¿Por qué pagar más por el aprendizaje automático?

Acelere sus cargas de trabajo de aprendizaje desequilibradas con Intel Extension para Scikit-learn
Ethan Glaser, Nikolay Petrov, Henry Gabb y Jui Mhatre, Corporación Intel
Un blog reciente de NVIDIA nos llamó la atención con sus resultados engañosos . ¿Cuál es el punto de comparar una GPU A100 con una CPU de nueve años (la Intel Xeon E5–2698 se lanzó en 2014 y desde entonces se suspendió) o comparar el código CUDA optimizado (la biblioteca RAPIDS cuML) con un solo subproceso no optimizado? ¿Código de Python ( scikit-learn de stock con la biblioteca de aprendizaje desequilibrado ) a menos que esté tratando deliberadamente de inflar la GPU frente a la aceleración de la CPU? La biblioteca de aprendizaje desequilibrado admite estimadores compatibles con scikit-learn, por lo que usaron estimadores cuML para la aceleración. Podemos usar los estimadores optimizados en Intel Extension para Scikit-learn simplemente agregando una llamada a patch_sklearn():
from sklearnex import patch_sklearn
patch_sklearn()
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.neighbors import NearestNeighbors
...
nn = NearestNeighbors(n_neighbors=4, n_jobs=-1)
X_resampled, y_resampled = EditedNearestNeighbours(n_neighbors=nn).fit_resample(X, y)

Comparación de rendimiento
Intel Extension para Scikit-learn ofrece aceleraciones en todos los ámbitos para los mismos puntos de referencia que Nvidia (Figura 1). Las aceleraciones van desde ~2x hasta ~140x según el algoritmo y los parámetros. Tenga en cuenta que la biblioteca stock scikit-learn se quedó sin memoria para los puntos de referencia de SMOTE y ADASYN "100 funciones, 5 clases". Si el rendimiento es importante, estos resultados demuestran que Intel Extension para Scikit-learn ofrece una aceleración significativa en comparación con Scikit-learn estándar.

¿Cómo se compara esto con los resultados del A100 de Nvidia? Echemos un vistazo a los dos algoritmos en los que Nvidia logró las mayores aceleraciones sobre scikit-learn: SVMSMOTE y CondensedNearestNeighbours (Figura 2). Estos resultados muestran que nuestro rendimiento está en un orden de magnitud similar al de cuML cuando se usa un procesador más nuevo y scikit-learn optimizado para comparar. Intel Extension para Scikit-learn incluso supera a cuML en algunas pruebas. Ahora, hablemos del precio.


Comparación de costos
Vale la pena señalar que el costo por hora de una instancia A100 a2-highgpu-1g en GCP es un 60 % más alto que el de la instancia n2-highcpu-64 (Tabla 1). Eso significa que la instancia A100 debe ofrecer una aceleración de al menos 1.6x sobre la instancia Xeon Gold 6268CL (n2-highcpu-64) para ser rentable. (Un A100 también consume 1,7x y 1,2x más energía que Xeon E5–2696 v4 y Xeon Gold 6268CL, respectivamente, pero lo dejaremos de lado por ahora porque el consumo de energía está integrado en el costo de la instancia).
Comparemos las relaciones precio-rendimiento de los puntos de referencia seleccionados por Nvidia para ver si la instancia A100 justifica su precio superior. El costo total (USD) de una ejecución comparativa es simplemente el costo de la instancia por hora (USD/hr) multiplicado por el tiempo de ejecución (hr). Una comparación de costos detallada muestra que ejecutar estos puntos de referencia en la instancia de Xeon suele ser la opción más rentable (Figura 3). En los gráficos a continuación, un valor superior a uno indica que el punto de referencia dado es más caro en la instancia A100. Por ejemplo, un valor de 1,29 significa que la instancia A100 es un 29 % más cara que la instancia Xeon.



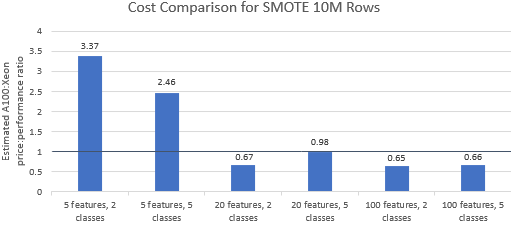
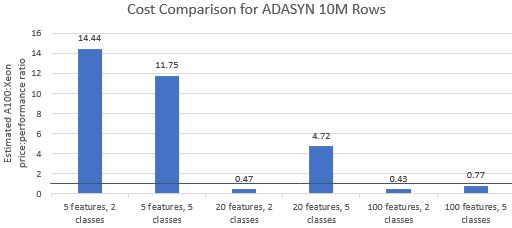
El costo de referencia varía según el algoritmo y los parámetros utilizados, pero los resultados generalmente favorecen la instancia de Xeon: la media geométrica del costo es mayor que uno para cuatro de los cinco algoritmos y la media geométrica general es 1,36 (Tabla 2).

Además, las CPU ofrecen más flexibilidad en la selección de instancias, lo que mejora aún más la eficiencia. Es más rentable seleccionar la instancia de Xeon con capacidad más pequeña que pueda manejar un tamaño de problema dado mientras satisface los requisitos de rendimiento y las restricciones presupuestarias. La Figura 4 muestra uno de esos ejemplos para los dos puntos de referencia más pequeños. Estos resultados demuestran que puede ser significativamente más económico ejecutarlo en el hardware que mejor se adapte a las necesidades de la configuración del modelo. Por ejemplo, ejecutar los dos puntos de referencia de ADASYN con Intel Extension para Scikit-learn en una instancia e2-highcpu-8 es solo el 1,5 % y el 2,1 % del costo de ejecutar cuML en la instancia A100.

Conclusión
Los resultados anteriores demuestran que Intel Extension para Scikit-learn es capaz de mejorar drásticamente los resultados de rendimiento en comparación con Scikit-learn estándar y también es capaz de superar a A100 en algunas pruebas. Cuando se considera el costo, los resultados de Intel Extension for Scikit-learn son aún más favorables porque las instancias Xeon son mucho más económicas que la instancia A100. Los usuarios pueden seleccionar una instancia de Xeon que cumpla con sus requisitos de rendimiento, potencia y precio.

![¿Qué es una lista vinculada, de todos modos? [Parte 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































