Использование многоядерной мощности с помощью Asyncio в Python

Это одна из моих статей в рубрике Python Concurrency , и если вы сочтете ее полезной, можете прочитать остальные отсюда .
Введение
В этой статье я покажу вам, как выполнить асинхронный код Python на многоядерном процессоре, чтобы разблокировать полную производительность параллельных задач.
В чем наша проблема?
asyncio использует только одно ядро.
В предыдущих статьях я подробно рассмотрел механику использования Python asyncio. Обладая этими знаниями, вы можете узнать, что asyncio позволяет выполнять задачи, связанные с вводом-выводом, с высокой скоростью, вручную переключая выполнение задачи, чтобы обойти процесс конкуренции GIL во время многопоточного переключения задач.
Теоретически время выполнения задач, связанных с вводом-выводом, зависит от времени от начала до ответа операции ввода-вывода и не зависит от производительности вашего ЦП. Таким образом, мы можем одновременно инициировать десятки тысяч задач ввода-вывода и быстро их выполнять.
Но недавно я писал программу, которой нужно было одновременно сканировать десятки тысяч веб-страниц, и обнаружил, что, хотя моя асинхронная программа была намного эффективнее программ, использующих итеративное сканирование веб-страниц, она все же заставила меня долго ждать. Должен ли я использовать полную производительность моего компьютера? Поэтому я открыл диспетчер задач и проверил:
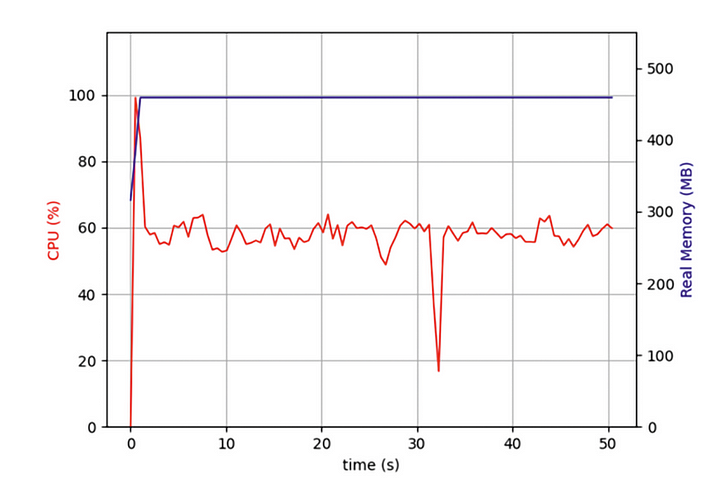
Я обнаружил, что с самого начала мой код работал только на одном ядре ЦП, а несколько других ядер простаивали. В дополнение к запуску операций ввода-вывода для захвата сетевых данных задача должна распаковать и отформатировать данные после их возврата. Хотя эта часть операции не потребляет много ресурсов ЦП, после выполнения дополнительных задач эти операции, связанные с ЦП, серьезно повлияют на общую производительность.
Я хотел, чтобы мои параллельные асинхронные задачи выполнялись параллельно на нескольких ядрах. Будет ли это снижать производительность моего компьютера?
Основополагающие принципы asyncio
Чтобы решить эту загадку, мы должны начать с базовой реализации asyncio, цикла обработки событий.

Как показано на рисунке, повышение производительности программ с помощью asyncio начинается с задач с интенсивным вводом-выводом. К задачам с интенсивным вводом-выводом относятся HTTP-запросы, чтение и запись файлов, доступ к базам данных и т. д. Наиболее важной особенностью этих задач является то, что ЦП не блокируется и тратит много времени на вычисления в ожидании возврата внешних данных, что сильно отличается от другого класса синхронных задач, которые требуют, чтобы ЦП был занят все время для вычисления определенного результата.
Когда мы генерируем пакет асинхронных задач, код сначала помещает эти задачи в очередь. На данный момент существует поток, называемый циклом событий, который берет одну задачу из очереди и выполняет ее. Когда задача достигает оператора ожидания и ожидает (обычно возврата запроса), цикл событий берет другую задачу из очереди и выполняет ее. Пока предыдущая ожидающая задача не получит данные через обратный вызов, цикл обработки событий возвращается к предыдущей ожидающей задаче и завершает выполнение остального кода.
Поскольку поток цикла событий выполняется только на одном ядре, цикл событий блокируется, когда «остальная часть кода» занимает процессорное время. Когда количество задач в этой категории велико, каждый небольшой блокирующий сегмент добавляется и замедляет работу программы в целом.
Каково мое решение?
Из этого мы знаем, что программы asyncio замедляются, потому что наш код Python выполняет цикл событий только на одном ядре, а обработка данных ввода-вывода приводит к замедлению работы программы. Есть ли способ запустить цикл событий на каждом ядре ЦП для его выполнения?
Как мы все знаем, начиная с Python 3.7, весь асинхронный код рекомендуется выполнять с помощью метода asyncio.run, который представляет собой высокоуровневую абстракцию, вызывающую цикл обработки событий для выполнения кода в качестве альтернативы следующему коду:
try:
loop = asyncio.get_event_loop()
loop.run_until_complete(task())
finally:
loop.close()
В предыдущей статье использовался пример из реальной жизни, чтобы объяснить использование метода asyncio loop.run_in_executorдля распараллеливания выполнения кода в пуле процессов, а также получения результатов каждого дочернего процесса из основного процесса. Если вы не читали предыдущую статью, вы можете ознакомиться с ней здесь:
Таким образом, возникает наше решение: распределить множество параллельных задач на несколько подпроцессов, используя многоядерное выполнение через метод loop.run_in_executor, а затем вызвать asyncio.runкаждый подпроцесс, чтобы запустить соответствующий цикл обработки событий и выполнить параллельный код. На следующей диаграмме показан весь поток:
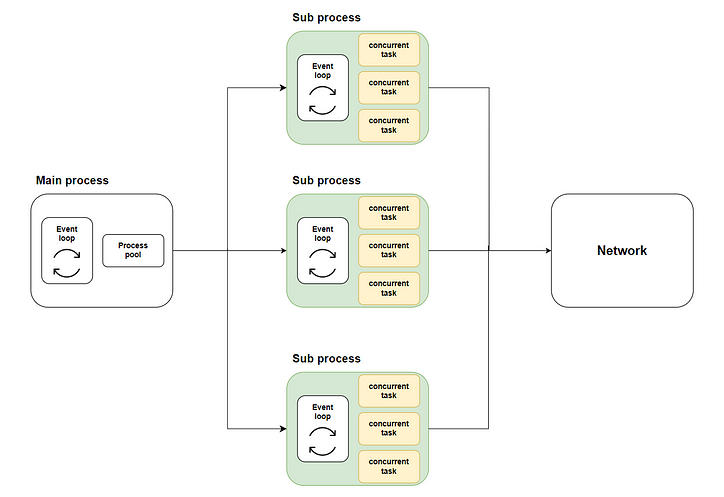
Где зеленая часть представляет подпроцессы, которые мы начали. Желтая часть представляет параллельные задачи, которые мы начали.
Подготовка перед началом
Моделирование выполнения задачи
Прежде чем мы сможем решить проблему, нам нужно подготовиться, прежде чем мы начнем. В этом примере мы не можем написать фактический код для сканирования веб-контента, потому что это будет очень раздражать целевой веб-сайт, поэтому мы смоделируем нашу реальную задачу с помощью кода:
Как видно из кода, мы сначала используем asyncio.sleepдля имитации возврата задачи ввода-вывода в случайное время и итеративного суммирования для имитации обработки ЦП после возврата данных.
Эффект традиционного кода
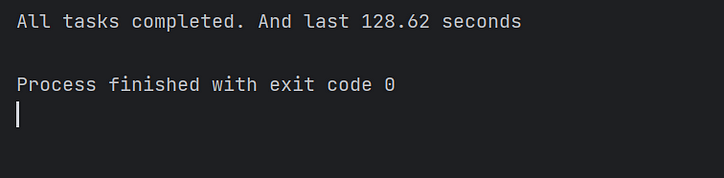
Затем мы используем традиционный подход, запуская 10 000 одновременных задач в основном методе и наблюдая за временем, затраченным на эту группу одновременных задач:
Как видно из рисунка, выполнение асинхронных задач только с одним ядром занимает больше времени.
Реализация кода
Далее давайте реализуем многоядерный асинхронный код в соответствии с блок-схемой и посмотрим, улучшится ли производительность.
Проектирование общей структуры кода
Во-первых, как архитектору, нам все еще нужно сначала определить общую структуру сценария, какие методы требуются и какие задачи должен выполнять каждый метод:
Конкретная реализация каждого метода
Затем давайте реализуем каждый метод шаг за шагом.
Метод query_concurrentlyзапустит указанный пакет задач одновременно и получит результаты с помощью asyncio.gatherметода:
Метод run_batch_tasksне является асинхронным, так как запускается непосредственно в дочернем процессе:
Наконец, есть наш mainметод. Этот метод вызовет loop.run_in_executorметод для run_batch_tasksвыполнения метода в пуле процессов и объединит результаты выполнения дочернего процесса в список:
Поскольку мы пишем многопроцессный скрипт, нам нужно использовать if __name__ == “__main__”для запуска метода main в основном процессе:
Выполните код и посмотрите результаты
Далее запускаем скрипт и смотрим нагрузку на каждое ядро в диспетчере задач:
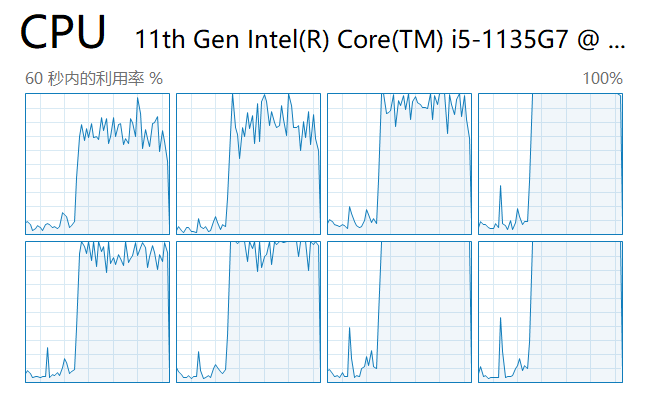
Как видите, используются все ядра ЦП.
Наконец, мы наблюдаем за временем выполнения кода и подтверждаем, что многопоточный код asyncio действительно ускоряет выполнение кода в несколько раз! Миссия выполнена!

Заключение
В этой статье я объяснил, почему asyncio может одновременно выполнять задачи с интенсивным вводом-выводом, но все равно занимает больше времени, чем ожидалось, при выполнении больших пакетов параллельных задач.
Это связано с тем, что в традиционной схеме реализации асинхронного кода цикл событий может выполнять задачи только на одном ядре, а остальные ядра находятся в состоянии простоя.
Поэтому я реализовал решение для вызова каждого цикла событий на нескольких ядрах отдельно для параллельного выполнения параллельных задач. И, наконец, это значительно улучшило производительность кода.
Из-за ограниченности моих возможностей решение в этой статье неизбежно имеет несовершенства. Я приветствую ваши комментарии и обсуждения. Я буду активно отвечать за вас.

![В любом случае, что такое связанный список? [Часть 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































