Как сделать из списка списков плоский список?
Интересно, есть ли ярлык для создания простого списка из списка списков в Python.
Я могу сделать это в forцикле, но, может быть, есть какой-нибудь крутой "однострочный"? Я пробовал reduce(), но получаю ошибку.
Код
l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
reduce(lambda x, y: x.extend(y), l)
Сообщение об ошибке
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 1, in <lambda>
AttributeError: 'NoneType' object has no attribute 'extend'
Ответы
Учитывая список списков t,
flat_list = [item for sublist in t for item in sublist]
что значит:
flat_list = []
for sublist in t:
for item in sublist:
flat_list.append(item)
быстрее, чем ранее опубликованные ярлыки. ( tсписок для сглаживания.)
Вот соответствующая функция:
flatten = lambda t: [item for sublist in t for item in sublist]
В качестве доказательства можно использовать timeitмодуль из стандартной библиотеки:
$ python -mtimeit -s't=[[1,2,3],[4,5,6], [7], [8,9]]*99' '[item for sublist in t for item in sublist]' 10000 loops, best of 3: 143 usec per loop $ python -mtimeit -s't=[[1,2,3],[4,5,6], [7], [8,9]]*99' 'sum(t, [])'
1000 loops, best of 3: 969 usec per loop
$ python -mtimeit -s't=[[1,2,3],[4,5,6], [7], [8,9]]*99' 'reduce(lambda x,y: x+y,t)'
1000 loops, best of 3: 1.1 msec per loop
Объяснение: ярлыки, основанные на +(включая подразумеваемое использование в sum), по необходимости, O(T**2)когда есть T подсписок - поскольку список промежуточных результатов становится длиннее, на каждом шаге выделяется новый объект списка промежуточных результатов, и все элементы в предыдущем промежуточном результате необходимо скопировать (а также добавить несколько новых в конце). Итак, для простоты и без фактической потери общности предположим, что у вас есть T подсписок по k элементов в каждом: первые k элементов копируются туда и обратно T-1 раз, вторые k элементов T-2 раз и так далее; общее количество копий в k раз больше суммы x для x от 1 до T исключено, т k * (T**2)/2. е ..
Понимание списка просто генерирует один список один раз и копирует каждый элемент (из исходного места жительства в список результатов) также ровно один раз.
Вы можете использовать itertools.chain():
import itertools
list2d = [[1,2,3], [4,5,6], [7], [8,9]]
merged = list(itertools.chain(*list2d))
Или вы можете использовать то, itertools.chain.from_iterable()что не требует распаковки списка с *оператором :
import itertools
list2d = [[1,2,3], [4,5,6], [7], [8,9]]
merged = list(itertools.chain.from_iterable(list2d))
Примечание автора : это неэффективно. Но весело, потому что моноиды - это круто. Это не подходит для производственного кода Python.
>>> sum(l, [])
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Это просто суммирует элементы итерации, переданные в первом аргументе, обрабатывая второй аргумент как начальное значение суммы (если не задано, 0вместо этого используется, и в этом случае вы получите ошибку).
Поскольку вы суммируете вложенные списки, вы фактически получаете [1,3]+[2,4]в результате sum([[1,3],[2,4]],[]), что равно [1,3,2,4].
Обратите внимание, что работает только со списками списков. Для списков списков списков вам понадобится другое решение.
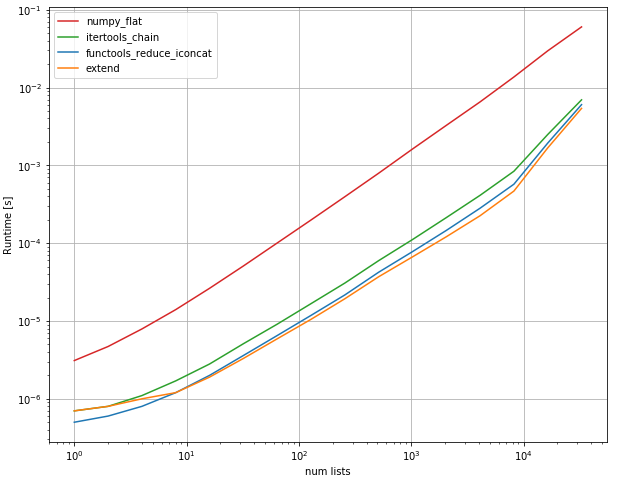
Я протестировал большинство предлагаемых решений с помощью perfplot ( мой любимый проект, по сути, обертка вокруг timeit) и обнаружил
import functools
import operator
functools.reduce(operator.iconcat, a, [])
чтобы быть самым быстрым решением как при объединении большого количества небольших списков, так и нескольких длинных списков. ( operator.iaddодинаково быстро.)
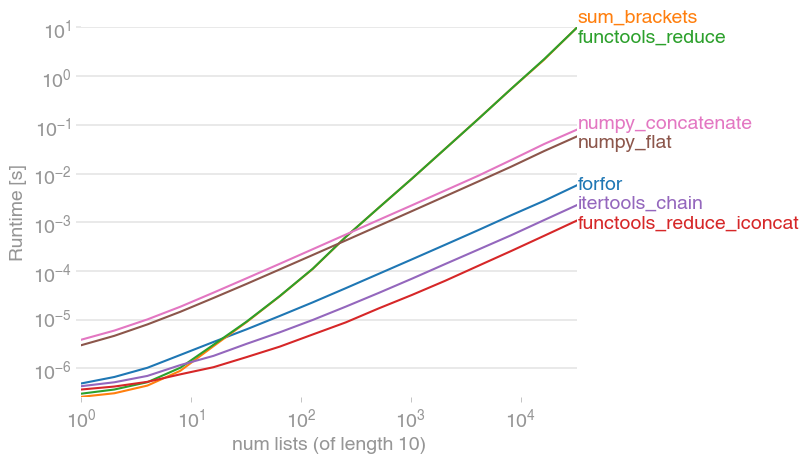
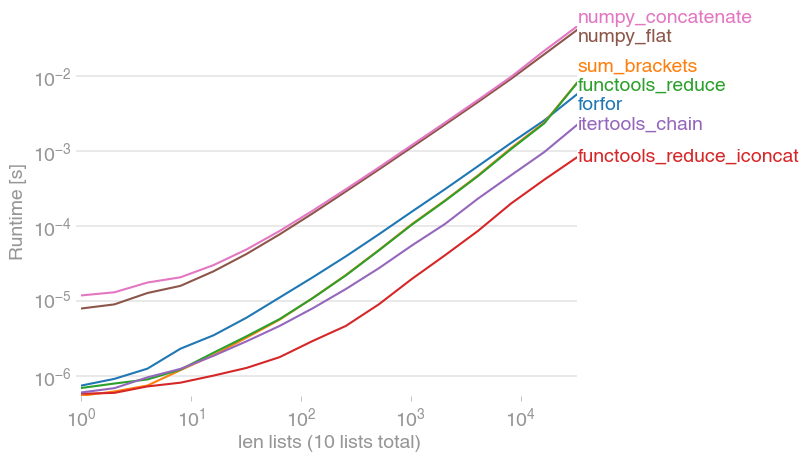
Код для воспроизведения сюжета:
import functools
import itertools
import numpy
import operator
import perfplot
def forfor(a):
return [item for sublist in a for item in sublist]
def sum_brackets(a):
return sum(a, [])
def functools_reduce(a):
return functools.reduce(operator.concat, a)
def functools_reduce_iconcat(a):
return functools.reduce(operator.iconcat, a, [])
def itertools_chain(a):
return list(itertools.chain.from_iterable(a))
def numpy_flat(a):
return list(numpy.array(a).flat)
def numpy_concatenate(a):
return list(numpy.concatenate(a))
perfplot.show(
setup=lambda n: [list(range(10))] * n,
# setup=lambda n: [list(range(n))] * 10,
kernels=[
forfor,
sum_brackets,
functools_reduce,
functools_reduce_iconcat,
itertools_chain,
numpy_flat,
numpy_concatenate,
],
n_range=[2 ** k for k in range(16)],
xlabel="num lists (of length 10)",
# xlabel="len lists (10 lists total)"
)
from functools import reduce #python 3
>>> l = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(lambda x,y: x+y,l)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
extend()Метод в вашем примере модифицирует xвместо возврата полезного значения (которое reduce()ожидает).
Более быстрый способ сделать reduceверсию -
>>> import operator
>>> l = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(operator.concat, l)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Не изобретайте велосипед, если используете Django :
>>> from django.contrib.admin.utils import flatten
>>> l = [[1,2,3], [4,5], [6]]
>>> flatten(l)
>>> [1, 2, 3, 4, 5, 6]
... Панды :
>>> from pandas.core.common import flatten
>>> list(flatten(l))
... Itertools :
>>> import itertools
>>> flatten = itertools.chain.from_iterable
>>> list(flatten(l))
... Матплотлиб
>>> from matplotlib.cbook import flatten
>>> list(flatten(l))
... Unipath :
>>> from unipath.path import flatten
>>> list(flatten(l))
... Инструменты настройки :
>>> from setuptools.namespaces import flatten
>>> list(flatten(l))
Вот общий подход, который применяется к числам , строкам , вложенным спискам и смешанным контейнерам.
Код
#from typing import Iterable
from collections import Iterable # < py38
def flatten(items):
"""Yield items from any nested iterable; see Reference."""
for x in items:
if isinstance(x, Iterable) and not isinstance(x, (str, bytes)):
for sub_x in flatten(x):
yield sub_x
else:
yield x
Примечания :
- В Python 3
yield from flatten(x)можно заменитьfor sub_x in flatten(x): yield sub_x - В Python 3.8, абстрактные базовые классы будут перемещены из
collection.abcкtypingмодулю.
Демо
lst = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
list(flatten(lst)) # nested lists
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
mixed = [[1, [2]], (3, 4, {5, 6}, 7), 8, "9"] # numbers, strs, nested & mixed
list(flatten(mixed))
# [1, 2, 3, 4, 5, 6, 7, 8, '9']
Ссылка
- Это решение модифицировано по рецепту Бизли, Д. и Б. Джонс. Рецепт 4.14, Поваренная книга Python, 3-е изд., O'Reilly Media Inc., Севастополь, Калифорния: 2013.
- Нашел более ранний пост SO , возможно, оригинальную демонстрацию.
Если вы хотите сгладить структуру данных, в которой вы не знаете, насколько глубоко она вложена, вы можете использовать 1iteration_utilities.deepflatten
>>> from iteration_utilities import deepflatten
>>> l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
>>> list(deepflatten(l, depth=1))
[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> l = [[1, 2, 3], [4, [5, 6]], 7, [8, 9]]
>>> list(deepflatten(l))
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Это генератор, поэтому вам нужно преобразовать результат в listили явно перебрать его.
Чтобы сгладить только один уровень, и если каждый из элементов сам итеративен, вы также можете использовать, iteration_utilities.flattenкоторый сам по себе является просто тонкой оболочкой itertools.chain.from_iterable:
>>> from iteration_utilities import flatten
>>> l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
>>> list(flatten(l))
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Просто чтобы добавить некоторые тайминги (на основе ответа Нико Шлёмера, который не включал функцию, представленную в этом ответе):
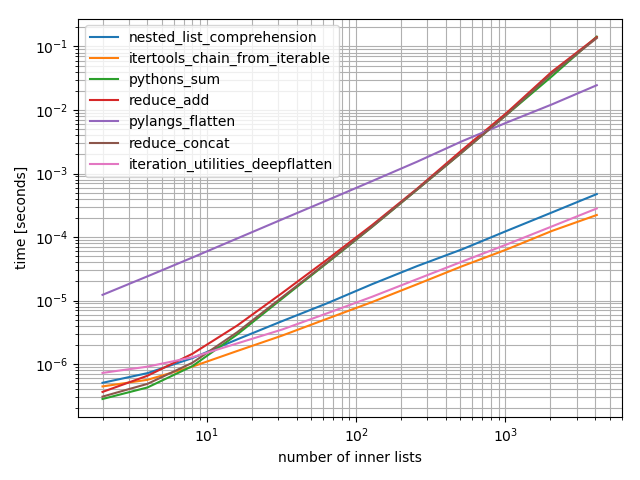
Это график журнала-журнала, позволяющий учесть огромный диапазон охватываемых значений. Из качественных соображений: чем ниже, тем лучше.
Результаты показывают, что если итерируемый объект содержит только несколько внутренних итераций, он sumбудет самым быстрым, однако для длинных итераций только itertools.chain.from_iterable, iteration_utilities.deepflattenили вложенное понимание имеет разумную производительность, itertools.chain.from_iterableбудучи самым быстрым (как уже заметил Нико Шлёмер).
from itertools import chain
from functools import reduce
from collections import Iterable # or from collections.abc import Iterable
import operator
from iteration_utilities import deepflatten
def nested_list_comprehension(lsts):
return [item for sublist in lsts for item in sublist]
def itertools_chain_from_iterable(lsts):
return list(chain.from_iterable(lsts))
def pythons_sum(lsts):
return sum(lsts, [])
def reduce_add(lsts):
return reduce(lambda x, y: x + y, lsts)
def pylangs_flatten(lsts):
return list(flatten(lsts))
def flatten(items):
"""Yield items from any nested iterable; see REF."""
for x in items:
if isinstance(x, Iterable) and not isinstance(x, (str, bytes)):
yield from flatten(x)
else:
yield x
def reduce_concat(lsts):
return reduce(operator.concat, lsts)
def iteration_utilities_deepflatten(lsts):
return list(deepflatten(lsts, depth=1))
from simple_benchmark import benchmark
b = benchmark(
[nested_list_comprehension, itertools_chain_from_iterable, pythons_sum, reduce_add,
pylangs_flatten, reduce_concat, iteration_utilities_deepflatten],
arguments={2**i: [[0]*5]*(2**i) for i in range(1, 13)},
argument_name='number of inner lists'
)
b.plot()
1 Отказ от ответственности: я являюсь автором этой библиотеки
Беру свое заявление обратно. сумма не является победителем. Хотя быстрее, когда список невелик. Но производительность значительно снижается с большими списками.
>>> timeit.Timer(
'[item for sublist in l for item in sublist]',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]] * 10000'
).timeit(100)
2.0440959930419922
Суммарная версия все еще работает более минуты и еще не обработана!
Для средних списков:
>>> timeit.Timer(
'[item for sublist in l for item in sublist]',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]] * 10'
).timeit()
20.126545906066895
>>> timeit.Timer(
'reduce(lambda x,y: x+y,l)',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]] * 10'
).timeit()
22.242258071899414
>>> timeit.Timer(
'sum(l, [])',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]] * 10'
).timeit()
16.449732065200806
Использование небольших списков и timeit: number = 1000000
>>> timeit.Timer(
'[item for sublist in l for item in sublist]',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]]'
).timeit()
2.4598159790039062
>>> timeit.Timer(
'reduce(lambda x,y: x+y,l)',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]]'
).timeit()
1.5289170742034912
>>> timeit.Timer(
'sum(l, [])',
'l=[[1, 2, 3], [4, 5, 6, 7, 8], [1, 2, 3, 4, 5, 6, 7]]'
).timeit()
1.0598428249359131
Вроде путаница с operator.add! Когда вы складываете два списка вместе, правильный термин для этого - concatне добавлять. operator.concatэто то, что вам нужно использовать.
Если вы думаете о функциональности, это очень просто:
>>> from functools import reduce
>>> list2d = ((1, 2, 3), (4, 5, 6), (7,), (8, 9))
>>> reduce(operator.concat, list2d)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
Вы видите, что сокращение уважает тип последовательности, поэтому, когда вы предоставляете кортеж, вы получаете обратно кортеж. Попробуем со списком:
>>> list2d = [[1, 2, 3],[4, 5, 6], [7], [8, 9]]
>>> reduce(operator.concat, list2d)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Ага, вы вернули список.
Как насчет производительности ::
>>> list2d = [[1, 2, 3],[4, 5, 6], [7], [8, 9]]
>>> %timeit list(itertools.chain.from_iterable(list2d))
1000000 loops, best of 3: 1.36 µs per loop
from_iterableдовольно быстро! Но это не сравнение, с которым можно сворачивать concat.
>>> list2d = ((1, 2, 3),(4, 5, 6), (7,), (8, 9))
>>> %timeit reduce(operator.concat, list2d)
1000000 loops, best of 3: 492 ns per loop
Почему вы используете расширение?
reduce(lambda x, y: x+y, l)
Это должно работать нормально.
Рассмотрите возможность установки more_itertoolsпакета.
> pip install more_itertools
Он поставляется с реализацией flatten( источник , из рецептов itertools ):
import more_itertools
lst = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
list(more_itertools.flatten(lst))
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
Примечание: как указано в документации , flattenтребуется список списков. См. Ниже сведения о сглаживании более нестандартных входов.
Начиная с версии 2.4, вы можете сглаживать более сложные вложенные итерации с помощью more_itertools.collapse( источник , предоставленный abarnet).
lst = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
list(more_itertools.collapse(lst))
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
lst = [[1, 2, 3], [[4, 5, 6]], [[[7]]], 8, 9] # complex nesting
list(more_itertools.collapse(lst))
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
Причина, по которой ваша функция не работала, заключается в том, что расширение расширяет массив на месте и не возвращает его. Вы все еще можете вернуть x из лямбда, используя что-то вроде этого:
reduce(lambda x,y: x.extend(y) or x, l)
Примечание: расширение более эффективно, чем + в списках.
def flatten(l, a):
for i in l:
if isinstance(i, list):
flatten(i, a)
else:
a.append(i)
return a
print(flatten([[[1, [1,1, [3, [4,5,]]]], 2, 3], [4, 5],6], []))
# [1, 1, 1, 3, 4, 5, 2, 3, 4, 5, 6]
Рекурсивная версия
x = [1,2,[3,4],[5,[6,[7]]],8,9,[10]]
def flatten_list(k):
result = list()
for i in k:
if isinstance(i,list):
#The isinstance() function checks if the object (first argument) is an
#instance or subclass of classinfo class (second argument)
result.extend(flatten_list(i)) #Recursive call
else:
result.append(i)
return result
flatten_list(x)
#result = [1,2,3,4,5,6,7,8,9,10]
Плохая особенность приведенной выше функции Anil заключается в том, что она требует, чтобы пользователь всегда вручную указывал второй аргумент как пустой список []. Вместо этого это должно быть по умолчанию. Из-за того, как работают объекты Python, их следует устанавливать внутри функции, а не в аргументах.
Вот рабочая функция:
def list_flatten(l, a=None):
#check a
if a is None:
#initialize with empty list
a = []
for i in l:
if isinstance(i, list):
list_flatten(i, a)
else:
a.append(i)
return a
Тестирование:
In [2]: lst = [1, 2, [3], [[4]],[5,[6]]]
In [3]: lst
Out[3]: [1, 2, [3], [[4]], [5, [6]]]
In [11]: list_flatten(lst)
Out[11]: [1, 2, 3, 4, 5, 6]
matplotlib.cbook.flatten() будет работать для вложенных списков, даже если они вложены глубже, чем в примере.
import matplotlib
l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
print(list(matplotlib.cbook.flatten(l)))
l2 = [[1, 2, 3], [4, 5, 6], [7], [8, [9, 10, [11, 12, [13]]]]]
print list(matplotlib.cbook.flatten(l2))
Результат:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
Это в 18 раз быстрее, чем подчеркивание ._. Flatten:
Average time over 1000 trials of matplotlib.cbook.flatten: 2.55e-05 sec
Average time over 1000 trials of underscore._.flatten: 4.63e-04 sec
(time for underscore._)/(time for matplotlib.cbook) = 18.1233394636
Принятый ответ не сработал для меня при работе с текстовыми списками переменной длины. Вот альтернативный подход, который мне помог.
l = ['aaa', 'bb', 'cccccc', ['xx', 'yyyyyyy']]
Принятый ответ, который не сработал:
flat_list = [item for sublist in l for item in sublist]
print(flat_list)
['a', 'a', 'a', 'b', 'b', 'c', 'c', 'c', 'c', 'c', 'c', 'xx', 'yyyyyyy']
Новое предлагаемое решение, которое действительно сработало для меня:
flat_list = []
_ = [flat_list.extend(item) if isinstance(item, list) else flat_list.append(item) for item in l if item]
print(flat_list)
['aaa', 'bb', 'cccccc', 'xx', 'yyyyyyy']
Следующее кажется мне самым простым:
>>> import numpy as np
>>> l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
>>> print (np.concatenate(l))
[1 2 3 4 5 6 7 8 9]
Также можно использовать квартиру NumPy :
import numpy as np
list(np.array(l).flat)
Изменить 11/02/2016: работает только тогда, когда подсписки имеют одинаковые размеры.
Вы можете использовать numpy:
flat_list = list(np.concatenate(list_of_list))
from nltk import flatten
l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]]
flatten(l)
Преимущество этого решения перед большинством других здесь заключается в том, что если у вас есть список вроде:
l = [1, [2, 3], [4, 5, 6], [7], [8, 9]]
в то время как большинство других решений выдают ошибку, это решение их обрабатывает.
Если вы готовы отказаться от крошечной скорости ради более чистого вида, вы можете использовать numpy.concatenate().tolist()или numpy.concatenate().ravel().tolist():
import numpy
l = [[1, 2, 3], [4, 5, 6], [7], [8, 9]] * 99
%timeit numpy.concatenate(l).ravel().tolist()
1000 loops, best of 3: 313 µs per loop
%timeit numpy.concatenate(l).tolist()
1000 loops, best of 3: 312 µs per loop
%timeit [item for sublist in l for item in sublist]
1000 loops, best of 3: 31.5 µs per loop
Вы можете узнать больше здесь, в документах numpy.concatenate и numpy.ravel.
Самое быстрое решение, которое я нашел (в любом случае, для большого списка):
import numpy as np
#turn list into an array and flatten()
np.array(l).flatten()
Выполнено! Конечно, вы можете превратить его обратно в список, выполнив list (l)
Простой код для underscore.pyпакетного вентилятора
from underscore import _
_.flatten([[1, 2, 3], [4, 5, 6], [7], [8, 9]])
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
Он решает все проблемы сглаживания (отсутствие элемента списка или сложного вложения)
from underscore import _
# 1 is none list item
# [2, [3]] is complex nesting
_.flatten([1, [2, [3]], [4, 5, 6], [7], [8, 9]])
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
Вы можете установить underscore.pyс помощью pip
pip install underscore.py
def flatten(alist):
if alist == []:
return []
elif type(alist) is not list:
return [alist]
else:
return flatten(alist[0]) + flatten(alist[1:])
Возможно, это не самый эффективный способ, но я подумал поставить однострочник (на самом деле двухстрочный). Обе версии будут работать с вложенными списками произвольной иерархии и использовать языковые функции (Python3.5) и рекурсию.
def make_list_flat (l):
flist = []
flist.extend ([l]) if (type (l) is not list) else [flist.extend (make_list_flat (e)) for e in l]
return flist
a = [[1, 2], [[[[3, 4, 5], 6]]], 7, [8, [9, [10, 11], 12, [13, 14, [15, [[16, 17], 18]]]]]]
flist = make_list_flat(a)
print (flist)
На выходе
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]
Это работает сначала глубоко. Рекурсия идет вниз, пока не найдет элемент, не входящий в список, затем расширяет локальную переменную flistи затем откатывает ее до родительского элемента . Каждый раз, когда flistвозвращается, он распространяется на родительский объект flistв понимании списка. Поэтому в корне возвращается плоский список.
Вышеупомянутый создает несколько локальных списков и возвращает их, которые используются для расширения родительского списка. Я думаю, что для этого можно создать глобал flist, как показано ниже.
a = [[1, 2], [[[[3, 4, 5], 6]]], 7, [8, [9, [10, 11], 12, [13, 14, [15, [[16, 17], 18]]]]]]
flist = []
def make_list_flat (l):
flist.extend ([l]) if (type (l) is not list) else [make_list_flat (e) for e in l]
make_list_flat(a)
print (flist)
Выход снова
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]
Хотя на данный момент я не уверен в эффективности.
Примечание : приведенное ниже относится к Python 3.3+, поскольку он использует yield_from. sixтакже является сторонним пакетом, хотя и стабильным. В качестве альтернативы вы можете использовать sys.version.
В случае с здесь obj = [[1, 2,], [3, 4], [5, 6]]все решения хороши, включая понимание списка и itertools.chain.from_iterable.
Однако рассмотрим этот немного более сложный случай:
>>> obj = [[1, 2, 3], [4, 5], 6, 'abc', [7], [8, [9, 10]]]
Здесь есть несколько проблем:
- Один элемент,,
6это просто скаляр; он не повторяется, поэтому приведенные выше маршруты здесь не пройдут. - Одним из элементов,
'abc', является технически итерацию (всеstrс есть). Однако, немного читая между строк, вы не хотите рассматривать его как таковой - вы хотите рассматривать его как единый элемент. - Последний элемент
[8, [9, 10]]сам по себе является вложенным итерабельным. Базовое понимание списка иchain.from_iterableизвлечение только «на 1 уровень ниже».
Вы можете исправить это следующим образом:
>>> from collections import Iterable
>>> from six import string_types
>>> def flatten(obj):
... for i in obj:
... if isinstance(i, Iterable) and not isinstance(i, string_types):
... yield from flatten(i)
... else:
... yield i
>>> list(flatten(obj))
[1, 2, 3, 4, 5, 6, 'abc', 7, 8, 9, 10]
Здесь вы проверяете, является ли подэлемент (1) итеративным с Iterableпомощью ABC от itertools, но также хотите убедиться, что (2) элемент не является «строковым».
flat_list = []
for i in list_of_list:
flat_list+=i
Этот код также отлично работает, поскольку он просто полностью расширяет список. Хотя он очень похож, но имеет только один цикл for. Таким образом, он имеет меньшую сложность, чем добавление 2 циклов for.
вы можете использовать list extendметод, он самый быстрый:
flat_list = []
for sublist in l:
flat_list.extend(sublist)
спектакль:
import functools
import itertools
import numpy
import operator
import perfplot
def functools_reduce_iconcat(a):
return functools.reduce(operator.iconcat, a, [])
def itertools_chain(a):
return list(itertools.chain.from_iterable(a))
def numpy_flat(a):
return list(numpy.array(a).flat)
def extend(a):
n = []
list(map(n.extend, a))
return n
perfplot.show(
setup=lambda n: [list(range(10))] * n,
kernels=[
functools_reduce_iconcat, extend,itertools_chain, numpy_flat
],
n_range=[2**k for k in range(16)],
xlabel='num lists',
)
выход: