การเรียนรู้และการปรับตัว
ดังที่ระบุไว้ก่อนหน้านี้ ANN ได้รับแรงบันดาลใจอย่างสมบูรณ์จากระบบประสาททางชีววิทยานั่นคือสมองของมนุษย์ทำงาน ลักษณะที่น่าประทับใจที่สุดของสมองมนุษย์คือการเรียนรู้ด้วยเหตุนี้ ANN จึงได้มาซึ่งคุณลักษณะเดียวกัน
การเรียนรู้ใน ANN คืออะไร?
โดยพื้นฐานแล้วการเรียนรู้หมายถึงการทำและปรับตัวให้เข้ากับการเปลี่ยนแปลงในตัวของมันเองและเมื่อมีการเปลี่ยนแปลงในสิ่งแวดล้อม ANN เป็นระบบที่ซับซ้อนหรือเราสามารถพูดได้อย่างชัดเจนว่าเป็นระบบปรับตัวที่ซับซ้อนซึ่งสามารถเปลี่ยนแปลงโครงสร้างภายในได้ตามข้อมูลที่ส่งผ่าน
ทำไมมันถึงสำคัญ?
การเป็นระบบการปรับตัวที่ซับซ้อนการเรียนรู้ใน ANN หมายความว่าหน่วยประมวลผลสามารถเปลี่ยนพฤติกรรมอินพุต / เอาต์พุตได้เนื่องจากการเปลี่ยนแปลงของสภาพแวดล้อม ความสำคัญของการเรียนรู้ใน ANN เพิ่มขึ้นเนื่องจากฟังก์ชันการเปิดใช้งานคงที่เช่นเดียวกับเวกเตอร์อินพุต / เอาต์พุตเมื่อสร้างเครือข่ายเฉพาะ ตอนนี้เพื่อเปลี่ยนพฤติกรรมอินพุต / เอาต์พุตเราจำเป็นต้องปรับน้ำหนัก
การจำแนกประเภท
อาจถูกกำหนดให้เป็นกระบวนการเรียนรู้เพื่อแยกแยะข้อมูลของกลุ่มตัวอย่างออกเป็นชั้นเรียนต่างๆโดยการค้นหาคุณลักษณะทั่วไประหว่างกลุ่มตัวอย่างในชั้นเรียนเดียวกัน ตัวอย่างเช่นในการฝึกอบรม ANN เรามีตัวอย่างการฝึกอบรมที่มีคุณสมบัติเฉพาะและในการทดสอบเรามีตัวอย่างการทดสอบที่มีคุณสมบัติเฉพาะอื่น ๆ การจัดหมวดหมู่เป็นตัวอย่างของการเรียนรู้ภายใต้การดูแล
กฎการเรียนรู้ของโครงข่ายประสาทเทียม
เรารู้ว่าในระหว่างการเรียนรู้ ANN ในการเปลี่ยนพฤติกรรมอินพุต / เอาต์พุตเราจำเป็นต้องปรับน้ำหนัก ดังนั้นจึงจำเป็นต้องใช้วิธีการที่สามารถแก้ไขน้ำหนักได้ วิธีการเหล่านี้เรียกว่ากฎการเรียนรู้ซึ่งเป็นเพียงอัลกอริทึมหรือสมการ ต่อไปนี้เป็นกฎการเรียนรู้บางประการสำหรับโครงข่ายประสาทเทียม -
กฎการเรียนรู้ Hebbian
กฎนี้หนึ่งในกฎที่เก่าแก่ที่สุดและง่ายที่สุดได้รับการแนะนำโดย Donald Hebb ในหนังสือของเขาThe Organization of Behaviorในปีพ. ศ. 2492 เป็นการเรียนรู้แบบป้อนไปข้างหน้าและไม่มีการดูแล
Basic Concept - กฎนี้เป็นไปตามข้อเสนอของ Hebb ผู้เขียน -
“ เมื่อแอกซอนของเซลล์ A อยู่ใกล้มากพอที่จะกระตุ้นเซลล์ B และมีส่วนร่วมในการยิงเซลล์ B ซ้ำ ๆ หรืออย่างต่อเนื่องกระบวนการเจริญเติบโตหรือการเปลี่ยนแปลงการเผาผลาญบางอย่างจะเกิดขึ้นในเซลล์เดียวหรือทั้งสองเซลล์เช่นประสิทธิภาพของ A ในขณะที่เซลล์ใดเซลล์หนึ่งยิง B เพิ่มขึ้น”
จากสมมติฐานข้างต้นเราสามารถสรุปได้ว่าการเชื่อมต่อระหว่างเซลล์ประสาทสองเซลล์อาจแข็งแรงขึ้นหากเซลล์ประสาททำงานในเวลาเดียวกันและอาจอ่อนแอลงหากพวกมันยิงในเวลาที่ต่างกัน
Mathematical Formulation - ตามกฎการเรียนรู้ของ Hebbian ต่อไปนี้เป็นสูตรในการเพิ่มน้ำหนักของการเชื่อมต่อในทุกขั้นตอน
$$ \ Delta w_ {ji} (t) \: = \: \ alpha x_ {i} (t) .y_ {j} (t) $$
ที่นี่ $ \ Delta w_ {ji} (t) $ = เพิ่มขึ้นโดยที่น้ำหนักของการเชื่อมต่อเพิ่มขึ้นในขั้นตอนเวลา t
$ \ alpha $ = อัตราการเรียนรู้เชิงบวกและคงที่
$ x_ {i} (t) $ = ค่าอินพุตจากเซลล์ประสาท pre-synaptic ในขั้นตอนเวลา t
$ y_ {i} (t) $ = ผลลัพธ์ของเซลล์ประสาท pre-synaptic ในขั้นตอนเดียวกัน t
กฎการเรียนรู้ของ Perceptron
กฎนี้เป็นข้อผิดพลาดในการแก้ไขอัลกอริธึมการเรียนรู้ภายใต้การดูแลของเครือข่ายฟีดฟอร์เวิร์ดชั้นเดียวที่มีฟังก์ชันการเปิดใช้งานเชิงเส้นซึ่งแนะนำโดย Rosenblatt
Basic Concept- ตามที่ได้รับการดูแลโดยธรรมชาติในการคำนวณข้อผิดพลาดจะมีการเปรียบเทียบระหว่างเอาต์พุตที่ต้องการ / เป้าหมายและเอาต์พุตจริง หากพบความแตกต่างจะต้องทำการเปลี่ยนแปลงน้ำหนักของการเชื่อมต่อ
Mathematical Formulation - เพื่ออธิบายการกำหนดทางคณิตศาสตร์สมมติว่าเรามีจำนวน 'n' ของเวกเตอร์อินพุต จำกัด x (n) พร้อมกับเวกเตอร์เอาต์พุตที่ต้องการ / เป้าหมาย t (n) โดยที่ n = 1 ถึง N
ตอนนี้สามารถคำนวณเอาต์พุต 'y' ได้ตามที่อธิบายไว้ก่อนหน้าบนพื้นฐานของอินพุตสุทธิและฟังก์ชันการเปิดใช้งานที่ใช้กับอินพุตสุทธินั้นสามารถแสดงได้ดังนี้ -
$$ y \: = \: f (y_ {in}) \: = \: \ begin {cases} 1, & y_ {in} \:> \: \ theta \\ 0, & y_ {in} \: \ leqslant \: \ theta \ end {cases} $$
ที่ไหน θ คือเกณฑ์
การอัปเดตน้ำหนักสามารถทำได้ในสองกรณีต่อไปนี้ -
Case I - เมื่อไหร่ t ≠ yแล้ว
$$ w (ใหม่) \: = \: w (เก่า) \: + \; tx $$
Case II - เมื่อไหร่ t = yแล้ว
ไม่มีการเปลี่ยนแปลงน้ำหนัก
กฎการเรียนรู้เดลต้า (กฎ Widrow-Hoff)
ได้รับการแนะนำโดย Bernard Widrow และ Marcian Hoff หรือที่เรียกว่าวิธี Least Mean Square (LMS) เพื่อลดข้อผิดพลาดในรูปแบบการฝึกอบรมทั้งหมด เป็นอัลกอริธึมการเรียนรู้ภายใต้การดูแลที่มีฟังก์ชันการเปิดใช้งานอย่างต่อเนื่อง
Basic Concept- พื้นฐานของกฎนี้คือแนวทางการไล่ระดับสีซึ่งจะดำเนินต่อไปตลอดกาล กฎเดลต้าจะอัปเดตน้ำหนักซิแนปติกเพื่อลดอินพุตสุทธิไปยังหน่วยเอาต์พุตและค่าเป้าหมาย
Mathematical Formulation - ในการอัปเดตน้ำหนัก synaptic กฎเดลต้าจะกำหนดโดย
$$ \ Delta w_ {i} \: = \: \ alpha \ :. x_ {i} .e_ {j} $$
ที่นี่ $ \ Delta w_ {i} $ = weight change for i th pattern;
$ \ alpha $ = อัตราการเรียนรู้เชิงบวกและคงที่
$ x_ {i} $ = ค่าอินพุตจากเซลล์ประสาท pre-synaptic;
$ e_ {j} $ = $ (t \: - \: y_ {in}) $ ความแตกต่างระหว่างผลลัพธ์ที่ต้องการ / เป้าหมายและผลลัพธ์จริง $ y_ {in} $
กฎเดลต้าข้างต้นมีไว้สำหรับหน่วยเอาต์พุตเดียวเท่านั้น
การอัปเดตน้ำหนักสามารถทำได้ในสองกรณีต่อไปนี้ -
Case-I - เมื่อไหร่ t ≠ yแล้ว
$$ w (ใหม่) \: = \: w (เก่า) \: + \: \ Delta w $$
Case-II - เมื่อไหร่ t = yแล้ว
ไม่มีการเปลี่ยนแปลงน้ำหนัก
กฎการเรียนรู้ที่แข่งขันได้ (ผู้ชนะจะได้ทั้งหมด)
เกี่ยวข้องกับการฝึกอบรมที่ไม่มีผู้ดูแลซึ่งโหนดเอาต์พุตพยายามแข่งขันกันเพื่อแสดงรูปแบบการป้อนข้อมูล เพื่อให้เข้าใจกฎการเรียนรู้นี้เราต้องเข้าใจเครือข่ายการแข่งขันซึ่งได้รับดังต่อไปนี้ -
Basic Concept of Competitive Network- เครือข่ายนี้เหมือนกับเครือข่าย feedforward แบบชั้นเดียวที่มีการเชื่อมต่อข้อมูลป้อนกลับระหว่างเอาต์พุต การเชื่อมต่อระหว่างเอาท์พุทเป็นประเภทการยับยั้งซึ่งแสดงโดยเส้นประซึ่งหมายความว่าคู่แข่งไม่เคยสนับสนุนตัวเอง
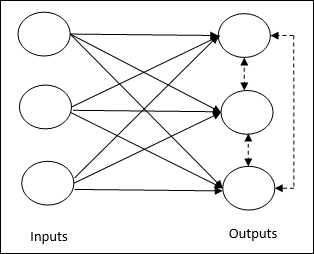
Basic Concept of Competitive Learning Rule- ดังที่กล่าวไว้ก่อนหน้านี้จะมีการแข่งขันระหว่างโหนดเอาต์พุต ดังนั้นแนวคิดหลักคือในระหว่างการฝึกอบรมหน่วยเอาต์พุตที่มีการเปิดใช้งานสูงสุดตามรูปแบบอินพุตที่กำหนดจะได้รับการประกาศให้เป็นผู้ชนะ กฎนี้เรียกอีกอย่างว่า Winner-take-all เนื่องจากมีการอัปเดตเฉพาะเซลล์ประสาทที่ชนะเท่านั้นและเซลล์ประสาทที่เหลือจะไม่เปลี่ยนแปลง
Mathematical formulation - ต่อไปนี้เป็นปัจจัยสำคัญสามประการสำหรับการกำหนดทางคณิตศาสตร์ของกฎการเรียนรู้นี้ -
Condition to be a winner - สมมติว่าถ้าเซลล์ประสาท $ y_ {k} $ อยากเป็นผู้ชนะก็จะมีเงื่อนไขดังต่อไปนี้ -
$$ y_ {k} \: = \: \ begin {cases} 1 & if \: v_ {k} \:> \: v_ {j} \: for \: all \: j, \: j \: \ neq \: k \\ 0 & มิฉะนั้น \ end {cases} $$
หมายความว่าหากเซลล์ประสาทใด ๆ พูดว่า $ y_ {k} $ ต้องการที่จะชนะจากนั้นฟิลด์ท้องถิ่นที่เกิดขึ้น (ผลลัพธ์ของหน่วยการรวม) กล่าวว่า $ v_ {k} $ จะต้องมีขนาดใหญ่ที่สุดในบรรดาเซลล์ประสาทอื่น ๆ ทั้งหมด ในเครือข่าย
Condition of sum total of weight - ข้อ จำกัด อีกประการหนึ่งของกฎการเรียนรู้เชิงแข่งขันคือผลรวมของน้ำหนักของเซลล์ประสาทขาออกเฉพาะจะเป็น 1 ตัวอย่างเช่นถ้าเราพิจารณาเซลล์ประสาท k แล้ว -
$$ \ displaystyle \ sum \ LIMIT_ {j} w_ {kj} \: = \: 1 \: \: \: \: \: \: \: \: \: สำหรับ \: ทั้งหมด \: k $$
Change of weight for winner- หากเซลล์ประสาทไม่ตอบสนองต่อรูปแบบการป้อนข้อมูลจะไม่มีการเรียนรู้เกิดขึ้นในเซลล์ประสาทนั้น อย่างไรก็ตามหากเซลล์ประสาทตัวใดตัวหนึ่งชนะน้ำหนักที่เกี่ยวข้องจะถูกปรับดังต่อไปนี้
$$ \ Delta w_ {kj} \: = \: \ begin {cases} - \ alpha (x_ {j} \: - \: w_ {kj}), & if \: neuron \: k \: wins \\ 0, & if \: neuron \: k \: Loss \ end {cases} $$
ที่นี่ $ \ alpha $ คืออัตราการเรียนรู้
สิ่งนี้แสดงให้เห็นอย่างชัดเจนว่าเรากำลังนิยมเซลล์ประสาทที่ชนะโดยการปรับน้ำหนักของมันและหากมีการสูญเสียเซลล์ประสาทเราก็ไม่จำเป็นต้องปรับน้ำหนักของมันใหม่
กฎการเรียนรู้ของ Outstar
กฎนี้นำเสนอโดย Grossberg เกี่ยวข้องกับการเรียนรู้ภายใต้การดูแลเนื่องจากทราบผลลัพธ์ที่ต้องการ เรียกอีกอย่างว่า Grossberg learning
Basic Concept- กฎนี้ใช้กับเซลล์ประสาทที่เรียงเป็นชั้น ๆ ได้รับการออกแบบมาเป็นพิเศษเพื่อให้ได้ผลลัพธ์ที่ต้องการd ของเลเยอร์ของ p เซลล์ประสาท.
Mathematical Formulation - การปรับน้ำหนักในกฎนี้คำนวณได้ดังนี้
$$ \ Delta w_ {j} \: = \: \ alpha \ :( d \: - \: w_ {j}) $$
ที่นี่ d คือผลลัพธ์ของเซลล์ประสาทที่ต้องการและ $ \ alpha $ คืออัตราการเรียนรู้