DIP-クイックガイド
前書き
信号処理は、電気工学および数学の分野であり、アナログおよびデジタル信号の分析と処理を扱い、信号の保存、フィルタリング、およびその他の操作を扱います。これらの信号には、送信信号、音声または音声信号、画像信号、およびその他の信号などが含まれます。
これらすべての信号のうち、入力が画像で出力も画像である信号の種類を扱うフィールドは、画像処理で行われます。その名前が示すように、それは画像の処理を扱います。
さらに、アナログ画像処理とデジタル画像処理に分けることができます。
アナログ画像処理
アナログ画像処理は、アナログ信号で行われます。これには、2次元アナログ信号の処理が含まれます。このタイプの処理では、画像は電気信号を変化させることによって電気的手段によって操作されます。一般的な例としては、テレビの画像があります。
デジタル画像処理は、その幅広いアプリケーションのために時間の経過とともにアナログ画像処理よりも支配的でした。
デジタル画像処理
デジタル画像処理は、デジタル画像に対して操作を実行するデジタルシステムの開発を扱います。
画像とは
画像は二次元信号にすぎません。これは、数学関数f(x、y)によって定義されます。ここで、xとyは、水平方向と垂直方向の2つの座標です。
任意の点でのf(x、y)の値は、画像のその点でのピクセル値を示します。

上の図は、現在コンピューターの画面に表示されているデジタル画像の例です。しかし実際には、この画像は0から255の範囲の数値の2次元配列にすぎません。
| 128 | 30 | 123 |
| 232 | 123 | 321 |
| 123 | 77 | 89 |
| 80 | 255 | 255 |
各数値は、任意の時点での関数f(x、y)の値を表します。この場合、値128、230、123はそれぞれ個々のピクセル値を表します。画像の寸法は、実際にはこの2次元配列の寸法です。
デジタル画像と信号の関係
画像が2次元配列の場合、信号とは何の関係がありますか?それを理解するためには、まずシグナルとは何かを理解する必要がありますか?
信号
物理的な世界では、空間またはより高い次元で時間の経過とともに測定可能な任意の量を信号と見なすことができます。信号は数学関数であり、いくつかの情報を伝達します。信号は、1次元または2次元以上の信号にすることができます。一次元信号は、時間の経過とともに測定される信号です。一般的な例は音声信号です。2次元信号は、他の物理量で測定された信号です。二次元信号の例はデジタル画像です。次のチュートリアルでは、1次元または2次元の信号と、より高い信号がどのように形成され、解釈されるかについて詳しく説明します。
関係
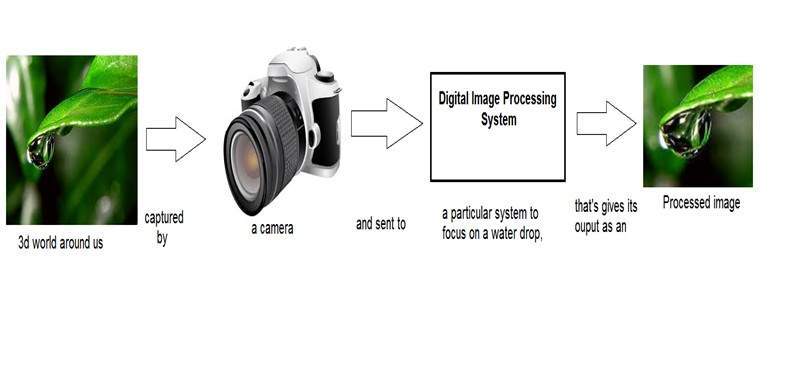
2人の観察者の間で物理的な世界で情報を伝えたりメッセージを放送したりするものはすべて信号です。これには、音声または(人間の声)または信号としての画像が含まれます。私たちが話すとき、私たちの声は音波/信号に変換され、私たちが話している人への時間に関して変換されます。これだけでなく、デジタルカメラから画像を取得する際のデジタルカメラの動作方法には、システムのある部分から別の部分への信号の転送が含まれます。
デジタル画像の形成方法
カメラから画像をキャプチャすることは物理的なプロセスであるため。太陽光はエネルギー源として使用されます。センサーアレイは、画像の取得に使用されます。そのため、太陽光が物体に当たると、その物体で反射された光の量がセンサーによって感知され、感知されたデータの量によって連続的な電圧信号が生成されます。デジタル画像を作成するには、このデータをデジタル形式に変換する必要があります。これには、サンプリングと量子化が含まれます。(これらについては後で説明します)。サンプリングと量子化の結果は、デジタル画像に他ならない数の2次元配列または行列になります。
重複するフィールド
マシン/コンピュータービジョン
マシンビジョンまたはコンピュータービジョンは、入力が画像であり、出力がいくつかの情報であるシステムの開発を扱います。例:人間の顔をスキャンしてあらゆる種類のロックを開くシステムの開発。このシステムは次のようになります。

コンピューターグラフィックス
コンピュータグラフィックスは、画像が何らかのデバイスによってキャプチャされるのではなく、オブジェクトモデルからの画像の形成を扱います。例:オブジェクトのレンダリング。オブジェクトモデルから画像を生成します。このようなシステムは次のようになります。
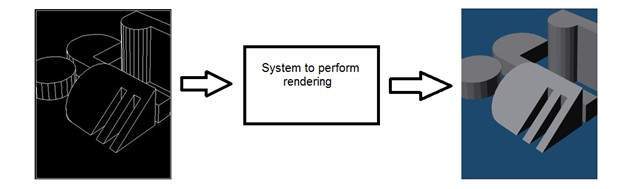
人工知能
人工知能は、多かれ少なかれ、人間の知能を機械に組み込む研究です。人工知能は、画像処理に多くの用途があります。例:医師がX線、MRIなどの画像を解釈し、医師が検査する目立つ部分を強調表示するのに役立つコンピュータ支援診断システムを開発します。
信号処理
信号処理は傘であり、画像処理はその下にあります。物理世界(3D世界)で物体によって反射された光の量は、カメラのレンズを通過し、2D信号になり、結果として画像が形成されます。次に、この画像は信号処理の方法を使用してデジタル化され、次にこのデジタル画像はデジタル画像処理で操作されます。
このチュートリアルでは、デジタル画像処理の概念を理解するために必要な信号とシステムの基本について説明します。詳細な概念に入る前に、まず簡単な用語を定義しましょう。
シグナル
電気工学では、ある情報を表す基本的な量は信号と呼ばれます。情報が何であるかは関係ありません。つまり、アナログまたはデジタル情報です。数学では、信号はいくつかの情報を伝える関数です。実際、空間またはより高い次元で時間の経過とともに測定可能な任意の量を信号と見なすことができます。信号は任意の次元であり、任意の形式である可能性があります。
アナログ信号
信号は、時間に関して定義されることを意味するアナログ量である可能性があります。連続信号です。これらの信号は、連続的な独立変数に対して定義されます。それらは膨大な数の値を持っているため、分析が困難です。値のサンプルが多いため、非常に正確です。これらの信号を保存するには、実数直線上で無限の値を達成できるため、無限のメモリが必要です。アナログ信号は正弦波で表されます。
例えば:
人間の声
人間の声はアナログ信号の一例です。あなたが話すとき、生成される声は圧力波の形で空気中を伝わり、したがって、空間と時間の独立変数と気圧に対応する値を持つ数学関数に属します。
もう1つの例は、次の図に示す正弦波です。
Y = sin(x)ここで、xは独立しています

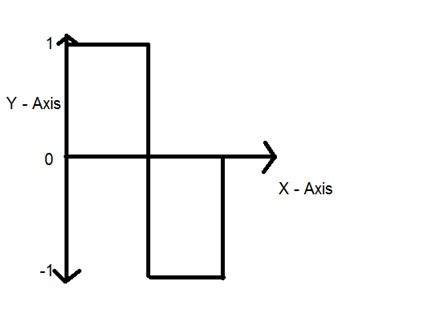
デジタル信号
アナログ信号と比較して、デジタル信号は分析が非常に簡単です。それらは不連続な信号です。それらはアナログ信号の流用です。
デジタルという言葉は離散値を表します。したがって、特定の値を使用して情報を表すことを意味します。デジタル信号では、1と0(バイナリ値)の2つの値のみが何かを表すために使用されます。デジタル信号は、一定期間にわたって取得されたアナログ信号の離散サンプルであるため、アナログ信号よりも精度が低くなります。ただし、デジタル信号はノイズの影響を受けません。したがって、それらは長持ちし、解釈が容易です。デジタル信号は方形波で表されます。
例えば:
キーボード
キーボードからキーが押されるたびに、その特定のキーのASCII値を含む適切な電気信号がキーボードコントローラーに送信されます。たとえば、キーボードのキーaが押されたときに生成される電気信号は、文字aのASCII値である0と1の形式で数字97の情報を伝達します。
アナログ信号とデジタル信号の違い
| 比較要素 | アナログ信号 | デジタル信号 |
|---|---|---|
| 分析 | 難しい | 分析可能 |
| 表現 | 継続的 | 不連続 |
| 正確さ | より正確な | 精度が低い |
| ストレージ | 無限の記憶 | 簡単に保管 |
| ノイズの影響を受ける | はい | 番号 |
| 録音テクニック | 元の信号は保持されます | 信号のサンプルが取得され、保存されます |
| 例 | 人間の声、温度計、アナログ電話など | コンピュータ、デジタル電話、デジタルペンなど |
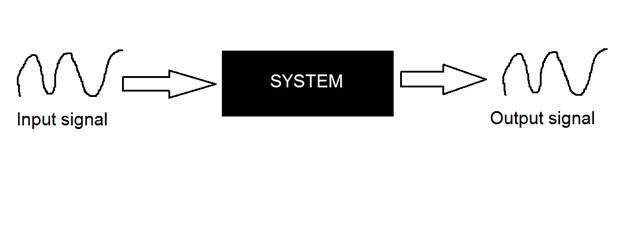
システム
システムは、処理する入力と出力のタイプによって定義されます。信号を扱っているので、この場合、システムは数学モデル、コード/ソフトウェア、または物理デバイス、または入力が信号であり、その信号に対して何らかの処理を実行するブラックボックスになります。出力は信号です。入力は励起と呼ばれ、出力は応答と呼ばれます。

上の図では、入力と出力の両方が信号であるが、入力がアナログ信号であるシステムが示されています。そして、出力はデジタル信号です。これは、私たちのシステムが実際にはアナログ信号をデジタル信号に変換する変換システムであることを意味します。
このブラックボックスシステムの内部を見てみましょう
アナログ信号からデジタル信号への変換
このアナログからデジタルへの変換、およびその逆に関連する概念がたくさんあるためです。ここでは、デジタル画像処理に関連するものについてのみ説明します。取材に関係する2つの主要な概念があります。
Sampling
Quantization
サンプリング
その名前が示すように、サンプリングはサンプルを取ると定義できます。x軸上のデジタル信号のサンプルを取得します。サンプリングは独立変数で行われます。この数式の場合:
サンプリングはx変数で行われます。x軸(無限大)からデジタルへの変換はサンプリングで行われているとも言えます。
サンプリングはさらにアップサンプリングとダウンサンプリングに分けられます。x軸の値の範囲が狭い場合は、値のサンプルを増やします。これはアップサンプリングと呼ばれ、その逆もダウンサンプリングと呼ばれます。
量子化
その名前が示すように、量子化は、量子(パーティション)に分割することとして定義できます。量子化は従属変数で行われます。サンプリングとは逆です。
この数式の場合、y = sin(x)
量子化はY変数で行われます。これはy軸で行われます。y軸の無限値を1、0、-1(またはその他のレベル)に変換することは、量子化として知られています。
これらは、アナログ信号をデジタル信号に変換する際に必要な2つの基本的な手順です。
信号の量子化を下図に示します。
なぜアナログ信号をデジタル信号に変換する必要があるのですか。
最初の明白な理由は、デジタル画像処理がデジタル信号であるデジタル画像を扱うということです。したがって、画像がキャプチャされるたびに、デジタル形式に変換されてから処理されます。
2番目の重要な理由は、デジタルコンピュータでアナログ信号の操作を実行するには、そのアナログ信号をコンピュータに保存する必要があるということです。そして、アナログ信号を保存するためには、それを保存するために無限のメモリが必要です。そして、それは不可能なので、その信号をデジタル形式に変換し、デジタルコンピュータに保存して、操作を実行するのはそのためです。
連続システムと離散システム
連続システム
入力と出力の両方が連続信号またはアナログ信号であるタイプのシステムは、連続システムと呼ばれます。
ディスクリートシステム
入力と出力の両方が離散信号またはデジタル信号であるシステムのタイプは、デジタルシステムと呼ばれます
カメラの起源
カメラと写真の歴史はまったく同じではありません。カメラの概念は、写真の概念よりもずっと前に導入されました
カメラオブスキュラ
カメラの歴史はアジアにあります。カメラの原理は、中国の哲学者MOZIによって最初に導入されました。それはカメラオブスクラとして知られています。カメラはこの原理から進化しました。
カメラオブスクラという言葉は、2つの異なる言葉から進化したものです。カメラとオブスクラ。カメラという言葉の意味は部屋またはある種の金庫室であり、オブスキュラは暗闇を意味します。
中国の哲学者によって導入された概念は、壁に周囲のイメージを投影するデバイスで構成されています。しかし、それは中国人によって建てられたものではありません。
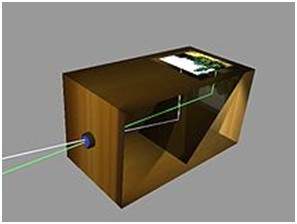
カメラオブスクラの作成
中国語の概念は、イスラム教徒の科学者アブ・アリ・アル・ハッサン・イブン・アル・ハイサム(通称イブン・アル・ハイサム)によって実現されました。彼は最初のカメラオブスクラを作りました。彼のカメラはピンホールカメラの原理に従っています。彼はこのデバイスを約1000のどこかに構築します。
ポータブルカメラ
1685年、最初のポータブルカメラがヨハンツァーンによって製造されました。このデバイスが登場する前は、カメラは部屋の大きさで構成されており、持ち運びできませんでした。デバイスはアイルランドの科学者ロバートボイルとロバートフックによって作られた可搬型カメラでしたが、それでもそのデバイスはある場所から別の場所に運ぶには非常に巨大でした。
写真の起源
カメラオブスクラはイスラム教徒の科学者によって1000年に建てられましたが。しかし、その最初の実際の使用は、13世紀に英国の哲学者ロジャーベーコンによって説明されました。ロジャーは日食の観測にカメラの使用を提案しました。
ダ・ヴィンチ
15世紀以前には多くの改善がなされてきましたが、レオナルド・ディ・セル・ピエロ・ダ・ヴィンチによる改善と発見は目覚ましいものでした。ダヴィンチは偉大な芸術家、音楽家、解剖学者、そして戦争技術者でした。彼は多くの発明の功績が認められています。彼の最も有名な絵の1つには、モナリザの絵が含まれます。

ダヴィンチは、ピンホールカメラの原理に従ってカメラオブスクラを作成しただけでなく、彼の芸術作品の描画補助としても使用しています。Codex Atlanticusで説明されている彼の作品では、カメラオブスクラの多くの原則が定義されています。
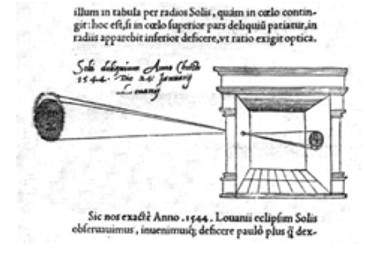
彼のカメラは、ピンホールカメラの原理に従っています。
照らされたオブジェクトの画像が小さな穴を通って非常に暗い部屋に入ると、[反対側の壁に]これらのオブジェクトが適切な形と色で表示され、光線の交差により逆の位置でサイズが縮小されます。
最初の写真
最初の写真は、1814年にフランスの発明家ジョセフニセフォールニエプスによって撮影されました。彼は、ピュータープレートをビチューメンでコーティングし、その後そのプレートを光にさらすことによって、ルグラの窓からの眺めの最初の写真をキャプチャします。

最初の水中写真
最初の水中写真は、英国の数学者ウィリアム・トムソンが水密ボックスを使用して撮影したものです。これは1856年に行われました。

映画の起源
映画の起源は、アメリカの発明家であり、写真のパイオニアと見なされているジョージ・イーストマンとして知られる慈善家によって紹介されました。
彼は、映画の開発で有名なイーストマンコダックという会社を設立しました。同社は1885年に紙フィルムの製造を開始しました。彼は最初にカメラコダックを作成し、次にブラウニーを作成しました。ブローニーはボックスカメラであり、スナップショットの機能により人気を博しました。

映画の登場後、カメラ業界は再びブームになり、ある発明が別の発明につながりました。
ライカとアーガス
ライカとアーガスは、それぞれ1925年と1939年に開発された2台のアナログカメラです。カメラライカは35mmシネフィルムを使用して作られました。

アーガスは35mmフォーマットを使用する別のカメラアナログカメラであり、ライカに比べてかなり安価であり、非常に人気がありました。

アナログCCTVカメラ
1942年、ドイツのエンジニアであるWalter Bruchが、アナログCCTVカメラの最初のシステムを開発して設置しました。彼はまた、1960年にカラーテレビを発明したことでも知られています。
フォトパック
最初の使い捨てカメラは、1949年にPhotoPacによって導入されました。このカメラは、フィルムのロールがすでに含まれている1回限りのカメラでした。Photo pacの新しいバージョンは防水で、フラッシュも付いています。

デジタルカメラ
ソニーのマビカ
マビカ(磁気ビデオカメラ)は1981年にソニーによって発売され、デジタルカメラの世界で最初のゲームチェンジャーでした。画像はフロッピーディスクに記録されており、後でどのモニター画面でも見ることができます。
それは純粋なデジタルカメラではなく、アナログカメラでした。しかし、フロッピーディスクに画像を保存できるため、人気を博しました。これは、画像を長期間保存できることを意味し、フロッピーに大量の画像を保存して、いっぱいになったときに新しい空のディスクに置き換えることができます。マビカはディスクに25枚の画像を保存する容量があります。
マビカが導入したもう1つの重要なことは、写真をキャプチャする0.3メガピクセルの容量でした。

デジタルカメラ
Fuji DS-1P camera 富士フイルム1988年は最初の真のデジタルカメラでした
Nikon D1 は2.74メガピクセルのカメラであり、ニコンが開発した最初の商用デジタル一眼レフカメラであり、専門家によって非常に手頃な価格でした。

今日、デジタルカメラは非常に高い解像度と品質で携帯電話に含まれています。
デジタル画像処理には非常に幅広い用途があり、ほとんどすべての技術分野がDIPの影響を受けるため、DIPの主要な用途のいくつかについて説明します。
デジタル画像処理は、カメラで撮影された日常の画像の空間解像度を調整するだけではありません。写真の明るさなどを上げるだけでなく、それだけではありません。
電磁波は、各粒子が光速で移動する粒子の流れと考えることができます。各粒子にはエネルギーの束が含まれています。このエネルギーの束は光子と呼ばれます。
光子のエネルギーに応じた電磁スペクトルを以下に示します。

この電磁スペクトルでは、可視スペクトルしか見ることができません。可視スペクトルには、主に(VIBGOYR)と一般に呼ばれる7つの異なる色が含まれています。VIBGOYRは、バイオレット、インディゴ、ブルー、グリーン、オレンジ、イエロー、レッドの略です。
しかし、それはスペクトル内の他のものの存在を無効にするものではありません。私たちの人間の目は、すべてのオブジェクトを見た目に見える部分しか見ることができません。しかし、カメラは肉眼では見ることができない他のものを見ることができます。例:X線、ガンマ線などしたがって、これらすべての分析もデジタル画像処理で行われます。
この議論は別の質問につながります
なぜEMスペクトルの他のすべてのものも分析する必要があるのですか?
X線のような他のものが医療の分野で広く使われているので、この質問への答えは事実にあります。ガンマ線の分析は、核医学や天文観測で広く利用されているため、必要です。同じことがEMスペクトルの他のものにも当てはまります。
デジタル画像処理の応用
デジタル画像処理が広く使用されている主な分野のいくつかを以下に示します。
画像の鮮明化と復元
医療分野
リモートセンシング
送信とエンコード
機械/ロボットのビジョン
色処理
パターン認識
ビデオ処理
顕微鏡イメージング
Others
画像の鮮明化と復元
ここでの画像の鮮鋭化と復元とは、最新のカメラからキャプチャされた画像を処理して、より良い画像にするか、目的の結果を達成するようにそれらの画像を操作することを指します。これは、Photoshopが通常行うことを行うことを指します。
これには、ズーム、ぼかし、シャープ、グレースケールから色への変換、エッジの検出、およびその逆、画像検索、画像認識が含まれます。一般的な例は次のとおりです。
元の画像

ズーム画像

ぼやけた画像

シャープな画像

エッジ

医療分野
医療分野でのDIPの一般的な用途は次のとおりです。
ガンマ線イメージング
PETスキャン
X線イメージング
医療CT
UVイメージング
UVイメージング
リモートセンシングの分野では、地球の領域を衛星または非常に高い地面からスキャンし、分析して情報を取得します。リモートセンシングの分野におけるデジタル画像処理の1つの特定のアプリケーションは、地震によって引き起こされたインフラストラクチャの損傷を検出することです。
深刻な被害に焦点を当てても、被害の把握に時間がかかるため。地震の影響を受ける地域は非常に広い場合があるため、被害を推定するために人間の目で調べることはできません。たとえそうだとしても、それは非常に多忙で時間のかかる手順です。したがって、これに対する解決策はデジタル画像処理にあります。被災地の画像を地上から撮影し、解析して地震によるさまざまな被害を検知します。
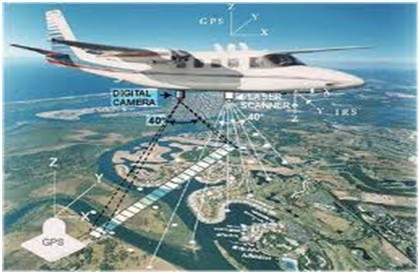
分析に含まれる重要なステップは次のとおりです。
エッジの抽出
さまざまなタイプのエッジの分析と強化
送信とエンコード
有線で送信された最初の画像は、海底ケーブルを介してロンドンからニューヨークに送信されました。送信された写真を以下に示します。
送られた写真は、ある場所から別の場所に到達するのに3時間かかりました。
想像してみてください。今日、ある大陸から別の大陸へのライブビデオフィードまたはライブcctv映像をほんの数秒の遅延で見ることができます。これは、この分野でも多くの作業が行われていることを意味します。このフィールドは、送信だけでなく、エンコードにも焦点を当てています。写真をエンコードしてインターネットなどでストリーミングするために、高帯域幅または低帯域幅用にさまざまな形式が開発されています。
機械/ロボットのビジョン
ロボットが今日直面している多くの課題とは別に、最大の課題の1つは、ロボットのビジョンを向上させることです。ロボットが物事を見て、特定し、ハードルを特定できるようにするなど、この分野では多くの作業が提供されており、コンピュータビジョンの他の完全な分野が導入されています。
ハードル検出
ハードルの検出は、画像内のさまざまな種類のオブジェクトを識別し、ロボットとハードルの間の距離を計算することにより、画像処理を通じて行われる一般的なタスクの1つです。

ラインフォロワーロボット
今日のロボットのほとんどは、ラインをたどることによって動作するため、ラインフォロワーロボットと呼ばれます。これは、ロボットがその経路を移動し、いくつかのタスクを実行するのに役立ちます。これは、画像処理によっても達成されています。

色処理
カラー処理には、使用されるカラー画像とさまざまな色空間の処理が含まれます。たとえば、RGBカラーモデル、YCbCr、HSV。また、これらのカラー画像の送信、保存、およびエンコードの調査も含まれます。
パターン認識
パターン認識には、画像処理や、機械学習(人工知能の分野)を含む他のさまざまな分野からの研究が含まれます。パターン認識では、画像処理を使用して画像内のオブジェクトを識別し、次に機械学習を使用してパターンの変化についてシステムをトレーニングします。パターン認識は、コンピュータ支援診断、手書きの認識、画像の認識などで使用されます
ビデオ処理
ビデオは、写真の非常に速い動きに他なりません。ビデオの品質は、1分あたりのフレーム/画像の数と使用されている各フレームの品質によって異なります。ビデオ処理には、ノイズリダクション、ディテールエンハンスメント、モーション検出、フレームレート変換、アスペクト比変換、色空間変換などが含まれます。
次元の概念を理解するために、この例を見ていきます。
あなたに月に住んでいる友人がいて、彼があなたの誕生日プレゼントにあなたに贈り物を送りたいと思っていると考えてください。彼はあなたに地球上のあなたの住居について尋ねます。唯一の問題は、月の宅配便がアルファベットの住所を理解せず、数値の座標しか理解しないことです。では、どうやって彼に地球上のあなたの立場を送るのですか?
そこで、寸法の概念が生まれます。寸法は、スペース内の特定のオブジェクトの位置を指すために必要な最小ポイント数を定義します。
それでは、地球上の自分の位置を月の友達に送信する必要がある例に戻りましょう。あなたは彼に3組の座標を送ります。1つ目は経度、2つ目は緯度、3つ目は高度と呼ばれます。
これらの3つの座標は、地球上の位置を定義します。最初の2つは場所を定義し、3つ目は海抜の高さを定義します。
つまり、地球上の位置を定義するために必要な座標は3つだけです。それはあなたが3次元の世界に住んでいることを意味します。したがって、これは次元に関する質問に答えるだけでなく、私たちが3Dの世界に住んでいる理由にも答えます。
この概念をデジタル画像処理に関連して研究しているので、次に、この次元の概念を画像と関連付けます。
画像の寸法
したがって、私たちが3Dの世界に住んでいる場合、つまり3次元の世界に住んでいる場合、キャプチャする画像の次元は何ですか。画像は2次元であるため、画像を2次元信号としても定義します。画像には高さと幅しかありません。画像に奥行きがありません。下のこの画像をご覧ください。
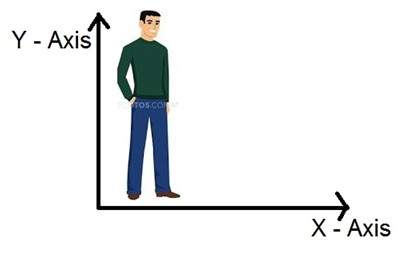
上の図を見ると、高さと幅の軸の2つの軸しかないことがわかります。この画像からは奥行きがわかりません。そのため、画像は2次元信号であると言えます。しかし、私たちの目は3次元のオブジェクトを知覚することができますが、これについては、カメラがどのように機能し、画像が知覚されるかについての次のチュートリアルで詳しく説明します。
この議論は、3次元システムが2次元からどのように形成されるかという他のいくつかの質問につながります。
テレビはどのように機能しますか?
上の画像を見ると、2次元画像であることがわかります。それを3次元に変換するには、もう1つの次元が必要です。3次元として時間を取りましょう。その場合、この2次元画像を3次元時間にわたって移動します。テレビで発生するのと同じ概念で、画面上のさまざまなオブジェクトの奥行きを認識するのに役立ちます。それは、テレビに表示されるもの、またはテレビ画面に表示されるものが3Dであることを意味しますか。ええ、そうすることができます。その理由は、テレビの場合、ビデオを再生している場合です。その場合、ビデオは他の何物でもありません。2次元の写真は時間の次元を超えて移動します。二次元の物体が三次元上を移動しているので、それは時間であるため、三次元であると言えます。
信号のさまざまな次元
1次元信号
1次元信号の一般的な例は波形です。数学的に次のように表すことができます
F(x)=波形
ここで、xは独立変数です。これは1次元の信号であるため、変数xが1つだけ使用されるのはそのためです。
一次元信号の図解を以下に示します。
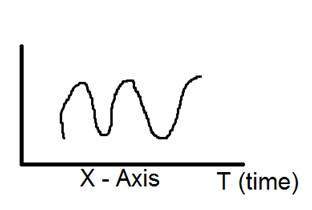
上の図は一次元信号を示しています。
さて、これは別の質問につながります。それは、それが1次元の信号であるにもかかわらず、なぜそれが2つの軸を持っているのかということです。この質問に対する答えは、それが1次元の信号であるにもかかわらず、2次元の空間で描画しているということです。または、この信号を表現している空間は2次元であると言えます。それが二次元信号のように見える理由です。
次の図を見ると、1次元の概念をよりよく理解できるかもしれません。

ここで、寸法に関する最初の説明に戻ります。上の図を、ある点から別の点への正の数を持つ実数直線と考えてください。ここで、この線上の任意の点の位置を説明する必要がある場合、必要なのは1つの数値、つまり1つの次元だけです。
2次元信号
二次元信号の一般的な例は画像であり、これについてはすでに上で説明しました。

画像が2次元信号であることはすでに見てきましたが、つまり、2次元です。数学的に次のように表すことができます。
F(x、y)=画像
ここで、xとyは2つの変数です。二次元の概念は、数学の観点から次のように説明することもできます。
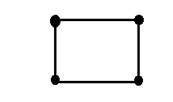
上の図で、正方形の四隅にそれぞれA、B、C、Dのラベルを付けます。図ABの1つの線分ともう1つのCDを呼び出すと、これら2つの平行な線分が結合して正方形を形成していることがわかります。各線分は1つの次元に対応するため、これら2つの線分は2つの次元に対応します。
3次元信号
三次元信号とは、その名前のとおり、三次元の信号を指します。最も一般的な例は、最初に私たちの世界で議論されました。私たちは三次元の世界に住んでいます。この例は非常に精巧に議論されています。3次元信号の別の例は、立方体または体積データです。最も一般的な例は、アニメーションまたは3D漫画のキャラクターです。
3次元信号の数学的表現は次のとおりです。
F(x、y、z)=アニメキャラクター。
別の軸または次元Zは、奥行きの錯覚を与える3次元に関係しています。デカルト座標系では、次のように表示できます。

4次元信号
4次元信号には、4次元が含まれます。最初の3つは(X、Y、Z)の3次元信号と同じであり、それらに追加される4番目の信号はT(時間)です。時間は、変化を測定する方法である時間次元と呼ばれることがよくあります。数学的には、4d信号は次のように表すことができます。
F(x、y、z、t)=アニメーション映画。
4次元信号の一般的な例は、アニメーション化された3D映画です。各キャラクターは3Dキャラクターであるため、時間に対して移動します。そのため、より現実世界のような3次元映画のような錯覚が見られました。
つまり、実際には、アニメーション映画は4次元です。つまり、4次元の時間にわたる3Dキャラクターの動きです。
人間の目はどのように機能しますか?
アナログカメラとデジタルカメラでの画像形成について説明する前に、まず人間の目の画像形成について説明する必要があります。カメラが従う基本原理は道から取られているので、人間の目は機能します。
光が特定のオブジェクトに当たると、オブジェクトに当たった後、反射して戻ります。目のレンズを通過する光線は特定の角度を形成し、画像は壁の裏側である網膜上に形成されます。形成された画像が反転します。この画像は脳によって解釈され、それによって私たちは物事を理解できるようになります。角度の形成により、私たちは私たちが見ている物体の高さと深さを知覚することができます。これについては、遠近法変換のチュートリアルで詳しく説明されています。
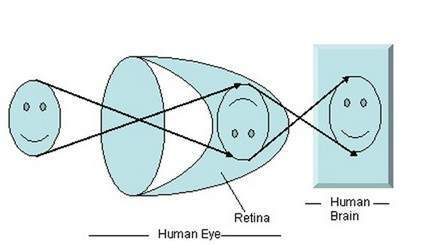
上の図からわかるように、太陽光がオブジェクト(この場合はオブジェクトは顔)に当たると、太陽光が反射され、レンズを通過するときにさまざまな光線がさまざまな角度を形成し、オブジェクトは後壁に形成されています。図の最後の部分は、オブジェクトが脳によって解釈され、再反転されたことを示しています。
それでは、アナログカメラとデジタルカメラでの画像形成について説明します。
アナログカメラでの画像形成
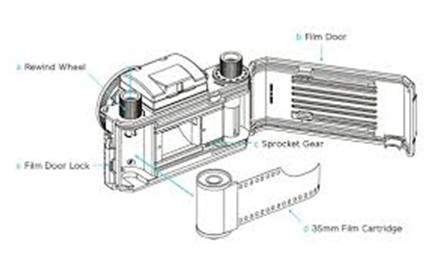
アナログカメラでは、画像形成は、画像形成に使用されるストリップ上で発生する化学反応によるものです。
35mmストリップはアナログカメラで使用されます。図では35mmフィルムカートリッジで示されています。このストリップはハロゲン化銀(化学物質)でコーティングされています。

35mmストリップはアナログカメラで使用されます。図では35mmフィルムカートリッジで示されています。このストリップはハロゲン化銀(化学物質)でコーティングされています。
光はフォトン粒子と呼ばれる小さな粒子に他なりません。したがって、これらのフォトン粒子がカメラを通過すると、ストリップ上のハロゲン化銀粒子と反応し、画像のネガティブである銀になります。
それをよりよく理解するために、この方程式を見てください。
光子(軽い粒子)+ハロゲン化銀?シルバー?イメージネガ。

これは基本的なことですが、画像形成には、内部の光の通過に関する他の多くの概念、シャッターとシャッタースピード、絞りとその開口部の概念が含まれますが、今のところ次の部分に進みます。これらの概念のほとんどは、シャッターと絞りのチュートリアルで説明されていますが。
これは基本的なことですが、画像形成には、内部の光の通過に関する他の多くの概念、シャッターとシャッタースピード、絞りとその開口部の概念が含まれますが、今のところ次の部分に進みます。これらの概念のほとんどは、シャッターと絞りのチュートリアルで説明されていますが。
デジタルカメラでの画像形成
デジタルカメラでは、画像の形成は起こる化学反応によるものではなく、これよりも少し複雑です。デジタルカメラでは、センサーのCCDアレイが画像形成に使用されます。
CCDアレイによる画像形成

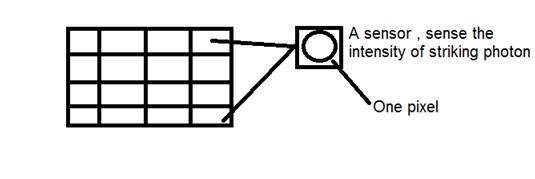
CCDは電荷結合素子の略です。これはイメージセンサーであり、他のセンサーと同様に、値を感知して電気信号に変換します。CCDの場合、画像を感知して電気信号などに変換します
このCCDは、実際にはアレイまたは長方形のグリッドの形をしています。これは、マトリックス内の各セルに光子の強度を感知するセンサーが含まれているマトリックスのようなものです。
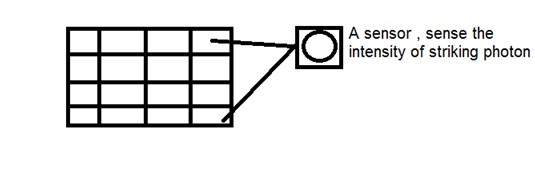
アナログカメラのように、デジタルの場合も、光が物体に当たると、光は物体に当たった後に反射して戻り、カメラの内部に入ることができます。
CCDアレイ自体の各センサーはアナログセンサーです。光の光子がチップに当たると、各フォトセンサーに小さな電荷として保持されます。各センサーの応答は、センサーの表面に当たる光または(光子)エネルギーの量に直接等しくなります。
すでに画像を2次元信号として定義しており、CCDアレイが2次元に形成されているため、このCCDアレイから完全な画像を得ることができます。
センサーの数が限られているため、限られた詳細をキャプチャできます。また、各センサーは、それに当たる各フォトン粒子に対して1つの値しか持つことができません。
そのため、衝突するフォトン(電流)の数がカウントされて保存されます。これらを正確に測定するために、外部CMOSセンサーもCCDアレイに取り付けられています。
ピクセルの紹介
CCDアレイの各センサーの値は、個々のピクセルの各値を参照します。センサーの数=ピクセルの数。また、各センサーが持つことができる値は1つだけであることも意味します。
画像の保存
CCDアレイに蓄積された電荷は、一度に1ピクセルずつ電圧に変換されます。追加の回路の助けを借りて、この電圧はデジタル情報に変換され、次に保存されます。
デジタルカメラを製造する各企業は、独自のCCDセンサーを製造しています。これには、ソニー、ミストゥビシ、ニコン、サムスン、東芝、富士フイルム、キヤノンなどが含まれます。
他の要因とは別に、キャプチャされる画像の品質は、使用されているCCDアレイのタイプと品質にも依存します。
このチュートリアルでは、絞り、シャッター、シャッタースピード、ISOなど、カメラの基本的な概念のいくつかについて説明し、これらの概念を組み合わせて使用して適切な画像をキャプチャする方法について説明します。
絞り
絞りは、光がカメラの内部に移動できるようにする小さな開口部です。これが絞りの写真です。

あなたは開口部の中にあるもののようないくつかの小さな刃を見るでしょう。これらのブレードは、開いて閉じられる八角形の形状を作成します。したがって、より多くのブレードが開くほど、光が通過しなければならない穴が大きくなることは理にかなっています。穴が大きいほど、より多くの光が入ることができます。
効果
絞りの効果は、画像の明るさと暗さに直接対応します。絞りの開口部が広いと、より多くの光がカメラに入ることができます。より多くの光はより多くのフォトンをもたらし、最終的にはより明るい画像をもたらします。
この例を以下に示します
これらの2枚の写真を検討してください


右側のものは明るく見えます、それはそれがカメラによって捕らえられたとき、開口部が大きく開いていたことを意味します。最初の写真と比較して非常に暗い左側の他の写真と比較すると、その画像がキャプチャされたとき、その開口部は大きく開いていなかったことを示しています。
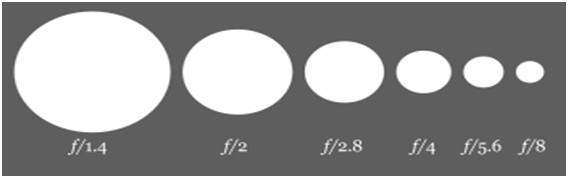
サイズ
それでは、絞りの背後にある数学について説明しましょう。絞りの大きさはaf値で表されます。そしてそれは開口部の開口部に反比例します。
これが、この概念を最もよく説明する2つの方程式です。
大きな開口サイズ=小さなf値
小さいアパーチャサイズ=大きいf値
絵画的には、次のように表すことができます。
シャッター
絞りの後にシャッターが来ます。絞りから通過させた光は、シャッターに直接当たる。シャッターは実際にはカバー、閉じた窓、またはカーテンと考えることができます。画像が形成されるCCDアレイセンサーについて話すときは覚えておいてください。シャッターのすぐ後ろにセンサーがあります。したがって、シャッターは、開口部から通過するときに、画像形成と光の間にある唯一のものです。
シャッターが開くとすぐに、イメージセンサーに光が当たり、アレイ上に画像が形成されます。
効果
シャッターが光を少し長く通過させると、画像は明るくなります。同様に、シャッターを非常に速く動かすことができるため、通過できる光の光子が非常に少なくなり、CCDアレイセンサー上に形成される画像が非常に暗くなると、より暗い画像が生成されます。
シャッターには、さらに2つの主要な概念があります。
シャッター速度
シャッタータイム
シャッター速度
シャッタースピードは、シャッターが開閉する回数と言えます。シャッターがどれだけ長く開閉するかについて話しているのではないことを忘れないでください。
シャッタータイム
シャッター時間は次のように定義できます。
シャッターが開いているとき、シャッターが閉じるまでの待ち時間をシャッター時間と呼びます。
この場合、シャッターが開閉した回数については話していませんが、シャッターが大きく開いたままになっている時間について話しているのです。
例えば:
このようにして、これら2つの概念をよりよく理解できます。つまり、シャッターが15回開いてから閉じ、そのたびに1秒間開いてから閉じます。この例では、15がシャッター速度、1秒がシャッター時間です。
関係
シャッタースピードとシャッター時間の関係は、どちらも反比例することです。
この関係は、次の式で定義できます。
シャッタースピードを上げる=シャッター時間を短くする
シャッタースピードが遅い=シャッター時間が長い。
説明:
必要な時間が短いほど、速度は速くなります。また、必要な時間が長いほど、速度は遅くなります。
アプリケーション
これらの2つの概念は、一緒になってさまざまなアプリケーションを作成します。それらのいくつかを以下に示します。
動きの速いオブジェクト:
動きの速い物体の画像をキャプチャする場合は、車などです。シャッタースピードとその時間の調整は大きな影響を及ぼします。
したがって、このような画像をキャプチャするために、2つの修正を行います。
シャッタースピードを上げる
シャッター時間を短くする
何が起こるかというと、シャッタースピードを上げると、シャッターが開閉する回数が増えるということです。これは、さまざまな光のサンプルが通過できることを意味します。シャッター時間を短縮すると、すぐにシーンをキャプチャし、シャッターゲートを閉じます。
これを行うと、動きの速いオブジェクトの鮮明な画像が得られます。
それを理解するために、この例を見ていきます。動きの速い滝の画像をキャプチャするとします。
シャッタースピードを1秒に設定し、写真を撮ります。これはあなたが得るものです

次に、シャッター速度をより速い速度に設定すると、が得られます。

次に、シャッター速度をさらに速く設定すると、が得られます。

最後の写真を見ると、シャッタースピードが非常に速くなっていることがわかります。つまり、1秒の200分の1でシャッターが開閉するため、鮮明な画像が得られます。
ISO
ISO係数は数値で測定されます。カメラに対する光の感度を示します。ISO番号が低い場合は、カメラの光に対する感度が低く、ISO番号が高い場合は、感度が高いことを意味します。
効果
ISOが高いほど、画像は明るくなります。ISOが1600に設定されている場合、画像は非常に明るくなり、その逆も同様です。
副作用
ISOが増加すると、画像のノイズも増加します。今日、ほとんどのカメラ製造会社は、ISOがより高速に設定されている場合に画像からノイズを除去することに取り組んでいます。
ピクセル
ピクセルは画像の最小要素です。各ピクセルは任意の1つの値に対応します。8ビットのグレースケール画像で、0〜255のピクセルの値。任意のポイントのピクセルの値は、そのポイントに当たる光の光子の強度に対応します。各ピクセルは、その特定の場所での光の強度に比例する値を格納します。
PEL
ピクセルはPELとも呼ばれます。以下の写真から、ピクセルをより深く理解することができます。
上の写真では、何千ものピクセルがあり、これらが一緒になってこの画像を構成しています。いくつかのピクセル分割が見える範囲で、その画像をズームします。下の画像に表示されています。

上の写真では、何千ものピクセルがあり、これらが一緒になってこの画像を構成しています。いくつかのピクセル分割が見える範囲で、その画像をズームします。下の画像に表示されています。
CCDアレイとの関係船
CCDアレイで画像がどのように形成されるかを見てきました。したがって、ピクセルは次のように定義することもできます。
CCDアレイの最小分割はピクセルとも呼ばれます。
CCDアレイの各分割には、それに当たる光子の強度に対する値が含まれています。この値はピクセルと呼ぶこともできます
総ピクセル数の計算
画像を2次元の信号または行列として定義しました。その場合、PELの数は、行の数に列の数を掛けたものに等しくなります。
これは数学的に次のように表すことができます。
総ピクセル数=行数(X)列数
または、(x、y)座標ペアの数がピクセルの総数を構成していると言えます。
画像タイプのチュートリアルで、カラー画像のピクセルをどのように計算するかについて詳しく見ていきます。
グレーレベル
任意のポイントでのピクセルの値は、その場所での画像の強度を示します。これは、グレーレベルとも呼ばれます。
画像ストレージ内のピクセルの値とピクセルあたりのビット数のチュートリアルについて詳しく説明しますが、ここでは1つのピクセル値のみの概念について説明します。
ピクセル値。(0)
このチュートリアルの冒頭ですでに定義されているように、各ピクセルは1つの値しか持つことができず、各値は画像のそのポイントでの光の強度を示します。
ここで、非常に一意の値0を確認します。値0は、光がないことを意味します。これは、0が暗いことを意味し、さらに、ピクセルの値が0の場合は常に、その時点で黒色が形成されることを意味します。
この画像マトリックスをご覧ください
| 0 | 0 | 0 |
| 0 | 0 | 0 |
| 0 | 0 | 0 |
これで、この画像マトリックスはすべて0で埋められました。すべてのピクセルの値は0です。このマトリックスからピクセルの総数を計算する場合は、次のようにします。
総ピクセル数=総ピクセル数 行数X合計数 列の
= 3 X 3
= 9。
これは、画像が9ピクセルで形成され、その画像のサイズが3行3列であり、最も重要なこととして、その画像が黒であることを意味します。
結果として作成される画像は次のようになります

では、なぜこの画像はすべて黒なのですか。画像のすべてのピクセルの値が0だったためです。
人間の目が近くのものを見るとき、それらは遠くにあるものと比較して大きく見えます。これは一般的にパースペクティブと呼ばれます。一方、変換とは、ある状態から別の状態へのオブジェクトなどの転送です。
したがって、全体として、遠近法変換は3Dワールドから2D画像への変換を扱います。人間の視覚が機能するのと同じ原理とカメラが機能するのと同じ原理。
これが発生する理由について詳しく説明します。近くにあるオブジェクトは大きく見えますが、遠くにあるオブジェクトは、到達すると大きく見えますが、小さく見えます。
この議論は、基準系の概念から始めます。
参照フレーム:
基準系は基本的に、何かを測定するための値のセットです。
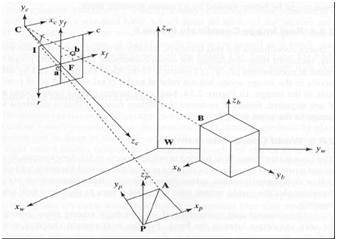
5フレームの参照
3Dの世界/画像/シーンを分析するには、5つの異なるフレームの参照が必要です。
Object
World
Camera
Image
Pixel
オブジェクト座標フレーム
オブジェクト座標フレームは、オブジェクトのモデリングに使用されます。たとえば、特定のオブジェクトが他のオブジェクトに対して適切な場所にあるかどうかを確認します。これは3D座標系です。
世界座標フレーム
ワールド座標フレームは、3次元ワールド内のオブジェクトを相互に関連付けるために使用されます。これは3D座標系です。
カメラ座標フレーム
カメラ座標フレームは、カメラに関してオブジェクトを関連付けるために使用されます。これは3D座標系です。
画像座標フレーム
これは3D座標系ではなく、2Dシステムです。これは、3Dポイントが2Dイメージプレーンにどのようにマッピングされるかを説明するために使用されます。
ピクセル座標フレーム
これは2D座標系でもあります。各ピクセルには、ピクセル座標の値があります。
これらの5つのフレーム間の変換
これが、3Dシーンがピクセルのイメージで2Dに変換される方法です。
次に、この概念を数学的に説明します。
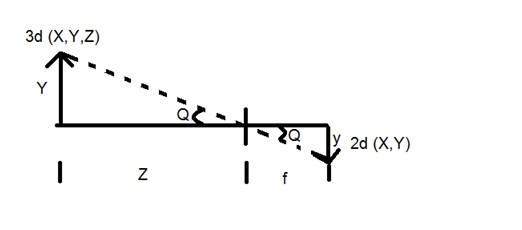
Y = 3Dオブジェクト
y = 2d画像
f =カメラの焦点距離
Z =画像とカメラの間の距離
ここで、この変換で形成される2つの異なる角度があり、Qで表されます。
最初の角度は
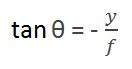
ここで、マイナスは画像が反転していることを示します。形成される2番目の角度は次のとおりです。

これらの2つの方程式を比較すると、

この式から、カメラから通過した物体に当たった後、光線が反射して戻ると、反転画像が形成されることがわかります。
この例を使用すると、これをよりよく理解できます。
例えば
形成された画像のサイズを計算する
身長5m、カメラから50mの距離に立っている人物を撮影したとすると、焦点距離のカメラでの人物の画像のサイズは50mmであることがわかります。
解決:
焦点距離はミリメートルなので、計算するにはすべてをミリメートルに変換する必要があります。
そう、
Y = 5000mm。
f = 50mm。
Z = 50000mm。
式に値を入れると、次のようになります。
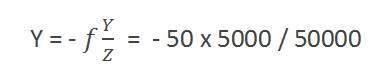
= -5mm。
この場合も、マイナス記号は画像が反転していることを示します。
Bppまたはピクセルあたりのビット数は、ピクセルあたりのビット数を示します。画像内の異なる色の数は、色の深さまたはピクセルあたりのビット数によって異なります。
数学のビット:
バイナリビットで遊ぶのと同じです。
1ビットで表現できる数値の数。
0
1
2ビットの組み合わせをいくつ作成できますか。
00
01
10
11
ビットから作成できる組み合わせの総数を計算する式を考案すると、次のようになります。
ここで、bppはピクセルあたりのビット数を示します。2を取得する式に1を入力すると、式に2を入力すると、4が取得されます。指数関数的に増加します。
異なる色の数:
さて、冒頭で述べたように、異なる色の数はピクセルあたりのビット数に依存します。
いくつかのビットとその色の表を以下に示します。
| ピクセルあたりのビット数 | 色数 |
|---|---|
| 1 bpp | 2色 |
| 2 bpp | 4色 |
| 3 bpp | 8色 |
| 4 bpp | 16色 |
| 5 bpp | 32色 |
| 6 bpp | 64色 |
| 7 bpp | 128色 |
| 8 bpp | 256色 |
| 10 bpp | 1024色 |
| 16 bpp | 65536色 |
| 24 bpp | 16777216色(1670万色) |
| 32 bpp | 4294967296色(4294百万色) |
この表は、ピクセルあたりのさまざまなビットとそれらに含まれる色の量を示しています。
シェード
指数関数的な成長のパターンに簡単に気付くことができます。有名なグレースケール画像は8bppで、256の異なる色または256の色合いがあることを意味します。
シェードは次のように表すことができます。
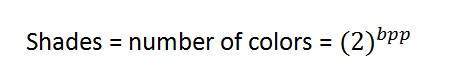
カラー画像は通常、24bpp形式または16bppです。
画像タイプのチュートリアルでは、他の色形式と画像タイプについて詳しく説明します。
色の値:
黒色:
白色:
白色を表す値は、次のように計算できます。
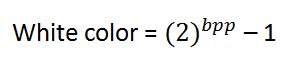
1 bppの場合、0は黒、1は白を示します。
8 bppの場合、0は黒を示し、255は白を示します。
灰色:
白黒の色の値を計算すると、灰色のピクセル値を計算できます。
灰色は実際には白黒の中間点です。そうは言っても、
8bppの場合、灰色を表すピクセル値は127または128bppです(0からではなく1から数える場合)。
画像ストレージの要件
ピクセルあたりのビット数について説明した後、画像のサイズを計算するために必要なすべてのものが揃いました。
画像サイズ
画像のサイズは3つのことに依存します。
行の数
列の数
ピクセルあたりのビット数
サイズの計算式は以下のとおりです。
画像のサイズ=行*列* bpp
これは、画像がある場合は、次のように言うことを意味します。
1024行と1024列があると仮定します。また、グレースケール画像であるため、256の異なるグレーの色合い、またはピクセルあたりのビット数があります。次に、これらの値を式に入れると、次のようになります。
画像のサイズ=行*列* bpp
= 1024 * 1024 * 8
= 8388608ビット。
しかし、それは私たちが認識する標準的な答えではないので、それを私たちのフォーマットに変換します。
それをバイトに変換する= 8388608/8 = 1048576バイト。
キロバイトに変換= 1048576/1024 = 1024kb。
メガバイトへの変換= 1024/1024 = 1Mb。
これが画像サイズの計算方法と保存方法です。ここで、式で、画像のサイズとピクセルあたりのビット数が指定されている場合、画像が正方形(同じ行と同じ列)であれば、画像の行と列を計算することもできます。
画像にはさまざまな種類がありますが、さまざまな種類の画像とその色の分布について詳しく見ていきます。
バイナリイメージ
名前が示すように、バイナリイメージには2つのピクセル値しか含まれていません。
0と1。
ピクセルあたりのビット数に関する以前のチュートリアルでは、ピクセル値をそれぞれの色に表現する方法について詳しく説明しました。
ここで、0は黒色を示し、1は白色を示します。モノクロとも呼ばれます。
白黒画像:
したがって、形成される結果の画像は、白黒の色のみで構成され、したがって、白黒画像と呼ぶこともできます。

グレーレベルなし
このバイナリイメージの興味深い点の1つは、グレーレベルが含まれていないことです。黒と白の2色しかありません。
フォーマット
バイナリイメージの形式はPBM(ポータブルビットマップ)です。
2、3、4、5、6ビットカラーフォーマット
2、3、4、5、および6ビットのカラーフォーマットの画像は、今日広く使用されていません。それらは昔、古いテレビディスプレイやモニターディスプレイに使用されていました。
ただし、これらの各色には2つ以上のグレーレベルがあるため、バイナリイメージとは異なりグレー色になります。
2ビット4、3ビット8、4ビット16、5ビット32、6ビット64の異なる色が存在します。
8ビットカラーフォーマット
8ビットカラーフォーマットは、最も有名な画像フォーマットの1つです。256種類の色合いがあります。これは一般にグレースケール画像として知られています。
8ビットの色の範囲は0〜255です。ここで、0は黒を表し、255は白を表し、127は灰色を表します。
この形式は、最初はオペレーティングシステムUNIXの初期モデルと初期カラーMacintoshで使用されていました。
アインシュタインのグレースケール画像を以下に示します。
フォーマット
これらの画像の形式はPGM(Portable Grey Map)です。
この形式は、Windowsではデフォルトでサポートされていません。グレースケール画像を表示するには、画像ビューアまたはMatlabなどの画像処理ツールボックスが必要です。
グレースケール画像の背後:
前のチュートリアルで何度か説明したように、画像は2次元関数にすぎず、2次元配列または行列で表すことができます。したがって、上記のアインシュタインの画像の場合、背後に0〜255の範囲の値を持つ2次元行列があります。
しかし、それはカラー画像には当てはまりません。
16ビットカラーフォーマット
カラー画像形式です。65,536種類の色があります。ハイカラーフォーマットとも呼ばれます。
これは、8ビット以上のカラーフォーマットをサポートするシステムでMicrosoftによって使用されています。この16ビット形式と次の形式では、どちらが24ビット形式であるかについて説明します。どちらもカラー形式です。
カラー画像の色の分布は、グレースケール画像の場合ほど単純ではありません。
16ビット形式は、実際には赤、緑、青の3つの形式に分けられます。有名な(RGB)フォーマット。
下の画像に絵で表されています。
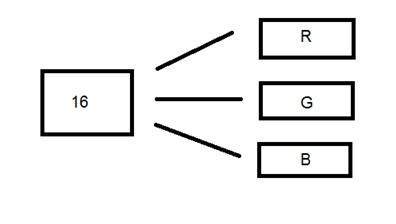
ここで、16を3つにどのように分配するかという疑問が生じます。このようにすれば、
Rの場合は5ビット、Gの場合は5ビット、Bの場合は5ビット
その後、最後に1ビットが残ります。
したがって、16ビットの配布はこのように行われます。
Rの場合は5ビット、Gの場合は6ビット、Bの場合は5ビット。
残された追加ビットが緑色のビットに追加されます。緑はこれら3色すべてで最も目を落ち着かせる色だからです。
これは、配布の後にすべてのシステムが従うわけではないことに注意してください。16ビットでアルファチャネルを導入したものもあります。
16ビット形式の別の分布は次のようになります。
R用に4ビット、G用に4ビット、B用に4ビット、アルファチャネル用に4ビット。
または、このように配布する人もいます
R用に5ビット、G用に5ビット、B用に5ビット、アルファチャネル用に1ビット。
24ビットカラーフォーマット
トゥルーカラーフォーマットとも呼ばれる24ビットカラーフォーマット。16ビットカラーフォーマットと同様に、24ビットカラーフォーマットでも、24ビットは赤、緑、青の3つの異なるフォーマットで配布されます。
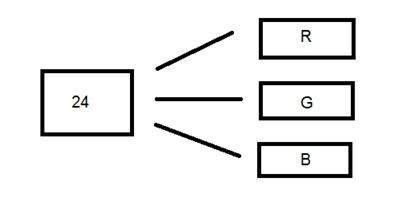
24は8で均等に分割されるため、3つの異なるカラーチャネルに均等に分散されます。
それらの分布はこのようなものです。
Rの場合は8ビット、Gの場合は8ビット、Bの場合は8ビット。
24ビット画像の背後。
背後に1つの行列がある8ビットのグレースケール画像とは異なり、24ビットの画像にはR、G、Bの3つの異なる行列があります。
フォーマット
これは最も一般的に使用される形式です。そのフォーマットは、LinuxオペレーティングシステムでサポートされているPPM(Portable pixMap)です。有名なウィンドウには、BMP(ビットマップ)という独自の形式があります。
このチュートリアルでは、さまざまなカラーコードを組み合わせて他の色を作成する方法と、RGBカラーコードを16進数に変換する方法(またはその逆)を確認します。
異なるカラーコード
ここでのすべての色は24ビット形式です。つまり、各色には8ビットの赤、8ビットの緑、8ビットの青が含まれています。または、各色には3つの異なる部分があると言えます。これらの3つの部分の量を変更するだけで、任意の色を作成できます。
バイナリカラーフォーマット
カラー:ブラック
画像:
10進コード:
(0,0,0)
説明:
前のチュートリアルで説明したように、8ビット形式では、0は黒を指します。したがって、純粋な黒色を作成する必要がある場合は、R、G、Bの3つの部分すべてを0にする必要があります。
カラー:ホワイト
画像:

10進コード:
(255,255,255)
説明:
R、G、Bの各部分は8ビット部分であるため。したがって、8ビットでは、白色は255で形成されます。これはピクセルのチュートリアルで説明されています。したがって、白色を作成するために、各部分を255に設定し、それによって白色を取得しました。それぞれの値を255に設定すると、全体の値は255になり、色が白になります。
RGBカラーモデル:
赤色
画像:

10進コード:
(255,0,0)
説明:
必要なのは赤色だけなので、残りの2つの部分である緑と青をゼロにし、赤の部分を最大値である255に設定します。
色:緑
画像:

10進コード:
(0,255,0)
説明:
必要なのは緑色だけなので、残りの2つの部分である赤と青をゼロにし、緑の部分を最大値である255に設定します。
青色
画像:

10進コード:
(0,0,255)
説明:
必要なのは青色だけなので、残りの2つの部分である赤と緑をゼロにし、青色の部分を最大値である255に設定します。
灰色:
カラー:グレー
画像:

10進コード:
(128,128,128)
説明:
ピクセルのチュートリアルですでに定義したように、その灰色は実際には中点です。8ビット形式では、中間点は128または127です。この場合は128を選択します。したがって、各部分を中間点である128に設定すると、全体的な中間値になり、灰色になります。
CMYKカラーモデル:
CMYKは別のカラーモデルで、cはシアン、mはマゼンタ、yは黄色、kは黒を表します。CMYKモデルは、2つのカラーカーターが使用されるカラープリンターで一般的に使用されます。1つはCMYで構成され、もう1つは黒色で構成されます。
CMYの色は、赤、緑、青の量や部分を変えることで作ることもできます。
色:シアン
画像:

10進コード:
(0,255,255)
説明:
シアン色は、緑と青の2つの異なる色の組み合わせから形成されます。したがって、これら2つを最大に設定し、赤の部分をゼロにします。そして、シアン色になります。
色:マゼンタ
画像:

10進コード:
(255,0,255)
説明:
マゼンタ色は、赤と青の2つの異なる色の組み合わせから形成されます。したがって、これら2つを最大に設定し、緑の部分をゼロにします。そして、マゼンタ色になります。
色:黄色
画像:

10進コード:
(255,255,0)
説明:
黄色は、赤と緑の2つの異なる色の組み合わせから形成されます。したがって、これら2つを最大に設定し、青の部分をゼロにします。そして、私たちは黄色になります。
変換
これで、色がどのように変換されるかが、ある形式から別の形式に変わることがわかります。
RGBから16進コードへの変換:
16進数からRGBへの変換は、次の方法で行われます。
色を取ります。例:白=(255、255、255)。
最初の部分、たとえば255を取ります。
それを16で割ります。このように:
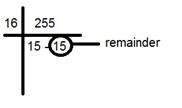
線の下の2つの数値、因数、および余りを取ります。この場合、FFである15×15です。
次の2つの部分について、手順2を繰り返します。
すべての16進コードを1つに結合します。
回答:#FFFFFF
16進数からRGBへの変換:
16進コードからRGB10進形式への変換はこの方法で行われます。
16進数を取ります。例:#FFFFFF
この数を3つの部分に分けます:FF FF FF
最初の部分を取り、そのコンポーネントを分離します:FF
各パーツを個別にバイナリに変換します:(1111)(1111)
次に、個々のバイナリを1つに結合します:11111111
このバイナリを10進数に変換します:255
ここで、手順2をさらに2回繰り返します。
最初のステップで得られる値はR、2番目の値はG、3番目の値はBに属します。
回答:(255、255、255)
この表には、一般的な色とその16進コードが示されています。
| 色 | 16進コード |
|---|---|
| ブラック | #000000 |
| 白い | #FFFFFF |
| グレー | #808080 |
| 赤 | #FF0000 |
| 緑 | #00FF00 |
| 青い | #0000FF |
| シアン | #00FFFF |
| 赤紫色 | #FF00FF |
| 黄 | #FFFF00 |
平均的な方法
加重法または光度法
平均的な方法
平均的な方法が最も簡単な方法です。あなたはただ3色の平均を取る必要があります。RGB画像なので、rにgをbに追加し、それを3で割って目的のグレースケール画像を取得することを意味します。
このようにして行われます。
グレースケール=(R + G + B)/ 3
例えば:

上記の画像のようなカラー画像があり、平均的な方法を使用してそれをグレースケールに変換したい場合。次の結果が表示されます。

説明
確かなことが一つあります。それは、オリジナルの作品に何かが起こるということです。これは、平均的な方法が機能することを意味します。しかし、結果は期待通りではありませんでした。画像をグレースケールに変換したかったのですが、これはかなり黒い画像であることがわかりました。
問題
この問題は、3色の平均を取るという事実が原因で発生します。3つの異なる色は3つの異なる波長を持ち、画像の形成に独自の寄与があるため、平均的な方法を使用して平均的に行うのではなく、それらの寄与に従って平均をとる必要があります。今私たちがしているのはこれです、
赤の33%、緑の33%、青の33%
それぞれの33%を使用しています。つまり、各部分が画像内で同じ寄与をしています。しかし実際にはそうではありません。これに対する解決策は、光度法によって与えられています。
加重法または光度法
あなたは平均的な方法で発生する問題を見てきました。加重法には、その問題に対する解決策があります。赤い色は3色すべての中で波長が長いので、緑は赤い色よりも波長が短いだけでなく、緑は目に心地よい効果を与える色です。
つまり、赤色の寄与を減らし、緑色の寄与を増やし、これら2つの間に青色の寄与を配置する必要があります。
したがって、その形式の新しい方程式は次のとおりです。
新しいグレースケール画像=((0.3 * R)+(0.59 * G)+(0.11 * B))。
この式によると、赤は30%、緑は59%、3色すべてで大きく、青は11%を占めています。
この方程式を画像に適用すると、次のようになります。
元の画像:
グレースケール画像:

説明
ここでわかるように、画像は加重法を使用してグレースケールに適切に変換されています。平均的な方法の結果と比較して、この画像はより明るくなっています。
アナログ信号からデジタル信号への変換:
ほとんどのイメージセンサーの出力はアナログ信号であり、保存できないためデジタル処理を行うことはできません。無限の値を持つことができる信号を格納するには無限のメモリが必要なため、格納できません。
したがって、アナログ信号をデジタル信号に変換する必要があります。
デジタルの画像を作成するには、連続データをデジタル形式に変換する必要があります。それが行われる2つのステップがあります。
Sampling
Quantization
ここでサンプリングについて説明し、量子化については後で説明しますが、ここでは、これら2つの違いとこれら2つのステップの必要性について少し説明します。
基本的な考え方:
アナログ信号をデジタル信号に変換する背後にある基本的な考え方は次のとおりです。

その軸(x、y)の両方をデジタル形式に変換します。
画像は座標(x軸)だけでなく振幅(y軸)でも連続しているため、座標のデジタル化を扱う部分はサンプリングと呼ばれます。そして、振幅のデジタル化を扱う部分は、量子化として知られています。
サンプリング。
サンプリングは、信号とシステムの概要のチュートリアルですでに紹介されています。しかし、ここでさらに議論します。
ここで、サンプリングについて説明しました。
サンプリングという用語は、サンプルを取ることを指します
サンプリングでx軸をデジタル化します
それは独立変数で行われます
方程式y = sin(x)の場合、x変数で実行されます
さらに、アップサンプリングとダウンサンプリングの2つの部分に分かれています。
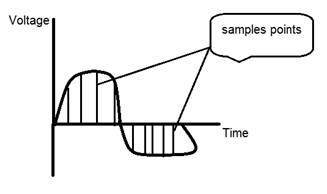
上の図を見ると、信号にランダムな変動があることがわかります。これらの変動はノイズによるものです。サンプリングでは、サンプルを採取することでこのノイズを低減します。より多くのサンプルを取得すると、画像の品質が向上し、ノイズがより除去され、同じことが逆に発生することは明らかです。
ただし、x軸でサンプリングを行う場合、量子化と呼ばれるy軸もサンプリングしない限り、信号はデジタル形式に変換されません。サンプルが多いということは、最終的にはより多くのデータを収集していることを意味し、画像の場合はより多くのピクセルを意味します。
ピクセルとの関係船
ピクセルは画像の最小要素であるため。画像の総ピクセル数は次のように計算できます。
ピクセル=行の総数*列の総数。
合計25ピクセルがあるとしましょう。つまり、5 X 5の正方形の画像があります。次に、サンプリングで上で説明したように、サンプルが多いほど、最終的にはピクセルが増えます。つまり、連続信号のうち、x軸で25個のサンプルを取得したことを意味します。これは、この画像の25ピクセルを指します。
これは、ピクセルもCCDアレイの最小分割であるためという別の結論につながります。つまり、CCDアレイとも関係があるということで、こう説明できます。
CCDアレイとの関係
CCDアレイ上のセンサーの数は、ピクセルの数と直接同じです。また、ピクセル数はサンプル数に直接等しいと結論付けたため、サンプル数はCCDアレイ上のセンサーの数に直接等しいことを意味します。
オーバーサンプリング。
最初に、サンプリングはさらに2つのタイプに分類されることを定義しました。これはアップサンプリングとダウンサンプリングです。アップサンプリングは、オーバーサンプリングとも呼ばれます。
オーバーサンプリングは、ズームと呼ばれる画像処理に非常に深く適用されます。
ズーミング
次回のチュートリアルで正式にズームを紹介しますが、ここでは、ズームについて簡単に説明します。
ズームとは、ピクセル数を増やすことです。これにより、画像をズームすると、より詳細に表示されます。
ピクセル数の増加は、オーバーサンプリングによって行われます。ズームする1つの方法は、レンズのモーターの動きを介して光学的にズームし、画像をキャプチャすることです。しかし、画像がキャプチャされたら、それを行う必要があります。
ズームとサンプリングには違いがあります。
コンセプトは同じです。つまり、サンプルを増やすことです。ただし、主な違いは、サンプリングは信号に対して行われるのに対し、ズームはデジタル画像に対して行われることです。
ピクセル解像度を定義する前に、ピクセルを定義する必要があります。
ピクセル
ピクセルの概念のチュートリアルでは、ピクセルを画像の最小要素として定義しました。また、ピクセルはその特定の場所での光の強度に比例する値を格納できることも定義しました。
ピクセルを定義したので、解像度とは何かを定義します。
解決
解像度はさまざまな方法で定義できます。ピクセル解像度、空間解像度、時間解像度、スペクトル解像度など。そのうち、ピクセル解像度について説明します。
あなたはおそらくあなた自身のコンピュータ設定で、あなたが800 x 600、640 x480などのモニター解像度を持っているのを見たことがあるでしょう
ピクセル解像度では、解像度という用語は、デジタル画像のピクセル数の総数を指します。例えば。画像にM行N列がある場合、その解像度はMXNとして定義できます。
解像度をピクセルの総数として定義すると、ピクセル解像度は2つの数値のセットで定義できます。最初の数字は画像の幅、つまり列全体のピクセルであり、2番目の数字は画像の高さ、つまりその幅全体のピクセルです。
ピクセル解像度が高いほど、画像の品質が高いと言えます。
画像のピクセル解像度は4500X5500と定義できます。
メガピクセル
ピクセル解像度を使用して、カメラのメガピクセルを計算できます。
列ピクセル(幅)X行ピクセル(高さ)/ 1百万。
画像のサイズは、そのピクセル解像度によって定義できます。
サイズ=ピクセル解像度Xbpp(ピクセルあたりのビット数)
カメラのメガピクセルを計算する
寸法が2500X3192の画像があるとします。
そのピクセル解像度= 2500 * 3192 = 7982350バイト。
100万で割ると= 7.9 = 8メガピクセル(約)。
アスペクト比
ピクセル解像度に関するもう1つの重要な概念は、アスペクト比です。
アスペクト比は、画像の幅と高さの比率です。これは通常、コロンで区切られた2つの数字として説明されます(8:9)。この比率は、画像や画面によって異なります。一般的なアスペクト比は次のとおりです。
1.33:1、1.37:1、1.43:1、1.50:1、1.56:1、1.66:1、1.75:1、1.78:1、1.85:1、2.00:1など
利点:
アスペクト比は、画面上の画像の外観のバランスを維持します。つまり、水平ピクセルと垂直ピクセルの比率を維持します。アスペクト比を上げても画像が歪むことはありません。
例えば:
これは、100行100列のサンプル画像です。小さくしたい場合で、品質が変わらない、または他の方法で画像が歪まないことが条件である場合、ここではそれがどのように発生するかを示します。
元の画像:

MSペイントでアスペクト比を維持して行と列を変更します。
結果

画像は小さくなりますが、バランスは同じです。
画面の解像度に応じてビデオを調整できるビデオプレーヤーでアスペクト比を見たことがあるでしょう。
アスペクト比から画像の寸法を見つける:
アスペクト比は多くのことを教えてくれます。アスペクト比を使用すると、画像のサイズとともに画像のサイズを計算できます。
例えば
ピクセル解像度が480000ピクセルの画像のアスペクト比が6:2の画像が与えられた場合、その画像はグレースケール画像です。
そして、2つのことを計算するように求められます。
ピクセル解像度を解決して、画像のサイズを計算します
画像のサイズを計算する
解決:
与えられた:
アスペクト比:c:r = 6:2
ピクセル解像度:c * r = 480000
ピクセルあたりのビット数:グレースケール画像= 8bpp
検索:
行数=?
列数=?
最初の部分を解く:
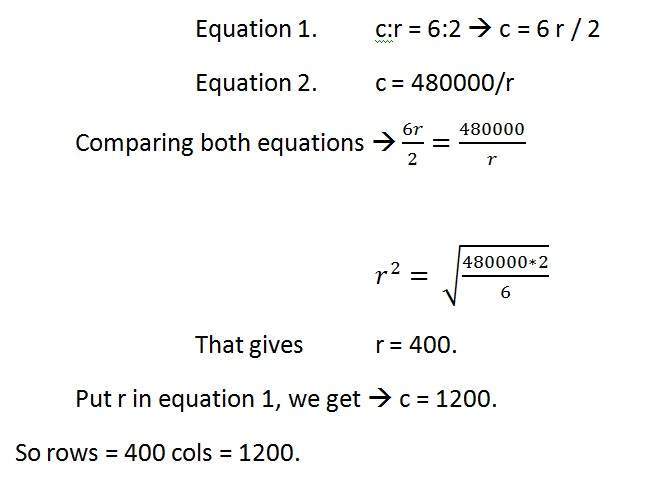
第2部の解決:
サイズ=行*列* bpp
画像のサイズ(ビット)= 400 * 1200 * 8 = 3840000ビット
画像のサイズ(バイト単位)= 480000バイト
キロバイト単位の画像のサイズ= 48 kb(約)。
このチュートリアルでは、ズームの概念と、画像のズームに使用される一般的な手法を紹介します。
ズーミング
ズームとは、画像の細部がより見やすく鮮明になるという意味で、画像を拡大することを意味します。画像のズームには、カメラレンズによるズームから、インターネット上の画像のズームまで、さまざまな用途があります。
例えば
ズームインします

2つの異なるステップで何かをズームできます。
最初のステップには、特定の画像を撮影する前のズームが含まれます。これは前処理ズームとして知られています。このズームには、ハードウェアと機械の動きが含まれます。
2番目のステップは、画像がキャプチャされたらズームすることです。これは、ピクセルを操作して必要な部分を拡大するさまざまなアルゴリズムによって行われます。
これらについては、次のチュートリアルで詳しく説明します。
光学ズームとデジタルズーム
これらの2種類のズームは、カメラでサポートされています。
光学ズーム:
光学ズームは、カメラのレンズの動きを使用して実現されます。光学ズームは実際には真のズームです。光学ズームの結果は、デジタルズームの結果よりもはるかに優れています。光学ズームでは、画像内のオブジェクトがカメラに近くなるように、レンズによって画像が拡大されます。光学ズームでは、レンズを物理的に伸ばしてオブジェクトをズームまたは拡大します。
デジタルズーム:
デジタルズームは基本的にカメラ内での画像処理です。デジタルズームでは、画像の中央が拡大され、画像の端が切り取られます。中央が拡大されているため、オブジェクトがあなたに近いように見えます。
デジタルズーム中にピクセルが拡大し、そのため画像の品質が低下します。
Photoshopなどの画像処理ツールボックス/ソフトウェアを使用してコンピューターから画像を取得した後も、デジタルズームの同じ効果を確認できます。
次の図は、以下のズーム方法のいずれかを使用してデジタルズームを行った結果です。

今はデジタル画像処理に傾倒しているので、レンズなどを使って画像を光学的にズームする方法には焦点を当てません。むしろ、デジタル画像をズームできる方法に焦点を当てます。
ズーム方法:
この仕事をする方法はたくさんありますが、ここではそれらの中で最も一般的な方法について説明します。
それらは以下にリストされています。
ピクセル複製または(最近隣内挿)
ゼロ次ホールド方式
K回ズーム
これら3つの方法はすべて、次のチュートリアルで正式に紹介されています。
このチュートリアルでは、ズーム入門のチュートリアルで紹介した3つのズーム方法を正式に紹介します。
メソッド
ピクセル複製または(最近隣内挿)
ゼロ次ホールド方式
K回ズーム
それぞれの方法には、それぞれ長所と短所があります。まず、ピクセルの複製について説明します。
方法1:ピクセル複製:
前書き:
これは、最近隣内挿法とも呼ばれます。その名前が示すように、この方法では、隣接するピクセルを複製するだけです。サンプリングのチュートリアルですでに説明したように、そのズームはサンプルまたはピクセルの量を増やすことに他なりません。このアルゴリズムは同じ原理で機能します。
ワーキング:
この方法では、すでに指定されているピクセルから新しいピクセルを作成します。この方法では、各ピクセルが行方向と列方向にn回複製され、ズームされた画像が得られます。それと同じくらい簡単です。
例えば:
2行2列の画像があり、ピクセルレプリケーションを使用して2倍または2倍にズームしたい場合は、ここでその方法を説明します。
理解を深めるために、画像は画像のピクセル値を含むマトリックスの形式で取得されています。
| 1 | 2 |
| 3 | 4 |
上の画像には2つの行と2つの列があり、最初に行ごとにズームします。
行ごとのズーム:
行ごとにズームするときは、行のピクセルを隣接する新しいセルにコピーするだけです。
ここでそれがどのように行われるか。
| 1 | 1 | 2 | 2 |
| 3 | 3 | 4 | 4 |
上記のマトリックスでできるように、各ピクセルは行に2回複製されます。
列サイズのズーム:
次のステップは、各ピクセルを列ごとに複製することです。列のピクセルを隣接する新しい列またはその下にコピーするだけです。
ここでそれがどのように行われるか。
| 1 | 1 | 2 | 2 |
| 1 | 1 | 2 | 2 |
| 3 | 3 | 4 | 4 |
| 3 | 3 | 4 | 4 |
新しい画像サイズ:
上記の例からわかるように、2行2列の元の画像は、ズーム後に4行4列に変換されています。つまり、新しい画像のサイズは
(元の画像の行*ズーム率、元の画像の列*ズーム率)
長所と短所:
このズーム技術の利点の1つは、非常に簡単なことです。ピクセルをコピーするだけで、他には何もありません。
この手法の欠点は、画像がズームされても出力が非常にぼやけることです。そして、ズーム率が増加するにつれて、画像はますますぼやけていきました。その結果、最終的に画像が完全にぼやけてしまいます。
方法2:ゼロ次ホールド
前書き
ゼロ次ホールド法は、ズームのもう1つの方法です。2回ズームとも呼ばれます。2回しかズームできないからです。以下の例で、なぜそうなるのかがわかります。
ワーキング
ゼロ次ホールド法では、行からそれぞれ2つの隣接する要素を選択し、それらを追加して結果を2で除算し、それらの結果をこれら2つの要素の間に配置します。最初にこの行を賢明に実行し、次にこの列を賢明に実行します。
例えば
2行2列の寸法の画像を撮り、ゼロ次ホールドを使用して2回ズームしてみましょう。
| 1 | 2 |
| 3 | 4 |
最初に行方向にズームし、次に列方向にズームします。
行ごとのズーム
| 1 | 1 | 2 |
| 3 | 3 | 4 |
最初の2つの数値:(2 + 1)= 3を取り、それを2で割ると、1.5が得られます。これは1に近似されます。同じ方法が行2に適用されます。
列ごとのズーム
| 1 | 1 | 2 |
| 2 | 2 | 3 |
| 3 | 3 | 4 |
1と3の2つの隣接する列ピクセル値を取得します。それらを加算して4を取得します。次に、4を2で除算し、それらの間に配置された2を取得します。同じ方法がすべての列に適用されます。
新しい画像サイズ
ご覧のとおり、新しい画像のサイズは3 x 3で、元の画像のサイズは2 x 2です。つまり、新しい画像のサイズは次の式に基づいているということです。
(2(行数)マイナス1)X(2(列数)マイナス1)
長所と短所。
このズーム手法の利点の1つは、最近隣内挿法と比較してぼやけた画像を作成しないことです。ただし、2の累乗でしか実行できないという欠点もあります。ここで説明できます。
2回のズームの背後にある理由:
上記の2行2列の画像について考えてみます。ゼロ次ホールド方式を使用して6倍ズームする必要がある場合、それはできません。式が示すように、これを示します。
22、4、8、16、32などの累乗でしかズームインできませんでした。
ズームしようとしてもできません。最初は2回ズームすると、結果は3x3に等しいサイズで列ごとにズームした場合と同じになるためです。次に、もう一度ズームすると、5 x 5の寸法になります。もう一度ズームすると、9 x9の寸法になります。
あなたの公式によると、答えは11x11でなければなりません。(6(2)マイナス1)X(6(2)マイナス1)は、11 x11になります。
方法3:K-Timesズーム
前書き:
K倍は、これから説明する3番目のズーム方法です。これは、これまでに説明した中で最も完璧なズームアルゴリズムの1つです。2倍ズームとピクセル複製の両方の課題に対応します。このズームアルゴリズムのKは、ズーム係数を表します。
ワーキング:
このように機能します。
まず、2回のズームで行ったように、2つの隣接するピクセルを取得する必要があります。次に、大きい方から小さい方を引く必要があります。この出力を(OP)と呼びます。
出力(OP)をズーム率(K)で除算します。次に、結果を小さい方の値に追加し、結果をこれら2つの値の間に配置する必要があります。
値OPを入力した値に再度追加し、前に入力した値の横に再度配置します。k-1の値を入れるまでそれをしなければなりません。
すべての行と列に対して同じ手順を繰り返すと、ズームされた画像が表示されます。
例えば:
以下に示す2行3列の画像があるとします。そして、3〜3回ズームする必要があります。
| 15 | 30 | 15 |
| 30 | 15 | 30 |
この場合のKは3です。K= 3。
挿入する必要のある値の数はk-1 = 3-1 = 2です。
行ごとのズーム
最初の2つの隣接するピクセルを取ります。15と30です。
30から15を引きます。30-15= 15。
15をkで割ります。15 / k = 15/3 = 5.これをOPと呼びます(opは単なる名前です)
小さい番号にOPを追加します。15 + OP = 15 + 5 = 20。
OPを再度20に追加します。20 + OP = 20 + 5 = 25。
k-1の値を挿入する必要があるため、これを2回行います。
次に、隣接する2つのピクセルに対してこの手順を繰り返します。それは最初の表に示されています。
値を挿入した後、挿入された値を昇順で並べ替える必要があるため、値の間に対称性が残ります。
2番目の表に示されています
表1。
| 15 | 20 | 25 | 30 | 20 | 25 | 15 |
| 30 | 20 | 25 | 15 | 20 | 25 | 30 |
表2。

列ごとのズーム
同じ手順を列ごとに実行する必要があります。手順には、隣接する2つのピクセル値を取得し、大きい方のピクセル値から小さい方のピクセル値を減算することが含まれます。その後、それをkで割る必要があります。結果をOPとして保存します。小さい方にOPを加算してから、最初にOPを加算した値にOPを再度加算します。新しい値を挿入します。
これがあなたがその後得たものです。
| 15 | 20 | 25 | 30 | 25 | 20 | 15 |
| 20 | 21 | 21 | 25 | 21 | 21 | 20 |
| 25 | 22 | 22 | 20 | 22 | 22 | 25 |
| 30 | 25 | 20 | 15 | 20 | 25 | 30 |
新しい画像サイズ
新しい画像の寸法の式を計算する最良の方法は、元の画像と最終画像の寸法を比較することです。元の画像のサイズは2X 3で、新しい画像のサイズは4 x7です。
したがって、式は次のとおりです。
(K(行数から1を引いた数)+ 1)X(K(列数から1を引いた数)+ 1)
長所と短所
k時間ズームアルゴリズムの明らかな利点の1つは、ピクセル複製アルゴリズムのパワーである任意の要素のズームを計算できることです。また、ゼロ次ホールド法のパワーである改善された結果(ぼやけが少ない)が得られます。したがって、それは2つのアルゴリズムの力で構成されます。
このアルゴリズムの唯一の難しさは、最後にソートする必要があることです。これは追加のステップであるため、計算のコストが増加します。
画像の解像度
画像の解像度はさまざまな方法で定義できます。ピクセル解像度とアスペクト比のチュートリアルで説明されているピクセル解像度です。
このチュートリアルでは、空間解像度という別のタイプの解像度を定義します。
空間分解能:
空間解像度は、画像の鮮明度をピクセル解像度では判断できないことを示しています。画像のピクセル数は関係ありません。
空間分解能は次のように定義できます
画像内の識別可能な最小の詳細。(デジタル画像処理-ゴンザレス、ウッズ-第2版)
または、他の方法で、空間解像度を1インチあたりの独立したピクセル値の数として定義できます。
要するに、空間解像度とは、2つの異なるタイプの画像を比較して、どちらが鮮明でどちらが鮮明でないかを確認できないことです。2つの画像を比較する必要がある場合、どちらがより鮮明であるか、どちらがより空間的な解像度を持っているかを確認するには、同じサイズの2つの画像を比較する必要があります。
例えば:
これらの2つの画像を比較して、画像の鮮明さを確認することはできません。
両方の画像は同じ人物のものですが、それは私たちが判断している条件ではありません。左側の画像は、227 x 222の寸法のアインシュタインのズームアウト画像です。一方、右側の画像は、980 x 749の寸法であり、ズームされた画像です。それらを比較して、どちらがより明確であるかを確認することはできません。この状態ではズームの要素は重要ではないことを覚えておいてください。重要なのは、これら2つの画像が等しくないことだけです。
したがって、空間分解能を測定するために、下の写真は目的を果たします。

これで、これら2つの写真を比較できます。両方の画像の寸法は同じで、227 X 222です。これらを比較すると、左側の画像の方が空間解像度が高いか、右側の画像よりも鮮明であることがわかります。右の写真がぼやけているからです。
空間分解能の測定:
空間分解能は明瞭さを指すため、デバイスごとに、それを測定するためにさまざまな測定が行われました。
例えば:
1インチあたりのドット数
1インチあたりの行数
1インチあたりのピクセル数
これらについては次のチュートリアルで詳しく説明しますが、以下に簡単な紹介を示します。
1インチあたりのドット数:
1インチあたりのドット数またはDPIは、通常、モニターで使用されます。
1インチあたりの行数:
1インチあたりの行数またはLPIは、通常、レーザープリンターで使用されます。
インチあたりのピクセル数:
1インチあたりのピクセル数またはPPIは、タブレット、携帯電話などのさまざまなデバイスの測定値です。
空間分解能の前のチュートリアルでは、PPI、DPI、LPIの簡単な紹介について説明しました。今、私たちはそれらすべてについて正式に議論するつもりです。
インチあたりのピクセル数。
ピクセル密度またはピクセル/インチは、タブレット、携帯電話などのさまざまなデバイスの空間解像度の尺度です。
PPIが高いほど、品質も高くなります。それをより理解するために、それがどのように計算されたか。携帯電話のPPIを計算してみましょう。
サムスンギャラクシーS4の1インチあたりのピクセル数(PPI)の計算:

サムスンギャラクシーs4のPPIまたはピクセル密度は441です。しかし、どのように計算されますか?
まず、ピタゴラスの定理を使用して、対角線の解像度をピクセル単位で計算します。
それは次のように与えることができます:
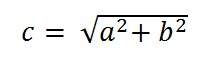
ここで、aとbはピクセル単位の高さと幅の解像度、cはピクセル単位の対角解像度です。
Samsung Galaxy s4の場合、1080 x1920ピクセルです。
したがって、これらの値を方程式に入れると、結果が得られます。
C = 2202.90717
次に、PPIを計算します
PPI = c /対角サイズ(インチ)
サムスンギャラクシーs4の対角サイズは5.0インチで、どこからでも確認できます。
PPI = 2202.90717 / 5.0
PPI = 440.58
PPI = 441(約)
これは、Samsung Galaxys4のピクセル密度が441PPIであることを意味します。
インチあたりのドット数。
dpiは多くの場合PPIに関連していますが、これら2つの間に違いがあります。DPIまたは1インチあたりのドット数は、プリンターの空間解像度の尺度です。プリンタの場合、dpiは、画像がプリンタから印刷されるときに1インチあたりに印刷されるインクのドット数を意味します。
1インチあたりの各ピクセルが1インチあたり1ドットで印刷される必要はないことを忘れないでください。1ピクセルの印刷に使用される1インチあたりのドット数が多い場合があります。この背後にある理由は、ほとんどのカラープリンターがCMYKモデルを使用しているためです。色に限りがあります。プリンタはこれらの色からピクセルの色を作成する必要がありますが、PC内では数十万の色があります。
プリンタのdpiが高いほど、紙に印刷されたドキュメントまたは画像の品質が高くなります。
通常、レーザープリンタの中にはdpiが300のものもあれば、600以上のものもあります。
1インチあたりの行数。
dpiが1インチあたりのドット数を指す場合、1インチあたりのライナーは1インチあたりのドット数の線を指します。ハーフトーンスクリーンの解像度は、1インチあたりのライン数で測定されます。
次の表は、プリンタの1インチあたりの行数の一部を示しています。
| プリンター | LPI |
|---|---|
| スクリーン印刷 | 45-65 lpi |
| レーザープリンター(300 dpi) | 65 lpi |
| レーザープリンター(600 dpi) | 85-105 lpi |
| オフセット印刷機(新聞用紙) | 85 lpi |
| オフセット印刷機(コート紙) | 85-185 lpi |
画像解像度:
グレーレベルの解像度:
グレーレベルの解像度とは、画像のグレーの色合いまたはレベルの予測可能または決定論的な変化を指します。
要するに、グレーレベルの解像度はピクセルあたりのビット数に等しい。
ピクセルあたりのビット数と画像ストレージの要件については、チュートリアルでピクセルあたりのビット数についてすでに説明しました。ここでbppを簡単に定義します。
BPP:
画像内の異なる色の数は、色の深さまたはピクセルあたりのビット数によって異なります。
数学的に:
グレーレベルの解像度とピクセルあたりのビット数の間に確立できる数学的関係は、として与えることができます。

この式で、Lはグレーレベルの数を表します。灰色の色合いとして定義することもできます。また、kはbppまたはピクセルあたりのビット数を指します。したがって、ピクセルあたりのビット数の2の累乗は、グレーレベルの解像度に等しくなります。
例えば:
上のアインシュタインの画像はグレースケール画像です。ピクセルあたり8ビットまたは8bppの画像であることを意味します。
グレーレベルの解像度を計算する場合は、ここでどのように計算しますか。
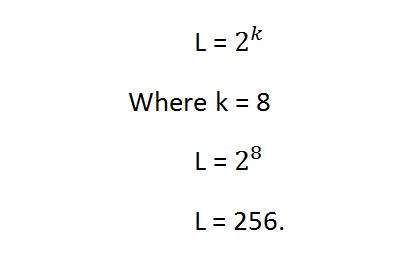
これは、グレーレベルの解像度が256であることを意味します。つまり、この画像には256の異なるグレーの色合いがあると言えます。
画像のピクセルあたりのビット数が多いほど、グレーレベルの解像度も高くなります。
bppの観点からグレーレベルの解像度を定義する:
グレーレベルの解像度をレベルのみで定義する必要はありません。ピクセルあたりのビット数で定義することもできます。
例えば:
4 bppの画像が与えられ、そのグレーレベルの解像度を計算するように求められた場合。その質問には2つの答えがあります。
最初の答えは16レベルです。
2番目の答えは4ビットです。
グレーレベルの解像度からbppを見つける:
また、指定されたグレーレベル解像度からピクセルあたりのビット数を見つけることもできます。このためには、式を少しひねるだけです。
式1。
この式はレベルを見つけます。ここで、ピクセルあたりのビット数、この場合はkを見つける場合は、次のように変更するだけです。
K =対数基数2(L)式(2)
最初の式では、レベル(L)とピクセルあたりのビット数(k)の関係は指数関数的であるためです。ここで、それを元に戻す必要があるため、指数の逆数は対数です。
グレーレベルの解像度からピクセルあたりのビット数を見つける例を見てみましょう。
例えば:
256レベルの画像が与えられた場合。それに必要なピクセルあたりのビット数はいくつですか。
方程式に256を入れると、次のようになります。
K =対数基数2(256)
K = 8。
したがって、答えは1ピクセルあたり8ビットです。
グレーレベルの解像度と量子化:
量子化は次のチュートリアルで正式に紹介されますが、ここではグレーレベルの解像度と量子化の関係について説明します。
グレーレベルの解像度は、信号のy軸にあります。信号とシステムの概要のチュートリアルでは、アナログ信号のデジタル化には2つのステップが必要であることを学習しました。サンプリングと量子化。
サンプリングはx軸で行われます。そして量子化はY軸で行われます。
つまり、画像のグレーレベル解像度のデジタル化は量子化で行われます。
信号とシステムのチュートリアルで量子化を導入しました。このチュートリアルでは、正式にデジタル画像と関連付けます。まず、量子化について少し説明しましょう。
信号のデジタル化。
前のチュートリアルで見たように、アナログ信号をデジタルにデジタル化するには、2つの基本的な手順が必要です。サンプリングと量子化。サンプリングはx軸で行われます。これは、x軸(無限値)からデジタル値への変換です。
次の図は、信号のサンプリングを示しています。
デジタル画像に関連するサンプリング:
サンプリングの概念は、ズームに直接関係しています。取得するサンプルが多いほど、より多くのピクセルが得られます。オーバーサンプリングは、ズームとも呼ばれます。これについては、サンプリングとズームのチュートリアルで説明しています。
しかし、信号のデジタル化の話はサンプリングだけで終わるわけではありません。量子化として知られている別のステップが含まれています。
量子化とは何ですか。
量子化はサンプリングの反対です。これはy軸で行われます。画像を量子化する場合、実際には信号を量子(パーティション)に分割します。
信号のx軸には座標値があり、y軸には振幅があります。したがって、振幅のデジタル化は量子化として知られています。
ここでそれがどのように行われるか
この画像では、信号が3つの異なるレベルに定量化されていることがわかります。つまり、画像をサンプリングするとき、実際には多くの値を収集し、量子化では、これらの値にレベルを設定します。これは、下の画像でより明確になります。
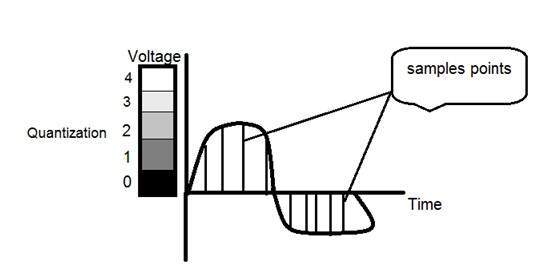
サンプリングに示されている図では、サンプルは取得されていますが、グレーレベル値の連続範囲まで垂直方向に広がっていました。上に示した図では、これらの垂直方向の範囲の値は、5つの異なるレベルまたはパーティションに量子化されています。0黒から4白までの範囲。このレベルは、必要な画像の種類によって異なる場合があります。
量子化とグレーレベルの関係については、以下でさらに説明します。
量子化とグレーレベル解像度の関係:
上に示した量子化された図には、5つの異なるレベルのグレーがあります。これは、この信号から形成された画像が5つの異なる色しかないことを意味します。それは多かれ少なかれ灰色のいくつかの色を伴う白黒画像になるでしょう。画像の品質を向上させるために、ここでできることが1つあります。これは、レベルを上げる、またはグレーレベルの解像度を上げることです。このレベルを256に上げると、グレースケール画像があることを意味します。これは、単純な白黒画像よりもはるかに優れています。
現在、256、5、または選択したレベルはグレーレベルと呼ばれます。グレーレベル解像度の前のチュートリアルで説明した式を覚えておいてください。
グレーレベルは2つの方法で定義できることを説明しました。これらの2つはどれでしたか。
グレーレベル=ピクセルあたりのビット数(BPP)(式のk)
グレーレベル=ピクセルあたりのレベル数。
この場合、グレーレベルは256に等しくなります。ビット数を計算する必要がある場合は、式に値を入力するだけです。256レベルの場合、256の異なるグレーの色合いとピクセルあたり8ビットがあるため、画像はグレースケール画像になります。
グレーレベルを下げる
次に、画像のグレーレベルを下げて、画像への影響を確認します。
例えば:
256の異なるレベルを持つ8bppの画像があるとします。グレースケール画像で、こんな感じです。
256グレーレベル
次に、グレーレベルの削減を開始します。まず、グレーレベルを256から128に減らします。
128グレーレベル

グレーレベルを半分に下げた後は、画像にあまり影響はありません。もう少し減らしましょう。
64グレーレベル

まだあまり効果がないので、レベルをさらに下げましょう。
32グレーレベル

まだ少し効果があるのを見て驚いた。アインシュタインの写真だからかもしれませんが、もっとレベルを下げましょう。
16グレーレベル

ここでブーム、私たちは行きます、画像は最終的にそれがレベルによって影響されることを明らかにします。
8つのグレーレベル

4つのグレーレベル

これを減らす前に、さらに2つの2レベル、グレーレベルを減らすことで画像がひどく歪んでいることが簡単にわかります。次に、それを2レベルに減らします。これは、単純な白黒レベルにすぎません。これは、画像が単純な白黒画像になることを意味します。
2つのグレーレベル

これが私たちが達成できる最後のレベルです。それをさらに減らすと、それは単に黒い画像になり、解釈できなくなるからです。
輪郭:
ここで興味深い観察があります。グレーレベルの数を減らすと、画像に特殊なタイプの効果が現れ始めます。これは、16グレーレベルの画像ではっきりと見ることができます。この効果は輪郭として知られています。
Isoプリファレンスカーブ:
この効果に対する答え、つまりそれが現れる理由は、Iso選好曲線にあります。これらについては、次の輪郭とIso設定曲線のチュートリアルで説明します。
輪郭とは何ですか?
画像のグレーレベルの数を減らすと、いくつかの偽色またはエッジが画像に表示され始めます。これは、量子化の最後のチュートリアルで示されています。
それを見てみましょう。
グレーまたはグレーレベルの256の異なる色合いを持つ8bppの画像(グレースケール画像)があるとします。
この上の写真には、256の異なるグレーの色合いがあります。これを128に減らし、さらに64に減らすと、画像はほぼ同じになります。しかし、それをさらに32の異なるレベルに減らすと、次のような画像が得られます。
よく見ると、効果が画像に現れ始めていることがわかります。これらの効果は、さらに16レベルに下げると、より見やすくなり、このような画像が得られます。
この画像に現れ始めるこれらの線は、上の画像で非常によく見える輪郭として知られています。
輪郭の増減
グレーレベルの数を減らすと輪郭の効果が増加し、グレーレベルの数を増やすと効果が減少します。どちらもその逆です
VS
つまり、より多くの量子化がより多くの輪郭に影響し、その逆も同様です。しかし、これは常に当てはまります。答えはノーです。それは、以下で説明する他の何かに依存します。
等方性曲線
グレーレベルと輪郭のこの効果について行われた研究と、その結果は、Iso優先曲線として知られる曲線の形でグラフに示されました。
アイソプリファレンス曲線の現象は、輪郭の効果がグレーレベルの解像度の低下だけでなく、画像の詳細にも依存することを示しています。
研究の本質は次のとおりです。
画像の詳細度が高い場合、グレーレベルが量子化されると、詳細度の低い画像と比較して、輪郭の効果が後でこの画像に現れ始めます。
元の研究によると、研究者はこれらの3つの画像を撮影し、3つの画像すべてでグレーレベルの解像度を変えています。
画像は



詳細度:
最初の画像には顔だけが含まれているため、詳細はほとんどありません。2番目の画像には、カメラマン、彼のカメラ、カメラスタンド、背景オブジェクトなど、画像内の他のオブジェクトも含まれていますが、3番目の画像には他のすべての画像よりも詳細が含まれています。
実験:
グレーレベルの解像度はすべての画像で異なり、聴衆はこれら3つの画像を主観的に評価するように求められました。評価後、結果に応じてグラフを作成しました。
結果:
結果はグラフに描かれました。グラフの各曲線は1つの画像を表しています。x軸の値はグレーレベルの数を表し、y軸の値はピクセルあたりのビット数(k)を表します。
グラフを以下に示します。
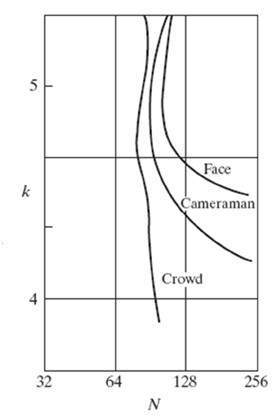
このグラフによると、顔の最初の画像は、他の2つの画像すべてよりも早く輪郭が描かれていることがわかります。カメラマンの2番目の画像は、最初の画像のグレーレベルが下がった後、少し輪郭が描かれていました。これは、最初の画像よりも詳細が含まれているためです。そして、3番目の画像は最初の2つの画像の後、つまり4bppの後の輪郭に大きく影響されました。これは、この画像に詳細があるためです。
結論:
したがって、より詳細な画像の場合、アイソプリファレンス曲線はますます垂直になります。また、詳細が多い画像の場合、必要なグレーレベルはごくわずかであることも意味します。
量子化と輪郭の最後の2つのチュートリアルでは、画像のグレーレベルを下げると、画像を表すために必要な色の数が減ることを確認しました。グレーレベルが22に減少すると、表示される画像の空間解像度が低くなるか、あまり魅力的ではなくなります。
ディザリング:
ディザリングは、実際には存在しない色の錯覚を作成するプロセスです。これは、ピクセルのランダムな配置によって行われます。
例えば。この画像を考えてみましょう。

これは、白黒のピクセルのみが含まれている画像です。そのピクセルは、以下に示す別の画像を形成するために配置されています。ピクセルの配置は変更されていますが、ピクセルの数は変更されていないことに注意してください。

なぜディザリング?
なぜディザリングが必要なのか、その答えは量子化との関係にあります。
量子化によるディザリング。
最後のレベルまで量子化を実行すると、最後のレベル(レベル2)に入る画像は次のようになります。
ここの画像からわかるように、特にアインシュタインの画像の左腕と背面を見ると、画像はあまりはっきりしていません。また、この写真にはアインシュタインの情報や詳細があまりありません。
ここで、この画像をこれよりも詳細な画像に変更する場合は、ディザリングを実行する必要があります。
ディザリングを実行します。
まず、しきい値設定に取り組みます。ディザリングは通常、しきい値を改善するために機能します。しきい値を設定すると、画像のグラデーションが滑らかな場所に鋭いエッジが表示されます。
しきい値処理では、定数値を選択するだけです。その値より上のすべてのピクセルは1と見なされ、その値より下のすべての値は0と見なされます。
しきい値処理後にこの画像を取得しました。

この画像では値がすでに0と1、または白黒であるため、画像に大きな変化はありません。
次に、ランダムなディザリングを実行します。ピクセルのランダムな配置。

細部が少しだけ見える画像が得られましたが、コントラストが非常に低くなっています。
そこで、コントラストを上げるために、さらにディザリングを行います。私たちが得た画像はこれです:

ここで、ランダムディザリングの概念としきい値を組み合わせて、次のような画像を取得しました。

ご覧のとおり、画像のピクセルを再配置するだけで、これらすべての画像を取得できました。この再配置はランダムである場合もあれば、何らかの方法による場合もあります。
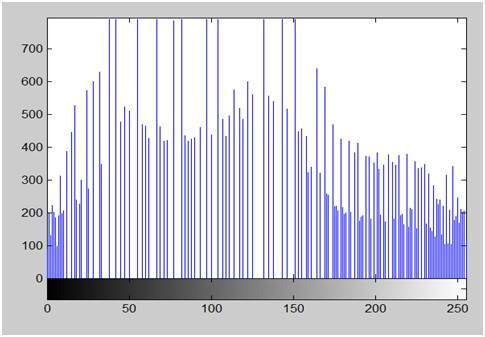
画像処理でのヒストグラムの使用について説明する前に、まずヒストグラムとは何か、どのように使用されるか、次にヒストグラムの例を見て、ヒストグラムをより深く理解します。
ヒストグラム:
ヒストグラムはグラフです。何かの頻度を示すグラフ。通常、ヒストグラムには、データセット全体でのデータの発生頻度を表すバーがあります。
ヒストグラムには、x軸とy軸の2つの軸があります。
x軸には、頻度をカウントする必要のあるイベントが含まれています。
y軸には周波数が含まれます。
バーの高さが異なると、データの発生頻度も異なります。
通常、ヒストグラムは次のようになります。
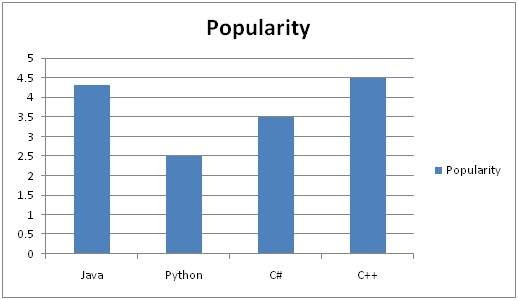
ここで、このヒストグラムの例がビルドされていることがわかります。
例:
プログラミングの学生のクラスを考えてみましょう。あなたは彼らにPythonを教えています。
学期の終わりに、あなたは表に示されているこの結果を得ました。しかし、それは非常に厄介で、クラスの全体的な結果を示していません。したがって、結果のヒストグラムを作成して、クラスでの成績の全体的な発生頻度を示す必要があります。ここであなたはそれをどのように行うつもりですか。
結果シート:
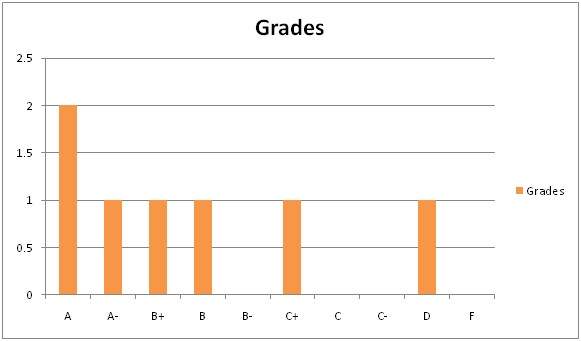
| 名前 | グレード |
|---|---|
| ジョン | A |
| ジャック | D |
| カーター | B |
| トミー | A |
| リサ | C + |
| デレク | A- |
| トム | B + |
結果シートのヒストグラム:
今、あなたがやろうとしていることは、x軸とy軸に何が来るかを見つけなければならないということです。
確かなことが1つあります。それは、y軸に周波数が含まれているため、x軸に何が来るかということです。X軸には、頻度を計算する必要があるイベントが含まれています。この場合、x軸にはグレードが含まれています。
次に、画像でヒストグラムを使用する方法を説明します。
画像のヒストグラム
他のヒストグラムと同様に、画像のヒストグラムも頻度を示します。しかし、画像ヒストグラムは、ピクセル強度値の頻度を示しています。画像ヒストグラムでは、x軸はグレーレベルの強度を示し、y軸はこれらの強度の頻度を示します。
例えば:
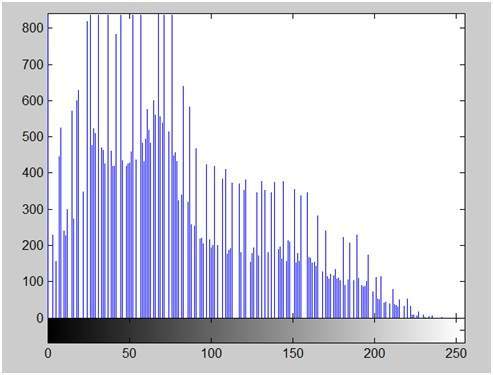
アインシュタインの上の写真のヒストグラムは次のようになります
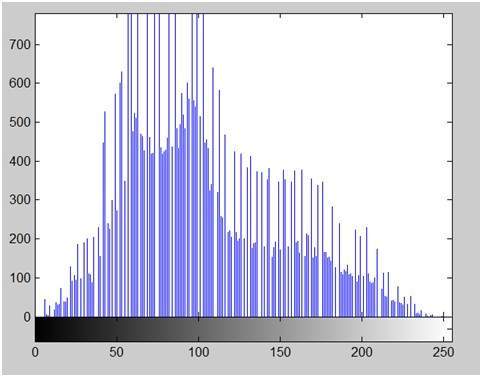
ヒストグラムのx軸は、ピクセル値の範囲を示しています。8 bppの画像なので、256レベルのグレーまたはグレーの色合いが含まれていることを意味します。そのため、x軸の範囲は0から始まり、255で終わり、ギャップは50です。一方、y軸では、これらの強度のカウントです。
グラフからわかるように、高周波のバーのほとんどは、前半の暗い部分にあります。つまり、私たちが得た画像はより暗いということです。そして、これは画像からも証明できます。
ヒストグラムのアプリケーション:
ヒストグラムは、画像処理で多くの用途があります。上でも説明したように、最初の用途は画像の分析です。ヒストグラムを見るだけで画像を予測できます。それは体の骨のX線を見るようなものです。
ヒストグラムの2番目の用途は、明るさの目的です。ヒストグラムは、画像の明るさに幅広く適用されます。明るさだけでなく、ヒストグラムは画像のコントラストの調整にも使用されます。
ヒストグラムのもう1つの重要な用途は、画像を均等化することです。
そして最後になりましたが、ヒストグラムはしきい値処理に広く使用されています。これは主にコンピュータビジョンで使用されます。
輝度:
明るさは相対的な用語です。それはあなたの視覚に依存します。明るさは相対的な用語であるため、明るさは、比較対象の光源に対する光源から出力されるエネルギー量として定義できます。画像が明るいと簡単に言える場合もあれば、知覚しにくい場合もあります。
例えば:
これらの画像の両方を見て、どちらが明るいかを比較してください。

左側の画像に比べて右側の画像が明るいことが簡単にわかります。
しかし、右側の画像を最初の画像よりも暗くすると、左側の画像は左側よりも明るくなると言えます。
画像を明るくする方法。
明るさは、画像マトリックスへの単純な加算または減算によって単純に増減できます。
5行5列のこの黒い画像を考えてみましょう

すでに知っているので、各画像の背後にはピクセル値を含む行列があります。この画像マトリックスを以下に示します。
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 |
行列全体がゼロで満たされているため、画像は非常に暗くなります。
次に、それを別の同じ黒い画像と比較して、この画像が明るくなったかどうかを確認します。

それでも両方の画像は同じですが、ここでimage1に対していくつかの操作を実行します。これにより、2番目の画像よりも明るくなります。
画像1の各行列値に値1を追加するだけです。画像1を追加すると、次のようになります。
ここでもう一度画像2と比較し、違いを確認します。
両方の画像が同じように見えるため、どちらの画像が明るいかはまだわかりません。
次に、画像1の各マトリックス値に50を加算して、画像がどのようになったかを確認します。
出力を以下に示します。

ここでも、画像2と比較します。
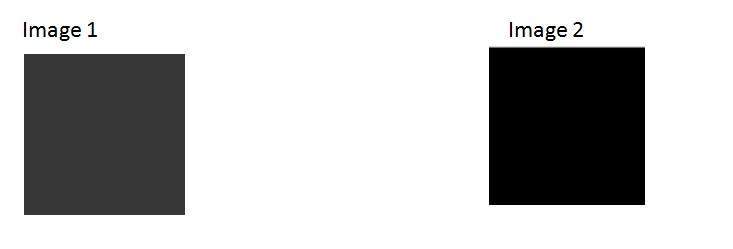
これで、画像1が画像2よりもわずかに明るいことがわかります。次に、画像1のマトリックスにさらに45の値を追加し、今度は両方の画像を再度比較します。

これを比較すると、この画像1は画像2よりも明らかに明るいことがわかります。
それでも古い画像よりも明るい1。この時点で、image1のマトリックスには、最初に5、次に50、次に45を加算するため、各インデックスに100が含まれます。したがって、5 + 50 + 45 = 100です。
コントラスト
コントラストは、画像の最大ピクセル強度と最小ピクセル強度の差として簡単に説明できます。
例えば。
明るさの最終的なimage1を考えてみましょう。

この画像のマトリックスは次のとおりです。
| 100 | 100 | 100 | 100 | 100 |
| 100 | 100 | 100 | 100 | 100 |
| 100 | 100 | 100 | 100 | 100 |
| 100 | 100 | 100 | 100 | 100 |
| 100 | 100 | 100 | 100 | 100 |
この行列の最大値は100です。
この行列の最小値は100です。
コントラスト=最大ピクセル強度(減算)最小ピクセル強度
= 100(減算)100
= 0
0は、この画像のコントラストが0であることを意味します。
画像変換とは何かを説明する前に、変換とは何かについて説明します。
変換。
変換は機能です。いくつかの操作を実行した後、あるセットを別のセットにマップする関数。
デジタル画像処理システム:
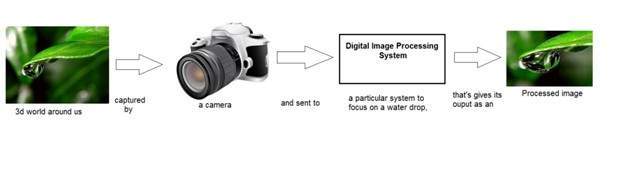
入門チュートリアルで、デジタル画像処理では、入力が画像で出力も画像になるシステムを開発することはすでに見てきました。そして、システムは入力画像に対して何らかの処理を実行し、その出力を処理済み画像として提供します。以下に示します。
これで、このデジタルシステム内で適用され、画像を処理して出力に変換する関数を変換関数と呼ぶことができます。
変換または関係を示しているように、image1がimage2に変換される方法。
画像変換。
この方程式を考えてみましょう
G(x、y)= T {f(x、y)}
この方程式では、
F(x、y)=変換関数を適用する必要のある入力画像。
G(x、y)=出力画像または処理された画像。
Tは変換関数です。
入力画像と処理された出力画像の間のこの関係は、として表すこともできます。
s = T(r)
ここで、rは実際には任意の点でのf(x、y)のピクセル値またはグレーレベル強度です。また、sは、任意の点でのg(x、y)のピクセル値またはグレーレベル強度です。
基本的なグレーレベル変換については、基本的なグレーレベル変換のチュートリアルで説明しています。
次に、非常に基本的な変換関数のいくつかについて説明します。
例:
この変換関数について考えてみましょう。
点rを256、点pを127とします。この画像を1bpp画像と見なします。つまり、強度のレベルは0と1の2つだけです。したがって、この場合、グラフに示されている変換は次のように説明できます。
127(ポイントp)未満のすべてのピクセル強度値は0であり、黒を意味します。そして、127より大きいすべてのピクセル強度値は1であり、これは白を意味します。しかし、127の正確なポイントで、送信に突然の変化があるため、その正確なポイントで、値が0または1になるかどうかはわかりません。
数学的には、この変換関数は次のように表すことができます。
次のような別の変換を検討してください。
この特定のグラフを見ると、入力画像と出力画像の間に直線の遷移線が表示されます。
これは、入力画像の各ピクセルまたは強度値に対して、出力画像の同じ強度値があることを示しています。つまり、出力画像は入力画像の正確なレプリカです。
数学的に次のように表すことができます。
g(x、y)= f(x、y)
この場合の入力画像と出力画像を以下に示します。

ヒストグラムの基本的な概念については、ヒストグラムの概要のチュートリアルで説明しています。ただし、ここではヒストグラムを簡単に紹介します。
ヒストグラム:
ヒストグラムは、データの発生頻度を示すグラフに他なりません。ヒストグラムは画像処理で多くの用途がありますが、ここではヒストグラムスライディングと呼ばれる1人のユーザーについて説明します。
ヒストグラムのスライド。
ヒストグラムのスライドでは、ヒストグラム全体を右または左にシフトするだけです。ヒストグラムを右または左にシフトまたはスライドさせると、画像に明確な変化が見られます。このチュートリアルでは、明るさを操作するためにヒストグラムのスライドを使用します。
つまり、明るさという用語は、明るさとコントラストの概要のチュートリアルで説明されています。ただし、ここで簡単に定義します。
輝度:
明るさは相対的な用語です。明るさは、特定の光源から放出される光の強度として定義できます。
コントラスト:
コントラストは、画像の最大ピクセル強度と最小ピクセル強度の差として定義できます。
スライドヒストグラム
ヒストグラムのスライドを使用して明るさを上げる
この画像のヒストグラムを以下に示します。
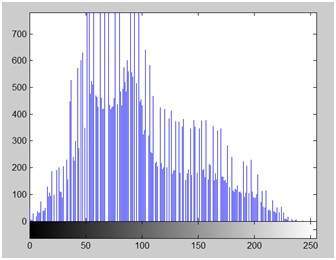
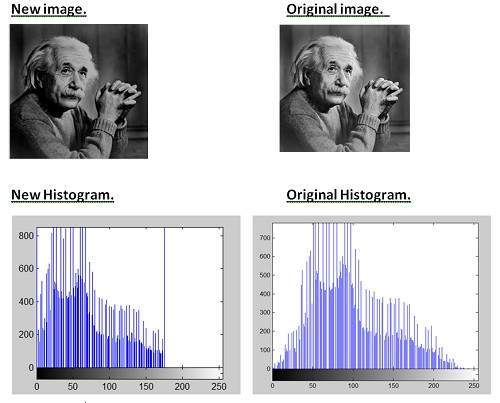
このヒストグラムのy軸には、頻度またはカウントがあります。また、x軸には、グレーレベル値があります。上記のヒストグラムからわかるように、カウントが700を超えるグレーレベルの強度は、前半の部分にあり、より黒い部分に向かっていることを意味します。そのため、少し暗い画像が得られました。
明るくするために、ヒストグラムを右または白い部分にスライドさせます。そのためには、この画像に少なくとも50の値を追加する必要があります。上のヒストグラムからわかるように、この画像にも0ピクセルの強度があり、純粋な黒です。したがって、0から50を追加すると、0の強度にあるすべての値が50の強度にシフトされ、残りのすべての値はそれに応じてシフトされます。
やってみましょう。
これは、各ピクセル強度に50を追加した後に得られたものです。
画像を以下に示します。

そして、そのヒストグラムを以下に示します。
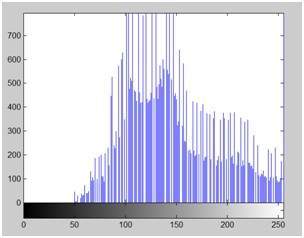
これらの2つの画像とそれらのヒストグラムを比較して、どのような変更が必要かを確認しましょう。
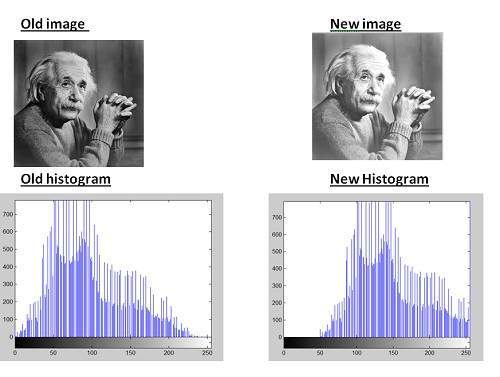
結論:
新しいヒストグラムから明らかなように、すべてのピクセル値が右にシフトされており、その効果が新しい画像で確認できます。
ヒストグラムのスライドを使用して明るさを下げる
ここで、この新しい画像の明るさを、古い画像が明るく見える程度に下げるとしたら、新しい画像のすべてのマトリックスからある値を差し引く必要があります。減算する値は80です。元の画像にすでに50を加算し、新しい明るい画像を取得したため、暗くしたい場合は、少なくとも50を減算する必要があります。
そして、これは新しい画像から80を引いた後に得られたものです。
結論:
新しい画像のヒストグラムから、すべてのピクセル値が右にシフトされていることが明らかです。したがって、この新しい画像と比較して、新しい画像が暗くなり、元の画像が明るく見えることが画像から確認できます。
ヒストグラム入門のチュートリアルで説明したヒストグラムの他の利点の1つは、コントラストの向上です。
コントラストを強調する方法は2つあります。1つ目は、コントラストを高めるヒストグラムストレッチと呼ばれます。2つ目は、コントラストを強化するヒストグラム均等化と呼ばれ、ヒストグラム均等化のチュートリアルで説明されています。
コントラストを上げるためのヒストグラムストレッチについて説明する前に、コントラストを簡単に定義します。
コントラスト。
コントラストは、最大ピクセル強度と最小ピクセル強度の差です。
この画像を考えてみましょう。

この画像のヒストグラムを以下に示します。
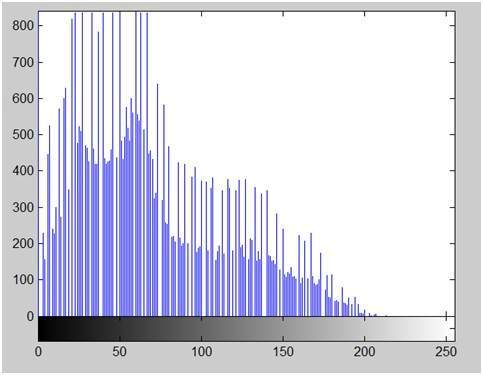
次に、この画像からコントラストを計算します。
コントラスト= 225。
次に、画像のコントラストを上げます。
画像のコントラストを上げる:
画像のヒストグラムを引き伸ばしてコントラストを上げるための式は次のとおりです。
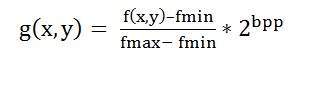
この式では、最小および最大のピクセル強度にグレーのレベルを掛けたものを見つける必要があります。この場合、画像は8bppなので、グレーのレベルは256です。
最小値は0、最大値は225です。したがって、この場合の式は次のようになります。
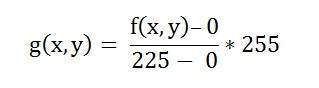
ここで、f(x、y)は各ピクセル強度の値を示します。画像内の各f(x、y)について、この式を計算します。
これを行うと、コントラストを高めることができます。
次の画像は、ヒストグラムストレッチを適用した後に表示されます。

この画像の拡大されたヒストグラムを以下に示します。
ヒストグラムの形状と対称性に注意してください。これで、ヒストグラムが引き伸ばされるか、他の方法で拡大されます。それを見てください。
この場合、画像のコントラストは次のように計算できます。
コントラスト= 240
したがって、画像のコントラストが向上していると言えます。
注:コントラストを上げるこの方法は常に機能するとは限りませんが、場合によっては失敗します。
ヒストグラムのストレッチの失敗
すでに説明したように、アルゴリズムが失敗する場合があります。これらのケースには、ピクセル強度が0および255の場合の画像が含まれます。
なぜなら、ピクセル強度0と255が画像に存在する場合、それらは最小および最大ピクセル強度になり、このような式を台無しにするからです。
オリジナルフォーミュラ
失敗ケースの値を式に入れる:
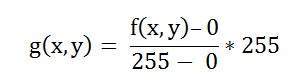
式が与えることを単純化する
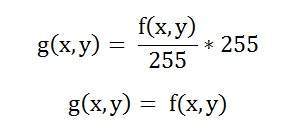
これは、出力画像が処理された画像と等しいことを意味します。これは、この画像ではヒストグラムストレッチの効果がないことを意味します。
PMFとCDFはどちらも、確率と統計に属します。今、あなたの心に浮かぶべき問題は、なぜ私たちが確率を研究しているのかということです。これは、PMFとCDFのこれら2つの概念が、ヒストグラム均等化の次のチュートリアルで使用されるためです。したがって、PMFとCDFの計算方法がわからない場合は、画像にヒストグラム均等化を適用できません。
PMFとは何ですか?
PMFは確率質量関数の略です。名前が示すように、データセット内の各数値の確率を示します。または、基本的に各要素の数または頻度を示していると言えます。
PMFの計算方法:
2つの異なる方法からPMFを計算します。最初に行列から。次のチュートリアルでは、行列からPMFを計算する必要があり、画像は2次元の行列にすぎません。
次に、ヒストグラムからPMFを計算する別の例を取り上げます。
この行列を考えてみましょう。
| 1 | 2 | 7 | 5 | 6 |
| 7 | 2 | 3 | 4 | 5 |
| 0 | 1 | 5 | 7 | 3 |
| 1 | 2 | 5 | 6 | 7 |
| 6 | 1 | 0 | 3 | 4 |
ここで、この行列のPMFを計算する場合、ここでどのように計算するかを説明します。
最初に、行列の最初の値を取得し、次に、この値が行列全体に表示される時間をカウントします。カウント後、それらはヒストグラムまたは以下のような表のいずれかで表すことができます。
PMF
| 0 | 2 | 2/25 |
| 1 | 4 | 4/25 |
| 2 | 3 | 3/25 |
| 3 | 3 | 3/25 |
| 4 | 2 | 2/25 |
| 5 | 4 | 4/25 |
| 6 | 3 | 3/25 |
| 7 | 4 | 4/25 |
カウントの合計は、値の総数と等しくなければならないことに注意してください。
ヒストグラムからPMFを計算する
上記のヒストグラムは、8ビット/ピクセルの画像のグレーレベル値の頻度を示しています。
ここで、PMFを計算する必要がある場合は、縦軸から各バーの数を簡単に調べて、それを合計数で割ります。
したがって、上記のヒストグラムのPMFはこれです。
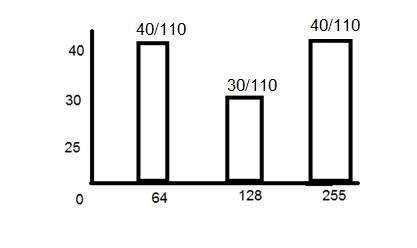
上記のヒストグラムで注意すべきもう1つの重要な点は、単調に増加していないことです。したがって、単調に増加させるために、CDFを計算します。
CDFとは何ですか?
CDFは、累積分布関数の略です。これは、PMFによって計算されたすべての値の累積合計を計算する関数です。基本的に前のものを合計します。
それはどのように計算されますか?
ヒストグラムを使用してCDFを計算します。ここでそれがどのように行われるか。PMFを示す上記のヒストグラムについて考えてみます。
このヒストグラムは単調に増加していないため、単調に増加します。
最初の値をそのままにして、2番目の値に最初の値を追加します。
上記のPMF関数のCDFは次のとおりです。
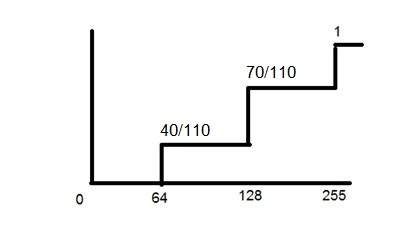
上のグラフからわかるように、PMFの最初の値はそのままです。PMFの2番目の値が最初の値に追加されて128を超えます。PMFの3番目の値がCDFの2番目の値に追加され、110/110が1に等しくなります。
また、現在、関数は単調に成長しています。これは、ヒストグラム均等化の必要条件です。
ヒストグラム均等化におけるPMFとCDFの使用
ヒストグラム均等化。
ヒストグラム均等化については次のチュートリアルで説明しますが、ヒストグラム均等化の簡単な紹介を以下に示します。
ヒストグラム均等化は、画像のコントラストを高めるために使用されます。
このチュートリアルの冒頭で説明したように、PMFとCDFはどちらもヒストグラム均等化で使用されます。ヒストグラム均等化では、最初と2番目のステップはPMFとCDFです。ヒストグラム均等化では、画像のすべてのピクセル値を均等化する必要があるためです。したがって、PMFは、画像内の各ピクセル値の確率を計算するのに役立ちます。そして、CDFはこれらの値の累積合計を提供します。さらに、このCDFにレベルを掛けて、古い値にマッピングされた新しいピクセル強度を見つけ、ヒストグラムを均等化します。
ヒストグラムストレッチを使用してコントラストを上げることができることはすでに見てきました。このチュートリアルでは、ヒストグラム均等化を使用してコントラストを強化する方法を説明します。
ヒストグラム均等化を実行する前に、ヒストグラム均等化で使用される2つの重要な概念を知っておく必要があります。これらの2つの概念は、PMFとCDFとして知られています。
これらについては、PMFとCDFのチュートリアルで説明しています。ヒストグラム均等化の概念をうまく理解するために、それらを訪問してください。
ヒストグラム均等化:
ヒストグラム均等化は、コントラストを高めるために使用されます。これで常にコントラストが上がる必要はありません。ヒストグラム均等化が悪化する場合があります。その場合、コントラストが低下します。
以下の画像を単純な画像として、ヒストグラム均等化を開始しましょう。
画像
この画像のヒストグラム:
この画像のヒストグラムを以下に示します。
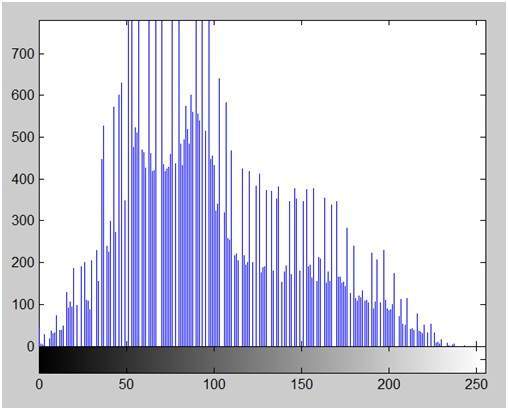
次に、ヒストグラム均等化を実行します。
PMF:
まず、この画像のすべてのピクセルのPMF(確率質量関数)を計算する必要があります。PMFの計算方法がわからない場合は、PMF計算のチュートリアルにアクセスしてください。
CDF:
次のステップは、CDF(累積分布関数)の計算です。CDFの計算方法がわからない場合も、CDF計算のチュートリアルにアクセスしてください。
グレーレベルに従ってCDFを計算します
たとえば、これを考えてみましょう。2番目のステップで計算されたCDFは次のようになります。
| グレーレベル値 | CDF |
|---|---|
| 0 | 0.11 |
| 1 | 0.22 |
| 2 | 0.55 |
| 3 | 0.66 |
| 4 | 0.77 |
| 5 | 0.88 |
| 6 | 0.99 |
| 7 | 1 |
次に、このステップでは、CDF値に(グレーレベル(マイナス)1)を掛けます。
3bppの画像があることを考慮してください。次に、レベルの数は8です。1から8を引くと7になります。したがって、CDFに7を掛けます。ここでは、掛けた後に得られたものを示します。
| グレーレベル値 | CDF | CDF *(レベル-1) |
|---|---|---|
| 0 | 0.11 | 0 |
| 1 | 0.22 | 1 |
| 2 | 0.55 | 3 |
| 3 | 0.66 | 4 |
| 4 | 0.77 | 5 |
| 5 | 0.88 | 6 |
| 6 | 0.99 | 6 |
| 7 | 1 | 7 |
これが最後のステップです。ここでは、新しいグレーレベル値をピクセル数にマッピングする必要があります。
古いグレーレベルの値にこれらのピクセル数があると仮定しましょう。
| グレーレベル値 | 周波数 |
|---|---|
| 0 | 2 |
| 1 | 4 |
| 2 | 6 |
| 3 | 8 |
| 4 | 10 |
| 5 | 12 |
| 6 | 14 |
| 7 | 16 |
ここで、新しい値をにマップすると、これが得られます。
| グレーレベル値 | 新しいグレーレベル値 | 周波数 |
|---|---|---|
| 0 | 0 | 2 |
| 1 | 1 | 4 |
| 2 | 3 | 6 |
| 3 | 4 | 8 |
| 4 | 5 | 10 |
| 5 | 6 | 12 |
| 6 | 6 | 14 |
| 7 | 7 | 16 |
次に、これらの新しい値をヒストグラムにマッピングします。これで完了です。
この手法を元の画像に適用してみましょう。適用後、次の画像とそのヒストグラムを取得しました。
ヒストグラム均等化画像

この画像の累積分布関数
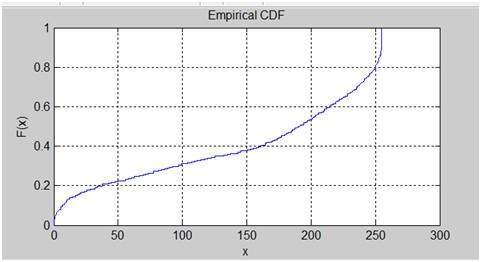
ヒストグラム均等化ヒストグラム
ヒストグラムと画像の両方を比較する

結論
画像から明らかなように、新しい画像のコントラストが強化され、そのヒストグラムも均等化されています。ここで注意すべき重要な点が1つあります。ヒストグラム均等化中に、ヒストグラムの全体的な形状が変化しますが、ヒストグラムのストレッチの場合と同様に、ヒストグラムの全体的な形状は同じままです。
基本変換のチュートリアルでは、いくつかの基本変換について説明しました。このチュートリアルでは、基本的なグレーレベル変換のいくつかを見ていきます。
画像エンハンスメント
画像を強調すると、強調されていない画像と比較して、より良いコントラストとより詳細な画像が得られます。画像エンハンスメントには非常に用途があります。医用画像、リモートセンシングでキャプチャされた画像、衛星からの画像などを強調するために使用されます
変換関数を以下に示します。
s = T(r)
ここで、rは入力画像のピクセル、sは出力画像のピクセルです。Tは、rの各値をsの各値にマップする変換関数です。画像の強調は、以下で説明するグレーレベル変換を通じて行うことができます。
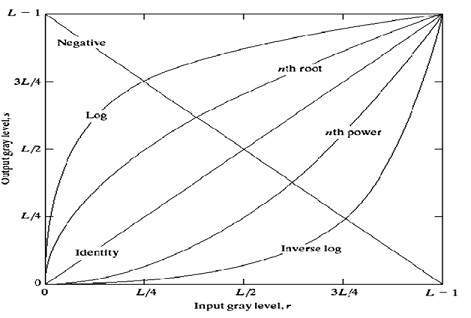
グレーレベル変換
3つの基本的なグレーレベル変換があります。
Linear
Logarithmic
べき乗則
これらの遷移の全体的なグラフを以下に示します。
線形変換
まず、線形変換について見ていきます。線形変換には、単純なアイデンティティと負の変換が含まれます。アイデンティティ変換については、画像変換のチュートリアルで説明しましたが、この変換について簡単に説明します。
アイデンティティの遷移は直線で示されます。この遷移では、入力画像の各値が出力画像の相互の値に直接マッピングされます。その結果、同じ入力画像と出力画像になります。したがって、アイデンティティ変換と呼ばれます。以下に示します
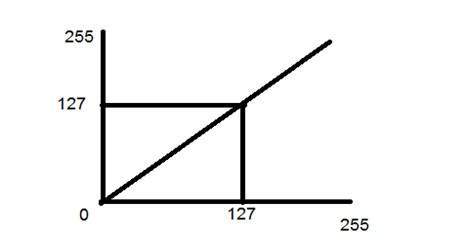
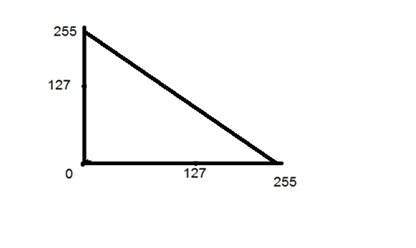
負の変換
2番目の線形変換は、恒等変換の反転である負の変換です。負の変換では、入力画像の各値がL-1から減算され、出力画像にマッピングされます。
結果はこんな感じです。
入力画像

出力画像

この場合、次の遷移が実行されています。
s =(L – 1)– r
アインシュタインの入力画像は8bpp画像であるため、この画像のレベル数は256です。方程式に256を入れると、次のようになります。
s = 255 – r
したがって、各値は255で減算され、結果の画像は上に表示されています。つまり、明るいピクセルは暗くなり、暗い画像は明るくなります。そしてそれはイメージネガになります。
下のグラフに示されています。
対数変換:
対数変換には、さらに2つのタイプの変換が含まれます。対数変換と逆対数変換。
ログ変換
対数変換は、この式で定義できます。
s = c log(r + 1)。
ここで、sとrは出力と入力画像のピクセル値であり、cは定数です。画像に0のピクセル強度がある場合、log(0)は無限大に等しいため、値1が入力画像の各ピクセル値に追加されます。したがって、最小値を少なくとも1にするために、1が追加されます。
対数変換中、画像の暗いピクセルは、高いピクセル値と比較して拡大されます。高いピクセル値は、対数変換で圧縮されます。これにより、次の画像が強調されます。
ログ変換のcの値は、探している拡張機能の種類を調整します。
入力画像

ログ変換画像

逆対数変換は、対数変換の反対です。
べき乗則の変換
さらに2つの変換があり、n乗変換とn乗根変換が含まれます。これらの変換は、次の式で与えることができます。
s = cr ^γ
この記号γはガンマと呼ばれ、この変換はガンマ変換とも呼ばれます。
γの値の変化は、画像の強調を変化させます。さまざまなディスプレイデバイス/モニターには独自のガンマ補正があるため、さまざまな強度で画像を表示します。
このタイプの変換は、さまざまなタイプのディスプレイデバイスの画像を強調するために使用されます。異なるディスプレイデバイスのガンマは異なります。たとえば、CRTのガンマは1.8〜2.5の間にあります。これは、CRTに表示される画像が暗いことを意味します。
ガンマを修正します。
s = cr ^γ
s = cr ^(1 / 2.5)
同じ画像ですが、ガンマ値が異なります。
例えば:
ガンマ= 10

ガンマ= 8

ガンマ= 6

このチュートリアルは、信号とシステムの非常に重要な概念の1つについてです。畳み込みについて完全に説明します。それは何ですか?それはなぜです?それで何ができるでしょうか?
画像処理の基礎から畳み込みについて説明します。
画像処理とは何ですか。
画像処理チュートリアルの概要と信号とシステムで説明したように、画像は2次元信号にすぎないため、画像処理は多かれ少なかれ信号とシステムの研究です。
また、画像処理では、入力が画像で出力が画像となるシステムを開発していることについても説明しました。これは絵で表されます。
上の図に「デジタル画像処理システム」と表示されているボックスは、ブラックボックスと考えることができます。
次のように表すことができます。

今までどこにたどり着いたか
これまで、画像を操作するための2つの重要な方法について説明してきました。言い換えれば、私たちのブラックボックスはこれまで2つの異なる方法で機能していると言えます。
画像を操作する2つの異なる方法は
Graphs (Histograms)

この方法は、ヒストグラム処理として知られています。コントラストの向上、画像の強調、明るさなどについては、以前のチュートリアルで詳しく説明しました。
Transformation functions
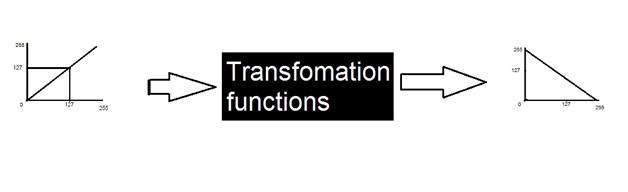
この方法は変換として知られており、さまざまなタイプの変換といくつかのグレーレベル変換について説明しました。
画像を扱う別の方法
ここでは、画像を処理する別の方法について説明します。この他の方法は畳み込みとして知られています。通常、画像処理に使用されるブラックボックス(システム)は、LTIシステムまたは線形時不変システムです。線形とは、出力が常に線形であり、対数でも指数でもないシステムを意味します。そして、時不変とは、時間の間同じままであるシステムを意味します。
したがって、この3番目の方法を使用します。として表すことができます。

それは数学的に2つの方法として表すことができます
g(x,y) = h(x,y) * f(x,y)
それは「画像と畳み込まれたマスク」として説明することができます。
または
g(x,y) = f(x,y) * h(x,y)
「マスクで畳み込まれた画像」と説明できます。
畳み込み演算子(*)は可換であるため、これを表すには2つの方法があります。h(x、y)はマスクまたはフィルターです。
マスクとは?
マスクも信号です。これは、2次元の行列で表すことができます。マスクは通常、1x1、3x3、5x5、7x7のオーダーです。マスクは常に奇数である必要があります。そうしないと、マスクの中央が見つからないためです。なぜマスクの真ん中を見つける必要があるのですか。答えは、以下のトピックで、畳み込みを実行する方法にありますか?
畳み込みを実行する方法は?
画像に対して畳み込みを実行するには、次の手順を実行する必要があります。
マスクを(水平および垂直に)1回だけ裏返します
マスクを画像上にスライドさせます。
対応する要素を乗算してから追加します
画像のすべての値が計算されるまで、この手順を繰り返します。
畳み込みの例
畳み込みを実行してみましょう。ステップ1はマスクを裏返すことです。
マスク:
マスクをこれにしましょう。
| 1 | 2 | 3 |
| 4 | 5 | 6 |
| 7 | 8 | 9 |
マスクを水平に反転させる
| 3 | 2 | 1 |
| 6 | 5 | 4 |
| 9 | 8 | 7 |
マスクを垂直に反転させる
| 9 | 8 | 7 |
| 6 | 5 | 4 |
| 3 | 2 | 1 |
画像:
このような画像を考えてみましょう
| 2 | 4 | 6 |
| 8 | 10 | 12 |
| 14 | 16 | 18 |
畳み込み
画像上の畳み込みマスク。それはこのように行われます。画像の各要素にマスクの中心を配置します。対応する要素を乗算してから追加し、その結果をマスクの中心を配置する画像の要素に貼り付けます。
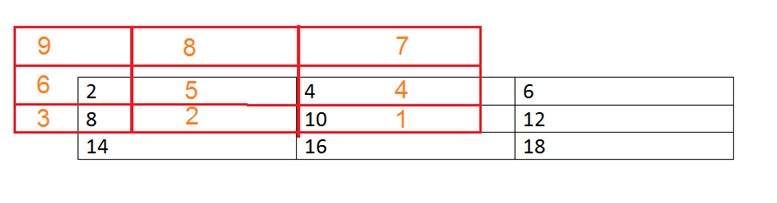
赤い色のボックスがマスクで、オレンジ色の値がマスクの値です。黒のカラーボックスと値は画像に属します。これで、画像の最初のピクセルについて、値は次のように計算されます。
最初のピクセル=(5 * 2)+(4 * 4)+(2 * 8)+(1 * 10)
= 10 + 16 + 16 + 10
= 52
元の画像の最初のインデックスに52を配置し、画像の各ピクセルに対してこの手順を繰り返します。
なぜ畳み込み
畳み込みは、画像を操作する前の2つの方法では達成できない何かを達成できます。それらには、ぼかし、シャープニング、エッジ検出、ノイズリダクションなどが含まれます。
マスクとは何ですか。
マスクはフィルターです。マスキングの概念は、空間フィルタリングとも呼ばれます。マスキングはフィルタリングとも呼ばれます。この概念では、画像に対して直接実行されるフィルタリング操作のみを扱います。
サンプルマスクを以下に示します
| -1 | 0 | 1 |
| -1 | 0 | 1 |
| -1 | 0 | 1 |
フィルタリングとは何ですか。
フィルタリングのプロセスは、マスクと画像の畳み込みとしても知られています。このプロセスは畳み込みと同じであるため、フィルターマスクは畳み込みマスクとも呼ばれます。
それがどのように行われるか。
マスクのフィルタリングと適用の一般的なプロセスは、画像内のポイントからポイントへフィルターマスクを移動することで構成されます。元の画像の各点(x、y)で、フィルターの応答は事前定義された関係によって計算されます。すべてのフィルター値は事前定義されており、標準です。
フィルタの種類
一般に、フィルターには2つのタイプがあります。1つは線形フィルターまたは平滑化フィルターと呼ばれ、もう1つは周波数領域フィルターと呼ばれます。
なぜフィルターが使用されるのですか?
フィルタは、複数の目的で画像に適用されます。最も一般的な2つの使用法は次のとおりです。
フィルタは、ぼかしとノイズリダクションに使用されます
フィルタが使用されているか、エッジ検出とシャープネス
ぼやけとノイズリダクション:
フィルタは、ぼかしやノイズ低減のために最も一般的に使用されます。ぼかしは、大きなオブジェクトを抽出する前に画像から細部を削除するなどの前処理ステップで使用されます。
ぼかし用のマスク。
ぼかしの一般的なマスクは次のとおりです。
ボックスフィルター
加重平均フィルター
ぼかしの過程で、画像のエッジコンテンツを減らし、異なるピクセル強度間の遷移をできるだけスムーズにしようとします。
ぼかしの助けを借りて、ノイズリダクションも可能です。
エッジ検出とシャープネス:
マスクまたはフィルターは、画像のエッジ検出や画像の鮮明度を高めるためにも使用できます。
エッジとは何ですか。
画像の不連続性の急激な変化をエッジと呼ぶこともできます。画像の重要な遷移はエッジと呼ばれます。エッジのある画像を以下に示します。
原画。

エッジのある同じ画像

ぼかしの簡単な紹介は、マスクの概念に関する以前のチュートリアルで説明しましたが、ここでは正式に説明します。
ぼやける
ぼかしでは、画像を単純にぼかします。すべてのオブジェクトとその形状を正しく認識できれば、画像はより鮮明またはより詳細に見えます。例えば。目、耳、鼻、唇、額などを非常にはっきりと識別できる場合、顔のある画像ははっきりと見えます。オブジェクトのこの形状は、そのエッジによるものです。したがって、ぼかしでは、エッジコンテンツを単純に減らし、ある色から別の色への遷移を非常にスムーズにします。
ぼかしとズーム。
画像をズームすると、ぼやけた画像が表示される場合があります。ピクセル複製を使用して画像をズームし、ズーム率を上げると、ぼやけた画像が表示されました。この画像も細部が少ないですが、本当のぼかしではありません。
ズームでは、画像に新しいピクセルを追加します。これにより、画像の全体的なピクセル数が増加しますが、ぼかしでは、通常の画像とぼやけた画像のピクセル数は同じままです。
ぼやけた画像の一般的な例。

フィルタの種類。
ぼかしはさまざまな方法で実現できます。ぼかしを実行するために使用される一般的なタイプのフィルターは次のとおりです。
平均フィルター
加重平均フィルター
ガウスフィルター
これらの3つのうち、最初の2つについてはここで説明し、ガウス分布については今後のチュートリアルで後で説明します。
平均フィルター。
平均フィルターは、ボックスフィルターおよび平均フィルターとも呼ばれます。平均フィルターには次の特性があります。
それは奇妙な順序でなければなりません
すべての要素の合計は1でなければなりません
すべての要素が同じである必要があります
このルールに従うと、3x3のマスクになります。次の結果が得られます。
| 1/9 | 1/9 | 1/9 |
| 1/9 | 1/9 | 1/9 |
| 1/9 | 1/9 | 1/9 |
これは3x3マスクなので、9個のセルがあることを意味します。すべての要素の合計が1に等しくなければならないという条件は、各値を9で割ることによって達成できます。
1/9 + 1/9 + 1/9 + 1/9 + 1/9 + 1/9 + 1/9 + 1/9 + 1/9 = 9/9 = 1
画像上の3x3のマスクの結果を以下に示します。
元の画像:

ぼやけた画像

結果はあまり明確ではないかもしれません。ぼかしを増やしましょう。マスクのサイズを大きくすると、ぼかしを大きくすることができます。マスクのサイズが大きいほど、ぼやけが大きくなります。マスクが大きいほど、より多くのピクセルが処理され、1つのスムーズな遷移が定義されるためです。
画像上の5x5のマスクの結果を以下に示します。
元の画像:

ぼやけた画像:

同様に、マスクを増やすと、ぼやけが大きくなり、結果を以下に示します。
画像上の7x7のマスクの結果を以下に示します。
元の画像:

ぼやけた画像:

画像上の9x9のマスクの結果を以下に示します。
元の画像:

ぼやけた画像:

画像上の11x11のマスクの結果を以下に示します。
元の画像:

ぼやけた画像:

加重平均フィルター。
加重平均フィルターでは、中心値により多くの重みを与えました。そのため、中心の寄与は残りの値よりも大きくなります。加重平均フィルタリングにより、実際にぼかしを制御できます。
加重平均フィルターのプロパティは次のとおりです。
それは奇妙な順序でなければなりません
すべての要素の合計は1でなければなりません
中央の要素の重量は、他のすべての要素よりも大きくする必要があります
フィルター1
| 1 | 1 | 1 |
| 1 | 2 | 1 |
| 1 | 1 | 1 |
(1と3)の2つのプロパティが満たされます。しかし、プロパティ2は満たされていません。したがって、それを満たすために、フィルター全体を単純に10で除算するか、1/10を掛けます。
フィルター2
| 1 | 1 | 1 |
| 1 | 10 | 1 |
| 1 | 1 | 1 |
除数= 18。
マスク入門のチュートリアルでは、エッジ検出について簡単に説明しました。ここでは、エッジ検出について正式に説明します。
エッジとは何ですか。
画像の不連続性の急激な変化をエッジと呼ぶこともできます。画像の重要な遷移はエッジと呼ばれます。
エッジの種類。
一般的にエッジには次の3つのタイプがあります。
水平エッジ
垂直エッジ
対角エッジ
エッジを検出する理由。
画像の形状情報のほとんどはエッジで囲まれています。したがって、最初に画像内のこれらのエッジを検出し、これらのフィルターを使用してから、エッジを含む画像の領域を強調することにより、画像の鮮明さが増し、画像がより鮮明になります。
これは、今後のチュートリアルで説明するエッジ検出用のマスクの一部です。
プレウィット演算子
Sobelオペレーター
ロビンソンコンパスマスク
クリッシュコンパスマスク
ラプラシアン演算子。
上記のすべてのフィルターは、線形フィルターまたは平滑化フィルターです。
プレウィット演算子
Prewitt演算子は、エッジを水平方向および垂直方向に検出するために使用されます。
Sobelオペレーター
ソーベル演算子は、プレウィット演算子と非常によく似ています。これは派生マスクでもあり、エッジ検出に使用されます。また、水平方向と垂直方向の両方のエッジを計算します。
ロビンソンコンパスマスク
この演算子は、方向マスクとも呼ばれます。この演算子では、1つのマスクを取得し、それを8つのコンパスの主方向すべてに回転させて、各方向のエッジを計算します。
キルシュコンパスマスク
キルシュコンパスマスクは、エッジを見つけるために使用される派生マスクでもあります。キルシュマスクは、すべての方向のエッジの計算にも使用されます。
ラプラシアン演算子。
ラプラシアン演算子は、画像内のエッジを見つけるために使用される微分演算子でもあります。ラプラシアンは二次微分マスクです。さらに、正のラプラシアンと負のラプラシアンに分けることができます。
これらのマスクはすべてエッジを見つけます。水平方向と垂直方向に見つけるものもあれば、一方向にのみ見つけるものもあれば、すべての方向に見つけるものもあります。この後の次の概念は、画像からエッジが抽出されたときに実行できるシャープ化です。
研ぎ:
シャープネスはブラーと反対です。ぼかしではエッジコンテンツを減らし、シャープネンではエッジコンテンツを増やします。したがって、画像のエッジコンテンツを増やすには、最初にエッジを見つける必要があります。
エッジは、任意の演算子を使用して、上記の任意の方法のいずれかで見つけることができます。エッジを見つけたら、それらのエッジを画像に追加します。これにより、画像のエッジが増え、シャープに見えます。
これは、画像をシャープにする1つの方法です。
シャープ画像を以下に示します。
元の画像

画像をシャープにする

Prewitt演算子は、画像のエッジ検出に使用されます。2種類のエッジを検出します。
水平エッジ
垂直エッジ
エッジは、画像の対応するピクセル強度間の差を使用して計算されます。エッジ検出に使用されるすべてのマスクは、微分マスクとも呼ばれます。この一連のチュートリアルで以前に何度も述べたように、画像は信号でもあるため、信号の変化は微分を使用してのみ計算できます。そのため、これらの演算子は微分演算子または微分マスクとも呼ばれます。
すべての派生マスクには、次のプロパティが必要です。
反対のサインがマスクに存在する必要があります。
マスクの合計はゼロに等しくなければなりません。
重みが大きいほど、エッジ検出が多くなります。
Prewitt演算子は、水平方向のエッジを検出するためのマスクと、垂直方向のエッジを検出するためのマスクの2つを提供します。
垂直方向:
| -1 | 0 | 1 |
| -1 | 0 | 1 |
| -1 | 0 | 1 |
マスクの上は垂直方向のエッジを見つけます。これは、垂直方向のゼロ列が原因です。このマスクを画像上で畳み込むと、画像の垂直方向のエッジが得られます。
使い方:
このマスクを画像に適用すると、垂直方向のエッジが目立ちます。これは、一次導関数のように機能し、エッジ領域のピクセル強度の差を計算します。中央の列はゼロであるため、画像の元の値は含まれませんが、そのエッジの周りの左右のピクセル値の差が計算されます。これにより、エッジ強度が増加し、元の画像に比べて強調されます。
水平方向:
| -1 | -1 | -1 |
| 0 | 0 | 0 |
| 1 | 1 | 1 |
マスクの上は水平方向のエッジを見つけます。これは、ゼロ列が水平方向にあるためです。このマスクを画像に畳み込むと、画像の水平方向のエッジが目立つようになります。
使い方:
このマスクは、画像の水平方向のエッジを目立たせます。また、上記のマスクの原理に基づいて機能し、特定のエッジのピクセル強度間の差を計算します。マスクの中央の行はゼロで構成されているため、画像のエッジの元の値は含まれませんが、特定のエッジのピクセル強度の上下の差が計算されます。したがって、強度の突然の変化を増やし、エッジをより見やすくします。上記の両方のマスクは、派生マスクの原則に従います。両方のマスクには反対の符号があり、両方のマスクの合計はゼロに等しくなります。上記のマスクは両方とも標準化されており、それらの値を変更できないため、3番目の条件はこの演算子には適用されません。
次に、これらのマスクの動作を確認します。
サンプル画像:
以下は、2つのマスクの上に一度に1つずつ適用するサンプル画像です。

垂直マスクを適用した後:
上記のサンプル画像に垂直マスクを適用すると、次の画像が得られます。この画像には垂直エッジが含まれています。横端の画像と比較することで、より正確に判断できます。

水平マスクを適用した後:
上記のサンプル画像に水平マスクを適用すると、次の画像が得られます。

比較:
垂直マスクを適用した最初の画像でわかるように、すべての垂直エッジが元の画像よりも見やすくなっています。同様に、2番目の画像では、水平マスクを適用した結果、すべての水平エッジが表示されています。このようにして、画像から水平エッジと垂直エッジの両方を検出できることがわかります。
ソーベル演算子は、プレウィット演算子と非常によく似ています。これは派生マスクでもあり、エッジ検出に使用されます。Prewitt演算子と同様に、sobel演算子も、画像内の2種類のエッジを検出するために使用されます。
垂直方向
水平方向
Prewitt演算子との違い:
主な違いは、ソーベル演算子ではマスクの係数が固定されておらず、微分マスクのプロパティに違反しない限り、要件に応じて調整できることです。
以下は、Sobel演算子の垂直マスクです。
| -1 | 0 | 1 |
| -2 | 0 | 2 |
| -1 | 0 | 1 |
このマスクは、プレウィット演算子の垂直マスクとまったく同じように機能します。1列目と3列目の中央に「2」と「-2」の値があるという違いが1つだけあります。このマスクを画像に適用すると、垂直方向のエッジが強調表示されます。
使い方:
このマスクを画像に適用すると、垂直方向のエッジが目立ちます。これは、一次導関数のように機能し、エッジ領域のピクセル強度の差を計算します。
中央の列はゼロであるため、画像の元の値は含まれませんが、そのエッジの周りの左右のピクセル値の差が計算されます。また、1列目と3列目の両方の中心値はそれぞれ2と-2です。
これにより、エッジ領域周辺のピクセル値により多くの重みが与えられます。これにより、エッジ強度が増加し、元の画像に比べて強調されます。
以下は、Sobel演算子の水平マスクです。
| -1 | -2 | -1 |
| 0 | 0 | 0 |
| 1 | 2 | 1 |
マスクの上は水平方向のエッジを見つけます。これは、ゼロ列が水平方向にあるためです。このマスクを画像に畳み込むと、画像の水平方向のエッジが目立つようになります。唯一の違いは、1行目と3行目の中心要素として2と-2があることです。
使い方:
このマスクは、画像の水平方向のエッジを目立たせます。また、上記のマスクの原理に基づいて機能し、特定のエッジのピクセル強度間の差を計算します。マスクの中央の行はゼロで構成されているため、画像のエッジの元の値は含まれませんが、特定のエッジのピクセル強度の上下の差が計算されます。したがって、強度の突然の変化を増やし、エッジをより見やすくします。
次に、これらのマスクの動作を確認します。
サンプル画像:
以下は、2つのマスクの上に一度に1つずつ適用するサンプル画像です。

垂直マスクを適用した後:
上記のサンプル画像に垂直マスクを適用すると、次の画像が得られます。

水平マスクを適用した後:
上記のサンプル画像に水平マスクを適用すると、次の画像が得られます。

比較:
垂直マスクを適用した最初の画像でわかるように、すべての垂直エッジが元の画像よりも見やすくなっています。同様に、2番目の画像では、水平マスクを適用した結果、すべての水平エッジが表示されています。
このようにして、画像から水平エッジと垂直エッジの両方を検出できることがわかります。また、ソーベル演算子の結果をプレウィット演算子と比較すると、ソーベル演算子は、プレウィット演算子と比較して、より多くのエッジを検出したり、エッジをより見やすくしたりすることがわかります。
これは、ソーベル演算子では、エッジ周辺のピクセル強度により多くの重みを割り当てているためです。
マスクにより多くの重みを適用する
これで、マスクにより多くの重みを適用すると、より多くのエッジが得られることもわかります。また、チュートリアルの冒頭で述べたように、ソーベル演算子には固定係数がないため、ここに別の加重演算子があります
| -1 | 0 | 1 |
| -5 | 0 | 5 |
| -1 | 0 | 1 |
このマスクの結果をPrewitt垂直マスクの結果と比較できる場合、マスクにより多くの重みを割り当てたという理由だけで、このマスクがPrewittのものと比較してより多くのエッジを与えることは明らかです。
ロビンソンコンパスマスクは、エッジ検出に使用される別のタイプの派生マスクです。この演算子は、方向マスクとも呼ばれます。この演算子では、1つのマスクを取得し、次の8つのコンパスの主な方向すべてに回転させます。
North
北西
West
南西
South
南東
East
北東
固定マスクはありません。あなたはどんなマスクでも取ることができます、そしてあなたはそれを回転させて上記のすべての方向のエッジを見つける必要があります。すべてのマスクは、ゼロ列の方向に基づいて回転します。
たとえば、北方向にある次のマスクを見て、それを回転させてすべての方向マスクを作成しましょう。
北方向マスク
| -1 | 0 | 1 |
| -2 | 0 | 2 |
| -1 | 0 | 1 |
北西方向マスク
| 0 | 1 | 2 |
| -1 | 0 | 1 |
| -2 | -1 | 0 |
西方向マスク
| 1 | 2 | 1 |
| 0 | 0 | 0 |
| -1 | -2 | -1 |
南西方向マスク
| 2 | 1 | 0 |
| 1 | 0 | -1 |
| 0 | -1 | -2 |
南方向マスク
| 1 | 0 | -1 |
| 2 | 0 | -2 |
| 1 | 0 | -1 |
南東方向マスク
| 0 | -1 | -2 |
| 1 | 0 | -1 |
| 2 | 1 | 0 |
東方向マスク
| -1 | -2 | -1 |
| 0 | 0 | 0 |
| 1 | 2 | 1 |
北東方向マスク
| -2 | -1 | 0 |
| -1 | 0 | 1 |
| 0 | 1 | 2 |
ご覧のとおり、すべての方向がゼロ方向に基づいてカバーされています。各マスクは、その方向のエッジを提供します。次に、上記のマスク全体の結果を見てみましょう。すべてのエッジを見つける必要があるサンプル画像があるとします。これが私たちのサンプル画像です:
サンプル画像:

次に、この画像に上記のすべてのフィルターを適用すると、次の結果が得られます。
北方向のエッジ

北西方向のエッジ

西方向エッジ

南西方向の端

南方向エッジ

サウスイーストディレクションエッジ

東方向エッジ

北東方向のエッジ

ご覧のとおり、上記のすべてのマスクを適用すると、すべての方向にエッジが得られます。結果も画像によって異なります。北東方向のエッジがない画像があるとすると、そのマスクは無効になります。
キルシュコンパスマスクは、エッジを見つけるために使用される派生マスクでもあります。これは、ロビンソンコンパスがコンパスの8方向すべてでエッジを見つけるようなものでもあります。ロビンソンマスクとキルシュコンパスマスクの唯一の違いは、キルシュには標準マスクがありますが、キルシュでは独自の要件に応じてマスクを変更することです。
キルシュコンパスマスクの助けを借りて、次の8つの方向にエッジを見つけることができます。
North
北西
West
南西
South
南東
East
北東
派生マスクのすべてのプロパティに従う標準マスクを取得し、それを回転させてエッジを見つけます。
たとえば、北方向にある次のマスクを見て、それを回転させてすべての方向マスクを作成しましょう。
北方向マスク
| -3 | -3 | 5 |
| -3 | 0 | 5 |
| -3 | -3 | 5 |
北西方向マスク
| -3 | 5 | 5 |
| -3 | 0 | 5 |
| -3 | -3 | -3 |
西方向マスク
| 5 | 5 | 5 |
| -3 | 0 | -3 |
| -3 | -3 | -3 |
南西方向マスク
| 5 | 5 | -3 |
| 5 | 0 | -3 |
| -3 | -3 | -3 |
南方向マスク
| 5 | -3 | -3 |
| 5 | 0 | -3 |
| 5 | -3 | -3 |
南東方向マスク
| -3 | -3 | -3 |
| 5 | 0 | -3 |
| 5 | 5 | -3 |
東方向マスク
| -3 | -3 | -3 |
| -3 | 0 | -3 |
| 5 | 5 | 5 |
北東方向マスク
| -3 | -3 | -3 |
| -3 | 0 | 5 |
| -3 | 5 | 5 |
ご覧のとおり、すべての方向がカバーされており、各マスクは独自の方向のエッジを提供します。これらのマスクの概念をよりよく理解できるように、実際の画像に適用します。すべてのエッジを見つける必要があるサンプル画像があるとします。これが私たちのサンプル画像です:
サンプル画像

次に、この画像に上記のすべてのフィルターを適用すると、次の結果が得られます。
北方向のエッジ

北西方向のエッジ

西方向エッジ

南西方向の端

南方向エッジ

サウスイーストディレクションエッジ

東方向エッジ

北東方向のエッジ

ご覧のとおり、上記のすべてのマスクを適用すると、すべての方向にエッジが得られます。結果も画像によって異なります。北東方向のエッジがない画像があるとすると、そのマスクは無効になります。
ラプラシアン演算子は、画像内のエッジを見つけるために使用される微分演算子でもあります。ラプラシアンと、プレウィット、ソーベル、ロビンソン、キルシュなどの他の演算子との主な違いは、これらはすべて1次微分マスクですが、ラプラシアンは2次微分マスクであるということです。このマスクには、さらに2つの分類があります。1つは正のラプラシアン演算子で、もう1つは負のラプラシアン演算子です。
ラプラシアンと他の演算子のもう1つの違いは、他の演算子とは異なり、ラプラシアンは特定の方向のエッジを取得しませんでしたが、次の分類でエッジを取得することです。
内向きのエッジ
外向きのエッジ
ラプラシアン演算子がどのように機能するかを見てみましょう。
正のラプラシアン演算子:
ポジティブラプラシアンには、マスクの中央要素が負で、マスクのコーナー要素がゼロである標準マスクがあります。
| 0 | 1 | 0 |
| 1 | -4 | 1 |
| 0 | 1 | 0 |
正のラプラシアン演算子は、画像の外側のエッジを取り除くために使用されます。
負のラプラシアン演算子:
負のラプラシアン演算子には、中央の要素が正である標準マスクもあります。コーナーのすべての要素はゼロで、マスクの残りのすべての要素は-1である必要があります。
| 0 | -1 | 0 |
| -1 | 4 | -1 |
| 0 | -1 | 0 |
負のラプラシアン演算子は、画像の内側のエッジを取り出すために使用されます
使い方:
ラプラシアンは微分演算子です。その使用法は、画像内のグレーレベルの不連続性を強調表示し、グレーレベルがゆっくりと変化する領域を強調しないようにします。結果として、この操作により、暗い背景に灰色がかったエッジラインやその他の不連続性を持つ画像が生成されます。これにより、画像に内側と外側のエッジが生成されます
重要なのは、これらのフィルターを画像に適用する方法です。同じ画像に正と負の両方のラプラシアン演算子を適用することはできないことに注意してください。1つだけ適用する必要がありますが、覚えておくべきことは、画像に正のラプラシアン演算子を適用すると、元の画像から結果の画像を減算して、シャープな画像を取得することです。同様に、負のラプラシアン演算子を適用すると、結果の画像を元の画像に追加して、シャープな画像を取得する必要があります。
これらのフィルターを画像に適用して、画像から内側と外側のエッジがどのように取得されるかを見てみましょう。次のサンプル画像があるとします。
サンプル画像

After applying Positive Laplacian Operator:
正のラプラシアン演算子を適用すると、次の画像が得られます。

After applying Negative Laplacian Operator:
負のラプラシアン演算子を適用すると、次の画像が得られます。

多くの分野で画像を扱ってきました。現在、周波数領域で信号(画像)を処理しています。このフーリエ級数と周波数領域は純粋に数学であるため、その数学の部分を最小限に抑え、DIPでの使用にさらに焦点を当てます。
周波数領域分析
これまで、信号を分析したすべてのドメインで、時間に関して分析します。しかし、周波数領域では、時間に関してではなく、周波数に関して信号を分析します。
空間領域と周波数領域の違い。
空間領域では、画像をそのまま扱います。画像のピクセルの値は、シーンに対して変化します。一方、周波数領域では、空間領域でピクセル値が変化する速度を扱います。
簡単にするために、このようにしましょう。
Spatial domain

単純な空間領域では、画像行列を直接処理します。一方、周波数領域では、このような画像を扱います。
周波数領域
まず、画像を度数分布に変換します。次に、ブラックボックスシステムは実行する必要のある処理を実行します。この場合のブラックボックスの出力は画像ではなく、変換です。逆変換を実行した後、画像に変換され、空間領域で表示されます。
それは絵で見ることができます
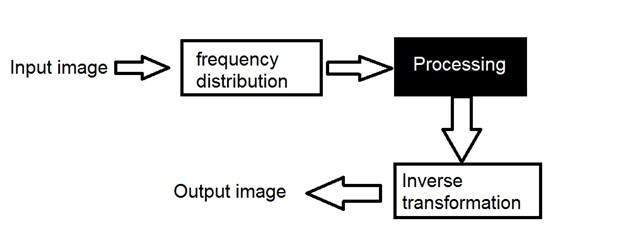
ここでは、変換という言葉を使用しました。それは実際にはどういう意味ですか?
変換。
信号は、変換と呼ばれる数学演算子を使用して、時間領域から周波数領域に変換できます。これを行う多くの種類の変換があります。それらのいくつかを以下に示します。
フーリエ級数
フーリエ変換
ラプラス変換
Z変換
これらすべてのうち、次のチュートリアルでは、フーリエ級数とフーリエ変換について詳しく説明します。
周波数成分
空間領域の任意の画像は、周波数領域で表すことができます。しかし、この周波数は実際にはどういう意味ですか。
周波数成分を2つの主要な成分に分けます。
High frequency components
高周波成分は画像のエッジに対応します。
Low frequency components
画像の低周波成分は滑らかな領域に対応します。
周波数領域分析の最後のチュートリアルでは、フーリエ級数とフーリエ変換を使用して信号を周波数領域に変換する方法について説明しました。
Fourier
フーリエは1822年に数学者でした。彼は信号を周波数領域に変換するためにフーリエ級数とフーリエ変換を与えます。
Fourier Series
フーリエ級数は、周期信号を特定の重みで乗算すると、正弦と余弦の合計に表すことができると単純に述べています。さらに、周期信号は、次の特性を持つさらなる信号に分解できると述べています。
信号はサインとコサインです
信号は互いに高調波です
それは絵で見ることができます
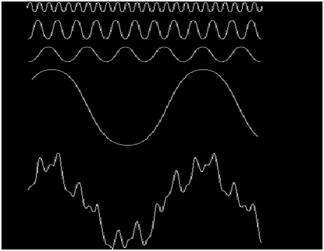
上記の信号では、最後の信号は実際には上記のすべての信号の合計です。これがフーリエのアイデアでした。
それがどのように計算されるか。
周波数領域で見たように、周波数領域で画像を処理するには、最初にを使用して画像を周波数領域に変換する必要があり、出力の逆数を取得して空間領域に戻す必要があります。そのため、フーリエ級数とフーリエ変換の両方に2つの式があります。1つは変換用で、もう1つはそれを空間ドメインに変換し直します。
フーリエ級数
フーリエ級数はこの式で表すことができます。
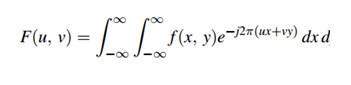
逆数はこの式で計算できます。
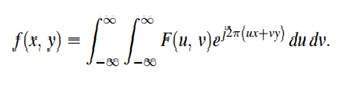
フーリエ変換
フーリエ変換は、曲線下面積が有限である非周期信号も、特定の重みを掛けた後、正弦と余弦の積分に表すことができると単純に述べています。
フーリエ変換には、画像圧縮(JPEG圧縮など)、フィルター処理、画像分析など、さまざまな用途があります。
フーリエ級数と変換の違い
フーリエ級数とフーリエ変換はどちらもフーリエで与えられますが、両者の違いは、フーリエ級数が周期信号に適用され、フーリエ変換が非周期信号に適用されることです。
どちらが画像に適用されますか。
ここで問題となるのは、画像、フーリエ級数、またはフーリエ変換のどちらに適用されるかです。さて、この質問への答えは、画像が何であるかという事実にあります。画像は非周期的です。また、画像は非周期的であるため、フーリエ変換を使用して画像を周波数領域に変換します。
離散フーリエ変換。
私たちは画像を扱っており、デジタル画像を実際に扱っているので、デジタル画像については離散フーリエ変換に取り組んでいます

正弦波の上記のフーリエ項を考えてみましょう。それは3つのことを含みます。
空間周波数
Magnitude
Phase
空間周波数は、画像の明るさに直接関係します。正弦波の大きさは、コントラストに直接関係します。コントラストは、最大ピクセル強度と最小ピクセル強度の差です。フェーズには色情報が含まれています。
2次元離散フーリエ変換の式を以下に示します。
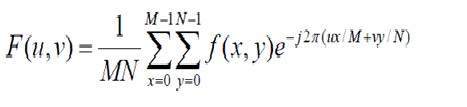
離散フーリエ変換は実際にはサンプリングされたフーリエ変換であるため、画像を表すいくつかのサンプルが含まれています。上記の式で、f(x、y)は画像を示し、F(u、v)は離散フーリエ変換を示します。2次元逆離散フーリエ変換の式を以下に示します。
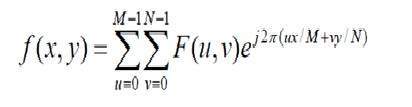
逆離散フーリエ変換は、フーリエ変換を画像に変換します
この信号を考えてみましょう。
次に、FFTマグニチュードスペクトルを計算し、次にシフトされたFFTマグニチュードスペクトルを計算し、そのシフトされたスペクトルの対数を取得する画像を表示します。
元の画像

フーリエ変換の大きさのスペクトル

シフトフーリエ変換

シフトされたマグニチュードスペクトル

前回のチュートリアルでは、周波数領域の画像について説明しました。このチュートリアルでは、周波数領域と画像(空間領域)の関係を定義します。
例えば:
この例を考えてみましょう。

周波数領域の同じ画像は、として表すことができます。

ここで、画像または空間ドメインと周波数ドメインの関係は何ですか。この関係は、畳み込み定理と呼ばれる定理によって説明できます。
畳み込み定理
空間領域と周波数領域の関係は、畳み込み定理によって確立できます。
畳み込み定理は次のように表すことができます。
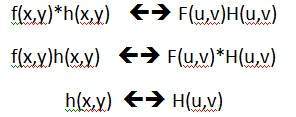
空間領域での畳み込みは周波数領域でのフィルタリングに等しく、その逆も同様であると言えます。
周波数領域でのフィルタリングは、次のように表すことができます。

The steps in filtering are given below.
最初のステップでは、空間領域で画像を前処理する必要があります。つまり、コントラストまたは明るさを上げることを意味します。
次に、画像の離散フーリエ変換を行います
次に、離散フーリエ変換をコーナーから中央に配置するため、離散フーリエ変換を中央に配置します。
次に、フィルタリングを適用します。つまり、フーリエ変換にフィルター関数を乗算します。
次に、DFTを中央からコーナーに再びシフトします
最後のステップは、結果を周波数領域から空間領域に戻すために、逆離散フーリエ変換を行うことです。
また、後処理のこのステップは、前処理と同様にオプションであり、画像の外観を向上させるだけです。
フィルター
周波数領域でのフィルターの概念は、畳み込みでのマスクの概念と同じです。
画像を周波数領域に変換した後、フィルタリングプロセスでいくつかのフィルタを適用して、画像に対してさまざまな種類の処理を実行します。処理には、画像のぼかし、画像の鮮明化などが含まれます。
これらの目的のための一般的なタイプのフィルターは次のとおりです。
理想的なハイパスフィルター
理想的なローパスフィルター
ガウスハイパスフィルター
ガウスローパスフィルター
次のチュートリアルでは、フィルターについて詳しく説明します。
前回のチュートリアルでは、フィルターについて簡単に説明します。このチュートリアルでは、それらについて徹底的に説明します。議論する前に、まずマスクについて話しましょう。マスクの概念は、畳み込みとマスクのチュートリアルで説明されています。
ぼかしマスクと派生マスク。
ぼかしマスクと微分マスクの比較を行います。
ぼかしマスク:
ぼかしマスクには、次の特性があります。
ぼかしマスクの値はすべて正です
すべての値の合計は1に等しい
ぼかしマスクを使用することにより、エッジコンテンツが削減されます
マスクのサイズが大きくなると、よりスムージング効果が発生します
派生マスク:
微分マスクには次の特性があります。
微分マスクには、正の値と負の値があります
微分マスクのすべての値の合計はゼロに等しい
エッジコンテンツは微分マスクによって増加します
マスクのサイズが大きくなると、より多くのエッジコンテンツが増加します
ハイパスフィルターとローパスフィルターを使用したブラーマスクと微分マスクの関係。
ハイパスフィルターとローパスフィルターを使用したブラーマスクと微分マスクの関係は、次のように簡単に定義できます。
ぼかしマスクはローパスフィルターとも呼ばれます
微分マスクはハイパスフィルターとも呼ばれます
ハイパス周波数成分とローパス周波数成分
ハイパス周波数成分はエッジを示し、ローパス周波数成分は滑らかな領域を示します。
理想的なローパスおよび理想的なハイパスフィルター
これはローパスフィルターの一般的な例です。
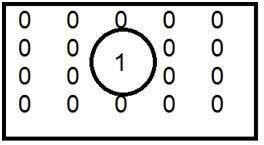
1つを内側に配置し、0を外側に配置すると、画像がぼやけます。ここで、サイズを1に増やすと、ぼかしが増加し、エッジの内容が減少します。
これは、ハイパスフィルターの一般的な例です。
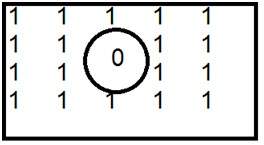
0を内側に配置すると、エッジが取得され、スケッチ画像が得られます。周波数領域での理想的なローパスフィルターを以下に示します。

理想的なローパスフィルターは、次のようにグラフィカルに表すことができます。
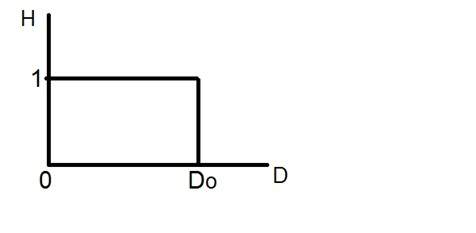
次に、このフィルターを実際の画像に適用して、何が得られたかを見てみましょう。
サンプル画像。

周波数領域の画像

この画像にフィルターを適用する

結果の画像

同様に、理想的なハイパスフィルターを画像に適用できます。しかし、明らかに結果は異なります。ローパスはエッジのあるコンテンツを減らし、ハイパスはそれを増やします。
ガウスローパスおよびガウスハイパスフィルター
ガウスローパスおよびガウスハイパスフィルターは、理想的なローパスおよびハイパスフィルターで発生する問題を最小限に抑えます。
この問題は、リンギング効果として知られています。これは、あるポイントである色から別の色への遷移を正確に定義できないため、そのポイントでリンギング効果が現れるためです。
このグラフを見てください。
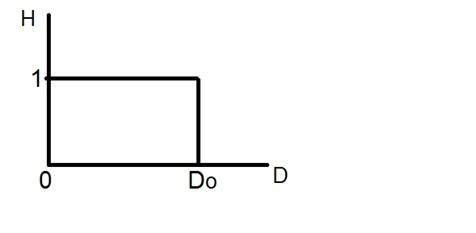
これは理想的なローパスフィルターの表現です。Doの正確なポイントでは、値が0または1になるかどうかはわかりません。そのため、そのポイントでリンギング効果が現れます。
そのため、理想的なローパスと理想的なハイパスフィルターが現れる影響を減らすために、次のガウスローパスフィルターとガウスハイパスフィルターが導入されています。
ガウスローパスフィルター
フィルタリングとローパスの概念は同じですが、遷移のみが異なり、よりスムーズになります。
ガウスローパスフィルターは、次のように表すことができます。

滑らかな曲線遷移に注意してください。これにより、各ポイントでDoの値を正確に定義できます。
ガウスハイパスフィルター
ガウスハイパスフィルターは、理想的なハイパスフィルターと同じ概念ですが、理想的なフィルターと比較して、遷移がよりスムーズになります。
このチュートリアルでは、色空間について説明します。
色空間とは何ですか?
色空間はさまざまなタイプのカラーモードであり、画像処理、信号、およびさまざまな目的のシステムで使用されます。一般的な色空間のいくつかは次のとおりです。
RGB
CMY’K
Y’UV
YIQ
Y’CbCr
HSV
RGB
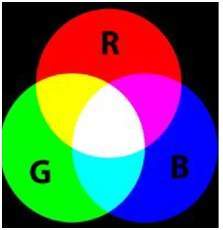
RGBは最も広く使用されている色空間であり、過去のチュートリアルですでに説明しました。RGBは赤、緑、青の略です。
RGBモデルが述べているように、各カラー画像は実際には3つの異なる画像で構成されています。赤の画像、青の画像、黒の画像。通常のグレースケール画像は1つのマトリックスでのみ定義できますが、カラー画像は実際には3つの異なるマトリックスで構成されています。
1つのカラー画像マトリックス=赤のマトリックス+青のマトリックス+緑のマトリックス
これは、以下のこの例で最もよくわかります。
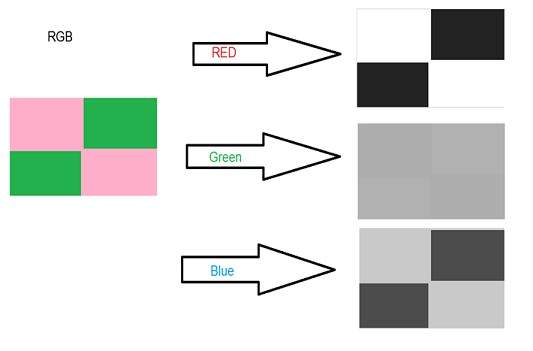
RGBのアプリケーション
RGBモデルの一般的なアプリケーションは次のとおりです。
ブラウン管(CRT)
液晶ディスプレイ(LCD)
プラズマディスプレイまたはテレビなどのLEDディスプレイ
計算モニターまたは大規模画面
CMYK

RGBからCMYへの変換
RGBからCMYへの変換は、この方法を使用して行われます。
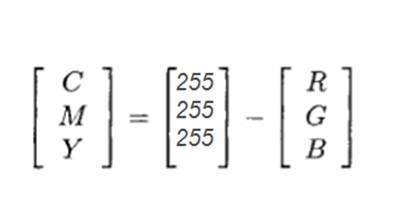
カラー画像があると考えてください。つまり、赤、緑、青の3つの異なる配列があります。これをCMYに変換したい場合は、次のことを行う必要があります。レベルの最大数– 1で減算する必要があります。各行列が減算され、それぞれのCMY行列に結果が入力されます。
Y'UV
Y'UVは、1つの輝度(Y ')と2つのクロミナンス(UV)コンポーネントの観点から色空間を定義します。Y'UVカラーモデルは、次のコンポジットカラービデオ規格で使用されています。
NTSC(全国テレビシステム委員会)
PAL(相交互線)
SECAM(Sequential couleur amemoire、フランス語で「記憶のあるシーケンシャルカラー」)

Y'CbCr
Y'CbCrカラーモデルにはY 'が含まれ、輝度成分とcbおよびcrは青の差と赤の差の彩度成分です。
絶対的な色空間ではありません。主にデジタルシステムに使用されます
その一般的なアプリケーションには、JPEGおよびMPEG圧縮が含まれます。
Y'UVはY'CbCrの用語としてよく使用されますが、まったく異なる形式です。これら2つの主な違いは、前者はアナログであり、後者はデジタルであるということです。

画像圧縮の最後のチュートリアルでは、圧縮に使用されるいくつかの手法について説明します。
一部のデータは最終的に非可逆圧縮であるため、非可逆圧縮であるJPEG圧縮について説明します。
まず、画像圧縮とは何かについて説明しましょう。
画像圧縮
画像圧縮は、デジタル画像のデータ圧縮の方法です。
画像圧縮の主な目的は次のとおりです。
効率的な形式でデータを保存する
効率的な形式でデータを送信する
画像圧縮は不可逆または可逆である可能性があります。
JPEG圧縮
JPEGはJointPhotography ExpertsGroupの略です。これは、画像圧縮における最初の国際標準です。今日広く使われています。損失があるだけでなく、損失がない可能性があります。ただし、本日ここで説明する手法は、非可逆圧縮手法です。
jpeg圧縮の仕組み:
最初のステップは、画像を8x8のサイズのブロックに分割することです。

記録のために、この8x8画像に次の値が含まれているとします。
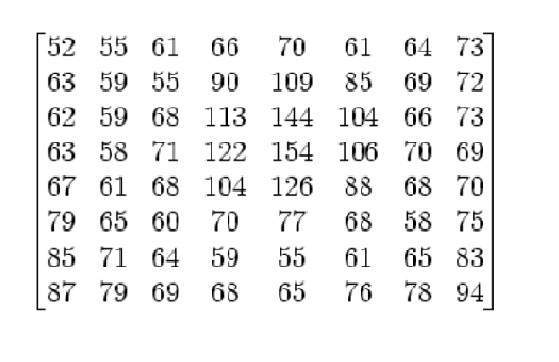
ピクセル強度の範囲は0から255になりました。範囲を-128から127に変更します。
各ピクセル値から128を引くと、-128から127までのピクセル値が得られます。各ピクセル値から128を引くと、次の結果が得られます。

次に、この式を使用して計算します。
これから得られる結果は、たとえばA(j、k)行列に格納されます。
JPEG圧縮の計算に使用される標準行列があります。これは、輝度行列と呼ばれる行列によって与えられます。
このマトリックスを以下に示します。
次の式を適用する

応募してこの結果が出ました。

次に、ZIG-ZAG移動であるJPEG圧縮で行われる実際のトリックを実行します。上記のマトリックスのジグザグシーケンスを以下に示します。前方にすべてのゼロが見つかるまで、ジグザグを実行する必要があります。したがって、画像が圧縮されます。
Summarizing JPEG compression
最初のステップは、画像をY'CbCrに変換し、Y 'チャネルを選択して8 x8ブロックに分割することです。次に、最初のブロックから始めて、-128から127の範囲をマップします。その後、行列の離散フーリエ変換を見つける必要があります。この結果は量子化する必要があります。最後のステップは、ジグザグ方式でエンコーディングを適用し、すべてゼロになるまでそれを行うことです。
この1次元配列を保存すれば、完了です。
Note. You have to repeat this procedure for all the block of 8 x 8.
光学式文字認識は通常、OCRと略されます。これには、手書きのタイプライターテキストのスキャン画像の機械テキストへの機械的および電気的変換が含まれます。印刷されたテキストをデジタル化して電子的に検索し、よりコンパクトに保存し、オンラインで表示し、機械翻訳、テキスト読み上げ、テキストマイニングなどの機械プロセスで使用できるようにするのが一般的な方法です。
近年、OCR(光学式文字認識)テクノロジーが業界全体に適用され、ドキュメント管理プロセスに革命をもたらしました。OCRにより、スキャンされたドキュメントは単なる画像ファイル以上のものになり、コンピューターで認識されるテキストコンテンツを含む完全に検索可能なドキュメントになります。OCRの助けを借りて、人々は電子データベースに入力するときに重要なドキュメントを手動で再入力する必要がなくなりました。代わりに、OCRは関連情報を抽出し、自動的に入力します。その結果、より短時間で正確で効率的な情報処理が実現します。
光学式文字認識には複数の研究分野がありますが、最も一般的な分野は次のとおりです。
Banking:
彼のOCRの使用法は、分野によって異なります。広く知られているアプリケーションの1つは銀行業務で、OCRを使用して人間の関与なしに小切手を処理します。小切手は機械に挿入でき、その書き込みは即座にスキャンされ、正しい金額が送金されます。このテクノロジーは、印刷された小切手にはほぼ完成しており、手書きの小切手にもかなり正確ですが、手動で確認する必要がある場合もあります。全体として、これにより多くの銀行の待ち時間が短縮されます。
Blind and visually impaired persons:
OCRの背後にある研究の開始における主要な要因の1つは、科学者が視覚障害者に本を大声で読むことができるコンピューターまたはデバイスを作りたいということです。この研究で、科学者は、ドキュメントスキャナーとして最も一般的に知られているフラットベッドスキャナーを作成しました。
Legal department:
法務業界では、紙の文書をデジタル化するという大きな動きもあります。スペースを節約し、紙のファイルの箱をふるいにかける必要をなくすために、ドキュメントがスキャンされ、コンピューターデータベースに入力されています。OCRは、ドキュメントをテキスト検索可能にすることでプロセスをさらに簡素化し、データベース内でドキュメントを見つけて操作しやすくします。法律専門家は、電子形式の膨大なドキュメントライブラリにすばやく簡単にアクセスできるようになりました。これらのライブラリは、いくつかのキーワードを入力するだけで見つけることができます。
Retail Industry:
バーコード認識技術もOCRに関連しています。このテクノロジーは、日常の使用に使用されています。
Other Uses:
OCRは、教育、金融、政府機関など、他の多くの分野で広く使用されています。OCRは無数のテキストをオンラインで利用できるようにし、学生のお金を節約し、知識を共有できるようにしました。請求書イメージングアプリケーションは、財務記録を追跡し、支払いのバックログが蓄積するのを防ぐために、多くの企業で使用されています。政府機関や独立した組織では、OCRは他のプロセスの中でも特にデータの収集と分析を簡素化します。テクノロジの開発が進むにつれて、手書き認識の使用の増加など、OCRテクノロジのアプリケーションがますます増えています。
コンピュータビジョン
コンピュータビジョンは、コンピュータソフトウェアとハードウェアを使用して人間の視覚をモデル化および複製することに関係しています。正式には、コンピュータビジョンを定義すると、コンピュータビジョンは、シーンに存在する構造のプロパティの観点から、2D画像から3Dシーンを再構築、中断、および理解する方法を研究する分野であるという定義になります。
人間の視覚システムの動作を理解し、刺激するためには、以下の分野の知識が必要です。
コンピュータサイエンス
電気工学
Mathematics
Physiology
Biology
認知科学
コンピュータビジョン階層:
コンピュータビジョンは、次の3つの基本的なカテゴリに分類されます。
低レベルのビジョン:特徴抽出のためのプロセスイメージが含まれます。
中級レベルのビジョン:オブジェクト認識と3Dシーンの解釈が含まれます
高レベルのビジョン:アクティビティ、意図、行動などのシーンの概念的な説明が含まれます。
関連分野:
コンピュータビジョンは、次の分野と大幅に重複しています。
画像処理:画像操作に焦点を当てています。
パターン認識:パターンを分類するためのさまざまな手法を研究します。
写真測量:画像から正確な測定値を取得することに関係しています。
コンピュータビジョン対画像処理:
画像処理は、画像から画像への変換を研究します。画像処理の入力と出力は両方とも画像です。
コンピュータビジョンは、画像から物理的なオブジェクトの明示的で意味のある記述を構築することです。コンピュータビジョンの出力は、3Dシーンの構造の説明または解釈です。
アプリケーション例:
Robotics
Medicine
Security
Transportation
産業自動化
ロボット工学アプリケーション:
ローカリゼーション-ロボットの位置を自動的に決定します
Navigation
障害物の回避
組立(ペグインホール、溶接、塗装)
操作(例:PUMAロボットマニピュレーター)
ヒューマンロボットインタラクション(HRI):人々と対話してサービスを提供するインテリジェントロボティクス
医学アプリケーション:
分類と検出(例:病変または細胞の分類と腫瘍の検出)
2D / 3Dセグメンテーション
3D人間の臓器の再構成(MRIまたは超音波)
視覚誘導ロボット手術
産業オートメーションアプリケーション:
産業検査(欠陥検出)
Assembly
バーコードとパッケージラベルの読み取り
オブジェクトの並べ替え
文書の理解(例:OCR)
セキュリティアプリケーション:
バイオメトリクス(虹彩、指紋、顔認識)
監視-特定の疑わしい活動または行動を検出する
輸送アプリケーション:
自動運転車
安全性、例えば、ドライバーの警戒監視
コンピューターグラフィックス
コンピュータグラフィックスは、コンピュータを使用して作成されたグラフィックスであり、特に特殊なグラフィックスハードウェアおよびソフトウェアの助けを借りてコンピュータによって画像データを表現したものです。正式には、コンピュータグラフィックスは、幾何学的オブジェクト(モデリング)とその画像(レンダリング)の作成、操作、および保存であると言えます。
コンピュータグラフィックスハードウェアの出現により開発されたコンピュータグラフィックスの分野。今日、コンピュータグラフィックスはほとんどすべての分野で使用されています。データを視覚化するために、多くの強力なツールが開発されています。コンピュータグラフィックスの分野は、企業がビデオゲームで使用し始めたときに人気が高まっています。今日、それは数十億ドルの産業であり、コンピュータグラフィックス開発の背後にある主要な原動力です。一般的なアプリケーション分野は次のとおりです。
コンピューター支援設計(CAD)
プレゼンテーショングラフィックス
3Dアニメーション
教育と訓練
グラフィカルユーザーインターフェイス
コンピューター支援設計:
建物、自動車、航空機、その他多くの製品の設計に使用されます
バーチャルリアリティシステムを作成するために使用します。
プレゼンテーショングラフィックス:
一般的に、財務、統計データを要約するために使用されます
スライドの生成に使用
3Dアニメーション:
Pixar、DresmsWorksなどの企業によって映画業界で頻繁に使用されています
ゲームや映画に特殊効果を追加します。
教育と訓練:
コンピューターで生成された物理システムのモデル
医療の視覚化
3D MRI
歯科および骨のスキャン
パイロット等の訓練用の刺激装置。
グラフィカルユーザーインターフェイス:
ボタン、アイコン、その他のコンポーネントなどのグラフィカルユーザーインターフェイスオブジェクトを作成するために使用されます