따라서 연결된 목록에 대해 알려주세요.

최근 코딩 부트 캠프를 졸업 한 저는 기본적인 지식을 향상시키기 위해 데이터 구조와 알고리즘을 깊이 연구했습니다. 연결된 목록은 비교적 단순한 데이터 구조이지만 앞으로 나아가는 더 복잡한 데이터 구조의 기초입니다. 이 기사에서는 링크드리스트의 강점, 약점 및 구현 방법에 대해 설명합니다.
데이터 구조는 간단히 말해서 데이터를 효율적으로 구성하고 보관하는 방법입니다.
데이터 구조 란?
데이터 구조는 간단히 말해서 데이터를 효율적으로 구성하고 보관하는 방법입니다. 이를 통해 나중에 액세스 할 수 있도록 정보를 보유 할 수 있습니다. 특정 항목을 검색하거나 특정 순서를 갖도록 정렬하거나 대규모 데이터 세트를 관리 할 수도 있습니다. 자바 스크립트에는 여러분이 매우 익숙한 배열과 객체의 데이터 구조가 있습니다. 이들은 언어에 고유 한 기본 데이터 구조입니다. 기본이 아닌 데이터 구조는 프로그래머가 정의한 데이터 구조입니다. 예를 들면 스택, 큐, 트리, 그래프 및 해시 테이블이 있습니다.
연결된 목록이란 무엇입니까?
연결 목록은 요소를 순차적으로 보유하는 선형 데이터 구조입니다. 익숙한가요? 그것들은 배열과 유사하지만 완전히 동일하지는 않습니다. 배열은 인덱스 가 0입니다 . 즉, 각 인덱스는 값에 매핑 되고 배열의 첫 번째 요소는 인덱스 0에서 시작합니다. 인덱스를 알고있는 한 배열에서 요소를 쉽게 가져올 수 있습니다.
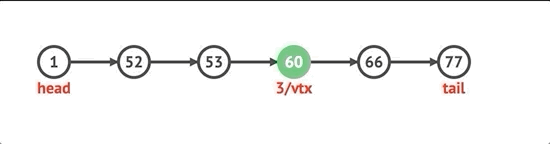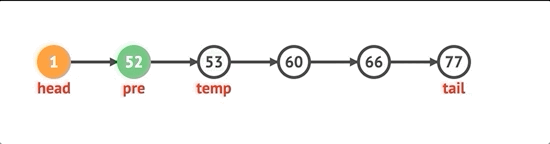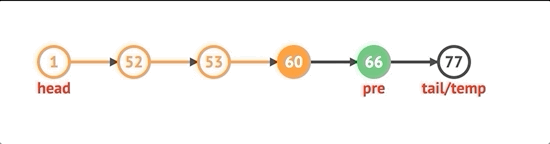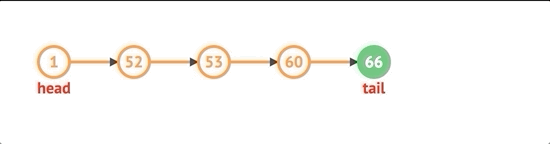
반면에 연결된 목록은 다른 노드 를 가리키는 노드로 구성 됩니다. 각 노드는 자신과 다음 노드 만 알고 있습니다. 선형 데이터 구조로서 항목은 순서대로 정렬됩니다. 기차로 생각할 수 있습니다. 각 철도 차량은 다음 철도 차량에 연결되어 있습니다. 연결된 목록은 색인이 생성 되지 않으므로 5 번째 요소에 직접 액세스 할 수 없습니다. 5 번째 요소를 찾을 때까지 처음부터 시작하여 다음으로 이동하고 다음으로 이동해야합니다. 첫 번째 노드를 머리라고하고 마지막 노드를 꼬리라고합니다. 연결 목록에는 단일 연결 목록, 이중 연결 목록, 순환 연결 목록 등 다양한 유형이 있습니다. 이 기사에서는 단일 연결 목록에 초점을 맞출 것입니다.
배열 전체의 요소에 액세스하는 것이 더 쉽지만 비용이 발생합니다.
배열에 연결된 목록을 사용하는 이유는 무엇입니까?
궁금 할 것입니다.하지만 배열을 사용하여 요소에 직접 액세스 할 수 있다면 왜 이것을 사용합니까? 사실입니다! 배열 전체의 요소에 액세스하는 것이 더 쉽지만 비용이 발생합니다.
배열이되어 색인 - 당신은 처음이나 중간에서 요소를 제거해야 할 때마다 그래서, 모두 다음과 같은 지표가 이동 될 필요가있다. 요소를 삽입해야하는 경우에도 마찬가지입니다. 모든 다음 요소는 다시 색인화되어야합니다. 연결 목록에서 요소를 삽입하거나 제거 할 때 색인을 다시 생성 할 필요가 없습니다. 중요한 것은 가리키는 노드뿐입니다 .
단일 연결 목록 구현
연결 목록에는 단일, 이중 및 순환 등 다양한 유형이 있습니다. 단일 연결 목록은 각 노드에 값과 다음 노드에 대한 포인터가있는 연결 목록 유형입니다 (꼬리 노드 인 경우 null). 반면에 이중 연결 목록에는 이전 노드에 대한 추가 포인터가 있습니다. 순환 연결 목록은 꼬리 노드가 다시 헤드 노드를 가리키는 곳입니다.
참고 : 시각적 학습자 인 경우 VisuAlgo 는 놀면서 데이터 구조가 변경되는 것을 볼 수있는 좋은 장소입니다.
전체 코드를 건너 뛰려면이 GitHub 요점을 확인하세요 .
노드 생성
사용할 노드를 구축하는 것으로 시작하겠습니다. 값과 다음 포인터 를 갖게되며 , 이는 후속 이웃을 나타냅니다.
class Node {
constructor(val) {
this.val = val;
this.next = null;
}
}
SinglyLinkedList라는 클래스를 작성하여 시작하여 목록의 머리, 꼬리 및 길이에 대한 기초를 제공합니다.
class SinglyLinkedList {
constructor() {
this.head = null;
this.tail = null;
this.length = 0;
}
}
끝에 노드를 추가하기 위해 목록에 이미 선언 된 헤드가 있는지 확인합니다. 그렇지 않은 경우 머리와 꼬리를 새로 만든 노드로 설정합니다. head 속성이 이미있는 경우 tail의 다음 속성을 새 노드로 설정하고 tail 속성을 새 노드로 설정합니다. 길이를 1 씩 늘립니다.
push(val) {
var newNode = new Node(val)
if (!this.head) {
this.head = newNode
this.tail = newNode
} else {
this.tail.next = newNode
this.tail = newNode
}
this.length++;
return this;
}
마지막에 노드를 제거하려면 먼저 목록에 노드가 있는지 확인해야합니다. 노드가 있으면 꼬리에 도달 할 때까지 목록을 반복해야합니다. 두 번째에서 마지막 노드까지의 다음 속성을 null로 설정하고 tail 속성을 해당 노드로 설정하고 길이를 1만큼 줄인 다음 제거 된 노드의 값을 반환합니다.
pop() {
if (!this.head) return undefined;
var current = this.head
var newTail = current
while (current.next) {
newTail = current
current = current.next;
}
this.tail = newTail;
this.tail.next = null;
this.length--;
if (this.length === 0) {
this.head = null;
this.tail = null;
}
return current;
}
처음부터 노드를 제거하려면 목록에 노드가 있는지 확인합니다. 현재 헤드 속성을 변수에 저장하고 헤드를 현재 헤드의 다음 노드로 설정합니다. 길이를 1만큼 줄이고 제거 된 노드의 값을 반환합니다.
shift() {
if (!this.head) return undefined
var oldHead = this.head;
this.head = oldHead.next;
this.length--
if (this.length===0) {
this.head = null;
this.tail = null;
}
return oldHead
}
처음에 노드를 추가하려면 먼저 노드를 만들고 목록에 head 속성이 있는지 확인합니다. 그렇다면 새로 생성 된 노드의 다음 속성을 현재 헤드로 설정하고 헤드를 새 노드로 설정 한 다음 길이를 늘립니다.
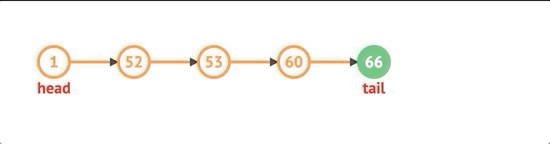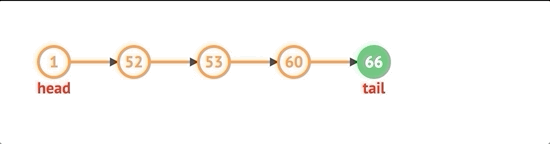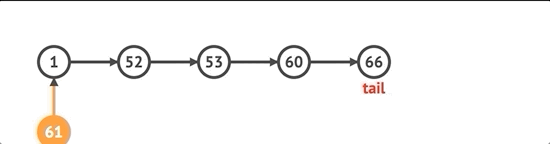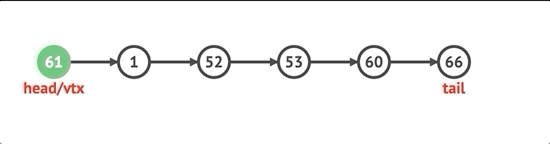
unshift(val) {
var newNode = new Node(val)
if (!this.head) {
this.head = newNode;
this.tail = newNode;
} else {
newNode.next = this.head;
this.head = newNode;
}
this.length++
return this
}
목록에서의 위치를 기준으로 노드에 액세스하려면 먼저 인덱스가 유효한 인덱스인지 확인합니다. 그런 다음 카운터 변수를 유지하면서 목록을 반복합니다. 카운터 변수가 인덱스와 일치하면 찾은 노드를 반환합니다.
get(idx) {
if (idx < 0 || idx >= this.length) return null
var counter = 0;
var current = this.head
while (counter !== idx) {
current = current.next;
counter++;
}
return current;
}
위치에 따라 노드를 변경하려면 먼저 get 메소드를 사용하여 노드를 찾고 값을 새 값으로 설정합니다.
set(idx, val) {
var foundNode = this.get(idx)
if (foundNode) {
foundNode.val = val
return true;
}
return false;
}
노드를 삽입하려면 먼저 인덱스를 확인합니다. 0과 같으면 unshift 방법을 사용합니다. 길이와 같으면 목록에 넣습니다. 그렇지 않으면 인덱스보다 작은 get 메서드를 사용하여 before 노드를 얻습니다. 기본적으로 포인터가 올바른 노드로 향하도록하기 위해 선택한 인덱스 전후의 노드를 추적해야합니다.
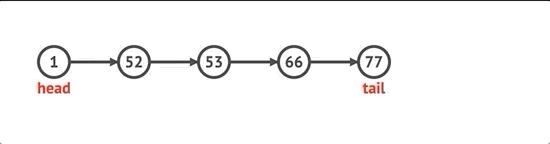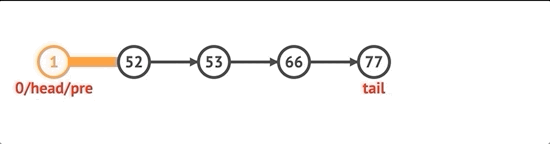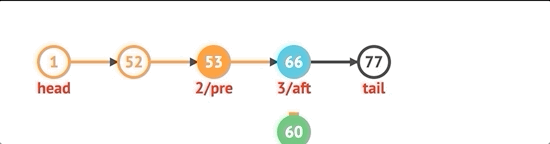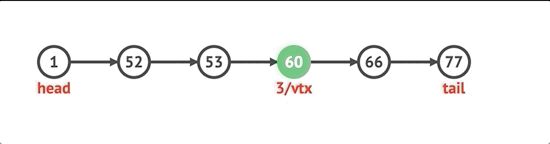
insert(idx, val) {
if (idx < 0 || idx > this.length) return false;
if (idx === 0) {
this.unshift(val)
return true;
};
if (idx === this.length) {
this.push(val);
return true;
};
var newNode = new Node(val);
var beforeNode = this.get(idx-1);
var afterNode = beforeNode.next;
beforeNode.next = newNode;
newNode.next = afterNode;
this.length++;
return true;
}
위치를 기준으로 노드를 제거하려면 get 메서드를 다시 사용하고 노드 삽입에 사용한 것과 동일한 원칙을 사용합니다. 선택한 인덱스 이전의 노드를 추적하여 포인터를 조작 할 수 있습니다.
remove(idx) {
if (idx < 0 || idx > this.length) return undefined;
if (idx === this.length-1) {
this.pop()
}
if (idx === 0) {
this.shift()
}
var prevNode = this.get(idx-1)
var removeNode = prevNode.next
prevNode.next = removeNode.next
this.length--;
return removeNode;
}
연결 목록의 강점
연결 목록 사용의 이점은 요소를 빠르게 삽입하고 제거 할 수 있다는 것입니다. 연결 목록은 인덱싱되지 않기 때문에 요소 삽입이 비교적 빠르고 쉽습니다.
연결 목록의 끝에 추가 하려면 이전 꼬리가 새 노드를 가리키고 꼬리 속성이 새 노드로 설정되어야합니다. 연결 목록의 시작 부분에 추가하는 것은 동일한 전제이지만 새 노드는 이전 헤드를 가리키고 헤드 속성은 새 노드로 설정됩니다. 기본적으로 동일한 동작이므로 삽입은 O (1)입니다.
참고 : 연결 목록 중간에 삽입하려면 노드 (O (N))를 찾기 위해 검색 한 다음 노드 (O (1))를 삽입해야합니다.
연결 목록에서 노드를 제거 하는 것은 쉽지만 그렇지 않습니다. 이것은 어디에 달려 있습니다. 목록의 시작 부분에서 노드를 제거하는 것은 간단합니다. 두 번째 노드가 새 헤드가되고 이전 헤드의 다음 포인터를 null로 설정합니다. 전체 목록을 살펴보고 두 번째에서 마지막 노드까지 중지해야하므로 끝에서 제거하는 것이 더 까다 롭습니다. 최악의 경우 O (N), 최상의 경우 O (1).
연결된 목록의 약점
연결 목록의 약점은 재 인덱싱이 없기 때문에 발생합니다. 요소에 직접 액세스 할 수 없기 때문에 요소 검색 및 액세스가 더 어려워집니다.
연결 목록에서 노드를 검색하고 액세스 하려면 목록의 시작 부분에서 시작하여 목록 아래의 이동 경로를 따라야합니다. 목록의 끝에서 노드를 검색하는 경우 전체 연결 목록을 살펴야하므로 시간 복잡도를 O (N)으로 만들 수 있습니다. 목록이 커지면 작업 수가 늘어납니다. 랜덤 액세스가있는 배열과 비교하여 요소에 액세스하는 데 일정한 시간이 걸립니다.
그게 다야!
연결 목록은 처음에 삽입 및 삭제가 핵심 작업 인 경우 배열에 대한 훌륭한 대안입니다. 배열은 인덱싱되지만 연결 목록은 그렇지 않습니다. 연결된 목록은 스택과 대기열이 구축되는 기본 데이터 구조이기도합니다. 이에 대해서는 이후 기사에서 설명하겠습니다. 여기까지 하셨다면, 당신에게 찬사를 보내고 프로그래밍 여정과 함께 약간의 너겟을 배웠기를 바랍니다!