पायथन में एसिन्सियो के साथ मल्टी-कोर पावर का उपयोग करना

यह पायथन कॉन्करेंसी कॉलम के तहत मेरे लेखों में से एक है , और यदि आपको यह उपयोगी लगता है, तो आप बाकी को यहाँ से पढ़ सकते हैं ।
परिचय
इस लेख में, मैं आपको दिखाऊंगा कि समवर्ती कार्यों के पूर्ण प्रदर्शन को अनलॉक करने के लिए मल्टी-कोर CPU पर Python asyncio कोड को कैसे निष्पादित किया जाए।
हमारी समस्या क्या है?
asyncio केवल एक कोर का उपयोग करता है।
पिछले लेखों में, मैंने Python asyncio का उपयोग करने के यांत्रिकी को विस्तार से कवर किया था। इस ज्ञान के साथ, आप सीख सकते हैं कि बहु-थ्रेडेड कार्य स्विचिंग के दौरान GIL विवाद प्रक्रिया को बायपास करने के लिए कार्य निष्पादन को मैन्युअल रूप से स्विच करके asyncio IO-बद्ध कार्यों को उच्च गति से निष्पादित करने की अनुमति देता है।
सैद्धांतिक रूप से, आईओ-बाध्य कार्यों का निष्पादन समय आईओ ऑपरेशन की शुरुआत से प्रतिक्रिया के समय पर निर्भर करता है और आपके सीपीयू प्रदर्शन पर निर्भर नहीं होता है। इस प्रकार, हम समवर्ती रूप से हजारों IO कार्यों को आरंभ कर सकते हैं और उन्हें शीघ्रता से पूरा कर सकते हैं।
लेकिन हाल ही में, मैं एक प्रोग्राम लिख रहा था जिसमें दसियों हज़ारों वेब पेजों को एक साथ क्रॉल करने की ज़रूरत थी और मैंने पाया कि हालाँकि मेरा एसिन्सियो प्रोग्राम वेब पेजों के पुनरावृत्त क्रॉलिंग का उपयोग करने वाले प्रोग्रामों की तुलना में बहुत अधिक कुशल था, फिर भी इसने मुझे लंबे समय तक प्रतीक्षा कराई। क्या मुझे अपने कंप्यूटर के पूर्ण प्रदर्शन का उपयोग करना चाहिए? इसलिए मैंने टास्क मैनेजर खोला और जाँच की:
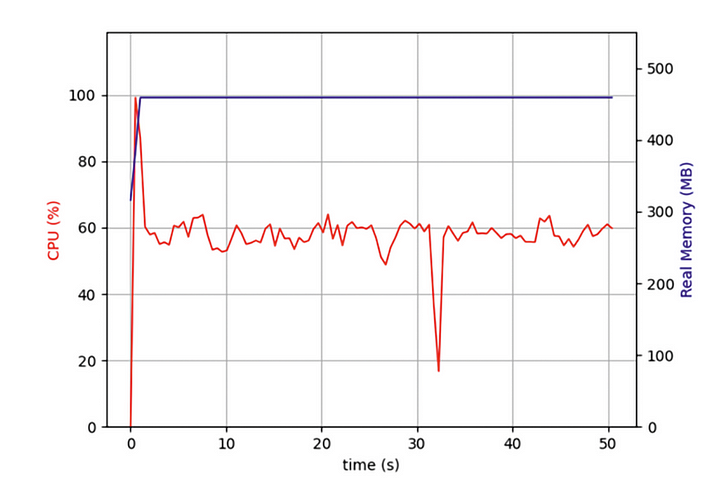
मैंने पाया कि शुरुआत से ही, मेरा कोड केवल एक सीपीयू कोर पर चल रहा था, और कई अन्य कोर निष्क्रिय थे। नेटवर्क डेटा को हड़पने के लिए IO संचालन शुरू करने के अलावा, एक कार्य को वापस आने के बाद डेटा को अनपैक और प्रारूपित करना होता है। हालाँकि ऑपरेशन का यह हिस्सा अधिक CPU प्रदर्शन का उपभोग नहीं करता है, अधिक कार्यों के बाद, ये CPU-बाउंड ऑपरेशन समग्र प्रदर्शन को गंभीर रूप से प्रभावित करेंगे।
मैं अपने asyncio समवर्ती कार्यों को कई कोर पर समानांतर में निष्पादित करना चाहता था। क्या इससे मेरे कंप्यूटर का प्रदर्शन कम हो जाएगा?
Asyncio के अंतर्निहित सिद्धांत
इस पहेली को हल करने के लिए, हमें अंतर्निहित asyncio कार्यान्वयन, इवेंट लूप से शुरू करना चाहिए।

जैसा कि चित्र में दिखाया गया है, कार्यक्रमों के लिए asyncio का प्रदर्शन सुधार IO-गहन कार्यों से शुरू होता है। आईओ-गहन कार्यों में HTTP अनुरोध, फ़ाइलों को पढ़ना और लिखना, डेटाबेस तक पहुँचना आदि शामिल हैं। इन कार्यों की सबसे महत्वपूर्ण विशेषता यह है कि सीपीयू ब्लॉक नहीं करता है और बाहरी डेटा के वापस आने की प्रतीक्षा में कंप्यूटिंग में बहुत समय व्यतीत करता है, जो है सिंक्रोनस कार्यों की एक अन्य श्रेणी से बहुत अलग है जिसमें एक विशिष्ट परिणाम की गणना करने के लिए सीपीयू को हर समय व्यस्त रहने की आवश्यकता होती है।
जब हम asyncio कार्यों का एक बैच उत्पन्न करते हैं, तो कोड पहले इन कार्यों को कतार में रखेगा। इस बिंदु पर, इवेंट लूप नामक एक थ्रेड होता है जो कतार से एक समय में एक कार्य को पकड़ता है और इसे निष्पादित करता है। जब कार्य प्रतीक्षित कथन तक पहुँचता है और प्रतीक्षा करता है (आमतौर पर अनुरोध की वापसी के लिए), ईवेंट लूप कतार से किसी अन्य कार्य को पकड़ लेता है और उसे निष्पादित करता है। जब तक पहले के प्रतीक्षारत कार्य को कॉलबैक के माध्यम से डेटा प्राप्त नहीं हो जाता, तब तक ईवेंट लूप पिछले प्रतीक्षारत कार्य पर वापस आ जाता है और शेष कोड को निष्पादित करना समाप्त कर देता है।
चूंकि ईवेंट लूप थ्रेड केवल एक कोर पर निष्पादित होता है, इसलिए इवेंट लूप ब्लॉक हो जाता है जब "शेष कोड" CPU समय लेने के लिए होता है। जब इस श्रेणी में कार्यों की संख्या बड़ी होती है, तो प्रत्येक छोटा अवरोधक खंड जुड़ जाता है और पूरे कार्यक्रम को धीमा कर देता है।
मेरा समाधान क्या है?
इससे, हम जानते हैं कि asyncio प्रोग्राम धीमा हो जाता है क्योंकि हमारा पायथन कोड केवल एक कोर पर इवेंट लूप को निष्पादित करता है, और IO डेटा के प्रसंस्करण से प्रोग्राम धीमा हो जाता है। क्या प्रत्येक सीपीयू कोर पर इसे निष्पादित करने के लिए इवेंट लूप शुरू करने का कोई तरीका है?
जैसा कि हम सभी जानते हैं, पायथन 3.7 से शुरू होकर, सभी asyncio कोड को विधि का उपयोग करके निष्पादित करने की अनुशंसा की जाती है asyncio.run, जो एक उच्च-स्तरीय अमूर्तता है जो ईवेंट लूप को कोड को निम्नलिखित कोड के विकल्प के रूप में निष्पादित करने के लिए कहता है:
try:
loop = asyncio.get_event_loop()
loop.run_until_complete(task())
finally:
loop.close()
पिछले लेख में loop.run_in_executorमुख्य प्रक्रिया से प्रत्येक बच्चे की प्रक्रिया के परिणाम प्राप्त करते समय प्रक्रिया पूल में कोड के निष्पादन को समानांतर करने के लिए asyncio की विधि का उपयोग करके व्याख्या करने के लिए एक वास्तविक जीवन उदाहरण का उपयोग किया गया था। यदि आपने पिछला लेख नहीं पढ़ा है, तो आप इसे यहाँ देख सकते हैं:
इस प्रकार, हमारा समाधान उभरता है: विधि के माध्यम से मल्टी-कोर निष्पादन का उपयोग करके कई उप-प्रक्रियाओं को कई समवर्ती कार्यों को वितरित करें loop.run_in_executor, और फिर asyncio.runप्रत्येक उप-प्रक्रिया को संबंधित ईवेंट लूप शुरू करने और समवर्ती कोड निष्पादित करने के लिए कॉल करें। निम्नलिखित आरेख संपूर्ण प्रवाह दिखाता है:
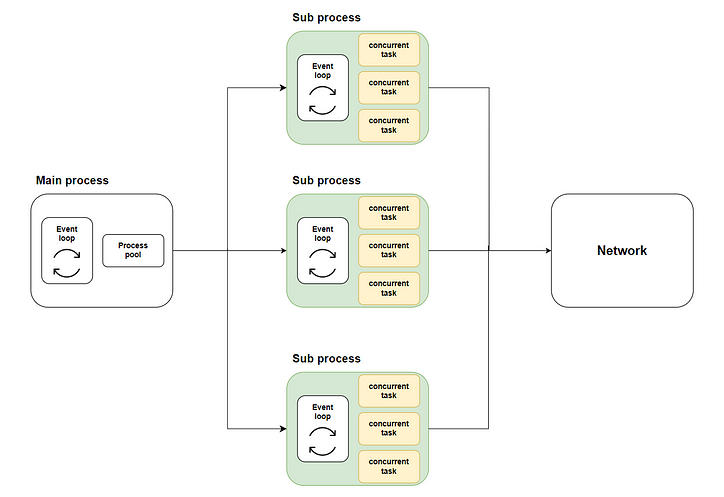
जहां हरा भाग हमारे द्वारा शुरू की गई उप-प्रक्रियाओं का प्रतिनिधित्व करता है। पीला भाग हमारे द्वारा शुरू किए गए समवर्ती कार्यों का प्रतिनिधित्व करता है।
तैयारी शुरू करने से पहले
कार्य कार्यान्वयन अनुकरण
इससे पहले कि हम समस्या का समाधान कर सकें, हमें शुरू करने से पहले तैयारी करनी होगी। इस उदाहरण में, हम वेब सामग्री को क्रॉल करने के लिए वास्तविक कोड नहीं लिख सकते हैं क्योंकि यह लक्षित वेबसाइट के लिए बहुत परेशान करने वाला होगा, इसलिए हम कोड के साथ अपने वास्तविक कार्य का अनुकरण करेंगे:
जैसा कि कोड दिखाता है, हम पहले asyncio.sleepयादृच्छिक समय में IO कार्य की वापसी का अनुकरण करने के लिए उपयोग करते हैं और डेटा वापस आने के बाद CPU प्रसंस्करण का अनुकरण करने के लिए एक पुनरावृत्त योग का उपयोग करते हैं।
पारंपरिक कोड का प्रभाव
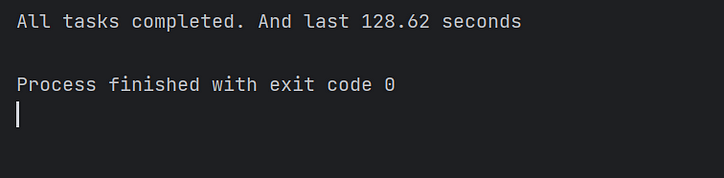
अगला, हम एक मुख्य विधि में 10,000 समवर्ती कार्यों को शुरू करने के पारंपरिक दृष्टिकोण को अपनाते हैं और समवर्ती कार्यों के इस बैच द्वारा खपत किए गए समय को देखते हैं:
जैसा कि चित्र में दिखाया गया है, केवल एक कोर के साथ एसिन्सियो कार्यों को निष्पादित करने में अधिक समय लगता है।
कोड कार्यान्वयन
इसके बाद, फ़्लोचार्ट के अनुसार मल्टी-कोर एसिंक्सियो कोड को लागू करते हैं और देखते हैं कि प्रदर्शन में सुधार हुआ है या नहीं।
कोड की समग्र संरचना को डिजाइन करना
सबसे पहले, एक वास्तुकार के रूप में, हमें अभी भी समग्र स्क्रिप्ट संरचना को परिभाषित करने की आवश्यकता है, किन विधियों की आवश्यकता है, और प्रत्येक विधि को कौन से कार्यों को पूरा करने की आवश्यकता है:
प्रत्येक विधि का विशिष्ट कार्यान्वयन
फिर, आइए प्रत्येक विधि को चरण दर चरण लागू करें।
विधि query_concurrentlyकार्यों के निर्दिष्ट बैच को समवर्ती रूप से शुरू करेगी और विधि के माध्यम से परिणाम प्राप्त करेगी asyncio.gather:
विधि run_batch_tasksएक async विधि नहीं है, क्योंकि यह सीधे बाल प्रक्रिया में शुरू होती है:
अंत में, हमारा mainतरीका है। यह विधि प्रक्रिया पूल में विधि को निष्पादित करने loop.run_in_executorके लिए विधि को कॉल करेगी और बाल प्रक्रिया निष्पादन के परिणामों को एक सूची में मर्ज करेगी:run_batch_tasks
चूंकि हम एक बहु-प्रक्रिया स्क्रिप्ट लिख रहे हैं, हमें if __name__ == “__main__”मुख्य प्रक्रिया में मुख्य विधि शुरू करने के लिए उपयोग करने की आवश्यकता है:
कोड निष्पादित करें और परिणाम देखें
अगला, हम स्क्रिप्ट शुरू करते हैं और कार्य प्रबंधक में प्रत्येक कोर पर भार देखते हैं:
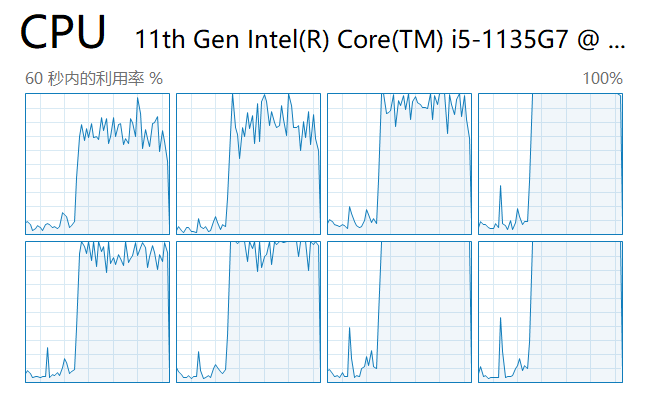
जैसा कि आप देख सकते हैं, सभी CPU कोर का उपयोग किया जाता है।
अंत में, हम कोड निष्पादन समय का निरीक्षण करते हैं और पुष्टि करते हैं कि बहु-थ्रेडेड asyncio कोड वास्तव में कई बार कोड निष्पादन को गति देता है! मिशन पूरा हुआ!

निष्कर्ष
इस लेख में, मैंने बताया कि क्यों asyncio IO- गहन कार्यों को समवर्ती रूप से निष्पादित कर सकता है, लेकिन फिर भी समवर्ती कार्यों के बड़े बैचों को चलाने में अपेक्षा से अधिक समय लगता है।
ऐसा इसलिए है क्योंकि asyncio कोड की पारंपरिक कार्यान्वयन योजना में, ईवेंट लूप केवल एक कोर पर कार्य निष्पादित कर सकता है, और अन्य कोर निष्क्रिय स्थिति में हैं।
इसलिए मैंने समानांतर में समवर्ती कार्यों को निष्पादित करने के लिए अलग-अलग कोर पर प्रत्येक ईवेंट लूप को कॉल करने के लिए आपके लिए एक समाधान लागू किया है। और अंत में, इसने कोड के प्रदर्शन में काफी सुधार किया।
मेरी क्षमता की सीमा के कारण, इस लेख के समाधान में अनिवार्य रूप से खामियां हैं। मैं आपकी टिप्पणियों और चर्चा का स्वागत करता हूं। मैं आपके लिए सक्रिय रूप से उत्तर दूंगा।

![क्या एक लिंक्ड सूची है, वैसे भी? [भाग 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































