Aproveitando o poder multi-core com Asyncio em Python

Este é um dos meus artigos na coluna Simultaneidade do Python e, se você achar útil, poderá ler o restante aqui .
Introdução
Neste artigo, mostrarei como executar código assíncrono Python em uma CPU multi-core para desbloquear o desempenho total de tarefas simultâneas.
Qual é o nosso problema?
asyncio usa apenas um núcleo.
Em artigos anteriores, abordei detalhadamente a mecânica do uso do assíncrono do Python. Com esse conhecimento, você pode aprender que o asyncio permite que tarefas vinculadas a IO sejam executadas em alta velocidade alternando manualmente a execução da tarefa para ignorar o processo de contenção GIL durante a alternância de tarefas multiencadeadas.
Teoricamente, o tempo de execução de tarefas vinculadas a IO depende do tempo desde o início até a resposta de uma operação de IO e não depende do desempenho da CPU. Assim, podemos iniciar simultaneamente dezenas de milhares de tarefas de IO e concluí-las rapidamente.
Mas, recentemente, eu estava escrevendo um programa que precisava rastrear dezenas de milhares de páginas da web simultaneamente e descobri que, embora meu programa assíncrono fosse muito mais eficiente do que programas que usam rastreamento iterativo de páginas da web, ainda me fazia esperar muito tempo. Devo usar o desempenho total do meu computador? Então abri o Gerenciador de Tarefas e verifiquei:
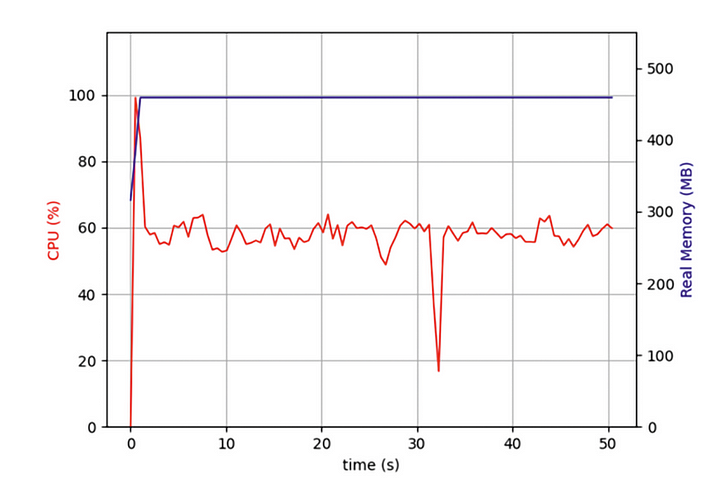
Descobri que, desde o início, meu código estava rodando em apenas um núcleo da CPU e vários outros núcleos estavam ociosos. Além de iniciar operações de IO para obter dados de rede, uma tarefa deve descompactar e formatar os dados após seu retorno. Embora essa parte da operação não consuma muito desempenho da CPU, depois de mais tarefas, essas operações vinculadas à CPU afetarão gravemente o desempenho geral.
Eu queria que minhas tarefas simultâneas assíncronas fossem executadas em paralelo em vários núcleos. Isso prejudicaria o desempenho do meu computador?
Os princípios subjacentes da assíncrona
Para resolver esse quebra-cabeça, devemos começar com a implementação assíncrona subjacente, o loop de eventos.

Conforme mostrado na figura, a melhoria de desempenho do assíncrono para programas começa com tarefas intensivas de E/S. Tarefas intensivas de IO incluem solicitações HTTP, leitura e gravação de arquivos, acesso a bancos de dados, etc. A característica mais importante dessas tarefas é que a CPU não bloqueia e gasta muito tempo computando enquanto aguarda o retorno de dados externos, muito diferente de outra classe de tarefas síncronas que exigem que a CPU esteja ocupada o tempo todo para computar um resultado específico.
Quando geramos um lote de tarefas assíncronas, o código primeiro coloca essas tarefas em uma fila. Neste ponto, existe uma thread chamada event loop que pega uma tarefa por vez da fila e a executa. Quando a tarefa alcança a instrução await e espera (geralmente pelo retorno de uma solicitação), o loop de eventos pega outra tarefa da fila e a executa. Até que a tarefa em espera anterior obtenha dados por meio de um retorno de chamada, o loop de eventos retorna à tarefa em espera anterior e termina de executar o restante do código.
Como o encadeamento do loop de eventos é executado em apenas um núcleo, o loop de eventos é bloqueado quando o “resto do código” ocupa o tempo da CPU. Quando o número de tarefas nessa categoria é grande, cada pequeno segmento de bloqueio aumenta e torna o programa mais lento como um todo.
Qual é a minha solução?
A partir disso, sabemos que os programas assíncronos ficam mais lentos porque nosso código Python executa o loop de eventos em apenas um núcleo, e o processamento de dados de E/S faz com que o programa fique mais lento. Existe uma maneira de iniciar um loop de eventos em cada núcleo da CPU para executá-lo?
Como todos sabemos, a partir do Python 3.7, todo código assíncrono é recomendado para ser executado usando o método asyncio.run, que é uma abstração de alto nível que chama o loop de eventos para executar o código como alternativa ao seguinte código:
try:
loop = asyncio.get_event_loop()
loop.run_until_complete(task())
finally:
loop.close()
O artigo anterior usou um exemplo da vida real para explicar o uso do método assíncrono loop.run_in_executorpara paralelizar a execução do código em um pool de processos e, ao mesmo tempo, obter os resultados de cada processo filho do processo principal. Se você não leu o artigo anterior, pode conferir aqui:
Assim, surge nossa solução: distribuir muitas tarefas simultâneas para vários subprocessos usando execução multinúcleo por meio do loop.run_in_executormétodo e, em seguida, chamar asyncio.runcada subprocesso para iniciar o respectivo loop de eventos e executar o código simultâneo. O diagrama a seguir mostra todo o fluxo:
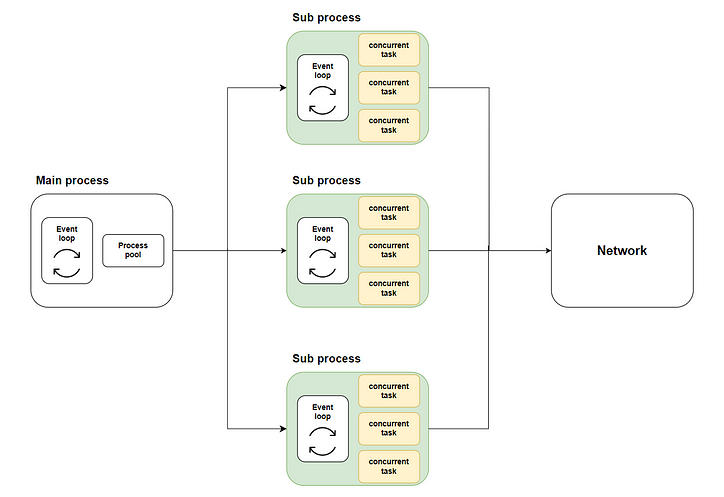
Onde a parte verde representa os subprocessos que iniciamos. A parte amarela representa as tarefas simultâneas que iniciamos.
Preparação antes de começar
Simulando a implementação da tarefa
Antes de podermos resolver o problema, precisamos nos preparar antes de começar. Neste exemplo, não podemos escrever código real para rastrear o conteúdo da web porque seria muito irritante para o site de destino, então simularemos nossa tarefa real com código:
Como mostra o código, primeiro usamos asyncio.sleeppara simular o retorno da tarefa IO em tempo aleatório e uma soma iterativa para simular o processamento da CPU após o retorno dos dados.
O efeito do código tradicional
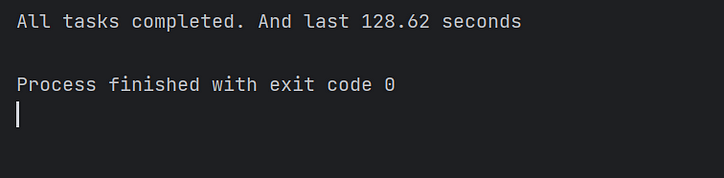
Em seguida, adotamos a abordagem tradicional de iniciar 10.000 tarefas simultâneas em um método principal e observamos o tempo consumido por esse lote de tarefas simultâneas:
Como mostra a figura, executar as tarefas assíncronas com apenas um núcleo leva mais tempo.
A implementação do código
Em seguida, vamos implementar o código assíncrono multi-core de acordo com o fluxograma e ver se o desempenho melhora.
Projetando a estrutura geral do código
Primeiro, como arquiteto, ainda precisamos definir a estrutura geral do script, quais métodos são necessários e quais tarefas cada método precisa realizar:
A implementação específica de cada método
Então, vamos implementar cada método passo a passo.
O query_concurrentlymétodo iniciará o lote especificado de tarefas simultaneamente e obterá os resultados por meio do asyncio.gathermétodo:
O run_batch_tasksmétodo não é um método assíncrono, pois é iniciado diretamente no processo filho:
Finalmente, há o nosso mainmétodo. Este método chamará o loop.run_in_executormétodo para run_batch_tasksexecutar o método no pool de processos e mesclar os resultados da execução do processo filho em uma lista:
Como estamos escrevendo um script multi-processo, precisamos usar if __name__ == “__main__”para iniciar o método main no processo principal:
Execute o código e veja os resultados
Em seguida, iniciamos o script e verificamos a carga de cada núcleo no gerenciador de tarefas:
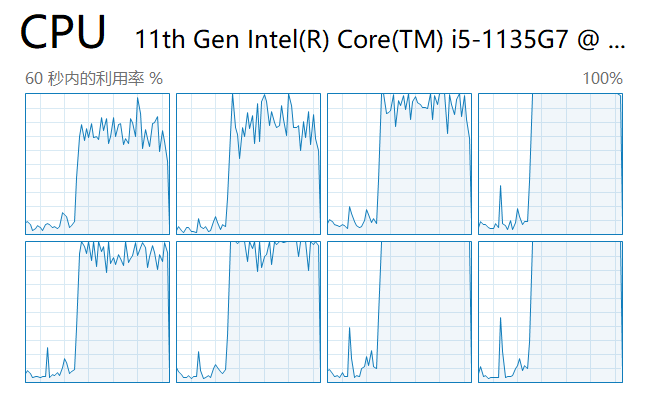
Como você pode ver, todos os núcleos da CPU são utilizados.
Finalmente, observamos o tempo de execução do código e confirmamos que o código assíncrono multi-thread realmente acelera a execução do código várias vezes! Missão cumprida!

Conclusão
Neste artigo, expliquei por que o asyncio pode executar tarefas intensivas de E/S simultaneamente, mas ainda leva mais tempo do que o esperado ao executar grandes lotes de tarefas simultâneas.
É porque no esquema de implementação tradicional do código assíncrono, o loop de eventos só pode executar tarefas em um núcleo e os outros núcleos estão em estado ocioso.
Portanto, implementei uma solução para você chamar cada loop de evento em vários núcleos separadamente para executar tarefas simultâneas em paralelo. E, finalmente, melhorou significativamente o desempenho do código.
Devido à limitação da minha capacidade, a solução neste artigo inevitavelmente tem imperfeições. Congratulo-me com seus comentários e discussão. Vou responder ativamente por você.















































![O que é uma lista vinculada, afinal? [Parte 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)