Parallelität der Linien erhalten, die Winkel jedoch nicht. Die folgende Abbildung zeigt die isometrische Projektion -

Perspektivische Projektion
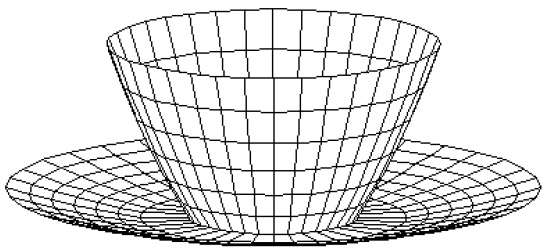
Bei der perspektivischen Projektion ist der Abstand vom Projektionszentrum zur Projektebene endlich und die Größe des Objekts ändert sich umgekehrt zum Abstand, der realistischer aussieht.
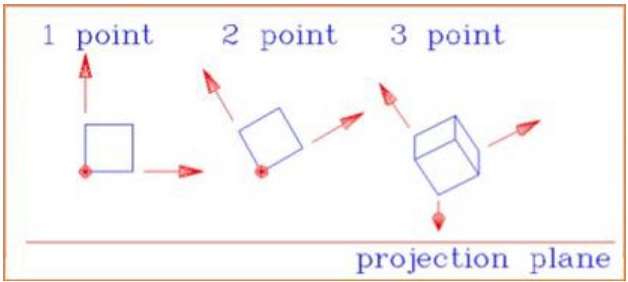
Der Abstand und die Winkel bleiben nicht erhalten und parallele Linien bleiben nicht parallel. Stattdessen konvergieren sie alle an einem einzigen Punkt, der aufgerufen wirdcenter of projection oder projection reference point. Es gibt 3 Arten von perspektivischen Projektionen, die in der folgenden Tabelle dargestellt sind.
One point Die perspektivische Projektion ist einfach zu zeichnen.
Two point Die perspektivische Projektion vermittelt einen besseren Eindruck von der Tiefe.
Three point Perspektivische Projektion ist am schwierigsten zu zeichnen.
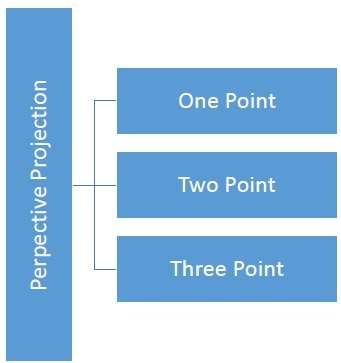
Die folgende Abbildung zeigt alle drei Arten der perspektivischen Projektion -
Übersetzung
Bei der 3D-Übersetzung übertragen wir die Z-Koordinate zusammen mit den X- und Y-Koordinaten. Der Prozess für die Übersetzung in 3D ähnelt der 2D-Übersetzung. Eine Übersetzung verschiebt ein Objekt an eine andere Position auf dem Bildschirm.
Die folgende Abbildung zeigt den Effekt der Übersetzung -
Ein Punkt kann durch Hinzufügen einer Übersetzungskoordinate in 3D übersetzt werden $(t_{x,} t_{y,} t_{z})$ auf die ursprüngliche Koordinate (X, Y, Z), um die neue Koordinate (X ', Y', Z ') zu erhalten.
$T = \begin{bmatrix} 1& 0& 0& 0\\ 0& 1& 0& 0\\ 0& 0& 1& 0\\ t_{x}& t_{y}& t_{z}& 1\\ \end{bmatrix}$
P '= P ∙ T.
$[X′ \:\: Y′ \:\: Z′ \:\: 1] \: = \: [X \:\: Y \:\: Z \:\: 1] \: \begin{bmatrix} 1& 0& 0& 0\\ 0& 1& 0& 0\\ 0& 0& 1& 0\\ t_{x}& t_{y}& t_{z}& 1\\ \end{bmatrix}$
$= [X + t_{x} \:\:\: Y + t_{y} \:\:\: Z + t_{z} \:\:\: 1]$
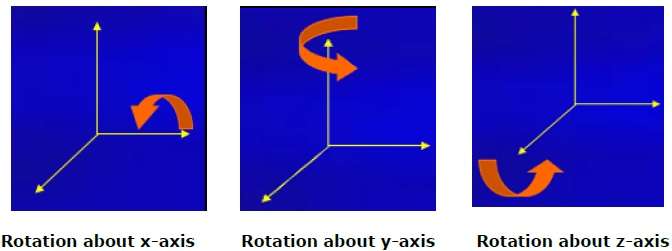
Drehung
3D-Rotation ist nicht dasselbe wie 2D-Rotation. Bei der 3D-Drehung müssen wir den Drehwinkel zusammen mit der Drehachse angeben. Wir können eine 3D-Drehung um die X-, Y- und Z-Achse durchführen. Sie werden in der Matrixform wie folgt dargestellt -
$$R_{x}(\theta) = \begin{bmatrix} 1& 0& 0& 0\\ 0& cos\theta & −sin\theta& 0\\ 0& sin\theta & cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix} R_{y}(\theta) = \begin{bmatrix} cos\theta& 0& sin\theta& 0\\ 0& 1& 0& 0\\ −sin\theta& 0& cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix} R_{z}(\theta) =\begin{bmatrix} cos\theta & −sin\theta & 0& 0\\ sin\theta & cos\theta & 0& 0\\ 0& 0& 1& 0\\ 0& 0& 0& 1 \end{bmatrix}$$
Die folgende Abbildung erklärt die Drehung um verschiedene Achsen -
Skalierung
Sie können die Größe eines Objekts mithilfe der Skalierungstransformation ändern. Während des Skalierungsprozesses erweitern oder komprimieren Sie die Abmessungen des Objekts. Die Skalierung kann erreicht werden, indem die ursprünglichen Koordinaten des Objekts mit dem Skalierungsfaktor multipliziert werden, um das gewünschte Ergebnis zu erhalten. Die folgende Abbildung zeigt den Effekt der 3D-Skalierung -
Bei der 3D-Skalierung werden drei Koordinaten verwendet. Nehmen wir an, dass die ursprünglichen Koordinaten (X, Y, Z) und Skalierungsfaktoren sind$(S_{X,} S_{Y,} S_{z})$und die erzeugten Koordinaten sind (X ', Y', Z '). Dies kann mathematisch wie unten dargestellt dargestellt werden -
$S = \begin{bmatrix} S_{x}& 0& 0& 0\\ 0& S_{y}& 0& 0\\ 0& 0& S_{z}& 0\\ 0& 0& 0& 1 \end{bmatrix}$
P '= P ∙ S.
$[{X}' \:\:\: {Y}' \:\:\: {Z}' \:\:\: 1] = [X \:\:\:Y \:\:\: Z \:\:\: 1] \:\: \begin{bmatrix} S_{x}& 0& 0& 0\\ 0& S_{y}& 0& 0\\ 0& 0& S_{z}& 0\\ 0& 0& 0& 1 \end{bmatrix}$
$ = [X.S_{x} \:\:\: Y.S_{y} \:\:\: Z.S_{z} \:\:\: 1]$
Scheren
Eine Transformation, die die Form eines Objekts neigt, wird als bezeichnet shear transformation. Wie bei der 2D-Scherung können wir ein Objekt entlang der X-Achse, Y-Achse oder Z-Achse in 3D scheren.
Wie in der obigen Abbildung gezeigt, gibt es eine Koordinate P. Sie können sie scheren, um eine neue Koordinate P 'zu erhalten, die in 3D-Matrixform wie folgt dargestellt werden kann:
$Sh = \begin{bmatrix} 1 & sh_{x}^{y} & sh_{x}^{z} & 0 \\ sh_{y}^{x} & 1 & sh_{y}^{z} & 0 \\ sh_{z}^{x} & sh_{z}^{y} & 1 & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}$
P '= P ∙ Sh
$X’ = X + Sh_{x}^{y} Y + Sh_{x}^{z} Z$
$Y' = Sh_{y}^{x}X + Y +sh_{y}^{z}Z$
$Z' = Sh_{z}^{x}X + Sh_{z}^{y}Y + Z$
Transformationsmatrizen
Die Transformationsmatrix ist ein grundlegendes Werkzeug für die Transformation. Eine Matrix mit nxm Dimensionen wird mit der Koordinate von Objekten multipliziert. Normalerweise werden 3 x 3 oder 4 x 4 Matrizen zur Transformation verwendet. Betrachten Sie beispielsweise die folgende Matrix für verschiedene Operationen.
| $T = \begin{bmatrix} 1& 0& 0& 0\\ 0& 1& 0& 0\\ 0& 0& 1& 0\\ t_{x}& t_{y}& t_{z}& 1\\ \end{bmatrix}$ | $S = \begin{bmatrix} S_{x}& 0& 0& 0\\ 0& S_{y}& 0& 0\\ 0& 0& S_{z}& 0\\ 0& 0& 0& 1 \end{bmatrix}$ | $Sh = \begin{bmatrix} 1& sh_{x}^{y}& sh_{x}^{z}& 0\\ sh_{y}^{x}& 1 & sh_{y}^{z}& 0\\ sh_{z}^{x}& sh_{z}^{y}& 1& 0\\ 0& 0& 0& 1 \end{bmatrix}$ |
| Translation Matrix | Scaling Matrix | Shear Matrix |
| $R_{x}(\theta) = \begin{bmatrix} 1& 0& 0& 0\\ 0& cos\theta & -sin\theta& 0\\ 0& sin\theta & cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix}$ | $R_{y}(\theta) = \begin{bmatrix} cos\theta& 0& sin\theta& 0\\ 0& 1& 0& 0\\ -sin\theta& 0& cos\theta& 0\\ 0& 0& 0& 1\\ \end{bmatrix}$ | $R_{z}(\theta) = \begin{bmatrix} cos\theta & -sin\theta & 0& 0\\ sin\theta & cos\theta & 0& 0\\ 0& 0& 1& 0\\ 0& 0& 0& 1 \end{bmatrix}$ |
| Rotation Matrix | ||
In der Computergrafik müssen wir oft verschiedene Arten von Objekten auf den Bildschirm zeichnen. Objekte sind nicht immer flach und wir müssen viele Male Kurven zeichnen, um ein Objekt zu zeichnen.
Arten von Kurven
Eine Kurve ist eine unendlich große Menge von Punkten. Jeder Punkt hat zwei Nachbarn außer Endpunkten. Kurven können grob in drei Kategorien eingeteilt werden -explicit, implicit, und parametric curves.
Implizite Kurven
Implizite Kurvendarstellungen definieren die Menge der Punkte auf einer Kurve mithilfe eines Verfahrens, mit dem geprüft werden kann, ob ein Punkt auf der Kurve liegt. Normalerweise wird eine implizite Kurve durch eine implizite Funktion der Form definiert -
f (x, y) = 0
Es kann mehrwertige Kurven darstellen (mehrere y-Werte für einen x-Wert). Ein häufiges Beispiel ist der Kreis, dessen implizite Darstellung ist
x2 + y2 - R2 = 0
Explizite Kurven
Eine mathematische Funktion y = f (x) kann als Kurve aufgetragen werden. Eine solche Funktion ist die explizite Darstellung der Kurve. Die explizite Darstellung ist nicht allgemein, da sie keine vertikalen Linien darstellen kann und auch einwertig ist. Für jeden Wert von x wird normalerweise nur ein einziger Wert von y von der Funktion berechnet.
Parametrische Kurven
Kurven mit parametrischer Form werden als parametrische Kurven bezeichnet. Die expliziten und impliziten Kurvendarstellungen können nur verwendet werden, wenn die Funktion bekannt ist. In der Praxis werden die Parameterkurven verwendet. Eine zweidimensionale Parameterkurve hat die folgende Form:
P (t) = f (t), g (t) oder P (t) = x (t), y (t)
Die Funktionen f und g werden zu den (x, y) -Koordinaten eines beliebigen Punktes auf der Kurve, und die Punkte werden erhalten, wenn der Parameter t über ein bestimmtes Intervall [a, b] variiert wird, normalerweise [0, 1].
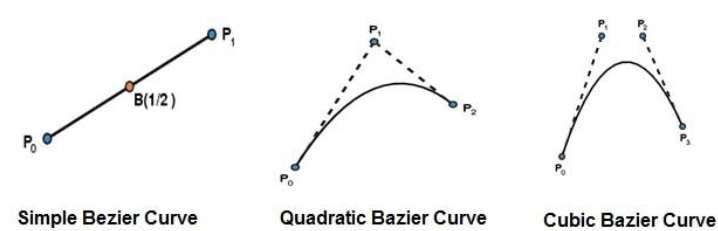
Bezierkurven
Die Bezier-Kurve wird vom französischen Ingenieur entdeckt Pierre Bézier. Diese Kurven können unter der Kontrolle anderer Punkte erzeugt werden. Ungefähre Tangenten unter Verwendung von Kontrollpunkten werden verwendet, um eine Kurve zu erzeugen. Die Bezier-Kurve kann mathematisch dargestellt werden als -
$$\sum_{k=0}^{n} P_{i}{B_{i}^{n}}(t)$$
Wo $p_{i}$ ist die Menge der Punkte und ${B_{i}^{n}}(t)$ stellt die Bernstein-Polynome dar, die gegeben sind durch -
$${B_{i}^{n}}(t) = \binom{n}{i} (1 - t)^{n-i}t^{i}$$
Wo n ist der Polynomgrad, i ist der Index und t ist die Variable.
Die einfachste Bézier-Kurve ist die gerade Linie vom Punkt $P_{0}$ zu $P_{1}$. Eine quadratische Bezier-Kurve wird durch drei Kontrollpunkte bestimmt. Eine kubische Bezier-Kurve wird durch vier Kontrollpunkte bestimmt.
Eigenschaften von Bezierkurven
Bezierkurven haben folgende Eigenschaften:
Sie folgen im Allgemeinen der Form des Steuerpolygons, das aus den Segmenten besteht, die die Steuerpunkte verbinden.
Sie passieren immer den ersten und den letzten Kontrollpunkt.
Sie sind in der konvexen Hülle ihrer definierenden Kontrollpunkte enthalten.
Der Grad des Polynoms, das das Kurvensegment definiert, ist eins weniger als die Anzahl der definierenden Polygonpunkte. Daher beträgt für 4 Kontrollpunkte der Grad des Polynoms 3, dh das kubische Polynom.
Eine Bezier-Kurve folgt im Allgemeinen der Form des definierenden Polygons.
Die Richtung des Tangentenvektors an den Endpunkten ist dieselbe wie die des Vektors, der durch das erste und das letzte Segment bestimmt wird.
Die konvexe Hülleneigenschaft für eine Bezier-Kurve stellt sicher, dass das Polynom den Kontrollpunkten reibungslos folgt.
Keine gerade Linie schneidet eine Bezier-Kurve öfter als ihr Steuerpolygon.
Sie sind unter einer affinen Transformation unveränderlich.
Bezier-Kurven weisen globale Steuerungsmittel auf. Durch Bewegen eines Kontrollpunkts wird die Form der gesamten Kurve geändert.
Eine gegebene Bezier-Kurve kann an einem Punkt t = t0 in zwei Bezier-Segmente unterteilt werden, die sich an dem Punkt verbinden, der dem Parameterwert t = t0 entspricht.
B-Spline-Kurven
Die von der Bernstein-Basisfunktion erzeugte Bezier-Kurve weist eine begrenzte Flexibilität auf.
Erstens legt die Anzahl der angegebenen Polygonscheitelpunkte die Reihenfolge des resultierenden Polynoms fest, das die Kurve definiert.
Das zweite begrenzende Merkmal ist, dass der Wert der Mischfunktion für alle Parameterwerte über die gesamte Kurve ungleich Null ist.
Die B-Spline-Basis enthält als Sonderfall die Bernstein-Basis. Die B-Spline-Basis ist nicht global.
Eine B-Spline-Kurve ist definiert als eine lineare Kombination der Kontrollpunkte Pi und der B-Spline-Basisfunktion $N_{i,}$ k (t) gegeben durch
$C(t) = \sum_{i=0}^{n}P_{i}N_{i,k}(t),$ $n\geq k-1,$ $t\: \epsilon \: [ tk-1,tn+1 ]$
Wo,
{$p_{i}$: i = 0, 1, 2… .n} sind die Kontrollpunkte
k ist die Reihenfolge der Polynomsegmente der B-Spline-Kurve. Ordnung k bedeutet, dass die Kurve aus stückweisen Polynomsegmenten vom Grad k - 1 besteht.
das $N_{i,k}(t)$sind die "normalisierten B-Spline-Mischfunktionen". Sie werden durch die Ordnung k und durch eine nicht abnehmende Folge von reellen Zahlen beschrieben, die normalerweise als "Knotenfolge" bezeichnet wird.
$${t_{i}:i = 0, ... n + K}$$
Die N i , k Funktionen werden wie folgt beschrieben:
$$N_{i,1}(t) = \left\{\begin{matrix} 1,& if \:u \: \epsilon \: [t_{i,}t_{i+1}) \\ 0,& Otherwise \end{matrix}\right.$$
und wenn k> 1 ist,
$$N_{i,k}(t) = \frac{t-t_{i}}{t_{i+k-1}} N_{i,k-1}(t) + \frac{t_{i+k}-t}{t_{i+k} - t_{i+1}} N_{i+1,k-1}(t)$$
und
$$t \: \epsilon \: [t_{k-1},t_{n+1})$$
Eigenschaften der B-Spline-Kurve
B-Spline-Kurven haben die folgenden Eigenschaften:
Die Summe der B-Spline-Basisfunktionen für jeden Parameterwert ist 1.
Jede Basisfunktion ist für alle Parameterwerte positiv oder Null.
Jede Basisfunktion hat bis auf k = 1 genau einen Maximalwert.
Die maximale Reihenfolge der Kurve entspricht der Anzahl der Eckpunkte des definierenden Polygons.
Der Grad des B-Spline-Polynoms ist unabhängig von der Anzahl der Eckpunkte des definierenden Polygons.
B-Spline ermöglicht die lokale Steuerung der Kurvenoberfläche, da jeder Scheitelpunkt die Form einer Kurve nur über einen Bereich von Parameterwerten beeinflusst, bei denen die zugehörige Basisfunktion ungleich Null ist.
Die Kurve zeigt die Variation verringernde Eigenschaft.
Die Kurve folgt im Allgemeinen der Form des definierenden Polygons.
Jede affine Transformation kann auf die Kurve angewendet werden, indem sie auf die Eckpunkte des definierenden Polygons angewendet wird.
Die Kurvenlinie innerhalb der konvexen Hülle des definierenden Polygons.
Polygonoberflächen
Objekte werden als Sammlung von Oberflächen dargestellt. Die 3D-Objektdarstellung ist in zwei Kategorien unterteilt.
Boundary Representations (B-reps) - Es beschreibt ein 3D-Objekt als eine Reihe von Oberflächen, die das Objektinnere von der Umgebung trennen.
Space–partitioning representations - Es wird verwendet, um innere Eigenschaften zu beschreiben, indem der räumliche Bereich, der ein Objekt enthält, in eine Reihe kleiner, nicht überlappender, zusammenhängender Körper (normalerweise Würfel) unterteilt wird.
Die am häufigsten verwendete Grenzdarstellung für ein 3D-Grafikobjekt ist eine Reihe von Oberflächenpolygonen, die das Objektinnere einschließen. Viele Grafiksysteme verwenden diese Methode. Polygonsätze werden zur Objektbeschreibung gespeichert. Dies vereinfacht und beschleunigt das Rendern und Anzeigen von Objekten auf der Oberfläche, da alle Oberflächen mit linearen Gleichungen beschrieben werden können.
Die Polygonoberflächen sind in Entwurfs- und Volumenmodellierungsanwendungen üblich, da sie wireframe displaykann schnell durchgeführt werden, um einen allgemeinen Hinweis auf die Oberflächenstruktur zu geben. Dann werden realistische Szenen erzeugt, indem Schattierungsmuster über die Polygonoberfläche interpoliert werden, um sie zu beleuchten.
Polygontabellen
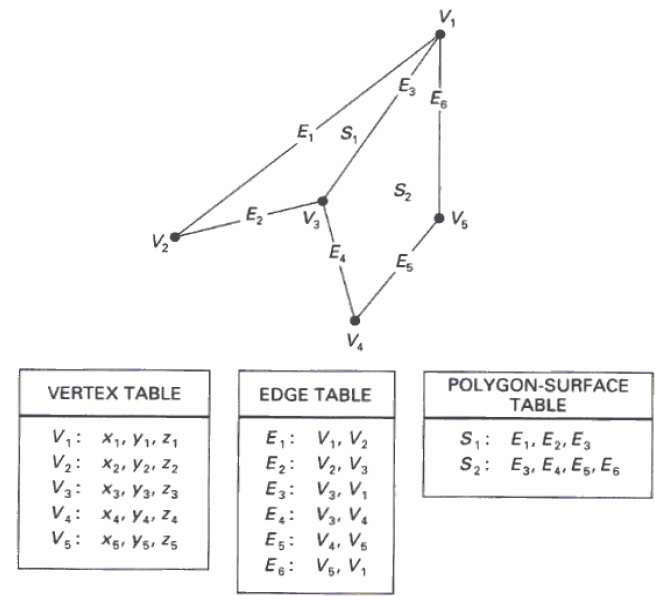
Bei dieser Methode wird die Oberfläche durch den Satz von Scheitelpunktkoordinaten und zugehörigen Attributen angegeben. Wie in der folgenden Abbildung gezeigt, gibt es fünf Eckpunkte von v 1 bis v 5 .
Jeder Scheitelpunkt speichert x-, y- und z-Koordinateninformationen, die in der Tabelle als v 1 dargestellt sind : x 1 , y 1 , z 1 .
In der Kantentabelle werden die Kanteninformationen des Polygons gespeichert. In der folgenden Figur liegt die Kante E 1 zwischen dem Scheitelpunkt v 1 und v 2, der in der Tabelle als E 1 dargestellt ist : v 1 , v 2 .
In der Polygonoberflächentabelle wird die Anzahl der im Polygon vorhandenen Flächen gespeichert. Aus der folgenden Abbildung geht hervor, dass die Oberfläche S 1 von den Kanten E 1 , E 2 und E 3 bedeckt ist, die in der Polygonoberflächentabelle als S 1 dargestellt werden können : E 1 , E 2 und E 3 .
Flugzeuggleichungen
Die Gleichung für die ebene Oberfläche kann ausgedrückt werden als -
Axe + By + Cz + D = 0
Wobei (x, y, z) ein beliebiger Punkt in der Ebene ist und die Koeffizienten A, B, C und D Konstanten sind, die die räumlichen Eigenschaften der Ebene beschreiben. Wir können die Werte von A, B, C und D erhalten, indem wir einen Satz von drei Ebenengleichungen unter Verwendung der Koordinatenwerte für drei nicht kollineare Punkte in der Ebene lösen. Nehmen wir an, dass drei Eckpunkte der Ebene (x 1 , y 1 , z 1 ), (x 2 , y 2 , z 2 ) und (x 3 , y 3 , z 3 ) sind.
Lösen wir die folgenden simultanen Gleichungen für die Verhältnisse A / D, B / D und C / D. Sie erhalten die Werte von A, B, C und D.
(A / D) x 1 + (B / D) y 1 + (C / D) z 1 = -1
(A / D) x 2 + (B / D) y 2 + (C / D) z 2 = -1
(A / D) x 3 + (B / D) y 3 + (C / D) z 3 = -1
Um die obigen Gleichungen in Determinantenform zu erhalten, wenden Sie die Cramer-Regel auf die obigen Gleichungen an.
$A = \begin{bmatrix} 1& y_{1}& z_{1}\\ 1& y_{2}& z_{2}\\ 1& y_{3}& z_{3} \end{bmatrix} B = \begin{bmatrix} x_{1}& 1& z_{1}\\ x_{2}& 1& z_{2}\\ x_{3}& 1& z_{3} \end{bmatrix} C = \begin{bmatrix} x_{1}& y_{1}& 1\\ x_{2}& y_{2}& 1\\ x_{3}& y_{3}& 1 \end{bmatrix} D = - \begin{bmatrix} x_{1}& y_{1}& z_{1}\\ x_{2}& y_{2}& z_{2}\\ x_{3}& y_{3}& z_{3} \end{bmatrix}$
Für jeden Punkt (x, y, z) mit den Parametern A, B, C und D können wir sagen, dass -
Ax + By + Cz + D ≠ 0 bedeutet, dass der Punkt nicht auf der Ebene liegt.
Axe + By + Cz + D <0 bedeutet, dass sich der Punkt innerhalb der Oberfläche befindet.
Ax + By + Cz + D> 0 bedeutet, dass sich der Punkt außerhalb der Oberfläche befindet.
Polygonnetze
3D-Oberflächen und Volumenkörper können durch eine Reihe von Polygon- und Linienelementen angenähert werden. Solche Oberflächen werden genanntpolygonal meshes. Im Polygonnetz wird jede Kante von höchstens zwei Polygonen geteilt. Die Menge der Polygone oder Flächen bildet zusammen die „Haut“ des Objekts.
Diese Methode kann verwendet werden, um eine breite Klasse von Volumenkörpern / Oberflächen in Grafiken darzustellen. Ein polygonales Netz kann mithilfe von Algorithmen zum Entfernen versteckter Oberflächen gerendert werden. Das Polygonnetz kann auf drei Arten dargestellt werden:
- Explizite Darstellung
- Zeiger auf eine Scheitelpunktliste
- Zeiger auf eine Kantenliste
Vorteile
- Es kann verwendet werden, um fast jedes Objekt zu modellieren.
- Sie lassen sich leicht als Sammlung von Eckpunkten darstellen.
- Sie sind leicht zu transformieren.
- Sie sind einfach auf dem Computerbildschirm zu zeichnen.
Nachteile
- Gekrümmte Flächen können nur annähernd beschrieben werden.
- Es ist schwierig, bestimmte Objekte wie Haare oder Flüssigkeiten zu simulieren.
Wenn wir ein Bild mit nicht transparenten Objekten und Oberflächen betrachten, können wir die Objekte nicht aus der Sicht sehen, die sich hinter Objekten befinden, die näher am Auge liegen. Wir müssen diese verborgenen Oberflächen entfernen, um ein realistisches Bildschirmbild zu erhalten. Die Identifizierung und Entfernung dieser Oberflächen wird genanntHidden-surface problem.
Es gibt zwei Ansätze, um Probleme mit verborgenen Oberflächen zu beseitigen: Object-Space method und Image-space method. Die Objektraummethode ist im physikalischen Koordinatensystem implementiert, und die Bildraummethode ist im Bildschirmkoordinatensystem implementiert.
Wenn wir ein 3D-Objekt auf einem 2D-Bildschirm anzeigen möchten, müssen wir die Teile eines Bildschirms identifizieren, die von einer ausgewählten Betrachtungsposition aus sichtbar sind.
Tiefenpuffer (Z-Puffer) -Methode
Diese Methode wurde von Cutmull entwickelt. Es ist ein Bildraum-Ansatz. Die Grundidee besteht darin, die Z-Tiefe jeder Oberfläche zu testen, um die nächstgelegene (sichtbare) Oberfläche zu bestimmen.
Bei diesem Verfahren wird jede Oberfläche einzeln um jeweils eine Pixelposition über die Oberfläche hinweg verarbeitet. Die Tiefenwerte für ein Pixel werden verglichen und die nächste (kleinste z) Oberfläche bestimmt die Farbe, die im Bildpuffer angezeigt werden soll.
Es wird sehr effizient auf Oberflächen von Polygonen angewendet. Oberflächen können in beliebiger Reihenfolge bearbeitet werden. Um die näheren Polygone von den entfernten zu überschreiben, wurden zwei Puffer benanntframe buffer und depth buffer, werden verwendet.
Depth buffer wird verwendet, um Tiefenwerte für die Position (x, y) zu speichern, wenn Oberflächen verarbeitet werden (0 ≤ Tiefe ≤ 1).
Das frame buffer wird verwendet, um den Intensitätswert des Farbwerts an jeder Position (x, y) zu speichern.
Die z-Koordinaten werden normalerweise auf den Bereich [0, 1] normiert. Der Wert 0 für die Z-Koordinate gibt den hinteren Beschneidungsbereich an, und der Wert 1 für die Z-Koordinaten gibt den vorderen Beschneidungsbereich an.
Algorithmus
Step-1 - Pufferwerte einstellen -
Tiefenpuffer (x, y) = 0
Framebuffer (x, y) = Hintergrundfarbe
Step-2 - Verarbeiten Sie jedes Polygon (einzeln)
Berechnen Sie für jede projizierte (x, y) Pixelposition eines Polygons die Tiefe z.
Wenn Z> Tiefenpuffer (x, y)
Oberflächenfarbe berechnen,
setze Tiefenpuffer (x, y) = z,
Bildpuffer (x, y) = Oberflächenfarbe (x, y)
Vorteile
- Es ist einfach zu implementieren.
- Es reduziert das Geschwindigkeitsproblem, wenn es in Hardware implementiert ist.
- Es wird jeweils ein Objekt verarbeitet.
Nachteile
- Es erfordert viel Speicher.
- Es ist ein zeitaufwändiger Prozess.
Scan-Line-Methode
Es ist eine Bildraummethode, um sichtbare Oberflächen zu identifizieren. Diese Methode enthält Tiefeninformationen nur für eine einzelne Scanlinie. Um eine Scanlinie mit Tiefenwerten zu benötigen, müssen alle Polygone, die eine bestimmte Scanlinie schneiden, gleichzeitig gruppiert und verarbeitet werden, bevor die nächste Scanlinie verarbeitet wird. Zwei wichtige Tabellen,edge table und polygon table, werden dafür gepflegt.
The Edge Table - Es enthält Koordinatenendpunkte jeder Linie in der Szene, die umgekehrte Neigung jeder Linie und Zeiger in die Polygontabelle, um Kanten mit Flächen zu verbinden.
The Polygon Table - Es enthält die ebenen Koeffizienten, Oberflächenmaterialeigenschaften und andere Oberflächendaten und kann Zeiger auf die Kantentabelle sein.

Um die Suche nach Oberflächen zu erleichtern, die eine bestimmte Scanlinie kreuzen, wird eine aktive Liste von Kanten gebildet. In der aktiven Liste werden nur die Kanten gespeichert, die die Scanlinie in der Reihenfolge der Erhöhung von x kreuzen. Außerdem wird für jede Oberfläche ein Flag gesetzt, um anzuzeigen, ob sich eine Position entlang einer Scanlinie entweder innerhalb oder außerhalb der Oberfläche befindet.
Pixelpositionen über jede Scanlinie werden von links nach rechts verarbeitet. Am linken Schnittpunkt mit einer Oberfläche wird die Oberflächenflagge eingeschaltet und rechts die Flagge ausgeschaltet. Sie müssen nur Tiefenberechnungen durchführen, wenn bei mehreren Oberflächen die Flags an einer bestimmten Position der Scanlinie aktiviert sind.
Bereichsunterteilungsmethode
Die Flächenunterteilungsmethode nutzt den Vorteil, indem die Ansichtsbereiche lokalisiert werden, die einen Teil einer einzelnen Oberfläche darstellen. Teilen Sie den gesamten Betrachtungsbereich in immer kleinere Rechtecke, bis jeder kleine Bereich die Projektion eines Teils einer einzelnen sichtbaren Fläche oder gar keiner Fläche ist.
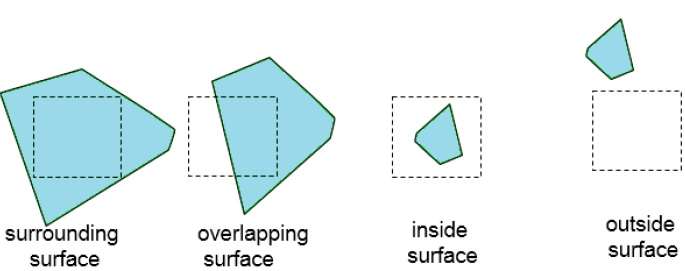
Setzen Sie diesen Vorgang fort, bis die Unterteilungen leicht als zu einer einzelnen Oberfläche gehörend analysiert werden können oder bis sie auf die Größe eines einzelnen Pixels reduziert sind. Eine einfache Möglichkeit, dies zu tun, besteht darin, den Bereich bei jedem Schritt nacheinander in vier gleiche Teile zu unterteilen. Es gibt vier mögliche Beziehungen, die eine Oberfläche zu einer bestimmten Flächengrenze haben kann.
Surrounding surface - Eine, die den Bereich vollständig einschließt.
Overlapping surface - Eine, die sich teilweise innerhalb und teilweise außerhalb des Bereichs befindet.
Inside surface - Eine, die sich vollständig innerhalb des Bereichs befindet.
Outside surface - Eine, die völlig außerhalb des Bereichs liegt.
Die Tests zur Bestimmung der Oberflächensichtbarkeit innerhalb eines Gebiets können anhand dieser vier Klassifikationen angegeben werden. Es sind keine weiteren Unterteilungen eines bestimmten Bereichs erforderlich, wenn eine der folgenden Bedingungen erfüllt ist:
- Alle Flächen sind flächenmäßig Außenflächen.
- In dem Bereich befindet sich nur eine innere, überlappende oder umgebende Oberfläche.
- Eine umgebende Oberfläche verdeckt alle anderen Oberflächen innerhalb der Bereichsgrenzen.
Rückseitenerkennung
Eine schnelle und einfache Objektraummethode zur Identifizierung der Rückseiten eines Polyeders basiert auf den "Inside-Outside" -Tests. Ein Punkt (x, y, z) befindet sich "innerhalb" einer Polygonfläche mit den Ebenenparametern A, B, C und D, wenn sich ein Innenpunkt entlang der Sichtlinie zur Oberfläche befindet und das Polygon eine Rückseite sein muss ( Wir befinden uns in diesem Gesicht und können die Vorderseite von unserer Betrachtungsposition aus nicht sehen.
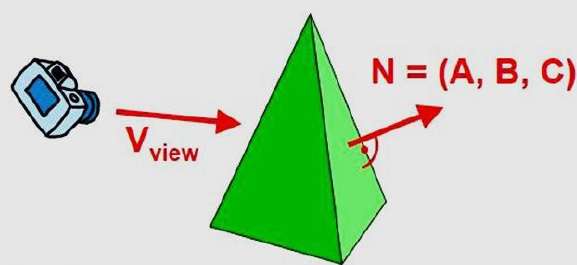
Wir können diesen Test vereinfachen, indem wir den normalen Vektor berücksichtigen N zu einer Polygonfläche, die kartesische Komponenten (A, B, C) aufweist.
Wenn V ein Vektor in Blickrichtung von der Position des Auges (oder der "Kamera") ist, ist dieses Polygon im Allgemeinen eine Rückseite, wenn
V.N > 0
Wenn Objektbeschreibungen in Projektionskoordinaten konvertiert werden und Ihre Blickrichtung parallel zur Betrachtungs-Z-Achse ist, gilt Folgendes:
V = (0, 0, V z ) und V. N = V Z C.
Damit müssen wir nur das Vorzeichen von C als Komponente des Normalenvektors betrachten N.
In einem rechtshändigen Betrachtungssystem mit Blickrichtung entlang des Negativs $Z_{V}$Achse ist das Polygon eine Rückseite, wenn C <0. Außerdem können wir keine Fläche sehen, deren Normalen die z-Komponente C = 0 haben, da Ihre Blickrichtung in Richtung dieses Polygons ist. Daher können wir im Allgemeinen jedes Polygon als Rückseite kennzeichnen, wenn sein normaler Vektor einen az-Komponentenwert hat -
C <= 0
Ähnliche Methoden können in Paketen verwendet werden, die ein linkshändiges Betrachtungssystem verwenden. In diesen Paketen können die Ebenenparameter A, B, C und D aus Polygonscheitelpunktkoordinaten berechnet werden, die im Uhrzeigersinn angegeben sind (im Gegensatz zur Richtung gegen den Uhrzeigersinn, die in einem rechtshändigen System verwendet wird).
Außerdem haben Rückseiten normale Vektoren, die von der Betrachtungsposition weg zeigen und durch C> = 0 gekennzeichnet sind, wenn die Betrachtungsrichtung entlang des Positivs liegt $Z_{v}$Achse. Indem wir Parameter C auf die verschiedenen Ebenen untersuchen, die ein Objekt definieren, können wir sofort alle Rückseiten identifizieren.
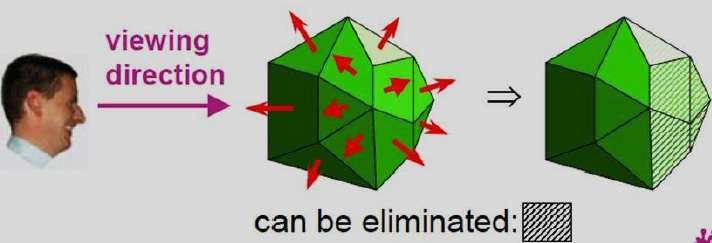
A-Puffer-Methode
Die A-Puffer-Methode ist eine Erweiterung der Tiefenpuffer-Methode. Die A-Puffer-Methode ist eine Sichtbarkeitserkennungsmethode, die in den Lucas Film Studios für das Rendering-System Renders Everything You Ever Saw (REYES) entwickelt wurde.
Der A-Puffer erweitert die Tiefenpuffermethode, um Transparenz zu ermöglichen. Die Schlüsseldatenstruktur im A-Puffer ist der Akkumulationspuffer.
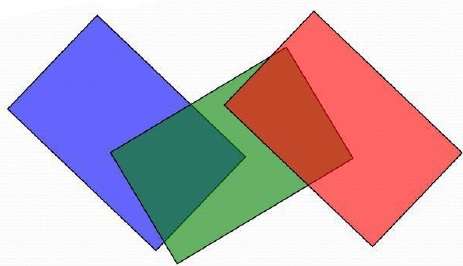
Jede Position im A-Puffer hat zwei Felder -
Depth field - Es speichert eine positive oder negative reelle Zahl
Intensity field - Es speichert Informationen zur Oberflächenintensität oder einen Zeigerwert

Wenn Tiefe> = 0 ist, ist die an dieser Position gespeicherte Zahl die Tiefe einer einzelnen Oberfläche, die den entsprechenden Pixelbereich überlappt. Das Intensitätsfeld speichert dann die RGB-Komponenten der Oberflächenfarbe an diesem Punkt und den Prozentsatz der Pixelabdeckung.
Wenn die Tiefe <0 ist, zeigt dies mehrere Oberflächenbeiträge zur Pixelintensität an. Das Intensitätsfeld speichert dann einen Zeiger auf eine verknüpfte Liste von Oberflächendaten. Der Oberflächenpuffer im A-Puffer enthält -
- RGB-Intensitätskomponenten
- Opazitätsparameter
- Depth
- Prozent der Flächendeckung
- Oberflächenkennung
Der Algorithmus läuft genauso ab wie der Tiefenpuffer-Algorithmus. Die Tiefen- und Opazitätswerte werden verwendet, um die endgültige Farbe eines Pixels zu bestimmen.
Tiefensortiermethode
Die Tiefensortierungsmethode verwendet sowohl Bildraum- als auch Objektraumoperationen. Die Tiefensortierungsmethode führt zwei Grundfunktionen aus:
Zunächst werden die Oberflächen in abnehmender Tiefe sortiert.
Zweitens werden die Oberflächen in der Reihenfolge scannen, beginnend mit der Oberfläche mit der größten Tiefe.
Die Scan-Konvertierung der Polygonflächen erfolgt im Bildraum. Diese Methode zur Lösung des Problems der verborgenen Oberfläche wird häufig als bezeichnetpainter's algorithm. Die folgende Abbildung zeigt den Effekt der Tiefensortierung -
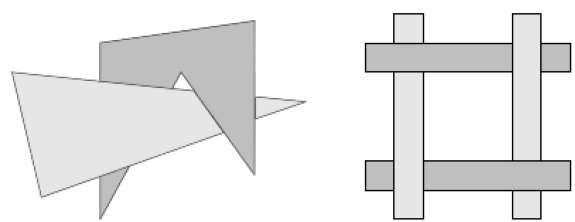
Der Algorithmus beginnt mit der Sortierung nach Tiefe. Beispielsweise kann die anfängliche "Tiefen" -Schätzung eines Polygons als der nächste z-Wert eines beliebigen Scheitelpunkts des Polygons angesehen werden.
Nehmen wir das Polygon P am Ende der Liste. Betrachten Sie alle Polygone Q, deren z-Ausdehnungen P überlappen. Vor dem Zeichnen von P führen wir die folgenden Tests durch. Wenn einer der folgenden Tests positiv ist, können wir davon ausgehen, dass P vor Q gezeichnet werden kann.
- Überlappen sich die x-Extents nicht?
- Überlappen sich die y-Extents nicht?
- Befindet sich P vom Standpunkt aus vollständig auf der gegenüberliegenden Seite der Q-Ebene?
- Befindet sich Q vollständig auf derselben Seite der P-Ebene wie der Ansichtspunkt?
- Überlappen sich die Projektionen der Polygone nicht?
Wenn alle Tests fehlschlagen, teilen wir entweder P oder Q auf der Ebene der anderen. Die neuen geschnittenen Polygone werden in die Tiefenreihenfolge eingefügt und der Vorgang wird fortgesetzt. Theoretisch könnte diese Aufteilung O (n 2 ) einzelne Polygone erzeugen , aber in der Praxis ist die Anzahl der Polygone viel kleiner.
BSP-Bäume (Binary Space Partition)
Die Partitionierung des Binärraums wird zur Berechnung der Sichtbarkeit verwendet. Um die BSP-Bäume zu erstellen, sollte man mit Polygonen beginnen und alle Kanten beschriften. Wenn Sie jeweils nur eine Kante bearbeiten, verlängern Sie jede Kante so, dass die Ebene in zwei Teile geteilt wird. Platzieren Sie die erste Kante im Baum als Wurzel. Fügen Sie nachfolgende Kanten hinzu, je nachdem, ob sie sich innerhalb oder außerhalb befinden. Kanten, die sich über die Ausdehnung einer Kante erstrecken, die sich bereits im Baum befindet, werden in zwei Teile geteilt und beide werden dem Baum hinzugefügt.

Nehmen Sie aus der obigen Abbildung zuerst A als Wurzel.
Erstellen Sie eine Liste aller Knoten in Abbildung (a).
Platzieren Sie alle Knoten vor root A auf der linken Seite des Knotens A und setzen Sie alle Knoten, die sich hinter der Wurzel befinden A auf der rechten Seite wie in Abbildung (b) gezeigt.
Verarbeiten Sie zuerst alle vorderen Knoten und dann die hinteren Knoten.
Wie in Abbildung (c) gezeigt, werden wir zuerst den Knoten verarbeiten B. Da ist nichts vor dem KnotenBhaben wir NIL gesetzt. Wir haben jedoch einen KnotenC auf der Rückseite des Knotens B, also Knoten C wird auf die rechte Seite des Knotens gehen B.
Wiederholen Sie den gleichen Vorgang für den Knoten D.
Ein französisch-amerikanischer Mathematiker, Dr. Benoit Mandelbrot, entdeckte Fraktale. Das Wort Fraktal wurde von einem lateinischen Wort Fraktus abgeleitet, was gebrochen bedeutet.
Was sind Fraktale?
Fraktale sind sehr komplexe Bilder, die von einem Computer aus einer einzigen Formel erzeugt werden. Sie werden mithilfe von Iterationen erstellt. Dies bedeutet, dass eine Formel immer wieder mit leicht unterschiedlichen Werten wiederholt wird, wobei die Ergebnisse der vorherigen Iteration berücksichtigt werden.
Fraktale werden in vielen Bereichen verwendet, wie z.
Astronomy - Zur Analyse von Galaxien, Saturnringen usw.
Biology/Chemistry - Zur Darstellung von Bakterienkulturen, chemischen Reaktionen, menschlicher Anatomie, Molekülen, Pflanzen,
Others - Zur Darstellung von Wolken, Küsten und Grenzen, Datenkomprimierung, Verbreitung, Wirtschaftlichkeit, fraktaler Kunst, fraktaler Musik, Landschaften, Spezialeffekten usw.

Erzeugung von Fraktalen
Fraktale können erzeugt werden, indem dieselbe Form immer wieder wiederholt wird, wie in der folgenden Abbildung gezeigt. In Abbildung (a) ist ein gleichseitiges Dreieck dargestellt. In Abbildung (b) sehen wir, dass das Dreieck wiederholt wird, um eine sternförmige Form zu erzeugen. In Abbildung (c) sehen wir, dass die Sternform in Abbildung (b) immer wieder wiederholt wird, um eine neue Form zu erstellen.
Wir können eine unbegrenzte Anzahl von Iterationen durchführen, um eine gewünschte Form zu erstellen. In Bezug auf die Programmierung wird die Rekursion verwendet, um solche Formen zu erstellen.

Geometrische Fraktale
Geometrische Fraktale befassen sich mit Formen, die in der Natur vorkommen und nicht ganzzahlige oder fraktale Dimensionen haben. Um ein deterministisches (nicht zufälliges) selbstähnliches Fraktal geometrisch zu konstruieren, beginnen wir mit einer gegebenen geometrischen Form, die alsinitiator. Unterteile des Initiators werden dann durch ein Muster ersetzt, das als das bezeichnet wirdgenerator.

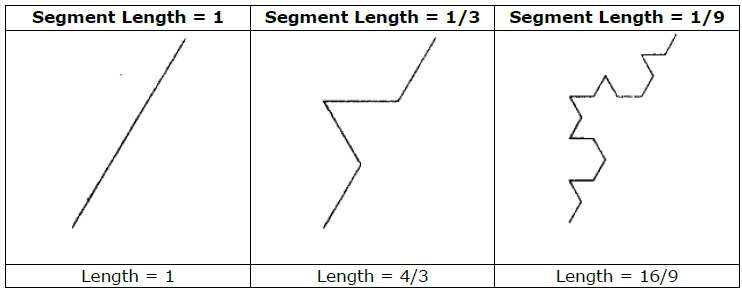
Wenn wir beispielsweise den in der obigen Abbildung gezeigten Initiator und Generator verwenden, können wir ein gutes Muster erstellen, indem wir es wiederholen. Jedes gerade Liniensegment im Initiator wird bei jedem Schritt durch vier gleichlange Liniensegmente ersetzt. Der Skalierungsfaktor beträgt 1/3, daher beträgt die fraktale Dimension D = ln 4 / ln 3 ≈ 1,2619.
Außerdem nimmt die Länge jedes Liniensegments im Initiator bei jedem Schritt um den Faktor 4/3 zu, so dass die Länge der fraktalen Kurve gegen unendlich tendiert, wenn der Kurve mehr Details hinzugefügt werden, wie in der folgenden Abbildung gezeigt.
Animation bedeutet, jedem Objekt in der Computergrafik Leben einzuhauchen. Es hat die Kraft, Energie und Emotionen in die scheinbar leblosen Objekte zu injizieren. Computergestützte Animation und computergenerierte Animation sind zwei Kategorien von Computeranimationen. Es kann per Film oder Video präsentiert werden.
Die Grundidee der Animation besteht darin, die aufgenommenen Bilder so schnell wiederzugeben, dass das menschliche Auge sie als kontinuierliche Bewegung interpretiert. Durch Animation können eine Reihe toter Bilder lebendig werden. Animation kann in vielen Bereichen wie Unterhaltung, computergestütztes Design, wissenschaftliche Visualisierung, Schulung, Bildung, E-Commerce und Computerkunst eingesetzt werden.
Animationstechniken
Animatoren haben eine Vielzahl verschiedener Animationstechniken erfunden und verwendet. Grundsätzlich gibt es sechs Animationstechniken, die wir in diesem Abschnitt einzeln diskutieren würden.
Traditionelle Animation (Bild für Bild)
Traditionell wurde der größte Teil der Animation von Hand gemacht. Alle Bilder in einer Animation mussten von Hand gezeichnet werden. Da für jede Sekunde der Animation 24 Bilder (Film) erforderlich sind, kann der Aufwand für die Erstellung selbst kürzester Filme enorm sein.
Keyframing
Bei dieser Technik wird ein Storyboard angelegt, und dann zeichnen die Künstler die Hauptrahmen der Animation. Hauptrahmen sind diejenigen, in denen markante Änderungen stattfinden. Sie sind die wichtigsten Punkte der Animation. Für das Keyframing muss der Animator kritische oder Schlüsselpositionen für die Objekte angeben. Der Computer füllt dann automatisch die fehlenden Frames aus, indem er reibungslos zwischen diesen Positionen interpoliert.
Verfahren
In einer prozeduralen Animation werden die Objekte durch eine Prozedur - eine Reihe von Regeln - und nicht durch Keyframing animiert. Der Animator legt Regeln und Anfangsbedingungen fest und führt die Simulation aus. Regeln basieren oft auf physikalischen Regeln der realen Welt, ausgedrückt durch mathematische Gleichungen.
Verhalten
In der Verhaltensanimation bestimmt ein autonomer Charakter zumindest bis zu einem gewissen Grad seine eigenen Handlungen. Dies gibt dem Charakter die Möglichkeit zu improvisieren und befreit den Animator von der Notwendigkeit, jedes Detail der Bewegung jedes Charakters anzugeben.
Leistungsbasiert (Motion Capture)
Eine andere Technik ist Motion Capture, bei der magnetische oder visionsbasierte Sensoren die Aktionen eines menschlichen oder tierischen Objekts in drei Dimensionen aufzeichnen. Ein Computer verwendet diese Daten dann, um das Objekt zu animieren.
Diese Technologie hat es einer Reihe berühmter Athleten ermöglicht, die Aktionen für Charaktere in Sportvideospielen bereitzustellen. Die Bewegungserfassung ist bei den Animatoren sehr beliebt, vor allem, weil einige der alltäglichen menschlichen Handlungen relativ einfach erfasst werden können. Es kann jedoch zu schwerwiegenden Abweichungen zwischen den Formen oder Abmessungen des Motivs und dem grafischen Charakter kommen, und dies kann zu Problemen bei der genauen Ausführung führen.
Physikalisch basiert (Dynamik)
Im Gegensatz zu Keyframing und Filmen verwendet die Simulation die Gesetze der Physik, um Bewegungen von Bildern und anderen Objekten zu erzeugen. Simulationen können leicht verwendet werden, um leicht unterschiedliche Sequenzen zu erzeugen, während der physische Realismus erhalten bleibt. Zweitens ermöglichen Echtzeitsimulationen ein höheres Maß an Interaktivität, bei der die reale Person die Aktionen des simulierten Charakters manövrieren kann.
Im Gegensatz dazu bilden die Anwendungen, die auf Keyframing und Bewegungsauswahl- und Änderungsbewegungen basieren, eine vorberechnete Bewegungsbibliothek. Ein Nachteil, unter dem die Simulation leidet, ist das Fachwissen und die Zeit, die erforderlich sind, um die entsprechenden Steuerungssysteme in Handarbeit herzustellen.
Key Framing
Ein Keyframe ist ein Frame, in dem wir Änderungen in der Animation definieren. Jeder Frame ist ein Keyframe, wenn wir Frame für Frame-Animation erstellen. Wenn jemand eine 3D-Animation auf einem Computer erstellt, gibt er normalerweise nicht die genaue Position eines bestimmten Objekts in jedem einzelnen Frame an. Sie erstellen Keyframes.
Keyframes sind wichtige Frames, in denen ein Objekt seine Größe, Richtung, Form oder andere Eigenschaften ändert. Der Computer ermittelt dann alle Zwischenbilder und spart dem Animator extrem viel Zeit. Die folgenden Abbildungen zeigen die vom Benutzer gezeichneten Frames und die vom Computer generierten Frames.


Morphing
Die Transformation von Objektformen von einer Form in eine andere Form wird als Morphing bezeichnet. Es ist eine der kompliziertesten Transformationen.

Ein Morph sieht aus, als ob zwei Bilder mit einer sehr fließenden Bewegung ineinander verschmelzen. Technisch gesehen sind zwei Bilder verzerrt und es tritt eine Überblendung zwischen ihnen auf.