기계 학습에 더 많은 비용을 지불해야 하는 이유는 무엇입니까?

Scikit-learn용 인텔 확장으로 불균형한 학습 워크로드 가속화
Ethan Glaser, Nikolay Petrov, Henry Gabb, Jui Mhatre, Intel Corporation
최근 NVIDIA 블로그는 오해의 소지가 있는 결과 로 우리의 시선을 사로잡았습니다 . A100 GPU를 9년 된 CPU(Intel Xeon E5–2698은 2014년에 출시된 후 단종됨)와 비교하거나 최적화된 CUDA 코드(RAPIDS cuML 라이브러리)를 최적화되지 않은 단일 스레드와 비교하는 이유는 무엇입니까? 의도적으로 GPU 대 CPU 속도 향상을 부풀리려고 하지 않는 한 Python 코드( 불균형 학습 라이브러리를 사용한 주식 scikit-learn )? imbalanced-learn 라이브러리는 scikit-learn 호환 추정기를 지원하므로 가속화를 위해 cuML 추정기를 사용했습니다. patch_sklearn()에 대한 호출을 추가하기만 하면 Scikit-learn용 인텔 확장 에서 최적화된 추정기를 사용할 수 있습니다 .
from sklearnex import patch_sklearn
patch_sklearn()
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.neighbors import NearestNeighbors
...
nn = NearestNeighbors(n_neighbors=4, n_jobs=-1)
X_resampled, y_resampled = EditedNearestNeighbours(n_neighbors=nn).fit_resample(X, y)

성능 비교
Scikit-learn용 인텔 확장은 Nvidia와 동일한 벤치마크에서 전반적으로 속도 향상을 제공합니다(그림 1). 속도 향상 범위는 알고리즘과 매개변수에 따라 ~2x에서 ~140x까지입니다. 스톡 scikit-learn 라이브러리는 SMOTE 및 ADASYN "100 기능, 5 클래스" 벤치마크에 대한 메모리가 부족합니다. 성능이 중요한 경우 이러한 결과는 Scikit-learn용 인텔 확장이 스톡 scikit-learn보다 상당한 속도 향상을 제공한다는 것을 보여줍니다.

이것은 Nvidia의 A100 결과와 어떻게 비교됩니까? Nvidia가 scikit-learn에 비해 가장 높은 속도 향상을 달성한 두 가지 알고리즘인 SVMSMOTE 및 CondensedNearestNeighbours를 살펴보겠습니다(그림 2). 이러한 결과는 최신 프로세서와 최적화된 scikit-learn을 비교에 사용할 때 성능이 cuML과 비슷한 수준임을 보여줍니다. Scikit-learn용 인텔 확장은 일부 테스트에서 cuML을 능가하기도 합니다. 이제 가격에 대해 이야기합시다.


비용 비교
GCP에서 a2-highgpu-1g A100 인스턴스의 시간당 비용이 n2-highcpu-64 인스턴스보다 60% 높다는 점은 주목할 가치가 있습니다(표 1). 즉, A100 인스턴스는 비용 경쟁력을 갖추기 위해 Xeon Gold 6268CL(n2-highcpu-64) 인스턴스보다 1.6배 이상의 속도 향상을 제공해야 합니다. (또한 A100은 Xeon E5–2696 v4 및 Xeon Gold 6268CL보다 각각 1.7배 및 1.2배 더 많은 전력을 소비하지만 전력 소비는 인스턴스 비용에 포함되기 때문에 지금은 제외하겠습니다.)
A100 인스턴스가 프리미엄 가격을 정당화하는지 확인하기 위해 Nvidia에서 선택한 벤치마크에 대한 가격 대비 성능 비율을 비교해 보겠습니다 . 벤치마크 실행의 총 비용(USD)은 단순히 시간당 인스턴스 비용(USD/hr)에 런타임(hr)을 곱한 것입니다. 자세한 비용 비교는 Xeon 인스턴스에서 이러한 벤치마크를 실행하는 것이 종종 더 비용 효율적인 옵션임을 보여줍니다(그림 3). 아래 차트에서 1보다 큰 값은 주어진 벤치마크가 A100 인스턴스에서 더 비싸다는 것을 나타냅니다. 예를 들어 값이 1.29이면 A100 인스턴스가 Xeon 인스턴스보다 29% 더 비쌉니다.



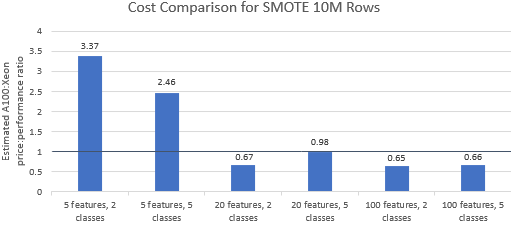
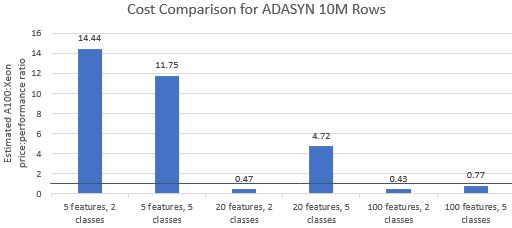
벤치마크 비용은 사용된 알고리즘과 매개변수에 따라 다르지만 결과는 일반적으로 Xeon 인스턴스에 유리합니다. 비용의 기하 평균은 5개 알고리즘 중 4개에서 1보다 크고 전체 기하 평균은 1.36입니다(표 2).

또한 CPU는 인스턴스 선택에 더 많은 유연성을 제공하여 효율성을 더욱 향상시킵니다. 성능 요구 사항과 예산 제약을 충족하면서 주어진 문제 크기를 처리할 수 있는 가장 작은 용량의 Xeon 인스턴스를 선택하는 것이 더 비용 효율적입니다. 그림 4는 두 개의 가장 작은 벤치마크에 대한 하나의 예를 보여줍니다. 이러한 결과는 모델 구성의 요구 사항에 가장 잘 맞는 하드웨어에서 실행하는 것이 훨씬 더 저렴할 수 있음을 보여줍니다. 예를 들어, e2-highcpu-8 인스턴스에서 Intel Extension for Scikit-learn을 사용하여 두 개의 ADASYN 벤치마크를 실행하는 것은 A100 인스턴스에서 cuML을 실행하는 비용의 1.5% 및 2.1%에 불과합니다.

결론
위의 결과는 Scikit-learn용 인텔 확장이 스톡 scikit-learn에 비해 성능 결과를 극적으로 개선할 수 있으며 일부 테스트에서 A100보다 우수한 성능을 발휘할 수 있음을 보여줍니다. 비용을 고려할 때 Xeon 인스턴스가 A100 인스턴스보다 훨씬 저렴하기 때문에 Intel Extension for Scikit-learn 결과가 훨씬 유리합니다. 사용자는 성능, 전력 및 가격 요구 사항을 충족하는 Xeon 인스턴스를 선택할 수 있습니다.

![연결된 목록이란 무엇입니까? [1 부]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































