Pandas Fusionando 101
- ¿Cómo realizar un (
INNER| (LEFT|RIGHT|FULL)OUTER)JOINcon pandas? - ¿Cómo agrego NaN para las filas que faltan después de la combinación?
- ¿Cómo me deshago de los NaN después de la fusión?
- ¿Puedo fusionarme en el índice?
- ¿Cruzar unirse con pandas?
- ¿Cómo fusiono varios DataFrames?
merge?join?concat?update? ¿OMS? ¿Qué? ¡¿Por qué?!
... y más. He visto estas preguntas recurrentes sobre varias facetas de la funcionalidad de fusión de pandas. La mayor parte de la información sobre la fusión y sus diversos casos de uso en la actualidad está fragmentada en docenas de publicaciones mal redactadas e inescrutables. El objetivo aquí es recopilar algunos de los puntos más importantes para la posteridad.
Esta QnA está destinada a ser la próxima entrega de una serie de útiles guías de usuario sobre modismos comunes de los pandas (consulte esta publicación sobre pivotar y esta publicación sobre concatenación , que abordaré más adelante).
Tenga en cuenta que esta publicación no pretende ser un reemplazo de la documentación , ¡así que léala también! Algunos de los ejemplos se toman de ahí.
Respuestas
Esta publicación tiene como objetivo brindar a los lectores una introducción a la fusión con sabor SQL con pandas, cómo usarlo y cuándo no usarlo.
En particular, esto es lo que atravesará esta publicación:
Conceptos básicos: tipos de uniones (IZQUIERDA, DERECHA, EXTERIOR, INTERIOR)
- fusionando con diferentes nombres de columna
- evitando la columna de clave de combinación duplicada en la salida
Fusión con índice en diferentes condiciones
- utilizando eficazmente su índice nombrado
- fusionar clave como índice de uno y columna de otro
Multiway se fusiona en columnas e índices (únicos y no únicos)
Alternativas a notables
mergeyjoin
Por lo que no pasará esta publicación:
- Debates y horarios relacionados con el rendimiento (por ahora). Sobre todo menciones notables de mejores alternativas, cuando corresponda.
- Manejo de sufijos, eliminación de columnas adicionales, cambio de nombre de salidas y otros casos de uso específicos. Hay otras publicaciones (léase: mejores) que tratan con eso, ¡así que descúbrelo!
Nota
La mayoría de los ejemplos utilizan de forma predeterminada las operaciones INNER JOIN mientras se muestran varias funciones, a menos que se especifique lo contrario.Además, todos los DataFrames aquí se pueden copiar y replicar para que pueda jugar con ellos. Además, vea esta publicación sobre cómo leer DataFrames desde su portapapeles.
Por último, toda la representación visual de las operaciones JOIN se ha dibujado a mano con Dibujos de Google. Inspiración de aquí .
Basta de hablar, ¡enséñame cómo usarlo merge!
Preparar
np.random.seed(0)
left = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': np.random.randn(4)})
right = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': np.random.randn(4)})
left
key value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right
key value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
En aras de la simplicidad, la columna clave tiene el mismo nombre (por ahora).
Una INNER JOIN está representada por
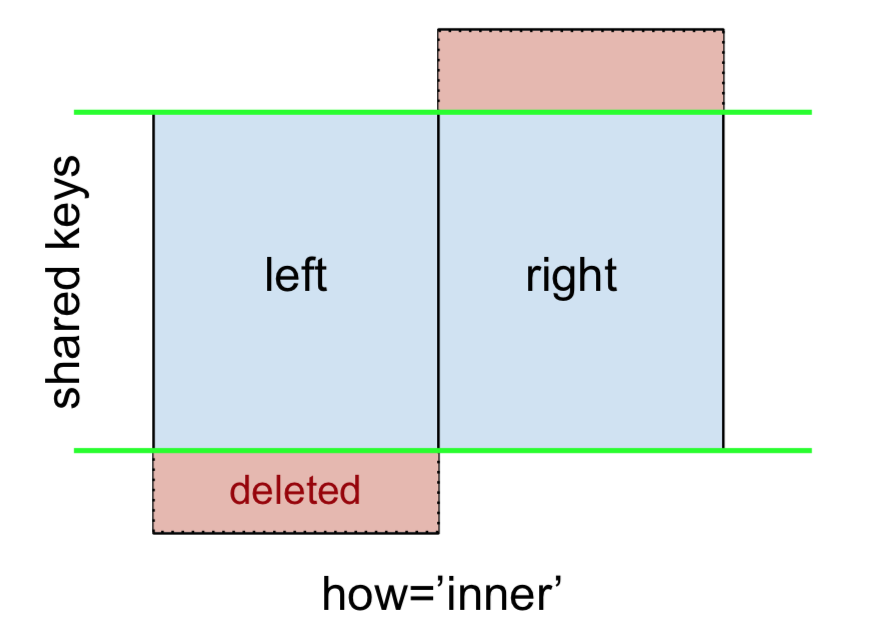
Tenga en cuenta que
esto, junto con las próximas cifras, siguen esta convención:
- azul indica filas que están presentes en el resultado de la combinación
- rojo indica filas que están excluidas del resultado (es decir, eliminadas)
- verde indica valores perdidos que se reemplazan con
NaNs en el resultado
Para realizar una INNER JOIN, llame mergeal DataFrame izquierdo, especificando el DataFrame derecho y la clave de combinación (como mínimo) como argumentos.
left.merge(right, on='key')
# Or, if you want to be explicit
# left.merge(right, on='key', how='inner')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
Esto devuelve solo filas de lefty rightque comparten una clave común (en este ejemplo, "B" y "D).
UN LEFT OUTER JOIN o LEFT JOIN está representado por
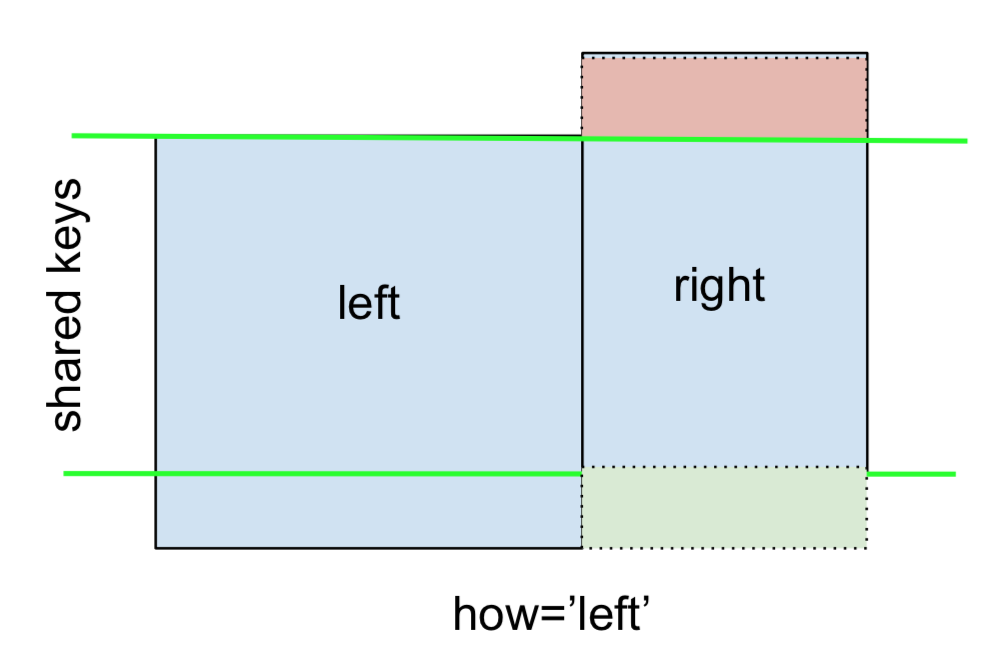
Esto se puede realizar especificando how='left'.
left.merge(right, on='key', how='left')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
Observe cuidadosamente la ubicación de los NaN aquí. Si lo especifica how='left', solo leftse utilizan las claves de y los datos faltantes de rightse reemplazan por NaN.
Y de manera similar, para un RIGHT OUTER JOIN , o RIGHT JOIN que es ...
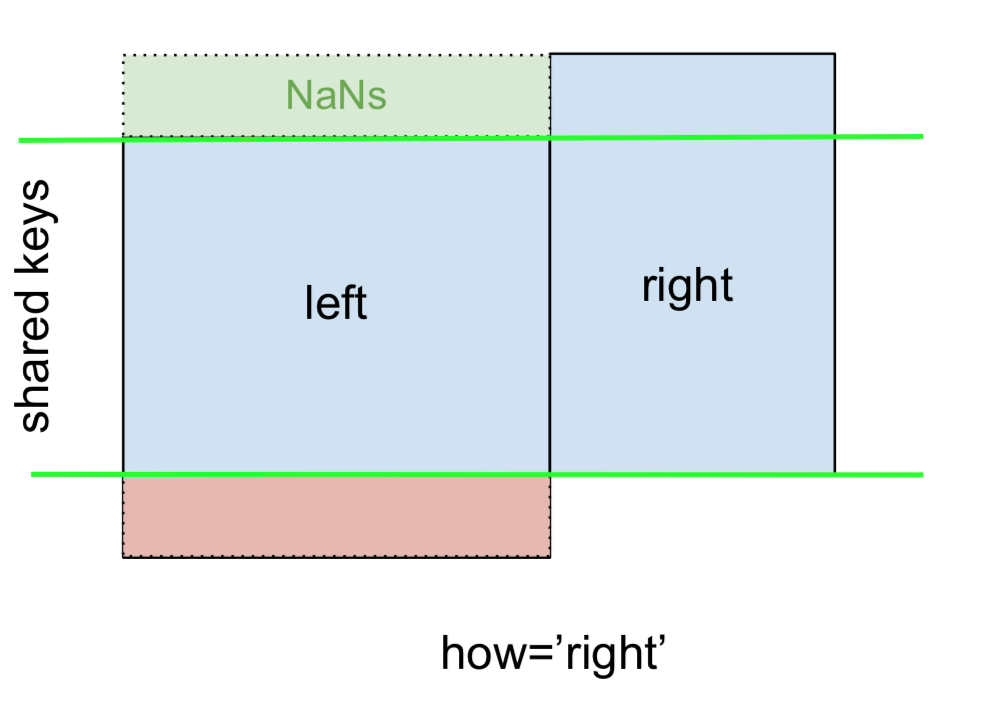
... especificar how='right':
left.merge(right, on='key', how='right')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
2 E NaN 0.950088
3 F NaN -0.151357
Aquí, rightse utilizan claves de y los datos faltantes de leftse reemplazan por NaN.
Finalmente, para el FULL OUTER JOIN , dado por
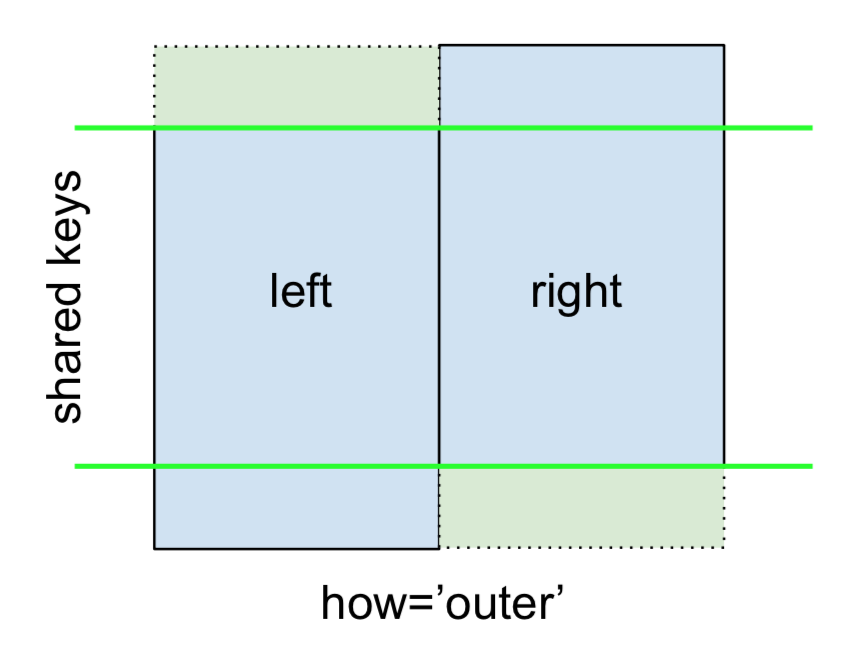
especificar how='outer'.
left.merge(right, on='key', how='outer')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
4 E NaN 0.950088
5 F NaN -0.151357
Esto usa las claves de ambos marcos y se insertan NaN para las filas faltantes en ambos.
La documentación resume muy bien estas diversas fusiones:

Otras UNIONES: IZQUIERDA-Excluyendo, DERECHA-Excluida y COMPLETA-Excluyendo / ANTI JOIN
Si necesita JOINs LEFT-Excluyendo y JOINs RIGHT-Excluyendo en dos pasos.
Para LEFT-Excluyendo JOIN, representado como
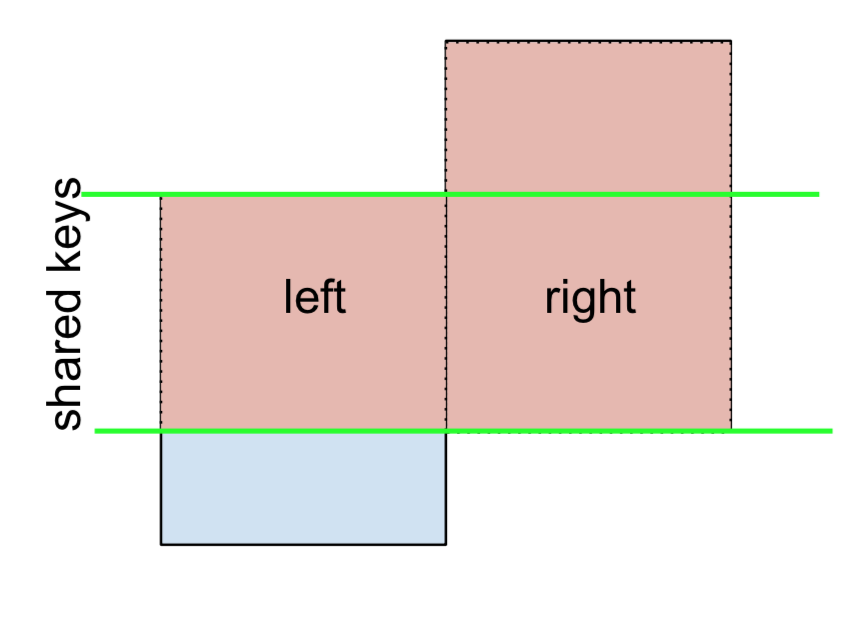
Comience realizando una LEFT OUTER JOIN y luego filtre (¡excluyendo!) Las filas que provienen leftsolo,
(left.merge(right, on='key', how='left', indicator=True)
.query('_merge == "left_only"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
Dónde,
left.merge(right, on='key', how='left', indicator=True)
key value_x value_y _merge
0 A 1.764052 NaN left_only
1 B 0.400157 1.867558 both
2 C 0.978738 NaN left_only
3 D 2.240893 -0.977278 bothY de manera similar, para un JOIN que excluye el DERECHO,
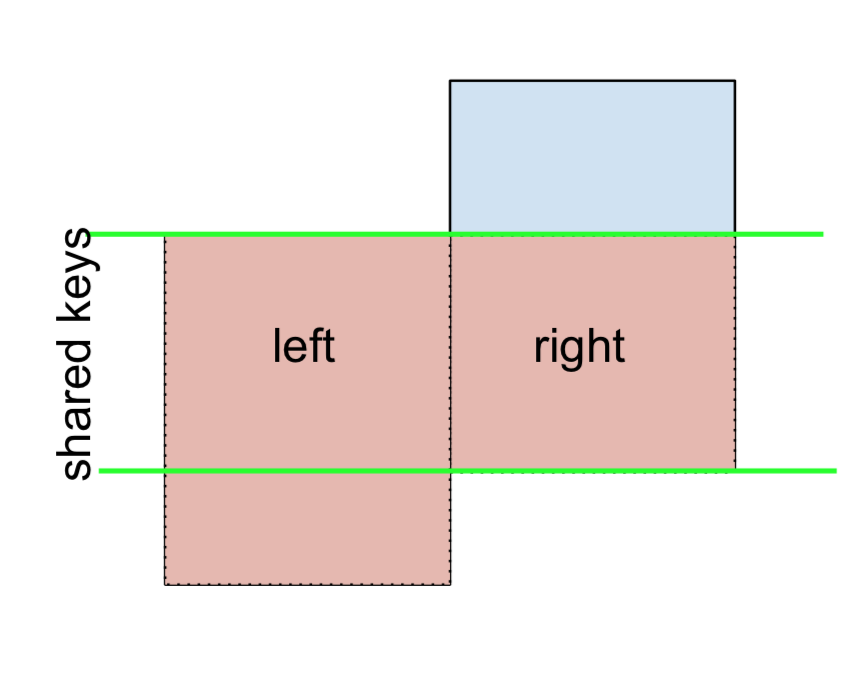
(left.merge(right, on='key', how='right', indicator=True)
.query('_merge == "right_only"')
.drop('_merge', 1))
key value_x value_y
2 E NaN 0.950088
3 F NaN -0.151357Por último, si debe realizar una combinación que solo retiene las claves de la izquierda o la derecha, pero no ambas (IOW, realizar un ANTI-JOIN ),
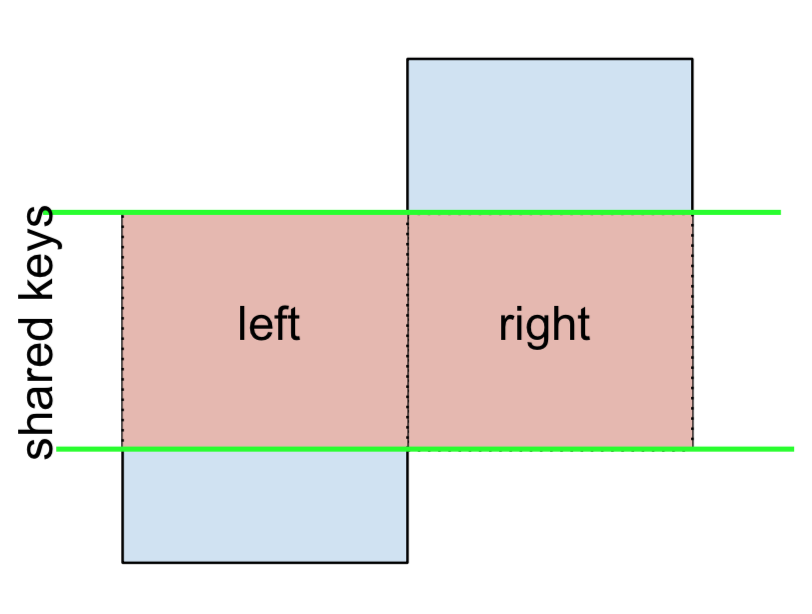
Puedes hacer esto de manera similar:
(left.merge(right, on='key', how='outer', indicator=True)
.query('_merge != "both"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
4 E NaN 0.950088
5 F NaN -0.151357
Diferentes nombres para columnas clave
Si las columnas de claves se nombran de manera diferente, por ejemplo, lefttiene keyLefty righttiene en keyRightlugar de, keyentonces tendrá que especificar left_ony right_oncomo argumentos en lugar de on:
left2 = left.rename({'key':'keyLeft'}, axis=1)
right2 = right.rename({'key':'keyRight'}, axis=1)
left2
keyLeft value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right2
keyRight value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')
keyLeft value_x keyRight value_y
0 B 0.400157 B 1.867558
1 D 2.240893 D -0.977278
Evitar la columna de clave duplicada en la salida
Al fusionar keyLeftdesde lefty keyRightdesde right, si solo desea uno de los keyLefto keyRight(pero no ambos) en la salida, puede comenzar estableciendo el índice como un paso preliminar.
left3 = left2.set_index('keyLeft')
left3.merge(right2, left_index=True, right_on='keyRight')
value_x keyRight value_y
0 0.400157 B 1.867558
1 2.240893 D -0.977278
Compare esto con la salida del comando justo antes (es decir, la salida de left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')), notará keyLeftque falta. Puede averiguar qué columna conservar en función del índice de fotograma establecido como clave. Esto puede ser importante cuando, por ejemplo, se realiza alguna operación OUTER JOIN.
Fusionando solo una columna de uno de los DataFrames
Por ejemplo, considere
right3 = right.assign(newcol=np.arange(len(right)))
right3
key value newcol
0 B 1.867558 0
1 D -0.977278 1
2 E 0.950088 2
3 F -0.151357 3
Si debe fusionar solo "new_val" (sin ninguna de las otras columnas), normalmente puede crear subconjuntos de columnas antes de fusionar:
left.merge(right3[['key', 'newcol']], on='key')
key value newcol
0 B 0.400157 0
1 D 2.240893 1
Si está haciendo una LEFT OUTER JOIN, una solución más eficaz implicaría map:
# left['newcol'] = left['key'].map(right3.set_index('key')['newcol']))
left.assign(newcol=left['key'].map(right3.set_index('key')['newcol']))
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
Como se mencionó, esto es similar, pero más rápido que
left.merge(right3[['key', 'newcol']], on='key', how='left')
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
Fusionar en varias columnas
Para unirse en más de una columna, especifique una lista para on(o left_ony right_on, según corresponda).
left.merge(right, on=['key1', 'key2'] ...)
O, en caso de que los nombres sean diferentes,
left.merge(right, left_on=['lkey1', 'lkey2'], right_on=['rkey1', 'rkey2'])
Otras merge*operaciones y funciones útiles
Fusionar un DataFrame con Series en el índice : consulte esta respuesta .
Además
merge,DataFrame.updateyDataFrame.combine_firsttambién se utilizan en determinados casos para actualizar un DataFrame con otro.pd.merge_orderedes una función útil para JOINs ordenados.pd.merge_asof(read: merge_asOf) es útil para combinaciones aproximadas .
Esta sección solo cubre los conceptos básicos y está diseñada para abrirle el apetito. Para más ejemplos y casos, consulte la documentación sobre merge, joinyconcat así como los enlaces a las especificaciones de función.
Basado en índice * -JOIN (+ columnas de índice merge)
Preparar
np.random.seed([3, 14])
left = pd.DataFrame({'value': np.random.randn(4)}, index=['A', 'B', 'C', 'D'])
right = pd.DataFrame({'value': np.random.randn(4)}, index=['B', 'D', 'E', 'F'])
left.index.name = right.index.name = 'idxkey'
left
value
idxkey
A -0.602923
B -0.402655
C 0.302329
D -0.524349
right
value
idxkey
B 0.543843
D 0.013135
E -0.326498
F 1.385076
Normalmente, una fusión en el índice se vería así:
left.merge(right, left_index=True, right_index=True)
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Soporte para nombres de índice
Si su índice tiene un nombre, los usuarios de la versión 0.23 también pueden especificar el nombre del nivel on(o left_ony right_onsegún sea necesario).
left.merge(right, on='idxkey')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Fusión en el índice de una, columna (s) de otra
Es posible (y bastante simple) utilizar el índice de uno y la columna de otro para realizar una fusión. Por ejemplo,
left.merge(right, left_on='key1', right_index=True)
O viceversa ( right_on=...y left_index=True).
right2 = right.reset_index().rename({'idxkey' : 'colkey'}, axis=1)
right2
colkey value
0 B 0.543843
1 D 0.013135
2 E -0.326498
3 F 1.385076
left.merge(right2, left_index=True, right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
En este caso especial, el índice para leftse nombra, por lo que también puede usar el nombre del índice con left_on, así:
left.merge(right2, left_on='idxkey', right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
DataFrame.join
Además de estos, hay otra opción sucinta. Puede usar DataFrame.joinqué valores predeterminados se unen en el índice. DataFrame.joinhace un LEFT OUTER JOIN de forma predeterminada, por lo que how='inner'es necesario aquí.
left.join(right, how='inner', lsuffix='_x', rsuffix='_y')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Tenga en cuenta que necesitaba especificar los argumentos lsuffixy rsuffixya que, de joinlo contrario, se produciría un error:
left.join(right)
ValueError: columns overlap but no suffix specified: Index(['value'], dtype='object')
Dado que los nombres de las columnas son los mismos. Esto no sería un problema si tuvieran otro nombre.
left.rename(columns={'value':'leftvalue'}).join(right, how='inner')
leftvalue value
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
pd.concat
Por último, como alternativa a las combinaciones basadas en índices, puede utilizar pd.concat:
pd.concat([left, right], axis=1, sort=False, join='inner')
value value
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Omita join='inner'si necesita un COMPLETO EXTERIOR JOIN (predeterminado):
pd.concat([left, right], axis=1, sort=False)
value value
A -0.602923 NaN
B -0.402655 0.543843
C 0.302329 NaN
D -0.524349 0.013135
E NaN -0.326498
F NaN 1.385076
Para obtener más información, consulte esta publicación canónica pd.concatde @piRSquared .
Generalización: mergeing múltiples DataFrames
A menudo, surge la situación cuando se deben fusionar varios DataFrames. Ingenuamente, esto se puede hacer encadenando mergellamadas:
df1.merge(df2, ...).merge(df3, ...)
Sin embargo, esto rápidamente se sale de control para muchos DataFrames. Además, puede ser necesario generalizar para un número desconocido de DataFrames.
Aquí presento pd.concatpara uniones de múltiples vías en claves únicas y DataFrame.joinpara uniones de múltiples vías en claves no únicas . Primero, la configuración.
# Setup.
np.random.seed(0)
A = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'valueA': np.random.randn(4)})
B = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'valueB': np.random.randn(4)})
C = pd.DataFrame({'key': ['D', 'E', 'J', 'C'], 'valueC': np.ones(4)})
dfs = [A, B, C]
# Note, the "key" column values are unique, so the index is unique.
A2 = A.set_index('key')
B2 = B.set_index('key')
C2 = C.set_index('key')
dfs2 = [A2, B2, C2]
Fusión múltiple en claves únicas (o índice)
Si sus claves (aquí, la clave podría ser una columna o un índice) son únicas, entonces puede usar pd.concat. Tenga en cuenta que se pd.concatune a DataFrames en el índice .
# merge on `key` column, you'll need to set the index before concatenating
pd.concat([
df.set_index('key') for df in dfs], axis=1, join='inner'
).reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# merge on `key` index
pd.concat(dfs2, axis=1, sort=False, join='inner')
valueA valueB valueC
key
D 2.240893 -0.977278 1.0
Omitir join='inner'para una UNIÓN EXTERIOR COMPLETA. Tenga en cuenta que no puede especificar uniones LEFT o RIGHT OUTER (si las necesita, utilice las que se joindescriben a continuación).
Fusión múltiple en claves con duplicados
concates rápido, pero tiene sus defectos. No puede manejar duplicados.
A3 = pd.DataFrame({'key': ['A', 'B', 'C', 'D', 'D'], 'valueA': np.random.randn(5)})
pd.concat([df.set_index('key') for df in [A3, B, C]], axis=1, join='inner')
ValueError: Shape of passed values is (3, 4), indices imply (3, 2)
En esta situación, podemos usar joinya que puede manejar claves no únicas (tenga en cuenta que se joinune a DataFrames en su índice; llama mergebajo el capó y hace un LEFT OUTER JOIN a menos que se especifique lo contrario).
# join on `key` column, set as the index first
# For inner join. For left join, omit the "how" argument.
A.set_index('key').join(
[df.set_index('key') for df in (B, C)], how='inner').reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# join on `key` index
A3.set_index('key').join([B2, C2], how='inner')
valueA valueB valueC
key
D 1.454274 -0.977278 1.0
D 0.761038 -0.977278 1.0
Una vista visual complementaria de pd.concat([df0, df1], kwargs). Tenga en cuenta que el significado de kwarg axis=0or axis=1no es tan intuitivo como df.mean()odf.apply(func)
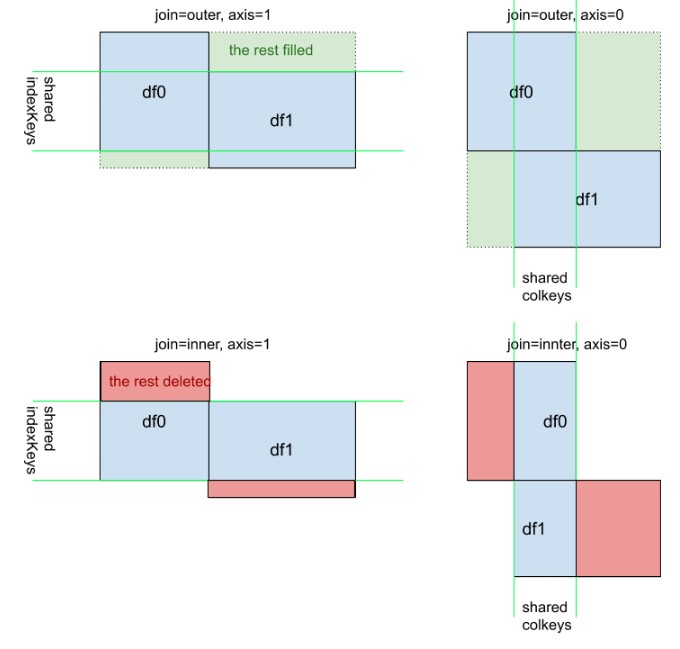
En esta respuesta, consideraré un ejemplo práctico de pandas.concat.
Considerando lo siguiente DataFramescon los mismos nombres de columna:
Preco2018 con talla (8784, 5)
Preco 2019 con talla (8760, 5)
Que tengan los mismos nombres de columna.
Puedes combinarlos usando pandas.concat, simplemente
import pandas as pd
frames = [Preco2018, Preco2019]
df_merged = pd.concat(frames)
Lo que da como resultado un DataFrame con el siguiente tamaño (17544, 5)

Si quieres visualizar, acaba funcionando así
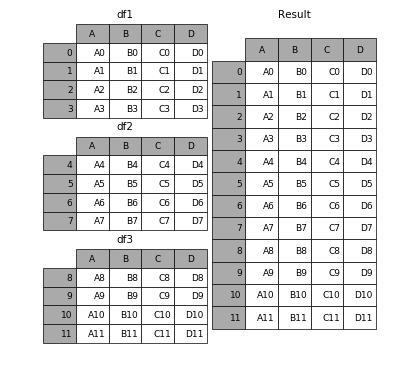
( Fuente )