Mengapa Membayar Lebih untuk Pembelajaran Mesin?

Percepat Beban Kerja Pembelajaran Anda yang Tidak Seimbang dengan Ekstensi Intel untuk Scikit-learn
Ethan Glaser, Nikolay Petrov, Henry Gabb, dan Jui Mhatre, Intel Corporation
Blog NVIDIA baru-baru ini menarik perhatian kami dengan hasil yang menyesatkan . Apa gunanya membandingkan GPU A100 dengan CPU berusia sembilan tahun (Intel Xeon E5–2698 diluncurkan pada tahun 2014 dan sejak itu dihentikan) atau membandingkan kode CUDA yang dioptimalkan (perpustakaan RAPIDS cuML) dengan yang tidak dioptimalkan, single-threaded Kode python (stock scikit-learn dengan perpustakaan balanced-learn ) kecuali jika Anda sengaja mencoba meningkatkan kecepatan GPU vs. CPU? Perpustakaan balanced-learn mendukung estimator yang kompatibel dengan scikit-learn, jadi mereka menggunakan estimator cuML untuk akselerasi. Kita dapat menggunakan estimator yang dioptimalkan di Intel Extension untuk Scikit-learn hanya dengan menambahkan panggilan ke patch_sklearn():
from sklearnex import patch_sklearn
patch_sklearn()
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.neighbors import NearestNeighbors
...
nn = NearestNeighbors(n_neighbors=4, n_jobs=-1)
X_resampled, y_resampled = EditedNearestNeighbours(n_neighbors=nn).fit_resample(X, y)

Perbandingan Kinerja
Ekstensi Intel untuk Scikit-learn memberikan percepatan secara menyeluruh untuk tolok ukur yang sama seperti Nvidia (Gambar 1). Percepatan berkisar dari ~2x hingga ~140x tergantung pada algoritme dan parameter. Perhatikan bahwa pustaka scikit-learn stok kehabisan memori untuk benchmark SMOTE dan ADASYN “100 fitur, 5 kelas”. Jika performa penting, hasil ini menunjukkan bahwa Intel Extension for Scikit-learn memberikan peningkatan yang signifikan dibandingkan scikit-learn stok.

Bagaimana ini dibandingkan dengan hasil A100 Nvidia? Mari kita lihat dua algoritme di mana Nvidia mencapai percepatan tertinggi melalui scikit-learn: SVMSMOTE dan CondensedNearestNeighbours (Gambar 2). Hasil ini menunjukkan bahwa kinerja kami sama besarnya dengan cuML ketika prosesor yang lebih baru dan scikit-learn yang dioptimalkan digunakan untuk perbandingan. Intel Extension for Scikit-learn bahkan mengungguli cuML dalam beberapa pengujian. Sekarang, mari kita bicara tentang harga.


Perbandingan Biaya
Perlu diperhatikan bahwa biaya per jam untuk instans a2-highgpu-1g A100 di GCP adalah 60% lebih tinggi daripada instans n2-highcpu-64 (Tabel 1). Itu berarti instans A100 harus memberikan kecepatan minimal 1,6x dibandingkan instans Xeon Gold 6268CL (n2-highcpu-64) agar hemat biaya. (A100 juga mengonsumsi daya 1,7x dan 1,2x lebih banyak daripada Xeon E5–2696 v4 dan Xeon Gold 6268CL, tetapi kami akan mengesampingkannya untuk saat ini karena konsumsi daya dimasukkan ke dalam biaya instans.)
Mari bandingkan rasio harga terhadap kinerja untuk tolok ukur yang dipilih oleh Nvidia untuk melihat apakah instans A100 membenarkan harga premiumnya. Total biaya (USD) dari proses benchmark hanyalah biaya instans per jam (USD/jam) dikalikan waktu proses (jam). Perbandingan biaya yang mendetail menunjukkan bahwa menjalankan tolok ukur ini pada instans Xeon seringkali merupakan opsi yang lebih hemat biaya (Gambar 3). Pada bagan di bawah, nilai yang lebih besar dari satu menunjukkan bahwa tolok ukur yang diberikan lebih mahal pada instans A100. Misalnya, nilai 1,29 berarti instans A100 29% lebih mahal daripada instans Xeon.



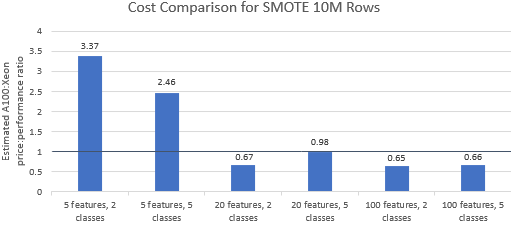
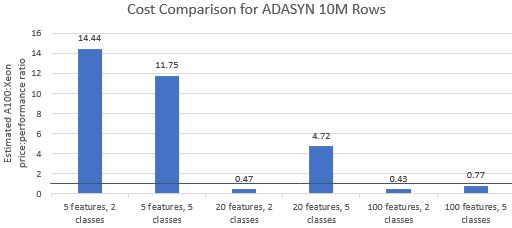
Biaya tolok ukur bervariasi tergantung pada algoritme dan parameter yang digunakan, tetapi hasilnya umumnya mendukung contoh Xeon: rata-rata geometrik biaya lebih besar dari satu untuk empat dari lima algoritme dan rata-rata geometrik keseluruhan adalah 1,36 (Tabel 2).

Selain itu, CPU menawarkan lebih banyak fleksibilitas dalam pemilihan instans, yang selanjutnya meningkatkan efisiensi. Lebih hemat biaya untuk memilih instans Xeon dengan kemampuan terkecil yang dapat menangani ukuran masalah tertentu sekaligus memenuhi persyaratan kinerja dan batasan anggaran. Gambar 4 menunjukkan salah satu contoh untuk dua tolok ukur terkecil. Hasil ini menunjukkan bahwa dapat jauh lebih murah untuk dijalankan pada perangkat keras yang paling sesuai dengan kebutuhan konfigurasi model. Misalnya, menjalankan dua tolok ukur ADASYN dengan Intel Extension untuk Scikit-learn pada instans e2-highcpu-8 hanya 1,5% dan 2,1% biaya menjalankan cuML pada instans A100.

Kesimpulan
Hasil di atas menunjukkan bahwa Intel Extension for Scikit-learn mampu secara dramatis meningkatkan hasil kinerja dibandingkan dengan scikit-learn stok dan juga mampu mengungguli A100 dalam beberapa pengujian. Ketika mempertimbangkan biaya, hasil Intel Extension for Scikit-learn bahkan lebih disukai karena instans Xeon jauh lebih murah daripada instans A100. Pengguna dapat memilih instans Xeon yang memenuhi persyaratan kinerja, daya, dan harga.

![Apa itu Linked List? [Bagian 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































