Nutzen Sie die Multi-Core-Leistung mit Asyncio in Python

Dies ist einer meiner Artikel in der Spalte „Python-Parallelität“ , und wenn Sie ihn nützlich finden, können Sie den Rest hier lesen .
Einführung
In diesem Artikel zeige ich Ihnen, wie Sie Python-Asyncio-Code auf einer Multi-Core-CPU ausführen, um die volle Leistung gleichzeitiger Aufgaben freizuschalten.
Was ist unser Problem?
Asyncio verwendet nur einen Kern.
In früheren Artikeln habe ich die Mechanismen der Verwendung von Python Asyncio ausführlich behandelt. Mit diesem Wissen können Sie lernen, dass Asyncio die Ausführung von IO-gebundenen Aufgaben mit hoher Geschwindigkeit ermöglicht, indem die Aufgabenausführung manuell umgeschaltet wird, um den GIL-Konkurrenzprozess während des Multithread-Aufgabenwechsels zu umgehen.
Theoretisch hängt die Ausführungszeit von IO-gebundenen Aufgaben von der Zeit von der Initiierung bis zur Reaktion eines IO-Vorgangs ab und ist nicht von Ihrer CPU-Leistung abhängig. So können wir Zehntausende IO-Aufgaben gleichzeitig initiieren und schnell abschließen.
Aber vor kurzem habe ich ein Programm geschrieben, das Zehntausende Webseiten gleichzeitig crawlen musste, und stellte fest, dass mein Asyncio-Programm zwar viel effizienter war als Programme, die iteratives Crawlen von Webseiten verwenden, mich aber dennoch lange warten ließ. Soll ich die volle Leistung meines Computers nutzen? Also habe ich den Task-Manager geöffnet und Folgendes überprüft:
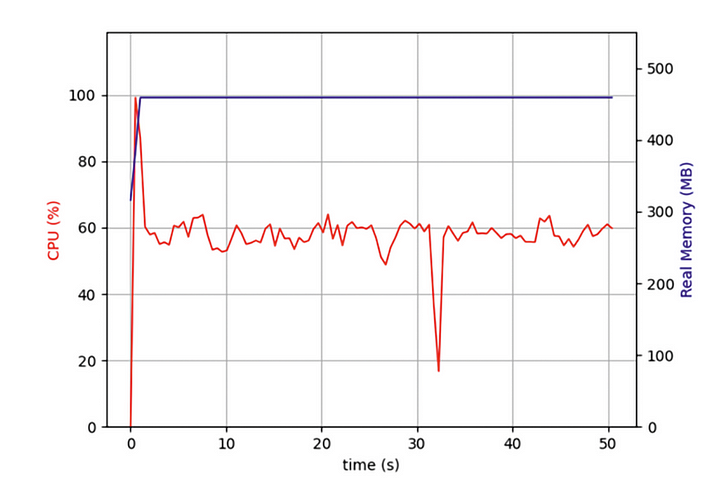
Ich stellte fest, dass mein Code von Anfang an nur auf einem CPU-Kern lief und mehrere andere Kerne im Leerlauf waren. Zusätzlich zum Starten von E/A-Vorgängen zum Erfassen von Netzwerkdaten muss eine Aufgabe die Daten nach ihrer Rückkehr entpacken und formatieren. Obwohl dieser Teil des Vorgangs nicht viel CPU-Leistung beansprucht, wirken sich diese CPU-gebundenen Vorgänge nach mehreren Aufgaben erheblich auf die Gesamtleistung aus.
Ich wollte, dass meine asynchronen gleichzeitigen Aufgaben auf mehreren Kernen parallel ausgeführt werden. Würde das die Leistung meines Computers beeinträchtigen?
Die zugrunde liegenden Prinzipien von Asyncio
Um dieses Rätsel zu lösen, müssen wir mit der zugrunde liegenden Asyncio-Implementierung beginnen, der Ereignisschleife.

Wie in der Abbildung gezeigt, beginnt die Leistungsverbesserung von Asyncio für Programme bei E/A-intensiven Aufgaben. Zu den IO-intensiven Aufgaben gehören HTTP-Anfragen, das Lesen und Schreiben von Dateien, der Zugriff auf Datenbanken usw. Das wichtigste Merkmal dieser Aufgaben ist, dass die CPU nicht blockiert und viel Zeit mit der Berechnung verbringt, während sie auf die Rückgabe externer Daten wartet unterscheidet sich stark von einer anderen Klasse synchroner Aufgaben, bei denen die CPU ständig ausgelastet sein muss, um ein bestimmtes Ergebnis zu berechnen.
Wenn wir einen Stapel asynchroner Aufgaben generieren, stellt der Code diese Aufgaben zunächst in eine Warteschlange. Zu diesem Zeitpunkt gibt es einen Thread namens „Ereignisschleife“, der jeweils eine Aufgabe aus der Warteschlange entnimmt und ausführt. Wenn die Aufgabe die Wait-Anweisung erreicht und wartet (normalerweise auf die Rückgabe einer Anfrage), greift die Ereignisschleife auf eine andere Aufgabe aus der Warteschlange und führt sie aus. Bis die zuvor wartende Aufgabe über einen Rückruf Daten erhält, kehrt die Ereignisschleife zur vorherigen wartenden Aufgabe zurück und beendet die Ausführung des restlichen Codes.
Da der Ereignisschleifen-Thread nur auf einem Kern ausgeführt wird, blockiert die Ereignisschleife, wenn der „Rest des Codes“ zufällig CPU-Zeit beansprucht. Wenn die Anzahl der Aufgaben in dieser Kategorie groß ist, summiert sich jedes kleine Blockierungssegment und verlangsamt das Programm als Ganzes.
Was ist meine Lösung?
Daraus wissen wir, dass Asyncio-Programme langsamer werden, weil unser Python-Code die Ereignisschleife nur auf einem Kern ausführt und die Verarbeitung von IO-Daten dazu führt, dass das Programm langsamer wird. Gibt es eine Möglichkeit, auf jedem CPU-Kern eine Ereignisschleife zu starten, um sie auszuführen?
Wie wir alle wissen, wird ab Python 3.7 empfohlen, den gesamten Asyncio-Code mit der Methode auszuführen asyncio.run, einer Abstraktion auf hoher Ebene, die die Ereignisschleife aufruft, um den Code als Alternative zum folgenden Code auszuführen:
try:
loop = asyncio.get_event_loop()
loop.run_until_complete(task())
finally:
loop.close()
Im vorherigen Artikel wurde anhand eines Beispiels aus der Praxis erläutert, wie die loop.run_in_executorMethode von Asyncio verwendet wird, um die Ausführung von Code in einem Prozesspool zu parallelisieren und gleichzeitig die Ergebnisse jedes untergeordneten Prozesses vom Hauptprozess abzurufen. Wenn Sie den vorherigen Artikel nicht gelesen haben, können Sie ihn hier nachlesen:
So entsteht unsere Lösung: Verteilen Sie viele gleichzeitige Aufgaben mithilfe der Multi-Core-Ausführung über die Methode auf mehrere Unterprozesse loop.run_in_executorund rufen Sie dann asyncio.runjeden Unterprozess auf, um die entsprechende Ereignisschleife zu starten und den gleichzeitigen Code auszuführen. Das folgende Diagramm zeigt den gesamten Ablauf:
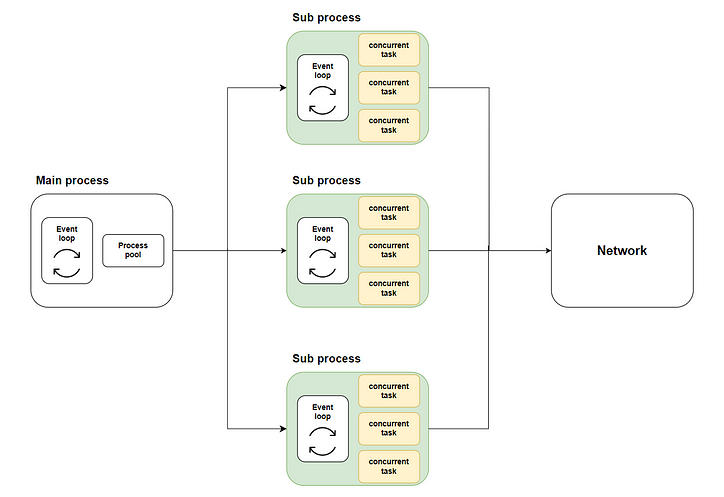
Wobei der grüne Teil die von uns gestarteten Teilprozesse darstellt. Der gelbe Teil stellt die gleichzeitigen Aufgaben dar, die wir gestartet haben.
Vorbereitung vor dem Start
Simulation der Aufgabenumsetzung
Bevor wir das Problem lösen können, müssen wir uns vorbereiten, bevor wir beginnen. In diesem Beispiel können wir keinen tatsächlichen Code zum Crawlen des Webinhalts schreiben, da dies für die Zielwebsite sehr ärgerlich wäre. Daher simulieren wir unsere eigentliche Aufgabe mit Code:
Wie der Code zeigt, verwenden wir zunächst asyncio.sleepdie Simulation der Rückgabe der E/A-Aufgabe in zufälliger Zeit und eine iterative Summierung, um die CPU-Verarbeitung nach der Rückgabe der Daten zu simulieren.
Die Wirkung von traditionellem Code
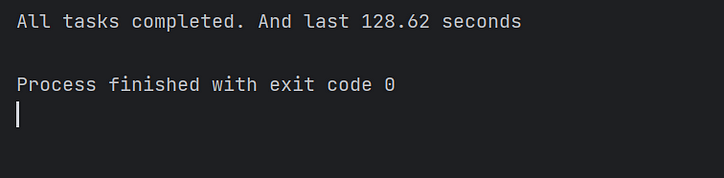
Als Nächstes verfolgen wir den traditionellen Ansatz, 10.000 gleichzeitige Aufgaben in einer Hauptmethode zu starten, und beobachten die Zeit, die dieser Stapel gleichzeitiger Aufgaben verbraucht:
Wie die Abbildung zeigt, dauert die Ausführung der Asyncio-Aufgaben mit nur einem Kern länger.
Die Code-Implementierung
Als Nächstes implementieren wir den Multi-Core-Asyncio-Code gemäß dem Flussdiagramm und prüfen, ob sich die Leistung verbessert.
Entwerfen der Gesamtstruktur des Codes
Als Architekt müssen wir zunächst noch die gesamte Skriptstruktur definieren, welche Methoden erforderlich sind und welche Aufgaben jede Methode erfüllen muss:
Die spezifische Implementierung jeder Methode
Lassen Sie uns dann jede Methode Schritt für Schritt implementieren.
Die query_concurrentlyMethode startet den angegebenen Aufgabenstapel gleichzeitig und ruft die Ergebnisse über die asyncio.gatherMethode ab:
Die run_batch_tasksMethode ist keine asynchrone Methode, da sie direkt im untergeordneten Prozess gestartet wird:
Schließlich gibt es noch unsere mainMethode. Diese Methode ruft die loop.run_in_executorMethode auf, damit sie run_batch_tasksim Prozesspool ausgeführt wird und die Ergebnisse der Ausführung des untergeordneten Prozesses in einer Liste zusammengeführt werden:
Da wir ein Multiprozess-Skript schreiben, müssen wir if __name__ == “__main__”zum Starten der Hauptmethode im Hauptprozess Folgendes verwenden:
Führen Sie den Code aus und sehen Sie sich die Ergebnisse an
Als nächstes starten wir das Skript und schauen uns im Task-Manager die Auslastung jedes Kerns an:
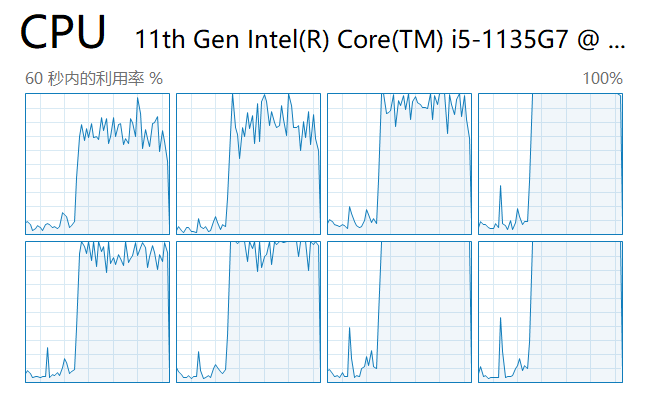
Wie Sie sehen, werden alle CPU-Kerne ausgelastet.
Abschließend beobachten wir die Codeausführungszeit und bestätigen, dass der Multithread-Asyncio-Code die Codeausführung tatsächlich um ein Vielfaches beschleunigt! Mission erfüllt!

Abschluss
In diesem Artikel habe ich erklärt, warum Asyncio E/A-intensive Aufgaben gleichzeitig ausführen kann, bei der Ausführung großer Stapel gleichzeitiger Aufgaben jedoch immer noch länger dauert als erwartet.
Dies liegt daran, dass im herkömmlichen Implementierungsschema von Asyncio-Code die Ereignisschleife nur Aufgaben auf einem Kern ausführen kann und sich die anderen Kerne im Ruhezustand befinden.
Deshalb habe ich für Sie eine Lösung implementiert, mit der Sie jede Ereignisschleife auf mehreren Kernen separat aufrufen können, um gleichzeitige Aufgaben parallel auszuführen. Und schließlich wurde die Leistung des Codes erheblich verbessert.
Aufgrund meiner eingeschränkten Fähigkeiten weist die Lösung in diesem Artikel zwangsläufig Mängel auf. Ich freue mich über Ihre Kommentare und Diskussionen. Ich werde aktiv für Sie antworten.

![Was ist überhaupt eine verknüpfte Liste? [Teil 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































