Exploiter la puissance multicœur avec Asyncio en Python

Ceci est l'un de mes articles sous la colonne Python Concurrency , et si vous le trouvez utile, vous pouvez lire le reste à partir d' ici .
Introduction
Dans cet article, je vais vous montrer comment exécuter du code asynchrone Python sur un processeur multicœur pour débloquer toutes les performances des tâches simultanées.
Quel est notre problème ?
asyncio utilise un seul cœur.
Dans les articles précédents, j'ai couvert en détail les mécanismes d'utilisation de Python asyncio. Avec cette connaissance, vous pouvez apprendre qu'asyncio permet aux tâches liées aux E/S de s'exécuter à grande vitesse en commutant manuellement l'exécution des tâches pour contourner le processus de contention GIL lors de la commutation de tâches multithread.
Théoriquement, le temps d'exécution des tâches liées aux E/S dépend du temps écoulé entre le lancement et la réponse d'une opération d'E/S et ne dépend pas des performances de votre CPU. Ainsi, nous pouvons lancer simultanément des dizaines de milliers de tâches IO et les terminer rapidement.
Mais récemment, j'écrivais un programme qui devait explorer simultanément des dizaines de milliers de pages Web et j'ai constaté que même si mon programme asyncio était beaucoup plus efficace que les programmes qui utilisent l'exploration itérative des pages Web, cela m'a quand même fait attendre longtemps. Dois-je utiliser toutes les performances de mon ordinateur ? J'ai donc ouvert le gestionnaire de tâches et vérifié:
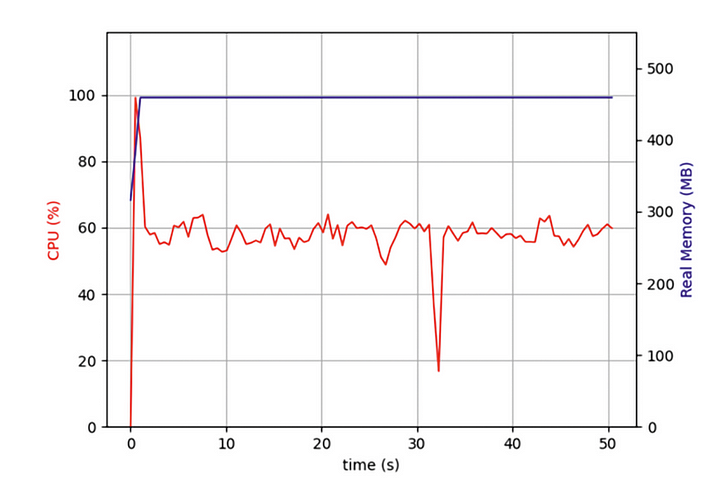
J'ai constaté que depuis le début, mon code fonctionnait sur un seul cœur de processeur et que plusieurs autres cœurs étaient inactifs. En plus de lancer des opérations d'E/S pour récupérer les données du réseau, une tâche doit décompresser et formater les données après leur retour. Bien que cette partie de l'opération ne consomme pas beaucoup de performances CPU, après plus de tâches, ces opérations liées au CPU auront un impact important sur les performances globales.
Je voulais que mes tâches simultanées asynchrones s'exécutent en parallèle sur plusieurs cœurs. Est-ce que cela réduirait les performances de mon ordinateur ?
Les principes sous-jacents de l'asyncio
Pour résoudre ce casse-tête, nous devons commencer par l'implémentation asyncio sous-jacente, la boucle d'événements.

Comme le montre la figure, l'amélioration des performances d'asyncio pour les programmes commence par des tâches gourmandes en E/S. Les tâches gourmandes en E/S incluent les requêtes HTTP, la lecture et l'écriture de fichiers, l'accès aux bases de données, etc. La caractéristique la plus importante de ces tâches est que le processeur ne bloque pas et passe beaucoup de temps à calculer en attendant que les données externes soient renvoyées, ce qui est très différent d'une autre classe de tâches synchrones qui nécessitent que le CPU soit occupé tout le temps pour calculer un résultat spécifique.
Lorsque nous générons un lot de tâches asynchrones, le code place d'abord ces tâches dans une file d'attente. À ce stade, il existe un thread appelé boucle d'événement qui récupère une tâche à la fois dans la file d'attente et l'exécute. Lorsque la tâche atteint l'instruction await et attend (généralement le retour d'une requête), la boucle d'événements saisit une autre tâche de la file d'attente et l'exécute. Jusqu'à ce que la tâche précédemment en attente obtienne des données via un rappel, la boucle d'événements revient à la tâche en attente précédente et termine l'exécution du reste du code.
Étant donné que le thread de la boucle d'événements s'exécute sur un seul cœur, la boucle d'événements se bloque lorsque le « reste du code » prend du temps CPU. Lorsque le nombre de tâches dans cette catégorie est important, chaque petit segment bloquant s'additionne et ralentit le programme dans son ensemble.
Quelle est ma solution ?
À partir de là, nous savons que les programmes asynchrones ralentissent car notre code Python exécute la boucle d'événements sur un seul cœur, et le traitement des données IO ralentit le programme. Existe-t-il un moyen de démarrer une boucle d'événements sur chaque cœur de processeur pour l'exécuter ?
Comme nous le savons tous, à partir de Python 3.7, il est recommandé d'exécuter tout le code asynchrone à l'aide de la méthode asyncio.run, qui est une abstraction de haut niveau qui appelle la boucle d'événement pour exécuter le code comme alternative au code suivant :
try:
loop = asyncio.get_event_loop()
loop.run_until_complete(task())
finally:
loop.close()
L'article précédent utilisait un exemple réel pour expliquer l'utilisation de loop.run_in_executorla méthode asyncio pour paralléliser l'exécution de code dans un pool de processus tout en obtenant les résultats de chaque processus enfant à partir du processus principal. Si vous n'avez pas lu l'article précédent, vous pouvez le consulter ici :
Ainsi, notre solution émerge : distribuer de nombreuses tâches simultanées à plusieurs sous-processus en utilisant une exécution multicœur via la loop.run_in_executorméthode, puis appeler asyncio.runchaque sous-processus pour démarrer la boucle d'événement respective et exécuter le code concurrent. Le schéma suivant montre l'intégralité du flux :
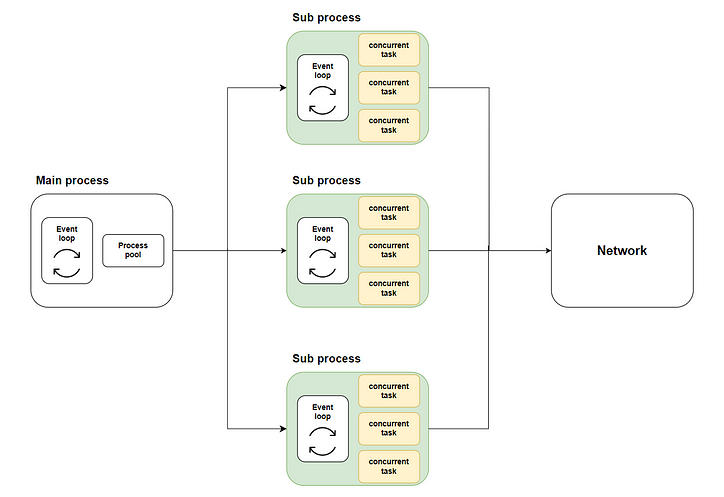
Où la partie verte représente les sous-processus que nous avons lancés. La partie jaune représente les tâches simultanées que nous avons démarrées.
Préparation avant de commencer
Simulation de la mise en œuvre de la tâche
Avant de pouvoir résoudre le problème, nous devons nous préparer avant de commencer. Dans cet exemple, nous ne pouvons pas écrire de code réel pour explorer le contenu Web car cela serait très ennuyeux pour le site Web cible. Nous allons donc simuler notre tâche réelle avec du code :
Comme le montre le code, nous utilisons d'abord asyncio.sleeppour simuler le retour de la tâche IO en temps aléatoire et une sommation itérative pour simuler le traitement CPU après le retour des données.
L'effet du code traditionnel
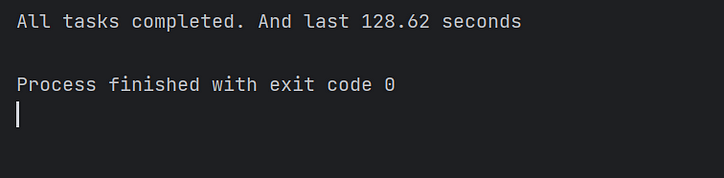
Ensuite, nous adoptons l'approche traditionnelle consistant à démarrer 10 000 tâches simultanées dans une méthode principale et observons le temps consommé par ce lot de tâches simultanées :
Comme le montre la figure, l'exécution des tâches asynchrones avec un seul cœur prend plus de temps.
L'implémentation du code
Ensuite, implémentons le code asyncio multicœur selon l'organigramme et voyons si les performances sont améliorées.
Conception de la structure globale du code
Tout d'abord, en tant qu'architecte, nous devons d'abord définir la structure globale du script, les méthodes requises et les tâches que chaque méthode doit accomplir :
La mise en œuvre spécifique de chaque méthode
Ensuite, implémentons chaque méthode étape par étape.
La query_concurrentlyméthode démarrera simultanément le lot de tâches spécifié et obtiendra les résultats via la asyncio.gatherméthode :
La run_batch_tasksméthode n'est pas une méthode asynchrone, car elle est démarrée directement dans le processus enfant :
Enfin, il y a notre mainméthode. Cette méthode appellera la loop.run_in_executorméthode pour que la run_batch_tasksméthode s'exécute dans le pool de processus et fusionne les résultats de l'exécution du processus enfant dans une liste :
Puisque nous écrivons un script multi-processus, nous devons utiliser if __name__ == “__main__”pour démarrer la méthode principale dans le processus principal :
Exécutez le code et voyez les résultats
Ensuite, nous démarrons le script et examinons la charge sur chaque cœur dans le gestionnaire de tâches :
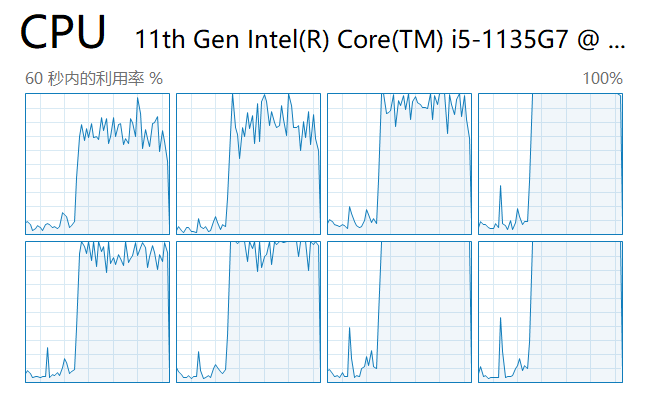
Comme vous pouvez le constater, tous les cœurs du processeur sont utilisés.
Enfin, nous observons le temps d'exécution du code et confirmons que le code asynchrone multi-thread accélère effectivement l'exécution du code de plusieurs fois ! Mission accomplie!

Conclusion
Dans cet article, j'ai expliqué pourquoi asyncio pouvait exécuter simultanément des tâches gourmandes en E/S, mais prenait toujours plus de temps que prévu lors de l'exécution de gros lots de tâches simultanées.
En effet, dans le schéma d'implémentation traditionnel du code asyncio, la boucle d'événements ne peut exécuter des tâches que sur un cœur et les autres cœurs sont dans un état inactif.
J'ai donc implémenté une solution pour que vous appeliez chaque boucle d'événement sur plusieurs cœurs séparément pour exécuter des tâches simultanées en parallèle. Et enfin, cela a considérablement amélioré les performances du code.
En raison de la limitation de mes capacités, la solution de cet article présente inévitablement des imperfections. J'attends vos commentaires et discussions. Je répondrai activement pour vous.
![Qu'est-ce qu'une liste liée, de toute façon? [Partie 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)














































