Pandas Merging 101
- Come eseguire un (
INNER| (LEFT|RIGHT|FULL)OUTER)JOINcon i panda? - Come si aggiungono NaN per le righe mancanti dopo l'unione?
- Come mi sbarazzo di NaN dopo l'unione?
- Posso unirmi all'indice?
- Cross join con i panda?
- Come si uniscono più DataFrame?
merge?join?concat?update? Chi? Che cosa? Perché?!
... e altro ancora. Ho visto queste domande ricorrenti che chiedevano informazioni su vari aspetti della funzionalità di fusione dei panda. La maggior parte delle informazioni relative alla fusione e ai suoi vari casi d'uso oggi sono frammentate in dozzine di post mal formulati e non ricercabili. L'obiettivo qui è quello di raccogliere alcuni dei punti più importanti per i posteri.
Questo QnA dovrebbe essere il prossimo capitolo di una serie di utili guide per l'utente sugli idiomi comuni dei panda (vedi questo post sul pivot e questo post sulla concatenazione , che toccherò più avanti).
Tieni presente che questo post non intende sostituire la documentazione , quindi leggi anche quello! Alcuni degli esempi sono presi da lì.
Risposte
Questo post ha lo scopo di fornire ai lettori un'introduzione alla fusione in stile SQL con i panda, su come usarlo e quando non usarlo.
In particolare, ecco di cosa parlerà questo post:
Nozioni di base: tipi di join (SINISTRA, DESTRA, ESTERNA, INTERNA)
- fusione con nomi di colonne diversi
- evitando la duplicazione della colonna chiave di unione nell'output
Fusione con indice in condizioni diverse
- utilizzando efficacemente il tuo indice denominato
- chiave di unione come indice di uno e colonna di un altro
Unioni a più vie su colonne e indici (univoci e non univoci)
Notevoli alternative a
mergeejoin
Cosa non passerà questo post:
- Discussioni e tempistiche relative alle prestazioni (per ora). Menzioni per lo più notevoli di alternative migliori, ove appropriato.
- Gestione di suffissi, rimozione di colonne aggiuntive, ridenominazione di output e altri casi d'uso specifici. Ci sono altri post (leggi: migliori) che si occupano di questo, quindi capiscilo!
Nota
La maggior parte degli esempi utilizza per impostazione predefinita le operazioni INNER JOIN durante la dimostrazione di varie funzionalità, se non diversamente specificato.Inoltre, tutti i DataFrame qui possono essere copiati e replicati in modo da poter giocare con loro. Inoltre, guarda questo post su come leggere DataFrame dagli appunti.
Infine, tutte le rappresentazioni visive delle operazioni JOIN sono state disegnate a mano utilizzando Disegni Google. Ispirazione da qui .
Basta parlare, fammi vedere come si usa merge!
Impostare
np.random.seed(0)
left = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': np.random.randn(4)})
right = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': np.random.randn(4)})
left
key value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right
key value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
Per semplicità, la colonna chiave ha lo stesso nome (per ora).
Un INNER JOIN è rappresentato da
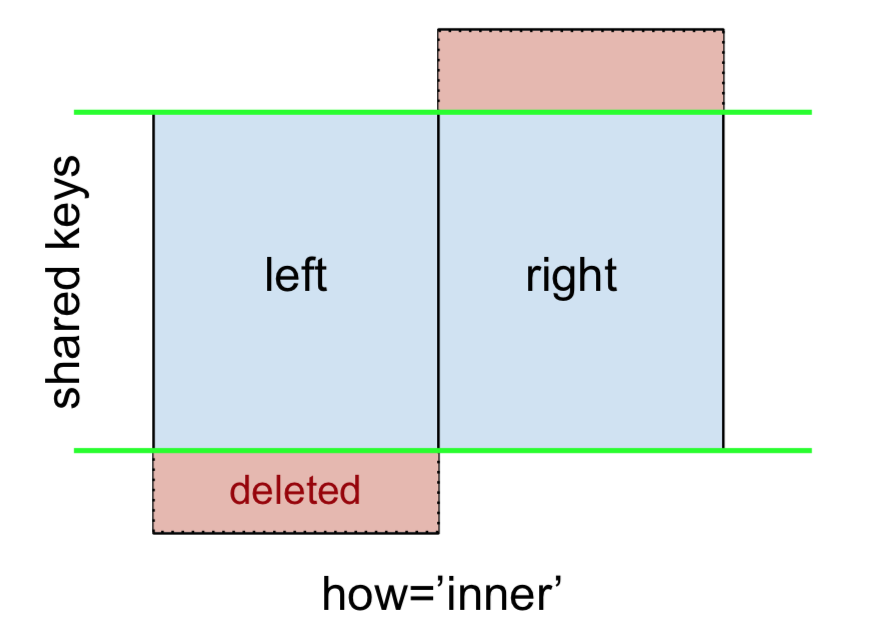
Nota
Questo, insieme alle figure imminenti, seguono tutte questa convenzione:
- il blu indica le righe presenti nel risultato dell'unione
- il rosso indica le righe escluse dal risultato (cioè rimosse)
- il verde indica valori mancanti che vengono sostituiti con
NaNs nel risultato
Per eseguire un INNER JOIN, chiama mergeil DataFrame sinistro, specificando il DataFrame destro e la chiave di join (almeno) come argomenti.
left.merge(right, on='key')
# Or, if you want to be explicit
# left.merge(right, on='key', how='inner')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
Restituisce solo le righe da lefte rightche condividono una chiave comune (in questo esempio, "B" e "D).
UN LEFT OUTER JOIN o LEFT JOIN è rappresentato da
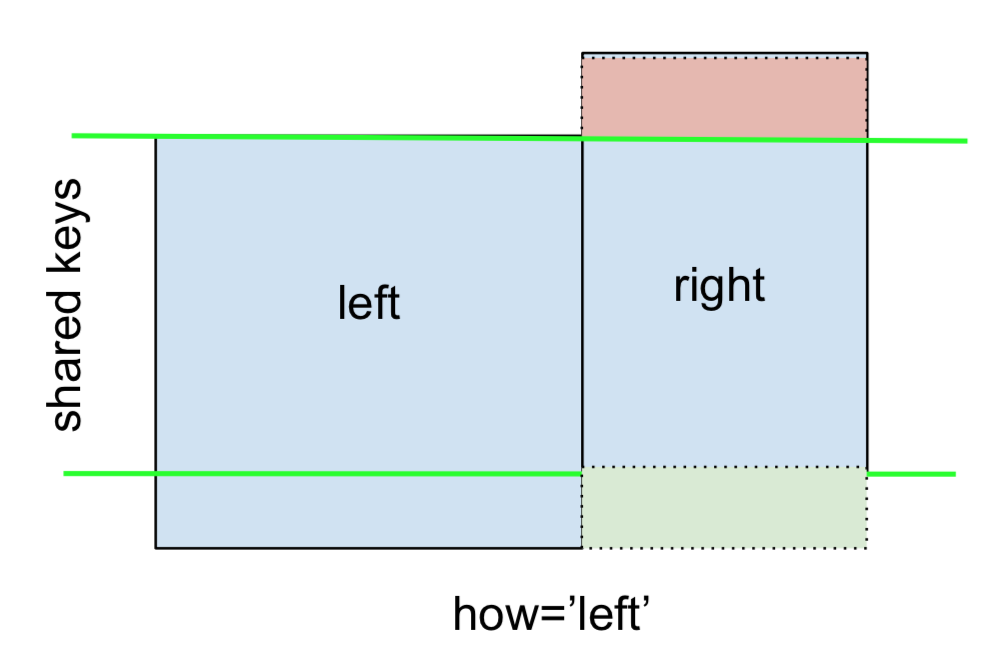
Questo può essere eseguito specificando how='left'.
left.merge(right, on='key', how='left')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
Nota attentamente il posizionamento dei NaN qui. Se si specifica how='left', leftvengono utilizzate solo le chiavi di e i dati mancanti vengono rightsostituiti da NaN.
Allo stesso modo, per un RIGHT OUTER JOIN , o RIGHT JOIN che è ...
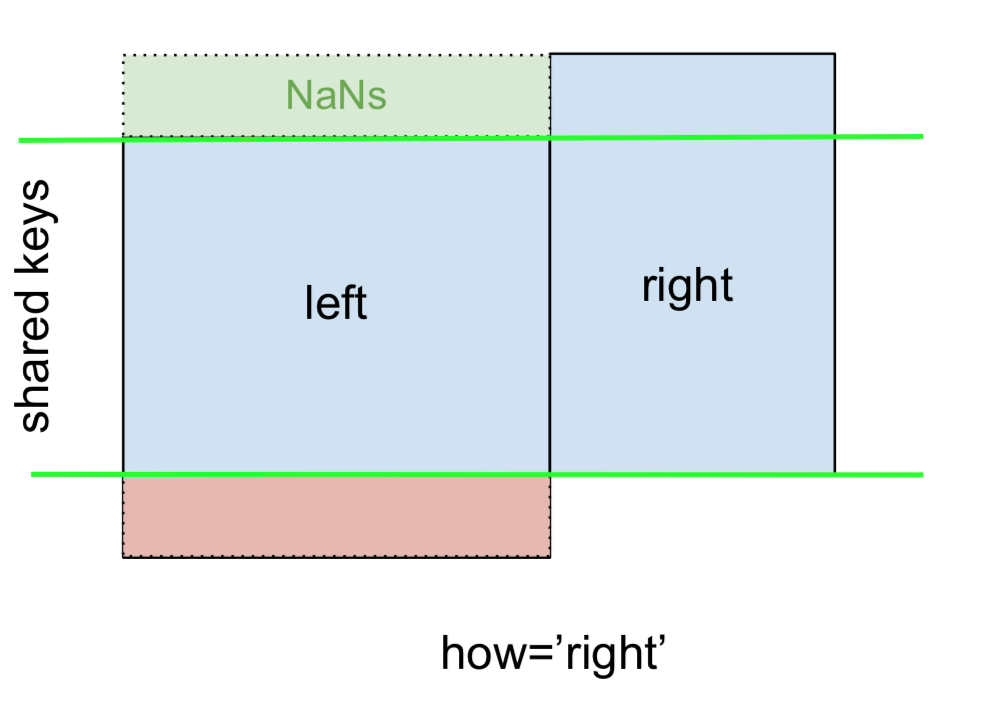
... specificare how='right':
left.merge(right, on='key', how='right')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
2 E NaN 0.950088
3 F NaN -0.151357
Qui, rightvengono utilizzate le chiavi di e i dati mancanti vengono leftsostituiti da NaN.
Infine, per il FULL OUTER JOIN , fornito da
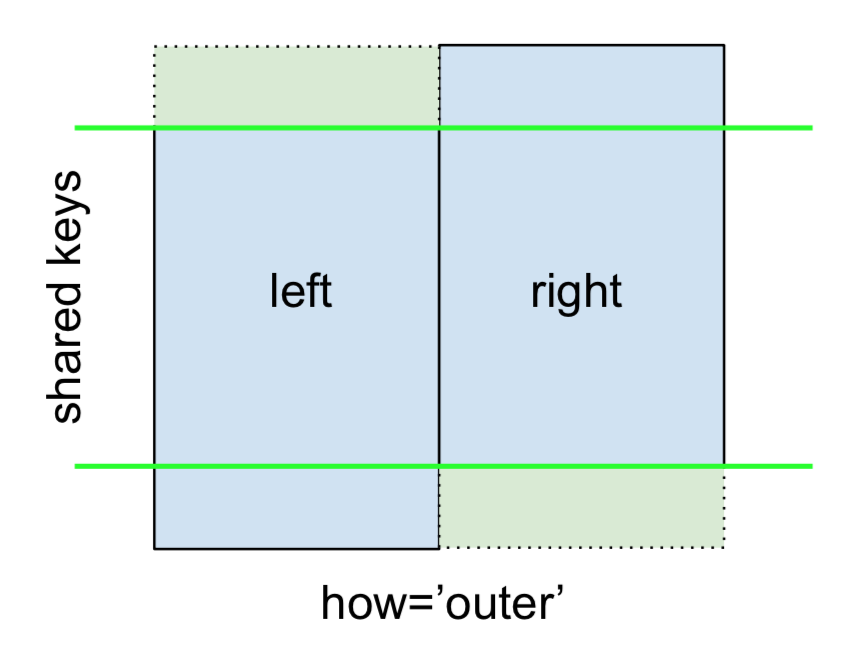
specificare how='outer'.
left.merge(right, on='key', how='outer')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
4 E NaN 0.950088
5 F NaN -0.151357
Questo utilizza le chiavi di entrambi i frame e NaN vengono inseriti per le righe mancanti in entrambi.
La documentazione riassume bene queste varie fusioni:

Altre JOIN - Escluse da SINISTRA, Escluse da DESTRA e ESCLUSE COMPLETAMENTE / ANTI JOIN
Se hai bisogno di JOIN escluso da SINISTRA e JOIN escluso da DESTRA in due passaggi.
Per LEFT-Excluding JOIN, rappresentato come
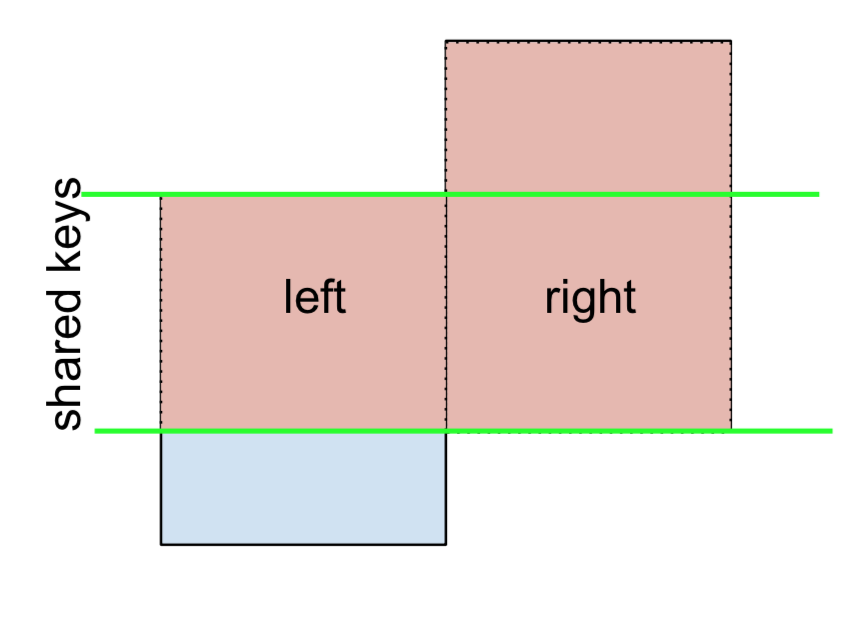
Inizia eseguendo un LEFT OUTER JOIN e quindi filtrando (escluse!) Le righe provenienti leftsolo da ,
(left.merge(right, on='key', how='left', indicator=True)
.query('_merge == "left_only"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
Dove,
left.merge(right, on='key', how='left', indicator=True)
key value_x value_y _merge
0 A 1.764052 NaN left_only
1 B 0.400157 1.867558 both
2 C 0.978738 NaN left_only
3 D 2.240893 -0.977278 bothAllo stesso modo, per un JOIN escluso da DIRITTI,
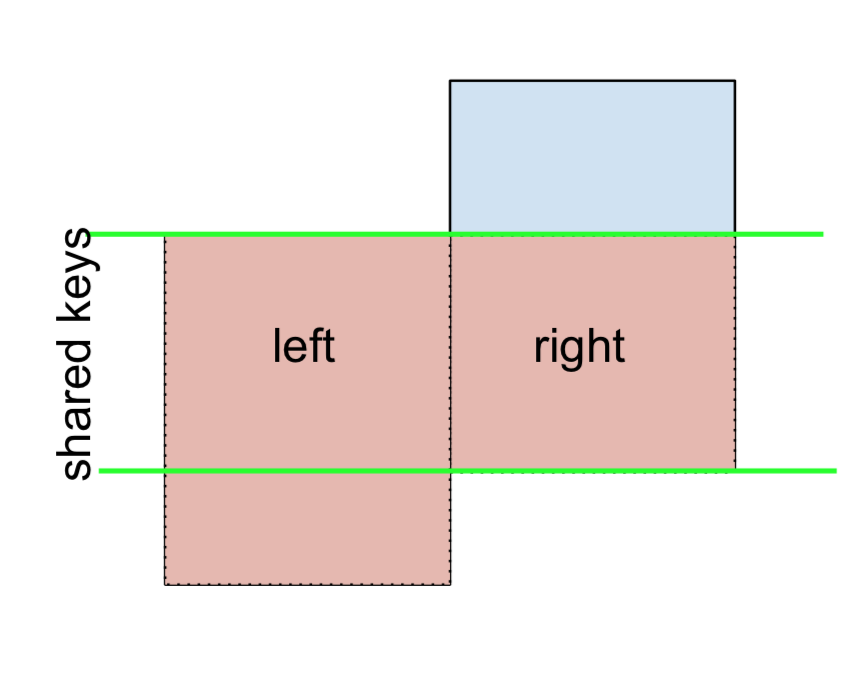
(left.merge(right, on='key', how='right', indicator=True)
.query('_merge == "right_only"')
.drop('_merge', 1))
key value_x value_y
2 E NaN 0.950088
3 F NaN -0.151357Infine, se ti viene richiesto di fare un'unione che trattiene solo le chiavi da sinistra o da destra, ma non entrambe (IOW, eseguendo un ANTI-JOIN ),
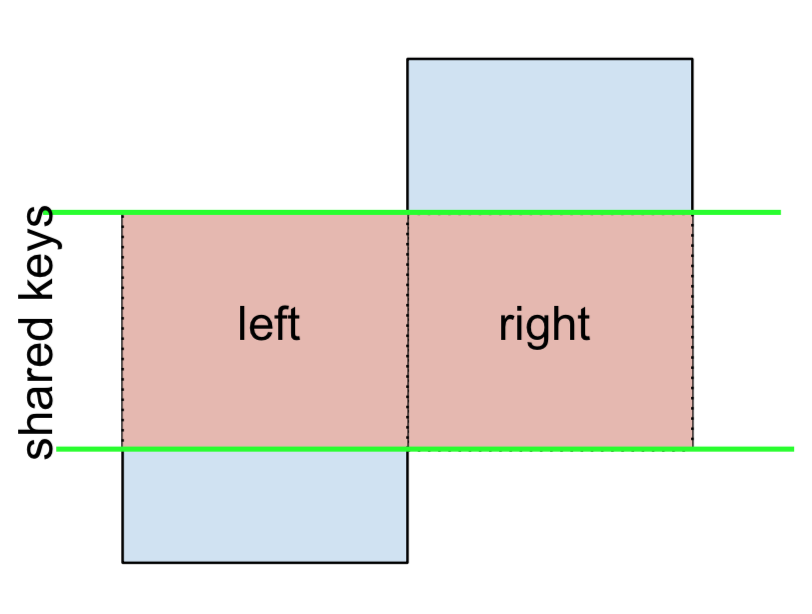
Puoi farlo in modo simile:
(left.merge(right, on='key', how='outer', indicator=True)
.query('_merge != "both"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
4 E NaN 0.950088
5 F NaN -0.151357
Nomi diversi per le colonne chiave
Se le colonne chiave hanno un nome diverso, ad esempio lefthas keyLefte righthas keyRightinvece di key, dovrai specificare left_one right_oncome argomenti invece di on:
left2 = left.rename({'key':'keyLeft'}, axis=1)
right2 = right.rename({'key':'keyRight'}, axis=1)
left2
keyLeft value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right2
keyRight value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')
keyLeft value_x keyRight value_y
0 B 0.400157 B 1.867558
1 D 2.240893 D -0.977278
Evitare colonne chiave duplicate nell'output
Quando si uniscono keyLeftda lefte keyRightda right, se si desidera solo uno dei keyLefto keyRight(ma non entrambi) nell'output, è possibile iniziare impostando l'indice come passaggio preliminare.
left3 = left2.set_index('keyLeft')
left3.merge(right2, left_index=True, right_on='keyRight')
value_x keyRight value_y
0 0.400157 B 1.867558
1 2.240893 D -0.977278
Confronta questo con l'output del comando appena prima (cioè l'output di left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')), noterai che keyLeftmanca. Puoi capire quale colonna mantenere in base all'indice del frame impostato come chiave. Ciò può essere importante quando, ad esempio, si esegue un'operazione OUTER JOIN.
Unendo solo una singola colonna da uno dei file DataFrames
Ad esempio, considera
right3 = right.assign(newcol=np.arange(len(right)))
right3
key value newcol
0 B 1.867558 0
1 D -0.977278 1
2 E 0.950088 2
3 F -0.151357 3
Se ti viene richiesto di unire solo "new_val" (senza nessuna delle altre colonne), di solito puoi solo creare un sottoinsieme di colonne prima di unire:
left.merge(right3[['key', 'newcol']], on='key')
key value newcol
0 B 0.400157 0
1 D 2.240893 1
Se stai facendo un LEFT OUTER JOIN, una soluzione più performante comporterebbe map:
# left['newcol'] = left['key'].map(right3.set_index('key')['newcol']))
left.assign(newcol=left['key'].map(right3.set_index('key')['newcol']))
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
Come accennato, questo è simile a, ma più veloce di
left.merge(right3[['key', 'newcol']], on='key', how='left')
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
Unione su più colonne
Per partecipare a più di una colonna, specificare un elenco per on(o left_one right_on, a seconda dei casi).
left.merge(right, on=['key1', 'key2'] ...)
Oppure, nel caso i nomi siano diversi,
left.merge(right, left_on=['lkey1', 'lkey2'], right_on=['rkey1', 'rkey2'])
Altre merge*operazioni e funzioni utili
Unione di un DataFrame con una serie sull'indice : vedere questa risposta .
Inoltre
merge,DataFrame.updateeDataFrame.combine_firstvengono utilizzati anche in alcuni casi per aggiornare un DataFrame con un altro.pd.merge_orderedè una funzione utile per i JOIN ordinati.pd.merge_asof(leggi: merge_asOf) è utile per i join approssimativi .
Questa sezione copre solo le basi ed è progettata solo per stuzzicare l'appetito. Per ulteriori esempi e casi, consultare la documentazione su merge, joineconcat così come i collegamenti alle specifiche funzioni.
Basato su indice * -JOIN (+ colonne-indice merge)
Impostare
np.random.seed([3, 14])
left = pd.DataFrame({'value': np.random.randn(4)}, index=['A', 'B', 'C', 'D'])
right = pd.DataFrame({'value': np.random.randn(4)}, index=['B', 'D', 'E', 'F'])
left.index.name = right.index.name = 'idxkey'
left
value
idxkey
A -0.602923
B -0.402655
C 0.302329
D -0.524349
right
value
idxkey
B 0.543843
D 0.013135
E -0.326498
F 1.385076
In genere, un'unione sull'indice sarebbe simile a questa:
left.merge(right, left_index=True, right_index=True)
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Supporto per i nomi degli indici
Se l'indice è denominato, gli utenti della v0.23 possono anche specificare il nome del livello in on(o left_one right_onsecondo necessità).
left.merge(right, on='idxkey')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Unione sull'indice di uno, colonne di un altro
È possibile (e abbastanza semplice) utilizzare l'indice di uno e la colonna di un altro per eseguire un'unione. Per esempio,
left.merge(right, left_on='key1', right_index=True)
O viceversa ( right_on=...e left_index=True).
right2 = right.reset_index().rename({'idxkey' : 'colkey'}, axis=1)
right2
colkey value
0 B 0.543843
1 D 0.013135
2 E -0.326498
3 F 1.385076
left.merge(right2, left_index=True, right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
In questo caso speciale, l'indice per leftè denominato, quindi puoi anche utilizzare il nome dell'indice con left_on, in questo modo:
left.merge(right2, left_on='idxkey', right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
DataFrame.join
Oltre a questi, c'è un'altra opzione succinta. È possibile utilizzare le DataFrame.joinimpostazioni predefinite per i join nell'indice. DataFrame.joinfa un LEFT OUTER JOIN per impostazione predefinita, quindi how='inner'è necessario qui.
left.join(right, how='inner', lsuffix='_x', rsuffix='_y')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Nota che avevo bisogno di specificare gli argomenti lsuffixe rsuffixpoiché joinaltrimenti si sarebbe verificato un errore:
left.join(right)
ValueError: columns overlap but no suffix specified: Index(['value'], dtype='object')
Poiché i nomi delle colonne sono gli stessi. Questo non sarebbe un problema se avessero un nome diverso.
left.rename(columns={'value':'leftvalue'}).join(right, how='inner')
leftvalue value
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
pd.concat
Infine, in alternativa ai join basati su indice, puoi utilizzare pd.concat:
pd.concat([left, right], axis=1, sort=False, join='inner')
value value
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Ometti join='inner'se hai bisogno di un FULL OUTER JOIN (predefinito):
pd.concat([left, right], axis=1, sort=False)
value value
A -0.602923 NaN
B -0.402655 0.543843
C 0.302329 NaN
D -0.524349 0.013135
E NaN -0.326498
F NaN 1.385076
Per ulteriori informazioni, vedere questo post canonico su pd.concat@piRSquared .
Generalizzazione: mergeing più DataFrame
Spesso, la situazione si verifica quando più DataFrame devono essere uniti insieme. Ingenuamente, questo può essere fatto concatenando le mergechiamate:
df1.merge(df2, ...).merge(df3, ...)
Tuttavia, questo sfugge rapidamente di mano a molti DataFrame. Inoltre, potrebbe essere necessario generalizzare per un numero sconosciuto di DataFrame.
Qui pd.concatpresento i join a più vie su chiavi univoche e DataFrame.joinper i join a più vie su chiavi non univoche . Innanzitutto, l'installazione.
# Setup.
np.random.seed(0)
A = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'valueA': np.random.randn(4)})
B = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'valueB': np.random.randn(4)})
C = pd.DataFrame({'key': ['D', 'E', 'J', 'C'], 'valueC': np.ones(4)})
dfs = [A, B, C]
# Note, the "key" column values are unique, so the index is unique.
A2 = A.set_index('key')
B2 = B.set_index('key')
C2 = C.set_index('key')
dfs2 = [A2, B2, C2]
Unione a più vie su chiavi univoche (o indice)
Se le tue chiavi (qui, la chiave potrebbe essere una colonna o un indice) sono uniche, puoi usare pd.concat. Nota che pd.concatunisce DataFrames nell'indice .
# merge on `key` column, you'll need to set the index before concatenating
pd.concat([
df.set_index('key') for df in dfs], axis=1, join='inner'
).reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# merge on `key` index
pd.concat(dfs2, axis=1, sort=False, join='inner')
valueA valueB valueC
key
D 2.240893 -0.977278 1.0
Ometti join='inner'per una FULL OUTER JOIN. Notare che non è possibile specificare i join ESTERNO SINISTRO o DESTRO (se necessario, utilizzare join, descritti di seguito).
Unione a più vie su chiavi con duplicati
concatè veloce, ma ha i suoi difetti. Non può gestire i duplicati.
A3 = pd.DataFrame({'key': ['A', 'B', 'C', 'D', 'D'], 'valueA': np.random.randn(5)})
pd.concat([df.set_index('key') for df in [A3, B, C]], axis=1, join='inner')
ValueError: Shape of passed values is (3, 4), indices imply (3, 2)
In questa situazione, possiamo usarlo joinpoiché può gestire chiavi non univoche (nota che joinunisce DataFrames sul loro indice; chiama mergesotto il cofano e fa un LEFT OUTER JOIN se non diversamente specificato).
# join on `key` column, set as the index first
# For inner join. For left join, omit the "how" argument.
A.set_index('key').join(
[df.set_index('key') for df in (B, C)], how='inner').reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# join on `key` index
A3.set_index('key').join([B2, C2], how='inner')
valueA valueB valueC
key
D 1.454274 -0.977278 1.0
D 0.761038 -0.977278 1.0
Una vista visiva supplementare di pd.concat([df0, df1], kwargs). Si noti che il significato di kwarg axis=0or axis=1non è intuitivo come df.mean()odf.apply(func)
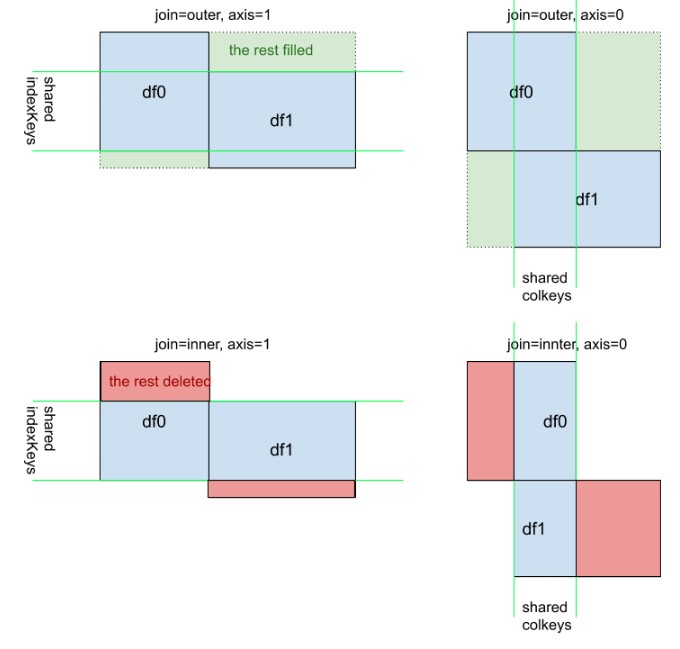
In questa risposta, prenderò in considerazione un esempio pratico di pandas.concat.
Considerando quanto segue DataFramescon gli stessi nomi di colonna:
Preco2018 con dimensione (8784, 5)
Preco 2019 con taglia (8760, 5)
Che hanno gli stessi nomi di colonna.
Puoi combinarli usando pandas.concat, semplicemente
import pandas as pd
frames = [Preco2018, Preco2019]
df_merged = pd.concat(frames)
Il che si traduce in un DataFrame con le seguenti dimensioni (17544, 5)

Se vuoi visualizzare, finisce per funzionare in questo modo
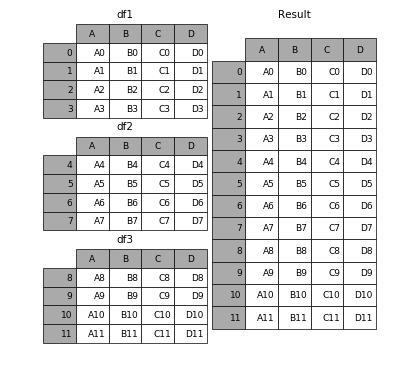
( Fonte )