การเรียนรู้ที่ไม่มีผู้ดูแล
ตามชื่อที่แนะนำการเรียนรู้ประเภทนี้ทำได้โดยไม่ต้องอยู่ภายใต้การดูแลของครู กระบวนการเรียนรู้นี้เป็นอิสระ ในระหว่างการฝึกอบรม ANN ภายใต้การเรียนรู้ที่ไม่มีการดูแลจะมีการรวมเวกเตอร์อินพุตประเภทที่คล้ายคลึงกันเพื่อสร้างกลุ่ม เมื่อใช้รูปแบบการป้อนข้อมูลใหม่เครือข่ายประสาทจะให้การตอบสนองเอาต์พุตที่ระบุคลาสที่เป็นรูปแบบอินพุต ในนี้จะไม่มีข้อเสนอแนะจากสิ่งแวดล้อมว่าอะไรควรเป็นผลลัพธ์ที่ต้องการและถูกต้องหรือไม่ถูกต้อง ดังนั้นในการเรียนรู้ประเภทนี้เครือข่ายจะต้องค้นพบรูปแบบคุณสมบัติจากข้อมูลอินพุตและความสัมพันธ์ของข้อมูลอินพุตผ่านเอาต์พุต
ผู้ชนะ - รับ - เครือข่ายทั้งหมด
เครือข่ายประเภทนี้ตั้งอยู่บนกฎการเรียนรู้แบบแข่งขันและจะใช้กลยุทธ์ที่มันเลือกเซลล์ประสาทที่มีอินพุตรวมมากที่สุดเป็นผู้ชนะ การเชื่อมต่อระหว่างเซลล์ประสาทเอาต์พุตแสดงการแข่งขันระหว่างพวกมันและหนึ่งในนั้นจะเป็น 'เปิด' ซึ่งหมายความว่าจะเป็นผู้ชนะและอื่น ๆ จะเป็น 'ปิด'
ต่อไปนี้เป็นเครือข่ายบางส่วนที่ใช้แนวคิดง่ายๆนี้โดยใช้การเรียนรู้ที่ไม่มีผู้ดูแล
Hamming Network
ในโครงข่ายประสาทเทียมส่วนใหญ่ใช้การเรียนรู้ที่ไม่มีผู้ดูแลจำเป็นอย่างยิ่งที่จะต้องคำนวณระยะทางและทำการเปรียบเทียบ เครือข่ายประเภทนี้คือเครือข่าย Hamming ซึ่งสำหรับเวกเตอร์อินพุตที่กำหนดทุกตัวจะรวมกลุ่มกันเป็นกลุ่มต่างๆ ต่อไปนี้เป็นคุณสมบัติที่สำคัญบางประการของ Hamming Networks -
Lippmann เริ่มทำงานกับเครือข่าย Hamming ในปี 1987
มันเป็นเครือข่ายชั้นเดียว
อินพุตอาจเป็นไบนารี {0, 1} ของไบโพลาร์ {-1, 1} ก็ได้
น้ำหนักของตาข่ายคำนวณโดยเวกเตอร์ตัวอย่าง
เป็นโครงข่ายน้ำหนักคงที่ซึ่งหมายความว่าน้ำหนักจะยังคงเหมือนเดิมแม้ในระหว่างการฝึก
สุทธิสูงสุด
นอกจากนี้ยังเป็นเครือข่ายน้ำหนักคงที่ซึ่งทำหน้าที่เป็นเครือข่ายย่อยสำหรับการเลือกโหนดที่มีอินพุตสูงสุด โหนดทั้งหมดเชื่อมต่อกันอย่างสมบูรณ์และมีน้ำหนักสมมาตรอยู่ในการเชื่อมต่อแบบถ่วงน้ำหนักเหล่านี้ทั้งหมด
สถาปัตยกรรม
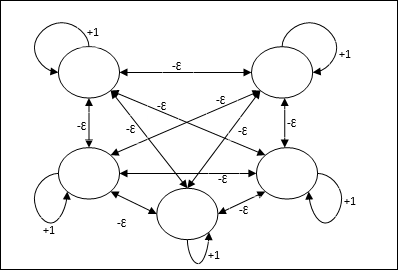
ใช้กลไกซึ่งเป็นกระบวนการซ้ำและแต่ละโหนดได้รับอินพุตยับยั้งจากโหนดอื่น ๆ ทั้งหมดผ่านการเชื่อมต่อ โหนดเดียวที่มีค่าสูงสุดจะใช้งานได้หรือเป็นผู้ชนะและการเปิดใช้งานของโหนดอื่น ๆ ทั้งหมดจะไม่ทำงาน Max Net ใช้ฟังก์ชันการเปิดใช้งานข้อมูลประจำตัวด้วย $$ f (x) \: = \: \ begin {cases} x & if \: x> 0 \\ 0 & if \: x \ leq 0 \ end {cases} $$
ภารกิจของตาข่ายนี้ทำได้โดยน้ำหนักกระตุ้นตัวเองที่ +1 และขนาดการยับยั้งซึ่งกันและกันซึ่งกำหนดไว้เช่น [0 <ɛ <$ \ frac {1} {m} $] โดยที่ “m” คือจำนวนโหนดทั้งหมด
การเรียนรู้เชิงแข่งขันใน ANN
เกี่ยวข้องกับการฝึกอบรมที่ไม่มีผู้ดูแลซึ่งโหนดเอาต์พุตพยายามแข่งขันกันเพื่อแสดงรูปแบบการป้อนข้อมูล เพื่อให้เข้าใจกฎการเรียนรู้นี้เราจะต้องทำความเข้าใจเกี่ยวกับการแข่งขันซึ่งอธิบายได้ดังนี้ -
แนวคิดพื้นฐานของเครือข่ายการแข่งขัน
เครือข่ายนี้เหมือนกับเครือข่ายฟีดฟอร์เวิร์ดชั้นเดียวที่มีการเชื่อมต่อข้อมูลป้อนกลับระหว่างเอาต์พุต การเชื่อมต่อระหว่างเอาต์พุตเป็นประเภทการยับยั้งซึ่งแสดงโดยเส้นประซึ่งหมายความว่าคู่แข่งไม่เคยสนับสนุนตัวเอง
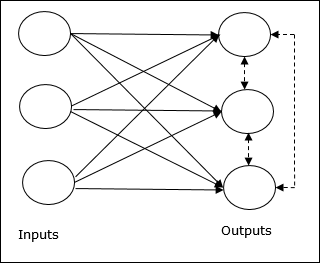
แนวคิดพื้นฐานของกฎการเรียนรู้เชิงแข่งขัน
ดังที่ได้กล่าวไว้ก่อนหน้านี้จะมีการแข่งขันระหว่างโหนดเอาต์พุตดังนั้นแนวคิดหลักคือ - ในระหว่างการฝึกอบรมหน่วยเอาต์พุตที่มีการเปิดใช้งานสูงสุดสำหรับรูปแบบอินพุตที่กำหนดจะได้รับการประกาศให้เป็นผู้ชนะ กฎนี้เรียกอีกอย่างว่า Winner-take-all เนื่องจากมีการปรับปรุงเฉพาะเซลล์ประสาทที่ชนะและเซลล์ประสาทที่เหลือจะไม่เปลี่ยนแปลง
การกำหนดทางคณิตศาสตร์
ต่อไปนี้เป็นปัจจัยสำคัญสามประการสำหรับการกำหนดทางคณิตศาสตร์ของกฎการเรียนรู้นี้ -
เงื่อนไขที่จะเป็นผู้ชนะ
สมมติว่าถ้าเซลล์ประสาท yk ต้องการเป็นผู้ชนะก็จะมีเงื่อนไขดังต่อไปนี้
$$ y_ {k} \: = \: \ begin {cases} 1 & if \: v_ {k}> v_ {j} \: for \: all \: \: j, \: j \: \ neq \ : k \\ 0 & มิฉะนั้น \ end {cases} $$
หมายความว่าถ้าเซลล์ประสาทใด ๆ พูดว่า yk ต้องการที่จะชนะจากนั้นฟิลด์ท้องถิ่นที่เกิดขึ้น (ผลลัพธ์ของหน่วยผลรวม) พูด vkต้องมีขนาดใหญ่ที่สุดในบรรดาเซลล์ประสาทอื่น ๆ ในเครือข่าย
เงื่อนไขของผลรวมของน้ำหนัก
ข้อ จำกัด อีกประการหนึ่งของกฎการเรียนรู้เชิงแข่งขันคือผลรวมของน้ำหนักของเซลล์ประสาทเอาท์พุตเฉพาะจะเท่ากับ 1 ตัวอย่างเช่นถ้าเราพิจารณาเซลล์ประสาท k แล้ว
$$ \ displaystyle \ sum \ LIMIT_ {k} w_ {kj} \: = \: 1 \: \: \: \: สำหรับ \: ทั้งหมด \: \: k $$
การเปลี่ยนแปลงน้ำหนักสำหรับผู้ชนะ
หากเซลล์ประสาทไม่ตอบสนองต่อรูปแบบการป้อนข้อมูลจะไม่มีการเรียนรู้เกิดขึ้นในเซลล์ประสาทนั้น อย่างไรก็ตามหากเซลล์ประสาทตัวใดตัวหนึ่งชนะน้ำหนักที่เกี่ยวข้องจะถูกปรับดังนี้ -
$$ \ Delta w_ {kj} \: = \: \ begin {cases} - \ alpha (x_ {j} \: - \: w_ {kj}), & if \: neuron \: k \: wins \\ 0 & if \: neuron \: k \: Loss \ end {cases} $$
ที่นี่ $ \ alpha $ คืออัตราการเรียนรู้
สิ่งนี้แสดงให้เห็นอย่างชัดเจนว่าเราให้ความสำคัญกับเซลล์ประสาทที่ชนะโดยการปรับน้ำหนักของมันและหากเซลล์ประสาทสูญเสียไปเราก็ไม่จำเป็นต้องปรับน้ำหนักของมันใหม่
K-mean Clustering Algorithm
K-mean เป็นหนึ่งในอัลกอริทึมการทำคลัสเตอร์ที่ได้รับความนิยมมากที่สุดซึ่งเราใช้แนวคิดของขั้นตอนการแบ่งพาร์ติชัน เราเริ่มต้นด้วยพาร์ติชันเริ่มต้นและย้ายรูปแบบจากคลัสเตอร์หนึ่งไปยังอีกคลัสเตอร์ซ้ำ ๆ จนกว่าเราจะได้ผลลัพธ์ที่น่าพอใจ
อัลกอริทึม
Step 1 - เลือก kจุดเป็นเซนทรอยด์เริ่มต้น เริ่มต้นk ต้นแบบ (w1,…,wk)ตัวอย่างเช่นเราสามารถระบุได้ด้วยเวกเตอร์อินพุตที่เลือกแบบสุ่ม -
$$ W_ {j} \: = \: i_ {p}, \: \: \: โดยที่ \: j \: \ in \ lbrace1, .... , k \ rbrace \: และ \: p \: \ ใน \ lbrace1, .... , n \ rbrace $$
แต่ละคลัสเตอร์ Cj เกี่ยวข้องกับต้นแบบ wj.
Step 2 - ทำซ้ำขั้นตอนที่ 3-5 จนกว่า E จะไม่ลดลงอีกต่อไปหรือสมาชิกคลัสเตอร์จะไม่เปลี่ยนแปลงอีกต่อไป
Step 3 - สำหรับเวกเตอร์อินพุตแต่ละรายการ ip ที่ไหน p ∈ {1,…,n}ใส่ ip ในคลัสเตอร์ Cj* ด้วยต้นแบบที่ใกล้ที่สุด wj* มีความสัมพันธ์ดังต่อไปนี้
$$ | i_ {p} \: - \: w_ {j *} | \: \ leq \: | i_ {p} \: - \: w_ {j} |, \: j \: \ in \ lbrace1, .... , k \ rbrace $$
Step 4 - สำหรับแต่ละคลัสเตอร์ Cj, ที่ไหน j ∈ { 1,…,k}ปรับปรุงต้นแบบ wj เป็นเซนทรอยด์ของตัวอย่างทั้งหมดในปัจจุบัน Cj , ดังนั้น
$$ w_ {j} \: = \: \ sum_ {i_ {p} \ in C_ {j}} \ frac {i_ {p}} {| C_ {j} |} $$
Step 5 - คำนวณข้อผิดพลาดเชิงปริมาณทั้งหมดดังนี้ -
$$ E \: = \: \ sum_ {j = 1} ^ k \ sum_ {i_ {p} \ in w_ {j}} | i_ {p} \: - \: w_ {j} | ^ 2 $$
นีโอโกนิตรอน
เป็นเครือข่ายฟีดฟอร์เวิร์ดหลายชั้นซึ่งพัฒนาโดย Fukushima ในปี 1980 โมเดลนี้ใช้การเรียนรู้ภายใต้การดูแลและใช้สำหรับการจดจำรูปแบบภาพซึ่งส่วนใหญ่เป็นอักขระที่เขียนด้วยมือ โดยพื้นฐานแล้วเป็นส่วนขยายของเครือข่าย Cognitron ซึ่งได้รับการพัฒนาโดย Fukushima ในปีพ. ศ. 2518
สถาปัตยกรรม
เป็นเครือข่ายแบบลำดับชั้นซึ่งประกอบด้วยหลายชั้นและมีรูปแบบการเชื่อมต่อภายในในเลเยอร์เหล่านั้น
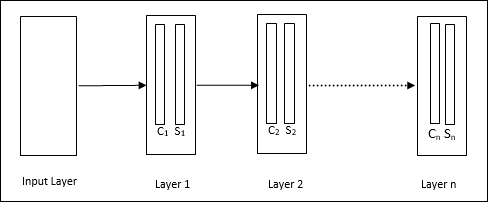
ดังที่เราได้เห็นในแผนภาพด้านบน neocognitron ถูกแบ่งออกเป็นชั้นต่างๆที่เชื่อมต่อกันและแต่ละชั้นมีสองเซลล์ คำอธิบายของเซลล์เหล่านี้มีดังนี้ -
S-Cell - เรียกว่าเซลล์ธรรมดาซึ่งได้รับการฝึกฝนให้ตอบสนองต่อรูปแบบเฉพาะหรือกลุ่มของรูปแบบ
C-Cell- เรียกว่าเซลล์ที่ซับซ้อนซึ่งรวมเอาผลลัพธ์จากเซลล์ S เข้าด้วยกันและลดจำนวนหน่วยในแต่ละอาร์เรย์ ในอีกแง่หนึ่ง C-cell แทนที่ผลลัพธ์ของ S-cell
อัลกอริทึมการฝึกอบรม
การฝึกของ neocognitron พบว่ามีความก้าวหน้าทีละชั้น น้ำหนักจากชั้นอินพุตไปยังชั้นแรกได้รับการฝึกฝนและแช่แข็ง จากนั้นน้ำหนักจากชั้นแรกถึงชั้นที่สองจะได้รับการฝึกฝนและอื่น ๆ การคำนวณภายในระหว่าง S-cell และ Ccell ขึ้นอยู่กับน้ำหนักที่มาจากชั้นก่อนหน้า ดังนั้นเราสามารถพูดได้ว่าอัลกอริทึมการฝึกขึ้นอยู่กับการคำนวณของ S-cell และ C-cell
การคำนวณใน S-cell
เซลล์ S มีสัญญาณกระตุ้นที่ได้รับจากชั้นก่อนหน้าและมีสัญญาณยับยั้งที่ได้รับภายในชั้นเดียวกัน
$$ \ theta = \: \ sqrt {\ sum \ sum t_ {i} c_ {i} ^ 2} $$
ที่นี่ ti คือน้ำหนักคงที่และ ci คือผลลัพธ์จากเซลล์ C
อินพุตที่ปรับขนาดของ S-cell สามารถคำนวณได้ดังนี้ -
$$ x \: = \: \ frac {1 \: + \: e} {1 \: + \: vw_ {0}} \: - \: 1 $$
ที่นี่ $ e \: = \: \ sum_i c_ {i} w_ {i} $
wi คือน้ำหนักที่ปรับจาก C-cell เป็น S-cell
w0 คือน้ำหนักที่ปรับได้ระหว่างอินพุตและเซลล์ S
v เป็นอินพุตกระตุ้นจากเซลล์ C
การเปิดใช้งานสัญญาณเอาต์พุตคือ
$$ s \: = \: \ begin {cases} x, & if \: x \ geq 0 \\ 0, & if \: x <0 \ end {cases} $$
การคำนวณในเซลล์ C
อินพุตสุทธิของ C-layer คือ
$$ C \: = \: \ displaystyle \ sum \ LIMIT_i s_ {i} x_ {i} $$
ที่นี่ si คือเอาต์พุตจาก S-cell และ xi คือน้ำหนักคงที่จาก S-cell ถึง C-cell
ผลลัพธ์สุดท้ายมีดังนี้ -
$$ C_ {out} \: = \: \ begin {cases} \ frac {C} {a + C}, & if \: C> 0 \\ 0, & else \ end {cases} $$
ที่นี่ ‘a’ คือพารามิเตอร์ที่ขึ้นอยู่กับประสิทธิภาพของเครือข่าย