การเรียนรู้ปริมาณเวกเตอร์
Learning Vector Quantization (LVQ) ซึ่งแตกต่างจาก Vector quantization (VQ) และ Kohonen Self-Organizing Maps (KSOM) โดยพื้นฐานแล้วเป็นเครือข่ายการแข่งขันที่ใช้การเรียนรู้ภายใต้การดูแล เราอาจกำหนดให้เป็นกระบวนการในการจำแนกรูปแบบโดยที่แต่ละหน่วยเอาต์พุตแสดงถึงคลาส เนื่องจากใช้การเรียนรู้ภายใต้การดูแลเครือข่ายจะได้รับชุดของรูปแบบการฝึกอบรมที่มีการจำแนกประเภทที่รู้จักพร้อมกับการกระจายเริ่มต้นของคลาสเอาต์พุต หลังจากเสร็จสิ้นขั้นตอนการฝึก LVQ จะจำแนกเวกเตอร์อินพุตโดยกำหนดให้เป็นคลาสเดียวกับของหน่วยเอาต์พุต
สถาปัตยกรรม
รูปต่อไปนี้แสดงสถาปัตยกรรมของ LVQ ซึ่งค่อนข้างคล้ายกับสถาปัตยกรรมของ KSOM อย่างที่เราเห็นก็มี“n” จำนวนหน่วยอินพุตและ “m”จำนวนหน่วยเอาต์พุต เลเยอร์มีการเชื่อมต่อกันอย่างเต็มที่โดยมีน้ำหนักอยู่

พารามิเตอร์ที่ใช้
ต่อไปนี้เป็นพารามิเตอร์ที่ใช้ในกระบวนการฝึกอบรม LVQ รวมทั้งในผังงาน
x= เวกเตอร์การฝึก (x 1 , ... , x i , ... , x n )
T = คลาสสำหรับเวกเตอร์การฝึกอบรม x
wj = เวกเตอร์น้ำหนักสำหรับ jth หน่วยเอาต์พุต
Cj = คลาสที่เชื่อมโยงกับ jth หน่วยเอาต์พุต
อัลกอริทึมการฝึกอบรม
Step 1 - เริ่มต้นเวกเตอร์อ้างอิงซึ่งสามารถทำได้ดังนี้ -
Step 1(a) - จากชุดเวกเตอร์การฝึกที่กำหนดให้เลือก "m” (จำนวนคลัสเตอร์) ฝึกเวกเตอร์และใช้เป็นเวกเตอร์น้ำหนัก เวกเตอร์ที่เหลือสามารถใช้สำหรับการฝึกอบรม
Step 1(b) - กำหนดน้ำหนักเริ่มต้นและการจำแนกแบบสุ่ม
Step 1(c) - ใช้ K-mean clustering method
Step 2 - เริ่มต้นเวกเตอร์อ้างอิง $ \ alpha $
Step 3 - ทำตามขั้นตอนที่ 4-9 ต่อไปหากไม่เป็นไปตามเงื่อนไขในการหยุดอัลกอริทึมนี้
Step 4 - ทำตามขั้นตอนที่ 5-6 สำหรับเวกเตอร์อินพุตการฝึกทุกตัว x.
Step 5 - คำนวณกำลังสองของระยะทางแบบยุคลิดสำหรับ j = 1 to m และ i = 1 to n
$$ D (j) \: = \: \ displaystyle \ sum \ LIMIT_ {i = 1} ^ n \ displaystyle \ sum \ LIMIT_ {j = 1} ^ m (x_ {i} \: - \: w_ {ij }) ^ 2 $$
Step 6 - รับหน่วยที่ชนะ J ที่ไหน D(j) เป็นขั้นต่ำ
Step 7 - คำนวณน้ำหนักใหม่ของหน่วยที่ชนะตามความสัมพันธ์ต่อไปนี้ -
ถ้า T = Cj แล้ว $ w_ {j} (ใหม่) \: = \: w_ {j} (เก่า) \: + \: \ alpha [x \: - \: w_ {j} (เก่า)] $
ถ้า T ≠ Cj แล้ว $ w_ {j} (ใหม่) \: = \: w_ {j} (เก่า) \: - \: \ alpha [x \: - \: w_ {j} (เก่า)] $
Step 8 - ลดอัตราการเรียนรู้ $ \ alpha $
Step 9- ทดสอบสภาพการหยุด อาจเป็นดังนี้ -
- ถึงจำนวนสูงสุดของยุคแล้ว
- อัตราการเรียนรู้ลดลงเหลือเพียงเล็กน้อย
ผังงาน
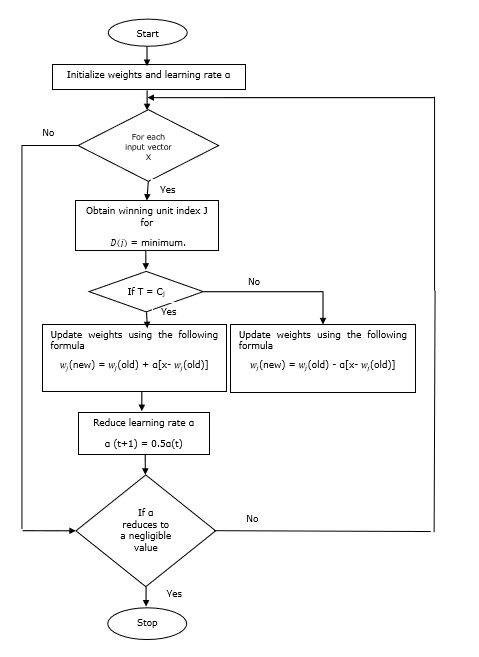
ตัวแปร
อีกสามสายพันธุ์ ได้แก่ LVQ2, LVQ2.1 และ LVQ3 ได้รับการพัฒนาโดย Kohonen ความซับซ้อนในทั้งสามสายพันธุ์เนื่องจากแนวคิดที่ผู้ชนะและหน่วยรองชนะเลิศจะได้เรียนรู้มากกว่าใน LVQ
LVQ2
ตามที่กล่าวไว้แนวคิดของสายพันธุ์อื่น ๆ ของ LVQ ข้างต้นเงื่อนไขของ LVQ2 ถูกสร้างขึ้นโดยหน้าต่าง หน้าต่างนี้จะขึ้นอยู่กับพารามิเตอร์ต่อไปนี้ -
x - เวกเตอร์อินพุตปัจจุบัน
yc - เวกเตอร์อ้างอิงที่ใกล้เคียงที่สุด x
yr - เวกเตอร์อ้างอิงอื่น ๆ ซึ่งอยู่ใกล้ที่สุด x
dc - ระยะทางจาก x ถึง yc
dr - ระยะทางจาก x ถึง yr
เวกเตอร์อินพุต x ตกหน้าต่างถ้า
$$ \ frac {d_ {c}} {d_ {r}} \:> \: 1 \: - \: \ theta \: \: และ \: \: \ frac {d_ {r}} {d_ {c }} \:> \: 1 \: + \: \ theta $$
ที่นี่ $ \ theta $ คือจำนวนตัวอย่างการฝึกอบรม
การอัปเดตสามารถทำได้ด้วยสูตรต่อไปนี้ -
$ y_ {c} (t \: + \: 1) \: = \: y_ {c} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c} (ท)] $ (belongs to different class)
$ y_ {r} (t \: + \: 1) \: = \: y_ {r} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {r} (ท)] $ (belongs to same class)
ที่นี่ $ \ alpha $ คืออัตราการเรียนรู้
LVQ2.1
ใน LVQ2.1 เราจะหาเวกเตอร์ที่ใกล้เคียงที่สุดสองตัวคือ yc1 และ yc2 และเงื่อนไขสำหรับหน้าต่างมีดังนี้ -
$$ นาที \ เริ่มต้น {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \:> \ :( 1 \ : - \: \ theta) $$
$$ Max \ begin {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \: <\ :( 1 \ : + \: \ theta) $$
การอัปเดตสามารถทำได้ด้วยสูตรต่อไปนี้ -
$ y_ {c1} (t \: + \: 1) \: = \: y_ {c1} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c1} (ท)] $ (belongs to different class)
$ y_ {c2} (t \: + \: 1) \: = \: y_ {c2} (t) \: + \: \ alpha (t) [x (t) \: - \: y_ {c2} (ท)] $ (belongs to same class)
ที่นี่ $ \ alpha $ คืออัตราการเรียนรู้
LVQ3
ใน LVQ3 เราจะหาเวกเตอร์ที่ใกล้เคียงที่สุดสองตัวคือ yc1 และ yc2 และเงื่อนไขสำหรับหน้าต่างมีดังนี้ -
$$ นาที \ เริ่มต้น {bmatrix} \ frac {d_ {c1}} {d_ {c2}}, \ frac {d_ {c2}} {d_ {c1}} \ end {bmatrix} \:> \ :( 1 \ : - \: \ theta) (1 \: + \: \ theta) $$
ที่นี่ $ \ theta \ ประมาณ 0.2 $
การอัปเดตสามารถทำได้ด้วยสูตรต่อไปนี้ -
$ y_ {c1} (t \: + \: 1) \: = \: y_ {c1} (t) \: + \: \ beta (t) [x (t) \: - \: y_ {c1} (ท)] $ (belongs to different class)
$ y_ {c2} (t \: + \: 1) \: = \: y_ {c2} (t) \: + \: \ beta (t) [x (t) \: - \: y_ {c2} (ท)] $ (belongs to same class)
ที่นี่ $ \ beta $ คือผลคูณของอัตราการเรียนรู้ $ \ alpha $ และ $\beta\:=\:m \alpha(t)$ สำหรับทุกๆ 0.1 < m < 0.5