TensorFlow - Guía rápida
TensorFlow es una biblioteca o marco de software, diseñado por el equipo de Google para implementar conceptos de aprendizaje automático y aprendizaje profundo de la manera más sencilla. Combina el álgebra computacional de técnicas de optimización para facilitar el cálculo de muchas expresiones matemáticas.
El sitio web oficial de TensorFlow se menciona a continuación:
www.tensorflow.org
Consideremos ahora las siguientes características importantes de TensorFlow:
Incluye una función de que define, optimiza y calcula expresiones matemáticas fácilmente con la ayuda de matrices multidimensionales llamadas tensores.
Incluye un soporte de programación de redes neuronales profundas y técnicas de aprendizaje automático.
Incluye una característica de cálculo altamente escalable con varios conjuntos de datos.
TensorFlow usa computación GPU para automatizar la administración. También incluye una característica única de optimización de la misma memoria y los datos utilizados.
¿Por qué TensorFlow es tan popular?
TensorFlow está bien documentado e incluye muchas bibliotecas de aprendizaje automático. Ofrece algunas funcionalidades y métodos importantes para el mismo.
TensorFlow también se denomina producto de "Google". Incluye una variedad de algoritmos de aprendizaje automático y aprendizaje profundo. TensorFlow puede entrenar y ejecutar redes neuronales profundas para la clasificación de dígitos escritos a mano, el reconocimiento de imágenes, la inserción de palabras y la creación de varios modelos de secuencia.
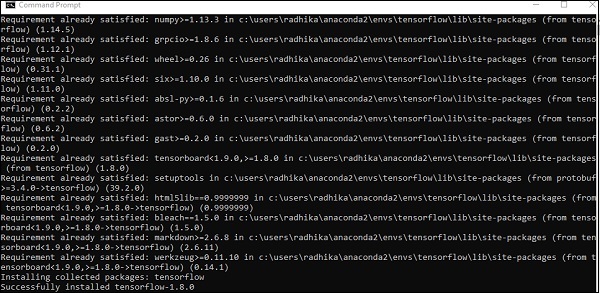
Para instalar TensorFlow, es importante tener "Python" instalado en su sistema. La versión 3.4+ de Python se considera la mejor para comenzar con la instalación de TensorFlow.
Considere los siguientes pasos para instalar TensorFlow en el sistema operativo Windows.
Step 1 - Verifique la versión de Python que se está instalando.
Step 2- Un usuario puede elegir cualquier mecanismo para instalar TensorFlow en el sistema. Recomendamos “pip” y “Anaconda”. Pip es un comando que se usa para ejecutar e instalar módulos en Python.
Antes de instalar TensorFlow, necesitamos instalar el marco de Anaconda en nuestro sistema.
Después de una instalación exitosa, verifique el símbolo del sistema a través del comando "conda". La ejecución del comando se muestra a continuación:
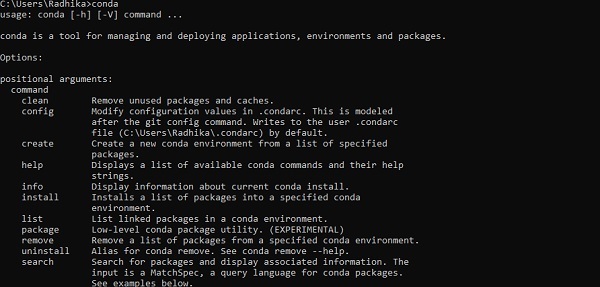
Step 3 - Ejecute el siguiente comando para inicializar la instalación de TensorFlow -
conda create --name tensorflow python = 3.5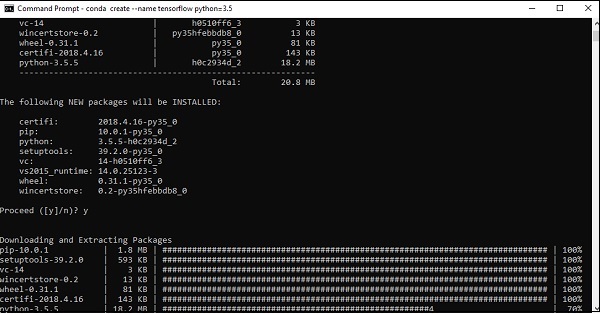
Descarga los paquetes necesarios para la configuración de TensorFlow.
Step 4 - Después de una configuración ambiental exitosa, es importante activar el módulo TensorFlow.
activate tensorflow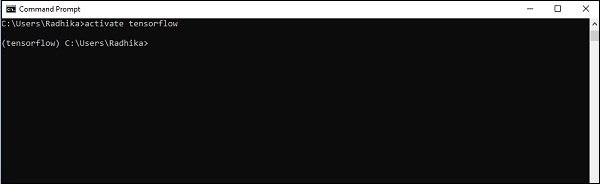
Step 5- Utilice pip para instalar "Tensorflow" en el sistema. El comando utilizado para la instalación se menciona a continuación:
pip install tensorflowY,
pip install tensorflow-gpu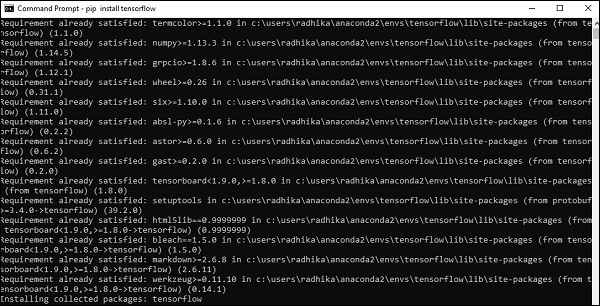
Después de una instalación exitosa, es importante conocer la ejecución del programa de muestra de TensorFlow.
El siguiente ejemplo nos ayuda a comprender la creación básica del programa "Hello World" en TensorFlow.
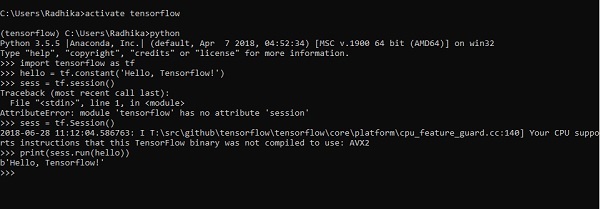
El código para la implementación del primer programa se menciona a continuación:
>> activate tensorflow
>> python (activating python shell)
>> import tensorflow as tf
>> hello = tf.constant(‘Hello, Tensorflow!’)
>> sess = tf.Session()
>> print(sess.run(hello))La inteligencia artificial incluye el proceso de simulación de la inteligencia humana mediante máquinas y sistemas informáticos especiales. Los ejemplos de inteligencia artificial incluyen el aprendizaje, el razonamiento y la autocorrección. Las aplicaciones de la IA incluyen reconocimiento de voz, sistemas expertos y reconocimiento de imágenes y visión artificial.
El aprendizaje automático es la rama de la inteligencia artificial, que se ocupa de sistemas y algoritmos que pueden aprender nuevos datos y patrones de datos.
Centrémonos en el diagrama de Venn que se menciona a continuación para comprender los conceptos de aprendizaje automático y aprendizaje profundo.
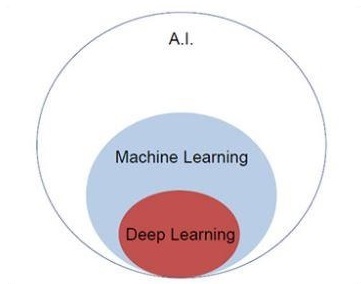
El aprendizaje automático incluye una sección de aprendizaje automático y el aprendizaje profundo es parte del aprendizaje automático. La capacidad del programa que sigue los conceptos de aprendizaje automático es mejorar su rendimiento de los datos observados. El motivo principal de la transformación de datos es mejorar su conocimiento para lograr mejores resultados en el futuro, proporcionar una salida más cercana a la salida deseada para ese sistema en particular. El aprendizaje automático incluye el "reconocimiento de patrones", que incluye la capacidad de reconocer los patrones en los datos.
Los patrones deben estar entrenados para mostrar el resultado de la manera deseada.
El aprendizaje automático se puede entrenar de dos formas diferentes:
- Entrenamiento supervisado
- Entrenamiento no supervisado
Aprendizaje supervisado
El aprendizaje supervisado o la formación supervisada incluye un procedimiento en el que el conjunto de formación se proporciona como entrada al sistema en el que cada ejemplo se etiqueta con un valor de salida deseado. El entrenamiento en este tipo se realiza utilizando la minimización de una función de pérdida particular, que representa el error de salida con respecto al sistema de salida deseado.
Una vez finalizado el entrenamiento, la precisión de cada modelo se mide con respecto a ejemplos separados del conjunto de entrenamiento, también llamado conjunto de validación.
El mejor ejemplo para ilustrar el "aprendizaje supervisado" es con un montón de fotos con información incluida. Aquí, el usuario puede entrenar a un modelo para que reconozca nuevas fotos.
Aprendizaje sin supervisión
En el aprendizaje no supervisado o la formación no supervisada, incluya ejemplos de formación, que no están etiquetados por el sistema a qué clase pertenecen. El sistema busca los datos que comparten características comunes y los modifica en función de las características del conocimiento interno. Este tipo de algoritmos de aprendizaje se utilizan básicamente en problemas de agrupación.
El mejor ejemplo para ilustrar el "aprendizaje no supervisado" es con un montón de fotos sin información incluida y el modelo de trenes de usuario con clasificación y agrupamiento. Este tipo de algoritmo de entrenamiento funciona con suposiciones ya que no se proporciona información.

Es importante comprender los conceptos matemáticos necesarios para TensorFlow antes de crear la aplicación básica en TensorFlow. Las matemáticas se consideran el corazón de cualquier algoritmo de aprendizaje automático. Es con la ayuda de los conceptos básicos de las matemáticas, se define una solución para un algoritmo de aprendizaje automático específico.
Vector
Una matriz de números, que es continua o discreta, se define como un vector. Los algoritmos de aprendizaje automático se ocupan de vectores de longitud fija para una mejor generación de resultados.
Los algoritmos de aprendizaje automático se ocupan de datos multidimensionales, por lo que los vectores juegan un papel crucial.

La representación pictórica del modelo vectorial es la que se muestra a continuación:
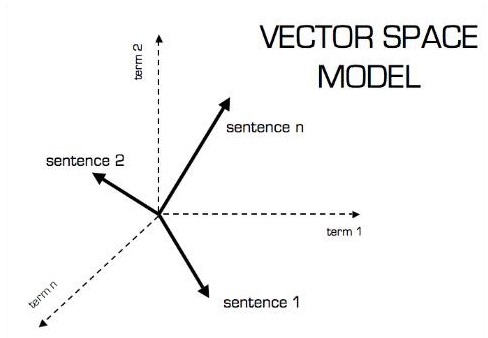
Escalar
El escalar se puede definir como un vector unidimensional. Los escalares son aquellos que incluyen solo magnitud y ninguna dirección. Con los escalares, solo nos preocupa la magnitud.
Los ejemplos de escalar incluyen parámetros de peso y altura de los niños.
Matriz
Matrix se puede definir como matrices multidimensionales, que se organizan en formato de filas y columnas. El tamaño de la matriz se define por la longitud de la fila y la longitud de la columna. La siguiente figura muestra la representación de cualquier matriz especificada.
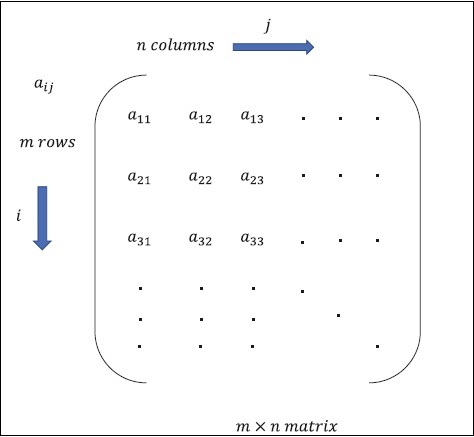
Considere la matriz con "m" filas y "n" columnas como se mencionó anteriormente, la representación de la matriz se especificará como "m * n matriz" que definió la longitud de la matriz también.
Cálculos matemáticos
En esta sección, aprenderemos sobre los diferentes cálculos matemáticos en TensorFlow.
Adición de matrices
Es posible sumar dos o más matrices si las matrices son de la misma dimensión. La adición implica la adición de cada elemento según la posición dada.
Considere el siguiente ejemplo para comprender cómo funciona la suma de matrices:
$$ Ejemplo: A = \ begin {bmatrix} 1 & 2 \\ 3 & 4 \ end {bmatrix} B = \ begin {bmatrix} 5 & 6 \\ 7 & 8 \ end {bmatrix} \: luego \: A + B = \ begin {bmatrix} 1 + 5 & 2 + 6 \\ 3 + 7 & 4 + 8 \ end {bmatrix} = \ begin {bmatrix} 6 & 8 \\ 10 & 12 \ end {bmatrix} $$
Resta de matrices
La resta de matrices opera de manera similar a la suma de dos matrices. El usuario puede restar dos matrices siempre que las dimensiones sean iguales.
$$ Ejemplo: A- \ begin {bmatrix} 1 & 2 \\ 3 & 4 \ end {bmatrix} B- \ begin {bmatrix} 5 & 6 \\ 7 & 8 \ end {bmatrix} \: luego \: AB - \ begin {bmatrix} 1-5 y 2-6 \\ 3-7 y 4-8 \ end {bmatrix} - \ begin {bmatrix} -4 y -4 \\ - 4 y -4 \ end {bmatrix} $$
Multiplicación de matrices
Para que dos matrices A m * n y B p * q sean multiplicables, n debe ser igual a p. La matriz resultante es -
C m * q
$$ A = \ begin {bmatrix} 1 & 2 \\ 3 & 4 \ end {bmatrix} B = \ begin {bmatrix} 5 & 6 \\ 7 & 8 \ end {bmatrix} $$
$$ c_ {11} = \ begin {bmatrix} 1 & 2 \ end {bmatrix} \ begin {bmatrix} 5 \\ 7 \ end {bmatrix} = 1 \ times5 + 2 \ times7 = 19 \: c_ {12} = \ begin {bmatrix} 1 & 2 \ end {bmatrix} \ begin {bmatrix} 6 \\ 8 \ end {bmatrix} = 1 \ times6 + 2 \ times8 = 22 $$
$$ c_ {21} = \ begin {bmatrix} 3 & 4 \ end {bmatrix} \ begin {bmatrix} 5 \\ 7 \ end {bmatrix} = 3 \ times5 + 4 \ times7 = 43 \: c_ {22} = \ begin {bmatrix} 3 & 4 \ end {bmatrix} \ begin {bmatrix} 6 \\ 8 \ end {bmatrix} = 3 \ times6 + 4 \ times8 = 50 $$
$$ C = \ begin {bmatrix} c_ {11} & c_ {12} \\ c_ {21} & c_ {22} \ end {bmatrix} = \ begin {bmatrix} 19 & 22 \\ 43 & 50 \ end {bmatrix} $$
Transposición de matriz
La transposición de una matriz A, m * n generalmente se representa mediante AT (transposición) n * my se obtiene transponiendo los vectores de columna como vectores de fila.
$$ Ejemplo: A = \ begin {bmatrix} 1 & 2 \\ 3 & 4 \ end {bmatrix} \: luego \: A ^ {T} \ begin {bmatrix} 1 & 3 \\ 2 & 4 \ end { bmatrix} $$
Producto escalar de vectores
Cualquier vector de dimensión n puede representarse como una matriz v = R ^ n * 1.
$$ v_ {1} = \ begin {bmatrix} v_ {11} \\ v_ {12} \\\ cdot \\\ cdot \\\ cdot \\ v_ {1n} \ end {bmatrix} v_ {2} = \ begin {bmatrix} v_ {21} \\ v_ {22} \\\ cdot \\\ cdot \\\ cdot \\ v_ {2n} \ end {bmatrix} $$
El producto escalar de dos vectores es la suma del producto de los componentes correspondientes - Componentes a lo largo de la misma dimensión y se puede expresar como
$$ v_ {1} \ cdot v_ {2} = v_1 ^ Tv_ {2} = v_2 ^ Tv_ {1} = v_ {11} v_ {21} + v_ {12} v_ {22} + \ cdot \ cdot + v_ {1n} v_ {2n} = \ Displaystyle \ sum \ limits_ {k = 1} ^ n v_ {1k} v_ {2k} $$
El ejemplo de producto escalar de vectores se menciona a continuación:
$$ Ejemplo: v_ {1} = \ begin {bmatrix} 1 \\ 2 \\ 3 \ end {bmatrix} v_ {2} = \ begin {bmatrix} 3 \\ 5 \\ - 1 \ end {bmatrix} v_ {1} \ cdot v_ {2} = v_1 ^ Tv_ {2} = 1 \ times3 + 2 \ times5-3 \ times1 = 10 $$
La inteligencia artificial es una de las tendencias más populares de los últimos tiempos. El aprendizaje automático y el aprendizaje profundo constituyen inteligencia artificial. El diagrama de Venn que se muestra a continuación explica la relación entre el aprendizaje automático y el aprendizaje profundo:
Aprendizaje automático
El aprendizaje automático es el arte de la ciencia de hacer que las computadoras actúen según los algoritmos diseñados y programados. Muchos investigadores piensan que el aprendizaje automático es la mejor manera de avanzar hacia la IA a nivel humano. El aprendizaje automático incluye los siguientes tipos de patrones
- Patrón de aprendizaje supervisado
- Patrón de aprendizaje no supervisado
Aprendizaje profundo
El aprendizaje profundo es un subcampo del aprendizaje automático en el que los algoritmos en cuestión se inspiran en la estructura y función del cerebro llamadas redes neuronales artificiales.
Todo el valor actual del aprendizaje profundo es a través del aprendizaje supervisado o el aprendizaje a partir de algoritmos y datos etiquetados.
Cada algoritmo en el aprendizaje profundo pasa por el mismo proceso. Incluye una jerarquía de transformación no lineal de entrada que se puede utilizar para generar un modelo estadístico como salida.
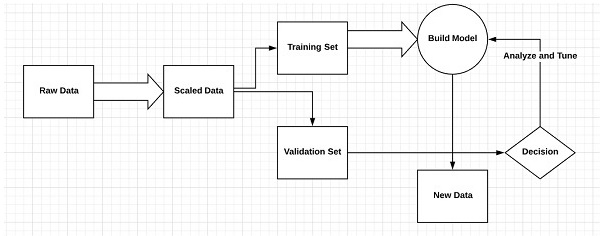
Considere los siguientes pasos que definen el proceso de aprendizaje automático
- Identifica conjuntos de datos relevantes y los prepara para su análisis.
- Elige el tipo de algoritmo a utilizar
- Construye un modelo analítico basado en el algoritmo utilizado.
- Entrena el modelo en conjuntos de datos de prueba y lo revisa según sea necesario.
- Ejecuta el modelo para generar puntajes de prueba.
Diferencia entre aprendizaje automático y aprendizaje profundo
En esta sección, aprenderemos sobre la diferencia entre Machine Learning y Deep Learning.
La cantidad de datos
El aprendizaje automático funciona con grandes cantidades de datos. También es útil para pequeñas cantidades de datos. El aprendizaje profundo, por otro lado, funciona de manera eficiente si la cantidad de datos aumenta rápidamente. El siguiente diagrama muestra el funcionamiento del aprendizaje automático y el aprendizaje profundo con la cantidad de datos:
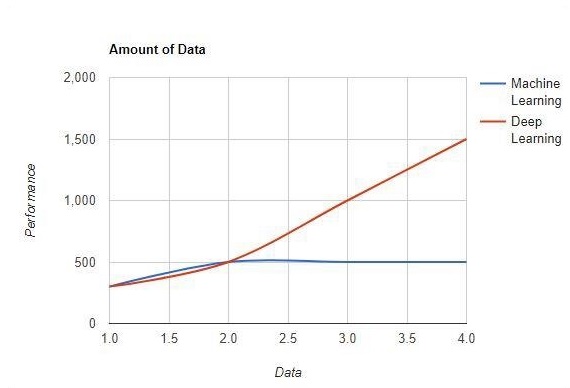
Dependencias de hardware
Los algoritmos de aprendizaje profundo están diseñados para depender en gran medida de máquinas de gama alta, a diferencia de los algoritmos tradicionales de aprendizaje automático. Los algoritmos de aprendizaje profundo realizan una serie de operaciones de multiplicación de matrices, que requieren una gran cantidad de soporte de hardware.
Ingeniería de funciones
La ingeniería de características es el proceso de poner el conocimiento del dominio en características específicas para reducir la complejidad de los datos y crear patrones que sean visibles para los algoritmos de aprendizaje que funcionan.
Ejemplo: los patrones tradicionales de aprendizaje automático se centran en píxeles y otros atributos necesarios para el proceso de ingeniería de características. Los algoritmos de aprendizaje profundo se centran en características de alto nivel a partir de datos. Reduce la tarea de desarrollar un extractor de nuevas características de cada nuevo problema.
Enfoque de resolución de problemas
Los algoritmos tradicionales de aprendizaje automático siguen un procedimiento estándar para resolver el problema. Divide el problema en partes, resuelve cada una de ellas y las combina para obtener el resultado requerido. El aprendizaje profundo se enfoca en resolver el problema de un extremo a otro en lugar de dividirlos en divisiones.
Tiempo de ejecución
El tiempo de ejecución es la cantidad de tiempo necesaria para entrenar un algoritmo. El aprendizaje profundo requiere mucho tiempo para entrenarse, ya que incluye muchos parámetros, lo que lleva más tiempo de lo habitual. El algoritmo de aprendizaje automático requiere comparativamente menos tiempo de ejecución.
Interpretabilidad
La interpretabilidad es el factor principal para comparar el aprendizaje automático y los algoritmos de aprendizaje profundo. La razón principal es que todavía se le da un segundo pensamiento al aprendizaje profundo antes de su uso en la industria.
Aplicaciones de Machine Learning y Deep Learning
En esta sección, conoceremos las diferentes aplicaciones de Machine Learning y Deep Learning.
Visión por computadora que se utiliza para el reconocimiento facial y marca de asistencia a través de huellas dactilares o identificación del vehículo a través de matrícula.
Recuperación de información de motores de búsqueda como búsqueda de texto para búsqueda de imágenes.
Marketing por correo electrónico automatizado con identificación de destino específica.
Diagnóstico médico de tumores cancerosos o identificación de anomalías de alguna enfermedad crónica.
Procesamiento de lenguaje natural para aplicaciones como etiquetado de fotografías. El mejor ejemplo para explicar este escenario se utiliza en Facebook.
Publicidad online.
Futuras tendencias
Con la creciente tendencia de usar ciencia de datos y aprendizaje automático en la industria, será importante para cada organización inculcar el aprendizaje automático en sus negocios.
El aprendizaje profundo está ganando más importancia que el aprendizaje automático. El aprendizaje profundo está demostrando ser una de las mejores técnicas en el desempeño de vanguardia.
El aprendizaje automático y el aprendizaje profundo resultarán beneficiosos en el campo académico y de la investigación.
Conclusión
En este artículo, tuvimos una descripción general del aprendizaje automático y el aprendizaje profundo con ilustraciones y diferencias que también se enfocan en las tendencias futuras. Muchas de las aplicaciones de IA utilizan algoritmos de aprendizaje automático principalmente para impulsar el autoservicio, aumentar la productividad de los agentes y los flujos de trabajo de forma más confiable. Los algoritmos de aprendizaje automático y aprendizaje profundo incluyen una perspectiva interesante para muchas empresas y líderes de la industria.
En este capítulo, aprenderemos los conceptos básicos de TensorFlow. Comenzaremos por comprender la estructura de datos del tensor.
Estructura de datos del tensor
Los tensores se utilizan como estructuras de datos básicas en el lenguaje TensorFlow. Los tensores representan los bordes de conexión en cualquier diagrama de flujo llamado Gráfico de flujo de datos. Los tensores se definen como matriz o lista multidimensional.
Los tensores se identifican mediante los siguientes tres parámetros:
Rango
La unidad de dimensionalidad descrita dentro del tensor se llama rango. Identifica el número de dimensiones del tensor. Un rango de un tensor se puede describir como el orden o las n dimensiones de un tensor definido.
Forma
El número de filas y columnas juntas define la forma de Tensor.
Tipo
Type describe el tipo de datos asignado a los elementos de Tensor.
Un usuario debe considerar las siguientes actividades para crear un tensor:
- Construye una matriz n-dimensional
- Convierta la matriz n-dimensional.
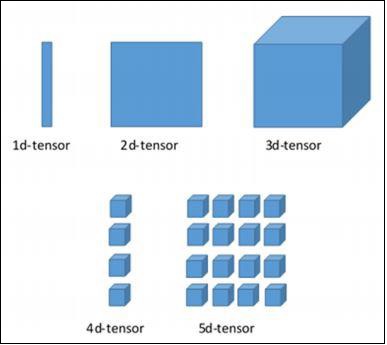
Varias dimensiones de TensorFlow
TensorFlow incluye varias dimensiones. Las dimensiones se describen brevemente a continuación:
Tensor unidimensional
El tensor unidimensional es una estructura de matriz normal que incluye un conjunto de valores del mismo tipo de datos.
Declaration
>>> import numpy as np
>>> tensor_1d = np.array([1.3, 1, 4.0, 23.99])
>>> print tensor_1dLa implementación con la salida se muestra en la captura de pantalla a continuación:
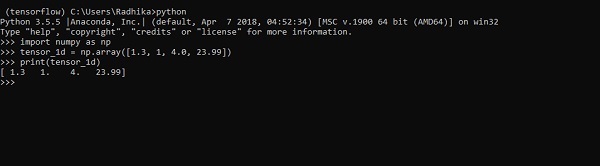
La indexación de elementos es la misma que la de las listas de Python. El primer elemento comienza con un índice de 0; para imprimir los valores a través del índice, todo lo que necesita hacer es mencionar el número de índice.
>>> print tensor_1d[0]
1.3
>>> print tensor_1d[2]
4.0
Tensores bidimensionales
La secuencia de matrices se utiliza para crear "tensores bidimensionales".
La creación de tensores bidimensionales se describe a continuación:

A continuación se muestra la sintaxis completa para crear matrices bidimensionales:
>>> import numpy as np
>>> tensor_2d = np.array([(1,2,3,4),(4,5,6,7),(8,9,10,11),(12,13,14,15)])
>>> print(tensor_2d)
[[ 1 2 3 4]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
>>>Los elementos específicos de los tensores bidimensionales se pueden rastrear con la ayuda del número de fila y el número de columna especificados como números de índice.
>>> tensor_2d[3][2]
14
Manejo y manipulaciones de tensores
En esta sección, aprenderemos sobre el manejo y las manipulaciones de tensor.
Para empezar, consideremos el siguiente código:
import tensorflow as tf
import numpy as np
matrix1 = np.array([(2,2,2),(2,2,2),(2,2,2)],dtype = 'int32')
matrix2 = np.array([(1,1,1),(1,1,1),(1,1,1)],dtype = 'int32')
print (matrix1)
print (matrix2)
matrix1 = tf.constant(matrix1)
matrix2 = tf.constant(matrix2)
matrix_product = tf.matmul(matrix1, matrix2)
matrix_sum = tf.add(matrix1,matrix2)
matrix_3 = np.array([(2,7,2),(1,4,2),(9,0,2)],dtype = 'float32')
print (matrix_3)
matrix_det = tf.matrix_determinant(matrix_3)
with tf.Session() as sess:
result1 = sess.run(matrix_product)
result2 = sess.run(matrix_sum)
result3 = sess.run(matrix_det)
print (result1)
print (result2)
print (result3)Output
El código anterior generará la siguiente salida:
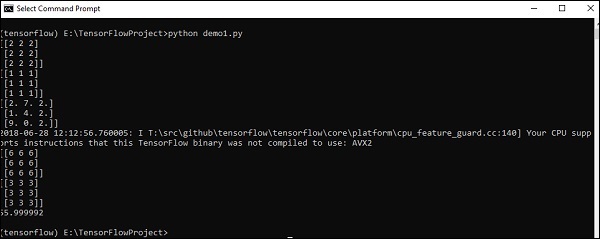
Explicación
Hemos creado matrices multidimensionales en el código fuente anterior. Ahora, es importante entender que creamos gráficos y sesiones, que administran los tensores y generan la salida adecuada. Con la ayuda del gráfico, tenemos la salida que especifica los cálculos matemáticos entre tensores.
Después de comprender los conceptos de aprendizaje automático, ahora podemos cambiar nuestro enfoque a los conceptos de aprendizaje profundo. El aprendizaje profundo es una división del aprendizaje automático y se considera un paso crucial dado por los investigadores en las últimas décadas. Los ejemplos de implementación de aprendizaje profundo incluyen aplicaciones como reconocimiento de imágenes y reconocimiento de voz.
A continuación se muestran los dos tipos importantes de redes neuronales profundas:
- Redes neuronales convolucionales
- Redes neuronales recurrentes
En este capítulo, nos centraremos en la CNN, Redes neuronales convolucionales.
Redes neuronales convolucionales
Las redes neuronales convolucionales están diseñadas para procesar datos a través de múltiples capas de arreglos. Este tipo de redes neuronales se utiliza en aplicaciones como el reconocimiento de imágenes o el reconocimiento facial. La principal diferencia entre CNN y cualquier otra red neuronal ordinaria es que CNN toma la entrada como una matriz bidimensional y opera directamente en las imágenes en lugar de enfocarse en la extracción de características en las que se enfocan otras redes neuronales.
El enfoque dominante de CNN incluye soluciones para problemas de reconocimiento. Las principales empresas como Google y Facebook han invertido en investigación y desarrollo hacia proyectos de reconocimiento para realizar actividades con mayor rapidez.
Una red neuronal convolucional utiliza tres ideas básicas:
- Campos respectivos locales
- Convolution
- Pooling
Entendamos estas ideas en detalle.
CNN utiliza correlaciones espaciales que existen dentro de los datos de entrada. Cada capa concurrente de una red neuronal conecta algunas neuronas de entrada. Esta región específica se llama campo receptivo local. El campo receptivo local se centra en las neuronas ocultas. Las neuronas ocultas procesan los datos de entrada dentro del campo mencionado sin darse cuenta de los cambios fuera del límite específico.
A continuación se muestra un diagrama de representación de la generación de campos respectivos locales:
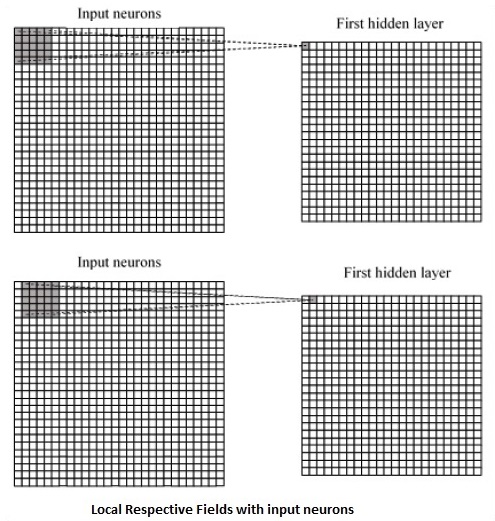
Si observamos la representación anterior, cada conexión aprende un peso de la neurona oculta con una conexión asociada con el movimiento de una capa a otra. Aquí, las neuronas individuales realizan un cambio de vez en cuando. Este proceso se llama "convolución".
El mapeo de conexiones desde la capa de entrada al mapa de características ocultas se define como "pesos compartidos" y el sesgo incluido se denomina "sesgo compartido".
CNN o las redes neuronales convolucionales utilizan capas de agrupación, que son las capas, colocadas inmediatamente después de la declaración de CNN. Toma la entrada del usuario como un mapa de características que proviene de redes convolucionales y prepara un mapa de características condensado. La agrupación de capas ayuda a crear capas con neuronas de capas anteriores.
Implementación de TensorFlow de CNN
En esta sección, aprenderemos sobre la implementación de TensorFlow de CNN. Los pasos, que requieren la ejecución y la dimensión adecuada de toda la red, son los que se muestran a continuación:
Step 1 - Incluya los módulos necesarios para TensorFlow y los módulos del conjunto de datos, que son necesarios para calcular el modelo CNN.
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_dataStep 2 - Declarar una función llamada run_cnn(), que incluye varios parámetros y variables de optimización con declaración de marcadores de posición de datos. Estas variables de optimización declararán el patrón de entrenamiento.
def run_cnn():
mnist = input_data.read_data_sets("MNIST_data/", one_hot = True)
learning_rate = 0.0001
epochs = 10
batch_size = 50Step 3 - En este paso, declararemos los marcadores de posición de datos de entrenamiento con parámetros de entrada - para 28 x 28 píxeles = 784. Estos son los datos de imagen acoplados que se extraen de mnist.train.nextbatch().
Podemos remodelar el tensor según nuestros requisitos. El primer valor (-1) le dice a la función que dé forma dinámica a esa dimensión en función de la cantidad de datos que se le pasan. Las dos dimensiones medias se establecen en el tamaño de la imagen (es decir, 28 x 28).
x = tf.placeholder(tf.float32, [None, 784])
x_shaped = tf.reshape(x, [-1, 28, 28, 1])
y = tf.placeholder(tf.float32, [None, 10])Step 4 - Ahora es importante crear algunas capas convolucionales -
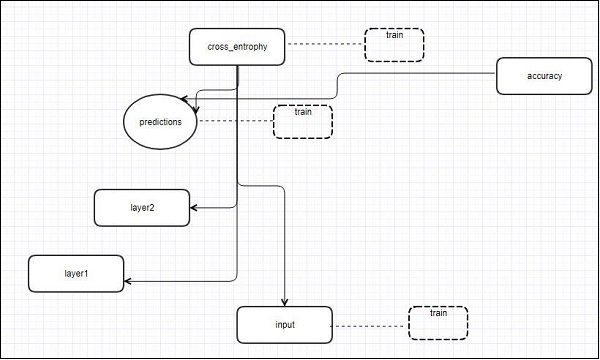
layer1 = create_new_conv_layer(x_shaped, 1, 32, [5, 5], [2, 2], name = 'layer1')
layer2 = create_new_conv_layer(layer1, 32, 64, [5, 5], [2, 2], name = 'layer2')Step 5- Aplanaremos la salida lista para la etapa de salida completamente conectada - después de dos capas de zancada 2 agrupadas con las dimensiones de 28 x 28, a una dimensión de 14 x 14 o un mínimo de 7 x 7 x, coordenadas y, pero con 64 canales de salida. Para crear la capa completamente conectada con "densa", la nueva forma debe ser [-1, 7 x 7 x 64]. Podemos configurar algunos pesos y valores de sesgo para esta capa, luego activar con ReLU.
flattened = tf.reshape(layer2, [-1, 7 * 7 * 64])
wd1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1000], stddev = 0.03), name = 'wd1')
bd1 = tf.Variable(tf.truncated_normal([1000], stddev = 0.01), name = 'bd1')
dense_layer1 = tf.matmul(flattened, wd1) + bd1
dense_layer1 = tf.nn.relu(dense_layer1)Step 6 - Otra capa con activaciones específicas de softmax con el optimizador requerido define la evaluación de precisión, que hace la configuración del operador de inicialización.
wd2 = tf.Variable(tf.truncated_normal([1000, 10], stddev = 0.03), name = 'wd2')
bd2 = tf.Variable(tf.truncated_normal([10], stddev = 0.01), name = 'bd2')
dense_layer2 = tf.matmul(dense_layer1, wd2) + bd2
y_ = tf.nn.softmax(dense_layer2)
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits = dense_layer2, labels = y))
optimiser = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
init_op = tf.global_variables_initializer()Step 7- Deberíamos configurar variables de grabación. Esto suma un resumen para almacenar la precisión de los datos.
tf.summary.scalar('accuracy', accuracy)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('E:\TensorFlowProject')
with tf.Session() as sess:
sess.run(init_op)
total_batch = int(len(mnist.train.labels) / batch_size)
for epoch in range(epochs):
avg_cost = 0
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size = batch_size)
_, c = sess.run([optimiser, cross_entropy], feed_dict = {
x:batch_x, y: batch_y})
avg_cost += c / total_batch
test_acc = sess.run(accuracy, feed_dict = {x: mnist.test.images, y:
mnist.test.labels})
summary = sess.run(merged, feed_dict = {x: mnist.test.images, y:
mnist.test.labels})
writer.add_summary(summary, epoch)
print("\nTraining complete!")
writer.add_graph(sess.graph)
print(sess.run(accuracy, feed_dict = {x: mnist.test.images, y:
mnist.test.labels}))
def create_new_conv_layer(
input_data, num_input_channels, num_filters,filter_shape, pool_shape, name):
conv_filt_shape = [
filter_shape[0], filter_shape[1], num_input_channels, num_filters]
weights = tf.Variable(
tf.truncated_normal(conv_filt_shape, stddev = 0.03), name = name+'_W')
bias = tf.Variable(tf.truncated_normal([num_filters]), name = name+'_b')
#Out layer defines the output
out_layer =
tf.nn.conv2d(input_data, weights, [1, 1, 1, 1], padding = 'SAME')
out_layer += bias
out_layer = tf.nn.relu(out_layer)
ksize = [1, pool_shape[0], pool_shape[1], 1]
strides = [1, 2, 2, 1]
out_layer = tf.nn.max_pool(
out_layer, ksize = ksize, strides = strides, padding = 'SAME')
return out_layer
if __name__ == "__main__":
run_cnn()A continuación se muestra la salida generada por el código anterior:
See @{tf.nn.softmax_cross_entropy_with_logits_v2}.
2018-09-19 17:22:58.802268: I
T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:140]
Your CPU supports instructions that this TensorFlow binary was not compiled to
use: AVX2
2018-09-19 17:25:41.522845: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 1003520000 exceeds 10% of system memory.
2018-09-19 17:25:44.630941: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
of 501760000 exceeds 10% of system memory.
Epoch: 1 cost = 0.676 test accuracy: 0.940
2018-09-19 17:26:51.987554: W
T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation
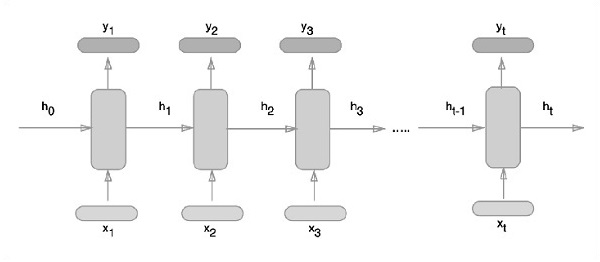
of 1003520000 exceeds 10% of system memory.Las redes neuronales recurrentes son un tipo de algoritmo orientado al aprendizaje profundo, que sigue un enfoque secuencial. En las redes neuronales, siempre asumimos que cada entrada y salida es independiente de todas las demás capas. Este tipo de redes neuronales se denominan recurrentes porque realizan cálculos matemáticos de manera secuencial.
Considere los siguientes pasos para entrenar una red neuronal recurrente:
Step 1 - Ingrese un ejemplo específico del conjunto de datos.
Step 2 - Network tomará un ejemplo y calculará algunos cálculos utilizando variables inicializadas aleatoriamente.
Step 3 - A continuación, se calcula un resultado previsto.
Step 4 - La comparación del resultado real generado con el valor esperado producirá un error.
Step 5 - Para rastrear el error, se propaga por el mismo camino donde también se ajustan las variables.
Step 6 - Se repiten los pasos del 1 al 5 hasta que estemos seguros de que las variables declaradas para obtener la salida están definidas correctamente.
Step 7 - Se realiza una predicción sistemática aplicando estas variables para obtener nuevas entradas invisibles.
El enfoque esquemático de representar redes neuronales recurrentes se describe a continuación:
Implementación recurrente de redes neuronales con TensorFlow
En esta sección, aprenderemos cómo implementar una red neuronal recurrente con TensorFlow.
Step 1 - TensorFlow incluye varias bibliotecas para la implementación específica del módulo de red neuronal recurrente.
#Import necessary modules
from __future__ import print_function
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)Como se mencionó anteriormente, las bibliotecas ayudan a definir los datos de entrada, que forman la parte principal de la implementación de la red neuronal recurrente.
Step 2- Nuestro motivo principal es clasificar las imágenes utilizando una red neuronal recurrente, donde consideramos cada fila de imágenes como una secuencia de píxeles. La forma de la imagen MNIST se define específicamente como 28 * 28 px. Ahora manejaremos 28 secuencias de 28 pasos para cada muestra que se menciona. Definiremos los parámetros de entrada para realizar el patrón secuencial.
n_input = 28 # MNIST data input with img shape 28*28
n_steps = 28
n_hidden = 128
n_classes = 10
# tf Graph input
x = tf.placeholder("float", [None, n_steps, n_input])
y = tf.placeholder("float", [None, n_classes]
weights = {
'out': tf.Variable(tf.random_normal([n_hidden, n_classes]))
}
biases = {
'out': tf.Variable(tf.random_normal([n_classes]))
}Step 3- Calcule los resultados utilizando una función definida en RNN para obtener los mejores resultados. Aquí, cada forma de datos se compara con la forma de entrada actual y los resultados se calculan para mantener la tasa de precisión.
def RNN(x, weights, biases):
x = tf.unstack(x, n_steps, 1)
# Define a lstm cell with tensorflow
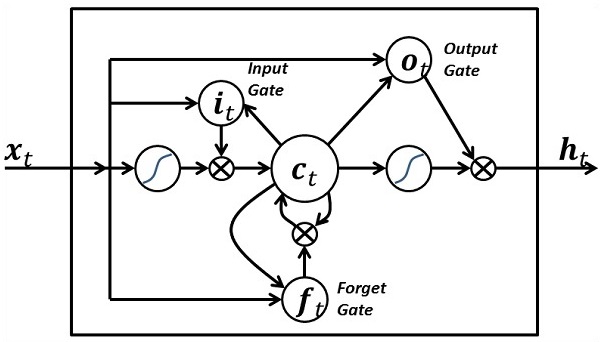
lstm_cell = rnn.BasicLSTMCell(n_hidden, forget_bias=1.0)
# Get lstm cell output
outputs, states = rnn.static_rnn(lstm_cell, x, dtype = tf.float32)
# Linear activation, using rnn inner loop last output
return tf.matmul(outputs[-1], weights['out']) + biases['out']
pred = RNN(x, weights, biases)
# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = pred, labels = y))
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
# Evaluate model
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initializing the variables
init = tf.global_variables_initializer()Step 4- En este paso, lanzaremos el gráfico para obtener los resultados computacionales. Esto también ayuda a calcular la precisión de los resultados de las pruebas.
with tf.Session() as sess:
sess.run(init)
step = 1
# Keep training until reach max iterations
while step * batch_size < training_iters:
batch_x, batch_y = mnist.train.next_batch(batch_size)
batch_x = batch_x.reshape((batch_size, n_steps, n_input))
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y})
if step % display_step == 0:
# Calculate batch accuracy
acc = sess.run(accuracy, feed_dict={x: batch_x, y: batch_y})
# Calculate batch loss
loss = sess.run(cost, feed_dict={x: batch_x, y: batch_y})
print("Iter " + str(step*batch_size) + ", Minibatch Loss= " + \
"{:.6f}".format(loss) + ", Training Accuracy= " + \
"{:.5f}".format(acc))
step += 1
print("Optimization Finished!")
test_len = 128
test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input))
test_label = mnist.test.labels[:test_len]
print("Testing Accuracy:", \
sess.run(accuracy, feed_dict={x: test_data, y: test_label}))Las capturas de pantalla a continuación muestran la salida generada:
TensorFlow incluye una herramienta de visualización, que se llama TensorBoard. Se utiliza para analizar el gráfico de flujo de datos y también para comprender los modelos de aprendizaje automático. La característica importante de TensorBoard incluye una vista de diferentes tipos de estadísticas sobre los parámetros y detalles de cualquier gráfico en alineación vertical.
La red neuronal profunda incluye hasta 36.000 nodos. TensorBoard ayuda a colapsar estos nodos en bloques de alto nivel y resaltar las estructuras idénticas. Esto permite un mejor análisis del gráfico centrándose en las secciones principales del gráfico de cálculo. Se dice que la visualización de TensorBoard es muy interactiva donde un usuario puede desplazar, hacer zoom y expandir los nodos para mostrar los detalles.
La siguiente representación del diagrama esquemático muestra el funcionamiento completo de la visualización de TensorBoard:
Los algoritmos colapsan los nodos en bloques de alto nivel y resaltan los grupos específicos con estructuras idénticas, que separan los nodos de alto grado. El TensorBoard así creado es útil y se trata igualmente importante para ajustar un modelo de aprendizaje automático. Esta herramienta de visualización está diseñada para el archivo de registro de configuración con información resumida y detalles que deben mostrarse.
Centrémonos en el ejemplo de demostración de visualización de TensorBoard con la ayuda del siguiente código:
import tensorflow as tf
# Constants creation for TensorBoard visualization
a = tf.constant(10,name = "a")
b = tf.constant(90,name = "b")
y = tf.Variable(a+b*2,name = 'y')
model = tf.initialize_all_variables() #Creation of model
with tf.Session() as session:
merged = tf.merge_all_summaries()
writer = tf.train.SummaryWriter("/tmp/tensorflowlogs",session.graph)
session.run(model)
print(session.run(y))La siguiente tabla muestra los diversos símbolos de visualización de TensorBoard utilizados para la representación del nodo:

La incrustación de palabras es el concepto de mapeo de objetos discretos como palabras a vectores y números reales. Es importante como entrada para el aprendizaje automático. El concepto incluye funciones estándar, que transforman efectivamente objetos de entrada discretos en vectores útiles.
La ilustración de muestra de la entrada de la inserción de palabras es la que se muestra a continuación:
blue: (0.01359, 0.00075997, 0.24608, ..., -0.2524, 1.0048, 0.06259)
blues: (0.01396, 0.11887, -0.48963, ..., 0.033483, -0.10007, 0.1158)
orange: (-0.24776, -0.12359, 0.20986, ..., 0.079717, 0.23865, -0.014213)
oranges: (-0.35609, 0.21854, 0.080944, ..., -0.35413, 0.38511, -0.070976)Word2vec
Word2vec es el enfoque más común utilizado para la técnica de incrustación de palabras sin supervisión. Entrena el modelo de tal manera que una palabra de entrada dada predice el contexto de la palabra usando skip -grams.
TensorFlow permite muchas formas de implementar este tipo de modelo con niveles cada vez mayores de sofisticación y optimización y utilizando conceptos de subprocesos múltiples y abstracciones de nivel superior.
import os
import math
import numpy as np
import tensorflow as tf
from tensorflow.contrib.tensorboard.plugins import projector
batch_size = 64
embedding_dimension = 5
negative_samples = 8
LOG_DIR = "logs/word2vec_intro"
digit_to_word_map = {
1: "One",
2: "Two",
3: "Three",
4: "Four",
5: "Five",
6: "Six",
7: "Seven",
8: "Eight",
9: "Nine"}
sentences = []
# Create two kinds of sentences - sequences of odd and even digits.
for i in range(10000):
rand_odd_ints = np.random.choice(range(1, 10, 2), 3)
sentences.append(" ".join([digit_to_word_map[r] for r in rand_odd_ints]))
rand_even_ints = np.random.choice(range(2, 10, 2), 3)
sentences.append(" ".join([digit_to_word_map[r] for r in rand_even_ints]))
# Map words to indices
word2index_map = {}
index = 0
for sent in sentences:
for word in sent.lower().split():
if word not in word2index_map:
word2index_map[word] = index
index += 1
index2word_map = {index: word for word, index in word2index_map.items()}
vocabulary_size = len(index2word_map)
# Generate skip-gram pairs
skip_gram_pairs = []
for sent in sentences:
tokenized_sent = sent.lower().split()
for i in range(1, len(tokenized_sent)-1):
word_context_pair = [[word2index_map[tokenized_sent[i-1]],
word2index_map[tokenized_sent[i+1]]], word2index_map[tokenized_sent[i]]]
skip_gram_pairs.append([word_context_pair[1], word_context_pair[0][0]])
skip_gram_pairs.append([word_context_pair[1], word_context_pair[0][1]])
def get_skipgram_batch(batch_size):
instance_indices = list(range(len(skip_gram_pairs)))
np.random.shuffle(instance_indices)
batch = instance_indices[:batch_size]
x = [skip_gram_pairs[i][0] for i in batch]
y = [[skip_gram_pairs[i][1]] for i in batch]
return x, y
# batch example
x_batch, y_batch = get_skipgram_batch(8)
x_batch
y_batch
[index2word_map[word] for word in x_batch] [index2word_map[word[0]] for word in y_batch]
# Input data, labels train_inputs = tf.placeholder(tf.int32, shape = [batch_size])
train_labels = tf.placeholder(tf.int32, shape = [batch_size, 1])
# Embedding lookup table currently only implemented in CPU with
tf.name_scope("embeddings"):
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_dimension], -1.0, 1.0),
name = 'embedding')
# This is essentialy a lookup table
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
# Create variables for the NCE loss
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_dimension], stddev = 1.0 /
math.sqrt(embedding_dimension)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
loss = tf.reduce_mean(
tf.nn.nce_loss(weights = nce_weights, biases = nce_biases, inputs = embed,
labels = train_labels,num_sampled = negative_samples,
num_classes = vocabulary_size)) tf.summary.scalar("NCE_loss", loss)
# Learning rate decay
global_step = tf.Variable(0, trainable = False)
learningRate = tf.train.exponential_decay(learning_rate = 0.1,
global_step = global_step, decay_steps = 1000, decay_rate = 0.95, staircase = True)
train_step = tf.train.GradientDescentOptimizer(learningRate).minimize(loss)
merged = tf.summary.merge_all()
with tf.Session() as sess:
train_writer = tf.summary.FileWriter(LOG_DIR,
graph = tf.get_default_graph())
saver = tf.train.Saver()
with open(os.path.join(LOG_DIR, 'metadata.tsv'), "w") as metadata:
metadata.write('Name\tClass\n') for k, v in index2word_map.items():
metadata.write('%s\t%d\n' % (v, k))
config = projector.ProjectorConfig()
embedding = config.embeddings.add() embedding.tensor_name = embeddings.name
# Link this tensor to its metadata file (e.g. labels).
embedding.metadata_path = os.path.join(LOG_DIR, 'metadata.tsv')
projector.visualize_embeddings(train_writer, config)
tf.global_variables_initializer().run()
for step in range(1000):
x_batch, y_batch = get_skipgram_batch(batch_size) summary, _ = sess.run(
[merged, train_step], feed_dict = {train_inputs: x_batch, train_labels: y_batch})
train_writer.add_summary(summary, step)
if step % 100 == 0:
saver.save(sess, os.path.join(LOG_DIR, "w2v_model.ckpt"), step)
loss_value = sess.run(loss, feed_dict = {
train_inputs: x_batch, train_labels: y_batch})
print("Loss at %d: %.5f" % (step, loss_value))
# Normalize embeddings before using
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims = True))
normalized_embeddings = embeddings /
norm normalized_embeddings_matrix = sess.run(normalized_embeddings)
ref_word = normalized_embeddings_matrix[word2index_map["one"]]
cosine_dists = np.dot(normalized_embeddings_matrix, ref_word)
ff = np.argsort(cosine_dists)[::-1][1:10] for f in ff: print(index2word_map[f])
print(cosine_dists[f])Salida
El código anterior genera la siguiente salida:
Para comprender el perceptrón de una sola capa, es importante comprender las redes neuronales artificiales (ANN). Las redes neuronales artificiales son el sistema de procesamiento de información cuyo mecanismo se inspira en la funcionalidad de los circuitos neuronales biológicos. Una red neuronal artificial posee muchas unidades de procesamiento conectadas entre sí. A continuación se muestra la representación esquemática de la red neuronal artificial:
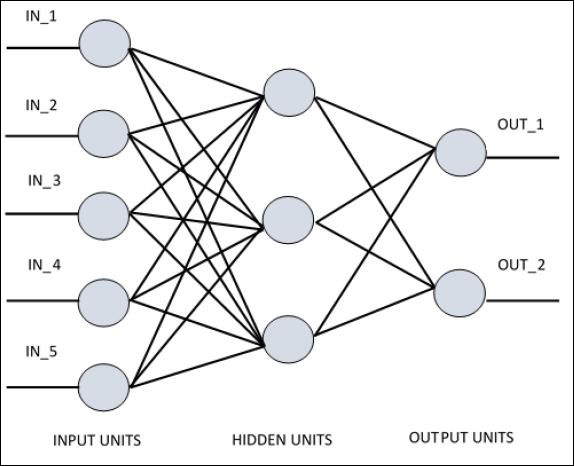
El diagrama muestra que las unidades ocultas se comunican con la capa externa. Mientras que las unidades de entrada y salida se comunican solo a través de la capa oculta de la red.
El patrón de conexión con los nodos, el número total de capas y el nivel de nodos entre las entradas y salidas con el número de neuronas por capa definen la arquitectura de una red neuronal.
Hay dos tipos de arquitectura. Estos tipos se centran en la funcionalidad de las redes neuronales artificiales de la siguiente manera:
- Perceptrón de una sola capa
- Perceptrón multicapa
Perceptrón de una sola capa
El perceptrón de capa única es el primer modelo neuronal propuesto creado. El contenido de la memoria local de la neurona consiste en un vector de pesos. El cálculo de un perceptrón de una sola capa se realiza sobre el cálculo de la suma del vector de entrada, cada uno con el valor multiplicado por el elemento correspondiente del vector de los pesos. El valor que se muestra en la salida será la entrada de una función de activación.

Centrémonos en la implementación del perceptrón de una sola capa para un problema de clasificación de imágenes con TensorFlow. El mejor ejemplo para ilustrar el perceptrón de una sola capa es a través de la representación de "Regresión logística".
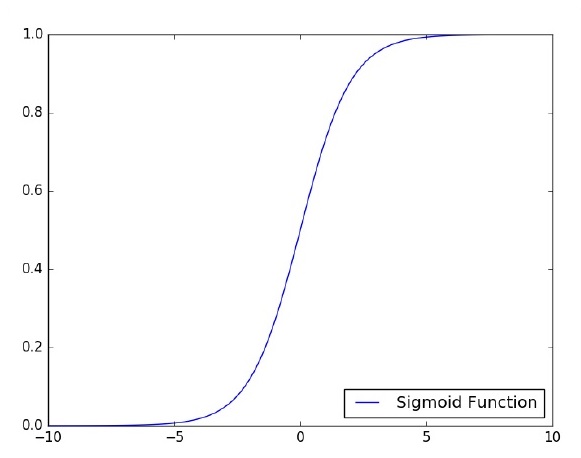
Ahora, consideremos los siguientes pasos básicos para entrenar la regresión logística:
Los pesos se inicializan con valores aleatorios al comienzo del entrenamiento.
Para cada elemento del conjunto de entrenamiento, el error se calcula con la diferencia entre la salida deseada y la salida real. El error calculado se utiliza para ajustar los pesos.
El proceso se repite hasta que el error cometido en todo el conjunto de entrenamiento no es menor que el umbral especificado, hasta que se alcanza el número máximo de iteraciones.
El código completo para la evaluación de la regresión logística se menciona a continuación:
# Import MINST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
import tensorflow as tf
import matplotlib.pyplot as plt
# Parameters
learning_rate = 0.01
training_epochs = 25
batch_size = 100
display_step = 1
# tf Graph Input
x = tf.placeholder("float", [None, 784]) # mnist data image of shape 28*28 = 784
y = tf.placeholder("float", [None, 10]) # 0-9 digits recognition => 10 classes
# Create model
# Set model weights
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# Construct model
activation = tf.nn.softmax(tf.matmul(x, W) + b) # Softmax
# Minimize error using cross entropy
cross_entropy = y*tf.log(activation)
cost = tf.reduce_mean\ (-tf.reduce_sum\ (cross_entropy,reduction_indices = 1))
optimizer = tf.train.\ GradientDescentOptimizer(learning_rate).minimize(cost)
#Plot settings
avg_set = []
epoch_set = []
# Initializing the variables init = tf.initialize_all_variables()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = \ mnist.train.next_batch(batch_size)
# Fit training using batch data sess.run(optimizer, \ feed_dict = {
x: batch_xs, y: batch_ys})
# Compute average loss avg_cost += sess.run(cost, \ feed_dict = {
x: batch_xs, \ y: batch_ys})/total_batch
# Display logs per epoch step
if epoch % display_step == 0:
print ("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost))
avg_set.append(avg_cost) epoch_set.append(epoch+1)
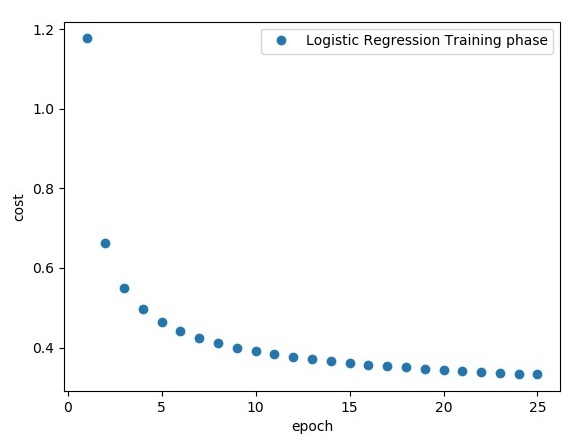
print ("Training phase finished")
plt.plot(epoch_set,avg_set, 'o', label = 'Logistic Regression Training phase')
plt.ylabel('cost')
plt.xlabel('epoch')
plt.legend()
plt.show()
# Test model
correct_prediction = tf.equal(tf.argmax(activation, 1), tf.argmax(y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) print
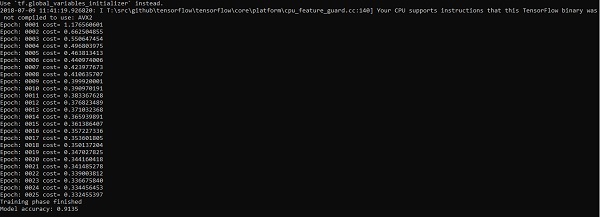
("Model accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))Salida
El código anterior genera la siguiente salida:
La regresión logística se considera un análisis predictivo. La regresión logística se utiliza para describir datos y explicar la relación entre una variable binaria dependiente y una o más variables nominales o independientes.
En este capítulo, nos centraremos en el ejemplo básico de implementación de regresión lineal con TensorFlow. La regresión logística o regresión lineal es un enfoque de aprendizaje automático supervisado para la clasificación de categorías discretas de orden. Nuestro objetivo en este capítulo es construir un modelo mediante el cual un usuario pueda predecir la relación entre las variables predictoras y una o más variables independientes.
La relación entre estas dos variables se considera lineal. Si y es la variable dependiente y x se considera la variable independiente, entonces la relación de regresión lineal de dos variables se verá como la siguiente ecuación:
Y = Ax+bDiseñaremos un algoritmo de regresión lineal. Esto nos permitirá comprender los siguientes dos conceptos importantes:
- Función de costo
- Algoritmos de descenso de gradientes
La representación esquemática de la regresión lineal se menciona a continuación:

La vista gráfica de la ecuación de regresión lineal se menciona a continuación:
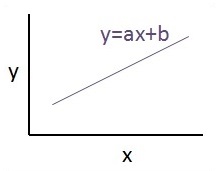
Pasos para diseñar un algoritmo de regresión lineal
Ahora aprenderemos sobre los pasos que ayudan a diseñar un algoritmo para regresión lineal.
Paso 1
Es importante importar los módulos necesarios para trazar el módulo de regresión lineal. Comenzamos a importar la biblioteca Python NumPy y Matplotlib.
import numpy as np
import matplotlib.pyplot as pltPaso 2
Defina el número de coeficientes necesarios para la regresión logística.
number_of_points = 500
x_point = []
y_point = []
a = 0.22
b = 0.78Paso 3
Itere las variables para generar 300 puntos aleatorios alrededor de la ecuación de regresión -
Y = 0,22x + 0,78
for i in range(number_of_points):
x = np.random.normal(0.0,0.5)
y = a*x + b +np.random.normal(0.0,0.1) x_point.append([x])
y_point.append([y])Etapa 4
Vea los puntos generados usando Matplotlib.
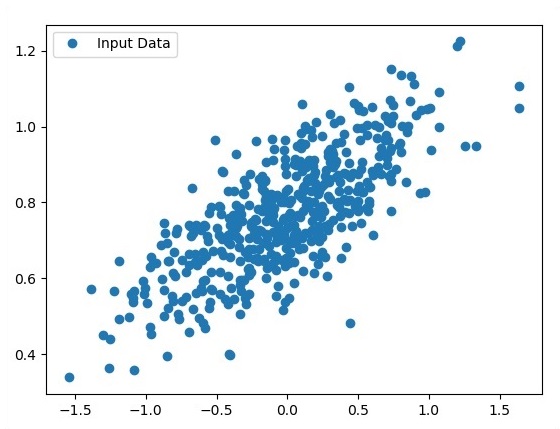
fplt.plot(x_point,y_point, 'o', label = 'Input Data') plt.legend() plt.show()El código completo para la regresión logística es el siguiente:
import numpy as np
import matplotlib.pyplot as plt
number_of_points = 500
x_point = []
y_point = []
a = 0.22
b = 0.78
for i in range(number_of_points):
x = np.random.normal(0.0,0.5)
y = a*x + b +np.random.normal(0.0,0.1) x_point.append([x])
y_point.append([y])
plt.plot(x_point,y_point, 'o', label = 'Input Data') plt.legend()
plt.show()El número de puntos que se toman como entrada se considera como datos de entrada.
TFLearn se puede definir como un aspecto de aprendizaje profundo modular y transparente que se usa en el marco de TensorFlow. El motivo principal de TFLearn es proporcionar una API de nivel superior a TensorFlow para facilitar y mostrar nuevos experimentos.
Considere las siguientes características importantes de TFLearn:
TFLearn es fácil de usar y comprender.
Incluye conceptos sencillos para construir capas de red altamente modulares, optimizadores y varias métricas integradas en ellos.
Incluye transparencia total con el sistema de trabajo TensorFlow.
Incluye potentes funciones de ayuda para entrenar los tensores integrados que aceptan múltiples entradas, salidas y optimizadores.
Incluye una visualización de gráficos fácil y hermosa.
La visualización del gráfico incluye varios detalles de pesos, gradientes y activaciones.
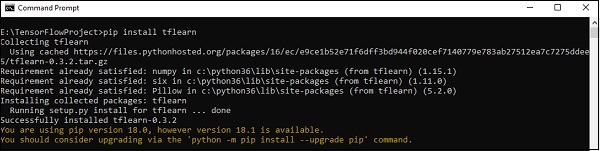
Instale TFLearn ejecutando el siguiente comando:
pip install tflearnTras la ejecución del código anterior, se generará la siguiente salida:
La siguiente ilustración muestra la implementación de TFLearn con el clasificador Random Forest -
from __future__ import division, print_function, absolute_import
#TFLearn module implementation
import tflearn
from tflearn.estimators import RandomForestClassifier
# Data loading and pre-processing with respect to dataset
import tflearn.datasets.mnist as mnist
X, Y, testX, testY = mnist.load_data(one_hot = False)
m = RandomForestClassifier(n_estimators = 100, max_nodes = 1000)
m.fit(X, Y, batch_size = 10000, display_step = 10)
print("Compute the accuracy on train data:")
print(m.evaluate(X, Y, tflearn.accuracy_op))
print("Compute the accuracy on test set:")
print(m.evaluate(testX, testY, tflearn.accuracy_op))
print("Digits for test images id 0 to 5:")
print(m.predict(testX[:5]))
print("True digits:")
print(testY[:5])En este capítulo, nos centraremos en la diferencia entre CNN y RNN:
| CNN | RNN |
|---|---|
| Es adecuado para datos espaciales como imágenes. | RNN es adecuado para datos temporales, también llamados datos secuenciales. |
| Se considera que CNN es más poderoso que RNN. | RNN incluye menos compatibilidad de funciones en comparación con CNN. |
| Esta red toma entradas de tamaño fijo y genera salidas de tamaño fijo. | RNN puede manejar longitudes de entrada / salida arbitrarias. |
| CNN es un tipo de red neuronal artificial de retroalimentación con variaciones de perceptrones multicapa diseñados para utilizar cantidades mínimas de preprocesamiento. | RNN, a diferencia de las redes neuronales de alimentación directa, puede utilizar su memoria interna para procesar secuencias arbitrarias de entradas. |
| Las CNN utilizan un patrón de conectividad entre las neuronas. Esto está inspirado en la organización de la corteza visual animal, cuyas neuronas individuales están dispuestas de tal manera que responden a regiones superpuestas que embaldosan el campo visual. | Las redes neuronales recurrentes utilizan información de series de tiempo: lo que un usuario habló por última vez tendrá un impacto en lo que hablará a continuación. |
| Las CNN son ideales para el procesamiento de imágenes y videos. | Los RNN son ideales para el análisis de texto y voz. |
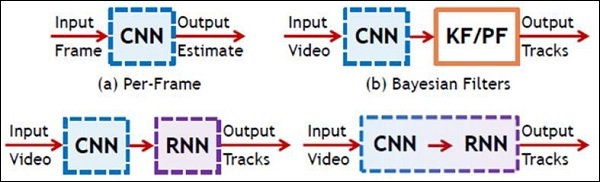
La siguiente ilustración muestra la representación esquemática de CNN y RNN:
Keras es una biblioteca de Python compacta, fácil de aprender y de alto nivel que se ejecuta sobre el marco de trabajo TensorFlow. Está hecho con un enfoque en la comprensión de técnicas de aprendizaje profundo, como la creación de capas para redes neuronales manteniendo los conceptos de formas y detalles matemáticos. La creación de freamework puede ser de los siguientes dos tipos:
- API secuencial
- API funcional
Considere los siguientes ocho pasos para crear un modelo de aprendizaje profundo en Keras:
- Cargando los datos
- Preprocesar los datos cargados
- Definición de modelo
- Compilando el modelo
- Ajustar el modelo especificado
- Evaluarlo
- Haz las predicciones requeridas
- Guardar el modelo
Usaremos Jupyter Notebook para ejecutar y mostrar la salida como se muestra a continuación:
Step 1 - La carga de los datos y el preprocesamiento de los datos cargados se implementa primero para ejecutar el modelo de aprendizaje profundo.
import warnings
warnings.filterwarnings('ignore')
import numpy as np
np.random.seed(123) # for reproducibility
from keras.models import Sequential
from keras.layers import Flatten, MaxPool2D, Conv2D, Dense, Reshape, Dropout
from keras.utils import np_utils
Using TensorFlow backend.
from keras.datasets import mnist
# Load pre-shuffled MNIST data into train and test sets
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1)
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
Y_train = np_utils.to_categorical(y_train, 10)
Y_test = np_utils.to_categorical(y_test, 10)Este paso se puede definir como "Importar bibliotecas y módulos", lo que significa que todas las bibliotecas y módulos se importan como paso inicial.
Step 2 - En este paso, definiremos la arquitectura del modelo -
model = Sequential()
model.add(Conv2D(32, 3, 3, activation = 'relu', input_shape = (28,28,1)))
model.add(Conv2D(32, 3, 3, activation = 'relu'))
model.add(MaxPool2D(pool_size = (2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation = 'relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation = 'softmax'))Step 3 - Ahora compilemos el modelo especificado -
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])Step 4 - Ahora ajustaremos el modelo usando datos de entrenamiento -
model.fit(X_train, Y_train, batch_size = 32, epochs = 10, verbose = 1)La salida de las iteraciones creadas es la siguiente:
Epoch 1/10 60000/60000 [==============================] - 65s -
loss: 0.2124 -
acc: 0.9345
Epoch 2/10 60000/60000 [==============================] - 62s -
loss: 0.0893 -
acc: 0.9740
Epoch 3/10 60000/60000 [==============================] - 58s -
loss: 0.0665 -
acc: 0.9802
Epoch 4/10 60000/60000 [==============================] - 62s -
loss: 0.0571 -
acc: 0.9830
Epoch 5/10 60000/60000 [==============================] - 62s -
loss: 0.0474 -
acc: 0.9855
Epoch 6/10 60000/60000 [==============================] - 59s -
loss: 0.0416 -
acc: 0.9871
Epoch 7/10 60000/60000 [==============================] - 61s -
loss: 0.0380 -
acc: 0.9877
Epoch 8/10 60000/60000 [==============================] - 63s -
loss: 0.0333 -
acc: 0.9895
Epoch 9/10 60000/60000 [==============================] - 64s -
loss: 0.0325 -
acc: 0.9898
Epoch 10/10 60000/60000 [==============================] - 60s -
loss: 0.0284 -
acc: 0.9910Este capítulo se centrará en cómo empezar con TensorFlow distribuido. El objetivo es ayudar a los desarrolladores a comprender los conceptos básicos de TF distribuida que son recurrentes, como los servidores TF. Usaremos Jupyter Notebook para evaluar TensorFlow distribuido. La implementación de la computación distribuida con TensorFlow se menciona a continuación:
Step 1 - Importar los módulos necesarios obligatorios para la computación distribuida -
import tensorflow as tfStep 2- Crea un clúster de TensorFlow con un nodo. Deje que este nodo sea responsable de un trabajo que tiene el nombre "trabajador" y que operará una toma en localhost: 2222.
cluster_spec = tf.train.ClusterSpec({'worker' : ['localhost:2222']})
server = tf.train.Server(cluster_spec)
server.targetLos scripts anteriores generan la siguiente salida:
'grpc://localhost:2222'
The server is currently running.Step 3 - La configuración del servidor con la sesión respectiva se puede calcular ejecutando el siguiente comando -
server.server_defEl comando anterior genera la siguiente salida:
cluster {
job {
name: "worker"
tasks {
value: "localhost:2222"
}
}
}
job_name: "worker"
protocol: "grpc"Step 4- Inicie una sesión de TensorFlow con el motor de ejecución como servidor. Usa TensorFlow para crear un servidor local y usalsof para averiguar la ubicación del servidor.
sess = tf.Session(target = server.target)
server = tf.train.Server.create_local_server()Step 5 - Ver los dispositivos disponibles en esta sesión y cerrar la sesión respectiva.
devices = sess.list_devices()
for d in devices:
print(d.name)
sess.close()El comando anterior genera la siguiente salida:
/job:worker/replica:0/task:0/device:CPU:0Aquí, nos centraremos en la formación de MetaGraph en TensorFlow. Esto nos ayudará a comprender el módulo de exportación en TensorFlow. El MetaGraph contiene la información básica, que se requiere para entrenar, realizar una evaluación o ejecutar inferencias en un gráfico previamente entrenado.
A continuación se muestra el fragmento de código para el mismo:
def export_meta_graph(filename = None, collection_list = None, as_text = False):
"""this code writes `MetaGraphDef` to save_path/filename.
Arguments:
filename: Optional meta_graph filename including the path. collection_list:
List of string keys to collect. as_text: If `True`,
writes the meta_graph as an ASCII proto.
Returns:
A `MetaGraphDef` proto. """Uno de los modelos de uso típicos para el mismo se menciona a continuación:
# Build the model ...
with tf.Session() as sess:
# Use the model ...
# Export the model to /tmp/my-model.meta.
meta_graph_def = tf.train.export_meta_graph(filename = '/tmp/my-model.meta')El perceptrón multicapa define la arquitectura más complicada de las redes neuronales artificiales. Está sustancialmente formado por múltiples capas de perceptrón.
La representación esquemática del aprendizaje del perceptrón multicapa es como se muestra a continuación:
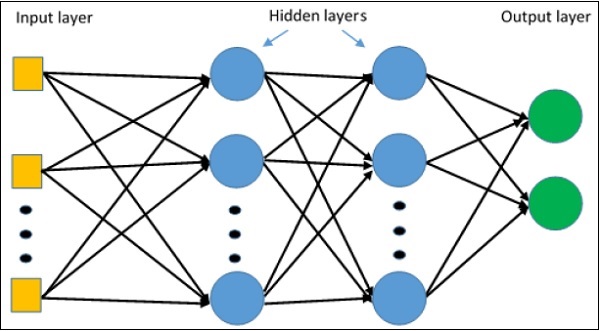
Las redes MLP se utilizan generalmente para el formato de aprendizaje supervisado. Un algoritmo de aprendizaje típico para redes MLP también se denomina algoritmo de retropropagación.
Ahora, nos centraremos en la implementación con MLP para un problema de clasificación de imágenes.
# Import MINST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot = True)
import tensorflow as tf
import matplotlib.pyplot as plt
# Parameters
learning_rate = 0.001
training_epochs = 20
batch_size = 100
display_step = 1
# Network Parameters
n_hidden_1 = 256
# 1st layer num features
n_hidden_2 = 256 # 2nd layer num features
n_input = 784 # MNIST data input (img shape: 28*28) n_classes = 10
# MNIST total classes (0-9 digits)
# tf Graph input
x = tf.placeholder("float", [None, n_input])
y = tf.placeholder("float", [None, n_classes])
# weights layer 1
h = tf.Variable(tf.random_normal([n_input, n_hidden_1])) # bias layer 1
bias_layer_1 = tf.Variable(tf.random_normal([n_hidden_1]))
# layer 1 layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, h), bias_layer_1))
# weights layer 2
w = tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2]))
# bias layer 2
bias_layer_2 = tf.Variable(tf.random_normal([n_hidden_2]))
# layer 2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, w), bias_layer_2))
# weights output layer
output = tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
# biar output layer
bias_output = tf.Variable(tf.random_normal([n_classes])) # output layer
output_layer = tf.matmul(layer_2, output) + bias_output
# cost function
cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(
logits = output_layer, labels = y))
#cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(output_layer, y))
# optimizer
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
# optimizer = tf.train.GradientDescentOptimizer(
learning_rate = learning_rate).minimize(cost)
# Plot settings
avg_set = []
epoch_set = []
# Initializing the variables
init = tf.global_variables_initializer()
# Launch the graph
with tf.Session() as sess:
sess.run(init)
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples / batch_size)
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# Fit training using batch data sess.run(optimizer, feed_dict = {
x: batch_xs, y: batch_ys})
# Compute average loss
avg_cost += sess.run(cost, feed_dict = {x: batch_xs, y: batch_ys}) / total_batch
# Display logs per epoch step
if epoch % display_step == 0:
print
Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(avg_cost)
avg_set.append(avg_cost)
epoch_set.append(epoch + 1)
print
"Training phase finished"
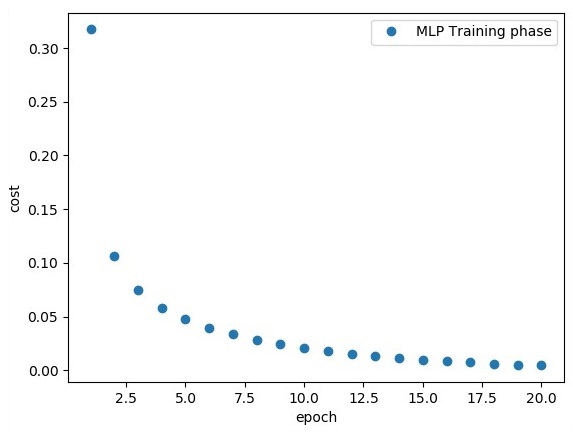
plt.plot(epoch_set, avg_set, 'o', label = 'MLP Training phase')
plt.ylabel('cost')
plt.xlabel('epoch')
plt.legend()
plt.show()
# Test model
correct_prediction = tf.equal(tf.argmax(output_layer, 1), tf.argmax(y, 1))
# Calculate accuracy
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print
"Model Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels})La línea de código anterior genera el siguiente resultado:
En este capítulo, nos centraremos en la red que tendremos que aprender de un conjunto conocido de puntos llamados xyf (x). Una sola capa oculta construirá esta simple red.
El código para la explicación de las capas ocultas de perceptrón es como se muestra a continuación:
#Importing the necessary modules
import tensorflow as tf
import numpy as np
import math, random
import matplotlib.pyplot as plt
np.random.seed(1000)
function_to_learn = lambda x: np.cos(x) + 0.1*np.random.randn(*x.shape)
layer_1_neurons = 10
NUM_points = 1000
#Training the parameters
batch_size = 100
NUM_EPOCHS = 1500
all_x = np.float32(np.random.uniform(-2*math.pi, 2*math.pi, (1, NUM_points))).T
np.random.shuffle(all_x)
train_size = int(900)
#Training the first 700 points in the given set x_training = all_x[:train_size]
y_training = function_to_learn(x_training)
#Training the last 300 points in the given set x_validation = all_x[train_size:]
y_validation = function_to_learn(x_validation)
plt.figure(1)
plt.scatter(x_training, y_training, c = 'blue', label = 'train')
plt.scatter(x_validation, y_validation, c = 'pink', label = 'validation')
plt.legend()
plt.show()
X = tf.placeholder(tf.float32, [None, 1], name = "X")
Y = tf.placeholder(tf.float32, [None, 1], name = "Y")
#first layer
#Number of neurons = 10
w_h = tf.Variable(
tf.random_uniform([1, layer_1_neurons],\ minval = -1, maxval = 1, dtype = tf.float32))
b_h = tf.Variable(tf.zeros([1, layer_1_neurons], dtype = tf.float32))
h = tf.nn.sigmoid(tf.matmul(X, w_h) + b_h)
#output layer
#Number of neurons = 10
w_o = tf.Variable(
tf.random_uniform([layer_1_neurons, 1],\ minval = -1, maxval = 1, dtype = tf.float32))
b_o = tf.Variable(tf.zeros([1, 1], dtype = tf.float32))
#build the model
model = tf.matmul(h, w_o) + b_o
#minimize the cost function (model - Y)
train_op = tf.train.AdamOptimizer().minimize(tf.nn.l2_loss(model - Y))
#Start the Learning phase
sess = tf.Session() sess.run(tf.initialize_all_variables())
errors = []
for i in range(NUM_EPOCHS):
for start, end in zip(range(0, len(x_training), batch_size),\
range(batch_size, len(x_training), batch_size)):
sess.run(train_op, feed_dict = {X: x_training[start:end],\ Y: y_training[start:end]})
cost = sess.run(tf.nn.l2_loss(model - y_validation),\ feed_dict = {X:x_validation})
errors.append(cost)
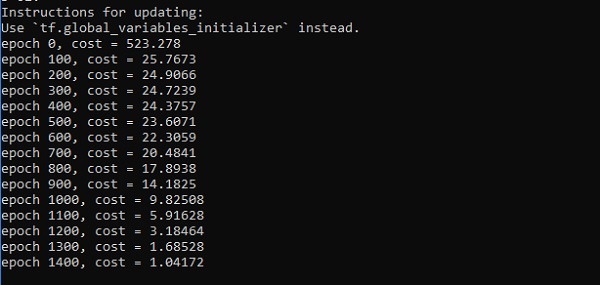
if i%100 == 0:
print("epoch %d, cost = %g" % (i, cost))
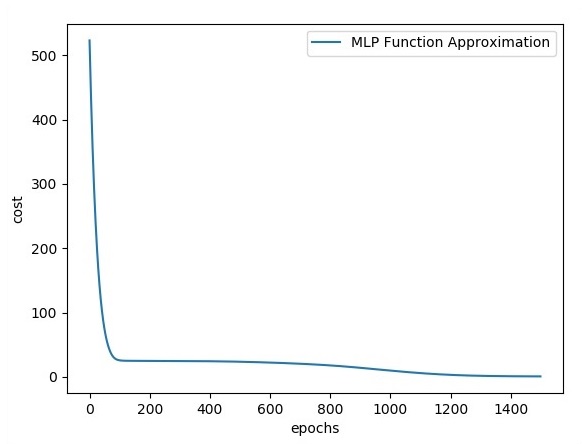
plt.plot(errors,label='MLP Function Approximation') plt.xlabel('epochs')
plt.ylabel('cost')
plt.legend()
plt.show()Salida
A continuación se muestra la representación de la aproximación de la capa de función:
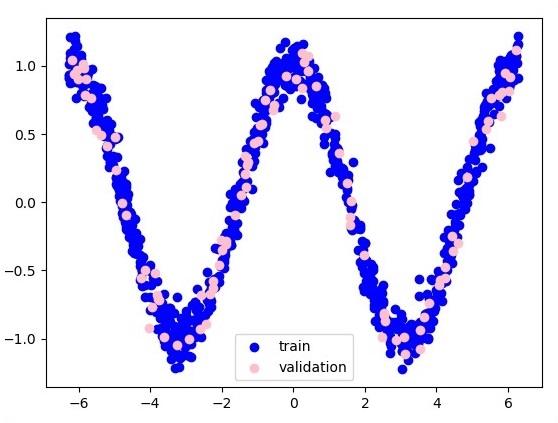
Aquí dos datos están representados en forma de W. Los dos datos son: tren y validación que están representados en distintos colores como se ve en la sección de leyenda.
Los optimizadores son la clase extendida, que incluyen información adicional para entrenar un modelo específico. La clase del optimizador se inicializa con los parámetros dados, pero es importante recordar que no se necesita ningún tensor. Los optimizadores se utilizan para mejorar la velocidad y el rendimiento para entrenar un modelo específico.
El optimizador básico de TensorFlow es:
tf.train.OptimizerEsta clase se define en la ruta especificada de tensorflow / python / training / optimizer.py.
A continuación se muestran algunos optimizadores en Tensorflow:
- Descenso de gradiente estocástico
- Descenso de gradiente estocástico con recorte de gradiente
- Momentum
- El impulso de Nesterov
- Adagrad
- Adadelta
- RMSProp
- Adam
- Adamax
- SMORMS3
Nos centraremos en el descenso del gradiente estocástico. La ilustración para crear optimizador para el mismo se menciona a continuación:
def sgd(cost, params, lr = np.float32(0.01)):
g_params = tf.gradients(cost, params)
updates = []
for param, g_param in zip(params, g_params):
updates.append(param.assign(param - lr*g_param))
return updatesLos parámetros básicos se definen dentro de la función específica. En nuestro capítulo siguiente, nos centraremos en la optimización del descenso de gradientes con la implementación de optimizadores.
En este capítulo, aprenderemos sobre la implementación de XOR usando TensorFlow. Antes de comenzar con la implementación de XOR en TensorFlow, veamos los valores de la tabla XOR. Esto nos ayudará a comprender el proceso de cifrado y descifrado.
| UN | segundo | UN XOR segundo |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
El método de cifrado XOR Cipher se utiliza básicamente para cifrar datos que son difíciles de descifrar con el método de fuerza bruta, es decir, mediante la generación de claves de cifrado aleatorias que coinciden con la clave adecuada.
El concepto de implementación con XOR Cipher es definir una clave de cifrado XOR y luego realizar la operación XOR de los caracteres en la cadena especificada con esta clave, que un usuario intenta cifrar. Ahora nos centraremos en la implementación de XOR usando TensorFlow, que se menciona a continuación:
#Declaring necessary modules
import tensorflow as tf
import numpy as np
"""
A simple numpy implementation of a XOR gate to understand the backpropagation
algorithm
"""
x = tf.placeholder(tf.float64,shape = [4,2],name = "x")
#declaring a place holder for input x
y = tf.placeholder(tf.float64,shape = [4,1],name = "y")
#declaring a place holder for desired output y
m = np.shape(x)[0]#number of training examples
n = np.shape(x)[1]#number of features
hidden_s = 2 #number of nodes in the hidden layer
l_r = 1#learning rate initialization
theta1 = tf.cast(tf.Variable(tf.random_normal([3,hidden_s]),name = "theta1"),tf.float64)
theta2 = tf.cast(tf.Variable(tf.random_normal([hidden_s+1,1]),name = "theta2"),tf.float64)
#conducting forward propagation
a1 = tf.concat([np.c_[np.ones(x.shape[0])],x],1)
#the weights of the first layer are multiplied by the input of the first layer
z1 = tf.matmul(a1,theta1)
#the input of the second layer is the output of the first layer, passed through the
activation function and column of biases is added
a2 = tf.concat([np.c_[np.ones(x.shape[0])],tf.sigmoid(z1)],1)
#the input of the second layer is multiplied by the weights
z3 = tf.matmul(a2,theta2)
#the output is passed through the activation function to obtain the final probability
h3 = tf.sigmoid(z3)
cost_func = -tf.reduce_sum(y*tf.log(h3)+(1-y)*tf.log(1-h3),axis = 1)
#built in tensorflow optimizer that conducts gradient descent using specified
learning rate to obtain theta values
optimiser = tf.train.GradientDescentOptimizer(learning_rate = l_r).minimize(cost_func)
#setting required X and Y values to perform XOR operation
X = [[0,0],[0,1],[1,0],[1,1]]
Y = [[0],[1],[1],[0]]
#initializing all variables, creating a session and running a tensorflow session
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
#running gradient descent for each iteration and printing the hypothesis
obtained using the updated theta values
for i in range(100000):
sess.run(optimiser, feed_dict = {x:X,y:Y})#setting place holder values using feed_dict
if i%100==0:
print("Epoch:",i)
print("Hyp:",sess.run(h3,feed_dict = {x:X,y:Y}))La línea de código anterior genera una salida como se muestra en la captura de pantalla a continuación:
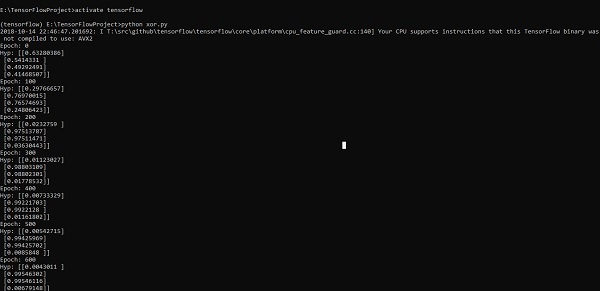
La optimización del descenso de gradientes se considera un concepto importante en la ciencia de datos.
Considere los pasos que se muestran a continuación para comprender la implementación de la optimización del descenso de gradientes:
Paso 1
Incluir los módulos necesarios y la declaración de las variables xey mediante las cuales vamos a definir la optimización del descenso del gradiente.
import tensorflow as tf
x = tf.Variable(2, name = 'x', dtype = tf.float32)
log_x = tf.log(x)
log_x_squared = tf.square(log_x)
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(log_x_squared)Paso 2
Inicialice las variables necesarias y llame a los optimizadores para definirlo y llamarlo con la función respectiva.
init = tf.initialize_all_variables()
def optimize():
with tf.Session() as session:
session.run(init)
print("starting at", "x:", session.run(x), "log(x)^2:", session.run(log_x_squared))
for step in range(10):
session.run(train)
print("step", step, "x:", session.run(x), "log(x)^2:", session.run(log_x_squared))
optimize()La línea de código anterior genera una salida como se muestra en la captura de pantalla a continuación:
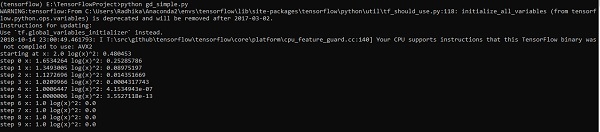
Podemos ver que las épocas e iteraciones necesarias se calculan como se muestra en la salida.
Una ecuación diferencial parcial (PDE) es una ecuación diferencial, que involucra derivadas parciales con función desconocida de varias variables independientes. Con referencia a las ecuaciones diferenciales parciales, nos centraremos en la creación de nuevos gráficos.
Supongamos que hay un estanque con una dimensión de 500 * 500 cuadrados -
N = 500
Ahora, calcularemos la ecuación diferencial parcial y formaremos la gráfica respectiva usándola. Considere los pasos que se dan a continuación para calcular el gráfico.
Step 1 - Importación de bibliotecas para simulación.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as pltStep 2 - Incluye funciones para la transformación de una matriz 2D en un núcleo de convolución y operación de convolución 2D simplificada.
def make_kernel(a):
a = np.asarray(a)
a = a.reshape(list(a.shape) + [1,1])
return tf.constant(a, dtype=1)
def simple_conv(x, k):
"""A simplified 2D convolution operation"""
x = tf.expand_dims(tf.expand_dims(x, 0), -1)
y = tf.nn.depthwise_conv2d(x, k, [1, 1, 1, 1], padding = 'SAME')
return y[0, :, :, 0]
def laplace(x):
"""Compute the 2D laplacian of an array"""
laplace_k = make_kernel([[0.5, 1.0, 0.5], [1.0, -6., 1.0], [0.5, 1.0, 0.5]])
return simple_conv(x, laplace_k)
sess = tf.InteractiveSession()Step 3 - Incluya el número de iteraciones y calcule el gráfico para mostrar los registros en consecuencia.
N = 500
# Initial Conditions -- some rain drops hit a pond
# Set everything to zero
u_init = np.zeros([N, N], dtype = np.float32)
ut_init = np.zeros([N, N], dtype = np.float32)
# Some rain drops hit a pond at random points
for n in range(100):
a,b = np.random.randint(0, N, 2)
u_init[a,b] = np.random.uniform()
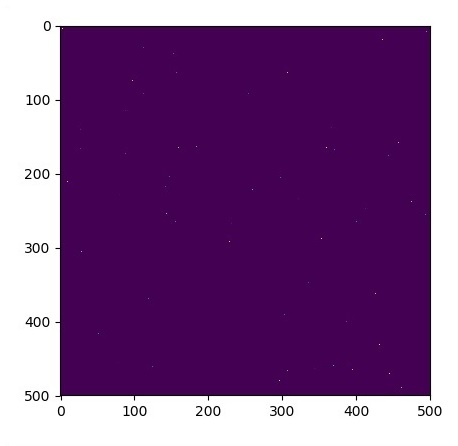
plt.imshow(u_init)
plt.show()
# Parameters:
# eps -- time resolution
# damping -- wave damping
eps = tf.placeholder(tf.float32, shape = ())
damping = tf.placeholder(tf.float32, shape = ())
# Create variables for simulation state
U = tf.Variable(u_init)
Ut = tf.Variable(ut_init)
# Discretized PDE update rules
U_ = U + eps * Ut
Ut_ = Ut + eps * (laplace(U) - damping * Ut)
# Operation to update the state
step = tf.group(U.assign(U_), Ut.assign(Ut_))
# Initialize state to initial conditions
tf.initialize_all_variables().run()
# Run 1000 steps of PDE
for i in range(1000):
# Step simulation
step.run({eps: 0.03, damping: 0.04})
# Visualize every 50 steps
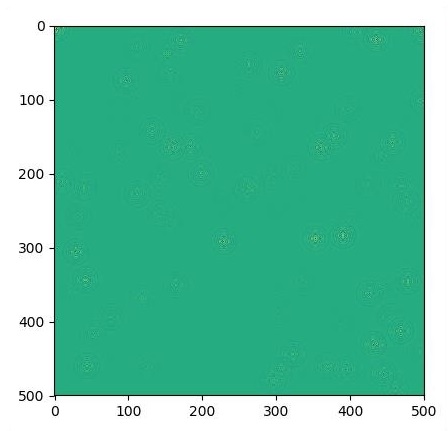
if i % 500 == 0:
plt.imshow(U.eval())
plt.show()Los gráficos se trazan como se muestra a continuación:
TensorFlow incluye una función especial de reconocimiento de imágenes y estas imágenes se almacenan en una carpeta específica. Con imágenes relativamente iguales, será fácil implementar esta lógica por motivos de seguridad.
La estructura de carpetas de la implementación del código de reconocimiento de imágenes es la que se muestra a continuación:
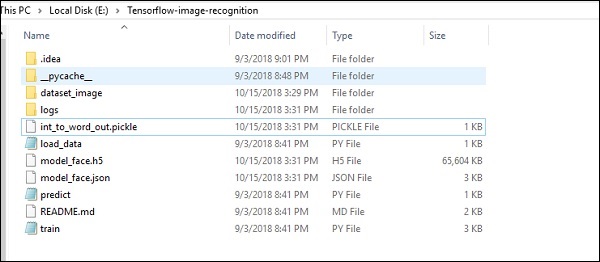
El dataset_image incluye las imágenes relacionadas, que deben cargarse. Nos centraremos en el reconocimiento de imágenes con nuestro logo definido en él. Las imágenes se cargan con el script "load_data.py", que ayuda a mantener una nota sobre varios módulos de reconocimiento de imágenes dentro de ellas.
import pickle
from sklearn.model_selection import train_test_split
from scipy import misc
import numpy as np
import os
label = os.listdir("dataset_image")
label = label[1:]
dataset = []
for image_label in label:
images = os.listdir("dataset_image/"+image_label)
for image in images:
img = misc.imread("dataset_image/"+image_label+"/"+image)
img = misc.imresize(img, (64, 64))
dataset.append((img,image_label))
X = []
Y = []
for input,image_label in dataset:
X.append(input)
Y.append(label.index(image_label))
X = np.array(X)
Y = np.array(Y)
X_train,y_train, = X,Y
data_set = (X_train,y_train)
save_label = open("int_to_word_out.pickle","wb")
pickle.dump(label, save_label)
save_label.close()El entrenamiento de imágenes ayuda a almacenar los patrones reconocibles dentro de la carpeta especificada.
import numpy
import matplotlib.pyplot as plt
from keras.layers import Dropout
from keras.layers import Flatten
from keras.constraints import maxnorm
from keras.optimizers import SGD
from keras.layers import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
from keras import backend as K
import load_data
from keras.models import Sequential
from keras.layers import Dense
import keras
K.set_image_dim_ordering('tf')
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load data
(X_train,y_train) = load_data.data_set
# normalize inputs from 0-255 to 0.0-1.0
X_train = X_train.astype('float32')
#X_test = X_test.astype('float32')
X_train = X_train / 255.0
#X_test = X_test / 255.0
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
#y_test = np_utils.to_categorical(y_test)
num_classes = y_train.shape[1]
# Create the model
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), padding = 'same',
activation = 'relu', kernel_constraint = maxnorm(3)))
model.add(Dropout(0.2))
model.add(Conv2D(32, (3, 3), activation = 'relu', padding = 'same',
kernel_constraint = maxnorm(3)))
model.add(MaxPooling2D(pool_size = (2, 2)))
model.add(Flatten())
model.add(Dense(512, activation = 'relu', kernel_constraint = maxnorm(3)))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation = 'softmax'))
# Compile model
epochs = 10
lrate = 0.01
decay = lrate/epochs
sgd = SGD(lr = lrate, momentum = 0.9, decay = decay, nesterov = False)
model.compile(loss = 'categorical_crossentropy', optimizer = sgd, metrics = ['accuracy'])
print(model.summary())
#callbacks = [keras.callbacks.EarlyStopping(
monitor = 'val_loss', min_delta = 0, patience = 0, verbose = 0, mode = 'auto')]
callbacks = [keras.callbacks.TensorBoard(log_dir='./logs',
histogram_freq = 0, batch_size = 32, write_graph = True, write_grads = False,
write_images = True, embeddings_freq = 0, embeddings_layer_names = None,
embeddings_metadata = None)]
# Fit the model
model.fit(X_train, y_train, epochs = epochs,
batch_size = 32,shuffle = True,callbacks = callbacks)
# Final evaluation of the model
scores = model.evaluate(X_train, y_train, verbose = 0)
print("Accuracy: %.2f%%" % (scores[1]*100))
# serialize model to JSONx
model_json = model.to_json()
with open("model_face.json", "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
model.save_weights("model_face.h5")
print("Saved model to disk")La línea de código anterior genera una salida como se muestra a continuación:
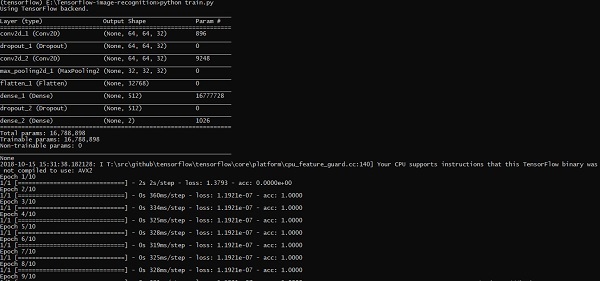
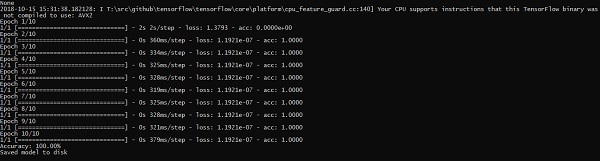
En este capítulo, comprenderemos los diversos aspectos del entrenamiento de redes neuronales que se pueden implementar con el marco de trabajo de TensorFlow.
A continuación se presentan las diez recomendaciones, que pueden evaluarse:
Propagación hacia atrás
La retropropagación es un método simple para calcular derivadas parciales, que incluye la forma básica de composición más adecuada para redes neuronales.
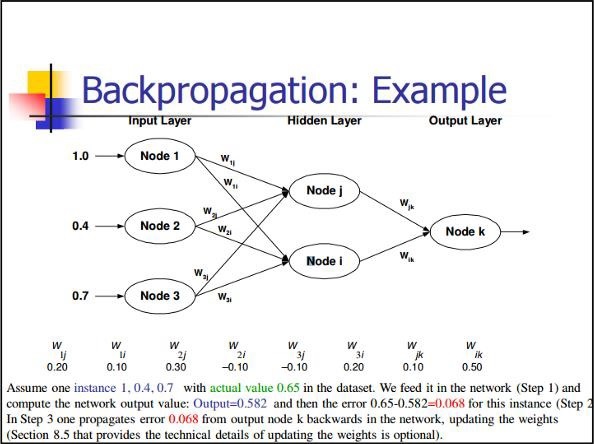
Descenso de gradiente estocástico
En descenso de gradiente estocástico, un batches el número total de ejemplos que usa un usuario para calcular el gradiente en una sola iteración. Hasta ahora, se supone que el lote ha sido el conjunto de datos completo. La mejor ilustración es trabajar a escala de Google; Los conjuntos de datos a menudo contienen miles de millones o incluso cientos de miles de millones de ejemplos.
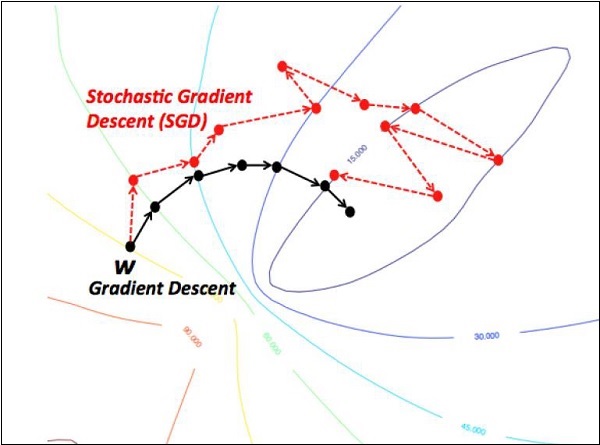
Decadencia de la tasa de aprendizaje
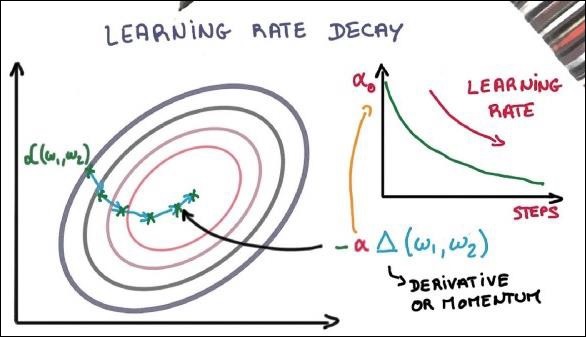
La adaptación de la tasa de aprendizaje es una de las características más importantes de la optimización del descenso de gradientes. Esto es crucial para la implementación de TensorFlow.
Abandonar
Las redes neuronales profundas con una gran cantidad de parámetros forman potentes sistemas de aprendizaje automático. Sin embargo, el ajuste excesivo es un problema grave en estas redes.

Agrupación máxima
La agrupación máxima es un proceso de discretización basado en muestras. El objetivo es reducir la muestra de una representación de entrada, lo que reduce la dimensionalidad con los supuestos requeridos.

Memoria a corto plazo (LSTM)
LSTM controla la decisión sobre qué entradas deben tomarse dentro de la neurona especificada. Incluye el control para decidir qué se debe calcular y qué resultado se debe generar.