โครงข่ายประสาทเทียม - อัลกอริทึมทางพันธุกรรม
ธรรมชาติเป็นแหล่งที่มาของแรงบันดาลใจที่ดีสำหรับมวลมนุษยชาติ Genetic Algorithms (GAs) คืออัลกอริธึมที่ใช้การค้นหาตามแนวคิดของการคัดเลือกโดยธรรมชาติและพันธุศาสตร์ GAs เป็นชุดย่อยของสาขาการคำนวณที่ใหญ่กว่าที่เรียกว่าEvolutionary Computation.
GAs ได้รับการพัฒนาโดย John Holland และนักศึกษาและเพื่อนร่วมงานของเขาที่ University of Michigan โดยเฉพาะอย่างยิ่ง David E.Goldberg และได้รับการทดลองในปัญหาการเพิ่มประสิทธิภาพต่างๆพร้อมกับความสำเร็จในระดับสูง
ใน GAs เรามีกลุ่มหรือกลุ่มของวิธีแก้ปัญหาที่เป็นไปได้สำหรับปัญหาที่กำหนด จากนั้นวิธีการแก้ปัญหาเหล่านี้จะผ่านการรวมตัวกันใหม่และการกลายพันธุ์ (เช่นเดียวกับในพันธุศาสตร์ตามธรรมชาติ) ผลิตลูกใหม่และกระบวนการนี้ซ้ำแล้วซ้ำอีกในหลายชั่วอายุคน แต่ละคน (หรือวิธีการแก้ปัญหาของผู้สมัคร) จะได้รับการกำหนดค่าสมรรถภาพ (ตามค่าฟังก์ชันวัตถุประสงค์) และบุคคลที่มีความเหมาะสมจะได้รับโอกาสที่สูงกว่าในการผสมพันธุ์และให้ผลตอบแทนแก่บุคคลที่ "ช่างฟิต" มากขึ้น ซึ่งสอดคล้องกับทฤษฎีดาร์วินเรื่อง“ Survival of the Fittest”
ด้วยวิธีนี้เราจะ“ พัฒนา” บุคคลหรือแนวทางแก้ไขที่ดีขึ้นเรื่อย ๆ มาหลายชั่วอายุคนจนกว่าจะถึงเกณฑ์ที่หยุดชะงัก
อัลกอริทึมทางพันธุกรรมมีการสุ่มอย่างเพียงพอในลักษณะ แต่จะทำงานได้ดีกว่าการค้นหาในพื้นที่แบบสุ่มมาก (ซึ่งเราลองใช้วิธีการสุ่มแบบต่างๆเพื่อติดตามสิ่งที่ดีที่สุดจนถึงตอนนี้) เนื่องจากใช้ประโยชน์จากข้อมูลในอดีตเช่นกัน
ข้อดีของ GAs
GAs มีข้อดีหลายประการซึ่งทำให้พวกเขาได้รับความนิยมอย่างกว้างขวาง สิ่งเหล่านี้ ได้แก่ -
ไม่ต้องการข้อมูลอนุพันธ์ใด ๆ (ซึ่งอาจไม่มีให้สำหรับปัญหาในโลกแห่งความเป็นจริง)
เร็วขึ้นและมีประสิทธิภาพมากขึ้นเมื่อเทียบกับวิธีการแบบเดิม
มีความสามารถแบบขนานที่ดีมาก
ปรับฟังก์ชั่นทั้งแบบต่อเนื่องและไม่ต่อเนื่องตลอดจนปัญหาหลายวัตถุประสงค์
แสดงรายการโซลูชันที่ "ดี" ไม่ใช่แค่โซลูชันเดียว
มักจะได้รับคำตอบสำหรับปัญหาซึ่งจะดีขึ้นเมื่อเวลาผ่านไป
มีประโยชน์เมื่อพื้นที่ค้นหามีขนาดใหญ่มากและมีพารามิเตอร์จำนวนมากที่เกี่ยวข้อง
ข้อ จำกัด ของ GAs
เช่นเดียวกับเทคนิคอื่น ๆ GAs ก็มีข้อ จำกัด บางประการเช่นกัน สิ่งเหล่านี้ ได้แก่ -
GAs ไม่เหมาะกับทุกปัญหาโดยเฉพาะปัญหาที่เรียบง่ายและมีข้อมูลอนุพันธ์
ค่าฟิตเนสจะคำนวณซ้ำ ๆ ซึ่งอาจมีราคาแพงในการคำนวณสำหรับปัญหาบางอย่าง
การสุ่มตัวอย่างจะไม่มีการรับประกันเกี่ยวกับความเหมาะสมหรือคุณภาพของโซลูชัน
หากไม่ได้ติดตั้งอย่างถูกต้อง GA อาจไม่รวมเข้ากับโซลูชันที่เหมาะสมที่สุด
GA - แรงจูงใจ
อัลกอริทึมทางพันธุกรรมมีความสามารถในการนำเสนอโซลูชันที่ "ดีเพียงพอ" "เร็วพอ" สิ่งนี้ทำให้ Gas น่าสนใจสำหรับใช้ในการแก้ปัญหาการเพิ่มประสิทธิภาพ เหตุผลที่ GAs จำเป็นมีดังต่อไปนี้ -
การแก้ปัญหาที่ยาก
ในวิทยาการคอมพิวเตอร์มีปัญหาชุดใหญ่ซึ่ง ได้แก่ NP-Hard. สิ่งนี้หมายความว่าโดยพื้นฐานแล้วแม้แต่ระบบคอมพิวเตอร์ที่ทรงพลังที่สุดก็ใช้เวลานานมาก (เป็นปี!) ในการแก้ปัญหานั้น ในสถานการณ์เช่นนี้ GAs พิสูจน์แล้วว่าเป็นเครื่องมือที่มีประสิทธิภาพในการจัดหาusable near-optimal solutions ในช่วงเวลาสั้น ๆ
ความล้มเหลวของวิธีการไล่ระดับสี
วิธีการที่ใช้แคลคูลัสแบบดั้งเดิมทำงานโดยเริ่มต้นที่จุดสุ่มและโดยการเคลื่อนที่ไปตามทิศทางของการไล่ระดับสีจนกว่าเราจะไปถึงยอดเขา เทคนิคนี้มีประสิทธิภาพและใช้ได้ผลดีกับฟังก์ชันวัตถุประสงค์จุดยอดเดียวเช่นฟังก์ชันต้นทุนในการถดถอยเชิงเส้น อย่างไรก็ตามในสถานการณ์จริงส่วนใหญ่เรามีปัญหาที่ซับซ้อนมากที่เรียกว่าภูมิประเทศซึ่งประกอบด้วยยอดเขาจำนวนมากและหุบเขาจำนวนมากซึ่งทำให้วิธีการดังกล่าวล้มเหลวเนื่องจากพวกเขาต้องทนทุกข์ทรมานจากแนวโน้มที่จะติดอยู่ที่ Optima ในท้องถิ่นดังที่แสดง ในรูปต่อไปนี้
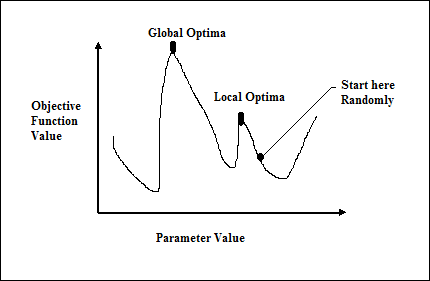
รับทางออกที่ดีอย่างรวดเร็ว
ปัญหาที่ยากบางอย่างเช่นปัญหาพนักงานขายการเดินทาง (TSP) มีแอปพลิเคชันในโลกแห่งความเป็นจริงเช่นการค้นหาเส้นทางและการออกแบบ VLSI ลองนึกภาพว่าคุณกำลังใช้ระบบการนำทางด้วย GPS และใช้เวลาสองสามนาที (หรือสองสามชั่วโมง) ในการคำนวณเส้นทางที่ "เหมาะสมที่สุด" จากต้นทางไปยังปลายทาง ความล่าช้าในแอปพลิเคชันในโลกแห่งความเป็นจริงนั้นไม่สามารถยอมรับได้ดังนั้นโซลูชันที่ "ดีเพียงพอ" ซึ่งส่งมอบให้ "เร็ว" จึงเป็นสิ่งที่จำเป็น
วิธีใช้ GA สำหรับปัญหาการเพิ่มประสิทธิภาพ
เราทราบดีอยู่แล้วว่าการเพิ่มประสิทธิภาพเป็นการกระทำเพื่อให้บางสิ่งบางอย่างเช่นการออกแบบสถานการณ์ทรัพยากรและระบบมีประสิทธิภาพมากที่สุด กระบวนการเพิ่มประสิทธิภาพจะแสดงในแผนภาพต่อไปนี้

ขั้นตอนของกลไก GA สำหรับกระบวนการเพิ่มประสิทธิภาพ
ต่อไปนี้เป็นขั้นตอนของกลไก GA เมื่อใช้เพื่อเพิ่มประสิทธิภาพของปัญหา
สร้างประชากรเริ่มต้นแบบสุ่ม
เลือกโซลูชันเริ่มต้นที่มีค่าสมรรถภาพที่ดีที่สุด
รวมโซลูชันที่เลือกใหม่โดยใช้ตัวดำเนินการการกลายพันธุ์และครอสโอเวอร์
แทรกลูกหลานเข้าไปในประชากร
ตอนนี้หากตรงตามเงื่อนไขการหยุดแล้วให้ส่งคืนโซลูชันที่มีค่าสมรรถภาพที่ดีที่สุด จากนั้นไปที่ขั้นตอนที่ 2