การเรียนรู้ภายใต้การดูแล
ตามชื่อ supervised learningเกิดขึ้นภายใต้การดูแลของครู กระบวนการเรียนรู้นี้ขึ้นอยู่กับ ในระหว่างการฝึก ANN ภายใต้การเรียนรู้ภายใต้การดูแลเวกเตอร์อินพุตจะถูกนำเสนอไปยังเครือข่ายซึ่งจะสร้างเวกเตอร์เอาต์พุต เวกเตอร์เอาต์พุตนี้เปรียบเทียบกับเวกเตอร์เอาต์พุตที่ต้องการ / เป้าหมาย สัญญาณข้อผิดพลาดจะถูกสร้างขึ้นหากมีความแตกต่างระหว่างเอาต์พุตจริงและเวกเตอร์เอาต์พุตที่ต้องการ / เป้าหมาย บนพื้นฐานของสัญญาณข้อผิดพลาดนี้น้ำหนักจะถูกปรับจนกว่าเอาต์พุตจริงจะตรงกับเอาต์พุตที่ต้องการ
เพอร์เซปตรอน
พัฒนาโดย Frank Rosenblatt โดยใช้แบบจำลอง McCulloch และ Pitts perceptron เป็นหน่วยปฏิบัติการพื้นฐานของโครงข่ายประสาทเทียม ใช้กฎการเรียนรู้ภายใต้การดูแลและสามารถจำแนกข้อมูลออกเป็นสองชั้น
ลักษณะการทำงานของเพอร์เซปตรอน: ประกอบด้วยเซลล์ประสาทเดียวที่มีจำนวนอินพุตตามอำเภอใจพร้อมกับน้ำหนักที่ปรับได้ แต่เอาต์พุตของเซลล์ประสาทคือ 1 หรือ 0 ขึ้นอยู่กับเกณฑ์ นอกจากนี้ยังประกอบด้วยอคติที่มีน้ำหนักเสมอ 1 รูปต่อไปนี้ให้การแสดงแผนผังของเพอร์เซปตรอน
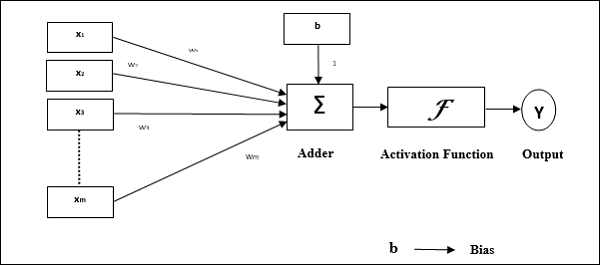
Perceptron จึงมีองค์ประกอบพื้นฐานสามประการดังต่อไปนี้ -
Links - มันจะมีชุดของลิงค์การเชื่อมต่อซึ่งมีน้ำหนักรวมถึงอคติที่มีน้ำหนักเสมอ 1
Adder - เพิ่มอินพุตหลังจากคูณด้วยน้ำหนักตามลำดับ
Activation function- มัน จำกัด การส่งออกของเซลล์ประสาท ฟังก์ชันการเปิดใช้งานขั้นพื้นฐานที่สุดคือฟังก์ชันขั้นตอน Heaviside ที่มีเอาต์พุตที่เป็นไปได้สองแบบ ฟังก์ชันนี้จะคืนค่า 1 หากอินพุตเป็นบวกและ 0 สำหรับอินพุตเชิงลบใด ๆ
อัลกอริทึมการฝึกอบรม
สามารถฝึกเครือข่าย Perceptron สำหรับยูนิตเอาต์พุตเดี่ยวและยูนิตเอาต์พุตหลายยูนิต
อัลกอริทึมการฝึกอบรมสำหรับหน่วยเอาต์พุตเดี่ยว
Step 1 - เริ่มต้นสิ่งต่อไปนี้เพื่อเริ่มการฝึกอบรม -
- Weights
- Bias
- อัตราการเรียนรู้ $ \ alpha $
เพื่อการคำนวณที่ง่ายและเรียบง่ายต้องกำหนดน้ำหนักและอคติให้เท่ากับ 0 และต้องกำหนดอัตราการเรียนรู้ให้เท่ากับ 1
Step 2 - ทำตามขั้นตอนที่ 3-8 ต่อเมื่อเงื่อนไขการหยุดไม่เป็นจริง
Step 3 - ทำต่อขั้นตอนที่ 4-6 สำหรับเวกเตอร์การฝึกทุกตัว x.
Step 4 - เปิดใช้งานหน่วยอินพุตแต่ละหน่วยดังนี้ -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: ถึง \: n) $$
Step 5 - ตอนนี้รับอินพุตสุทธิด้วยความสัมพันธ์ต่อไปนี้ -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ LIMIT_ {i} ^ n x_ {i}. \: w_ {i} $$
ที่นี่ ‘b’ เป็นอคติและ ‘n’ คือจำนวนเซลล์ประสาทอินพุตทั้งหมด
Step 6 - ใช้ฟังก์ชันการเปิดใช้งานต่อไปนี้เพื่อรับผลลัพธ์สุดท้าย
$$ f (y_ {in}) \: = \: \ begin {cases} 1 & if \: y_ {in} \:> \: \ theta \\ 0 & if \: - \ theta \: \ leqslant \ : y_ {in} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {in} \: <\: - \ theta \ end {cases} $$
Step 7 - ปรับน้ำหนักและอคติดังนี้ -
Case 1 - ถ้า y ≠ t จากนั้น
$$ w_ {i} (ใหม่) \: = \: w_ {i} (เก่า) \: + \: \ alpha \: tx_ {i} $$
$$ b (ใหม่) \: = \: b (เก่า) \: + \: \ alpha t $$
Case 2 - ถ้า y = t จากนั้น
$$ w_ {i} (ใหม่) \: = \: w_ {i} (เก่า) $$
$$ b (ใหม่) \: = \: b (เก่า) $$
ที่นี่ ‘y’ คือผลลัพธ์จริงและ ‘t’ คือผลลัพธ์ที่ต้องการ / เป้าหมาย
Step 8 - ทดสอบสภาพการหยุดซึ่งจะเกิดขึ้นเมื่อไม่มีการเปลี่ยนแปลงของน้ำหนัก
อัลกอริทึมการฝึกอบรมสำหรับหน่วยเอาต์พุตหลายหน่วย
แผนภาพต่อไปนี้เป็นสถาปัตยกรรมของ perceptron สำหรับเอาต์พุตหลายคลาส
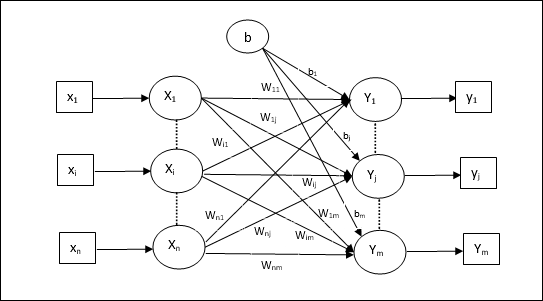
Step 1 - เริ่มต้นสิ่งต่อไปนี้เพื่อเริ่มการฝึกอบรม -
- Weights
- Bias
- อัตราการเรียนรู้ $ \ alpha $
เพื่อการคำนวณที่ง่ายและเรียบง่ายต้องกำหนดน้ำหนักและอคติให้เท่ากับ 0 และต้องกำหนดอัตราการเรียนรู้ให้เท่ากับ 1
Step 2 - ทำตามขั้นตอนที่ 3-8 ต่อเมื่อเงื่อนไขการหยุดไม่เป็นจริง
Step 3 - ทำต่อขั้นตอนที่ 4-6 สำหรับเวกเตอร์การฝึกทุกตัว x.
Step 4 - เปิดใช้งานหน่วยอินพุตแต่ละหน่วยดังนี้ -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: ถึง \: n) $$
Step 5 - รับอินพุตสุทธิด้วยความสัมพันธ์ต่อไปนี้ -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ LIMIT_ {i} ^ n x_ {i} \: w_ {ij} $$
ที่นี่ ‘b’ เป็นอคติและ ‘n’ คือจำนวนเซลล์ประสาทอินพุตทั้งหมด
Step 6 - ใช้ฟังก์ชันการเปิดใช้งานต่อไปนี้เพื่อรับเอาต์พุตสุดท้ายสำหรับเอาต์พุตแต่ละยูนิต j = 1 to m -
$$ f (y_ {in}) \: = \: \ begin {cases} 1 & if \: y_ {อันตราย} \:> \: \ theta \\ 0 & if \: - \ theta \: \ leqslant \ : y_ {อันตราย} \: \ leqslant \: \ theta \\ - 1 & if \: y_ {อันตราย} \: <\: - \ theta \ end {cases} $$
Step 7 - ปรับน้ำหนักและอคติสำหรับ x = 1 to n และ j = 1 to m ดังต่อไปนี้ -
Case 1 - ถ้า yj ≠ tj จากนั้น
$$ w_ {ij} (ใหม่) \: = \: w_ {ij} (เก่า) \: + \: \ alpha \: t_ {j} x_ {i} $$
$$ b_ {j} (ใหม่) \: = \: b_ {j} (เก่า) \: + \: \ alpha t_ {j} $$
Case 2 - ถ้า yj = tj จากนั้น
$$ w_ {ij} (ใหม่) \: = \: w_ {ij} (เก่า) $$
$$ b_ {j} (ใหม่) \: = \: b_ {j} (เก่า) $$
ที่นี่ ‘y’ คือผลลัพธ์จริงและ ‘t’ คือผลลัพธ์ที่ต้องการ / เป้าหมาย
Step 8 - ทดสอบสภาพการหยุดซึ่งจะเกิดขึ้นเมื่อไม่มีการเปลี่ยนแปลงของน้ำหนัก
เซลล์ประสาทเชิงเส้นปรับตัว (Adaline)
Adaline ซึ่งย่อมาจาก Adaptive Linear Neuron คือเครือข่ายที่มีหน่วยเชิงเส้นเดียว ได้รับการพัฒนาโดย Widrow and Hoff ในปี 1960 จุดสำคัญบางประการเกี่ยวกับ Adaline มีดังนี้ -
ใช้ฟังก์ชันการเปิดใช้งานสองขั้ว
ใช้กฎเดลต้าสำหรับการฝึกอบรมเพื่อลดข้อผิดพลาด Mean-Squared Error (MSE) ระหว่างเอาต์พุตจริงและเอาต์พุตที่ต้องการ / เป้าหมาย
น้ำหนักและอคติสามารถปรับได้
สถาปัตยกรรม
โครงสร้างพื้นฐานของ Adaline นั้นคล้ายกับ perceptron ที่มีลูปข้อเสนอแนะพิเศษซึ่งจะเปรียบเทียบผลลัพธ์จริงกับเอาต์พุตที่ต้องการ / เป้าหมาย หลังจากเปรียบเทียบบนพื้นฐานของอัลกอริทึมการฝึกแล้วน้ำหนักและอคติจะได้รับการอัปเดต
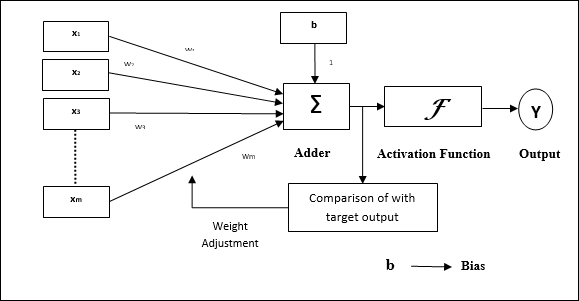
อัลกอริทึมการฝึกอบรม
Step 1 - เริ่มต้นสิ่งต่อไปนี้เพื่อเริ่มการฝึกอบรม -
- Weights
- Bias
- อัตราการเรียนรู้ $ \ alpha $
เพื่อการคำนวณที่ง่ายและเรียบง่ายต้องกำหนดน้ำหนักและอคติให้เท่ากับ 0 และต้องกำหนดอัตราการเรียนรู้ให้เท่ากับ 1
Step 2 - ทำตามขั้นตอนที่ 3-8 ต่อเมื่อเงื่อนไขการหยุดไม่เป็นจริง
Step 3 - ทำขั้นตอนที่ 4-6 ต่อสำหรับคู่ฝึกไบโพลาร์ทุกคู่ s:t.
Step 4 - เปิดใช้งานหน่วยอินพุตแต่ละหน่วยดังนี้ -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: ถึง \: n) $$
Step 5 - รับอินพุตสุทธิด้วยความสัมพันธ์ต่อไปนี้ -
$$ y_ {in} \: = \: b \: + \: \ displaystyle \ sum \ LIMIT_ {i} ^ n x_ {i} \: w_ {i} $$
ที่นี่ ‘b’ เป็นอคติและ ‘n’ คือจำนวนเซลล์ประสาทอินพุตทั้งหมด
Step 6 - ใช้ฟังก์ชันการเปิดใช้งานต่อไปนี้เพื่อรับผลลัพธ์สุดท้าย -
$$ f (y_ {in}) \: = \: \ begin {cases} 1 & if \: y_ {in} \: \ geqslant \: 0 \\ - 1 & if \: y_ {in} \: < \: 0 \ end {cases} $$
Step 7 - ปรับน้ำหนักและอคติดังนี้ -
Case 1 - ถ้า y ≠ t จากนั้น
$$ w_ {i} (ใหม่) \: = \: w_ {i} (เก่า) \: + \: \ alpha (t \: - \: y_ {in}) x_ {i} $$
$$ b (ใหม่) \: = \: b (เก่า) \: + \: \ alpha (t \: - \: y_ {in}) $$
Case 2 - ถ้า y = t จากนั้น
$$ w_ {i} (ใหม่) \: = \: w_ {i} (เก่า) $$
$$ b (ใหม่) \: = \: b (เก่า) $$
ที่นี่ ‘y’ คือผลลัพธ์จริงและ ‘t’ คือผลลัพธ์ที่ต้องการ / เป้าหมาย
$ (t \: - \; y_ {in}) $ คือข้อผิดพลาดในการคำนวณ
Step 8 - ทดสอบสภาพการหยุดซึ่งจะเกิดขึ้นเมื่อไม่มีการเปลี่ยนแปลงของน้ำหนักหรือการเปลี่ยนแปลงของน้ำหนักสูงสุดที่เกิดขึ้นระหว่างการฝึกซ้อมมีค่าน้อยกว่าค่าเผื่อที่กำหนด
เซลล์ประสาทเชิงเส้นปรับตัวหลายตัว (Madaline)
Madaline ซึ่งย่อมาจาก Multiple Adaptive Linear Neuron เป็นเครือข่ายที่ประกอบด้วย Adalines จำนวนมากควบคู่กัน มันจะมีหน่วยเอาท์พุตเดียว ประเด็นสำคัญบางประการเกี่ยวกับ Madaline มีดังนี้ -
มันเหมือนกับ Perceptron หลายชั้นโดยที่ Adaline จะทำหน้าที่เป็นหน่วยที่ซ่อนอยู่ระหว่างอินพุตและเลเยอร์ Madaline
น้ำหนักและความลำเอียงระหว่างชั้นอินพุตและชั้นอะดาไลน์ตามที่เราเห็นในสถาปัตยกรรม Adaline สามารถปรับได้
ชั้น Adaline และ Madaline มีน้ำหนักและอคติคงที่เท่ากับ 1
การฝึกอบรมสามารถทำได้ด้วยความช่วยเหลือของกฎเดลต้า
สถาปัตยกรรม
สถาปัตยกรรมของ Madaline ประกอบด้วย “n” เซลล์ประสาทของชั้นอินพุต “m”เซลล์ประสาทของชั้น Adaline และ 1 เซลล์ประสาทของชั้น Madaline ชั้น Adaline ถือได้ว่าเป็นชั้นที่ซ่อนอยู่เนื่องจากอยู่ระหว่างชั้นอินพุตและชั้นเอาต์พุตนั่นคือชั้น Madaline
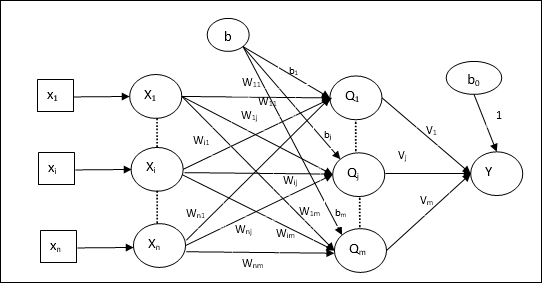
อัลกอริทึมการฝึกอบรม
ถึงตอนนี้เรารู้แล้วว่าต้องปรับเฉพาะน้ำหนักและอคติระหว่างชั้นอินพุตและชั้นอะดาลีนและน้ำหนักและอคติระหว่างชั้นอะดาลีนและชั้นมาดาไลน์ได้รับการแก้ไข
Step 1 - เริ่มต้นสิ่งต่อไปนี้เพื่อเริ่มการฝึกอบรม -
- Weights
- Bias
- อัตราการเรียนรู้ $ \ alpha $
เพื่อการคำนวณที่ง่ายและเรียบง่ายต้องกำหนดน้ำหนักและอคติให้เท่ากับ 0 และต้องกำหนดอัตราการเรียนรู้ให้เท่ากับ 1
Step 2 - ทำตามขั้นตอนที่ 3-8 ต่อเมื่อเงื่อนไขการหยุดไม่เป็นจริง
Step 3 - ทำขั้นตอนที่ 4-6 ต่อสำหรับคู่ฝึกไบโพลาร์ทุกคู่ s:t.
Step 4 - เปิดใช้งานหน่วยอินพุตแต่ละหน่วยดังนี้ -
$$ x_ {i} \: = \: s_ {i} \ :( i \: = \: 1 \: ถึง \: n) $$
Step 5 - รับอินพุตสุทธิในแต่ละชั้นที่ซ่อนอยู่นั่นคือชั้น Adaline ที่มีความสัมพันธ์ดังต่อไปนี้ -
$$ Q_ {อันตราย} \: = \: b_ {j} \: + \: \ displaystyle \ sum \ LIMIT_ {i} ^ n x_ {i} \: w_ {ij} \: \: \: j \: = \: 1 \: ถึง \: m $$
ที่นี่ ‘b’ เป็นอคติและ ‘n’ คือจำนวนเซลล์ประสาทอินพุตทั้งหมด
Step 6 - ใช้ฟังก์ชันการเปิดใช้งานต่อไปนี้เพื่อให้ได้ผลลัพธ์สุดท้ายที่ชั้น Adaline และชั้น Madaline -
$$ f (x) \: = \: \ begin {cases} 1 & if \: x \: \ geqslant \: 0 \\ - 1 & if \: x \: <\: 0 \ end {cases} $ $
เอาท์พุทที่หน่วย (Adaline) ที่ซ่อนอยู่
$$ Q_ {j} \: = \: f (Q_ {อันตราย}) $$
ผลลัพธ์สุดท้ายของเครือข่าย
$$ y \: = \: f (y_ {in}) $$
i.e. $ \: \: y_ {อันตราย} \: = \: b_ {0} \: + \: \ sum_ {j = 1} ^ m \: Q_ {j} \: v_ {j} $
Step 7 - คำนวณข้อผิดพลาดและปรับน้ำหนักดังนี้ -
Case 1 - ถ้า y ≠ t และ t = 1 จากนั้น
$$ w_ {ij} (ใหม่) \: = \: w_ {ij} (เก่า) \: + \: \ alpha (1 \: - \: Q_ {อันตราย}) x_ {i} $$
$$ b_ {j} (ใหม่) \: = \: b_ {j} (เก่า) \: + \: \ alpha (1 \: - \: Q_ {อันตราย}) $$
ในกรณีนี้น้ำหนักจะได้รับการอัปเดตเมื่อ Qj โดยที่อินพุตสุทธิใกล้เคียงกับ 0 เนื่องจาก t = 1.
Case 2 - ถ้า y ≠ t และ t = -1 จากนั้น
$$ w_ {ik} (ใหม่) \: = \: w_ {ik} (เก่า) \: + \: \ alpha (-1 \: - \: Q_ {ink}) x_ {i} $$
$$ b_ {k} (ใหม่) \: = \: b_ {k} (เก่า) \: + \: \ alpha (-1 \: - \: Q_ {ink}) $$
ในกรณีนี้น้ำหนักจะได้รับการอัปเดตเมื่อ Qk โดยที่อินพุตสุทธิเป็นบวกเพราะ t = -1.
ที่นี่ ‘y’ คือผลลัพธ์จริงและ ‘t’ คือผลลัพธ์ที่ต้องการ / เป้าหมาย
Case 3 - ถ้า y = t แล้ว
น้ำหนักจะไม่มีการเปลี่ยนแปลง
Step 8 - ทดสอบสภาพการหยุดซึ่งจะเกิดขึ้นเมื่อไม่มีการเปลี่ยนแปลงของน้ำหนักหรือการเปลี่ยนแปลงของน้ำหนักสูงสุดที่เกิดขึ้นระหว่างการฝึกซ้อมมีค่าน้อยกว่าค่าเผื่อที่กำหนด
ย้อนกลับเครือข่ายประสาทการแพร่กระจาย
Back Propagation Neural (BPN) คือโครงข่ายประสาทเทียมหลายชั้นซึ่งประกอบด้วยชั้นอินพุตชั้นที่ซ่อนอยู่และเลเยอร์เอาต์พุตอย่างน้อยหนึ่งชั้น ตามชื่อของมันการเผยแพร่ย้อนกลับจะเกิดขึ้นในเครือข่ายนี้ ข้อผิดพลาดซึ่งคำนวณที่เลเยอร์เอาต์พุตโดยการเปรียบเทียบเอาต์พุตเป้าหมายและเอาต์พุตจริงจะถูกส่งกลับไปยังเลเยอร์อินพุต
สถาปัตยกรรม
ดังที่แสดงในแผนภาพสถาปัตยกรรมของ BPN มีสามชั้นที่เชื่อมต่อกันซึ่งมีน้ำหนักอยู่ เลเยอร์ที่ซ่อนอยู่และเลเยอร์เอาต์พุตยังมีอคติซึ่งมีน้ำหนักเท่ากับ 1 เสมอ ดังที่เห็นได้ชัดจากแผนภาพการทำงานของ BPN มีสองขั้นตอน เฟสหนึ่งส่งสัญญาณจากชั้นอินพุตไปยังชั้นเอาต์พุตและอีกเฟสกลับเผยแพร่ข้อผิดพลาดจากชั้นเอาต์พุตไปยังชั้นอินพุต

อัลกอริทึมการฝึกอบรม
สำหรับการฝึกอบรม BPN จะใช้ฟังก์ชันการเปิดใช้งานไบนารีซิกมอยด์ การฝึกอบรมของ BPN จะมีสามขั้นตอนดังต่อไปนี้
Phase 1 - ฟีดไปข้างหน้าเฟส
Phase 2 - กลับเผยแพร่ข้อผิดพลาด
Phase 3 - อัปเดตน้ำหนัก
ขั้นตอนทั้งหมดนี้จะสรุปได้ในอัลกอริทึมดังนี้
Step 1 - เริ่มต้นสิ่งต่อไปนี้เพื่อเริ่มการฝึกอบรม -
- Weights
- อัตราการเรียนรู้ $ \ alpha $
สำหรับการคำนวณที่ง่ายและเรียบง่ายให้ใช้ค่าสุ่มเล็ก ๆ
Step 2 - ทำต่อขั้นตอนที่ 3-11 เมื่อเงื่อนไขการหยุดไม่เป็นจริง
Step 3 - ทำขั้นตอนที่ 4-10 ต่อทุกคู่การฝึก
ขั้นตอนที่ 1
Step 4 - หน่วยอินพุตแต่ละหน่วยรับสัญญาณอินพุต xi และส่งไปยังหน่วยที่ซ่อนอยู่สำหรับทุกคน i = 1 to n
Step 5 - คำนวณอินพุตสุทธิที่หน่วยที่ซ่อนอยู่โดยใช้ความสัมพันธ์ต่อไปนี้ -
$$ Q_ {อันตราย} \: = \: b_ {0j} \: + \: \ sum_ {i = 1} ^ n x_ {i} v_ {ij} \: \: \: \: j \: = \ : 1 \: ถึง \: p $$
ที่นี่ b0j คืออคติของหน่วยที่ซ่อนอยู่ vij น้ำหนักอยู่ที่ j หน่วยของเลเยอร์ที่ซ่อนอยู่มาจาก i หน่วยของชั้นอินพุต
ตอนนี้คำนวณผลลัพธ์สุทธิโดยใช้ฟังก์ชันการเปิดใช้งานต่อไปนี้
$$ Q_ {j} \: = \: f (Q_ {อันตราย}) $$
ส่งสัญญาณเอาต์พุตเหล่านี้ของยูนิตเลเยอร์ที่ซ่อนอยู่ไปยังยูนิตเลเยอร์เอาต์พุต
Step 6 - คำนวณอินพุตสุทธิที่หน่วยชั้นเอาต์พุตโดยใช้ความสัมพันธ์ต่อไปนี้ -
$$ y_ {ink} \: = \: b_ {0k} \: + \: \ sum_ {j = 1} ^ p \: Q_ {j} \: w_ {jk} \: \: k \: = \ : 1 \: ถึง \: m $$
ที่นี่ b0k เป็นอคติของหน่วยเอาท์พุท wjk น้ำหนักอยู่ที่ k หน่วยของชั้นเอาต์พุตที่มาจาก j หน่วยของชั้นที่ซ่อนอยู่
คำนวณผลลัพธ์สุทธิโดยใช้ฟังก์ชันการเปิดใช้งานต่อไปนี้
$$ y_ {k} \: = \: f (y_ {ink}) $$
ระยะที่ 2
Step 7 - คำนวณระยะการแก้ไขข้อผิดพลาดให้สอดคล้องกับรูปแบบเป้าหมายที่ได้รับในแต่ละหน่วยเอาต์พุตดังนี้ -
$$ \ delta_ {k} \: = \ :( t_ {k} \: - \: y_ {k}) f ^ {'} (y_ {ink}) $$
บนพื้นฐานนี้ให้อัปเดตน้ำหนักและอคติดังนี้ -
$$ \ Delta v_ {jk} \: = \: \ alpha \ delta_ {k} \: Q_ {ij} $$
$$ \ Delta b_ {0k} \: = \: \ alpha \ delta_ {k} $$
จากนั้นส่ง $ \ delta_ {k} $ กลับไปที่เลเยอร์ที่ซ่อนอยู่
Step 8 - ตอนนี้แต่ละหน่วยที่ซ่อนอยู่จะเป็นผลรวมของอินพุตเดลต้าจากหน่วยเอาต์พุต
$$ \ delta_ {อันตราย} \: = \: \ displaystyle \ sum \ LIMIT_ {k = 1} ^ m \ delta_ {k} \: w_ {jk} $$
สามารถคำนวณระยะผิดพลาดได้ดังนี้ -
$$ \ delta_ {j} \: = \: \ delta_ {อันตราย} f ^ {'} (Q_ {อันตราย}) $$
บนพื้นฐานนี้ให้อัปเดตน้ำหนักและอคติดังนี้ -
$$ \ Delta w_ {ij} \: = \: \ alpha \ delta_ {j} x_ {i} $$
$$ \ Delta b_ {0j} \: = \: \ alpha \ delta_ {j} $$
ระยะที่ 3
Step 9 - แต่ละหน่วยเอาต์พุต (ykk = 1 to m) ปรับปรุงน้ำหนักและอคติดังนี้ -
$$ v_ {jk} (ใหม่) \: = \: v_ {jk} (เก่า) \: + \: \ Delta v_ {jk} $$
$$ b_ {0k} (ใหม่) \: = \: b_ {0k} (เก่า) \: + \: \ Delta b_ {0k} $$
Step 10 - แต่ละหน่วยเอาต์พุต (zjj = 1 to p) ปรับปรุงน้ำหนักและอคติดังนี้ -
$$ w_ {ij} (ใหม่) \: = \: w_ {ij} (เก่า) \: + \: \ Delta w_ {ij} $$
$$ b_ {0j} (ใหม่) \: = \: b_ {0j} (เก่า) \: + \: \ Delta b_ {0j} $$
Step 11 - ตรวจสอบเงื่อนไขการหยุดซึ่งอาจเป็นได้ทั้งจำนวนยุคที่ถึงหรือผลลัพธ์เป้าหมายตรงกับผลลัพธ์จริง
กฎการเรียนรู้ทั่วไปของ Delta
กฎเดลต้าใช้งานได้กับเลเยอร์เอาต์พุตเท่านั้น ในทางกลับกันกฎเดลต้าทั่วไปเรียกอีกอย่างว่าback-propagation กฎคือวิธีการสร้างค่าที่ต้องการของเลเยอร์ที่ซ่อนอยู่
การกำหนดทางคณิตศาสตร์
สำหรับฟังก์ชั่นการเปิดใช้งาน $ y_ {k} \: = \: f (y_ {ink}) $ การมาของอินพุตสุทธิบนเลเยอร์ที่ซ่อนอยู่และในชั้นเอาต์พุตสามารถกำหนดได้โดย
$$ y_ {ink} \: = \: \ displaystyle \ sum \ LIMIT_i \: z_ {i} w_ {jk} $$
และ $ \: \: y_ {อันตราย} \: = \: \ sum_i x_ {i} v_ {ij} $
ตอนนี้ข้อผิดพลาดที่ต้องย่อให้เล็กที่สุดคือ
$$ E \: = \: \ frac {1} {2} \ displaystyle \ sum \ LIMIT_ {k} \: [t_ {k} \: - \: y_ {k}] ^ 2 $$
โดยใช้กฎลูกโซ่เรามี
$$ \ frac {\ partial E} {\ partial w_ {jk}} \: = \: \ frac {\ partial} {\ partial w_ {jk}} (\ frac {1} {2} \ displaystyle \ sum \ Limit_ {k} \: [t_ {k} \: - \: y_ {k}] ^ 2) $$
$$ = \: \ frac {\ partial} {\ partial w_ {jk}} \ lgroup \ frac {1} {2} [t_ {k} \: - \: t (y_ {ink})] ^ 2 \ rgroup $$
$$ = \: - [t_ {k} \: - \: y_ {k}] \ frac {\ partial} {\ partial w_ {jk}} f (y_ {ink}) $$
$$ = \: - [t_ {k} \: - \: y_ {k}] f (y_ {ink}) \ frac {\ partial} {\ partial w_ {jk}} (y_ {ink}) $$
$$ = \: - [t_ {k} \: - \: y_ {k}] f ^ {'} (y_ {ink}) z_ {j} $$
ตอนนี้ให้เราพูดว่า $ \ delta_ {k} \: = \: - [t_ {k} \: - \: y_ {k}] f ^ {'} (y_ {ink}) $
น้ำหนักในการเชื่อมต่อกับหน่วยที่ซ่อนอยู่ zj ได้โดย -
$$ \ frac {\ partial E} {\ partial v_ {ij}} \: = \: - \ displaystyle \ sum \ LIMIT_ {k} \ delta_ {k} \ frac {\ partial} {\ partial v_ {ij} } \ :( y_ {ink}) $$
ใส่ค่า $ y_ {ink} $ เราจะได้สิ่งต่อไปนี้
$$ \ delta_ {j} \: = \: - \ displaystyle \ sum \ LIMIT_ {k} \ delta_ {k} w_ {jk} f ^ {'} (z_ {อันตราย}) $$
การอัปเดตน้ำหนักสามารถทำได้ดังนี้ -
สำหรับหน่วยเอาต์พุต -
$$ \ Delta w_ {jk} \: = \: - \ alpha \ frac {\ partial E} {\ partial w_ {jk}} $$
$$ = \: \ alpha \: \ delta_ {k} \: z_ {j} $$
สำหรับยูนิตที่ซ่อนอยู่ -
$$ \ Delta v_ {ij} \: = \: - \ alpha \ frac {\ partial E} {\ partial v_ {ij}} $$
$$ = \: \ alpha \: \ delta_ {j} \: x_ {i} $$