データ エンジニアリングが簡単に — ETL タスクを開始するための添付の Python スクリプト
概要:
ファイル形式の複数のソースからデータを抽出し、特定のデータ型に変換し、分析のために単一のソースにロードするデータ エンジニアの仕事を想定します。すぐにこの記事を読んだ後、いくつかの実用的な例の助けを借りて、Web スクレイピングを実装し、API を使用してデータを抽出することで、スキルをテストできるようになります。Python とデータ エンジニアリングを使用すると、多くのソースから膨大なデータセットを収集して単一のプライマリ ソースに変換したり、Web スクレイピングを開始して有用なビジネス インサイトを得たりすることができます。

あらすじ:
- データ エンジニアリングの信頼性が高いのはなぜですか?
- ETL サイクルのプロセス
- ステップバイステップの抽出、変換、読み込み機能
- データエンジニアリングについて
- 結論
Webスクレイピングとデータセットのクロールに集中しているため、現在の世代ではより信頼性が高く、最も急速に成長している技術職です.
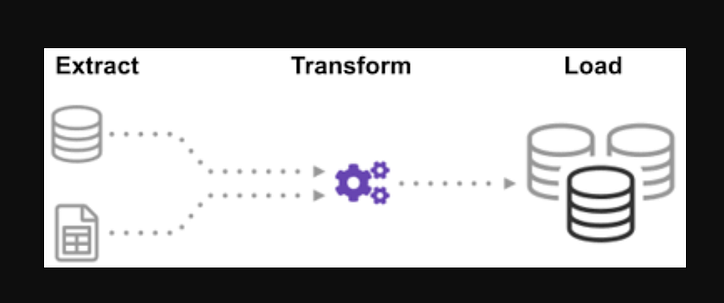
プロセス (ETL サイクル):
単一の情報源を作成するために、多くのソースからのデータがどのように統合されているか疑問に思ったことはありませんか? バッチ処理は一種のデータ収集であり、抽出、変換、ロードと呼ばれる「バッチ処理の種類を調査する方法」について詳しく学びます。

ETL は、さまざまなソースやフォーマットから膨大な量のデータを抽出し、単一のフォーマットに変換してから、データベースまたは宛先ファイルに入れるプロセスです。
一部のデータは CSV ファイルに保存され、他のデータは JSON ファイルに保存されます。AI が読み取れるように、このすべての情報を 1 つのファイルに収集する必要があります。データは帝国単位ですが、AI はメートル単位を必要とするため、変換する必要があります。AI は 1 つの大きなファイルの CSV データしか読み取ることができないため、最初にそれをロードする必要があります。データが CSV 形式の場合は、Python で次の ETL を配置し、いくつかの簡単な例で抽出手順を見てみましょう。
.json および .csv ファイルのリストを見る。入力では、glob ファイル拡張子の前に星とドットが付きます。.csv ファイルのリストが返されます。.json ファイルについても、同じことができます。名前、身長、体重をCSV形式で抽出したファイルを作成する場合があります。.csv ファイルのファイル名が入力で、出力はデータ フレームです。JSON 形式の場合も、同じことができます。
ステップ1:
関数と必要なモジュールをインポートする
import glob
import pandas as pd
import xml.etree.ElementTree as ET
from datetime import datetime
ファイルには、、 、、dealership_dataという名前の機能を含む中古車データの CSV、JSON、および XML ファイルが含まれています。そのため、生データからファイルを抽出し、それをターゲット ファイルに変換して、出力に読み込みます。car_modelyear_of_manufacturepricefuel
ターゲット ファイルのパスを設定します。
tmpfile = "dealership_temp.tmp" # store all extracted data
logfile = "dealership_logfile.txt" # all event logs will be stored
targetfile = "dealership_transformed_data.csv" # transformed data is stored
この関数は、複数のソースから大量のデータをバッチで抽出します。この関数を追加すると、すべての CSV ファイル名が検出されてロードされ、CSV ファイルがループの各反復で日付フレームに追加されます。最初の反復が最初に添付され、次に 2 番目の反復が続きます。抽出されたデータのリスト。データを収集したら、プロセスの「変換」ステップに進みます。
注: 「インデックスを無視」が true に設定されている場合、各行の順序は、行がデータ フレームに追加された順序と同じになります。
CSV抽出機能
def extract_from_csv(file_to_process):
dataframe = pd.read_csv(file_to_process)
return dataframe
def extract_from_json(file_to_process):
dataframe = pd.read_json(file_to_process,lines=True)
return dataframe
def extract_from_xml(file_to_process):
dataframe = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
tree = ET.parse(file_to_process)
root = tree.getroot()
for person in root:
car_model = person.find("car_model").text
year_of_manufacture = int(person.find("year_of_manufacture").text)
price = float(person.find("price").text)
fuel = person.find("fuel").text
dataframe = dataframe.append({"car_model":car_model, "year_of_manufacture":year_of_manufacture, "price":price, "fuel":fuel}, ignore_index=True)
return dataframe
次に、 CSV 、 JSON 、 XML の関数呼び出しを使用して抽出関数を呼び出します。
def extract():
extracted_data = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
#for csv files
for csvfile in glob.glob("dealership_data/*.csv"):
extracted_data = extracted_data.append(extract_from_csv(csvfile), ignore_index=True)
#for json files
for jsonfile in glob.glob("dealership_data/*.json"):
extracted_data = extracted_data.append(extract_from_json(jsonfile), ignore_index=True)
#for xml files
for xmlfile in glob.glob("dealership_data/*.xml"):
extracted_data = extracted_data.append(extract_from_xml(xmlfile), ignore_index=True)
return extracted_data
データを収集したら、プロセスの「変換」フェーズに進みます。この関数は、インチ単位の列の高さをミリメートルに、ポンド単位の列のポンドをキログラムに変換し、結果を変数データに返します。入力データ フレームでは、列の高さはフィート単位です。列を変換してメートルに変換し、小数点以下 2 桁に丸めます。
def transform(data):
data['price'] = round(data.price, 2)
return data
データを収集して指定したので、データをターゲット ファイルにロードします。このシナリオでは、pandas データ フレームを CSV として保存します。さまざまなソースから単一のターゲット ファイルにデータを抽出、変換、およびロードする手順を実行しました。作業を完了する前に、ログ エントリを確立する必要があります。これは、ロギング関数を作成することで実現します。
ロード機能:
def load(targetfile,data_to_load):
data_to_load.to_csv(targetfile)
「a」が追加されると、書き込まれたすべてのデータが現在の情報に追加されます。次に、このタイプのエントリを生成することにより、プロセスの各フェーズにタイムスタンプを添付して、開始時刻と終了時刻を示すことができます。データに対して ETL プロセスを実行するために必要なすべてのコードを定義したら、最後のステップはすべての関数を呼び出すことです。
def log(message):
timestamp_format = '%H:%M:%S-%h-%d-%Y'
#Hour-Minute-Second-MonthName-Day-Year
now = datetime.now() # get current timestamp
timestamp = now.strftime(timestamp_format)
with open("dealership_logfile.txt","a") as f: f.write(timestamp + ',' + message + 'n')
まず、extract_data 関数を呼び出します。このステップから受信したデータは、データを変換する 2 番目のステップに転送されます。これが完了すると、データがターゲット ファイルにロードされます。また、各ステップの前後に、開始と完了の時刻と日付が追加されていることに注意してください。
ETL プロセスを開始したログ:
log("ETL Job Started")
log("Extract phase Started")
extracted_data = extract()
log("Extract phase Ended")
log(“変換フェーズ開始”)
変換されたデータ = 変換 (抽出されたデータ)
log("Transform phase Ended")
log("Load phase Started")
load(targetfile,transformed_data)
log("Load phase Ended")
log("ETL Job Ended")
- 簡単な Extract 関数の作成方法。
- 簡単な Transform 関数の書き方。
- シンプルな Load 関数の書き方。
- 簡単なロギング関数の書き方。
せいぜい、すべての ETL プロセスについて説明しました。さらに、「データエンジニアの仕事のメリットは何ですか?」を見てみましょう。
データ エンジニアリングについて:
データ エンジニアリングは、多くの名前を持つ広大な分野です。多くの機関では、正式なタイトルさえ持っていない場合があります。結果として、期待される出力につながるデータ エンジニアリング作業の目的を定義することから始めることをお勧めします。データ エンジニアに依存するユーザーは、データ エンジニアリング チームの才能と結果と同じくらい多様です。どの分野を追求するかに関係なく、消費者は常に、どのような問題を処理し、どのように解決するかを定義します。
結論:
データ エンジニアリングを学ぶ旅を始めるにあたって、この記事で何らかの助けが得られ、Python を使用して ETL を使用することについてある程度理解していただければ幸いです。もっと学びたいですか?Python クラスを使用してデータ エンジニアリング プロセスを改善する方法については、私の他の記事をご覧になることをお勧めします。また、データ パイプラインの最初で最も重要なステップの 1 つで、pydanticを使用してデータ検証を改善する方法も示します。データの視覚化に関心がある場合は、Apache Superset を使用して最初のグラフを作成するためのこのステップバイステップ ガイドを確認してください。
行動を求めます
このガイドが役に立ったら、拍手してフォローしてください。このリンクからmedium に参加して、mediumで私と他のすべての素晴らしいライターからのすべてのプレミアム記事にアクセスしてください。
コーディングのレベルアップ
私たちのコミュニティに参加してくれてありがとう!行く前に:
- ストーリーに拍手して作者をフォローしてください
- Level Up Coding の出版物のコンテンツをもっと見る
- フォローしてください: Twitter | リンクトイン| ニュースレター

![とにかく、リンクリストとは何ですか?[パート1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































