Warum mehr für maschinelles Lernen bezahlen?

Beschleunigen Sie Ihre unausgeglichenen Lernarbeitslasten mit der Intel-Erweiterung für Scikit-Learn
Ethan Glaser, Nikolay Petrov, Henry Gabb und Jui Mhatre, Intel Corporation
Ein kürzlich veröffentlichter NVIDIA-Blog fiel uns mit seinen irreführenden Ergebnissen auf . Welchen Sinn hat es, eine A100-GPU mit einer neun Jahre alten CPU zu vergleichen (der Intel Python-Code (Standard- Scikit-Learn mit der Imbalanced-Learn- Bibliothek), es sei denn, Sie versuchen absichtlich, die GPU- vs. CPU-Beschleunigung zu erhöhen? Die Imbalanced-Learn-Bibliothek unterstützt Scikit-Learn-kompatible Schätzer, daher verwendeten sie zur Beschleunigung cuML-Schätzer. Wir können die optimierten Schätzer in der Intel Extension für Scikit-learn verwenden , indem wir einfach einen Aufruf von patch_sklearn() hinzufügen:
from sklearnex import patch_sklearn
patch_sklearn()
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.neighbors import NearestNeighbors
...
nn = NearestNeighbors(n_neighbors=4, n_jobs=-1)
X_resampled, y_resampled = EditedNearestNeighbours(n_neighbors=nn).fit_resample(X, y)

Leistungsvergleich
Die Intel-Erweiterung für Scikit-learn sorgt für allgemeine Geschwindigkeitssteigerungen bei denselben Benchmarks wie Nvidia (Abbildung 1). Die Beschleunigungen reichen von ~2x bis ~140x, abhängig vom Algorithmus und den Parametern. Beachten Sie, dass die Standard-Scikit-Learn-Bibliothek für SMOTE- und ADASYN-Benchmarks „100 Funktionen, 5 Klassen“ nicht mehr über genügend Speicher verfügt. Wenn es auf die Leistung ankommt, zeigen diese Ergebnisse, dass die Intel-Erweiterung für Scikit-Learn eine deutliche Beschleunigung gegenüber Standard-Scikit-Learn bietet.

Wie ist das im Vergleich zu den A100-Ergebnissen von Nvidia? Werfen wir einen Blick auf die beiden Algorithmen, bei denen Nvidia im Vergleich zu scikit-learn die höchsten Beschleunigungen erzielte: SVMSMOTE und CondensedNearestNeighbours (Abbildung 2). Diese Ergebnisse zeigen, dass unsere Leistung in einer ähnlichen Größenordnung wie cuML liegt, wenn zum Vergleich ein neuerer Prozessor und optimiertes Scikit-Learn verwendet werden. Die Intel Extension für Scikit-learn übertrifft in einigen Tests sogar cuML. Lassen Sie uns nun über den Preis sprechen.


Kostenvergleich
Es ist erwähnenswert, dass die stündlichen Kosten einer a2-highgpu-1g A100-Instanz auf GCP 60 % höher sind als die der n2-highcpu-64-Instanz (Tabelle 1). Das bedeutet, dass die A100-Instanz mindestens eine 1,6-fache Beschleunigung gegenüber der Xeon Gold 6268CL-Instanz (n2-highcpu-64) bieten muss, um kostenwettbewerbsfähig zu sein. (Ein A100 verbraucht außerdem 1,7-mal bzw. 1,2-mal mehr Strom als Xeon E5–2696 v4 bzw.
Vergleichen wir die Preis-Leistungs-Verhältnisse der von Nvidia ausgewählten Benchmarks , um zu sehen, ob die A100-Instanz ihren Premiumpreis rechtfertigt. Die Gesamtkosten (USD) eines Benchmark-Laufs sind einfach die Instanzkosten pro Stunde (USD/Std.) multipliziert mit der Laufzeit (Std.). Ein detaillierter Kostenvergleich zeigt, dass die Ausführung dieser Benchmarks auf der Xeon-Instanz häufig die kostengünstigere Option ist (Abbildung 3). In den folgenden Diagrammen bedeutet ein Wert größer als eins, dass der angegebene Benchmark auf der A100-Instanz teurer ist. Ein Wert von 1,29 bedeutet beispielsweise, dass die A100-Instanz 29 % teurer ist als die Xeon-Instanz.



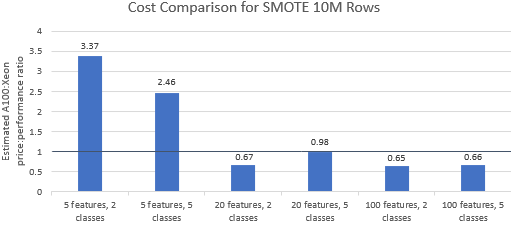
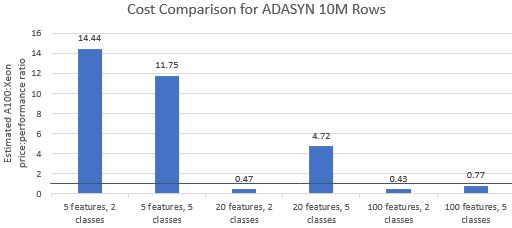
Die Benchmark-Kosten variieren je nach Algorithmus und verwendeten Parametern, aber die Ergebnisse begünstigen im Allgemeinen die Xeon-Instanz: Der geometrische Mittelwert der Kosten ist für vier der fünf Algorithmen größer als eins und der geometrische Gesamtmittelwert beträgt 1,36 (Tabelle 2).

Darüber hinaus bieten CPUs mehr Flexibilität bei der Instanzauswahl, was die Effizienz weiter verbessert. Es ist kostengünstiger, die kleinste leistungsfähige Xeon-Instanz auszuwählen, die eine bestimmte Problemgröße bewältigen und gleichzeitig Leistungsanforderungen und Budgetbeschränkungen erfüllen kann. Abbildung 4 zeigt ein solches Beispiel für die beiden kleinsten Benchmarks. Diese Ergebnisse zeigen, dass es deutlich günstiger sein kann, die Hardware zu verwenden, die den Anforderungen der Modellkonfiguration am besten entspricht. Beispielsweise kostet die Ausführung der beiden ADASYN-Benchmarks mit Intel Extension für Scikit-learn auf einer e2-highcpu-8-Instanz nur 1,5 % und 2,1 % der Kosten für die Ausführung von cuML auf der A100-Instanz.

Abschluss
Die obigen Ergebnisse zeigen, dass die Intel-Erweiterung für Scikit-Learn in der Lage ist, die Leistungsergebnisse im Vergleich zum Standard-Scikit-Learn erheblich zu verbessern und in einigen Tests auch A100 zu übertreffen. Wenn man die Kosten berücksichtigt, sind die Ergebnisse der Intel Extension für Scikit-learn sogar noch günstiger, da Xeon-Instanzen viel günstiger sind als die A100-Instanz. Benutzer können eine Xeon-Instanz auswählen, die ihren Leistungs-, Leistungs- und Preisanforderungen entspricht.

![Was ist überhaupt eine verknüpfte Liste? [Teil 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































