पंडों का विलय 101
- पंडों के साथ
INNER((LEFT|RIGHT! |FULL)OUTER) कैसे करेंJOIN? - मर्ज के बाद लापता पंक्तियों के लिए मैं NaN कैसे जोड़ूं?
- विलय के बाद मुझे NaN से कैसे छुटकारा मिलेगा?
- क्या मैं सूचकांक में विलय कर सकता हूं?
- पंडों के साथ क्रॉस ज्वाइन?
- मैं एकाधिक डेटाफ़्रेम को कैसे मर्ज करूं?
merge?join?concat?update? Who? क्या? क्यों?!
... और अधिक। मैंने इन आवर्ती प्रश्नों को पांडा के मर्ज कार्यक्षमता के विभिन्न पहलुओं के बारे में पूछते हुए देखा है। मर्ज और इसके विभिन्न उपयोग के मामलों के बारे में अधिकांश जानकारी आज दर्जनों बुरी तरह से शब्द-विहीन, अनुपयोगी पोस्टों में खंडित है। यहाँ उद्देश्य के लिए कुछ और महत्वपूर्ण बिंदुओं को टालना है।
इस QnA का मतलब सामान्य पांडा पांडा मुहावरों पर सहायक उपयोगकर्ता-मार्गदर्शकों की श्रृंखला में अगली किस्त होना है ( इस पोस्ट को पिवट पर देखें , और इस पोस्ट को कॉनटेनटेशन पर , जिसे मैं बाद में स्पर्श करूंगा)।
कृपया ध्यान दें कि यह पोस्ट प्रलेखन के लिए एक प्रतिस्थापन नहीं है , इसलिए कृपया इसे भी पढ़ें! कुछ उदाहरण वहां से लिए गए हैं।
जवाब
इस पोस्ट का उद्देश्य पाठकों को SQL- फ्लेवर्ड मर्जिंग के साथ पंडों के साथ एक प्राइमर देना है कि इसका उपयोग कैसे करना है, और जब इसका उपयोग नहीं करना है।
विशेष रूप से, यहाँ इस पोस्ट के माध्यम से जाना जाएगा:
मूल बातें - जुड़ने के प्रकार (LEFT, RIGHT, OUTER, INNER)
- विभिन्न कॉलम नामों के साथ विलय
- आउटपुट में डुप्लिकेट मर्ज कुंजी कॉलम से बचना
विभिन्न परिस्थितियों में सूचकांक के साथ विलय
- प्रभावी रूप से अपने नामित सूचकांक का उपयोग कर
- एक के सूचकांक और दूसरे के कॉलम के रूप में मर्ज करें
कॉलम और इंडेक्स पर मल्टीवे मर्ज (अद्वितीय और गैर-अद्वितीय)
के लिए उल्लेखनीय विकल्प
mergeऔरjoin
इस पोस्ट के माध्यम से नहीं जाना होगा:
- प्रदर्शन-संबंधित चर्चा और समय (अब के लिए)। जहाँ भी उपयुक्त हो, बेहतर विकल्पों के ज्यादातर उल्लेखनीय उल्लेख।
- प्रत्यय संभालना, अतिरिक्त कॉलम हटाना, आउटपुट का नाम बदलना, और अन्य विशिष्ट उपयोग के मामले। अन्य (पढ़ें: बेहतर) पोस्ट हैं जो इससे निपटते हैं, इसलिए इसे समझें!
नोट
विभिन्न उदाहरणों को प्रदर्शित करते हुए INNER JOIN संचालन में डिफ़ॉल्ट रूप से, जब तक कि अन्यथा निर्दिष्ट न हो।इसके अलावा, यहां सभी डेटाफ़्रेमों को कॉपी और दोहराया जा सकता है ताकि आप उनके साथ खेल सकें। इसके अलावा, इस पोस्ट को देखें कि अपने क्लिपबोर्ड से डेटाफ्रेम कैसे पढ़ें।
अंत में, Google ड्रॉइंग का उपयोग करते हुए JOIN संचालन के सभी दृश्य प्रतिनिधित्व को हाथ से तैयार किया गया है। यहां से प्रेरणा मिली ।
बस बात करो, मुझे दिखाओ कि कैसे उपयोग करना है merge!
सेट अप
np.random.seed(0)
left = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': np.random.randn(4)})
right = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': np.random.randn(4)})
left
key value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right
key value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
सरलता के लिए, कुंजी कॉलम का एक ही नाम (अभी के लिए) है।
एक INNER JOIN द्वारा दर्शाया गया है
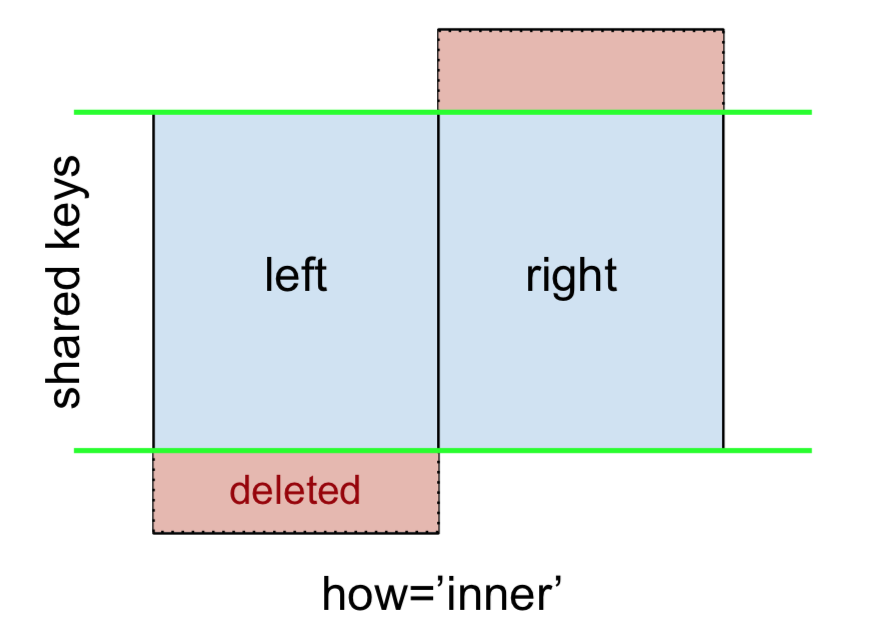
ध्यान दें
, आगामी आंकड़ों के साथ सभी इस सम्मेलन का अनुसरण करते हैं:
- नीला, उन पंक्तियों को इंगित करता है जो मर्ज परिणाम में मौजूद होती हैं
- लाल उन पंक्तियों को इंगित करता है जिन्हें परिणाम से बाहर रखा गया है (यानी, हटाया गया)
- हरे लापता मानों को इंगित करता
NaNहै जिन्हें परिणाम में s के साथ बदल दिया जाता है
INNER JOIN करने के लिए, mergeदाएं DataFrame को निर्दिष्ट करते हुए बाएं DataFrame पर कॉल करें और तर्कों के रूप में (बहुत कम से कम) कुंजी ज्वाइन करें।
left.merge(right, on='key')
# Or, if you want to be explicit
# left.merge(right, on='key', how='inner')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
यह केवल पंक्तियों को लौटाता है leftऔर rightजो एक सामान्य कुंजी साझा करते हैं (इस उदाहरण में, "बी" और "डी)।"
एक LEFT OUTER JOIN , या LEFT JOIN द्वारा दर्शाया गया है
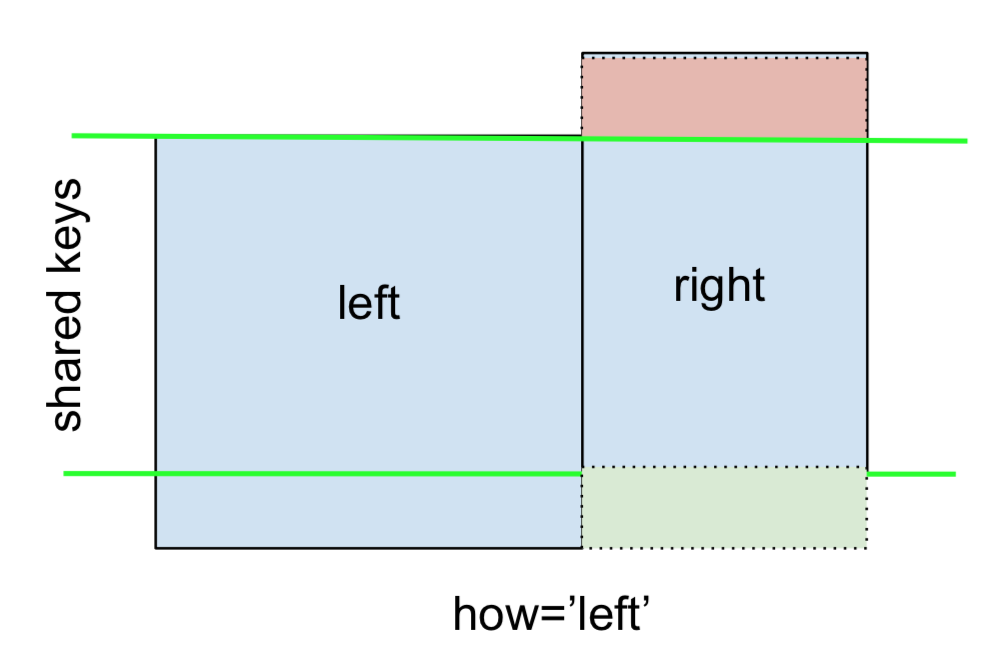
यह निर्दिष्ट करके प्रदर्शन किया जा सकता है how='left'।
left.merge(right, on='key', how='left')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
यहां NaNs के प्लेसमेंट पर ध्यान दें। यदि आप निर्दिष्ट करते हैं how='left', तो केवल कुंजी leftका उपयोग किया जाता है, और लापता डेटा को rightNaN से बदल दिया जाता है।
और इसी तरह, राइट ऑउट जॉइन के लिए , या राइट जॉइन जो है ...
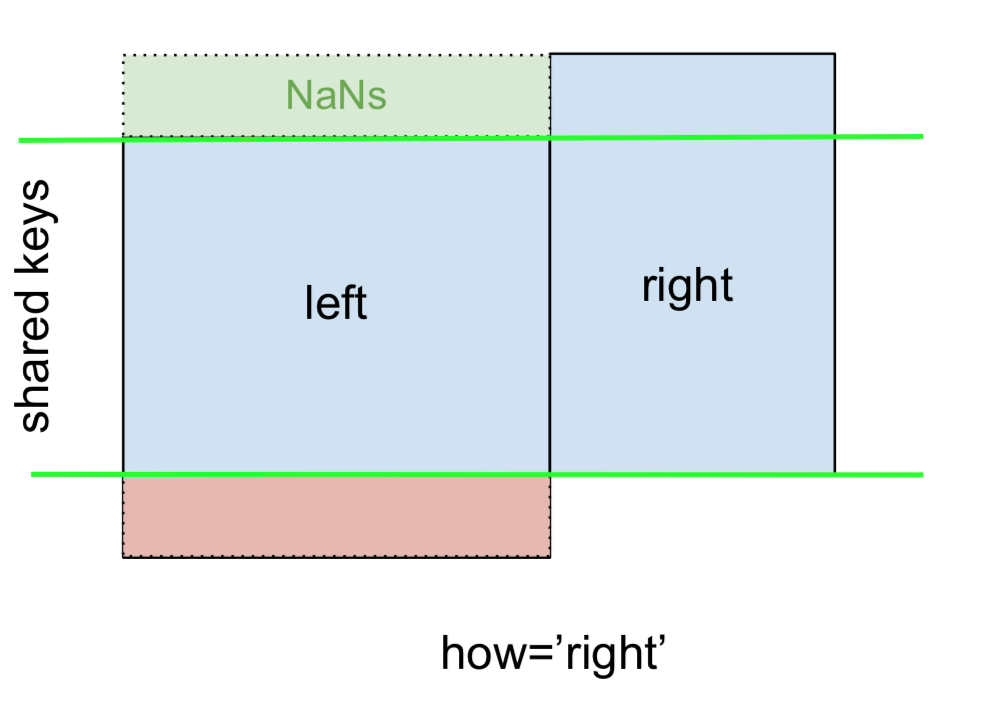
... निर्दिष्ट करें how='right':
left.merge(right, on='key', how='right')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
2 E NaN 0.950088
3 F NaN -0.151357
यहां, कुंजियों rightका उपयोग किया जाता है, और अनुपलब्ध डेटा को leftNaN से बदल दिया जाता है।
अंत में, फुल ऑर्ट जॉइन के लिए , द्वारा दिया गया
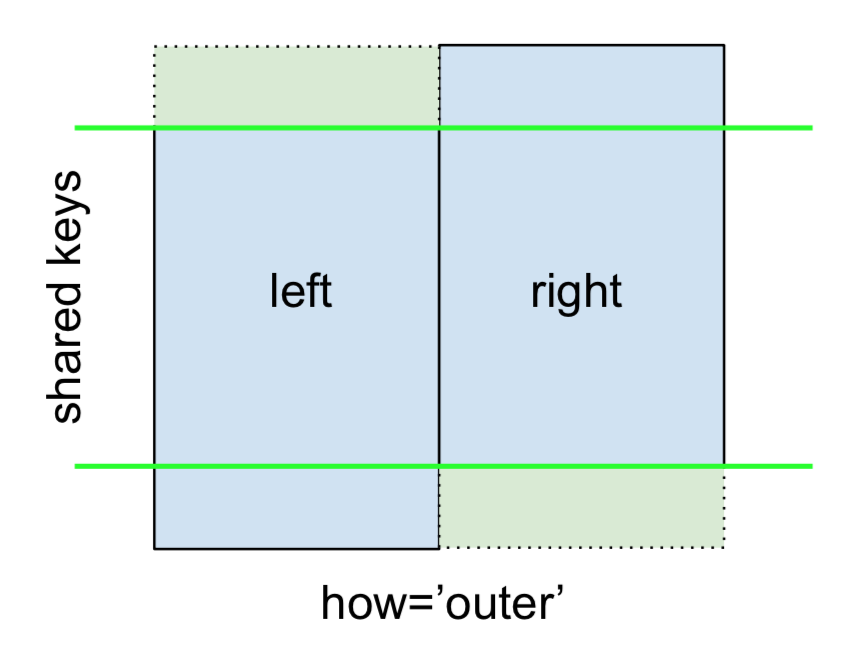
निर्दिष्ट करें how='outer'।
left.merge(right, on='key', how='outer')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
4 E NaN 0.950088
5 F NaN -0.151357
यह दोनों फ़्रेमों से कुंजियों का उपयोग करता है, और NaN दोनों में लापता पंक्तियों के लिए डाला जाता है।
प्रलेखन इन विभिन्न मर्जों को संक्षेप में प्रस्तुत करता है:

अन्य जॉइन - LEFT- एक्सक्लूसिविंग, राइट-एक्सक्लूसिविंग, और फुल-एक्सक्लूडिंग / ANTI जॉन्स
यदि आपको दो चरणों में LEFT-Excluding JOINs और RIGHT-Excluding JOINs की आवश्यकता है।
LEFT- बहिष्कृत JOIN के लिए, के रूप में प्रतिनिधित्व किया
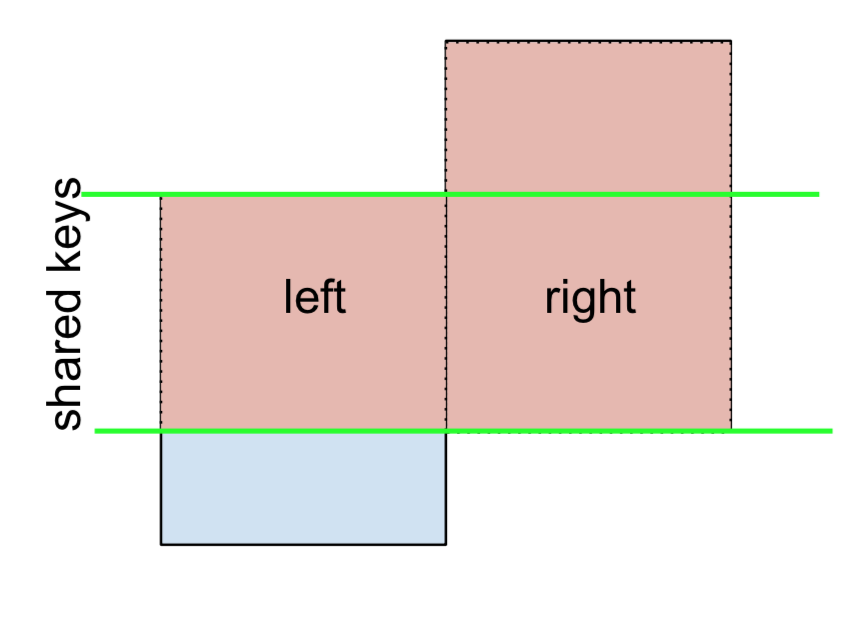
केवल एक बाईं ओर जॉय प्रदर्शन करके प्रारंभ करें और फिर फ़िल्टरिंग (छोड़कर!) leftकेवल से आने वाली पंक्तियों को
(left.merge(right, on='key', how='left', indicator=True)
.query('_merge == "left_only"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
कहाँ पे,
left.merge(right, on='key', how='left', indicator=True)
key value_x value_y _merge
0 A 1.764052 NaN left_only
1 B 0.400157 1.867558 both
2 C 0.978738 NaN left_only
3 D 2.240893 -0.977278 bothऔर इसी तरह, एक सही-बहिष्कृत जॉय के लिए,
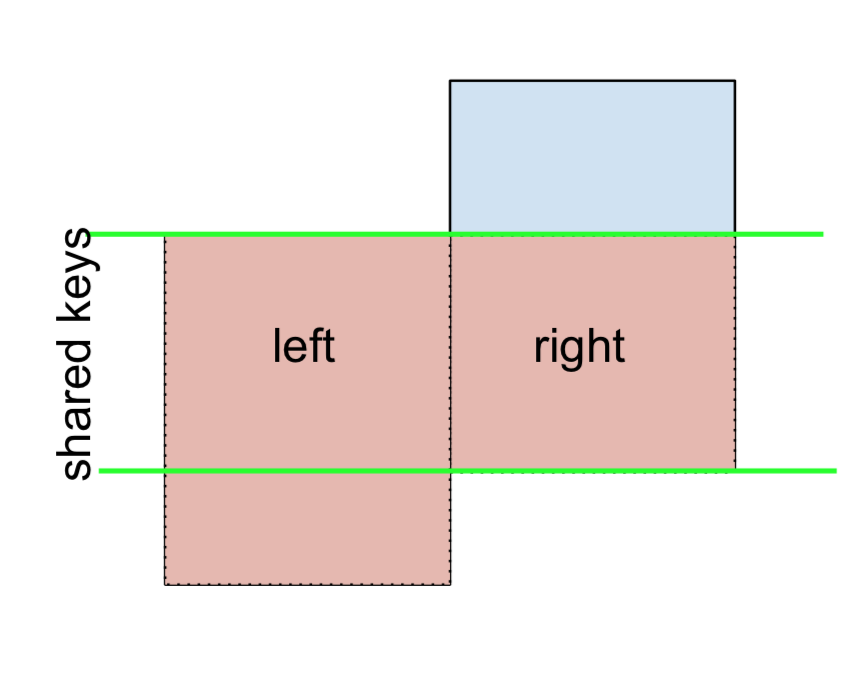
(left.merge(right, on='key', how='right', indicator=True)
.query('_merge == "right_only"')
.drop('_merge', 1))
key value_x value_y
2 E NaN 0.950088
3 F NaN -0.151357अंत में, यदि आपको एक मर्ज करने की आवश्यकता होती है जो केवल बाईं या दाईं ओर से कुंजी रखता है, लेकिन दोनों नहीं (IOW, ANTI-JOIN का प्रदर्शन करते हुए )
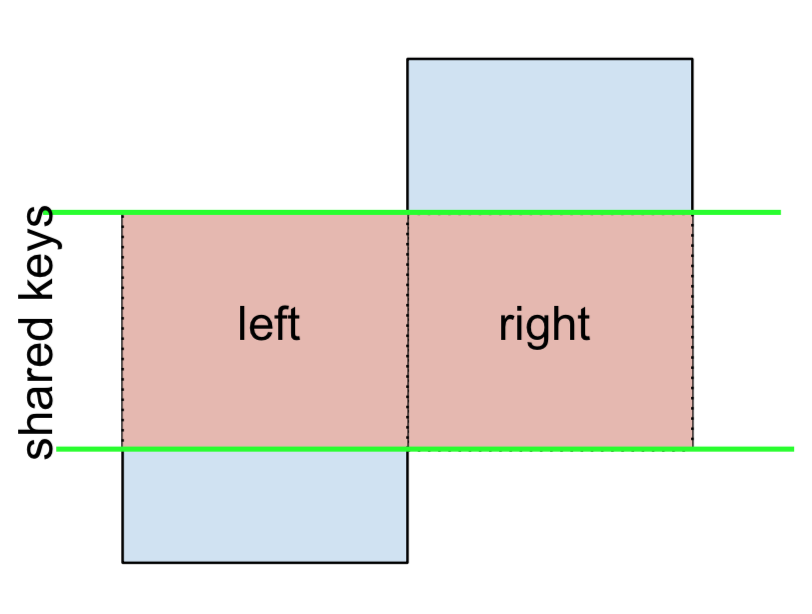
आप इसी तरह से कर सकते हैं-
(left.merge(right, on='key', how='outer', indicator=True)
.query('_merge != "both"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
4 E NaN 0.950088
5 F NaN -0.151357
कुंजी कॉलम के लिए अलग-अलग नाम
प्रमुख कॉलम नामित रहे हैं, तो अलग ढंग से-उदाहरण के लिए, leftहै keyLeft, और rightहै keyRightके बजाय keyआपके द्वारा निर्दिष्ट करना होगा -तो left_onऔर right_onबजाय तर्क के रूप में on:
left2 = left.rename({'key':'keyLeft'}, axis=1)
right2 = right.rename({'key':'keyRight'}, axis=1)
left2
keyLeft value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right2
keyRight value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')
keyLeft value_x keyRight value_y
0 B 0.400157 B 1.867558
1 D 2.240893 D -0.977278
आउटपुट में डुप्लिकेट कुंजी कॉलम से बचना
जब पर विलय keyLeftसे leftऔर keyRightसे right, यदि आप केवल या तो की चाहते हैं keyLeftया keyRightउत्पादन में (लेकिन दोनों नहीं), तो आपको एक प्रारंभिक चरण के रूप में सूचकांक की स्थापना द्वारा शुरू कर सकते हैं।
left3 = left2.set_index('keyLeft')
left3.merge(right2, left_index=True, right_on='keyRight')
value_x keyRight value_y
0 0.400157 B 1.867558
1 2.240893 D -0.977278
इसके विपरीत कमांड के आउटपुट से ठीक पहले (जो है, आउटपुट है left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')), आप देखेंगे keyLeftकि गायब है। आप यह पता लगा सकते हैं कि किस फ्रेम के इंडेक्स को कुंजी के रूप में सेट किया गया है। यह बात तब हो सकती है, जब कहें कि कुछ OUTER JOIN ऑपरेशन कर रहे हैं।
किसी एक में से केवल एक कॉलम जोड़ना DataFrames
उदाहरण के लिए, विचार करें
right3 = right.assign(newcol=np.arange(len(right)))
right3
key value newcol
0 B 1.867558 0
1 D -0.977278 1
2 E 0.950088 2
3 F -0.151357 3
यदि आपको केवल "new_val" (किसी भी अन्य कॉलम के बिना) को मर्ज करने की आवश्यकता है, तो आप आमतौर पर विलय के लिए केवल सब्मिट कर सकते हैं:
left.merge(right3[['key', 'newcol']], on='key')
key value newcol
0 B 0.400157 0
1 D 2.240893 1
यदि आप एक LEUT OUTER JOIN कर रहे हैं, तो एक अधिक प्रभावी समाधान शामिल होगा map:
# left['newcol'] = left['key'].map(right3.set_index('key')['newcol']))
left.assign(newcol=left['key'].map(right3.set_index('key')['newcol']))
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
जैसा कि उल्लेख किया गया है, यह समान है, लेकिन इससे भी तेज है
left.merge(right3[['key', 'newcol']], on='key', how='left')
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
कई कॉलम पर विलय
एक से अधिक स्तंभ पर शामिल होने के लिए, के लिए एक सूची निर्दिष्ट on(या left_onऔर right_on, उचित रूप में)।
left.merge(right, on=['key1', 'key2'] ...)
या, घटना में नाम अलग हैं,
left.merge(right, left_on=['lkey1', 'lkey2'], right_on=['rkey1', 'rkey2'])
अन्य उपयोगी merge*संचालन और कार्य
अनुक्रमणिका पर श्रृंखला के साथ डेटाफ़्रेम मर्ज करना : यह उत्तर देखें ।
इसके अलावा
merge,DataFrame.updateऔरDataFrame.combine_firstभी दूसरे के साथ एक DataFrame अद्यतन करने के लिए कुछ मामलों में किया जाता है।pd.merge_orderedआदेशित JOIN के लिए एक उपयोगी कार्य है।pd.merge_asof(read: merge_asOf) अनुमानित जोड़ के लिए उपयोगी है ।
यह खंड केवल बहुत मूल बातें शामिल करता है, और केवल आपकी भूख को बढ़ाने के लिए डिज़ाइन किया गया है। अधिक उदाहरण और मामलों के लिए, देखें पर प्रलेखन merge, joinऔरconcat साथ ही समारोह चश्मा लिंक के रूप में।
सूचकांक आधारित * -JOIN (+ सूचकांक-स्तंभ merges)
सेट अप
np.random.seed([3, 14])
left = pd.DataFrame({'value': np.random.randn(4)}, index=['A', 'B', 'C', 'D'])
right = pd.DataFrame({'value': np.random.randn(4)}, index=['B', 'D', 'E', 'F'])
left.index.name = right.index.name = 'idxkey'
left
value
idxkey
A -0.602923
B -0.402655
C 0.302329
D -0.524349
right
value
idxkey
B 0.543843
D 0.013135
E -0.326498
F 1.385076
आमतौर पर, सूचकांक पर एक मर्ज इस तरह दिखेगा:
left.merge(right, left_index=True, right_index=True)
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
सूचकांक नामों के लिए समर्थन
अपने सूचकांक के नाम पर है, तो v0.23 उपयोगकर्ताओं की भी स्तर नाम निर्दिष्ट कर सकते हैं on(या left_onऔर right_onआवश्यक के रूप में)।
left.merge(right, on='idxkey')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
एक के सूचकांक पर विलय, दूसरे के कॉलम (एस)
मर्ज करने के लिए एक के सूचकांक और दूसरे के कॉलम का उपयोग करना (और काफी सरल) संभव है। उदाहरण के लिए,
left.merge(right, left_on='key1', right_index=True)
या इसके विपरीत ( right_on=...और left_index=True)।
right2 = right.reset_index().rename({'idxkey' : 'colkey'}, axis=1)
right2
colkey value
0 B 0.543843
1 D 0.013135
2 E -0.326498
3 F 1.385076
left.merge(right2, left_index=True, right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
इस विशेष मामले में, के लिए इंडेक्स leftका नाम दिया गया है, इसलिए आप इंडेक्स नाम का उपयोग left_onइस तरह भी कर सकते हैं :
left.merge(right2, left_on='idxkey', right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
DataFrame.join
इनके अलावा, एक और रसीला विकल्प है। आप DataFrame.joinसूचकांक में शामिल होने के लिए कौन सी चूक का उपयोग कर सकते हैं । DataFrame.joinडिफ़ॉल्ट रूप से एक बाईं ओर शामिल है, तो how='inner'यहाँ आवश्यक है।
left.join(right, how='inner', lsuffix='_x', rsuffix='_y')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
ध्यान दें कि मुझे lsuffixऔर को निर्दिष्ट करने के लिए rsuffixतर्क की आवश्यकता joinहोगी अन्यथा अन्यथा त्रुटि होगी:
left.join(right)
ValueError: columns overlap but no suffix specified: Index(['value'], dtype='object')
चूंकि कॉलम के नाम समान हैं। यह एक समस्या नहीं होगी अगर उन्हें अलग नाम दिया गया।
left.rename(columns={'value':'leftvalue'}).join(right, how='inner')
leftvalue value
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
pd.concat
अंत में, इंडेक्स-आधारित जॉइन के लिए एक विकल्प के रूप में, आप इसका उपयोग कर सकते हैं pd.concat:
pd.concat([left, right], axis=1, sort=False, join='inner')
value value
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
join='inner'यदि आपको पूर्ण OOO JOIN (डिफ़ॉल्ट) चाहिए तो Omit :
pd.concat([left, right], axis=1, sort=False)
value value
A -0.602923 NaN
B -0.402655 0.543843
C 0.302329 NaN
D -0.524349 0.013135
E NaN -0.326498
F NaN 1.385076
अधिक जानकारी के लिए, इस कैनोनिकल पोस्ट को pd.concat@piRSquared द्वारा देखें ।
सामान्यीकरण: mergeकई डेटाफ़्रेम का अंतर्ग्रहण करें
अक्सर, कई DataFrames को एक साथ मर्ज किए जाने की स्थिति उत्पन्न होती है। धनात्मक रूप से, यह mergeकॉल को चैन करके किया जा सकता है :
df1.merge(df2, ...).merge(df3, ...)
हालाँकि, यह कई डेटाफ़्रेम के लिए जल्दी से हाथ से निकल जाता है। इसके अलावा, डेटाफ्रैम की एक अज्ञात संख्या के लिए सामान्यीकरण करना आवश्यक हो सकता है।
यहां मैं अनूठी कुंजियों pd.concatपर मल्टी-वे जॉइन के लिए परिचय देता हूं , और गैर-यूनीक कुंजी पर मल्टी-वे जॉइन के लिए । सबसे पहले, सेटअप।DataFrame.join
# Setup.
np.random.seed(0)
A = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'valueA': np.random.randn(4)})
B = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'valueB': np.random.randn(4)})
C = pd.DataFrame({'key': ['D', 'E', 'J', 'C'], 'valueC': np.ones(4)})
dfs = [A, B, C]
# Note, the "key" column values are unique, so the index is unique.
A2 = A.set_index('key')
B2 = B.set_index('key')
C2 = C.set_index('key')
dfs2 = [A2, B2, C2]
अद्वितीय कुंजी (या अनुक्रमणिका) पर मल्टीवे मर्ज
यदि आपकी चाबियाँ (यहां, कुंजी या तो एक कॉलम या इंडेक्स हो सकती है) अद्वितीय हैं, तो आप उपयोग कर सकते हैं pd.concat। ध्यान दें कि pd.concatइंडेक्स पर DataFrames जुड़ता है ।
# merge on `key` column, you'll need to set the index before concatenating
pd.concat([
df.set_index('key') for df in dfs], axis=1, join='inner'
).reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# merge on `key` index
pd.concat(dfs2, axis=1, sort=False, join='inner')
valueA valueB valueC
key
D 2.240893 -0.977278 1.0
join='inner'एक पूर्ण OUT JOIN के लिए Omit । ध्यान दें कि आप LEFT या RIGHT OUTER जॉइन को निर्दिष्ट नहीं कर सकते हैं (यदि आपको इनका उपयोग करने की आवश्यकता है, तो joinनीचे वर्णित है)।
डुप्लिकेट के साथ कुंजियों पर मल्टीवे मर्ज
concatतेज है, लेकिन इसकी कमियां हैं। यह डुप्लिकेट को संभाल नहीं सकता है।
A3 = pd.DataFrame({'key': ['A', 'B', 'C', 'D', 'D'], 'valueA': np.random.randn(5)})
pd.concat([df.set_index('key') for df in [A3, B, C]], axis=1, join='inner')
ValueError: Shape of passed values is (3, 4), indices imply (3, 2)
इस स्थिति में, हम इसका उपयोग कर सकते हैं joinक्योंकि यह गैर-अद्वितीय कुंजियों को संभाल सकता है (ध्यान दें कि joinडेटा इंडेक्स को उनके सूचकांक में शामिल करता है; यह mergeहुड के नीचे कॉल करता है और जब तक अन्यथा निर्दिष्ट नहीं होता है तब तक एक LEFT OUTER JOIN करता है)।
# join on `key` column, set as the index first
# For inner join. For left join, omit the "how" argument.
A.set_index('key').join(
[df.set_index('key') for df in (B, C)], how='inner').reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# join on `key` index
A3.set_index('key').join([B2, C2], how='inner')
valueA valueB valueC
key
D 1.454274 -0.977278 1.0
D 0.761038 -0.977278 1.0
का एक पूरक दृश्य दृश्य pd.concat([df0, df1], kwargs)। ध्यान दें कि, kwarg axis=0या axis=1का अर्थ उतना सहज नहीं है जितना df.mean()याdf.apply(func)
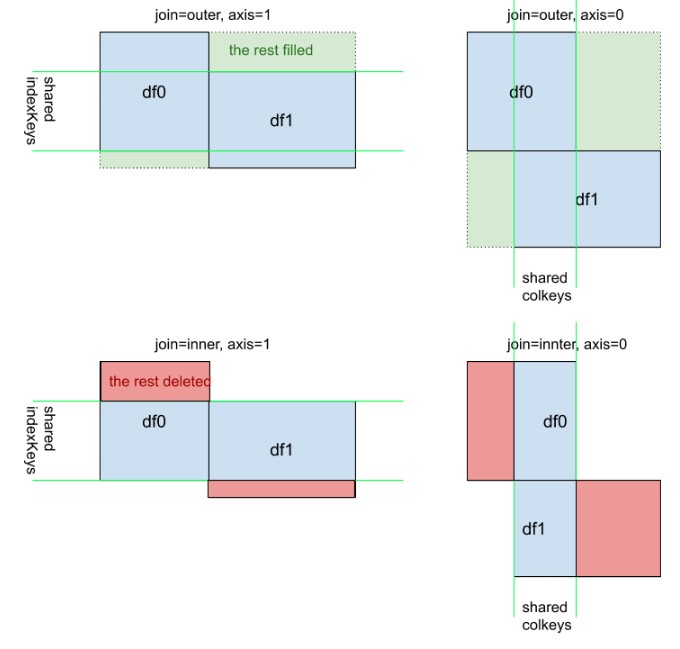
इस जवाब में, मैं एक व्यावहारिक उदाहरण पर विचार करूंगा pandas.concat।
निम्नलिखित DataFramesसमान कॉलम नामों के साथ विचार करना :
आकार के साथ Preco2018 (8784, 5)
प्रीको 2019 आकार के साथ (8760, 5)
जिसमें समान कॉलम नाम हैं।
आप pandas.concatबस उन्हें इस्तेमाल करके जोड़ सकते हैं
import pandas as pd
frames = [Preco2018, Preco2019]
df_merged = pd.concat(frames)
निम्नलिखित आकार (17544, 5) के साथ एक DataFrame में परिणाम

यदि आप कल्पना करना चाहते हैं, तो यह इस तरह से काम करता है
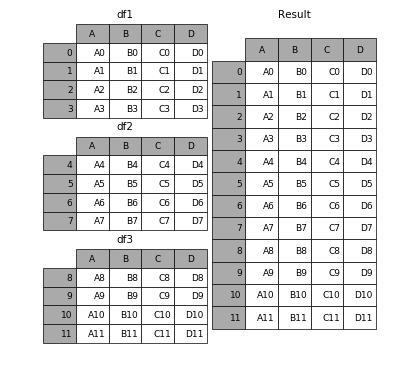
( स्रोत )