연결된 목록이란 무엇입니까? [1 부]
정보는 우리 주변에 있습니다.
소프트웨어 세계에서 정보를 구성하기 위해 선택하는 방법은 절반의 문제입니다. 하지만 문제 는 다음과 같습니다 . 문제를 해결하는 방법 은 매우 많습니다 . 데이터를 구성 할 때 작업에 사용할 수있는 많은 도구가 있습니다. 요령은 어떤 도구가 사용하기에 적합한 지 아는 것입니다.
코딩을 시작하는 언어에 관계없이 가장 먼저 접하게되는 것 중 하나는 데이터 구조입니다 . 이는 데이터를 구성 할 수있는 다양한 방법입니다. 변수 , 배열 , 해시 및 객체 는 모두 데이터 구조 유형입니다. 그러나 이것들은 데이터 구조와 관련하여 여전히 빙산의 일각에 불과합니다. 더 많은 것들이 있으며, 그중 일부는 당신이 그들에 대해 더 많이들을수록 매우 복잡하게 들리기 시작합니다.
저에게 복잡한 것 중 하나는 항상 연결 목록 이었습니다. 나는 연결 목록에 대해 몇 년 동안 알고 있었지만 결코 내 머리 속에 똑바로 유지할 수는 없습니다. 기술 면접을 준비 할 때 (때로는 중간에있을 때), 누군가가 그에 대해 물어볼 때만 생각합니다. 나는 약간의 조사를하고 그들이 무엇에 관한 것인지 이해한다고 생각할 것이다. 그러나 몇 주 후에 나는 그들을 다시 잊는다. 모든 것이 매우 비효율적이며 모든 것이 존재한다는 사실을 알고 있지만 근본적으로 이해 하지 못한다는 사실에서 비롯 됩니다! 그래서, 그것을 바꾸고 질문에 답할 때입니다 : 어쨌든 연결된 목록은 도대체 무엇입니까?
선형 데이터 구조
연결 목록의 기본 사항을 정말로 이해하고 싶다면 연결 목록이 어떤 유형 의 데이터 구조 인지에 대해 이야기하는 것이 중요합니다 .
연결 목록의 한 가지 특징은 선형 데이터 구조 라는 것입니다. 즉, 구성 및 탐색 방법에 순서와 순서가 있습니다. 우리는 돌 차기 놀이 게임 과 같은 선형 데이터 구조를 생각할 수 있습니다 . 목록의 끝에 도달하려면 목록의 모든 항목을 순서대로 또는 순차적으로 살펴야 합니다. 그러나 선형 구조는 비선형 구조와 반대입니다. 에서는 비선형 데이터 구조 , 항목, 우리는 데이터 구조를 통과 할 수있는 수단의 순서로 배치 될 필요가 없다 비 순차적 .
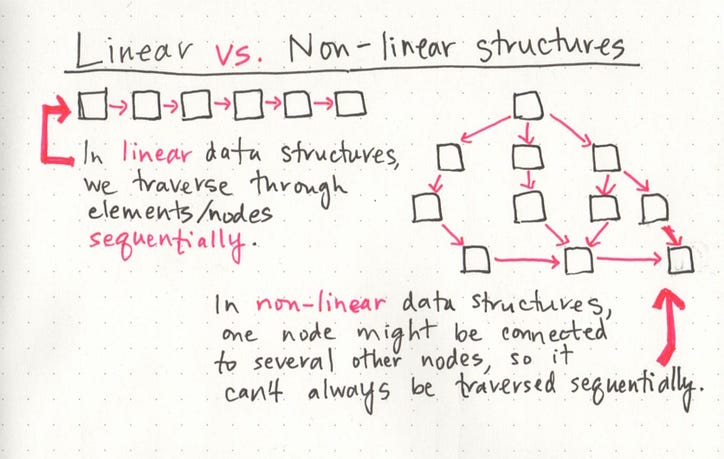
우리는 항상 그것을 깨닫지 못할 수도 있지만, 우리 모두는 매일 선형 및 비선형 데이터 구조로 작업합니다! 데이터를 해시 ( 사전 이라고도 함 ) 로 구성 할 때 비선형 데이터 구조를 구현합니다. 트리 와 그래프 는 우리가 다른 방식으로 횡단하는 비선형 데이터 구조이기도하지만, 연말에 더 자세히 설명 할 것입니다.
마찬가지로 코드에서 배열 을 사용할 때 선형 데이터 구조를 구현합니다! 배열과 연결 목록을 우리가 데이터를 시퀀싱하는 방식과 비슷하다고 생각하면 도움이 될 수 있습니다. 이 두 구조 모두에서 순서가 중요 합니다. 그러나 배열과 연결 목록이 다른 이유는 무엇입니까?
메모리 관리
배열과 연결 목록의 가장 큰 차이점은 시스템에서 메모리를 사용하는 방식입니다. Ruby, JavaScript 또는 Python과 같은 동적 유형의 언어로 작업하는 사람들은 여러 추상화 계층이 있기 때문에 매일 코드를 작성할 때 배열이 사용하는 메모리 양을 생각할 필요가 없습니다. 메모리 할당에 대해 전혀 걱정할 필요가 없습니다.
그러나 그것이 메모리 할당이 일어나지 않는다는 것을 의미하지는 않습니다! 추상화는 마술이 아니라 항상 보거나 처리 할 필요가없는 것을 숨기는 단순성 일뿐입니다. 코드를 작성할 때 메모리 할당에 대해 생각할 필요가 없더라도 링크드리스트에서 무슨 일이 일어나고 있는지, 그리고 무엇이 그것을 강력하게 만드는지 진정으로 이해하고 싶다면 기초 수준으로 내려 가야합니다.
우리는 이미 바이너리와 데이터 를 비트와 바이트로 나눌 수있는 방법에 대해 배웠습니다 . 문자, 숫자, 단어, 문장을 나타 내기 위해 메모리 바이트가 필요한 것처럼 데이터 구조도 마찬가지입니다.
때 배열 생성되고, 이는 일정량의 메모리를 필요로한다. 배열에 저장해야하는 7 개의 문자가있는 경우 해당 배열을 나타내는 데 7 바이트의 메모리가 필요합니다. 그러나 하나의 연속 된 블록에 모든 메모리 가 필요합니다 . 즉, 우리의 컴퓨터는 한곳에서 한 바이트 옆에있는 7 바이트의 메모리를 모두 함께 찾아야합니다.
반면에 연결 목록 이 생성 되면 한곳에 7 바이트의 메모리가 모두 필요하지 않습니다. 한 바이트는 어딘가에있을 수 있고 다음 바이트는 모두 메모리의 다른 위치에 저장 될 수 있습니다! 연결된 목록은 단일 메모리 블록을 차지할 필요가 없습니다. 대신, 그들이 사용하는 메모리는 흩어져 수 있습니다 .
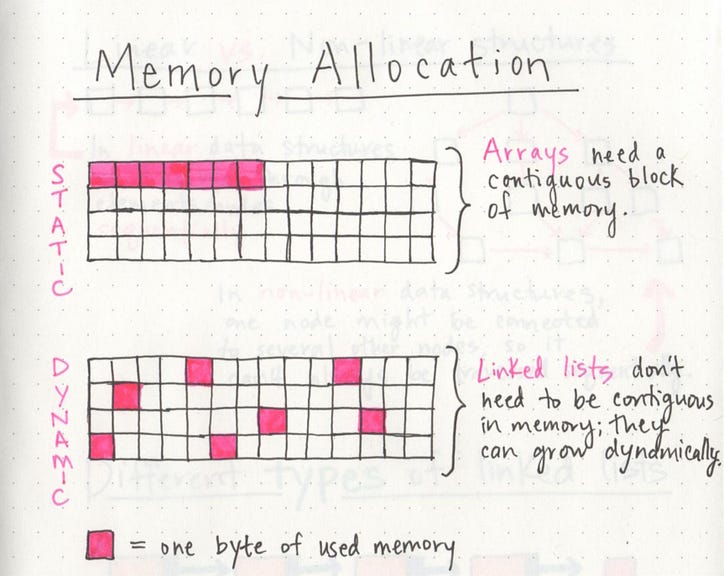
배열과 연결 목록의 근본적인 차이점은 배열 은 정적 데이터 구조 이고 연결 목록 은 동적 데이터 구조라는 것 입니다. 정적 데이터 구조는 구조가 생성 될 때 모든 리소스를 할당해야합니다. 즉, 구조가 크기가 커지거나 줄어들고 요소가 추가되거나 제거 되더라도 항상 주어진 크기와 양의 메모리가 필요합니다. 정적 데이터 구조에 더 많은 요소를 추가해야하는데 메모리가 충분하지 않은 경우, 예를 들어 해당 배열의 데이터를 복사하고 더 많은 메모리로 다시 생성하여 요소를 추가 할 수 있습니다. 그것.
반면에 동적 데이터 구조는 메모리에서 축소 및 증가 할 수 있습니다. 존재하기 위해 일정량의 메모리를 할당 할 필요가 없으며 크기와 모양이 변경 될 수 있으며 필요한 메모리의 양도 변경 될 수 있습니다.
이제 우리는 이미 배열과 연결 목록 간의 몇 가지 주요 차이점을 볼 수 있습니다. 그러나 이것은 질문을 불러 일으킨다. 연결된 목록이 모든 곳에 흩어져있는 메모리를 가질 수있게하는 것은 무엇인가? 이 질문에 답하려면 연결 목록이 구성되는 방식을 살펴 봐야합니다.
연결 목록의 일부
연결 목록은 작거나 클 수 있지만 크기에 관계없이 구성하는 부분은 실제로 매우 간단합니다. 연결 목록은 목록 의 요소 인 일련의 노드 로 구성됩니다.
목록의 시작점은 head 라고하는 첫 번째 노드에 대한 참조 입니다. 거의 모든 연결 목록에는 헤드가 있어야합니다. 왜냐하면 이것은 효과적으로 목록과 모든 요소에 대한 유일한 진입 점이기 때문이며, 그것이 없으면 어디서부터 시작해야할지 알 수 없습니다! 목록의 끝은 노드가 아니라 null 또는 빈 값 을 가리키는 노드입니다 .
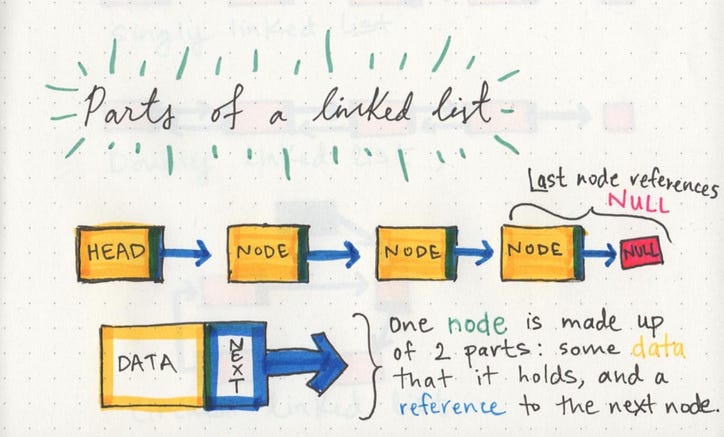
단일 노드도 매우 간단합니다. 여기에는 data 또는 노드에 포함 된 정보와 다음 노드에 대한 참조의 두 부분 만 있습니다 .
우리가 이것으로 머리를 감쌀 수 있다면, 우리는 거기에있는 것입니다. 노드가 작동하는 방식은 매우 중요하고 강력하며 다음과 같이 요약 할 수 있습니다.
노드는 포함 된 데이터와 인접 항목 만 알고 있습니다.
단일 노드는 연결 목록의 길이를 알지 못하며, 시작 위치 또는 끝 위치를 반드시 알지 못할 수도 있습니다. 관련된 모든 노드는 포함 된 데이터와 포인터가 참조하는 노드 인 목록의 다음 노드입니다.
그리고 이것은 매우 이유는 왜 연결리스트는 메모리의 연속 된 블록을 필요로하지 않는다은. 단일 노드에는 "주소"또는 다음 노드에 대한 참조가 있기 때문에 요소가 배열에 있어야하는 방식으로 서로 바로 옆에있을 필요가 없습니다. 대신 다음 노드에 대한 포인터 참조에 기대어 목록을 순회 할 수 있다는 사실에 의존 할 수 있습니다. 즉, 목록을 나타 내기 위해 시스템이 단일 메모리 청크를 차단할 필요가 없음을 의미합니다.
이것은 또한 연결된 목록이 프로그램 실행 중에 동적으로 늘어나고 줄어들 수있는 이유에 대한 설명이기도합니다. 연결된 목록으로 노드를 추가하거나 제거하는 것은 배열의 요소를 복사하는 대신 포인터를 재배 열하는 것처럼 간단합니다! 그러나 연결 목록에는 아직 언급하지 않은 몇 가지 단점이 있지만 다음 주에 더 자세히 설명합니다.
지금은 연결 목록이 얼마나 멋진 지 영광을 누릴 것입니다!
모든 모양과 크기에 대한 목록
연결 목록의 일부는 변경되지 않지만 연결 목록을 구성하는 방식은 상당히 다를 수 있습니다. 소프트웨어의 대부분과 마찬가지로 해결하려는 문제에 따라 한 유형의 연결 목록이 다른 유형보다 작업에 더 나은 도구가 될 수 있습니다.
단일 연결 목록 은 한 방향으로 만 이동한다는 사실만을 기반으로하는 가장 간단한 연결 목록 유형입니다. 목록을 탐색 할 수있는 단일 트랙 이 있습니다. 헤드 노드에서 시작하여 루트에서 마지막 노드까지 순회하면 빈 null 값으로끝납니다.
그러나 노드가 후속 인접 노드를 참조 할 수있는 것처럼 이전 노드에 대한 참조 포인터도 가질 수 있습니다! 각 노드 내에 두 개의 참조가 포함되어 있기 때문에 이를 이중 연결 목록 이라고 합니다. 다음 노드와 이전 노드에 대한 참조입니다. 이것은 우리가 데이터 구조를 단일 트랙이나 방향뿐만 아니라 뒤로 이동할 수 있기를 원할 때 유용 할 수 있습니다.
예를 들어 목록 의 맨 처음으로 돌아갈 필요없이 한 노드와 이전 노드 사이를 홉핑 할 수 있도록하려면 이중 연결 목록이 단일 연결 목록보다 더 나은 데이터 구조가 될 것입니다. 그러나 모든 것이 공간과 메모리를 필요로하므로 노드가 하나가 아닌 두 개의 참조 포인터를 저장해야한다면 고려해야 할 또 다른 사항이 될 것입니다.
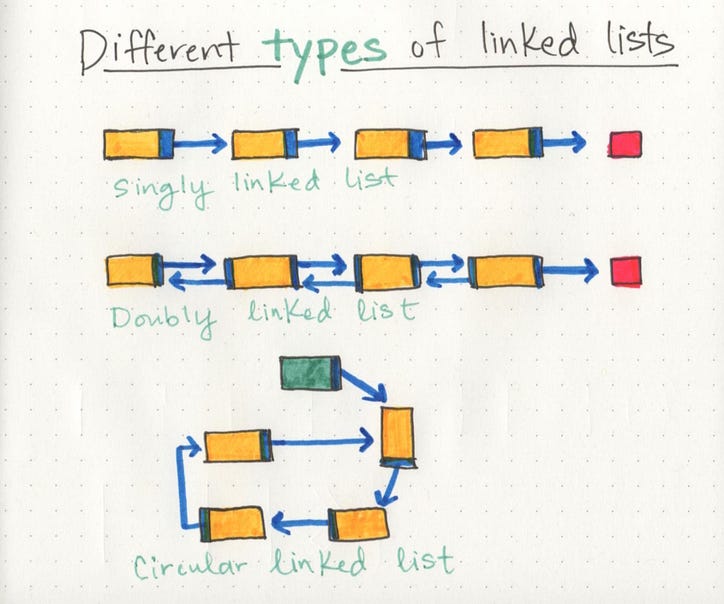
원형 연결 목록은 그것이 NULL 값에 노드를 가리키는으로 끝나지 않는 것을 조금 홀수이다. 대신 목록 의 꼬리 역할을하는 노드 (기존의 헤드 노드가 아닌)가 있으며 꼬리 노드 뒤의 노드가 목록의 시작입니다. 이 조직 구조는 첫 번째 요소와 마지막 요소가 서로를 가리 키기 때문에 꼬리 노드 에서 탐색을 시작할 수 있기 때문에 목록 끝에 무언가를 추가하기가 정말 쉽습니다 . 순환 연결 목록은 단일 연결 목록과 이중 연결 목록 을 모두 순환 연결 목록 으로 바꿀 수 있기 때문에 정말 미쳐 버릴 수 있습니다 !
그러나 연결 목록이 아무리 복잡하더라도 노드의 기본 사항과 작동 방식, 목록의 다른 포인터 참조가 구조화되는 방식을 기억할 수 있다면 해결할 수없는 연결 목록이 없습니다!
다음 주,이 시리즈의 2 부에서는 연결 목록의 시공간 복잡성과 이들이 사촌 인 배열과 비교하는 방식에 대해 알아볼 것입니다. 나는 그것이 실제로 들리는 것보다 훨씬 더 재미 있다고 약속합니다!
자원
연결된 목록이 매우 멋지다고 생각한다면 다음 유용한 리소스를 확인하세요.
- 배열과 연결된 목록의 차이점 , Damien Wintour
- 데이터 구조 : 배열 vs 연결 목록 , mycodeschool
- 연결된 목록 : 기본 , Edward Gehringer 박사
- 링크 된 목록 소개 , Victor Adamchik 박사
- 데이터 구조 및 구현 , Jennifer Welch 박사
- 정적 데이터 구조 대 동적 데이터 구조 , Ayoma Gayan Wijethunga