Ingeniería de datos simplificada: secuencias de comandos de Python adjuntas para iniciar sus tareas de ETL
Descripción general:
Asuma el trabajo de un ingeniero de datos, extraiga datos de múltiples fuentes de formatos de archivo, transformándolos en tipos de datos particulares y cargándolos en una única fuente para su análisis. Poco después de leer este artículo, con la ayuda de varios ejemplos prácticos, podrá poner a prueba sus habilidades implementando web scraping y extrayendo datos con API. Con Python y la ingeniería de datos, podrá comenzar a recopilar grandes conjuntos de datos de muchas fuentes y transformarlos en una única fuente principal o comenzar a raspar la web para obtener información empresarial útil.

Sinopsis:
- ¿Por qué la ingeniería de datos es más fiable?
- Proceso del ciclo ETL
- Paso a paso Extraer, Transformar, la función Cargar
- Acerca de la ingeniería de datos
- Conclusión
Es una ocupación tecnológica más confiable y de más rápido crecimiento en la generación actual, ya que se concentra más en el web scraping y el rastreo de conjuntos de datos.
Proceso (Ciclo ETL):
¿Se ha preguntado alguna vez cómo se integraron los datos de muchas fuentes para crear una única fuente de información? El procesamiento por lotes es un tipo de recopilación de datos y aprender más sobre "cómo explorar un tipo de procesamiento por lotes" llamado Extraer, Transformar y Cargar.

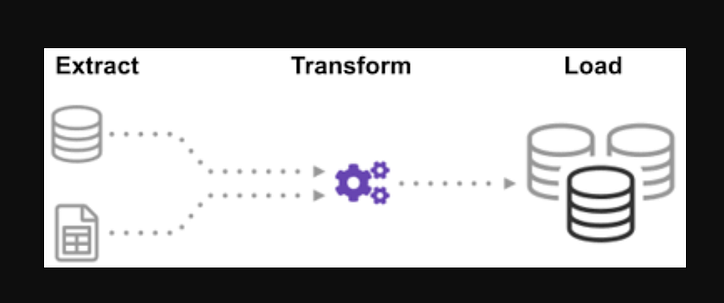
ETL es el proceso de extraer grandes volúmenes de datos de una variedad de fuentes y formatos y convertirlos a un solo formato antes de colocarlos en una base de datos o archivo de destino.
Algunos de sus datos se almacenan en archivos CSV, mientras que otros se almacenan en archivos JSON. Debe recopilar toda esta información en un solo archivo para que la IA la lea. Debido a que sus datos están en unidades imperiales, pero la IA necesita unidades métricas, deberá convertirlos. Debido a que la IA solo puede leer datos CSV en un solo archivo grande, primero debe cargarlo. Si los datos están en formato CSV, coloquemos el siguiente ETL con python y veamos el paso de extracción con algunos ejemplos sencillos.
Mirando la lista de archivos .json y .csv. La extensión de archivo global está precedida por una estrella y un punto en la entrada. Se devuelve una lista de archivos.csv. Para los archivos .json, podemos hacer lo mismo. Podemos crear un archivo que extraiga nombres, alturas y pesos en formato CSV. El nombre de archivo del archivo.csv es la entrada y la salida es un marco de datos. Para formatos JSON, podemos hacer lo mismo.
Paso 1:
Importar las funciones y módulos requeridos
import glob
import pandas as pd
import xml.etree.ElementTree as ET
from datetime import datetime
Los archivos dealership_datacontienen archivos CSV, JSON y XML para datos de automóviles usados que contienen funciones denominadas car_model, year_of_manufacture, pricey fuel. Así que vamos a extraer el archivo de los datos sin procesar y transformarlo en un archivo de destino y cargarlo en la salida.
Establezca la ruta para los archivos de destino:
tmpfile = "dealership_temp.tmp" # store all extracted data
logfile = "dealership_logfile.txt" # all event logs will be stored
targetfile = "dealership_transformed_data.csv" # transformed data is stored
La función extraerá grandes cantidades de datos de múltiples fuentes en lotes. Al agregar esta función, ahora descubrirá y cargará todos los nombres de archivos CSV, y los archivos CSV se agregarán al marco de fecha con cada iteración del bucle, con la primera iteración adjuntándose primero, seguida de la segunda iteración, lo que resulta en una lista de datos extraídos. Una vez que hayamos recopilado los datos, pasaremos al paso "Transformar" del proceso.
Nota: si "ignorar índice" se establece en verdadero, el orden de cada fila será el mismo que el orden en que se agregaron las filas al marco de datos.
Función de extracción de CSV
def extract_from_csv(file_to_process):
dataframe = pd.read_csv(file_to_process)
return dataframe
def extract_from_json(file_to_process):
dataframe = pd.read_json(file_to_process,lines=True)
return dataframe
def extract_from_xml(file_to_process):
dataframe = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
tree = ET.parse(file_to_process)
root = tree.getroot()
for person in root:
car_model = person.find("car_model").text
year_of_manufacture = int(person.find("year_of_manufacture").text)
price = float(person.find("price").text)
fuel = person.find("fuel").text
dataframe = dataframe.append({"car_model":car_model, "year_of_manufacture":year_of_manufacture, "price":price, "fuel":fuel}, ignore_index=True)
return dataframe
Ahora llame a la función de extracción usando su llamada de función para CSV, JSON, XML.
def extract():
extracted_data = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
#for csv files
for csvfile in glob.glob("dealership_data/*.csv"):
extracted_data = extracted_data.append(extract_from_csv(csvfile), ignore_index=True)
#for json files
for jsonfile in glob.glob("dealership_data/*.json"):
extracted_data = extracted_data.append(extract_from_json(jsonfile), ignore_index=True)
#for xml files
for xmlfile in glob.glob("dealership_data/*.xml"):
extracted_data = extracted_data.append(extract_from_xml(xmlfile), ignore_index=True)
return extracted_data
Una vez que hayamos recopilado los datos, pasaremos a la fase "Transformar" del proceso. Esta función convertirá la altura de la columna, que está en pulgadas, a milímetros y la columna de libras, que está en libras, a kilogramos, y devolverá los resultados en los datos variables. En el marco de datos de entrada, la altura de la columna está en pies. Convierta la columna para convertirla a metros y redondee a dos decimales.
def transform(data):
data['price'] = round(data.price, 2)
return data
Es hora de cargar los datos en el archivo de destino ahora que lo hemos recopilado y especificado. Guardamos el marco de datos de pandas como un CSV en este escenario. Ya hemos pasado por los pasos de extracción, transformación y carga de datos de varias fuentes en un solo archivo de destino. Necesitamos establecer una entrada de registro antes de que podamos terminar nuestro trabajo. Lo lograremos escribiendo una función de registro.
Función de carga:
def load(targetfile,data_to_load):
data_to_load.to_csv(targetfile)
Todos los datos que se escriban se agregarán a la información actual cuando se agregue la "a". Entonces podemos adjuntar una marca de tiempo a cada fase del proceso, indicando cuándo comienza y cuándo termina, generando este tipo de entrada. Una vez que hayamos definido todo el código necesario para realizar el proceso ETL en los datos, el último paso es llamar a todas las funciones.
def log(message):
timestamp_format = '%H:%M:%S-%h-%d-%Y'
#Hour-Minute-Second-MonthName-Day-Year
now = datetime.now() # get current timestamp
timestamp = now.strftime(timestamp_format)
with open("dealership_logfile.txt","a") as f: f.write(timestamp + ',' + message + 'n')
Primero comenzamos llamando a la función extract_data. Los datos recibidos de este paso se transferirán al segundo paso de transformación de datos. Una vez que esto se ha completado, los datos se cargan en el archivo de destino. Además, tenga en cuenta que antes y después de cada paso se han agregado la hora y la fecha de inicio y finalización.
El registro de que ha iniciado el proceso ETL:
log("ETL Job Started")
log("Extract phase Started")
extracted_data = extract()
log("Extract phase Ended")
log ("Fase de transformación iniciada")
datos_transformados = transformar(datos_extraídos)
log("Transform phase Ended")
log("Load phase Started")
load(targetfile,transformed_data)
log("Load phase Ended")
log("ETL Job Ended")
- Cómo escribir una función de extracción simple.
- Cómo escribir una función de transformación simple.
- Cómo escribir una función de carga simple.
- Cómo escribir una función de registro simple.
A lo sumo, hemos discutido todos los procesos de ETL. Además, veamos, "¿cuáles son los beneficios del trabajo de ingeniero de datos?".
Sobre ingeniería de datos:
La ingeniería de datos es un campo amplio con muchos nombres. Es posible que ni siquiera tenga un título formal en muchas instituciones. Como resultado, generalmente es mejor comenzar definiendo los objetivos del trabajo de ingeniería de datos que conducen a los resultados esperados. Los usuarios que confían en los ingenieros de datos son tan diversos como los talentos y los resultados de los equipos de ingeniería de datos. Tus consumidores siempre definirán qué problemas manejas y cómo los resuelves, independientemente del sector al que te dediques.
Conclusión:
Espero que encuentre ayuda en el artículo y obtenga cierta comprensión del uso de Python para ETL a medida que comienza su viaje para aprender ingeniería de datos. ¿Tienes ganas de aprender más? Lo animo a que consulte mis otros artículos sobre cómo podría usar las clases de Python para mejorar los procesos de ingeniería de datos . También demuestro cómo usar pydantic para mejorar su validación de datos en uno de los primeros y más importantes pasos de su flujo de datos. Si está interesado en la visualización de datos, consulte esta guía paso a paso para crear su primer gráfico con Apache Superset .
Llamado a la acción
Si encuentra útil la guía, siéntase libre de aplaudir y seguirme. Únase a medium a través de este enlace para acceder a todos mis artículos premium y a todos los demás escritores increíbles aquí en medium.
Codificación de nivel superior
¡Gracias por ser parte de nuestra comunidad! Antes de que te vayas:
- Aplaude la historia y sigue al autor
- Ver más contenido en la publicación Level Up Coding
- Síguenos: Twitter | LinkedIn | Boletin informativo

![¿Qué es una lista vinculada, de todos modos? [Parte 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































