TensorFlow: redes neuronales convolucionales
Después de comprender los conceptos de aprendizaje automático, ahora podemos cambiar nuestro enfoque a los conceptos de aprendizaje profundo. El aprendizaje profundo es una división del aprendizaje automático y se considera un paso crucial dado por los investigadores en las últimas décadas. Los ejemplos de implementación de aprendizaje profundo incluyen aplicaciones como reconocimiento de imágenes y reconocimiento de voz.
A continuación se muestran los dos tipos importantes de redes neuronales profundas:
- Redes neuronales convolucionales
- Redes neuronales recurrentes
En este capítulo, nos centraremos en la CNN, Redes neuronales convolucionales.
Redes neuronales convolucionales
Las redes neuronales convolucionales están diseñadas para procesar datos a través de múltiples capas de arreglos. Este tipo de redes neuronales se utiliza en aplicaciones como el reconocimiento de imágenes o el reconocimiento facial. La principal diferencia entre CNN y cualquier otra red neuronal ordinaria es que CNN toma la entrada como una matriz bidimensional y opera directamente en las imágenes en lugar de enfocarse en la extracción de características en las que se enfocan otras redes neuronales.
El enfoque dominante de CNN incluye soluciones para problemas de reconocimiento. Las principales empresas como Google y Facebook han invertido en investigación y desarrollo hacia proyectos de reconocimiento para realizar actividades con mayor rapidez.
Una red neuronal convolucional utiliza tres ideas básicas:
- Campos respectivos locales
- Convolution
- Pooling
Entendamos estas ideas en detalle.
CNN utiliza correlaciones espaciales que existen dentro de los datos de entrada. Cada capa concurrente de una red neuronal conecta algunas neuronas de entrada. Esta región específica se llama campo receptivo local. El campo receptivo local se centra en las neuronas ocultas. Las neuronas ocultas procesan los datos de entrada dentro del campo mencionado sin darse cuenta de los cambios fuera del límite específico.
A continuación se muestra un diagrama de representación de la generación de campos respectivos locales:
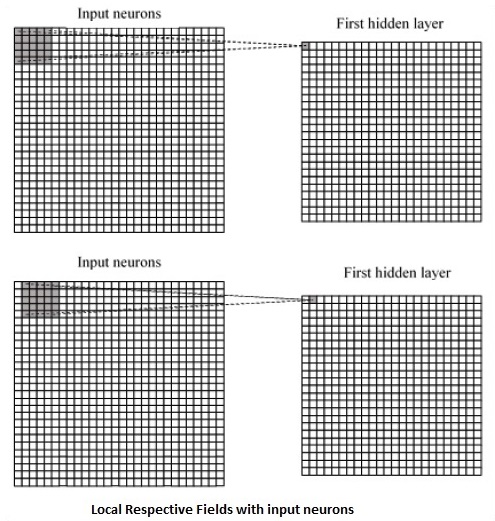
Si observamos la representación anterior, cada conexión aprende un peso de la neurona oculta con una conexión asociada con el movimiento de una capa a otra. Aquí, las neuronas individuales realizan un cambio de vez en cuando. Este proceso se llama "convolución".
El mapeo de conexiones desde la capa de entrada al mapa de características ocultas se define como "pesos compartidos" y el sesgo incluido se denomina "sesgo compartido".
CNN o las redes neuronales convolucionales utilizan capas de agrupación, que son las capas, ubicadas inmediatamente después de la declaración de CNN. Toma la entrada del usuario como un mapa de características que proviene de redes convolucionales y prepara un mapa de características condensado. La agrupación de capas ayuda a crear capas con neuronas de capas anteriores.
Implementación de TensorFlow de CNN
En esta sección, aprenderemos sobre la implementación de TensorFlow de CNN. Los pasos, que requieren la ejecución y la dimensión adecuada de toda la red, son los que se muestran a continuación:
Step 1 - Incluya los módulos necesarios para TensorFlow y los módulos del conjunto de datos, que son necesarios para calcular el modelo CNN.
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_dataStep 2 - Declarar una función llamada run_cnn(), que incluye varios parámetros y variables de optimización con declaración de marcadores de posición de datos. Estas variables de optimización declararán el patrón de entrenamiento.
def run_cnn():
mnist = input_data.read_data_sets("MNIST_data/", one_hot = True)
learning_rate = 0.0001
epochs = 10
batch_size = 50Step 3 - En este paso, declararemos los marcadores de posición de datos de entrenamiento con parámetros de entrada - para 28 x 28 píxeles = 784. Estos son los datos de imagen acoplados que se extraen de mnist.train.nextbatch().
Podemos remodelar el tensor según nuestros requisitos. El primer valor (-1) le dice a la función que dé forma dinámica a esa dimensión en función de la cantidad de datos que se le pasan. Las dos dimensiones medias se establecen en el tamaño de la imagen (es decir, 28 x 28).
x = tf.placeholder(tf.float32, [None, 784])
x_shaped = tf.reshape(x, [-1, 28, 28, 1])
y = tf.placeholder(tf.float32, [None, 10])Step 4 - Ahora es importante crear algunas capas convolucionales -
layer1 = create_new_conv_layer(x_shaped, 1, 32, [5, 5], [2, 2], name = 'layer1')
layer2 = create_new_conv_layer(layer1, 32, 64, [5, 5], [2, 2], name = 'layer2')Step 5- Aplanaremos la salida lista para la etapa de salida completamente conectada - después de dos capas de zancada 2 agrupadas con las dimensiones de 28 x 28, a una dimensión de 14 x 14 o un mínimo de 7 x 7 x, coordenadas y, pero con 64 canales de salida. Para crear la capa completamente conectada con "densa", la nueva forma debe ser [-1, 7 x 7 x 64]. Podemos configurar algunos pesos y valores de sesgo para esta capa, luego activar con ReLU.
flattened = tf.reshape(layer2, [-1, 7 * 7 * 64])
wd1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1000], stddev = 0.03), name = 'wd1')
bd1 = tf.Variable(tf.truncated_normal([1000], stddev = 0.01), name = 'bd1')
dense_layer1 = tf.matmul(flattened, wd1) + bd1
dense_layer1 = tf.nn.relu(dense_layer1)Step 6 - Otra capa con activaciones específicas de softmax con el optimizador requerido define la evaluación de precisión, que hace la configuración del operador de inicialización.
wd2 = tf.Variable(tf.truncated_normal([1000, 10], stddev = 0.03), name = 'wd2')
bd2 = tf.Variable(tf.truncated_normal([10], stddev = 0.01), name = 'bd2')
dense_layer2 = tf.matmul(dense_layer1, wd2) + bd2
y_ = tf.nn.softmax(dense_layer2)
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits = dense_layer2, labels = y))
optimiser = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
init_op = tf.global_variables_initializer()Step 7- Deberíamos configurar variables de grabación. Esto suma un resumen para almacenar la precisión de los datos.
tf.summary.scalar('accuracy', accuracy)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('E:\TensorFlowProject')
with tf.Session() as sess:
sess.run(init_op)
total_batch = int(len(mnist.train.labels) / batch_size)
for epoch in range(epochs):
avg_cost = 0
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size = batch_size)
_, c = sess.run([optimiser, cross_entropy], feed_dict = {
x:batch_x, y: batch_y})
avg_cost += c / total_batch
test_acc = sess.run(accuracy, feed_dict = {x: mnist.test.images, y:
mnist.test.labels})
summary = sess.run(merged, feed_dict = {x: mnist.test.images, y:
mnist.test.labels})
writer.add_summary(summary, epoch)
print("\nTraining complete!")
writer.add_graph(sess.graph)
print(sess.run(accuracy, feed_dict = {x: mnist.test.images, y:
mnist.test.labels}))
def create_new_conv_layer(
input_data, num_input_channels, num_filters,filter_shape, pool_shape, name):
conv_filt_shape = [
filter_shape[0], filter_shape[1], num_input_channels, num_filters]
weights = tf.Variable(
tf.truncated_normal(conv_filt_shape, stddev = 0.03), name = name+'_W')
bias = tf.Variable(tf.truncated_normal([num_filters]), name = name+'_b')
#Out layer defines the output
out_layer =
tf.nn.conv2d(input_data, weights, [1, 1, 1, 1], padding = 'SAME')
out_layer += bias
out_layer = tf.nn.relu(out_layer)
ksize = [1, pool_shape[0], pool_shape[1], 1]
strides = [1, 2, 2, 1]
out_layer = tf.nn.max_pool(
out_layer, ksize = ksize, strides = strides, padding = 'SAME')
return out_layer
if __name__ == "__main__":
run_cnn()A continuación se muestra la salida generada por el código anterior:
See @{tf.nn.softmax_cross_entropy_with_logits_v2}.
2018-09-19 17:22:58.802268: I
T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:140]
Your CPU supports instructions that this TensorFlow binary was not compiled to
use: AVX2
2018-09-19 17:25:41.522845: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 1003520000 exceeds 10% of system memory.
2018-09-19 17:25:44.630941: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 501760000 exceeds 10% of system memory.
Epoch: 1 cost = 0.676 test accuracy: 0.940
2018-09-19 17:26:51.987554: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 1003520000 exceeds 10% of system memory.