BARD VS ChatGPT: 분석 문제 테스트

연결할 수 있습니다 :| 링크드인 | 트위터 | 미디엄 | 하위 스택 |
5월 10일, ChatGPT에 대한 Google의 가장 강력한 경쟁자인 BARD가 인도에서 생중계되었습니다. 내 매력 때문에 Bard와 ChatGPT를 비교하는 것을 멈출 수 없었습니다. 여기에 몇 가지 멋진 비교가 있습니다.
이 블로그에서는 GPT 3 기반 chatGPT 와 GPT4가 아닌 BARD를 비교하고 있습니다 .Google Bard와 ChatGPT는 모두 대규모 언어 모델이지만 몇 가지 중요한 차이점이 있습니다. Google Bard는 규모가 더 크고 더 다양한 데이터 세트에 대한 교육을 받아 더 넓은 범위의 지식과 능력을 제공합니다. ChatGPT는 더 작고 더 제한된 데이터 세트에 대해 교육을 받았기 때문에 정확성과 창의성이 떨어집니다. 그러나 ChatGPT는 Google Bard보다 저렴하고 더 널리 사용됩니다.
다음은 Google Bard와 ChatGPT를 비교한 표입니다.
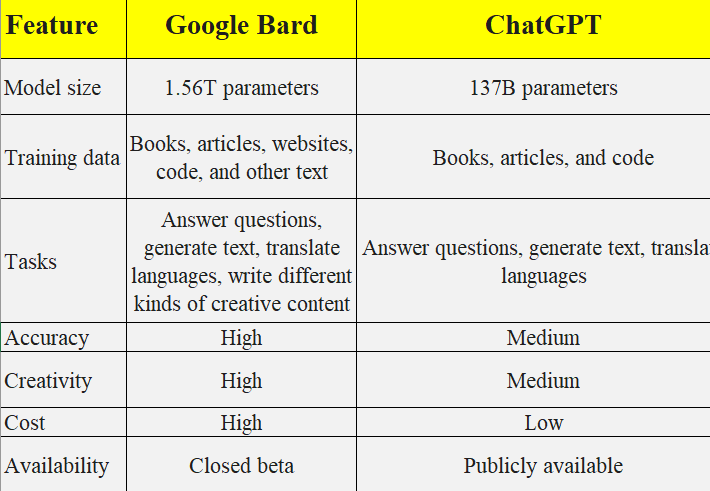
충분한 이론과 주장. 실제 결과를 확인해보자.
(진짜) 비교:
수많은 비교 방법이 있지만, 나는 분석 능력 의 비교를 선호하는 경향이 있습니다 . 분석 기술은 인간과 시스템 사이의 주요 구별 요소입니다. 사고 과정을 구성하고, 추론에 참여하고, 이후에 질문에 답하는 것은 언어 모델에 더 큰 도전이 될 수 있기 때문입니다. 결과를 검토해 봅시다.
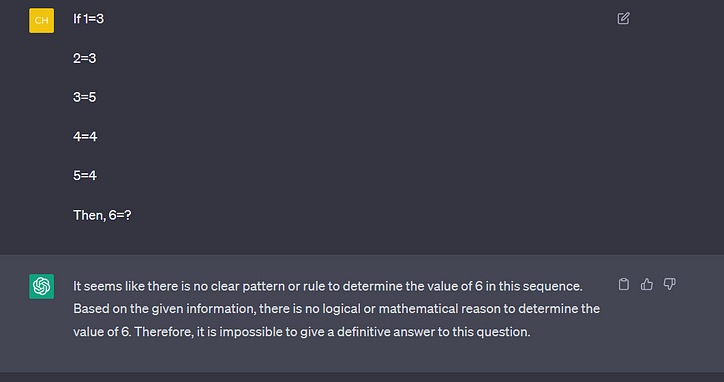
질문 1:
- 1=3, 2=3, 3=5, 4=4, 5=4이면 6=?
채팅GPT
음유 시인
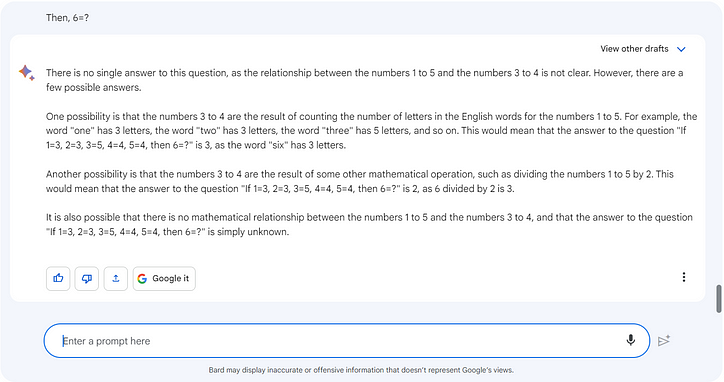
ChatGPT는 숫자 간의 관계를 이해할 수 없습니다. BARD가 힘들어도 1문단에서 BARD가 제대로 대답해줬다.
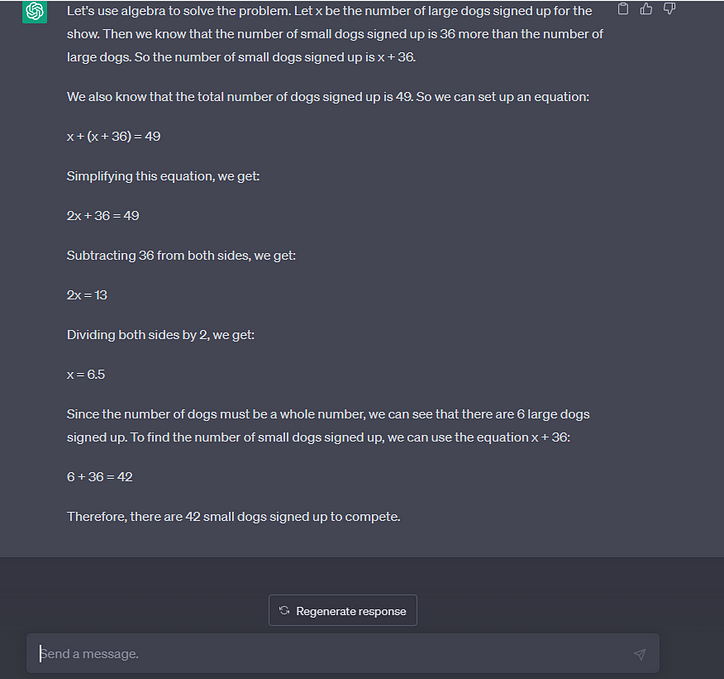
질문 2:
도그 쇼에 등록된 개는 49마리입니다. 대형견보다 소형견이 36마리 더 많습니다. 얼마나 많은 작은 개들이 대회에 등록했습니까?
대답: 몇 마리의 작은 개가 경쟁하는지 알아내려면 49에서 36을 뺀 다음 그 답인 13을 2로 나누어 6.5마리의 개, 즉 경쟁하는 대형견의 수를 구해야 합니다. 하지만 아직 끝나지 않았습니다! 그런 다음 6.5에서 36을 더해 경쟁하는 소형견의 수인 42.5를 구해야 합니다. 물론 반 마리의 개가 도그 쇼에서 경쟁하는 것은 실제로 가능하지 않지만 이 수학 문제를 위해 가능하다고 가정해 봅시다.
채팅GPT
음유 시인
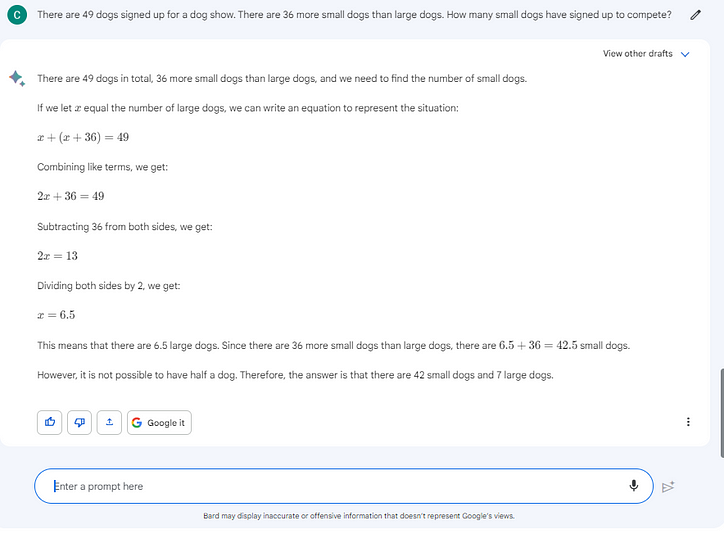
이 질문에서 두 모델 모두 잘 작동했습니다. 둘 다 답변 작업에 대한 좋은 추론과 COT를 얻었습니다.
질문 3:
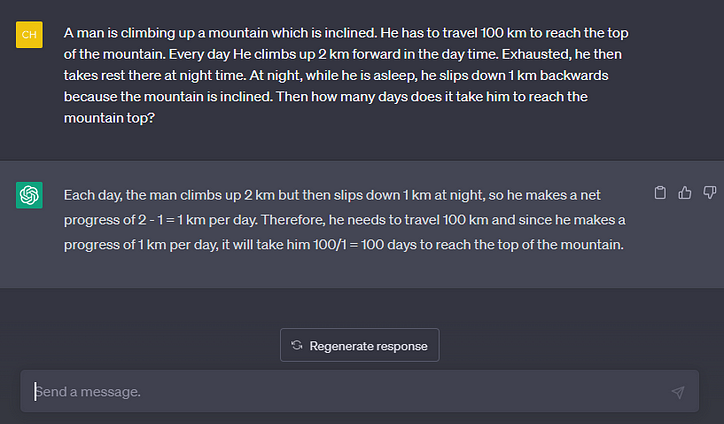
한 남자가 경사진 산을 오르고 있다. 그는 산 정상에 도달하기 위해 100km를 여행해야 합니다. 매일 그는 낮에 2km를 앞으로 올라갑니다. 지친 그는 밤에 그곳에서 휴식을 취합니다. 밤에 잠을 잘 때 산이 기울어져 1km 뒤로 미끄러진다. 그러면 그가 산 정상에 도달하는 데 며칠이 걸립니까?
답변:첫날 높이 2km 달성
1박 -1km
2일차 시작 시 효과적인 등반은 1km입니다.
2일차 높이 3km 달성
2박 -1km
3일차 시작 시 유효 등반 거리는 2km입니다.
곧…
98일 시작 시 효과적인 등반은 97km입니다.
98일 높이 99km 달성
98일 밤 -1km
99일 시작 시 효과적인 상승은 98km입니다.
99일째 달성한 고도는 100km
채팅GPT
음유 시인
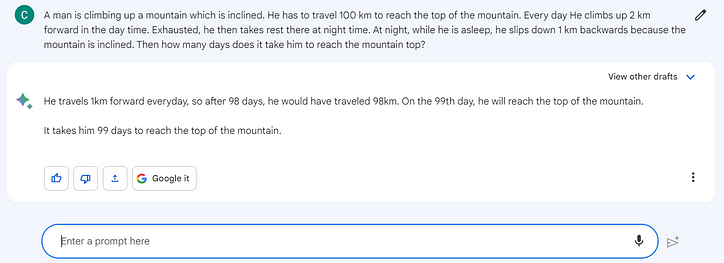
이 문제에서는 BARD가 해냈습니다. GPT가 이해할 수 없는 트릭이 있었습니다.
질문 4:
세 사람은 각각 1/3의 시간 동안 거짓말을 하는 경향이 있습니다. 그들이 모두 보는 동전 던지기가 있습니다. 그들은 모두 그것이 머리라고 말합니다. 실제로 앞면일 확률은 얼마입니까?
답변: 일반적으로 (1/3)*(1/3)*(1/3) = 모두 거짓말을 할 확률이 1/27이고 (2/3)*(2/3)*(2 /3) = 그들 모두가 진실을 말했을 확률 8/27. 그들 모두가 같은 대답을 했다는 것을 알고 있기 때문에 이것이 유일한 두 가지 선택입니다. 따라서 앞면(모두 진실을 말함)일 확률은 (8/27)/((8/27)+(1/27)) = 8/9입니다.
채팅GPT
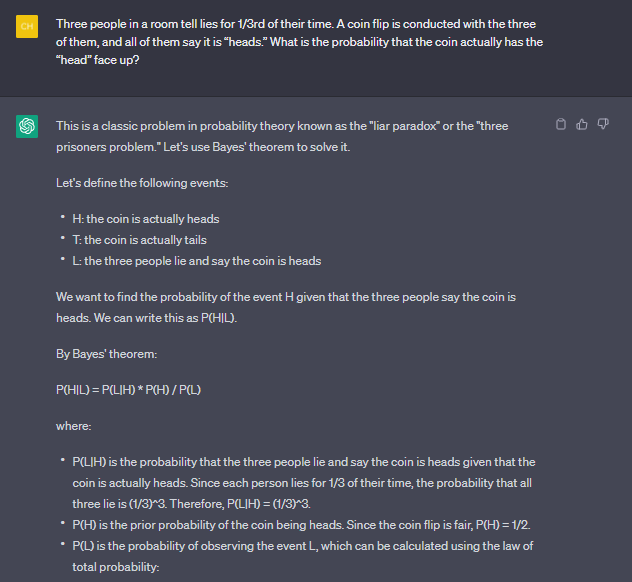
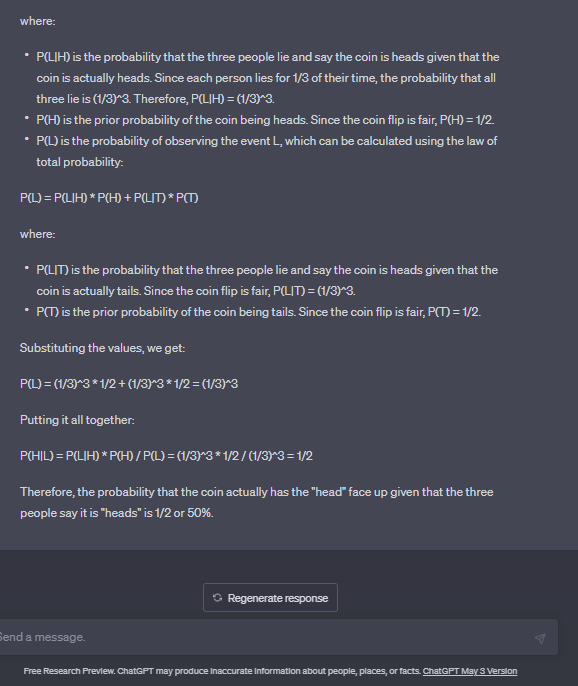
음유 시인
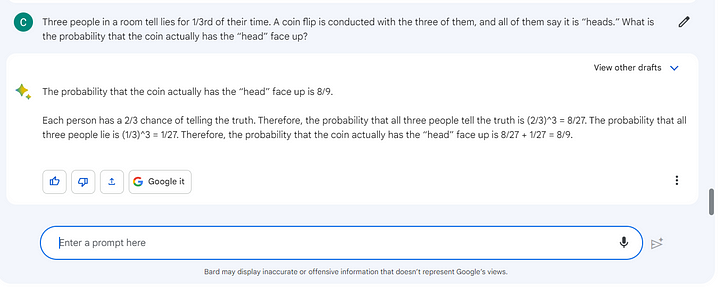
흥미로운! 확률 게임!!! 다시 BARD가 잘 대답했습니다.
마찬가지로 분석 수학에 대한 많은 질문을 테스트했으며 BARD가 주장한 대로 우수하다는 것을 알았습니다 . 그래도 GPT3를 GPT 4로 대체할 때는 이야기가 달라질 수 있습니다. 같은 형식의 BARD와 GPT4의 전투. 나는 그 비교를 곧 수행 할 것이다.
궁극적으로 귀하에게 가장 적합한 선택은 특정 요구 사항과 요구 사항에 따라 달라집니다. 광범위한 지식과 능력을 갖춘 대규모 언어 모델이 필요한 경우 Google Bard가 더 나은 선택입니다. 더 작고 저렴한 언어 모델을 찾고 있다면 ChatGPT가 좋은 선택입니다 .
틈새 및 문서 성능에 따라 두 모델을 모두 테스트할 수 있습니다.
ChatGPT: 여기를 클릭하세요
바드: 여기를 클릭하세요
이 기사가 통찰력있는 것을 발견했다면
" 너그러움은 당신을 더 행복한 사람으로 만든다 " 는 것은 입증된 사실입니다 . 따라서 기사가 마음에 들면 박수를 보내십시오. 이 기사가 통찰력이 있다면 Linkedin 및 매체 에서 저를 팔로우하십시오 . 내가 기사를 게시할 때 알림을 받도록 구독 할 수도 있습니다 . 커뮤니티를 만들자! 지원해 주셔서 감사합니다!
다음과 관련된 다른 블로그를 읽을 수 있습니다.
대규모 언어 모델 마스터링: 1부 LLM 모델 미세 조정을 위해 데이터를 SQuAD 형식으로 변환크리에이티브 AI 공간의 최신 뉴스와 업데이트를 받아보세요. Generative AI 간행물을 팔로우하세요.

![연결된 목록이란 무엇입니까? [1 부]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































