Veri Mühendisliği Kolaylaştırıldı — ETL Görevlerinizi Başlatmak İçin Ekli Python Komut Dosyaları
Genel bakış:
Birden çok dosya biçimi kaynağından veri ayıklayan, belirli veri türlerine dönüştüren ve analiz için tek bir kaynağa yükleyen bir Veri Mühendisi görevini üstlenin. Bu makaleyi okuduktan kısa bir süre sonra, birkaç pratik örneğin yardımıyla, web kazıma uygulayarak ve API'lerle veri çekerek becerilerinizi test edebileceksiniz. Python ve veri mühendisliği ile birçok kaynaktan devasa veri kümelerini toplamaya ve bunları tek bir birincil kaynağa dönüştürmeye veya yararlı iş içgörüleri için web kazımaya başlayabileceksiniz.

özet:
- Veri mühendisliği neden daha güvenilirdir?
- ETL döngüsünün süreci
- Adım adım Çıkart, Dönüştür, Yükle işlevi
- Veri mühendisliği hakkında
- Çözüm
Web kazıma ve veri kümelerini taramaya daha fazla odaklandığından, mevcut nesilde daha güvenilir ve en hızlı büyüyen bir teknoloji mesleğidir.
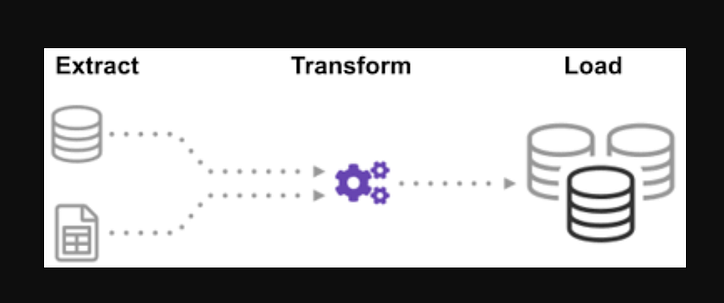
İşlem (ETL Döngüsü):
Tek bir bilgi kaynağı oluşturmak için birçok kaynaktan gelen verilerin nasıl entegre edildiğini hiç merak ettiniz mi? Toplu işleme, bir tür veri toplamadır ve Çıkarma, Dönüştürme ve Yükleme adı verilen "bir toplu işleme türünün nasıl keşfedileceği" hakkında daha fazla bilgi edinin.

ETL, çeşitli kaynaklardan ve formatlardan büyük hacimli verileri çıkarma ve bir veritabanına veya hedef dosyaya koymadan önce tek bir formata dönüştürme işlemidir.
Verilerinizin bir kısmı CSV dosyalarında saklanırken, diğerleri JSON dosyalarında saklanır. AI'nın okuyabilmesi için tüm bu bilgileri tek bir dosyada toplamanız gerekir. Verileriniz emperyal birimlerde olduğundan, ancak yapay zekanın metrik birimlere ihtiyacı olduğundan, bunları dönüştürmeniz gerekir. AI yalnızca tek bir büyük dosyadaki CSV verilerini okuyabildiğinden, önce onu yüklemeniz gerekir. Veriler CSV formatında ise aşağıdaki ETL'yi python ile koyalım ve bazı kolay örneklerle çıkarma adımına bir göz atalım.
.json ve.csv dosyalarının listesine bakarak. Glob dosya uzantısından önce girişte bir yıldız ve bir nokta bulunur. .csv dosyalarının bir listesi döndürülür. .json dosyaları için aynı şeyi yapabiliriz. İsimleri, boyları ve ağırlıkları CSV formatında çıkaran bir dosya oluşturabiliriz. .csv dosyasının dosya adı girdi, çıktı ise bir veri çerçevesidir. JSON biçimleri için aynı şeyi yapabiliriz.
Aşama 1:
İşlevleri ve gerekli modülleri içe aktarın
import glob
import pandas as pd
import xml.etree.ElementTree as ET
from datetime import datetime
Dosyalar , , , ve dealership_dataadlı özellikleri içeren kullanılmış araba verileri için CSV, JSON ve XML dosyalarını içerir . Bu yüzden dosyayı ham veriden çıkaracağız ve onu bir hedef dosyaya dönüştürüp çıktıya yükleyeceğiz.car_modelyear_of_manufacturepricefuel
Hedef dosyalar için yolu ayarlayın:
tmpfile = "dealership_temp.tmp" # store all extracted data
logfile = "dealership_logfile.txt" # all event logs will be stored
targetfile = "dealership_transformed_data.csv" # transformed data is stored
İşlev, birden çok kaynaktan büyük miktarda veriyi toplu olarak çıkaracaktır. Bu işlevi ekleyerek, şimdi tüm CSV dosya adlarını keşfedecek ve yükleyecek ve CSV dosyaları, döngünün her yinelemesinde tarih çerçevesine eklenecek, ilk yineleme önce eklenecek, ardından ikinci yineleme gelecek. ayıklanan veriler listesinde. Verileri topladıktan sonra sürecin “Dönüştürme” adımına geçeceğiz.
Not: "Ignore index" true olarak ayarlanırsa, her satırın sırası, satırların veri çerçevesine eklenme sırası ile aynı olacaktır.
CSV Çıkarma İşlevi
def extract_from_csv(file_to_process):
dataframe = pd.read_csv(file_to_process)
return dataframe
def extract_from_json(file_to_process):
dataframe = pd.read_json(file_to_process,lines=True)
return dataframe
def extract_from_xml(file_to_process):
dataframe = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
tree = ET.parse(file_to_process)
root = tree.getroot()
for person in root:
car_model = person.find("car_model").text
year_of_manufacture = int(person.find("year_of_manufacture").text)
price = float(person.find("price").text)
fuel = person.find("fuel").text
dataframe = dataframe.append({"car_model":car_model, "year_of_manufacture":year_of_manufacture, "price":price, "fuel":fuel}, ignore_index=True)
return dataframe
Şimdi CSV , JSON , XML için işlev çağrısını kullanarak ayıklama işlevini çağırın.
def extract():
extracted_data = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
#for csv files
for csvfile in glob.glob("dealership_data/*.csv"):
extracted_data = extracted_data.append(extract_from_csv(csvfile), ignore_index=True)
#for json files
for jsonfile in glob.glob("dealership_data/*.json"):
extracted_data = extracted_data.append(extract_from_json(jsonfile), ignore_index=True)
#for xml files
for xmlfile in glob.glob("dealership_data/*.xml"):
extracted_data = extracted_data.append(extract_from_xml(xmlfile), ignore_index=True)
return extracted_data
Verileri topladıktan sonra sürecin “Dönüştürme” aşamasına geçeceğiz. Bu işlev, inç cinsinden olan sütun yüksekliğini milimetreye ve pound cinsinden olan sütun pound'u kilograma çevirecek ve sonuçları değişken verilerde döndürecektir. Giriş verisi çerçevesinde sütun yüksekliği fit cinsindendir. Sütunu metreye dönüştürün ve iki ondalık basamağa yuvarlayın.
def transform(data):
data['price'] = round(data.price, 2)
return data
Artık verileri toplayıp belirlediğimize göre, verileri hedef dosyaya yükleme zamanı. Bu senaryoda pandas veri çerçevesini CSV olarak kaydediyoruz. Artık çeşitli kaynaklardan verileri ayıklama, dönüştürme ve tek bir hedef dosyaya yükleme adımlarından geçtik. İşimizi bitirmeden önce bir günlük kaydı oluşturmamız gerekiyor. Bunu bir günlük işlevi yazarak başaracağız.
Yük fonksiyonu:
def load(targetfile,data_to_load):
data_to_load.to_csv(targetfile)
Yazılan tüm veriler “a” eklendiğinde mevcut bilgilere eklenecektir. Daha sonra, bu tür bir giriş oluşturarak sürecin her aşamasına, ne zaman başladığını ve ne zaman bittiğini gösteren bir zaman damgası ekleyebiliriz. Veriler üzerinde ETL işlemini gerçekleştirmek için gerekli tüm kodları tanımladıktan sonra son adım tüm fonksiyonları çağırmak.
def log(message):
timestamp_format = '%H:%M:%S-%h-%d-%Y'
#Hour-Minute-Second-MonthName-Day-Year
now = datetime.now() # get current timestamp
timestamp = now.strftime(timestamp_format)
with open("dealership_logfile.txt","a") as f: f.write(timestamp + ',' + message + 'n')
İlk önce veri_çıkarı işlevini çağırarak başlıyoruz. Bu adımdan alınan veriler daha sonra verilerin dönüştürüldüğü ikinci adıma aktarılacaktır. Bu tamamlandıktan sonra, veriler hedef dosyaya yüklenir. Ayrıca, her adımdan önce ve sonra başlangıç ve bitiş saat ve tarihinin eklendiğini unutmayın.
ETL sürecini başlattığınız günlük:
log("ETL Job Started")
log("Extract phase Started")
extracted_data = extract()
log("Extract phase Ended")
log(“Dönüşüm aşaması başladı”)
transformed_data = transform(extracted_data)
log("Transform phase Ended")
log("Load phase Started")
load(targetfile,transformed_data)
log("Load phase Ended")
log("ETL Job Ended")
- Basit bir Extract işlevi nasıl yazılır?
- Basit bir Dönüştürme işlevi nasıl yazılır?
- Basit bir Load fonksiyonu nasıl yazılır?
- Basit bir günlük işlevi nasıl yazılır.
En fazla, tüm ETL süreçlerini tartıştık. Ayrıca, “veri mühendisi işinin faydaları nelerdir” bakalım.
Veri Mühendisliği Hakkında:
Veri mühendisliği, birçok isme sahip geniş bir alandır. Birçok kurumda resmi bir unvanı bile olmayabilir. Sonuç olarak, beklenen çıktılara götüren veri mühendisliği çalışmasının amaçlarını tanımlayarak başlamak genellikle daha iyidir. Veri mühendislerine güvenen kullanıcılar, veri mühendisliği ekiplerinin yetenekleri ve sonuçları kadar çeşitlidir. Hangi sektörü takip ederseniz edin, hangi sorunları ele aldığınızı ve bunları nasıl çözeceğinizi her zaman tüketicileriniz belirleyecektir.
Çözüm:
Umarım bu makalede biraz yardım bulursunuz ve veri mühendisliğini öğrenme yolculuğunuza başlarken Python'dan ETL'ye geçiş hakkında biraz fikir edinirsiniz. Daha fazla öğrenmek ister misin? Veri mühendisliği süreçlerini geliştirmek için python sınıflarını nasıl kullanabileceğinize dair diğer makalelerime göz atmanızı tavsiye ederim . Ayrıca , veri hattınızın ilk ve en önemli adımlarından birinde veri doğrulamanızı geliştirmek için pydantic'i nasıl kullanacağınızı gösteriyorum. Veri görselleştirmeyle ilgileniyorsanız, Apache Superset ile ilk grafiğinizi oluşturmak için bu adım adım kılavuzu kontrol edin .
Eylem çağrısı
Rehberi yararlı bulursanız, alkışlamaktan ve beni takip etmekten çekinmeyin. Medium'daki benden ve diğer tüm harika yazarlardan gelen tüm premium makalelere erişmek için bu bağlantı aracılığıyla Medium'a katılın .
Seviye Atlama Kodlama
Topluluğumuzun bir parçası olduğunuz için teşekkürler! Gitmeden önce:
- Hikaye için alkışlayın ve yazarı takip edin
- Seviye Atlama Kodlama yayınında daha fazla içerik görüntüleyin
- Bizi takip edin: Twitter | LinkedIn | Bülten

![Bağlantılı Liste Nedir? [Bölüm 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































