डाटा इंजीनियरिंग मेड ईज़ी - हेड स्टार्ट योर ईटीएल टास्क के लिए पायथन स्क्रिप्ट संलग्न
अवलोकन:
डेटा इंजीनियर के काम को मान लें, फ़ाइल स्वरूपों के कई स्रोतों से डेटा निकालना, इसे विशेष डेटा प्रकारों में बदलना और विश्लेषण के लिए एकल स्रोत में लोड करना। जल्द ही इस लेख को पढ़ने के बाद, कई व्यावहारिक उदाहरणों की सहायता से, आप एपीआई के साथ वेब स्क्रैपिंग और डेटा निकालने को लागू करके अपने कौशल का परीक्षण करने में सक्षम होंगे। पायथन और डेटा इंजीनियरिंग के साथ, आप कई स्रोतों से विशाल डेटासेट एकत्र करना शुरू कर सकते हैं और उन्हें एक प्राथमिक स्रोत में बदल सकते हैं या उपयोगी व्यावसायिक अंतर्दृष्टि के लिए वेब स्क्रैपिंग शुरू कर सकते हैं।

सार:
- डेटा इंजीनियरिंग अधिक विश्वसनीय क्यों है?
- ईटीएल चक्र की प्रक्रिया
- स्टेप बाय स्टेप एक्सट्रैक्ट, ट्रांसफॉर्म, लोड फंक्शन
- डेटा इंजीनियरिंग के बारे में
- निष्कर्ष
यह वर्तमान पीढ़ी में अधिक विश्वसनीय और सबसे तेजी से बढ़ने वाला तकनीकी पेशा है, क्योंकि यह वेब स्क्रैपिंग और क्रॉलिंग डेटासेट पर अधिक ध्यान केंद्रित करता है।
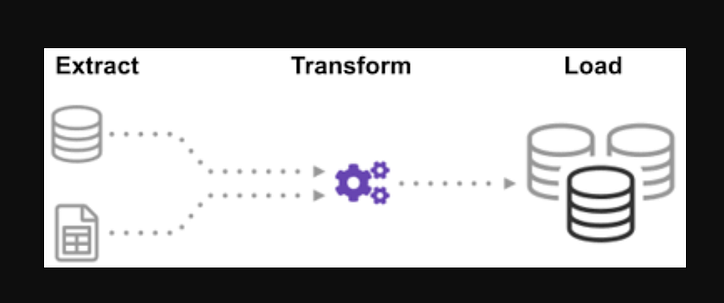
प्रक्रिया (ईटीएल चक्र):
क्या आपने कभी सोचा है कि सूचना का एकल स्रोत बनाने के लिए कई स्रोतों के डेटा को कैसे एकीकृत किया गया? बैच प्रोसेसिंग डेटा एकत्र करने का एक प्रकार है और एक्सट्रैक्ट, ट्रांसफॉर्म और लोड नामक "बैच प्रोसेसिंग के प्रकार का पता कैसे लगाएं" के बारे में अधिक जानें।

ईटीएल विभिन्न प्रकार के स्रोतों और प्रारूपों से बड़ी मात्रा में डेटा निकालने और डेटाबेस या गंतव्य फ़ाइल में डालने से पहले इसे एक प्रारूप में परिवर्तित करने की प्रक्रिया है।
आपका कुछ डेटा CSV फ़ाइलों में संग्रहीत है, जबकि अन्य JSON फ़ाइलों में संग्रहीत हैं। एआई को पढ़ने के लिए आपको यह सारी जानकारी एक फाइल में इकट्ठा करनी होगी। क्योंकि आपका डेटा शाही इकाइयों में है, लेकिन AI को मीट्रिक इकाइयों की आवश्यकता है, आपको इसे बदलने की आवश्यकता होगी। चूंकि एआई केवल एक बड़ी फ़ाइल में सीएसवी डेटा पढ़ सकता है, आपको इसे पहले लोड करना होगा। यदि डेटा सीएसवी प्रारूप में है, तो आइए निम्नलिखित ईटीएल को अजगर के साथ रखें और कुछ आसान उदाहरणों के साथ निष्कर्षण चरण पर एक नज़र डालें।
Json और.csv फ़ाइलों की सूची को देखकर। ग्लोब फाइल एक्सटेंशन के पहले एक स्टार और इनपुट में एक डॉट होता है। csv फ़ाइलों की एक सूची दी जाती है। For.json फ़ाइलें, हम वही काम कर सकते हैं। हम एक ऐसी फ़ाइल बना सकते हैं जो CSV प्रारूप में नाम, ऊँचाई और वज़न निकालती है। csv फ़ाइल का फ़ाइल नाम इनपुट है, और आउटपुट एक डेटा फ़्रेम है। JSON स्वरूपों के लिए, हम वही काम कर सकते हैं।
चरण 1:
कार्यों और आवश्यक मॉड्यूल आयात करें
import glob
import pandas as pd
import xml.etree.ElementTree as ET
from datetime import datetime
फ़ाइलों dealership_dataमें उपयोग किए गए कार डेटा के लिए CSV, JSON और XML फ़ाइलें होती हैं जिनमें car_model, year_of_manufacture, price, और नाम की विशेषताएं होती हैं fuel। इसलिए हम फ़ाइल को कच्चे डेटा से निकालने जा रहे हैं और इसे लक्ष्य फ़ाइल में बदलकर आउटपुट में लोड कर रहे हैं।
लक्ष्य फ़ाइलों के लिए पथ सेट करें:
tmpfile = "dealership_temp.tmp" # store all extracted data
logfile = "dealership_logfile.txt" # all event logs will be stored
targetfile = "dealership_transformed_data.csv" # transformed data is stored
फ़ंक्शन कई स्रोतों से बैचों में बड़ी मात्रा में डेटा निकालेगा। इस फ़ंक्शन को जोड़कर, यह अब सभी CSV फ़ाइल नामों को खोजेगा और लोड करेगा, और CSV फ़ाइलों को लूप के प्रत्येक पुनरावृत्ति के साथ दिनांक फ़्रेम में जोड़ा जाएगा, जिसमें पहला पुनरावृत्ति पहले संलग्न किया जाएगा, उसके बाद दूसरा पुनरावृत्ति, परिणामस्वरूप निकाले गए डेटा की सूची में। हमारे द्वारा डेटा एकत्र करने के बाद, हम प्रक्रिया के "रूपांतरण" चरण पर जाएँगे।
नोट: यदि "इग्नोर इंडेक्स" को सही पर सेट किया गया है, तो प्रत्येक पंक्ति का क्रम उसी क्रम के समान होगा जिसमें पंक्तियों को डेटा फ़्रेम में जोड़ा गया था।
सीएसवी एक्सट्रैक्ट फंक्शन
def extract_from_csv(file_to_process):
dataframe = pd.read_csv(file_to_process)
return dataframe
def extract_from_json(file_to_process):
dataframe = pd.read_json(file_to_process,lines=True)
return dataframe
def extract_from_xml(file_to_process):
dataframe = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
tree = ET.parse(file_to_process)
root = tree.getroot()
for person in root:
car_model = person.find("car_model").text
year_of_manufacture = int(person.find("year_of_manufacture").text)
price = float(person.find("price").text)
fuel = person.find("fuel").text
dataframe = dataframe.append({"car_model":car_model, "year_of_manufacture":year_of_manufacture, "price":price, "fuel":fuel}, ignore_index=True)
return dataframe
अब सीएसवी, जेएसओएन, एक्सएमएल के लिए इसके फंक्शन कॉल का उपयोग करके एक्सट्रेक्ट फंक्शन को कॉल करें।
def extract():
extracted_data = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
#for csv files
for csvfile in glob.glob("dealership_data/*.csv"):
extracted_data = extracted_data.append(extract_from_csv(csvfile), ignore_index=True)
#for json files
for jsonfile in glob.glob("dealership_data/*.json"):
extracted_data = extracted_data.append(extract_from_json(jsonfile), ignore_index=True)
#for xml files
for xmlfile in glob.glob("dealership_data/*.xml"):
extracted_data = extracted_data.append(extract_from_xml(xmlfile), ignore_index=True)
return extracted_data
हमारे द्वारा डेटा एकत्र करने के बाद, हम प्रक्रिया के "रूपांतरण" चरण पर जाएँगे। यह फ़ंक्शन कॉलम की ऊंचाई, जो इंच में है, मिलीमीटर में और कॉलम पाउंड, जो पाउंड में है, को किलोग्राम में बदल देगा, और चर डेटा में परिणाम लौटाएगा। इनपुट डेटा फ्रेम में कॉलम की ऊंचाई फीट में है। इसे मीटर में बदलने के लिए कॉलम को रूपांतरित करें और इसे दो दशमलव स्थानों पर गोल करें।
def transform(data):
data['price'] = round(data.price, 2)
return data
यह डेटा को लक्ष्य फ़ाइल में लोड करने का समय है, जिसे हमने इकट्ठा किया है और इसे निर्दिष्ट किया है। हम इस परिदृश्य में पांडा डेटा फ़्रेम को CSV के रूप में सहेजते हैं। अब हम विभिन्न स्रोतों से एकल लक्ष्य फ़ाइल में डेटा निकालने, बदलने और लोड करने के चरणों से गुजर चुके हैं। अपना काम पूरा करने से पहले हमें एक लॉगिंग प्रविष्टि स्थापित करने की आवश्यकता है। हम इसे लॉगिंग फ़ंक्शन लिखकर प्राप्त करेंगे।
लोड फ़ंक्शन:
def load(targetfile,data_to_load):
data_to_load.to_csv(targetfile)
लिखे गए सभी डेटा को वर्तमान जानकारी में जोड़ा जाएगा जब "ए" जोड़ा जाएगा। फिर हम इस प्रकार की प्रविष्टि उत्पन्न करके प्रक्रिया के प्रत्येक चरण में एक टाइमस्टैम्प संलग्न कर सकते हैं, यह इंगित करते हुए कि यह कब शुरू होता है और कब समाप्त होता है। डेटा पर ईटीएल प्रक्रिया करने के लिए आवश्यक सभी कोड को परिभाषित करने के बाद, अंतिम चरण सभी कार्यों को कॉल करना है।
def log(message):
timestamp_format = '%H:%M:%S-%h-%d-%Y'
#Hour-Minute-Second-MonthName-Day-Year
now = datetime.now() # get current timestamp
timestamp = now.strftime(timestamp_format)
with open("dealership_logfile.txt","a") as f: f.write(timestamp + ',' + message + 'n')
हम सबसे पहले Extract_data फ़ंक्शन को कॉल करके प्रारंभ करते हैं। इस चरण से प्राप्त डेटा को तब डेटा बदलने के दूसरे चरण में स्थानांतरित कर दिया जाएगा। इसके पूरा होने के बाद, डेटा को लक्ष्य फ़ाइल में लोड किया जाता है। साथ ही, ध्यान दें कि प्रत्येक चरण के पहले और बाद में प्रारंभ और पूर्ण होने का समय और दिनांक जोड़ा गया है।
लॉग कि आपने ईटीएल प्रक्रिया शुरू की है:
log("ETL Job Started")
log("Extract phase Started")
extracted_data = extract()
log("Extract phase Ended")
लॉग ("रूपांतरण चरण प्रारंभ")
रूपांतरित_डेटा = परिवर्तन (निकाले गए_डेटा)
log("Transform phase Ended")
log("Load phase Started")
load(targetfile,transformed_data)
log("Load phase Ended")
log("ETL Job Ended")
- एक साधारण एक्सट्रैक्ट फंक्शन कैसे लिखें।
- एक साधारण ट्रांसफ़ॉर्म फ़ंक्शन कैसे लिखें।
- एक साधारण लोड फ़ंक्शन कैसे लिखें।
- एक साधारण लॉगिंग फ़ंक्शन कैसे लिखें।
अधिक से अधिक, हमने सभी ईटीएल प्रक्रियाओं पर चर्चा की है। आगे, देखते हैं, "डेटा इंजीनियर की नौकरी के क्या फायदे हैं?"।
डाटा इंजीनियरिंग के बारे में:
डेटा इंजीनियरिंग कई नामों वाला एक विशाल क्षेत्र है। कई संस्थानों में इसका औपचारिक शीर्षक भी नहीं हो सकता है। परिणामस्वरूप, डेटा इंजीनियरिंग कार्य के उद्देश्यों को परिभाषित करके शुरू करना आम तौर पर बेहतर होता है जो अपेक्षित आउटपुट की ओर ले जाता है। डेटा इंजीनियरों पर भरोसा करने वाले उपयोगकर्ता डेटा इंजीनियरिंग टीमों की प्रतिभा और परिणाम के रूप में विविध हैं। आपके उपभोक्ता हमेशा परिभाषित करेंगे कि आप किन मुद्दों को संभालते हैं और आप उन्हें कैसे हल करते हैं, चाहे आप किसी भी क्षेत्र का पीछा करें।
निष्कर्ष:
मुझे आशा है कि आपको लेख में कुछ मदद मिलेगी और आप डेटा इंजीनियरिंग सीखने के लिए अपनी यात्रा शुरू करने के साथ-साथ पायथन से ईटीएल का उपयोग करने की कुछ समझ हासिल करेंगे। अधिक सीखने का मन करता है? मैं आपको डेटा इंजीनियरिंग प्रक्रियाओं को बेहतर बनाने के लिए पायथन कक्षाओं का उपयोग करने के तरीके पर अपने अन्य लेखों को देखने के लिए प्रोत्साहित करता हूं । मैं यह भी प्रदर्शित करता हूं कि आपके डेटा पाइपलाइन के पहले और सबसे महत्वपूर्ण चरणों में से एक में अपने डेटा सत्यापन को बेहतर बनाने के लिए पाइडेंटिक का उपयोग कैसे करें। यदि आप डेटा विज़ुअलाइज़ेशन में रुचि रखते हैं, तो अपाचे सुपरसेट के साथ अपना पहला चार्ट बनाने के लिए चरण-दर-चरण मार्गदर्शिका देखें ।
कार्रवाई के लिए पुकार
यदि आप गाइड को मददगार पाते हैं, तो बेझिझक ताली बजाएं और मेरे पीछे आएं। मेरे और अन्य सभी भयानक लेखकों के सभी प्रीमियम लेखों तक पहुँचने के लिए इस लिंक के माध्यम से माध्यम से जुड़ें ।
लेवल अप कोडिंग
हमारे समुदाय का हिस्सा बनने के लिए धन्यवाद! तुम्हारे जाने से पहले:
- कहानी के लिए ताली बजाएं और लेखक को फॉलो करें
- लेवल अप कोडिंग प्रकाशन में अधिक सामग्री देखें
- हमें फॉलो करें: ट्विटर | लिंक्डइन | समाचार पत्रिका

![क्या एक लिंक्ड सूची है, वैसे भी? [भाग 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































