Pandas verschmelzen 101
- Wie führe ich ein (
INNER| (LEFT|RIGHT|FULL)OUTER)JOINmit Pandas durch? - Wie füge ich NaNs für fehlende Zeilen nach dem Zusammenführen hinzu?
- Wie entferne ich NaNs nach dem Zusammenführen?
- Kann ich den Index zusammenführen?
- Cross Join mit Pandas?
- Wie füge ich mehrere DataFrames zusammen?
merge?join?concat?update? Wer? Was? Warum?!
... und mehr. Ich habe diese wiederkehrenden Fragen zu verschiedenen Facetten der Pandas-Merge-Funktionalität gesehen. Die meisten Informationen zu Merge und seinen verschiedenen Anwendungsfällen sind heute auf Dutzende von schlecht formulierten, nicht durchsuchbaren Posts verteilt. Ziel ist es, einige der wichtigsten Punkte für die Nachwelt zusammenzustellen.
Diese QnA soll der nächste Teil einer Reihe hilfreicher Benutzerhandbücher zu gängigen Pandas-Redewendungen sein (siehe diesen Beitrag zum Schwenken und diesen Beitrag zur Verkettung , auf den ich später noch eingehen werde).
Bitte beachten Sie, dass dieser Beitrag nicht als Ersatz für die Dokumentation gedacht ist. Lesen Sie ihn daher auch! Einige der Beispiele stammen von dort.
Antworten
Dieser Beitrag soll den Lesern eine Einführung in das Zusammenführen von SQLas mit Pandas geben, wie man es benutzt und wann man es nicht benutzt.
Im Folgenden wird Folgendes beschrieben:
Die Grundlagen - Arten von Verknüpfungen (LINKS, RECHTS, AUSSEN, INNEN)
- Zusammenführen mit verschiedenen Spaltennamen
- Vermeiden doppelter Zusammenführungsschlüsselspalten in der Ausgabe
Zusammenführung mit dem Index unter verschiedenen Bedingungen
- effektiv mit Ihrem benannten Index
- Zusammenführungsschlüssel als Index eines und Spalte eines anderen
Mehrfachzusammenführung von Spalten und Indizes (eindeutig und nicht eindeutig)
Bemerkenswerte Alternativen zu
mergeundjoin
Was dieser Beitrag nicht durchmachen wird:
- Leistungsbezogene Diskussionen und Timings (vorerst). Meist bemerkenswerte Erwähnungen besserer Alternativen, wo immer dies angebracht ist.
- Behandeln von Suffixen, Entfernen zusätzlicher Spalten, Umbenennen von Ausgaben und anderer spezifischer Anwendungsfälle. Es gibt andere (sprich: bessere) Beiträge, die sich damit befassen, also finde es heraus!
Hinweis
Die meisten Beispiele verwenden standardmäßig INNER JOIN-Vorgänge, während verschiedene Funktionen demonstriert werden, sofern nicht anders angegeben.Außerdem können alle DataFrames hier kopiert und repliziert werden, damit Sie mit ihnen spielen können. In diesem Beitrag erfahren Sie auch, wie Sie DataFrames aus Ihrer Zwischenablage lesen.
Zuletzt wurden alle visuellen Darstellungen von JOIN-Vorgängen mithilfe von Google Drawings von Hand gezeichnet. Inspiration von hier .
Genug geredet, zeig mir einfach, wie man es benutzt merge!
Installieren
np.random.seed(0)
left = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': np.random.randn(4)})
right = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': np.random.randn(4)})
left
key value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right
key value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
Der Einfachheit halber hat die Schlüsselspalte (vorerst) den gleichen Namen.
Ein INNER JOIN wird vertreten durch
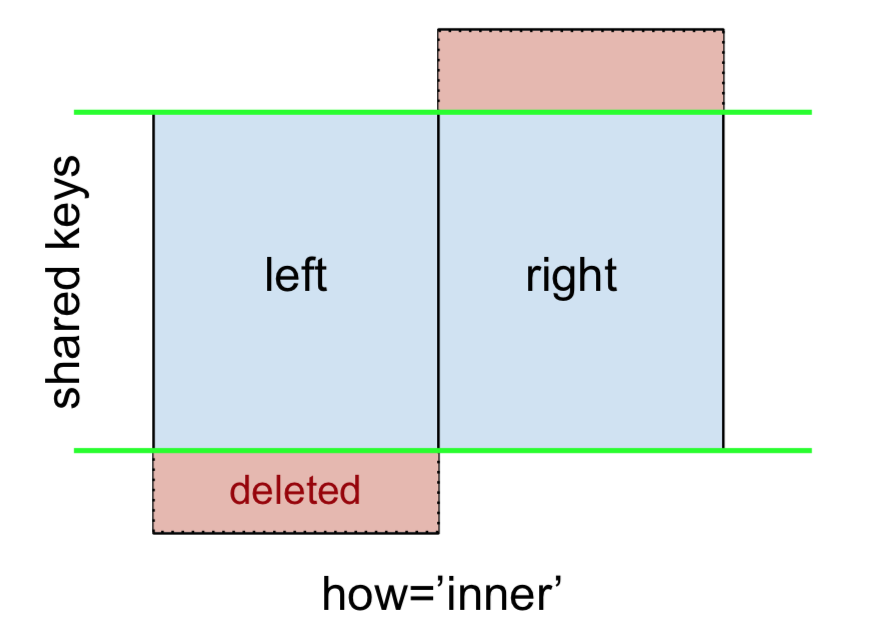
Hinweis
: Zusammen mit den bevorstehenden Zahlen folgen alle dieser Konvention:
- Blau zeigt Zeilen an, die im Zusammenführungsergebnis vorhanden sind
- rot zeigt Zeilen an, die vom Ergebnis ausgeschlossen sind (dh entfernt wurden)
- Grün zeigt fehlende Werte an, die
NaNim Ergebnis durch s ersetzt werden
Um einen INNER JOIN auszuführen, rufen Sie mergeden linken DataFrame auf und geben Sie den rechten DataFrame und den Join-Schlüssel (zumindest) als Argumente an.
left.merge(right, on='key')
# Or, if you want to be explicit
# left.merge(right, on='key', how='inner')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
Dies gibt nur Zeilen aus leftund rightdie einen gemeinsamen Schlüssel (in diesem Beispiel „B“ und „D).
Ein LEFT OUTER JOIN oder LEFT JOIN wird durch dargestellt
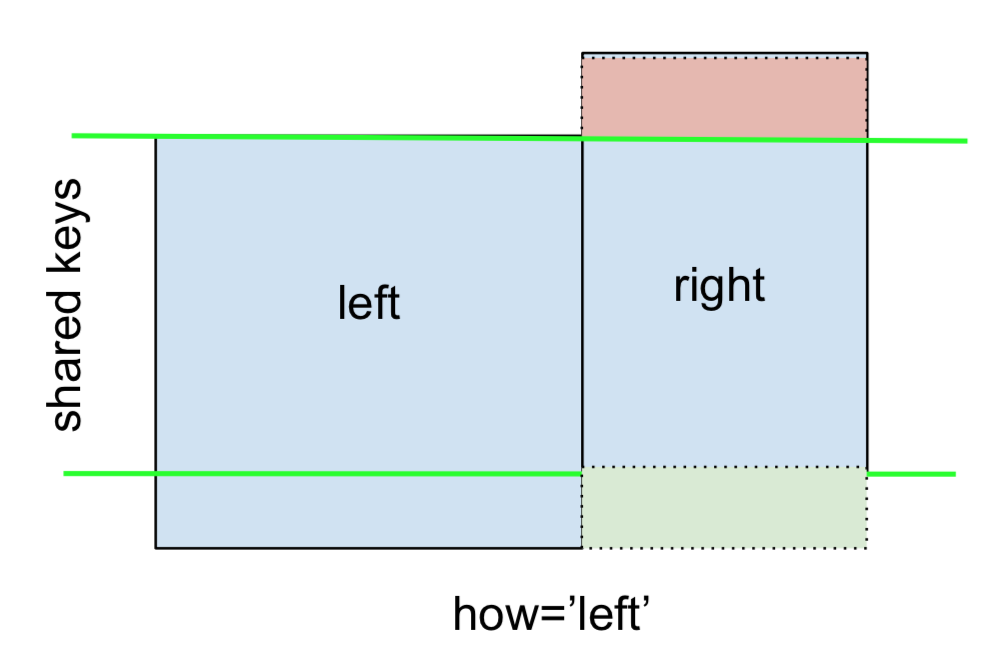
Dies kann durch Angabe erfolgen how='left'.
left.merge(right, on='key', how='left')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
Beachten Sie hier die Platzierung der NaNs. Wenn Sie angeben how='left', werden nur Schlüssel von leftverwendet, und fehlende Daten von werden rightdurch NaN ersetzt.
Und in ähnlicher Weise für einen RIGHT OUTER JOIN oder RIGHT JOIN, der ...
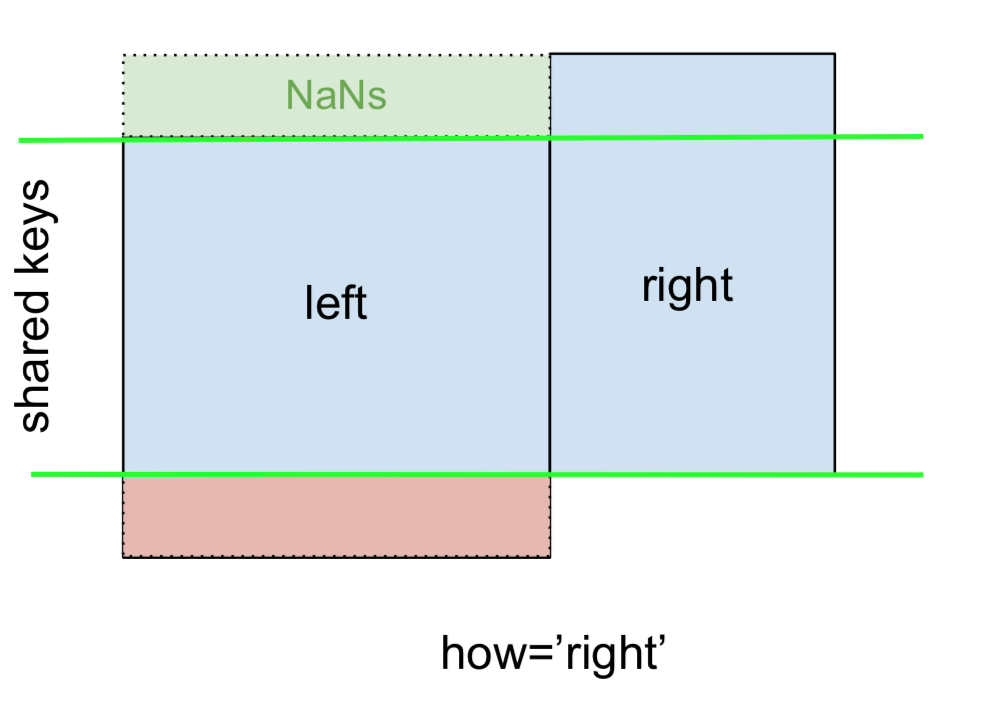
... angeben how='right':
left.merge(right, on='key', how='right')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
2 E NaN 0.950088
3 F NaN -0.151357
Hier werden Schlüssel von rightverwendet und fehlende Daten von leftdurch NaN ersetzt.
Zum Schluss für den FULL OUTER JOIN , gegeben von
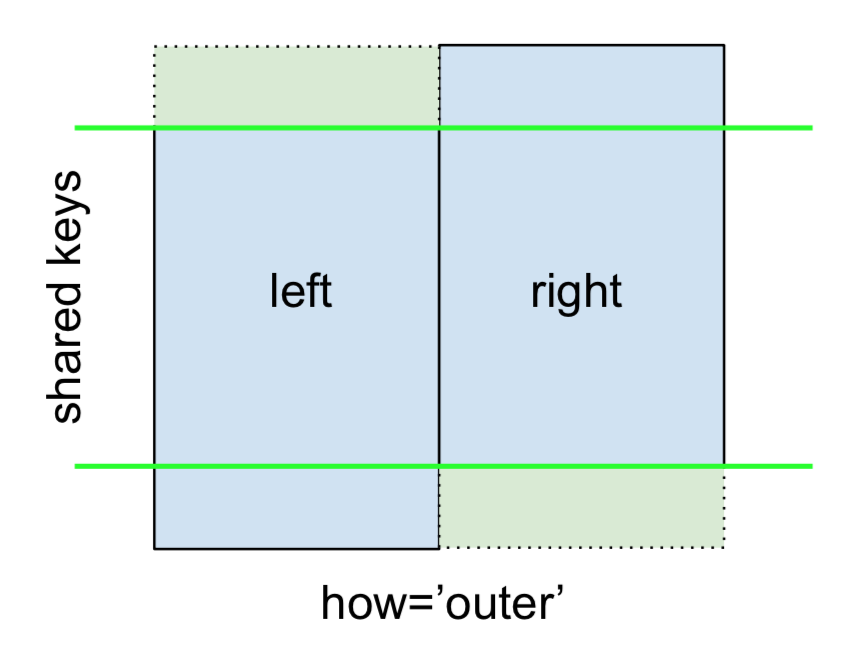
angeben how='outer'.
left.merge(right, on='key', how='outer')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
4 E NaN 0.950088
5 F NaN -0.151357
Dies verwendet die Schlüssel aus beiden Frames, und NaNs werden für fehlende Zeilen in beiden eingefügt.
Die Dokumentation fasst diese verschiedenen Zusammenführungen gut zusammen:

Andere VERBINDUNGEN - LINKS-AUSSCHLIESSLICH, RECHTS-AUSSCHLIESSLICH und VOLLSTÄNDIG / ANTI-VERBINDUNGEN
Wenn Sie LINKS -AUSSCHLIESSENDE VERBINDUNGEN und RECHTS-AUSSCHLIESSENDE VERBINDUNGEN in zwei Schritten benötigen .
Für LEFT-Excluding JOIN, dargestellt als
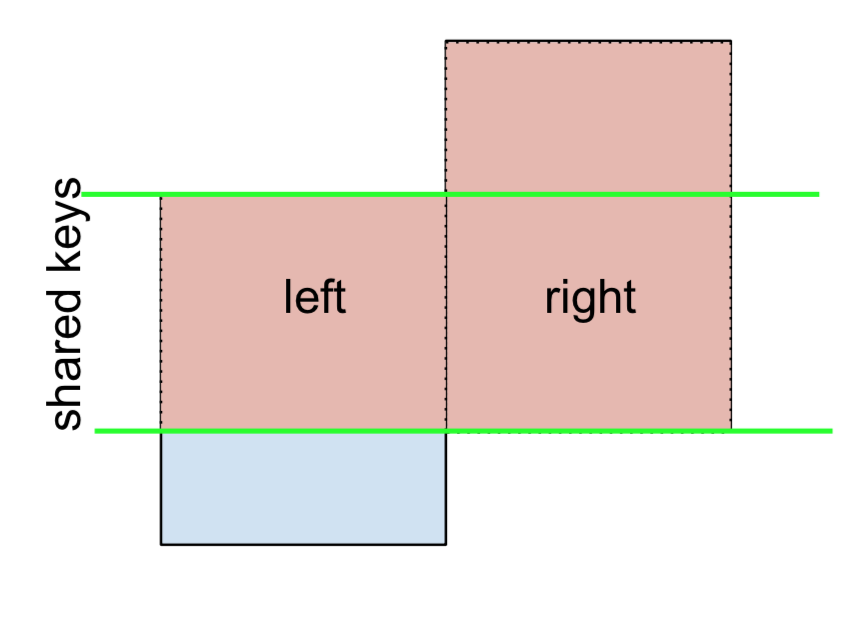
Führen Sie zunächst einen LEFT OUTER JOIN durch und filtern Sie dann (ausgenommen!) Zeilen, die leftnur von stammen.
(left.merge(right, on='key', how='left', indicator=True)
.query('_merge == "left_only"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
Wo,
left.merge(right, on='key', how='left', indicator=True)
key value_x value_y _merge
0 A 1.764052 NaN left_only
1 B 0.400157 1.867558 both
2 C 0.978738 NaN left_only
3 D 2.240893 -0.977278 bothUnd in ähnlicher Weise für einen RECHTS-AUSSCHLUSS
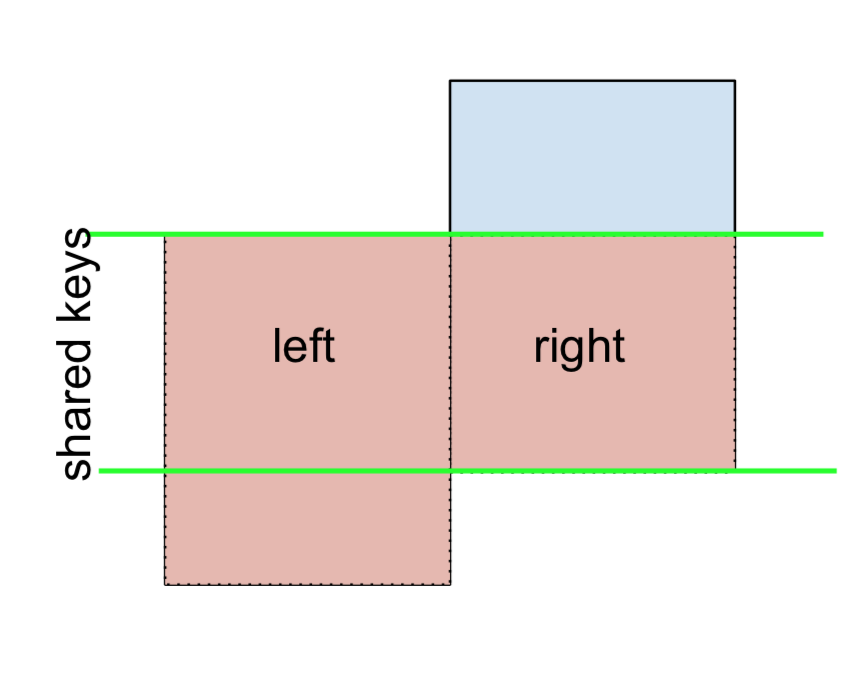
(left.merge(right, on='key', how='right', indicator=True)
.query('_merge == "right_only"')
.drop('_merge', 1))
key value_x value_y
2 E NaN 0.950088
3 F NaN -0.151357Wenn Sie eine Zusammenführung durchführen müssen, bei der nur die Schlüssel von links oder rechts, aber nicht beide beibehalten werden (IOW, Durchführen eines ANTI-JOIN ),
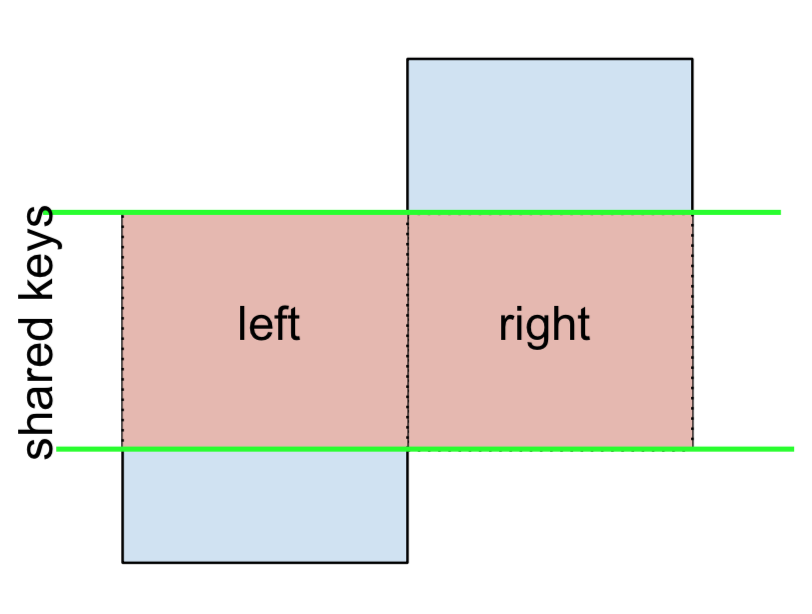
Sie können dies auf ähnliche Weise tun -
(left.merge(right, on='key', how='outer', indicator=True)
.query('_merge != "both"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
4 E NaN 0.950088
5 F NaN -0.151357
Unterschiedliche Namen für Schlüsselspalten
Wenn die Schlüsselspalten unterschiedlich benannt sind, z. B. lefthas keyLeftund righthas keyRightanstelle von, keymüssen Sie left_onund right_onals Argumente angeben, anstatt on:
left2 = left.rename({'key':'keyLeft'}, axis=1)
right2 = right.rename({'key':'keyRight'}, axis=1)
left2
keyLeft value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right2
keyRight value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')
keyLeft value_x keyRight value_y
0 B 0.400157 B 1.867558
1 D 2.240893 D -0.977278
Vermeiden doppelter Schlüsselspalten in der Ausgabe
Wenn Sie beim Zusammenführen keyLeftvon leftund keyRightvon rightnur eines keyLeftoder keyRight(aber nicht beide) in der Ausgabe verwenden möchten , können Sie zunächst den Index als vorläufigen Schritt festlegen.
left3 = left2.set_index('keyLeft')
left3.merge(right2, left_index=True, right_on='keyRight')
value_x keyRight value_y
0 0.400157 B 1.867558
1 2.240893 D -0.977278
Vergleichen Sie dies mit der Ausgabe des Befehls kurz vor (dh der Ausgabe von left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')), Sie werden feststellen, dass sie keyLeftfehlt. Sie können anhand des Frame-Index als Schlüssel herausfinden, welche Spalte beibehalten werden soll. Dies kann von Bedeutung sein, wenn beispielsweise eine OUTER JOIN-Operation ausgeführt wird.
Zusammenführen nur einer einzelnen Spalte aus einer der DataFrames
Betrachten Sie zum Beispiel
right3 = right.assign(newcol=np.arange(len(right)))
right3
key value newcol
0 B 1.867558 0
1 D -0.977278 1
2 E 0.950088 2
3 F -0.151357 3
Wenn Sie nur "new_val" (ohne eine der anderen Spalten) zusammenführen müssen, können Sie vor dem Zusammenführen normalerweise nur Spalten unterteilen:
left.merge(right3[['key', 'newcol']], on='key')
key value newcol
0 B 0.400157 0
1 D 2.240893 1
Wenn Sie einen LEFT OUTER JOIN durchführen, würde eine leistungsfähigere Lösung Folgendes beinhalten map:
# left['newcol'] = left['key'].map(right3.set_index('key')['newcol']))
left.assign(newcol=left['key'].map(right3.set_index('key')['newcol']))
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
Wie bereits erwähnt, ist dies ähnlich, aber schneller als
left.merge(right3[['key', 'newcol']], on='key', how='left')
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
Zusammenführen mehrerer Spalten
Geben Sie eine Liste für on(oder left_onund) an right_on, um mehr als einer Spalte beizutreten .
left.merge(right, on=['key1', 'key2'] ...)
Oder falls die Namen unterschiedlich sind,
left.merge(right, left_on=['lkey1', 'lkey2'], right_on=['rkey1', 'rkey2'])
Andere nützliche merge*Operationen und Funktionen
Zusammenführen eines DataFrame mit Serien im Index : Siehe diese Antwort .
Außerdem
merge,DataFrame.updateundDataFrame.combine_firstwird auch in bestimmten Fällen mit einem anderen Datenrahmen zu aktualisieren.pd.merge_orderedist eine nützliche Funktion für bestellte JOINs.pd.merge_asof(read: merge_asOf) ist nützlich für ungefähre Verknüpfungen .
Dieser Abschnitt behandelt nur die Grundlagen und soll nur Ihren Appetit anregen. Weitere Beispiele und Fälle finden Sie in der Dokumentation merge, joinundconcat sowie die Links zu den Funktionsdaten.
Indexbasiertes * -JOIN (+ Indexspalte merges)
Installieren
np.random.seed([3, 14])
left = pd.DataFrame({'value': np.random.randn(4)}, index=['A', 'B', 'C', 'D'])
right = pd.DataFrame({'value': np.random.randn(4)}, index=['B', 'D', 'E', 'F'])
left.index.name = right.index.name = 'idxkey'
left
value
idxkey
A -0.602923
B -0.402655
C 0.302329
D -0.524349
right
value
idxkey
B 0.543843
D 0.013135
E -0.326498
F 1.385076
In der Regel sieht eine Zusammenführung des Index folgendermaßen aus:
left.merge(right, left_index=True, right_index=True)
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Unterstützung für Indexnamen
Wenn Ihr Index genannt wird, dann v0.23 Benutzer können auch die Ebenennamen angeben on(oder left_onund je right_onnach Bedarf).
left.merge(right, on='idxkey')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Zusammenführen auf Index einer, Spalte (n) einer anderen
Es ist möglich (und recht einfach), den Index eines und die Spalte eines anderen zu verwenden, um eine Zusammenführung durchzuführen. Zum Beispiel,
left.merge(right, left_on='key1', right_index=True)
Oder umgekehrt ( right_on=...und left_index=True).
right2 = right.reset_index().rename({'idxkey' : 'colkey'}, axis=1)
right2
colkey value
0 B 0.543843
1 D 0.013135
2 E -0.326498
3 F 1.385076
left.merge(right2, left_index=True, right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
In diesem speziellen Fall wird der Index für leftbenannt, sodass Sie den Indexnamen auch wie folgt verwenden können left_on:
left.merge(right2, left_on='idxkey', right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
DataFrame.join
Daneben gibt es noch eine weitere prägnante Option. Sie können DataFrame.joindie Standardeinstellungen für Verknüpfungen im Index verwenden. DataFrame.joinführt standardmäßig einen LEFT OUTER JOIN durch, how='inner'ist hier also erforderlich.
left.join(right, how='inner', lsuffix='_x', rsuffix='_y')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Beachten Sie, dass ich die Argumente lsuffixund angeben musste, rsuffixda joinsonst ein Fehler auftreten würde:
left.join(right)
ValueError: columns overlap but no suffix specified: Index(['value'], dtype='object')
Da die Spaltennamen gleich sind. Dies wäre kein Problem, wenn sie anders benannt wären.
left.rename(columns={'value':'leftvalue'}).join(right, how='inner')
leftvalue value
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
pd.concat
Als Alternative für indexbasierte Joins können Sie Folgendes verwenden pd.concat:
pd.concat([left, right], axis=1, sort=False, join='inner')
value value
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
join='inner'Lassen Sie es aus, wenn Sie einen FULL OUTER JOIN benötigen (Standardeinstellung):
pd.concat([left, right], axis=1, sort=False)
value value
A -0.602923 NaN
B -0.402655 0.543843
C 0.302329 NaN
D -0.524349 0.013135
E NaN -0.326498
F NaN 1.385076
Weitere Informationen finden Sie in diesem kanonischen Beitrag pd.concatvon @piRSquared .
Verallgemeinern: mergeMehrere DataFrames
Oft tritt die Situation auf, wenn mehrere DataFrames zusammengeführt werden sollen. Naiv kann dies durch Verketten von mergeAnrufen erfolgen:
df1.merge(df2, ...).merge(df3, ...)
Dies gerät jedoch für viele DataFrames schnell außer Kontrolle. Darüber hinaus kann es erforderlich sein, eine unbekannte Anzahl von DataFrames zu verallgemeinern.
Hier stelle ich pd.concatfür Mehrweg-Verknüpfungen mit eindeutigen Schlüsseln und DataFrame.joinfür Mehrweg-Verknüpfungen mit nicht eindeutigen Schlüsseln vor. Zunächst das Setup.
# Setup.
np.random.seed(0)
A = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'valueA': np.random.randn(4)})
B = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'valueB': np.random.randn(4)})
C = pd.DataFrame({'key': ['D', 'E', 'J', 'C'], 'valueC': np.ones(4)})
dfs = [A, B, C]
# Note, the "key" column values are unique, so the index is unique.
A2 = A.set_index('key')
B2 = B.set_index('key')
C2 = C.set_index('key')
dfs2 = [A2, B2, C2]
Mehrfachzusammenführung auf eindeutigen Schlüsseln (oder Index)
Wenn Ihre Schlüssel (hier kann der Schlüssel entweder eine Spalte oder ein Index sein) eindeutig sind, können Sie sie verwenden pd.concat. Beachten Sie, dass pd.concatDataFrames im Index verknüpft werden .
# merge on `key` column, you'll need to set the index before concatenating
pd.concat([
df.set_index('key') for df in dfs], axis=1, join='inner'
).reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# merge on `key` index
pd.concat(dfs2, axis=1, sort=False, join='inner')
valueA valueB valueC
key
D 2.240893 -0.977278 1.0
join='inner'Lassen Sie für eine vollständige äußere Verbindung. Beachten Sie, dass Sie keine Verknüpfungen für LINKS oder RECHTS AUSSEN angeben können (wenn Sie diese benötigen, verwenden Sie joindie unten beschriebenen).
Mehrweg-Zusammenführung von Schlüsseln mit Duplikaten
concatist schnell, hat aber seine Mängel. Duplikate können nicht verarbeitet werden.
A3 = pd.DataFrame({'key': ['A', 'B', 'C', 'D', 'D'], 'valueA': np.random.randn(5)})
pd.concat([df.set_index('key') for df in [A3, B, C]], axis=1, join='inner')
ValueError: Shape of passed values is (3, 4), indices imply (3, 2)
In dieser Situation können wir verwenden, joinda es nicht eindeutige Schlüssel verarbeiten kann (beachten Sie, dass joinDataFrames in ihrem Index verknüpft werden; es wird mergeunter der Haube aufgerufen und führt eine LEFT OUTER JOIN durch, sofern nicht anders angegeben).
# join on `key` column, set as the index first
# For inner join. For left join, omit the "how" argument.
A.set_index('key').join(
[df.set_index('key') for df in (B, C)], how='inner').reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# join on `key` index
A3.set_index('key').join([B2, C2], how='inner')
valueA valueB valueC
key
D 1.454274 -0.977278 1.0
D 0.761038 -0.977278 1.0
Eine ergänzende visuelle Ansicht von pd.concat([df0, df1], kwargs). Beachten Sie, dass die Bedeutung von kwarg axis=0oder axis=1nicht so intuitiv ist wie df.mean()oderdf.apply(func)
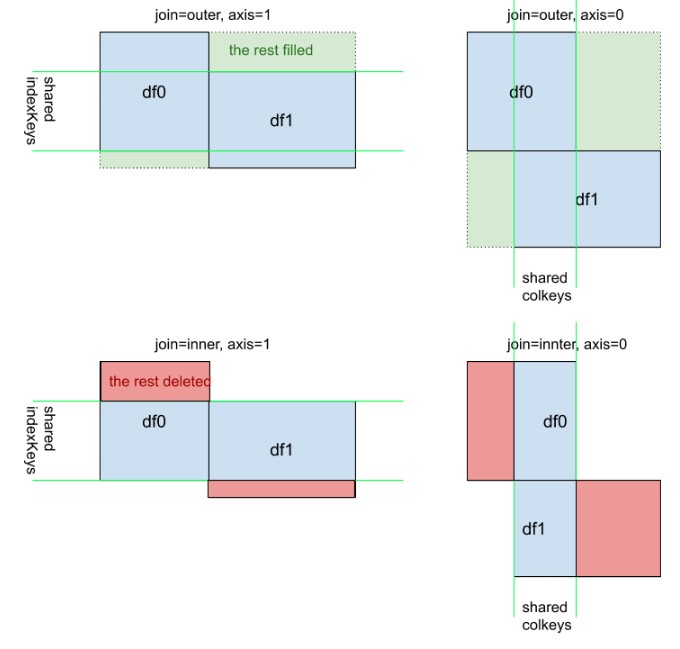
In dieser Antwort werde ich ein praktisches Beispiel für die pandas.concat.
Berücksichtigen Sie Folgendes DataFramesmit denselben Spaltennamen:
Preco2018 mit Größe (8784, 5)
Preco 2019 mit Größe (8760, 5)
Das haben die gleichen Spaltennamen.
Sie können sie pandas.concateinfach mit kombinieren
import pandas as pd
frames = [Preco2018, Preco2019]
df_merged = pd.concat(frames)
Was zu einem DataFrame mit der folgenden Größe führt (17544, 5)

Wenn Sie visualisieren möchten, funktioniert es am Ende so
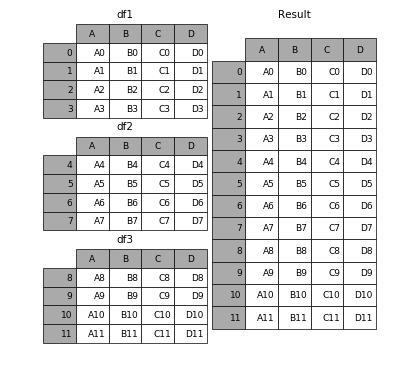
( Quelle )