В любом случае, что такое связанный список? [Часть 1]
Информация повсюду вокруг нас.
В мире программного обеспечения способы, которые мы выбираем для организации нашей информации, - это половина дела. Но вот в чем дело: есть много способов решить проблему. А когда дело доходит до организации данных, есть множество инструментов, которые могут сработать. Уловка состоит в том, чтобы знать, какой инструмент лучше всего использовать.
Независимо от того, на каком языке мы начинаем кодировать, первое, с чем мы сталкиваемся, - это структуры данных , которые представляют собой различные способы организации данных; переменные , массивы , хэши и объекты - это все типы структур данных. Но это все еще только верхушка айсберга, когда дело касается структур данных; есть намного больше, некоторые из которых начинают казаться сверхсложными, чем больше вы о них слышите.
Одной из тех сложных вещей для меня всегда были связанные списки . Я знаю о связанных списках уже несколько лет, но никогда не могу держать их прямо в голове. Я думаю о них только тогда, когда готовлюсь к техническому собеседованию (или иногда в середине), и меня спрашивают о них. Я проведу небольшое исследование и думаю, что понимаю, о чем они, но через несколько недель я снова их забываю. Все это довольно неэффективно, и все это проистекает из того факта, что я знаю, что они существуют, но я их принципиально не понимаю ! Итак, пришло время изменить это и ответить на вопрос: что вообще такое связанный список?
Линейные структуры данных
Если мы действительно хотим понять основы связанных списков, важно поговорить о том, какой тип структуры данных они представляют.
Одной из характеристик связанных списков является то, что они представляют собой линейные структуры данных , а это означает, что существует последовательность и порядок их построения и обхода. Мы можем думать о линейной структуре данных как о игре в классики : чтобы добраться до конца списка, мы должны пройти все элементы в списке по порядку или последовательно . Однако линейные структуры противоположны нелинейным структурам. В нелинейных структурах данных элементы не должны располагаться по порядку, что означает, что мы можем перемещаться по структуре данных не последовательно .
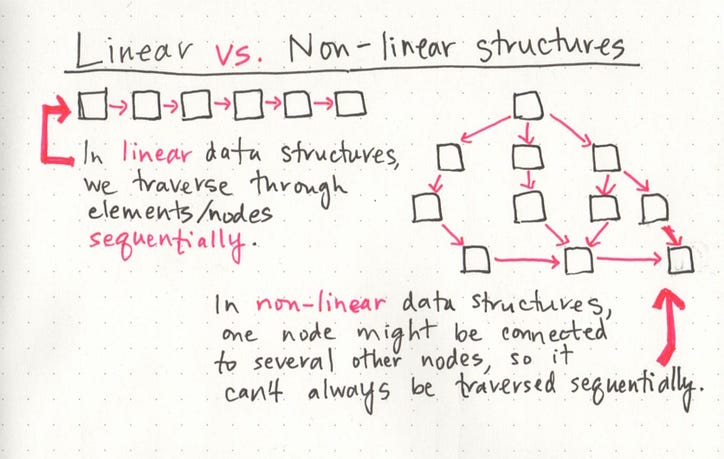
Возможно, мы не всегда осознаем это, но все мы ежедневно работаем с линейными и нелинейными структурами данных! Когда мы организуем наши данные в хэши (иногда называемые словарями ), мы реализуем нелинейную структуру данных. Деревья и графики также являются нелинейными структурами данных, которые мы проходим по-разному, но мы поговорим о них более подробно позже в этом году.
Точно так же, когда мы используем массивы в нашем коде, мы реализуем линейную структуру данных! Может быть полезно думать о массивах и связанных списках как о схожих способах упорядочивания данных. В обеих этих структурах важен порядок . Но чем отличаются массивы и связанные списки?
Управление памятью
Самым большим отличием массивов от связанных списков является способ использования памяти на наших машинах. Тем из нас, кто работает с динамически типизированными языками, такими как Ruby, JavaScript или Python, не нужно думать о том, сколько памяти использует массив, когда мы пишем наш код на повседневной основе, потому что есть несколько уровней абстракции, которые в конечном итоге нам совсем не нужно беспокоиться о выделении памяти.
Но это не значит, что выделения памяти не происходит! Абстракция - это не волшебство, это просто скрытие вещей, которые вам не нужно постоянно видеть или иметь дело. Даже если нам не нужно думать о распределении памяти при написании кода, если мы действительно хотим понять, что происходит в связном списке и что делает его мощным, мы должны перейти к элементарному уровню.
Мы уже узнали о двоичном коде и о том, как данные можно разбить на биты и байты. Как символы, числа, слова, предложения требуют байтов памяти для их представления, так и структуры данных.
Когда создается массив , ему требуется определенный объем памяти. Если бы у нас было 7 букв, которые нам нужно было сохранить в массиве, нам потребовалось бы 7 байтов памяти для представления этого массива. Но нам понадобится вся эта память в одном непрерывном блоке . Другими словами, нашему компьютеру нужно будет найти 7 свободных байтов памяти, один байт рядом с другим, все вместе, в одном месте.
С другой стороны, когда создается связанный список , ему не нужно 7 байт памяти в одном месте. Один байт мог где-то жить, а следующий байт мог вообще храниться в другом месте памяти! Связанные списки не обязательно должны занимать один блок памяти; вместо этого память, которую они используют, может быть разбросана повсюду .
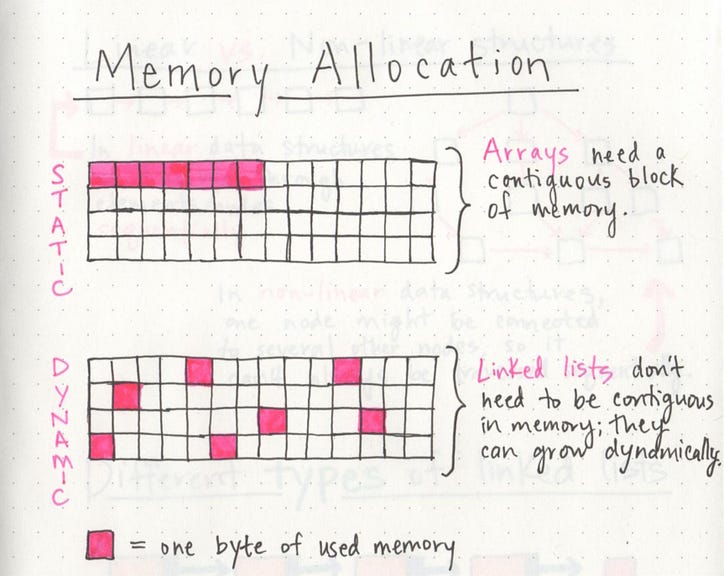
Основное различие между массивами и связанными списками состоит в том, что массивы представляют собой статические структуры данных , а связанные списки - это динамические структуры данных . Статическая структура данных требует, чтобы все ее ресурсы были выделены при создании структуры; это означает, что даже если структура должна была увеличиваться или уменьшаться в размере, а элементы должны были быть добавлены или удалены, она все равно всегда нуждается в заданном размере и объеме памяти. Если в статическую структуру данных нужно было добавить больше элементов и в ней недостаточно памяти, вам нужно будет скопировать данные этого массива, например, и воссоздать их с большим объемом памяти, чтобы вы могли добавлять элементы в Это.
С другой стороны, динамическая структура данных может сжиматься и увеличиваться в памяти. Ему не нужно выделять определенный объем памяти, чтобы существовать, его размер и форма могут изменяться, а также может изменяться объем памяти, который ему нужен.
К настоящему времени мы уже можем начать видеть некоторые важные различия между массивами и связанными списками. Но возникает вопрос: что позволяет связному списку иметь разбросанную повсюду память? Чтобы ответить на этот вопрос, нам нужно взглянуть на то, как структурирован связанный список.
Части связанного списка
Связанный список может быть маленьким или огромным, но независимо от размера составляющие его части на самом деле довольно просты. Связанный список состоит из серии узлов , которые являются элементами списка.
Начальной точкой списка является ссылка на первый узел, который называется головкой . Почти все связанные списки должны иметь заголовок, потому что это фактически единственная точка входа в список и все его элементы, и без него вы бы не знали, с чего начать! Конец списка - это не узел, а узел, указывающий на нуль или пустое значение.
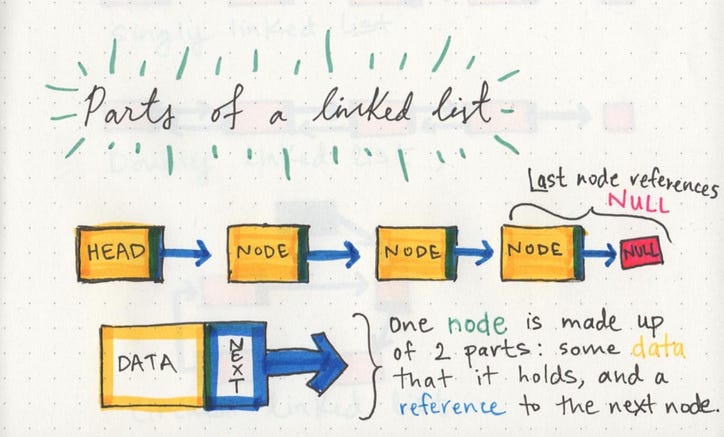
С одним узлом тоже довольно просто. Он состоит всего из двух частей: данных или информации, содержащейся в узле, и ссылки на следующий узел .
Если мы сможем осмыслить это, то мы на полпути. То, как работают узлы, очень важно и очень мощно, и его можно резюмировать следующим образом:
Узел знает только о том, какие данные он содержит и кто его сосед.
Отдельный узел не знает длины связанного списка, и он может даже не знать, где он начинается или где заканчивается. Все, что касается узла, - это данные, которые он содержит, и то, на какой узел ссылается его указатель - следующий узел в списке.
И это причина того, почему связанный список не нужен непрерывный блок памяти. Поскольку у одного узла есть «адрес» или ссылка на следующий узел, им не нужно жить рядом друг с другом, как элементы массива. Вместо этого мы можем просто полагаться на тот факт, что мы можем перемещаться по нашему списку, опираясь на ссылки указателя на следующий узел, что означает, что нашим машинам не нужно блокировать один кусок памяти, чтобы представить наш список.
Это также объясняет, почему связанные списки могут динамически увеличиваться и уменьшаться во время выполнения программы. Добавление или удаление узла со связанным списком становится таким же простым, как перестановка некоторых указателей, а не копирование элементов массива! Тем не менее, у связанных списков есть и некоторые недостатки, о которых я пока не буду вам упоминать, но подробнее о них на следующей неделе.
А пока мы просто будем наслаждаться славой того, насколько круты связанные списки!
Списки для всех форм и размеров
Несмотря на то, что части связанного списка не меняются, способ, которым мы структурируем связанные списки, может быть совершенно другим. Как и большинство вещей в программном обеспечении, в зависимости от проблемы, которую мы пытаемся решить, один тип связанных списков может быть лучшим инструментом для работы, чем другой.
Односвязные списки - это простейший тип связанных списков, основанный исключительно на том факте, что они идут только в одном направлении. Есть единственный трек, по которому мы можем пройти по списку; мы начинаем с головного узла и проходим от корня до последнего узла, который заканчивается пустым нулевым значением.
Но точно так же, как узел может ссылаться на свой последующий соседний узел, он также может иметь указатель ссылки на свой предыдущий узел! Это то, что мы называем двусвязным списком , потому что в каждом узле содержатся две ссылки : ссылка на следующий узел, а также на предыдущий узел. Это может быть полезно, если мы хотим иметь возможность перемещаться по нашей структуре данных не только в одном направлении или направлении, но и в обратном направлении.
Например, если бы мы хотели иметь возможность переключаться между одним узлом и предыдущим узлом, не возвращаясь к самому началу списка , двусвязный список был бы лучшей структурой данных, чем односвязный список. Однако для всего требуется пространство и память, поэтому, если бы нашему узлу пришлось хранить два ссылочных указателя вместо одного, это было бы еще одним вопросом.
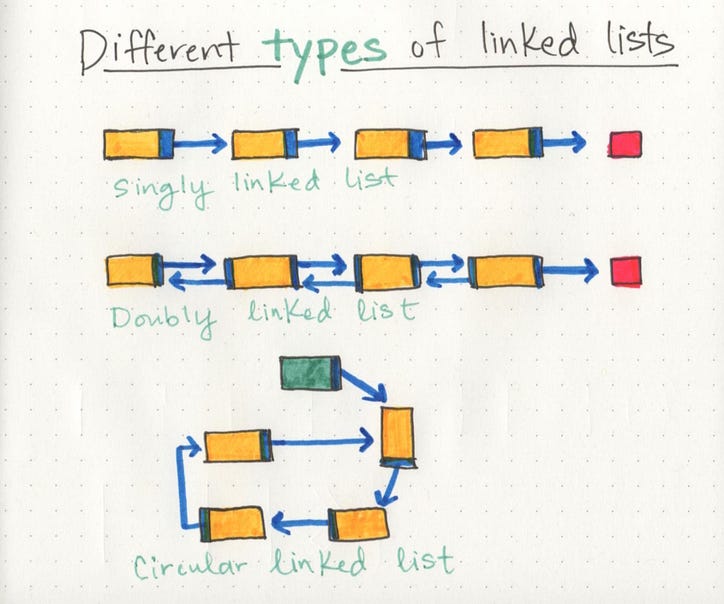
Круговой связанный список является немного странным , что он не заканчивается узел , указывающий на нулевое значение. Вместо этого у него есть узел, который действует как хвост списка (а не обычный головной узел), а узел после хвостового узла является началом списка. Эта организационная структура позволяет очень легко добавить что-то в конец списка, потому что вы можете начать обходить его с хвостового узла, поскольку первый и последний элементы указывают друг на друга. Списки с круговой связью могут начать сходить с ума, потому что мы можем превратить как односвязный, так и двусвязный список в круговой связанный список!
Но независимо от того, насколько сложен связанный список, если мы можем помнить основы узла и то, как он работает, и как структурированы различные ссылки на указатели в нашем списке, связанного списка, с которым мы не могли бы справиться, не существует!
На следующей неделе, во второй части этой серии статей, мы углубимся в пространственно-временную сложность связанных списков и то, как они сравниваются со своим кузеном, массивом. Я обещаю, что на самом деле это намного веселее, чем кажется!
Ресурсы
Если вы думаете, что связанные списки - это здорово, ознакомьтесь с этими полезными ресурсами.
- Различия между массивами и связанными списками , Дэмиен Винтур
- Структуры данных: массивы против связанных списков , mycodeschool
- Связанные списки: основы , доктор Эдвард Герингер
- Введение в связанные списки , Виктор Адамчик
- Структуры данных и реализации , д-р Дженнифер Велч
- Статические структуры данных против динамических структур данных , Айома Гаян Виджетунга