Erkennung sichtbarer Oberflächen
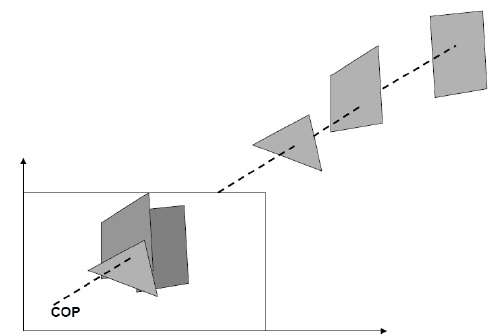
Wenn wir ein Bild mit nicht transparenten Objekten und Oberflächen betrachten, können wir die Objekte nicht aus der Sicht sehen, die sich hinter Objekten befinden, die näher am Auge liegen. Wir müssen diese verborgenen Oberflächen entfernen, um ein realistisches Bildschirmbild zu erhalten. Die Identifizierung und Entfernung dieser Oberflächen wird genanntHidden-surface problem.
Es gibt zwei Ansätze, um Probleme mit verborgenen Oberflächen zu beseitigen: Object-Space method und Image-space method. Die Objektraummethode ist im physikalischen Koordinatensystem implementiert, und die Bildraummethode ist im Bildschirmkoordinatensystem implementiert.
Wenn wir ein 3D-Objekt auf einem 2D-Bildschirm anzeigen möchten, müssen wir die Teile eines Bildschirms identifizieren, die von einer ausgewählten Betrachtungsposition aus sichtbar sind.
Tiefenpuffer (Z-Puffer) -Methode
Diese Methode wurde von Cutmull entwickelt. Es ist ein Bildraum-Ansatz. Die Grundidee besteht darin, die Z-Tiefe jeder Oberfläche zu testen, um die nächstgelegene (sichtbare) Oberfläche zu bestimmen.
Bei diesem Verfahren wird jede Oberfläche einzeln um jeweils eine Pixelposition über die Oberfläche hinweg verarbeitet. Die Tiefenwerte für ein Pixel werden verglichen und die nächste (kleinste z) Oberfläche bestimmt die Farbe, die im Bildpuffer angezeigt werden soll.
Es wird sehr effizient auf Oberflächen von Polygonen angewendet. Oberflächen können in beliebiger Reihenfolge bearbeitet werden. Um die näheren Polygone von den entfernten zu überschreiben, wurden zwei Puffer benanntframe buffer und depth buffer, werden verwendet.
Depth buffer wird verwendet, um Tiefenwerte für die Position (x, y) zu speichern, wenn Oberflächen verarbeitet werden (0 ≤ Tiefe ≤ 1).
Das frame buffer wird verwendet, um den Intensitätswert des Farbwerts an jeder Position (x, y) zu speichern.
Die z-Koordinaten werden normalerweise auf den Bereich [0, 1] normiert. Der Wert 0 für die Z-Koordinate gibt den hinteren Beschneidungsbereich an, und der Wert 1 für die Z-Koordinaten gibt den vorderen Beschneidungsbereich an.
Algorithmus
Step-1 - Stellen Sie die Pufferwerte ein -
Tiefenpuffer (x, y) = 0
Framebuffer (x, y) = Hintergrundfarbe
Step-2 - Verarbeiten Sie jedes Polygon (einzeln)
Berechnen Sie für jede projizierte (x, y) Pixelposition eines Polygons die Tiefe z.
Wenn Z> Tiefenpuffer (x, y)
Oberflächenfarbe berechnen,
setze Tiefenpuffer (x, y) = z,
Bildpuffer (x, y) = Oberflächenfarbe (x, y)
Vorteile
- Es ist einfach zu implementieren.
- Es reduziert das Geschwindigkeitsproblem, wenn es in Hardware implementiert ist.
- Es wird jeweils ein Objekt verarbeitet.
Nachteile
- Es erfordert viel Speicher.
- Es ist ein zeitaufwändiger Prozess.
Scan-Line-Methode
Es ist eine Bildraummethode, um sichtbare Oberflächen zu identifizieren. Diese Methode enthält Tiefeninformationen nur für eine einzelne Scanlinie. Um eine Scanlinie mit Tiefenwerten zu benötigen, müssen alle Polygone, die eine bestimmte Scanlinie schneiden, gleichzeitig gruppiert und verarbeitet werden, bevor die nächste Scanlinie verarbeitet wird. Zwei wichtige Tabellen,edge table und polygon table, werden dafür gepflegt.
The Edge Table - Es enthält Koordinatenendpunkte jeder Linie in der Szene, die inverse Neigung jeder Linie und Zeiger in die Polygontabelle, um Kanten mit Flächen zu verbinden.
The Polygon Table - Es enthält die ebenen Koeffizienten, Oberflächenmaterialeigenschaften und andere Oberflächendaten und kann Zeiger auf die Kantentabelle sein.

Um die Suche nach Oberflächen zu erleichtern, die eine bestimmte Scanlinie kreuzen, wird eine aktive Liste von Kanten gebildet. In der aktiven Liste werden nur die Kanten gespeichert, die die Scanlinie in der Reihenfolge der Erhöhung von x kreuzen. Außerdem wird für jede Oberfläche ein Flag gesetzt, um anzuzeigen, ob sich eine Position entlang einer Scanlinie entweder innerhalb oder außerhalb der Oberfläche befindet.
Pixelpositionen über jede Scanlinie werden von links nach rechts verarbeitet. Am linken Schnittpunkt mit einer Oberfläche wird die Oberflächenflagge eingeschaltet und rechts die Flagge ausgeschaltet. Sie müssen nur Tiefenberechnungen durchführen, wenn bei mehreren Oberflächen die Flags an einer bestimmten Position der Scanlinie aktiviert sind.
Bereichsunterteilungsmethode
Die Flächenunterteilungsmethode nutzt den Vorteil, indem die Ansichtsbereiche lokalisiert werden, die einen Teil einer einzelnen Oberfläche darstellen. Teilen Sie den gesamten Betrachtungsbereich in immer kleinere Rechtecke, bis jeder kleine Bereich die Projektion eines Teils einer einzelnen sichtbaren Fläche oder gar keiner Fläche ist.
Setzen Sie diesen Vorgang fort, bis die Unterteilungen leicht als zu einer einzelnen Oberfläche gehörend analysiert werden können oder bis sie auf die Größe eines einzelnen Pixels reduziert sind. Eine einfache Möglichkeit, dies zu tun, besteht darin, den Bereich bei jedem Schritt nacheinander in vier gleiche Teile zu unterteilen. Es gibt vier mögliche Beziehungen, die eine Oberfläche zu einer bestimmten Flächengrenze haben kann.
Surrounding surface - Eine, die den Bereich vollständig einschließt.
Overlapping surface - Eine, die sich teilweise innerhalb und teilweise außerhalb des Bereichs befindet.
Inside surface - Eine, die sich vollständig innerhalb des Bereichs befindet.
Outside surface - Eine, die völlig außerhalb des Bereichs liegt.
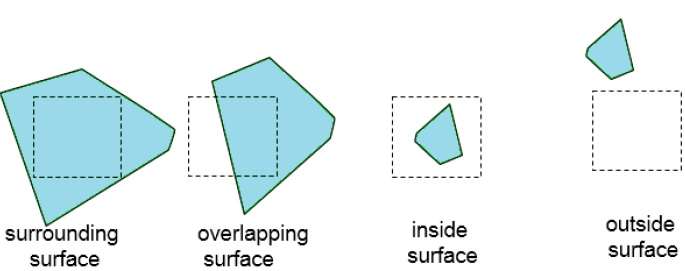
Die Tests zur Bestimmung der Oberflächensichtbarkeit innerhalb eines Gebiets können anhand dieser vier Klassifikationen angegeben werden. Es sind keine weiteren Unterteilungen eines bestimmten Bereichs erforderlich, wenn eine der folgenden Bedingungen erfüllt ist:
- Alle Flächen sind flächenmäßig Außenflächen.
- In dem Bereich befindet sich nur eine innere, überlappende oder umgebende Oberfläche.
- Eine umgebende Oberfläche verdeckt alle anderen Oberflächen innerhalb der Bereichsgrenzen.
Rückseitenerkennung
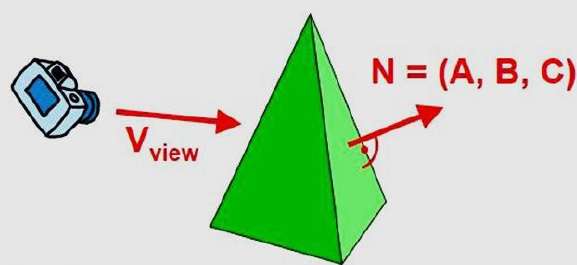
Eine schnelle und einfache Objektraummethode zur Identifizierung der Rückseiten eines Polyeders basiert auf den "Inside-Outside" -Tests. Ein Punkt (x, y, z) befindet sich "innerhalb" einer Polygonfläche mit den Ebenenparametern A, B, C und D, wenn sich ein Innenpunkt entlang der Sichtlinie zur Oberfläche befindet und das Polygon eine Rückseite sein muss ( Wir befinden uns in diesem Gesicht und können die Vorderseite von unserer Betrachtungsposition aus nicht sehen.
Wir können diesen Test vereinfachen, indem wir den normalen Vektor berücksichtigen N zu einer Polygonfläche, die kartesische Komponenten (A, B, C) aufweist.
Wenn V ein Vektor in Blickrichtung von der Position des Auges (oder der "Kamera") ist, ist dieses Polygon im Allgemeinen eine Rückseite, wenn
V.N > 0
Wenn Objektbeschreibungen in Projektionskoordinaten konvertiert werden und Ihre Blickrichtung parallel zur Betrachtungs-Z-Achse ist, gilt Folgendes:
V = (0, 0, V z ) und V. N = V Z C.
Damit müssen wir nur das Vorzeichen von C als Komponente des Normalenvektors betrachten N.
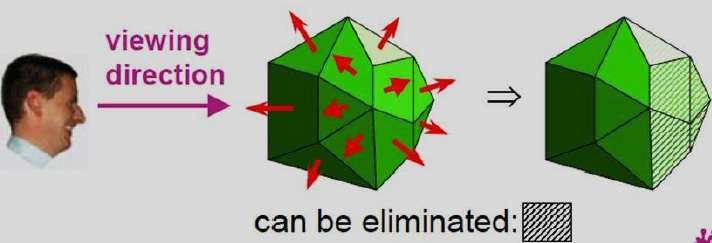
In einem rechtshändigen Betrachtungssystem mit Blickrichtung entlang der negativen $ Z_ {V} $ -Achse ist das Polygon eine Rückseite, wenn C <0. Außerdem können wir keine Fläche sehen, deren Normalen die z-Komponente C = 0 haben, da Ihre Die Blickrichtung ist in Richtung dieses Polygons. Daher können wir im Allgemeinen jedes Polygon als Rückseite kennzeichnen, wenn sein normaler Vektor einen az-Komponentenwert hat -
C <= 0
Ähnliche Methoden können in Paketen verwendet werden, die ein linkshändiges Betrachtungssystem verwenden. In diesen Paketen können die Ebenenparameter A, B, C und D aus Polygonscheitelpunktkoordinaten berechnet werden, die im Uhrzeigersinn angegeben sind (im Gegensatz zur Richtung gegen den Uhrzeigersinn, die in einem rechtshändigen System verwendet wird).
Außerdem haben Rückseiten normale Vektoren, die von der Betrachtungsposition weg zeigen und durch C> = 0 gekennzeichnet sind, wenn die Betrachtungsrichtung entlang der positiven $ Z_ {v} $ -Achse liegt. Indem wir Parameter C auf die verschiedenen Ebenen untersuchen, die ein Objekt definieren, können wir sofort alle Rückseiten identifizieren.
A-Puffer-Methode
Die A-Puffer-Methode ist eine Erweiterung der Tiefenpuffer-Methode. Die A-Puffer-Methode ist eine Sichtbarkeitserkennungsmethode, die in den Lucas Film Studios für das Rendering-System Renders Everything You Ever Saw (REYES) entwickelt wurde.
Der A-Puffer erweitert die Tiefenpuffermethode, um Transparenz zu ermöglichen. Die Schlüsseldatenstruktur im A-Puffer ist der Akkumulationspuffer.
Jede Position im A-Puffer hat zwei Felder -
Depth field - Es speichert eine positive oder negative reelle Zahl
Intensity field - Es speichert Informationen zur Oberflächenintensität oder einen Zeigerwert

Wenn Tiefe> = 0 ist, ist die an dieser Position gespeicherte Zahl die Tiefe einer einzelnen Oberfläche, die den entsprechenden Pixelbereich überlappt. Das Intensitätsfeld speichert dann die RGB-Komponenten der Oberflächenfarbe an diesem Punkt und den Prozentsatz der Pixelabdeckung.
Wenn die Tiefe <0 ist, zeigt dies Beiträge mehrerer Oberflächen zur Pixelintensität an. Das Intensitätsfeld speichert dann einen Zeiger auf eine verknüpfte Liste von Oberflächendaten. Der Oberflächenpuffer im A-Puffer enthält -
- RGB-Intensitätskomponenten
- Opazitätsparameter
- Depth
- Prozent der Flächendeckung
- Oberflächenkennung
Der Algorithmus läuft genauso ab wie der Tiefenpuffer-Algorithmus. Die Tiefen- und Deckkraftwerte werden verwendet, um die endgültige Farbe eines Pixels zu bestimmen.
Tiefensortiermethode
Die Tiefensortierungsmethode verwendet sowohl Bildraum- als auch Objektraumoperationen. Die Tiefensortierungsmethode führt zwei Grundfunktionen aus:
Zunächst werden die Oberflächen nach abnehmender Tiefe sortiert.
Zweitens werden die Oberflächen in der Reihenfolge scannen, beginnend mit der Oberfläche mit der größten Tiefe.
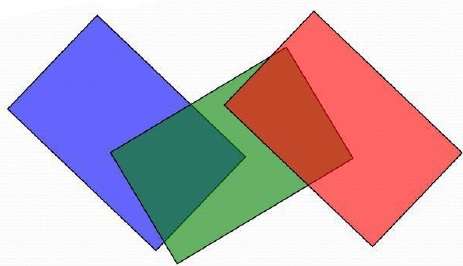
Die Scan-Konvertierung der Polygonflächen erfolgt im Bildraum. Diese Methode zur Lösung des Problems der verborgenen Oberfläche wird häufig als bezeichnetpainter's algorithm. Die folgende Abbildung zeigt den Effekt der Tiefensortierung -
Der Algorithmus beginnt mit der Sortierung nach Tiefe. Beispielsweise kann die anfängliche "Tiefen" -Schätzung eines Polygons als der nächste z-Wert eines beliebigen Scheitelpunkts des Polygons angesehen werden.
Nehmen wir das Polygon P am Ende der Liste. Betrachten Sie alle Polygone Q, deren z-Ausdehnungen P überlappen. Vor dem Zeichnen von P führen wir die folgenden Tests durch. Wenn einer der folgenden Tests positiv ist, können wir davon ausgehen, dass P vor Q gezeichnet werden kann.
- Überlappen sich die x-Extents nicht?
- Überlappen sich die y-Extents nicht?
- Befindet sich P vom Standpunkt aus vollständig auf der gegenüberliegenden Seite der Q-Ebene?
- Befindet sich Q vollständig auf derselben Seite der P-Ebene wie der Ansichtspunkt?
- Überlappen sich die Projektionen der Polygone nicht?
Wenn alle Tests fehlschlagen, teilen wir entweder P oder Q auf der Ebene der anderen. Die neuen geschnittenen Polygone werden in die Tiefenreihenfolge eingefügt und der Vorgang wird fortgesetzt. Theoretisch könnte diese Aufteilung O (n 2 ) einzelne Polygone erzeugen , aber in der Praxis ist die Anzahl der Polygone viel kleiner.
BSP-Bäume (Binary Space Partition)
Die Partitionierung des Binärraums wird zur Berechnung der Sichtbarkeit verwendet. Um die BSP-Bäume zu erstellen, sollte man mit Polygonen beginnen und alle Kanten beschriften. Wenn Sie jeweils nur eine Kante bearbeiten, verlängern Sie jede Kante so, dass die Ebene in zwei Teile geteilt wird. Platzieren Sie die erste Kante im Baum als Wurzel. Fügen Sie nachfolgende Kanten hinzu, je nachdem, ob sie sich innerhalb oder außerhalb befinden. Kanten, die sich über die Ausdehnung einer Kante erstrecken, die sich bereits im Baum befindet, werden in zwei Teile geteilt und beide zum Baum hinzugefügt.

Nehmen Sie aus der obigen Abbildung zuerst A als Wurzel.
Erstellen Sie eine Liste aller Knoten in Abbildung (a).
Platzieren Sie alle Knoten vor root A auf der linken Seite des Knotens A und setzen Sie alle Knoten, die sich hinter der Wurzel befinden A auf der rechten Seite wie in Abbildung (b) gezeigt.
Verarbeiten Sie zuerst alle vorderen Knoten und dann die hinteren Knoten.
Wie in Abbildung (c) gezeigt, werden wir zuerst den Knoten verarbeiten B. Da ist nichts vor dem KnotenBhaben wir NIL gesetzt. Wir haben jedoch einen KnotenC auf der Rückseite des Knotens B, also Knoten C wird auf die rechte Seite des Knotens gehen B.
Wiederholen Sie den gleichen Vorgang für den Knoten D.