L'ingegneria dei dati semplificata: script Python allegati per dare il via alle tue attività ETL
Panoramica:
Assumi il lavoro di un ingegnere dei dati, estraendo i dati da più fonti di formati di file, trasformandoli in particolari tipi di dati e caricandoli in un'unica fonte per l'analisi. Presto Dopo aver letto questo articolo, con l'aiuto di diversi esempi pratici, sarai in grado di mettere alla prova le tue capacità implementando il web scraping e l'estrazione di dati con le API. Con Python e l'ingegneria dei dati, sarai in grado di iniziare a raccogliere enormi set di dati da molte fonti e trasformarli in un'unica fonte primaria o avviare il web scraping per utili approfondimenti aziendali.

Sinossi:
- Perché l'ingegneria dei dati è più affidabile?
- Processo del ciclo ETL
- Passo dopo passo Estrai, Trasforma, la funzione Carica
- Informazioni sull'ingegneria dei dati
- Conclusione
È un'occupazione tecnologica più affidabile e in più rapida crescita nella generazione attuale, poiché si concentra maggiormente sul web scraping e sul crawling dei set di dati.
Processo (ciclo ETL):
Ti sei mai chiesto come sono stati integrati i dati provenienti da molte fonti per creare un'unica fonte di informazioni? L'elaborazione in batch è una sorta di raccolta di dati e ulteriori informazioni su "come esplorare un tipo di elaborazione in batch" chiamato Estrai, Trasforma e Carica.

ETL è il processo di estrazione di enormi volumi di dati da una varietà di fonti e formati e di conversione in un unico formato prima di inserirli in un database o in un file di destinazione.
Alcuni dei tuoi dati sono archiviati in file CSV, mentre altri sono archiviati in file JSON. Devi raccogliere tutte queste informazioni in un unico file affinché l'IA possa leggerle. Poiché i tuoi dati sono in unità imperiali, ma l'intelligenza artificiale ha bisogno di unità metriche, dovrai convertirli. Poiché l'intelligenza artificiale può leggere solo i dati CSV in un unico file di grandi dimensioni, devi prima caricarlo. Se i dati sono in formato CSV, inseriamo il seguente ETL con python e diamo un'occhiata alla fase di estrazione con alcuni semplici esempi.
Osservando l'elenco dei file .json e .csv. L'estensione del file glob è preceduta da una stella e da un punto nell'input. Viene restituito un elenco di file.csv. For.json, possiamo fare la stessa cosa. Potremmo creare un file che estrae nomi, altezze e pesi in formato CSV. Il nome file del file.csv è l'input e l'output è un frame di dati. Per i formati JSON, possiamo fare la stessa cosa.
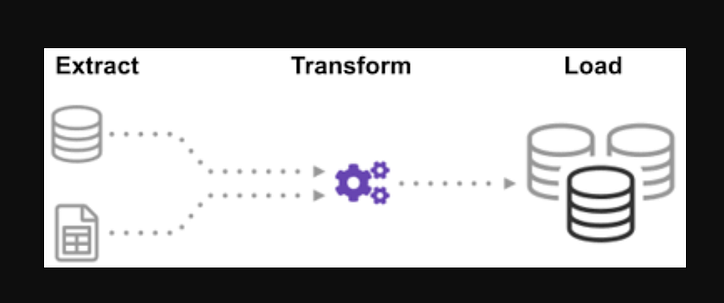
Passo 1:
Importa le funzioni e i moduli richiesti
import glob
import pandas as pd
import xml.etree.ElementTree as ET
from datetime import datetime
I file dealership_datacontengono file CSV, JSON e XML per i dati delle auto usate che contengono caratteristiche denominate car_model, year_of_manufacture, pricee fuel. Quindi estrarremo il file dai dati grezzi e lo trasformeremo in un file di destinazione e lo caricheremo nell'output.
Imposta il percorso per i file di destinazione:
tmpfile = "dealership_temp.tmp" # store all extracted data
logfile = "dealership_logfile.txt" # all event logs will be stored
targetfile = "dealership_transformed_data.csv" # transformed data is stored
La funzione estrarrà grandi quantità di dati da più fonti in batch. Aggiungendo questa funzione, ora scoprirà e caricherà tutti i nomi dei file CSV e i file CSV verranno aggiunti al frame della data con ogni iterazione del ciclo, con la prima iterazione allegata per prima, seguita dalla seconda iterazione, risultando in un elenco di dati estratti. Dopo aver raccolto i dati, passeremo alla fase "Trasformazione" del processo.
Nota: se "ignore index" è impostato su true, l'ordine di ogni riga sarà lo stesso dell'ordine in cui le righe sono state accodate al frame di dati.
Funzione di estrazione CSV
def extract_from_csv(file_to_process):
dataframe = pd.read_csv(file_to_process)
return dataframe
def extract_from_json(file_to_process):
dataframe = pd.read_json(file_to_process,lines=True)
return dataframe
def extract_from_xml(file_to_process):
dataframe = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
tree = ET.parse(file_to_process)
root = tree.getroot()
for person in root:
car_model = person.find("car_model").text
year_of_manufacture = int(person.find("year_of_manufacture").text)
price = float(person.find("price").text)
fuel = person.find("fuel").text
dataframe = dataframe.append({"car_model":car_model, "year_of_manufacture":year_of_manufacture, "price":price, "fuel":fuel}, ignore_index=True)
return dataframe
Ora chiama la funzione di estrazione usando la sua chiamata di funzione per CSV , JSON , XML.
def extract():
extracted_data = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
#for csv files
for csvfile in glob.glob("dealership_data/*.csv"):
extracted_data = extracted_data.append(extract_from_csv(csvfile), ignore_index=True)
#for json files
for jsonfile in glob.glob("dealership_data/*.json"):
extracted_data = extracted_data.append(extract_from_json(jsonfile), ignore_index=True)
#for xml files
for xmlfile in glob.glob("dealership_data/*.xml"):
extracted_data = extracted_data.append(extract_from_xml(xmlfile), ignore_index=True)
return extracted_data
Dopo aver raccolto i dati, passeremo alla fase di "Trasformazione" del processo. Questa funzione convertirà l'altezza della colonna, espressa in pollici, in millimetri e la colonna in libbre, espressa in libbre, in chilogrammi e restituirà i risultati nei dati variabili. Nel frame di dati di input, l'altezza della colonna è in piedi. Converti la colonna per convertirla in metri e arrotondala a due cifre decimali.
def transform(data):
data['price'] = round(data.price, 2)
return data
È ora di caricare i dati nel file di destinazione ora che li abbiamo raccolti e specificati. Salviamo il data frame dei panda come CSV in questo scenario. Ora abbiamo eseguito le fasi di estrazione, trasformazione e caricamento dei dati da varie fonti in un singolo file di destinazione. Dobbiamo stabilire una voce di registrazione prima di poter terminare il nostro lavoro. Otterremo ciò scrivendo una funzione di registrazione.
Funzione di carico:
def load(targetfile,data_to_load):
data_to_load.to_csv(targetfile)
Tutti i dati scritti verranno aggiunti alle informazioni correnti quando viene aggiunta la "a". Possiamo quindi allegare un timestamp ad ogni fase del processo, indicando quando inizia e quando finisce, generando questo tipo di voce. Dopo aver definito tutto il codice necessario per eseguire il processo ETL sui dati, l'ultimo passo è chiamare tutte le funzioni.
def log(message):
timestamp_format = '%H:%M:%S-%h-%d-%Y'
#Hour-Minute-Second-MonthName-Day-Year
now = datetime.now() # get current timestamp
timestamp = now.strftime(timestamp_format)
with open("dealership_logfile.txt","a") as f: f.write(timestamp + ',' + message + 'n')
Per prima cosa iniziamo chiamando la funzione extract_data. I dati ricevuti da questo passaggio verranno quindi trasferiti al secondo passaggio di trasformazione dei dati. Dopo che questo è stato completato, i dati vengono quindi caricati nel file di destinazione. Inoltre, si noti che prima e dopo ogni passaggio sono state aggiunte l'ora e la data di inizio e completamento.
Il registro che hai avviato il processo ETL:
log("ETL Job Started")
log("Extract phase Started")
extracted_data = extract()
log("Extract phase Ended")
log("Fase di trasformazione avviata")
transform_data = transform(extracted_data)
log("Transform phase Ended")
log("Load phase Started")
load(targetfile,transformed_data)
log("Load phase Ended")
log("ETL Job Ended")
- Come scrivere una semplice funzione di estrazione.
- Come scrivere una semplice funzione di trasformazione.
- Come scrivere una semplice funzione Load.
- Come scrivere una semplice funzione di registrazione.
Al massimo, abbiamo discusso di tutti i processi ETL. Inoltre, vediamo "quali sono i vantaggi del lavoro di ingegnere dei dati?".
Informazioni sull'ingegneria dei dati:
L'ingegneria dei dati è un campo vasto con molti nomi. Potrebbe non avere nemmeno un titolo formale in molte istituzioni. Di conseguenza, in genere è meglio iniziare definendo gli obiettivi del lavoro di ingegneria dei dati che portano ai risultati attesi. Gli utenti che si affidano ai data engineer sono diversi quanto i talenti ei risultati dei team di data engineering. I tuoi consumatori definiranno sempre quali problemi gestisci e come li risolvi, indipendentemente dal settore che persegui.
Conclusione:
Spero che tu possa trovare aiuto nell'articolo e acquisire una certa comprensione dell'utilizzo di Python in ETL mentre inizi il tuo viaggio per apprendere l'ingegneria dei dati. Hai voglia di saperne di più? Ti incoraggio a dare un'occhiata ai miei altri articoli su come utilizzare le classi Python per migliorare i processi di ingegneria dei dati . Dimostro anche come utilizzare pydantic per migliorare la convalida dei dati in uno dei primi e più importanti passaggi della pipeline di dati. Se sei interessato alla visualizzazione dei dati, consulta questa guida dettagliata per creare il tuo primo grafico con Apache Superset .
Richiedere un'azione
Se trovi utile la guida, sentiti libero di applaudire e seguirmi. Unisciti a medium tramite questo link per accedere a tutti gli articoli premium da me e da tutti gli altri fantastici scrittori qui su medium.
Codifica di livello superiore
Grazie per far parte della nostra comunità! Prima che tu vada:
- Batti le mani per la storia e segui l'autore
- Visualizza altri contenuti nella pubblicazione Level Up Coding
- Seguici: Twitter | Linkedin | Notiziario

![Che cos'è un elenco collegato, comunque? [Parte 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































