Data Engineering leicht gemacht – Angehängte Python-Skripte, um Ihre ETL-Aufgaben voranzutreiben
Überblick:
Übernehmen Sie die Aufgabe eines Dateningenieurs, extrahieren Sie Daten aus mehreren Quellen von Dateiformaten, wandeln Sie sie in bestimmte Datentypen um und laden Sie sie zur Analyse in eine einzige Quelle. Bald nach der Lektüre dieses Artikels können Sie anhand mehrerer praktischer Beispiele Ihre Fähigkeiten unter Beweis stellen, indem Sie Web Scraping implementieren und Daten mit APIs extrahieren. Mit Python und Data Engineering können Sie damit beginnen, riesige Datensätze aus vielen Quellen zu sammeln und sie in eine einzige Primärquelle umzuwandeln oder mit Web Scraping für nützliche Geschäftseinblicke zu beginnen.

Zusammenfassung:
- Warum Data Engineering zuverlässiger ist
- Ablauf des ETL-Zyklus
- Schritt für Schritt Extrahieren, Transformieren, die Ladefunktion
- Über Datentechnik
- Fazit
Es ist ein zuverlässigerer und am schnellsten wachsender Tech-Beruf in der aktuellen Generation, da er sich mehr auf Web Scraping und Crawling von Datensätzen konzentriert.
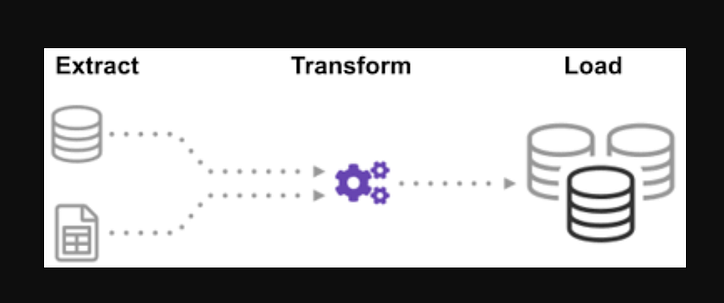
Prozess (ETL-Zyklus):
Haben Sie sich jemals gefragt, wie Daten aus vielen Quellen integriert wurden, um eine einzige Informationsquelle zu schaffen? Die Batch-Verarbeitung ist eine Art Datenerfassung. Erfahren Sie mehr darüber, „wie man eine Art von Batch-Verarbeitung untersucht“, die als Extrahieren, Transformieren und Laden bezeichnet wird.

ETL ist der Prozess, riesige Datenmengen aus einer Vielzahl von Quellen und Formaten zu extrahieren und sie in ein einziges Format zu konvertieren, bevor sie in eine Datenbank oder Zieldatei übertragen werden.
Einige Ihrer Daten werden in CSV-Dateien gespeichert, während andere in JSON-Dateien gespeichert werden. Sie müssen alle diese Informationen in einer einzigen Datei sammeln, damit die KI sie lesen kann. Da Ihre Daten in imperialen Einheiten vorliegen, die KI jedoch metrische Einheiten benötigt, müssen Sie sie konvertieren. Da die KI nur CSV-Daten in einer einzigen großen Datei lesen kann, müssen Sie diese zuerst laden. Wenn die Daten im CSV-Format vorliegen, fügen wir die folgende ETL mit Python ein und sehen uns den Extraktionsschritt mit einigen einfachen Beispielen an.
Indem Sie sich die Liste der.json- und.csv-Dateien ansehen. Der Glob-Dateierweiterung wird in der Eingabe ein Stern und ein Punkt vorangestellt. Eine Liste von CSV-Dateien wird zurückgegeben. Für.json-Dateien können wir dasselbe tun. Wir können eine Datei erstellen, die Namen, Größen und Gewichte im CSV-Format extrahiert. Der Dateiname der CSV-Datei ist die Eingabe, und die Ausgabe ist ein Datenrahmen. Für JSON-Formate können wir dasselbe tun.
Schritt 1:
Importieren Sie die Funktionen und erforderlichen Module
import glob
import pandas as pd
import xml.etree.ElementTree as ET
from datetime import datetime
Die Dateien dealership_dataenthalten CSV-, JSON- und XML-Dateien für Gebrauchtwagendaten, die Merkmale mit den Namen car_model, year_of_manufacture, priceund enthalten fuel. Wir werden also die Datei aus den Rohdaten extrahieren und in eine Zieldatei umwandeln und in die Ausgabe laden.
Legen Sie den Pfad für die Zieldateien fest:
tmpfile = "dealership_temp.tmp" # store all extracted data
logfile = "dealership_logfile.txt" # all event logs will be stored
targetfile = "dealership_transformed_data.csv" # transformed data is stored
Die Funktion extrahiert große Datenmengen aus mehreren Quellen in Stapeln. Durch Hinzufügen dieser Funktion werden nun alle CSV-Dateinamen erkannt und geladen, und die CSV-Dateien werden bei jeder Iteration der Schleife zum Datumsrahmen hinzugefügt, wobei die erste Iteration zuerst angehängt wird, gefolgt von der zweiten Iteration in einer Liste extrahierter Daten. Nachdem wir die Daten gesammelt haben, fahren wir mit dem Schritt „Transformieren“ des Prozesses fort.
Hinweis: Wenn „Index ignorieren“ auf „true“ gesetzt ist, entspricht die Reihenfolge jeder Zeile der Reihenfolge, in der die Zeilen an den Datenrahmen angehängt wurden.
CSV-Extraktionsfunktion
def extract_from_csv(file_to_process):
dataframe = pd.read_csv(file_to_process)
return dataframe
def extract_from_json(file_to_process):
dataframe = pd.read_json(file_to_process,lines=True)
return dataframe
def extract_from_xml(file_to_process):
dataframe = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
tree = ET.parse(file_to_process)
root = tree.getroot()
for person in root:
car_model = person.find("car_model").text
year_of_manufacture = int(person.find("year_of_manufacture").text)
price = float(person.find("price").text)
fuel = person.find("fuel").text
dataframe = dataframe.append({"car_model":car_model, "year_of_manufacture":year_of_manufacture, "price":price, "fuel":fuel}, ignore_index=True)
return dataframe
Rufen Sie nun die Extraktionsfunktion mit ihrem Funktionsaufruf für CSV , JSON , XML auf.
def extract():
extracted_data = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
#for csv files
for csvfile in glob.glob("dealership_data/*.csv"):
extracted_data = extracted_data.append(extract_from_csv(csvfile), ignore_index=True)
#for json files
for jsonfile in glob.glob("dealership_data/*.json"):
extracted_data = extracted_data.append(extract_from_json(jsonfile), ignore_index=True)
#for xml files
for xmlfile in glob.glob("dealership_data/*.xml"):
extracted_data = extracted_data.append(extract_from_xml(xmlfile), ignore_index=True)
return extracted_data
Nachdem wir die Daten gesammelt haben, fahren wir mit der „Transform“-Phase des Prozesses fort. Diese Funktion konvertiert die Spaltenhöhe, die in Zoll angegeben ist, in Millimeter und die Spalte in Pfund, die in Pfund angegeben ist, in Kilogramm und gibt die Ergebnisse in den variablen Daten zurück. Im Eingabedatenrahmen wird die Spaltenhöhe in Fuß angegeben. Konvertieren Sie die Spalte, um sie in Meter umzurechnen, und runden Sie sie auf zwei Dezimalstellen.
def transform(data):
data['price'] = round(data.price, 2)
return data
Es ist an der Zeit, die Daten in die Zieldatei zu laden, nachdem wir sie gesammelt und spezifiziert haben. Wir speichern den Pandas-Datenrahmen in diesem Szenario als CSV. Wir haben jetzt die Schritte zum Extrahieren, Transformieren und Laden von Daten aus verschiedenen Quellen in eine einzige Zieldatei durchlaufen. Wir müssen einen Protokolleintrag erstellen, bevor wir unsere Arbeit beenden können. Wir erreichen dies, indem wir eine Logging-Funktion schreiben.
Ladefunktion:
def load(targetfile,data_to_load):
data_to_load.to_csv(targetfile)
Alle geschriebenen Daten werden an die aktuellen Informationen angehängt, wenn das „a“ hinzugefügt wird. Wir können dann jeder Phase des Prozesses einen Zeitstempel hinzufügen, der angibt, wann er beginnt und wann er endet, indem wir diese Art von Eintrag generieren. Nachdem wir den gesamten Code definiert haben, der zum Ausführen des ETL-Prozesses für die Daten erforderlich ist, besteht der letzte Schritt darin, alle Funktionen aufzurufen.
def log(message):
timestamp_format = '%H:%M:%S-%h-%d-%Y'
#Hour-Minute-Second-MonthName-Day-Year
now = datetime.now() # get current timestamp
timestamp = now.strftime(timestamp_format)
with open("dealership_logfile.txt","a") as f: f.write(timestamp + ',' + message + 'n')
Wir beginnen zunächst mit dem Aufruf der Funktion extract_data. Die aus diesem Schritt erhaltenen Daten werden dann zum zweiten Schritt der Transformation der Daten übertragen. Nachdem dies abgeschlossen ist, werden die Daten dann in die Zieldatei geladen. Beachten Sie auch, dass vor und nach jedem Schritt die Uhrzeit und das Datum für Beginn und Abschluss hinzugefügt wurden.
Das Protokoll, dass Sie den ETL-Prozess gestartet haben:
log("ETL Job Started")
log("Extract phase Started")
extracted_data = extract()
log("Extract phase Ended")
log („Transformationsphase gestartet“)
transformierte_Daten = transformieren (extrahierte_Daten)
log("Transform phase Ended")
log("Load phase Started")
load(targetfile,transformed_data)
log("Load phase Ended")
log("ETL Job Ended")
- So schreiben Sie eine einfache Extract-Funktion.
- Wie schreibe ich eine einfache Transformationsfunktion?
- Wie man eine einfache Ladefunktion schreibt.
- Wie schreibt man eine einfache Logging-Funktion.
Wir haben höchstens alle ETL-Prozesse besprochen. Sehen wir uns außerdem an: "Was sind die Vorteile des Jobs als Dateningenieur?".
Über Data Engineering:
Data Engineering ist ein weites Feld mit vielen Namen. In vielen Institutionen hat es möglicherweise nicht einmal einen offiziellen Titel. Daher ist es im Allgemeinen besser, zunächst die Ziele der Data-Engineering-Arbeit zu definieren, die zu den erwarteten Ergebnissen führen. Die Benutzer, die sich auf Data Engineers verlassen, sind so vielfältig wie die Talente und Ergebnisse der Data-Engineering-Teams. Ihre Verbraucher werden immer bestimmen, welche Probleme Sie behandeln und wie Sie sie lösen, unabhängig davon, in welcher Branche Sie tätig sind.
Fazit:
Ich hoffe, Sie finden in diesem Artikel etwas Hilfe und gewinnen ein gewisses Verständnis für die Verwendung von Python für ETL, wenn Sie Ihre Reise zum Erlernen von Data Engineering beginnen. Möchten Sie mehr erfahren? Ich ermutige Sie, meine anderen Artikel zu lesen, wie Sie Python-Klassen verwenden können, um Data-Engineering-Prozesse zu verbessern . Ich zeige auch, wie Sie pydantic verwenden , um Ihre Datenvalidierung in einem der ersten und wichtigsten Schritte Ihrer Datenpipeline zu verbessern. Wenn Sie an Datenvisualisierung interessiert sind, sehen Sie sich diese Schritt-für-Schritt-Anleitung zum Erstellen Ihres ersten Diagramms mit Apache Superset an .
Aufruf zum Handeln
Wenn Sie den Leitfaden hilfreich finden, können Sie gerne klatschen und mir folgen. Melden Sie sich über diesen Link bei Medium an, um auf alle Premium-Artikel von mir und allen anderen großartigen Autoren hier auf Medium zuzugreifen.
Level-Up-Codierung
Danke, dass Sie ein Teil unserer Community sind! Bevor du gehst:
- Klatsche für die Geschichte und folge dem Autor
- Sehen Sie sich weitere Inhalte in der Level Up Coding-Publikation an
- Folge uns: Twitter | LinkedIn | Newsletter

![Was ist überhaupt eine verknüpfte Liste? [Teil 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































