Зачем платить больше за машинное обучение?

Ускорьте несбалансированные учебные нагрузки с помощью расширения Intel для Scikit-learn
Итан Глейзер, Николай Петров, Генри Габб и Джуи Мхатре, корпорация Intel
Недавний блог NVIDIA привлек наше внимание вводящими в заблуждение результатами . Какой смысл сравнивать GPU A100 с процессором девятилетней давности (Intel Xeon E5–2698 был выпущен в 2014 году и с тех пор снят с производства) или сравнивать оптимизированный код CUDA (библиотека RAPIDS cuML) с неоптимизированным однопоточным Код Python (стандартный scikit-learn с библиотекой несбалансированного обучения ), если только вы не пытаетесь намеренно увеличить ускорение GPU по сравнению с CPU? Библиотека несбалансированного обучения поддерживает оценщики, совместимые с scikit-learn, поэтому для ускорения они использовали оценщики cuML. Мы можем использовать оптимизированные оценщики в расширении Intel для Scikit-learn , просто добавив вызов patch_sklearn():
from sklearnex import patch_sklearn
patch_sklearn()
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.neighbors import NearestNeighbors
...
nn = NearestNeighbors(n_neighbors=4, n_jobs=-1)
X_resampled, y_resampled = EditedNearestNeighbours(n_neighbors=nn).fit_resample(X, y)

Сравнение производительности
Расширение Intel для Scikit-learn дает ускорение по всем направлениям для тех же тестов, что и Nvidia (рис. 1). Ускорение варьируется от ~ 2x до ~ 140x в зависимости от алгоритма и параметров. Обратите внимание, что стандартной библиотеке scikit-learn не хватило памяти для тестов SMOTE и ADASYN «100 функций, 5 классов». Если производительность имеет значение, эти результаты демонстрируют, что Intel Extension for Scikit-learn обеспечивает значительное ускорение по сравнению со стандартным scikit-learn.

Как это соотносится с результатами Nvidia A100? Давайте взглянем на два алгоритма, в которых Nvidia добилась наибольшего ускорения по сравнению с scikit-learn: SVMSMOTE и CondensedNearestNeighbours (рис. 2). Эти результаты показывают, что наша производительность находится на том же уровне, что и cuML, когда для сравнения используется более новый процессор и оптимизированный scikit-learn. Расширение Intel для Scikit-learn даже превосходит cuML в некоторых тестах. Теперь поговорим о цене.


Сравнение стоимости
Стоит отметить, что почасовая стоимость инстанса a2-highgpu-1g A100 на GCP на 60 % выше, чем у инстанса n2-highcpu-64 (таблица 1). Это означает, что инстанс A100 должен обеспечивать как минимум 1,6-кратное ускорение по сравнению с инстансом Xeon Gold 6268CL (n2-highcpu-64), чтобы быть конкурентоспособным по цене. (А100 также потребляет в 1,7 и 1,2 раза больше энергии, чем Xeon E5-2696 v4 и Xeon Gold 6268CL соответственно, но мы пока отложим это в сторону, поскольку энергопотребление заложено в стоимость инстанса.)
Давайте сравним соотношение цены и производительности для тестов, выбранных Nvidia , чтобы увидеть, оправдывает ли экземпляр A100 свою премиальную цену. Общая стоимость (в долларах США) запуска эталонного теста — это просто стоимость экземпляра в час (доллары США в час), умноженная на время выполнения (часы). Подробное сравнение затрат показывает, что выполнение этих тестов на экземпляре Xeon часто оказывается более экономичным вариантом (рис. 3). На приведенных ниже диаграммах значение больше единицы указывает на то, что данный эталонный показатель дороже экземпляра A100. Например, значение 1,29 означает, что экземпляр A100 на 29 % дороже экземпляра Xeon.



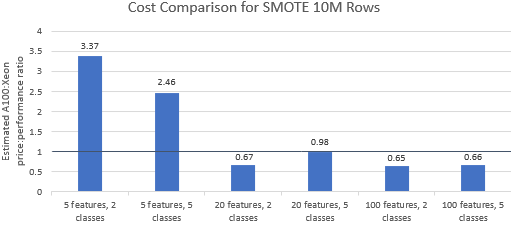
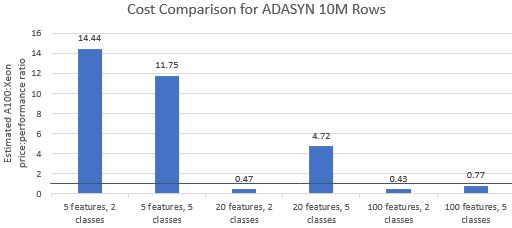
Эталонная стоимость варьируется в зависимости от используемого алгоритма и параметров, но в целом результаты в пользу экземпляра Xeon: среднее геометрическое стоимости больше единицы для четырех из пяти алгоритмов, а общее среднее геометрическое равно 1,36 (таблица 2).

Кроме того, ЦП обеспечивают большую гибкость при выборе экземпляров, что еще больше повышает эффективность. Более экономично выбрать экземпляр Xeon с наименьшими возможностями, способный справиться с задачей заданного размера, удовлетворяя при этом требования к производительности и бюджетные ограничения. На рис. 4 показан один такой пример для двух самых маленьких тестов. Эти результаты показывают, что может быть значительно дешевле работать на оборудовании, которое наилучшим образом соответствует потребностям конфигурации модели. Например, выполнение двух эталонных тестов ADASYN с расширением Intel Extension for Scikit-learn на экземпляре e2-highcpu-8 составляет всего 1,5 % и 2,1 % от стоимости запуска cuML на экземпляре A100.

Заключение
Приведенные выше результаты демонстрируют, что расширение Intel для Scikit-learn способно значительно улучшить результаты производительности по сравнению со стандартным scikit-learn, а также может превзойти A100 в некоторых тестах. С точки зрения стоимости результаты Intel Extension for Scikit-learn еще более благоприятны, поскольку экземпляры Xeon намного дешевле, чем экземпляры A100. Пользователи могут выбрать экземпляр Xeon, отвечающий их требованиям к производительности, мощности и цене.

![В любом случае, что такое связанный список? [Часть 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































