Apakah matematika floating point rusak?
Perhatikan kode berikut:
0.1 + 0.2 == 0.3 -> false
0.1 + 0.2 -> 0.30000000000000004
Mengapa ketidakakuratan ini terjadi?
Jawaban
Matematika floating point biner adalah seperti ini. Di sebagian besar bahasa pemrograman, ini didasarkan pada standar IEEE 754 . Inti dari masalah ini adalah bahwa bilangan direpresentasikan dalam format ini sebagai bilangan bulat dikalikan pangkat dua; bilangan rasional (seperti 0.1, yang mana 1/10) yang penyebutnya bukan pangkat dua tidak dapat direpresentasikan secara tepat.
Karena 0.1dalam binary64format standar , representasi bisa ditulis persis seperti
0.1000000000000000055511151231257827021181583404541015625dalam desimal, atau0x1.999999999999ap-4dalam notasi hexfloat C99 .
Sebaliknya, bilangan rasional 0.1, yang 1/10dapat dituliskan persis seperti
0.1dalam desimal, atau0x1.99999999999999...p-4dalam analog notasi hexfloat C99, di mana...mewakili urutan 9 yang tak berujung.
Konstanta 0.2dan 0.3program Anda juga akan menjadi perkiraan nilai sebenarnya. Hal ini terjadi bahwa yang paling dekat doubleuntuk 0.2lebih besar dari jumlah yang rasional 0.2tapi itu yang paling dekat doubleuntuk 0.3lebih kecil dari jumlah yang rasional 0.3. Jumlah 0.1dan 0.2akhirnya menjadi lebih besar dari bilangan rasional 0.3dan karenanya tidak sesuai dengan konstanta dalam kode Anda.
Perawatan yang cukup komprehensif untuk masalah aritmatika floating-point adalah Apa yang Harus Diketahui Setiap Ilmuwan Komputer Tentang Aritmatika Titik-mengambang . Untuk penjelasan yang lebih mudah dicerna, lihat floating-point-gui.de .
Catatan Samping: Semua sistem nomor posisi (basis-N) berbagi masalah ini dengan presisi
Angka desimal lama biasa (basis 10) memiliki masalah yang sama, itulah sebabnya angka seperti 1/3 berakhir sebagai 0,3333333333 ...
Anda baru saja menemukan angka (3/10) yang mudah diwakili oleh sistem desimal, tetapi tidak sesuai dengan sistem biner. Ini berlaku dua arah (untuk beberapa derajat kecil) juga: 1/16 adalah angka jelek dalam desimal (0,0625), tetapi dalam biner terlihat serapi 10.000 dalam desimal (0,0001) ** - jika kita berada di Kebiasaan menggunakan sistem bilangan berbasis 2 dalam kehidupan kita sehari-hari, Anda bahkan akan melihat angka itu dan secara naluriah memahami bahwa Anda bisa sampai di sana dengan membagi dua, membelahnya lagi, dan lagi dan lagi.
** Tentu saja, bilangan floating-point tidak persis seperti itu disimpan dalam memori (mereka menggunakan bentuk notasi ilmiah). Namun, ini menggambarkan titik bahwa kesalahan presisi floating-point biner cenderung muncul karena bilangan "dunia nyata" yang biasanya kami minati sering kali merupakan pangkat sepuluh - tetapi hanya karena kami menggunakan sistem bilangan desimal hari- hari ini. Ini juga mengapa kita akan mengatakan hal-hal seperti 71% alih-alih "5 dari setiap 7" (71% adalah perkiraan, karena 5/7 tidak dapat direpresentasikan secara tepat dengan angka desimal apa pun).
Jadi tidak: bilangan floating point biner tidak rusak, mereka kebetulan sama tidak sempurna dengan setiap sistem bilangan base-N lainnya :)
Side Side Note: Bekerja dengan Floats dalam Pemrograman
Dalam praktiknya, masalah ketepatan ini berarti Anda perlu menggunakan fungsi pembulatan untuk membulatkan bilangan floating point Anda ke berapa pun tempat desimal yang Anda minati sebelum Anda menampilkannya.
Anda juga perlu mengganti pengujian kesetaraan dengan perbandingan yang memungkinkan sejumlah toleransi, yang berarti:
Jangan tidak melakukanif (x == y) { ... }
Sebaliknya lakukan if (abs(x - y) < myToleranceValue) { ... }.
dimana absnilai absolutnya. myToleranceValueharus dipilih untuk aplikasi khusus Anda - dan itu akan banyak berkaitan dengan berapa banyak "ruang gerak" yang Anda siapkan untuk memungkinkan, dan berapa jumlah terbesar yang akan Anda bandingkan (karena hilangnya masalah presisi ). Waspadalah terhadap konstanta gaya "epsilon" dalam bahasa pilihan Anda. Ini tidak untuk digunakan sebagai nilai toleransi.
Perspektif Desainer Perangkat Keras
Saya yakin saya harus menambahkan perspektif perancang perangkat keras untuk ini karena saya merancang dan membangun perangkat keras floating point. Mengetahui asal mula kesalahan dapat membantu dalam memahami apa yang terjadi pada perangkat lunak, dan pada akhirnya, saya harap ini membantu menjelaskan alasan mengapa kesalahan floating point terjadi dan tampaknya terakumulasi dari waktu ke waktu.
1. Ikhtisar
Dari perspektif teknik, sebagian besar operasi floating point akan memiliki beberapa elemen kesalahan karena perangkat keras yang melakukan perhitungan floating point hanya perlu memiliki kesalahan kurang dari setengah dari satu unit di tempat terakhir. Oleh karena itu, banyak perangkat keras akan berhenti pada presisi yang hanya diperlukan untuk menghasilkan kesalahan kurang dari setengah dari satu unit di tempat terakhir untuk operasi tunggal yang sangat bermasalah dalam pembagian floating point. Apa yang dimaksud dengan operasi tunggal bergantung pada berapa banyak operand yang dibutuhkan unit. Untuk sebagian besar, ini adalah dua, tetapi beberapa unit membutuhkan 3 operan atau lebih. Karena itu, tidak ada jaminan bahwa operasi berulang akan menghasilkan kesalahan yang diinginkan karena kesalahan bertambah seiring waktu.
2. Standar
Sebagian besar prosesor mengikuti standar IEEE-754 tetapi beberapa menggunakan standar yang didenormalisasi, atau berbeda. Misalnya, ada mode denormalisasi di IEEE-754 yang memungkinkan representasi bilangan floating point yang sangat kecil dengan mengorbankan presisi. Berikut ini, bagaimanapun, akan mencakup mode normalisasi IEEE-754 yang merupakan mode operasi tipikal.
Dalam standar IEEE-754, perancang perangkat keras diizinkan nilai kesalahan / epsilon apa pun selama kurang dari setengah dari satu unit di tempat terakhir, dan hasilnya hanya harus kurang dari setengah dari satu unit di tempat terakhir. tempat untuk satu operasi. Ini menjelaskan mengapa ketika ada operasi berulang, kesalahan bertambah. Untuk presisi ganda IEEE-754, ini adalah bit ke-54, karena 53 bit digunakan untuk mewakili bagian numerik (dinormalisasi), juga disebut mantissa, dari bilangan floating point (misalnya 5.3 dalam 5.3e5). Bagian selanjutnya membahas lebih detail tentang penyebab kesalahan perangkat keras pada berbagai operasi floating point.
3. Penyebab Kesalahan Pembulatan pada Divisi
Penyebab utama kesalahan dalam pembagian floating point adalah algoritma pembagian yang digunakan untuk menghitung hasil bagi. Kebanyakan sistem komputer menghitung pembagian menggunakan perkalian dengan terbalik, terutama dalam Z=X/Y, Z = X * (1/Y). Pembagian dihitung secara iteratif yaitu setiap siklus menghitung beberapa bit hasil bagi sampai presisi yang diinginkan tercapai, yang untuk IEEE-754 adalah apa pun dengan kesalahan kurang dari satu unit di tempat terakhir. Tabel timbal balik dari Y (1 / Y) dikenal sebagai tabel pemilihan hasil bagi (QST) di divisi lambat, dan ukuran dalam bit tabel pemilihan hasil bagi biasanya adalah lebar radix, atau sejumlah bit hasil bagi dihitung di setiap iterasi, ditambah beberapa bit penjaga. Untuk standar IEEE-754, presisi ganda (64-bit), itu akan menjadi ukuran radix pembagi, ditambah beberapa bit penjaga k, di mana k>=2. Jadi misalnya, Tabel Pemilihan Hasil Bagi yang khas untuk pembagi yang menghitung 2 bit hasil bagi pada satu waktu (radix 4) akan menjadi 2+2= 4bit (ditambah beberapa bit opsional).
3.1 Kesalahan Pembulatan Divisi: Perkiraan Timbal Balik
Resiprokal yang ada dalam tabel pemilihan hasil bagi bergantung pada metode pembagian : pembagian lambat seperti pembagian SRT, atau pembagian cepat seperti pembagian Goldschmidt; setiap entri dimodifikasi sesuai dengan algoritma pembagian dalam upaya untuk menghasilkan kesalahan serendah mungkin. Namun, dalam kasus apa pun, semua timbal balik adalah perkiraan timbal balik aktual dan memperkenalkan beberapa elemen kesalahan. Metode pembagian lambat dan pembagian cepat menghitung hasil bagi secara iteratif, yaitu sejumlah bit hasil bagi dihitung setiap langkah, kemudian hasilnya dikurangi dari dividen, dan pembagi mengulangi langkah-langkah tersebut hingga kesalahannya kurang dari setengah satu unit di tempat terakhir. Metode pembagian lambat menghitung jumlah tetap dari digit hasil bagi di setiap langkah dan biasanya lebih murah untuk dibuat, dan metode pembagian cepat menghitung sejumlah variabel digit per langkah dan biasanya lebih mahal untuk dibuat. Bagian terpenting dari metode pembagian adalah bahwa kebanyakan dari mereka bergantung pada perkalian berulang dengan pendekatan timbal balik, sehingga mereka rentan terhadap kesalahan.
4. Kesalahan Pembulatan dalam Operasi Lain: Pemotongan
Penyebab lain dari kesalahan pembulatan di semua operasi adalah mode pemotongan yang berbeda dari jawaban akhir yang diizinkan oleh IEEE-754. Ada pemotongan, pembulatan ke nol, pembulatan ke terdekat (default), pembulatan ke bawah, dan pembulatan ke atas. Semua metode memperkenalkan elemen kesalahan kurang dari satu unit di tempat terakhir untuk satu operasi. Seiring waktu dan operasi berulang, pemotongan juga menambah kesalahan yang dihasilkan secara kumulatif. Kesalahan pemotongan ini sangat bermasalah dalam eksponensial, yang melibatkan beberapa bentuk perkalian berulang.
5. Operasi Berulang
Karena perangkat keras yang melakukan penghitungan floating point hanya perlu menghasilkan hasil dengan kesalahan kurang dari setengah dari satu unit di tempat terakhir untuk satu operasi, kesalahan akan bertambah selama operasi berulang jika tidak diawasi. Ini adalah alasan bahwa dalam komputasi yang membutuhkan kesalahan terbatas, matematikawan menggunakan metode seperti menggunakan digit genap bulat-ke-terdekat di tempat terakhir IEEE-754, karena, seiring waktu, kesalahan lebih cenderung membatalkan satu sama lain. out, dan Aritmatika Interval dikombinasikan dengan variasi mode pembulatan IEEE 754 untuk memprediksi kesalahan pembulatan, dan memperbaikinya. Karena kesalahan relatifnya yang rendah dibandingkan dengan mode pembulatan lainnya, pembulatan ke digit genap terdekat (di tempat terakhir), adalah mode pembulatan default dari IEEE-754.
Perhatikan bahwa mode pembulatan default, angka genap bulat-ke-terdekat di tempat terakhir , menjamin kesalahan kurang dari satu setengah unit di tempat terakhir untuk satu operasi. Menggunakan pemotongan, pembulatan, dan pembulatan ke bawah saja dapat menghasilkan kesalahan yang lebih besar dari setengah dari satu unit di tempat terakhir, tetapi kurang dari satu unit di tempat terakhir, jadi mode ini tidak disarankan kecuali jika ada. digunakan dalam Aritmatika Interval.
6. Ringkasan
Singkatnya, alasan mendasar untuk kesalahan dalam operasi floating point adalah kombinasi dari pemotongan perangkat keras, dan pemotongan timbal balik dalam kasus pembagian. Karena standar IEEE-754 hanya membutuhkan kesalahan kurang dari setengah dari satu unit di tempat terakhir untuk satu operasi, kesalahan floating point selama operasi berulang akan bertambah kecuali diperbaiki.
Ini dipecah dengan cara yang sama persis dengan notasi desimal (basis 10), hanya untuk basis 2.
Untuk memahaminya, pikirkan tentang merepresentasikan 1/3 sebagai nilai desimal. Tidak mungkin untuk melakukan dengan tepat! Dengan cara yang sama, 1/10 (desimal 0,1) tidak dapat direpresentasikan dengan tepat dalam basis 2 (biner) sebagai nilai "desimal"; pola berulang setelah koma desimal berlangsung selamanya. Nilainya tidak tepat, dan oleh karena itu Anda tidak dapat melakukan matematika persis dengannya menggunakan metode titik mengambang normal.
Sebagian besar jawaban di sini menjawab pertanyaan ini dengan istilah teknis yang sangat kering. Saya ingin membahas ini dalam istilah yang dapat dipahami oleh manusia normal.
Bayangkan Anda mencoba mengiris pizza. Anda memiliki pemotong pizza robot yang dapat memotong potongan pizza tepat menjadi dua. Itu bisa membagi dua pizza utuh, atau bisa juga membagi dua potongan yang ada, tapi bagaimanapun, halving selalu tepat.
Pemotong pizza itu memiliki gerakan yang sangat halus, dan jika Anda mulai dengan seluruh pizza, kemudian membelahnya, dan terus membagi dua bagian terkecil setiap kali, Anda dapat melakukan halving sebanyak 53 kali sebelum potongannya terlalu kecil bahkan untuk kemampuan presisi tingginya. . Pada saat itu, Anda tidak dapat lagi membagi dua bagian yang sangat tipis itu, tetapi harus menyertakan atau mengecualikannya sebagaimana adanya.
Sekarang, bagaimana Anda akan memotong semua irisan sedemikian rupa sehingga menghasilkan sepersepuluh (0,1) atau seperlima (0,2) dari pizza? Benar-benar pikirkan tentang itu, dan coba kerjakan. Anda bahkan dapat mencoba menggunakan pizza asli, jika Anda memiliki pemotong pizza presisi yang mistis. :-)
Kebanyakan programmer berpengalaman, tentu saja, tahu jawaban sebenarnya, yaitu bahwa tidak ada cara untuk menyatukan kepingan tepat sepersepuluh atau seperlima dari pizza menggunakan mereka iris, tidak peduli seberapa halus Anda mengiris mereka. Anda dapat melakukan aproksimasi yang cukup bagus, dan jika Anda menjumlahkan aproksimasi 0,1 dengan aproksimasi 0,2, Anda mendapatkan aproksimasi 0,3 yang cukup bagus, tetapi tetap saja, aproksimasi.
Untuk angka presisi ganda (yaitu presisi yang memungkinkan Anda membagi dua pizza Anda 53 kali), angka yang segera kurang dan lebih besar dari 0,1 adalah 0,09999999999999999167332731531132594682276248931884765625 dan 0,000000000000000055511151231257827021181583404541015625. Yang terakhir lebih dekat ke 0,1 daripada yang sebelumnya, jadi pengurai numerik akan, dengan masukan 0,1, mendukung yang terakhir.
(Perbedaan antara kedua angka tersebut adalah "potongan terkecil" yang harus kita putuskan untuk disertakan, yang menyebabkan bias ke atas, atau dikecualikan, yang menyebabkan bias ke bawah. Istilah teknis untuk potongan terkecil itu adalah ulp .)
Dalam kasus 0,2, semua angkanya sama, hanya ditingkatkan dengan faktor 2. Sekali lagi, kami menyukai nilai yang sedikit lebih tinggi dari 0,2.
Perhatikan bahwa dalam kedua kasus tersebut, perkiraan untuk 0,1 dan 0,2 memiliki sedikit bias ke atas. Jika kita menambahkan cukup banyak bias ini, mereka akan mendorong angka semakin jauh dari yang kita inginkan, dan pada kenyataannya, dalam kasus 0,1 + 0,2, biasnya cukup tinggi sehingga angka yang dihasilkan bukan lagi angka terdekat. menjadi 0,3.
Khususnya, 0,1 + 0,2 benar-benar 0,000000000000000055511151231257827021181583404541015625 + 0,200000000000000011102230246251565404236316680908203125 = 0,3000000000000000444089209850062616169452667236328125
PS Beberapa bahasa pemrograman juga menyediakan pemotong pizza yang dapat membagi irisan menjadi persepuluhan yang tepat . Meskipun pemotong pizza semacam itu jarang terjadi, jika Anda memiliki akses ke sana, Anda harus menggunakannya pada saat-saat penting untuk bisa mendapatkan sepersepuluh atau seperlima dari potongan.
(Awalnya diposting di Quora.)
Kesalahan pembulatan floating point. 0,1 tidak dapat direpresentasikan secara akurat dalam basis 2 seperti pada basis 10 karena faktor prima 5. yang hilang sama seperti 1/3 membutuhkan jumlah digit tak hingga untuk mewakili dalam desimal, tetapi adalah "0,1" dalam basis 3, 0.1 mengambil jumlah digit yang tak terbatas di basis 2 di mana tidak di basis 10. Dan komputer tidak memiliki jumlah memori yang tidak terbatas.
Selain jawaban benar lainnya, Anda mungkin ingin mempertimbangkan penskalaan nilai Anda untuk menghindari masalah dengan aritmatika floating-point.
Sebagai contoh:
var result = 1.0 + 2.0; // result === 3.0 returns true
... dari pada:
var result = 0.1 + 0.2; // result === 0.3 returns false
Ekspresi 0.1 + 0.2 === 0.3kembali falsedalam JavaScript, tetapi untungnya aritmatika bilangan bulat dalam floating-point tepat, sehingga kesalahan representasi desimal dapat dihindari dengan penskalaan.
Sebagai contoh praktis, untuk menghindari masalah floating-point di mana akurasi adalah yang terpenting, direkomendasikan 1 untuk menangani uang sebagai bilangan bulat yang mewakili jumlah sen: 2550sen, bukan 25.50dolar.
1 Douglas Crockford: JavaScript: Bagian yang Baik : Lampiran A - Bagian yang Mengerikan (halaman 105) .
Jawaban saya cukup panjang, jadi saya membaginya menjadi tiga bagian. Karena pertanyaannya adalah tentang matematika floating point, saya telah menekankan pada apa yang sebenarnya dilakukan mesin. Saya juga membuatnya khusus untuk menggandakan presisi (64 bit), tetapi argumennya berlaku sama untuk aritmatika floating point apa pun.
Pembukaan
Sebuah IEEE 754 presisi ganda biner Format floating-point (binary64) nomor mewakili sejumlah bentuk
nilai = (-1) ^ s * (1.m 51 m 50 ... m 2 m 1 m 0 ) 2 * 2 e-1023
dalam 64 bit:
- Bit pertama adalah bit tanda :
1jika angkanya negatif,0jika tidak 1 . - 11 bit berikutnya adalah eksponen , yang diimbangi dengan 1023. Dengan kata lain, setelah membaca bit eksponen dari bilangan presisi ganda, 1023 harus dikurangi untuk mendapatkan pangkat dua.
- 52 bit sisanya adalah signifikan (atau mantissa). Dalam mantissa, 'tersirat'
1.selalu 2 dihilangkan karena bit paling signifikan dari nilai biner mana pun adalah1.
1 - IEEE 754 memungkinkan konsep nol bertanda - +0dan -0diperlakukan berbeda: 1 / (+0)positif tak terhingga; 1 / (-0)adalah ketidakterbatasan negatif. Untuk nilai nol, bit mantissa dan eksponen semuanya nol. Catatan: nilai nol (+0 dan -0) secara eksplisit tidak digolongkan sebagai denormal 2 .
2 - Ini bukan kasus untuk bilangan denormal , yang memiliki eksponen offset nol (dan tersirat 0.). Kisaran angka presisi ganda denormal adalah d min ≤ | x | ≤ d max , di mana d min (bilangan bukan nol terkecil yang dapat diwakili) adalah 2 -1023 - 51 (≈ 4,94 * 10 -324 ) dan d max (bilangan denormal terbesar, yang mantisanya seluruhnya terdiri dari 1s) adalah 2 -1023 + 1 - 2 -1023 - 51 (≈ 2.225 * 10 -308 ).
Mengubah angka presisi ganda menjadi biner
Banyak konverter online ada untuk mengonversi bilangan titik mengambang presisi ganda ke biner (misalnya di binaryconvert.com ), tetapi berikut adalah beberapa contoh kode C # untuk mendapatkan representasi IEEE 754 untuk bilangan presisi ganda (Saya memisahkan tiga bagian dengan titik dua ( :) :
public static string BinaryRepresentation(double value)
{
long valueInLongType = BitConverter.DoubleToInt64Bits(value);
string bits = Convert.ToString(valueInLongType, 2);
string leadingZeros = new string('0', 64 - bits.Length);
string binaryRepresentation = leadingZeros + bits;
string sign = binaryRepresentation[0].ToString();
string exponent = binaryRepresentation.Substring(1, 11);
string mantissa = binaryRepresentation.Substring(12);
return string.Format("{0}:{1}:{2}", sign, exponent, mantissa);
}
Langsung ke intinya: pertanyaan asli
(Lewati ke bawah untuk versi TL; DR)
Cato Johnston (penanya pertanyaan) bertanya mengapa 0,1 + 0,2! = 0,3.
Ditulis dalam biner (dengan titik dua memisahkan tiga bagian), representasi IEEE 754 dari nilainya adalah:
0.1 => 0:01111111011:1001100110011001100110011001100110011001100110011010
0.2 => 0:01111111100:1001100110011001100110011001100110011001100110011010
Perhatikan bahwa mantissa terdiri dari digit berulang 0011. Ini adalah kunci mengapa ada kesalahan pada perhitungan - 0,1, 0,2 dan 0,3 tidak dapat direpresentasikan dalam biner secara tepat dalam jumlah bit biner yang terbatas, lebih dari 1/9, 1/3 atau 1/7 dapat direpresentasikan dengan tepat di angka desimal .
Perhatikan juga bahwa kita dapat menurunkan pangkat dalam eksponen sebesar 52 dan menggeser titik dalam representasi biner ke kanan sebanyak 52 tempat (seperti 10 -3 * 1,23 == 10 -5 * 123). Ini kemudian memungkinkan kita untuk merepresentasikan representasi biner sebagai nilai eksak yang diwakilinya dalam bentuk a * 2 p . di mana 'a' adalah bilangan bulat.
Mengubah eksponen menjadi desimal, menghapus offset, dan menambahkan kembali tersirat 1(dalam tanda kurung siku), 0,1 dan 0,2 adalah:
0.1 => 2^-4 * [1].1001100110011001100110011001100110011001100110011010
0.2 => 2^-3 * [1].1001100110011001100110011001100110011001100110011010
or
0.1 => 2^-56 * 7205759403792794 = 0.1000000000000000055511151231257827021181583404541015625
0.2 => 2^-55 * 7205759403792794 = 0.200000000000000011102230246251565404236316680908203125
Untuk menjumlahkan dua angka, eksponennya harus sama, yaitu:
0.1 => 2^-3 * 0.1100110011001100110011001100110011001100110011001101(0)
0.2 => 2^-3 * 1.1001100110011001100110011001100110011001100110011010
sum = 2^-3 * 10.0110011001100110011001100110011001100110011001100111
or
0.1 => 2^-55 * 3602879701896397 = 0.1000000000000000055511151231257827021181583404541015625
0.2 => 2^-55 * 7205759403792794 = 0.200000000000000011102230246251565404236316680908203125
sum = 2^-55 * 10808639105689191 = 0.3000000000000000166533453693773481063544750213623046875
Karena jumlahnya bukan dalam bentuk 2 n * 1. {bbb} kita menambah eksponen satu dan menggeser titik desimal ( biner ) untuk mendapatkan:
sum = 2^-2 * 1.0011001100110011001100110011001100110011001100110011(1)
= 2^-54 * 5404319552844595.5 = 0.3000000000000000166533453693773481063544750213623046875
Sekarang ada 53 bit di mantissa (yang ke 53 dalam tanda kurung siku di baris di atas). Modus pembulatan default untuk IEEE 754 adalah ' Round to Nearest ' - yaitu jika angka x berada di antara dua nilai a dan b , nilai di mana bit yang paling tidak signifikan adalah nol yang dipilih.
a = 2^-54 * 5404319552844595 = 0.299999999999999988897769753748434595763683319091796875
= 2^-2 * 1.0011001100110011001100110011001100110011001100110011
x = 2^-2 * 1.0011001100110011001100110011001100110011001100110011(1)
b = 2^-2 * 1.0011001100110011001100110011001100110011001100110100
= 2^-54 * 5404319552844596 = 0.3000000000000000444089209850062616169452667236328125
Perhatikan bahwa a dan b hanya berbeda pada bit terakhir; ...0011+ 1= ...0100. Dalam hal ini, nilai dengan bit paling kecil dari nol adalah b , jadi jumlahnya adalah:
sum = 2^-2 * 1.0011001100110011001100110011001100110011001100110100
= 2^-54 * 5404319552844596 = 0.3000000000000000444089209850062616169452667236328125
sedangkan representasi biner 0,3 adalah:
0.3 => 2^-2 * 1.0011001100110011001100110011001100110011001100110011
= 2^-54 * 5404319552844595 = 0.299999999999999988897769753748434595763683319091796875
yang hanya berbeda dari representasi biner dari jumlah 0,1 dan 0,2 dengan 2 -54 .
Representasi biner 0,1 dan 0,2 adalah representasi paling akurat dari angka yang diizinkan oleh IEEE 754. Penambahan representasi ini, karena mode pembulatan default, menghasilkan nilai yang hanya berbeda pada bit yang paling signifikan.
TL; DR
Menulis 0.1 + 0.2dalam representasi biner IEEE 754 (dengan titik dua memisahkan tiga bagian) dan membandingkannya dengan 0.3, ini (saya telah meletakkan bit yang berbeda dalam tanda kurung siku):
0.1 + 0.2 => 0:01111111101:0011001100110011001100110011001100110011001100110[100]
0.3 => 0:01111111101:0011001100110011001100110011001100110011001100110[011]
Dikonversi kembali ke desimal, nilai-nilai ini adalah:
0.1 + 0.2 => 0.300000000000000044408920985006...
0.3 => 0.299999999999999988897769753748...
Perbedaannya persis 2 -54 , yaitu ~ 5,5511151231258 × 10 -17 - tidak signifikan (untuk banyak aplikasi) jika dibandingkan dengan nilai aslinya.
Membandingkan beberapa bit terakhir dari bilangan floating point pada dasarnya berbahaya, karena siapa pun yang membaca " Apa yang Harus Diketahui Setiap Ilmuwan Komputer Tentang Aritmatika Titik Mengambang " yang terkenal (yang mencakup semua bagian utama dari jawaban ini) akan mengetahuinya.
Kebanyakan kalkulator menggunakan digit penjaga tambahan untuk mengatasi masalah ini, seperti yang 0.1 + 0.2akan diberikan 0.3: beberapa bit terakhir dibulatkan.
Bilangan floating point yang disimpan di komputer terdiri dari dua bagian, bilangan bulat dan eksponen yang basisnya diambil dan dikalikan dengan bagian bilangan bulat.
Jika komputer bekerja di basis 10, 0.1akan 1 x 10⁻¹, 0.2akan 2 x 10⁻¹, dan 0.3akan 3 x 10⁻¹. Matematika bilangan bulat itu mudah dan tepat, jadi penjumlahan 0.1 + 0.2pasti akan menghasilkan 0.3.
Komputer tidak biasanya bekerja dalam basis 10, mereka bekerja dalam basis 2. Anda masih bisa mendapatkan hasil yang tepat untuk beberapa nilai, misalnya 0.5adalah 1 x 2⁻¹dan 0.25adalah 1 x 2⁻², dan menambahkan mereka menghasilkan 3 x 2⁻², atau 0.75. Persis.
Masalahnya muncul dengan angka yang dapat direpresentasikan persis di basis 10, tetapi tidak di basis 2. Angka-angka itu perlu dibulatkan ke angka terdekatnya. Dengan asumsi format titik mengambang IEEE 64-bit yang sangat umum, angka terdekat ke 0.1adalah 3602879701896397 x 2⁻⁵⁵, dan angka terdekat ke 0.2adalah 7205759403792794 x 2⁻⁵⁵; menambahkan mereka bersama-sama menghasilkan 10808639105689191 x 2⁻⁵⁵, atau nilai desimal yang tepat dari 0.3000000000000000444089209850062616169452667236328125. Angka floating point umumnya dibulatkan untuk tampilan.
Kesalahan pembulatan titik mengambang. Dari Apa Yang Harus Diketahui Setiap Ilmuwan Komputer Tentang Aritmatika Titik-Apung :
Meremas banyak bilangan real yang tak terhingga menjadi sejumlah bit yang terbatas membutuhkan representasi perkiraan. Meskipun ada banyak bilangan bulat yang tak terhingga, pada kebanyakan program hasil perhitungan bilangan bulat dapat disimpan dalam 32 bit. Sebaliknya, dengan jumlah bit yang tetap, sebagian besar kalkulasi dengan bilangan real akan menghasilkan kuantitas yang tidak dapat direpresentasikan secara tepat menggunakan banyak bit tersebut. Oleh karena itu, hasil kalkulasi floating-point seringkali harus dibulatkan agar sesuai kembali ke representasi finitnya. Kesalahan pembulatan ini adalah fitur karakteristik komputasi floating-point.
Solusi saya:
function add(a, b, precision) {
var x = Math.pow(10, precision || 2);
return (Math.round(a * x) + Math.round(b * x)) / x;
}
presisi mengacu pada jumlah digit yang ingin Anda pertahankan setelah koma desimal selama penjumlahan.
Banyak jawaban bagus telah diposting, tapi saya ingin menambahkan satu lagi.
Tidak semua angka dapat direpresentasikan melalui float / doubles Misalnya, angka "0,2" akan direpresentasikan sebagai "0.200000003" dalam presisi tunggal dalam standar titik mengambang IEEE754.
Model untuk menyimpan bilangan real di bawah kap mewakili bilangan float sebagai
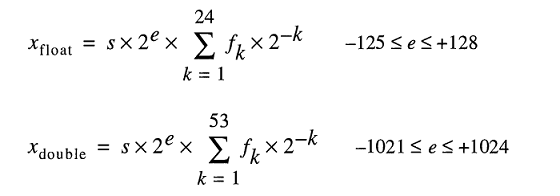
Meskipun Anda dapat mengetik 0.2dengan mudah, FLT_RADIXdan DBL_RADIX2; bukan 10 untuk komputer dengan FPU yang menggunakan "IEEE Standard for Binary Floating-Point Arithmetic (ISO / IEEE Std 754-1985)".
Jadi agak sulit untuk merepresentasikan angka seperti itu dengan tepat. Meskipun Anda menentukan variabel ini secara eksplisit tanpa kalkulasi perantara.
Beberapa statistik terkait dengan pertanyaan presisi ganda yang terkenal ini.
Saat menambahkan semua nilai ( a + b ) menggunakan langkah 0,1 (dari 0,1 hingga 100) kami memiliki ~ 15% kemungkinan kesalahan presisi . Perhatikan bahwa kesalahan dapat menghasilkan nilai yang sedikit lebih besar atau lebih kecil. Berikut beberapa contohnya:
0.1 + 0.2 = 0.30000000000000004 (BIGGER)
0.1 + 0.7 = 0.7999999999999999 (SMALLER)
...
1.7 + 1.9 = 3.5999999999999996 (SMALLER)
1.7 + 2.2 = 3.9000000000000004 (BIGGER)
...
3.2 + 3.6 = 6.800000000000001 (BIGGER)
3.2 + 4.4 = 7.6000000000000005 (BIGGER)
Saat mengurangkan semua nilai ( a - b di mana a> b ) menggunakan langkah 0,1 (dari 100 ke 0,1) kami memiliki ~ 34% kemungkinan kesalahan presisi . Berikut beberapa contohnya:
0.6 - 0.2 = 0.39999999999999997 (SMALLER)
0.5 - 0.4 = 0.09999999999999998 (SMALLER)
...
2.1 - 0.2 = 1.9000000000000001 (BIGGER)
2.0 - 1.9 = 0.10000000000000009 (BIGGER)
...
100 - 99.9 = 0.09999999999999432 (SMALLER)
100 - 99.8 = 0.20000000000000284 (BIGGER)
* 15% dan 34% memang sangat besar, jadi selalu gunakan BigDecimal jika presisi sangat penting. Dengan 2 digit desimal (langkah 0,01) situasinya semakin memburuk (18% dan 36%).
Tidak, tidak rusak, tetapi sebagian besar pecahan desimal harus didekati
Ringkasan
Aritmatika floating point itu tepat, sayangnya tidak cocok dengan representasi bilangan base-10 yang biasa kita lakukan, sehingga ternyata kita sering memberikan input yang sedikit meleset dari yang kita tulis.
Bahkan angka sederhana seperti 0,01, 0,02, 0,03, 0,04 ... 0,24 tidak dapat direpresentasikan persis sebagai pecahan biner. Jika Anda menghitung 0,01, 0,02, 0,03 ..., Anda tidak akan mendapatkan pecahan pertama yang mewakili basis 2 sebelum Anda mencapai 0,25 . Jika Anda mencobanya menggunakan FP, 0,01 Anda akan sedikit meleset, jadi satu-satunya cara untuk menambahkan 25 di antaranya hingga tepat 0,25 akan memerlukan rantai kausalitas panjang yang melibatkan bit penjaga dan pembulatan. Sulit untuk diprediksi jadi kami angkat tangan dan berkata "FP tidak tepat", tapi itu tidak benar.
Kami terus-menerus memberikan perangkat keras FP sesuatu yang tampak sederhana di basis 10 tetapi merupakan pecahan berulang di basis 2.
Bagaimana ini bisa terjadi?
Saat kita menulis dalam desimal, setiap pecahan (khususnya, setiap desimal yang berakhir) adalah bilangan rasional dari bentuknya
a / (2 n x 5 m )
Dalam biner, kita hanya mendapatkan suku 2 n , yaitu:
a / 2 n
Jadi dalam desimal, kita tidak dapat mewakili 1 / 3 . Karena basis 10 menyertakan 2 sebagai faktor prima, setiap bilangan yang dapat kita tulis sebagai pecahan biner juga dapat ditulis sebagai pecahan basis 10. Namun, hampir semua yang kita tulis sebagai pecahan basis 10 dapat direpresentasikan dalam biner. Dalam rentang 0,01, 0,02, 0,03 ... 0,99, hanya tiga angka yang dapat direpresentasikan dalam format FP kami: 0,25, 0,50, dan 0,75, karena semuanya adalah 1/4, 1/2, dan 3/4, semua angka dengan faktor prima yang hanya menggunakan suku 2 n .
Dalam basis 10 kita tidak dapat mewakili 1 / 3 . Namun dalam biner, kita tidak bisa melakukan 1 / 10 atau 1 / 3 .
Jadi meskipun setiap pecahan biner dapat ditulis dalam desimal, kebalikannya tidak benar. Dan faktanya, sebagian besar pecahan desimal berulang dalam biner.
Berurusan dengan itu
Pengembang biasanya diinstruksikan untuk melakukan <epsilon perbandingan, saran yang lebih baik mungkin untuk membulatkan ke nilai integral (di pustaka C: round () dan roundf (), yaitu, tetap dalam format FP) dan kemudian membandingkan. Membulatkan ke panjang pecahan desimal tertentu memecahkan sebagian besar masalah dengan keluaran.
Juga, pada masalah penghitungan angka nyata (masalah yang FP ditemukan pada komputer awal yang sangat mahal) konstanta fisik alam semesta dan semua pengukuran lainnya hanya diketahui oleh sejumlah kecil angka signifikan, jadi seluruh ruang masalah adalah "tidak tepat". FP "akurasi" bukanlah masalah dalam aplikasi semacam ini.
Seluruh masalah benar-benar muncul ketika orang mencoba menggunakan FP untuk menghitung kacang. Itu berhasil untuk itu, tetapi hanya jika Anda tetap berpegang pada nilai integral, yang jenisnya mengalahkan tujuan penggunaannya. Inilah mengapa kami memiliki semua pustaka perangkat lunak pecahan desimal.
Saya suka jawaban Pizza oleh Chris , karena ini menggambarkan masalah sebenarnya, bukan hanya tulisan tangan biasa tentang "ketidakakuratan". Jika FP hanya "tidak akurat", kita bisa memperbaikinya dan akan melakukannya beberapa dekade yang lalu. Alasan kami belum melakukannya adalah karena format FP kompak dan cepat dan ini cara terbaik untuk menghitung banyak angka. Juga, ini adalah warisan dari era luar angkasa dan perlombaan senjata dan upaya awal untuk memecahkan masalah besar dengan komputer yang sangat lambat menggunakan sistem memori kecil. (Terkadang, inti magnetik individu untuk penyimpanan 1-bit, tapi itu cerita lain. )
Kesimpulan
Jika Anda hanya menghitung kacang di bank, solusi perangkat lunak yang menggunakan representasi string desimal pada awalnya berfungsi dengan baik. Tetapi Anda tidak dapat melakukan kromodinamika kuantum atau aerodinamika seperti itu.
Singkatnya itu karena:
Bilangan floating point tidak dapat mewakili semua desimal secara tepat dalam biner
Jadi seperti 3/10 yang tidak ada di basis 10 tepatnya (itu akan menjadi 3,33 ... berulang), dengan cara yang sama 1/10 tidak ada dalam biner.
Terus? Bagaimana cara menghadapinya? Apakah ada solusi lain?
Untuk menawarkan solusi terbaik, saya dapat mengatakan saya menemukan metode berikut:
parseFloat((0.1 + 0.2).toFixed(10)) => Will return 0.3
Izinkan saya menjelaskan mengapa ini adalah solusi terbaik. Seperti yang disebutkan orang lain dalam jawaban di atas, sebaiknya gunakan fungsi Javascript toFixed () siap pakai untuk memecahkan masalah. Tetapi kemungkinan besar Anda akan mengalami beberapa masalah.
Bayangkan Anda akan menambahkan dua angka float seperti 0.2dan 0.7di sini adalah: 0.2 + 0.7 = 0.8999999999999999.
Hasil yang Anda harapkan adalah 0.9itu berarti Anda membutuhkan hasil dengan presisi 1 digit dalam kasus ini. Jadi Anda seharusnya sudah menggunakan (0.2 + 0.7).tofixed(1)tetapi Anda tidak bisa begitu saja memberikan parameter tertentu ke toFixed () karena itu tergantung pada nomor yang diberikan, misalnya
0.22 + 0.7 = 0.9199999999999999
Dalam contoh ini, Anda memerlukan presisi 2 digit toFixed(2), jadi apa yang harus menjadi parameter agar sesuai dengan setiap angka float yang diberikan?
Anda bisa mengatakan biarlah menjadi 10 dalam setiap situasi lalu:
(0.2 + 0.7).toFixed(10) => Result will be "0.9000000000"
Sial! Apa yang akan Anda lakukan dengan angka nol yang tidak diinginkan setelah 9? Saatnya mengubahnya menjadi float agar sesuai keinginan Anda:
parseFloat((0.2 + 0.7).toFixed(10)) => Result will be 0.9
Sekarang setelah Anda menemukan solusinya, lebih baik menawarkannya sebagai fungsi seperti ini:
function floatify(number){
return parseFloat((number).toFixed(10));
}
Ayo coba sendiri:
function floatify(number){
return parseFloat((number).toFixed(10));
}
function addUp(){
var number1 = +$("#number1").val(); var number2 = +$("#number2").val();
var unexpectedResult = number1 + number2;
var expectedResult = floatify(number1 + number2);
$("#unexpectedResult").text(unexpectedResult); $("#expectedResult").text(expectedResult);
}
addUp();input{
width: 50px;
}
#expectedResult{
color: green;
}
#unexpectedResult{
color: red;
}<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<input id="number1" value="0.2" onclick="addUp()" onkeyup="addUp()"/> +
<input id="number2" value="0.7" onclick="addUp()" onkeyup="addUp()"/> =
<p>Expected Result: <span id="expectedResult"></span></p>
<p>Unexpected Result: <span id="unexpectedResult"></span></p>Anda dapat menggunakannya dengan cara ini:
var x = 0.2 + 0.7;
floatify(x); => Result: 0.9
Seperti yang disarankan W3SCHOOLS, ada solusi lain juga, Anda dapat mengalikan dan membagi untuk menyelesaikan masalah di atas:
var x = (0.2 * 10 + 0.1 * 10) / 10; // x will be 0.3
Ingatlah bahwa (0.2 + 0.1) * 10 / 10itu tidak akan berhasil sama sekali meskipun kelihatannya sama! Saya lebih suka solusi pertama karena saya dapat menerapkannya sebagai fungsi yang mengubah float input menjadi float keluaran yang akurat.
Apakah Anda sudah mencoba larutan lakban?
Cobalah untuk menentukan kapan kesalahan terjadi dan perbaiki dengan pernyataan singkat if, itu tidak bagus tetapi untuk beberapa masalah ini adalah satu-satunya solusi dan ini adalah salah satunya.
if( (n * 0.1) < 100.0 ) { return n * 0.1 - 0.000000000000001 ;}
else { return n * 0.1 + 0.000000000000001 ;}
Saya memiliki masalah yang sama dalam proyek simulasi ilmiah di c #, dan saya dapat memberitahu Anda bahwa jika Anda mengabaikan efek kupu-kupu, itu akan berubah menjadi naga gemuk besar dan menggigit Anda di a **
Angka-angka aneh itu muncul karena komputer menggunakan sistem bilangan biner (basis 2) untuk keperluan kalkulasi, sedangkan kami menggunakan desimal (basis 10).
Ada sebagian besar bilangan pecahan yang tidak dapat direpresentasikan dengan tepat baik dalam biner atau desimal atau keduanya. Hasil - Hasil angka yang dibulatkan (tapi tepat).
Mengingat tidak ada yang menyebutkan ini ...
Beberapa bahasa tingkat tinggi seperti Python dan Java dilengkapi dengan alat untuk mengatasi batasan titik mengambang biner. Sebagai contoh:
decimalModul Python dan BigDecimalkelas Java , yang merepresentasikan angka secara internal dengan notasi desimal (berlawanan dengan notasi biner). Keduanya memiliki ketepatan yang terbatas, sehingga masih rentan terhadap kesalahan, namun keduanya memecahkan masalah paling umum dengan aritmatika titik mengambang biner.
Desimal sangat bagus jika berurusan dengan uang: sepuluh sen ditambah dua puluh sen selalu tepat tiga puluh sen:
>>> 0.1 + 0.2 == 0.3 False >>> Decimal('0.1') + Decimal('0.2') == Decimal('0.3') TruedecimalModul Python didasarkan pada standar IEEE 854-1987 .fractionsModul Python dan BigFractionkelas Apache Common . Keduanya mewakili bilangan rasional sebagai
(numerator, denominator)pasangan dan dapat memberikan hasil yang lebih akurat daripada aritmatika floating point desimal.
Tidak satu pun dari solusi ini yang sempurna (terutama jika kita melihat performa, atau jika kita memerlukan presisi yang sangat tinggi), tetapi solusi tersebut tetap dapat memecahkan sejumlah besar masalah dengan aritmatika floating point biner.
Banyak dari banyak duplikat pertanyaan ini menanyakan tentang efek pembulatan floating point pada nomor tertentu. Dalam praktiknya, lebih mudah untuk mengetahui cara kerjanya dengan melihat hasil kalkulasi yang tepat daripada hanya dengan membaca tentangnya. Beberapa bahasa menyediakan cara untuk melakukannya - seperti mengonversi a floatatau doubleke BigDecimaldi Java.
Karena ini adalah pertanyaan bahasa-agnostik, itu membutuhkan alat bahasa-agnostik, seperti Decimal to Floating-Point Converter .
Menerapkannya ke nomor dalam pertanyaan, diperlakukan sebagai ganda:
0.1 mengonversi menjadi 0.1000000000000000055511151231257827021181583404541015625,
0.2 mengonversi menjadi 0.200000000000000011102230246251565404236316680908203125,
0,3 mengonversi menjadi 0,299999999999999988897769753748434595763683319091796875, dan
0,30000000000000004 dikonversi menjadi 0,3000000000000000444089209850062616169452667236328125.
Menambahkan dua angka pertama secara manual atau dalam kalkulator desimal seperti Kalkulator Presisi Penuh , menunjukkan jumlah pasti dari input aktual adalah 0,3000000000000000166533453693773481063544750213623046875.
Jika dibulatkan ke bawah hingga setara dengan 0,3 kesalahan pembulatan akan menjadi 0,000000000000000000277555756156289135105907917022705078125. Pembulatan ke atas setara dengan 0,30000000000000004 juga memberikan kesalahan pembulatan 0,000000000000000000277555756156289135105907917022705078125. Pemutus dasi bulat-ke-genap berlaku.
Kembali ke konverter floating point, heksadesimal mentah untuk 0,0000000000000004 adalah 3fd3333333333334, yang diakhiri dengan digit genap dan oleh karena itu merupakan hasil yang benar.
Bisakah saya menambahkan; orang selalu menganggap ini sebagai masalah komputer, tetapi jika Anda menghitung dengan tangan Anda (basis 10), Anda tidak bisa mendapatkan (1/3+1/3=2/3)=truekecuali Anda memiliki tak terhingga untuk menambahkan 0,333 ... menjadi 0,333 ... begitu juga dengan (1/10+2/10)!==3/10masalah di basis 2, Anda memotongnya menjadi 0,333 + 0,333 = 0,666 dan mungkin membulatkannya menjadi 0,667 yang juga secara teknis tidak akurat.
Menghitung dalam terner, dan pertiga bukanlah masalah - mungkin beberapa perlombaan dengan 15 jari di masing-masing tangan akan menanyakan mengapa matematika desimal Anda rusak ...
Jenis matematika floating-point yang dapat diterapkan di komputer digital harus menggunakan pendekatan bilangan real dan operasi pada mereka. (Versi standar mencapai lebih dari lima puluh halaman dokumentasi dan memiliki komite untuk menangani errata dan penyempurnaan lebih lanjut.)
Perkiraan ini adalah campuran dari berbagai jenis perkiraan, yang masing-masing dapat diabaikan atau diperhitungkan dengan cermat karena cara khusus penyimpangannya dari ketepatan. Ini juga melibatkan sejumlah kasus luar biasa eksplisit di tingkat perangkat keras dan perangkat lunak yang kebanyakan orang berjalan melewati sambil berpura-pura tidak menyadarinya.
Jika Anda membutuhkan ketelitian tak terbatas (menggunakan angka π, misalnya, alih-alih salah satu dari banyak stand-in pendeknya), Anda harus menulis atau menggunakan program matematika simbolis.
Tetapi jika Anda setuju dengan gagasan bahwa terkadang matematika floating-point memiliki nilai yang kabur dan logika serta kesalahan dapat terakumulasi dengan cepat, dan Anda dapat menulis persyaratan dan tes untuk memungkinkannya, maka kode Anda sering kali dapat bertahan dengan apa yang ada di dalamnya. FPU Anda.
Sekadar iseng, saya bermain-main dengan representasi float, mengikuti definisi dari Standard C99 dan saya menulis kode di bawah ini.
Kode mencetak representasi biner float dalam 3 grup terpisah
SIGN EXPONENT FRACTION
dan setelah itu mencetak jumlah, yang jika dijumlahkan dengan cukup presisi, ia akan menunjukkan nilai yang benar-benar ada di perangkat keras.
Jadi ketika Anda menulis float x = 999..., kompilator akan mengubah angka itu dalam representasi bit yang dicetak oleh fungsi xxsehingga jumlah yang dicetak oleh fungsi yytersebut sama dengan angka yang diberikan.
Pada kenyataannya, jumlah ini hanyalah perkiraan. Untuk nomor 999.999.999 compiler akan memasukkan representasi bit dari float nomor 1.000.000.000
Setelah kode saya lampirkan sesi konsol, di mana saya menghitung jumlah istilah untuk kedua konstanta (minus PI dan 999999999) yang benar-benar ada di perangkat keras, dimasukkan ke sana oleh kompiler.
#include <stdio.h>
#include <limits.h>
void
xx(float *x)
{
unsigned char i = sizeof(*x)*CHAR_BIT-1;
do {
switch (i) {
case 31:
printf("sign:");
break;
case 30:
printf("exponent:");
break;
case 23:
printf("fraction:");
break;
}
char b=(*(unsigned long long*)x&((unsigned long long)1<<i))!=0;
printf("%d ", b);
} while (i--);
printf("\n");
}
void
yy(float a)
{
int sign=!(*(unsigned long long*)&a&((unsigned long long)1<<31));
int fraction = ((1<<23)-1)&(*(int*)&a);
int exponent = (255&((*(int*)&a)>>23))-127;
printf(sign?"positive" " ( 1+":"negative" " ( 1+");
unsigned int i = 1<<22;
unsigned int j = 1;
do {
char b=(fraction&i)!=0;
b&&(printf("1/(%d) %c", 1<<j, (fraction&(i-1))?'+':')' ), 0);
} while (j++, i>>=1);
printf("*2^%d", exponent);
printf("\n");
}
void
main()
{
float x=-3.14;
float y=999999999;
printf("%lu\n", sizeof(x));
xx(&x);
xx(&y);
yy(x);
yy(y);
}
Berikut adalah sesi konsol di mana saya menghitung nilai sebenarnya dari float yang ada di perangkat keras. Saya biasa bcmencetak jumlah istilah yang dikeluarkan oleh program utama. Seseorang dapat memasukkan jumlah itu dengan python replatau yang serupa juga.
-- .../terra1/stub
@ qemacs f.c
-- .../terra1/stub
@ gcc f.c
-- .../terra1/stub
@ ./a.out
sign:1 exponent:1 0 0 0 0 0 0 fraction:0 1 0 0 1 0 0 0 1 1 1 1 0 1 0 1 1 1 0 0 0 0 1 1
sign:0 exponent:1 0 0 1 1 1 0 fraction:0 1 1 0 1 1 1 0 0 1 1 0 1 0 1 1 0 0 1 0 1 0 0 0
negative ( 1+1/(2) +1/(16) +1/(256) +1/(512) +1/(1024) +1/(2048) +1/(8192) +1/(32768) +1/(65536) +1/(131072) +1/(4194304) +1/(8388608) )*2^1
positive ( 1+1/(2) +1/(4) +1/(16) +1/(32) +1/(64) +1/(512) +1/(1024) +1/(4096) +1/(16384) +1/(32768) +1/(262144) +1/(1048576) )*2^29
-- .../terra1/stub
@ bc
scale=15
( 1+1/(2) +1/(4) +1/(16) +1/(32) +1/(64) +1/(512) +1/(1024) +1/(4096) +1/(16384) +1/(32768) +1/(262144) +1/(1048576) )*2^29
999999999.999999446351872
Itu dia. Nilai 999999999 sebenarnya
999999999.999999446351872
Anda juga dapat memeriksa bcbahwa -3.14 juga terganggu. Jangan lupa untuk menentukan scalefaktor bc.
Jumlah yang ditampilkan adalah apa yang ada di dalam perangkat keras. Nilai yang Anda peroleh dengan menghitungnya bergantung pada skala yang Anda tetapkan. Saya memang menyetel scalefaktor ke 15. Secara matematis, dengan ketepatan tak terbatas, tampaknya 1.000.000.000.
Cara lain untuk melihat ini: 64 bit yang digunakan untuk mewakili angka. Akibatnya tidak ada cara lebih dari 2 ** 64 = 18.446.744.073.709.551.616 angka yang berbeda dapat diwakili secara tepat.
Namun, Math mengatakan sudah ada banyak desimal tak terhingga antara 0 dan 1. IEE 754 mendefinisikan pengkodean untuk menggunakan 64 bit ini secara efisien untuk ruang bilangan yang jauh lebih besar ditambah NaN dan +/- Infinity, jadi ada celah antara bilangan yang diwakili secara akurat yang diisi dengan angka hanya diperkirakan.
Sayangnya 0,3 berada di celah.
Sejak Python 3.5 Anda dapat menggunakan math.isclose()fungsi untuk menguji persamaan perkiraan:
>>> import math
>>> math.isclose(0.1 + 0.2, 0.3)
True
>>> 0.1 + 0.2 == 0.3
False
Bayangkan bekerja di basis sepuluh dengan, katakanlah, 8 digit akurasi. Anda memeriksa apakah
1/3 + 2 / 3 == 1
dan belajar bahwa ini kembali false. Mengapa? Nah, sebagai bilangan real yang kita miliki
1/3 = 0,333 .... dan 2/3 = 0,666 ....
Memotong di delapan tempat desimal, kita dapatkan
0.33333333 + 0.66666666 = 0.99999999
yang, tentu saja, berbeda 1.00000000dengan tepatnya 0.00000001.
Situasi untuk bilangan biner dengan jumlah bit tetap sama persis. Sebagai bilangan real, kami punya
1/10 = 0,0001100110011001100 ... (basis 2)
dan
1/5 = 0,0011001100110011001 ... (basis 2)
Jika kita memotongnya menjadi, katakanlah, tujuh bit, maka kita akan mendapatkannya
0.0001100 + 0.0011001 = 0.0100101
sementara di sisi lain,
3/10 = 0,01001100110011 ... (basis 2)
yang, dipotong menjadi tujuh bit, adalah 0.0100110, dan ini berbeda persis 0.0000001.
Situasi sebenarnya sedikit lebih halus karena angka-angka ini biasanya disimpan dalam notasi ilmiah. Jadi, misalnya, alih-alih menyimpan 1/10 karena 0.0001100kita dapat menyimpannya sebagai sesuatu seperti 1.10011 * 2^-4, tergantung pada berapa banyak bit yang kita alokasikan untuk eksponen dan mantissa. Ini memengaruhi berapa digit presisi yang Anda peroleh untuk kalkulasi Anda.
Hasilnya adalah karena kesalahan pembulatan ini, Anda pada dasarnya tidak ingin menggunakan == pada bilangan floating-point. Sebaliknya, Anda dapat memeriksa apakah nilai absolut selisihnya lebih kecil daripada bilangan kecil tetap.
Angka desimal seperti 0.1, 0.2, dan 0.3tidak diwakili tepat dalam biner dikodekan tipe floating point. Jumlah aproksimasi untuk 0.1dan 0.2berbeda dari aproksimasi yang digunakan untuk 0.3, maka kesalahan 0.1 + 0.2 == 0.3as dapat dilihat lebih jelas di sini:
#include <stdio.h>
int main() {
printf("0.1 + 0.2 == 0.3 is %s\n", 0.1 + 0.2 == 0.3 ? "true" : "false");
printf("0.1 is %.23f\n", 0.1);
printf("0.2 is %.23f\n", 0.2);
printf("0.1 + 0.2 is %.23f\n", 0.1 + 0.2);
printf("0.3 is %.23f\n", 0.3);
printf("0.3 - (0.1 + 0.2) is %g\n", 0.3 - (0.1 + 0.2));
return 0;
}
Keluaran:
0.1 + 0.2 == 0.3 is false
0.1 is 0.10000000000000000555112
0.2 is 0.20000000000000001110223
0.1 + 0.2 is 0.30000000000000004440892
0.3 is 0.29999999999999998889777
0.3 - (0.1 + 0.2) is -5.55112e-17
Agar penghitungan ini dapat dievaluasi dengan lebih andal, Anda perlu menggunakan representasi berbasis desimal untuk nilai titik mengambang. Standar C tidak menentukan jenis seperti itu secara default tetapi sebagai ekstensi yang dijelaskan dalam Laporan teknis .
Jenis _Decimal32, _Decimal64dan _Decimal128mungkin tersedia di sistem Anda (misalnya, GCC mendukungnya pada target yang dipilih , tetapi Clang tidak mendukungnya di OS X ).
Karena utas ini bercabang sedikit menjadi diskusi umum tentang implementasi floating point saat ini, saya akan menambahkan bahwa ada proyek untuk memperbaiki masalah mereka.
Melihat https://posithub.org/misalnya, yang menampilkan tipe angka yang disebut posit (dan pendahulunya unum) yang menjanjikan akurasi yang lebih baik dengan bit yang lebih sedikit. Jika pemahaman saya benar, itu juga memperbaiki jenis masalah dalam pertanyaan. Proyek yang cukup menarik, orang di baliknya adalah ahli matematika Dr. John Gustafson . Semuanya adalah open source, dengan banyak implementasi aktual di C / C ++, Python, Julia dan C # (https://hastlayer.com/arithmetics).
Sebenarnya sangat sederhana. Jika Anda memiliki sistem basis 10 (seperti milik kita), sistem ini hanya dapat mengekspresikan pecahan yang menggunakan faktor prima dari basis tersebut. Faktor prima dari 10 adalah 2 dan 5. Jadi 1/2, 1/4, 1/5, 1/8, dan 1/10 semuanya dapat dinyatakan dengan jelas karena penyebutnya semuanya menggunakan faktor prima dari 10. Sebaliknya, 1 / 3, 1/6, dan 1/7 adalah desimal berulang karena penyebutnya menggunakan faktor prima dari 3 atau 7. Dalam biner (atau basis 2), satu-satunya faktor prima adalah 2. Jadi Anda hanya dapat mengekspresikan pecahan dengan bersih yang mana hanya mengandung 2 sebagai faktor prima. Dalam biner, 1/2, 1/4, 1/8 semuanya akan diekspresikan dengan rapi sebagai desimal. Sementara, 1/5 atau 1/10 akan menjadi desimal berulang. Jadi 0,1 dan 0,2 (1/10 dan 1/5) sementara desimal bersih dalam sistem basis 10, adalah desimal berulang dalam sistem basis 2 tempat komputer beroperasi. Saat Anda menghitung desimal berulang ini, Anda akan mendapatkan sisa yang terbawa ketika Anda mengubah angka basis 2 (biner) komputer menjadi angka basis 10 yang lebih dapat dibaca manusia.
Dari https://0.30000000000000004.com/
Aritmatika normal adalah basis 10, jadi desimal mewakili persepuluhan, perseratus, dll. Saat Anda mencoba merepresentasikan bilangan floating-point dalam aritmatika basis 2 biner, Anda berurusan dengan dua, empat, delapan, dll.
Di perangkat keras, titik mengambang disimpan sebagai mantisa dan eksponen bilangan bulat. Mantissa mewakili angka penting. Eksponen mirip dengan notasi ilmiah tetapi menggunakan basis 2, bukan 10. Misalnya 64,0 akan direpresentasikan dengan mantisa 1 dan eksponen 6. 0,125 akan diwakili dengan mantra 1 dan eksponen -3.
Desimal titik mengambang harus menjumlahkan pangkat negatif dari 2
0.1b = 0.5d
0.01b = 0.25d
0.001b = 0.125d
0.0001b = 0.0625d
0.00001b = 0.03125d
dan seterusnya.
Biasanya menggunakan delta kesalahan daripada menggunakan operator persamaan saat berurusan dengan aritmatika titik mengambang. Dari pada
if(a==b) ...
Anda akan menggunakan
delta = 0.0001; // or some arbitrarily small amount
if(a - b > -delta && a - b < delta) ...
Bilangan floating point diwakili, di tingkat perangkat keras, sebagai pecahan dari bilangan biner (basis 2). Misalnya, pecahan desimal:
0.125
memiliki nilai 1/10 + 2/100 + 5/1000 dan, dengan cara yang sama, pecahan biner:
0.001
memiliki nilai 0/2 + 0/4 + 1/8. Kedua pecahan ini memiliki nilai yang sama, satu-satunya perbedaan adalah yang pertama adalah pecahan desimal, yang kedua adalah pecahan biner.
Sayangnya, sebagian besar pecahan desimal tidak dapat memiliki representasi yang tepat dalam pecahan biner. Oleh karena itu, secara umum, angka floating point yang Anda berikan hanya mendekati pecahan biner untuk disimpan di mesin.
Masalahnya lebih mudah didekati di basis 10. Ambil contoh, pecahan 1/3. Anda dapat memperkirakannya menjadi pecahan desimal:
0.3
atau lebih baik,
0.33
atau lebih baik,
0.333
dll. Tidak peduli berapa banyak tempat desimal yang Anda tulis, hasilnya tidak pernah persis 1/3, tetapi ini adalah perkiraan yang selalu mendekati.
Demikian juga, tidak peduli berapa banyak tempat desimal basis 2 yang Anda gunakan, nilai desimal 0,1 tidak dapat direpresentasikan persis sebagai pecahan biner. Dalam basis 2, 1/10 adalah bilangan periodik berikut:
0.0001100110011001100110011001100110011001100110011 ...
Berhenti pada jumlah bit yang terbatas, dan Anda akan mendapatkan perkiraan.
Untuk Python, pada mesin biasa, 53 bit digunakan untuk ketepatan pelampung, jadi nilai yang disimpan saat Anda memasukkan desimal 0,1 adalah pecahan biner.
0.00011001100110011001100110011001100110011001100110011010
yang mendekati, tetapi tidak persis sama, dengan 1/10.
Sangat mudah untuk melupakan bahwa nilai yang disimpan adalah perkiraan dari pecahan desimal asli, karena cara pelampung ditampilkan di penerjemah. Python hanya menampilkan perkiraan desimal dari nilai yang disimpan dalam biner. Jika Python mengeluarkan nilai desimal sebenarnya dari perkiraan biner yang disimpan untuk 0,1, itu akan menghasilkan:
>>> 0.1
0.1000000000000000055511151231257827021181583404541015625
Ini adalah tempat desimal yang jauh lebih banyak daripada yang diperkirakan kebanyakan orang, jadi Python menampilkan nilai bulat untuk meningkatkan keterbacaan:
>>> 0.1
0.1
Penting untuk dipahami bahwa pada kenyataannya ini adalah ilusi: nilai yang disimpan tidak persis 1/10, hanya pada tampilan yang nilai yang disimpan dibulatkan. Ini menjadi bukti segera setelah Anda melakukan operasi aritmatika dengan nilai-nilai ini:
>>> 0.1 + 0.2
0.30000000000000004
Perilaku ini melekat pada sifat representasi floating-point mesin: ini bukan bug di Python, juga bukan bug di kode Anda. Anda dapat mengamati jenis perilaku yang sama di semua bahasa lain yang menggunakan dukungan perangkat keras untuk menghitung bilangan floating point (meskipun beberapa bahasa tidak membuat perbedaan terlihat secara default, atau tidak di semua mode tampilan).
Kejutan lain melekat dalam hal ini. Misalnya, jika Anda mencoba membulatkan nilai 2,675 ke dua tempat desimal, Anda akan mendapatkan
>>> round (2.675, 2)
2.67
Dokumentasi untuk round () primitif menunjukkan bahwa round () membulatkan ke nilai terdekat dari nol. Karena pecahan desimal berada tepat di tengah antara 2,67 dan 2,68, Anda akan mendapatkan (perkiraan biner) 2,68. Namun, ini tidak terjadi, karena ketika pecahan desimal 2,675 diubah menjadi pelampung, itu disimpan dengan perkiraan yang nilai pastinya adalah:
2.67499999999999982236431605997495353221893310546875
Karena perkiraannya sedikit lebih dekat ke 2,67 daripada 2,68, pembulatannya ke bawah.
Jika Anda berada dalam situasi di mana membulatkan angka desimal setengah ke bawah penting, Anda harus menggunakan modul desimal. Selain itu, modul desimal juga menyediakan cara mudah untuk "melihat" nilai pasti yang disimpan untuk pelampung apa pun.
>>> from decimal import Decimal
>>> Decimal (2.675)
>>> Decimal ('2.67499999999999982236431605997495353221893310546875')
Konsekuensi lain dari fakta bahwa 0,1 tidak disimpan secara tepat dalam 1/10 adalah bahwa jumlah dari sepuluh nilai 0,1 juga tidak menghasilkan 1,0:
>>> sum = 0.0
>>> for i in range (10):
... sum + = 0.1
...>>> sum
0.9999999999999999
Aritmatika bilangan floating point biner menyimpan banyak kejutan seperti itu. Masalah dengan "0,1" dijelaskan secara mendetail di bawah, di bagian "Kesalahan representasi". Lihat The Perils of Floating Point untuk daftar lebih lengkap dari kejutan semacam itu.
Memang benar tidak ada jawaban yang sederhana, namun jangan terlalu curiga dengan angka virtula mengambang! Kesalahan, dalam Python, dalam operasi bilangan floating-point disebabkan oleh perangkat keras yang mendasarinya, dan pada kebanyakan mesin tidak lebih dari 1 dalam 2 ** 53 per operasi. Ini lebih dari yang diperlukan untuk sebagian besar tugas, tetapi Anda harus ingat bahwa ini bukan operasi desimal, dan setiap operasi pada bilangan floating point mungkin mengalami kesalahan baru.
Meskipun ada kasus patologis, untuk sebagian besar kasus penggunaan umum, Anda akan mendapatkan hasil yang diharapkan di bagian akhir hanya dengan membulatkan ke jumlah tempat desimal yang Anda inginkan pada tampilan. Untuk kontrol yang baik atas bagaimana float ditampilkan, lihat Sintaks Pemformatan String untuk spesifikasi pemformatan metode str.format ().
Bagian jawaban ini menjelaskan secara detail contoh "0.1" dan menunjukkan bagaimana Anda dapat melakukan analisis yang tepat untuk jenis kasus ini sendiri. Kami berasumsi bahwa Anda sudah familiar dengan representasi biner dari bilangan floating point. Istilah Error Representation berarti bahwa sebagian besar pecahan desimal tidak dapat direpresentasikan dengan tepat dalam biner. Inilah alasan utama mengapa Python (atau Perl, C, C ++, Java, Fortran, dan banyak lainnya) biasanya tidak menampilkan hasil yang tepat dalam desimal:
>>> 0.1 + 0.2
0.30000000000000004
Kenapa? 1/10 dan 2/10 tidak dapat direpresentasikan secara tepat dalam pecahan biner. Namun, semua mesin hari ini (Juli 2010) mengikuti standar IEEE-754 untuk aritmatika bilangan floating point. dan sebagian besar platform menggunakan "presisi ganda IEEE-754" untuk mewakili float Python. Presisi ganda IEEE-754 menggunakan presisi 53 bit, jadi saat membaca komputer mencoba mengubah 0,1 ke pecahan terdekat dari bentuk J / 2 ** N dengan J bilangan bulat tepat 53 bit. Menulis kembali :
1/10 ~ = J / (2 ** N)
di :
J ~ = 2 ** N / 10
mengingat bahwa J tepat 53 bit (jadi> = 2 ** 52 tetapi <2 ** 53), nilai terbaik untuk N adalah 56:
>>> 2 ** 52
4503599627370496
>>> 2 ** 53
9007199254740992
>>> 2 ** 56/10
7205759403792793
Jadi 56 adalah satu-satunya nilai yang mungkin untuk N yang menyisakan tepat 53 bit untuk J. Oleh karena itu, nilai terbaik untuk J adalah hasil bagi ini, dibulatkan:
>>> q, r = divmod (2 ** 56, 10)
>>> r
6
Karena carry lebih besar dari setengah dari 10, perkiraan terbaik diperoleh dengan membulatkan:
>>> q + 1
7205759403792794
Oleh karena itu, perkiraan terbaik untuk 1/10 dalam "presisi ganda IEEE-754" adalah di atas 2 ** 56, yaitu:
7205759403792794/72057594037927936
Perhatikan bahwa karena pembulatan dilakukan ke atas, hasilnya sebenarnya sedikit lebih besar dari 1/10; jika kita tidak membulatkannya, hasil bagi akan menjadi sedikit kurang dari 1/10. Tetapi dalam kasus apa pun tidak tepat 1/10!
Jadi komputer tidak pernah "melihat" 1/10: yang dilihatnya adalah pecahan tepat yang diberikan di atas, perkiraan terbaik menggunakan angka titik mengambang presisi ganda dari "" IEEE-754 ":
>>>. 1 * 2 ** 56
7205759403792794.0
Jika kita mengalikan pecahan ini dengan 10 ** 30, kita dapat mengamati nilai dari 30 tempat desimal bobot kuatnya.
>>> 7205759403792794 * 10 ** 30 // 2 ** 56
100000000000000005551115123125L
artinya nilai pasti yang disimpan di komputer kira-kira sama dengan nilai desimal 0.100000000000000005551115123125. Dalam versi sebelum Python 2.7 dan Python 3.1, Python membulatkan nilai-nilai ini ke 17 tempat desimal penting, menampilkan “0,10000000000000001”. Dalam versi Python saat ini, nilai yang ditampilkan adalah nilai yang pecahannya sesingkat mungkin sambil memberikan representasi yang persis sama ketika diubah kembali ke biner, hanya menampilkan "0,1".
Saya baru saja melihat masalah menarik ini seputar floating point:
Perhatikan hasil berikut ini:
error = (2**53+1) - int(float(2**53+1))
>>> (2**53+1) - int(float(2**53+1))
1
Kita dapat dengan jelas melihat breakpoint ketika 2**53+1- semua berfungsi dengan baik sampai 2**53.
>>> (2**53) - int(float(2**53))
0
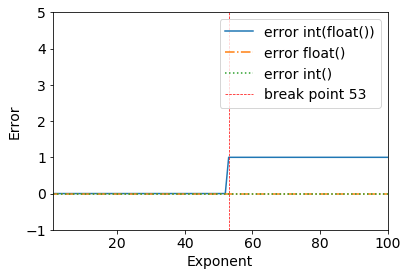
Ini terjadi karena biner presisi ganda: IEEE 754 format titik mengambang biner presisi ganda: binary64
Dari halaman Wikipedia untuk format titik-mengambang presisi ganda :
Titik mengambang biner presisi ganda adalah format yang umum digunakan pada PC, karena jangkauannya yang lebih luas di atas titik mengambang presisi tunggal, terlepas dari performa dan biaya bandwidth-nya. Seperti format titik mengambang presisi tunggal, format ini kurang presisi pada bilangan bulat jika dibandingkan dengan format bilangan bulat dengan ukuran yang sama. Ini umumnya dikenal hanya sebagai ganda. Standar IEEE 754 menetapkan binary64 sebagai yang memiliki:
- Bit tanda: 1 bit
- Eksponen: 11 bit
- Presisi yang signifikan: 53 bit (52 disimpan secara eksplisit)
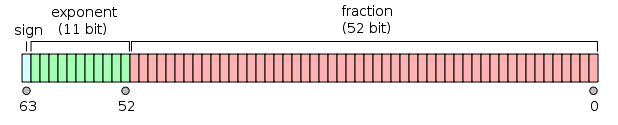
Nilai sebenarnya yang diasumsikan oleh datum presisi ganda 64-bit dengan eksponen bias tertentu dan pecahan 52-bit adalah
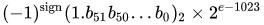
atau
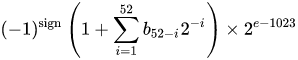
Terima kasih kepada @a_guest karena telah menunjukkannya kepada saya.