Python の Asyncio を使用してマルチコアのパワーを活用する

これは、「Python 同時実行性」コラムにある私の記事の 1 つです。役立つと思われる場合は、ここから残りを読むことができます。
序章
この記事では、マルチコア CPU で Python asyncio コードを実行して、同時タスクのパフォーマンスを最大限に引き出す方法を説明します。
私たちの問題は何でしょうか?
asyncio は 1 つのコアのみを使用します。
以前の記事では、Python asyncio の使用メカニズムについて詳しく説明しました。この知識があれば、asyncio を使用すると、マルチスレッド タスクの切り替え中にタスクの実行を手動で切り替えて GIL 競合プロセスをバイパスし、IO バウンド タスクを高速で実行できることがわかります。
理論的には、IO バインド タスクの実行時間は、IO 操作の開始から応答までの時間に依存し、CPU のパフォーマンスには依存しません。したがって、何万もの IO タスクを同時に開始し、それらを迅速に完了できます。
しかし最近、数万の Web ページを同時にクロールする必要があるプログラムを作成していたところ、asyncio プログラムは Web ページの反復クロールを使用するプログラムよりもはるかに効率的であるにもかかわらず、それでも長時間待たされることがわかりました。コンピューターのパフォーマンスを最大限に活用する必要がありますか? そこで、タスクマネージャーを開いて次のことを確認しました。
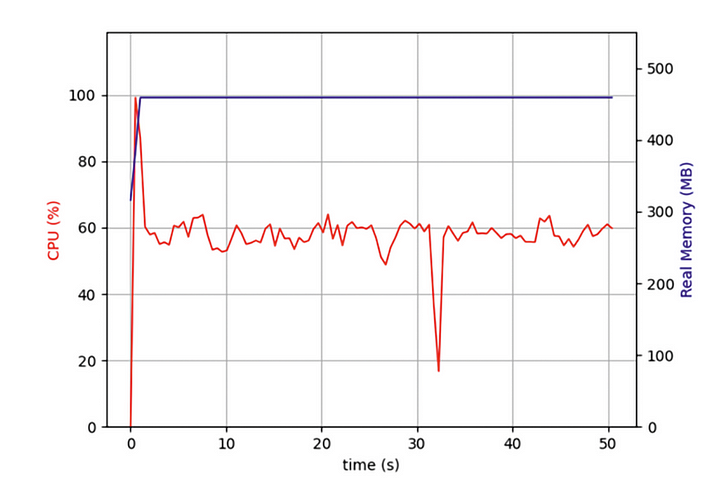
最初から、コードは 1 つの CPU コアのみで実行されており、他のいくつかのコアがアイドル状態であることがわかりました。タスクは、ネットワーク データを取得するための IO 操作を開始することに加えて、データが返された後にデータを解凍してフォーマットする必要があります。操作のこの部分では CPU パフォーマンスはあまり消費されませんが、タスクが増えた後は、これらの CPU バウンド操作が全体のパフォーマンスに重大な影響を与えます。
asyncio 同時タスクを複数のコアで並行して実行したいと考えていました。それによってコンピューターのパフォーマンスが圧迫されてしまうでしょうか?
asyncio の基本原則
このパズルを解決するには、基礎となる asyncio 実装であるイベント ループから始める必要があります。

図に示すように、asyncio によるプログラムのパフォーマンス向上は、IO 集中型のタスクから始まります。IO 集中型のタスクには、HTTP リクエスト、ファイルの読み書き、データベースへのアクセスなどが含まれます。これらのタスクの最も重要な特徴は、CPU がブロックされず、外部データが返されるのを待機している間、計算に多くの時間を費やすことです。これは、特定の結果を計算するために CPU を常に占有する必要がある別のクラスの同期タスクとは大きく異なります。
asyncio タスクのバッチを生成すると、コードはまずこれらのタスクをキューに入れます。この時点で、イベント ループと呼ばれるスレッドがあり、キューから一度に 1 つのタスクを取得して実行します。タスクが await ステートメントに到達して待機すると (通常はリクエストが返されるのを待ちます)、イベント ループはキューから別のタスクを取得して実行します。前に待機していたタスクがコールバックを通じてデータを取得するまで、イベント ループは前の待機タスクに戻り、残りのコードの実行を終了します。
イベント ループ スレッドは 1 つのコア上でのみ実行されるため、「コードの残りの部分」が CPU 時間を占有すると、イベント ループはブロックされます。このカテゴリのタスクの数が多い場合、小さなブロッキング セグメントがそれぞれ積み重なり、プログラム全体の速度が低下します。
私の解決策は何ですか?
このことから、Python コードが 1 つのコアのみでイベント ループを実行し、IO データの処理によってプログラムの速度が低下するため、asyncio プログラムの速度が低下することがわかります。各 CPU コアでイベント ループを開始して実行する方法はありますか?
ご存知のとおり、Python 3.7 以降では、すべての asyncio コードはメソッド を使用して実行することが推奨されます。asyncio.runこれは、次のコードの代わりにイベント ループを呼び出してコードを実行する高レベルの抽象化です。
try:
loop = asyncio.get_event_loop()
loop.run_until_complete(task())
finally:
loop.close()
前回の記事では、実際の例を使用して、asyncio のメソッドを使用してloop.run_in_executorプロセス プール内のコードの実行を並列化し、同時にメイン プロセスから各子プロセスの結果を取得する方法を説明しました。前回の記事をまだ読んでいない場合は、ここから確認できます。
したがって、私たちの解決策は次のとおりです。メソッドを介してマルチコア実行を使用して、多くの同時タスクを複数のサブプロセスに分散しloop.run_in_executor、asyncio.run各サブプロセスを呼び出してそれぞれのイベント ループを開始し、同時コードを実行します。次の図は全体の流れを示しています。
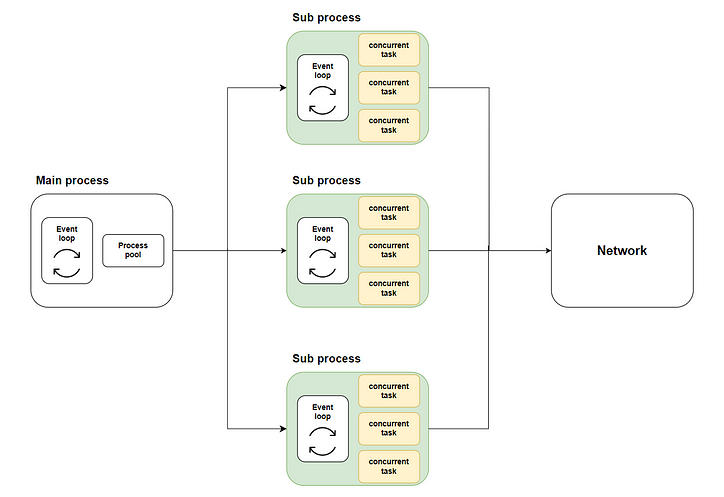
緑色の部分は、開始したサブプロセスを表します。黄色の部分は、開始した同時タスクを表します。
始める前の準備
タスク実装のシミュレーション
問題を解決するには、始める前に準備をする必要があります。この例では、ターゲット Web サイトにとって非常に煩わしいため、Web コンテンツをクロールする実際のコードを記述することはできません。そのため、コードを使用して実際のタスクをシミュレートします。
コードが示すように、最初にasyncio.sleepランダムな時間で IO タスクの戻りをシミュレートするために使用し、データが返された後の CPU 処理をシミュレートするために反復合計を使用します。
従来のコードの効果
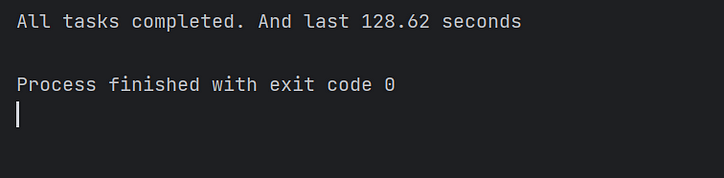
次に、メイン メソッドで 10,000 の同時タスクを開始する従来のアプローチを採用し、この同時タスクのバッチによって消費される時間を監視します。
図が示すように、1 つのコアのみで asyncio タスクを実行すると、より長い時間がかかります。
コードの実装
次に、フローチャートに従ってマルチコア asyncio コードを実装し、パフォーマンスが向上するかどうかを確認してみましょう。
コード全体の構造を設計する
まず、アーキテクトとして、スクリプト全体の構造、必要なメソッド、および各メソッドが実行する必要があるタスクを定義する必要があります。
各メソッドの具体的な実装
次に、各メソッドを段階的に実装してみましょう。
このquery_concurrentlyメソッドは、指定されたタスクのバッチを同時に開始し、メソッド経由で結果を取得しますasyncio.gather。
このrun_batch_tasksメソッドは子プロセスで直接開始されるため、非同期メソッドではありません。
最後に、私たちの方法ですmain。loop.run_in_executorこのメソッドは、メソッドを呼び出してrun_batch_tasksプロセス プール内でメソッドを実行し、子プロセスの実行結果をリストにマージします。
マルチプロセス スクリプトを作成しているため、if __name__ == “__main__”メイン プロセスで main メソッドを開始するために を使用する必要があります。
コードを実行して結果を確認する
次に、スクリプトを開始し、タスク マネージャーで各コアの負荷を確認します。
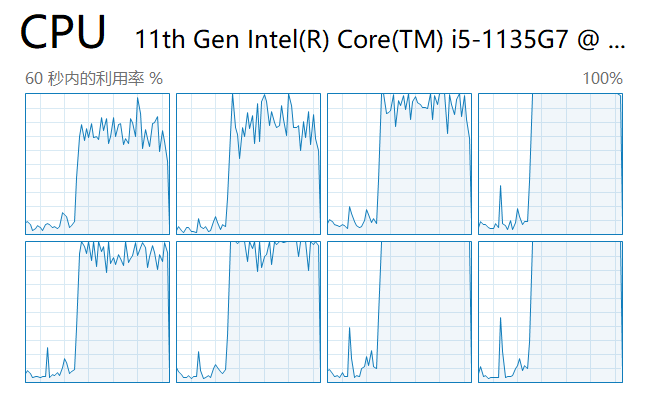
ご覧のとおり、すべての CPU コアが使用されています。
最後に、コードの実行時間を観察し、マルチスレッドの asyncio コードによって実際にコードの実行が数倍高速化されることを確認しました。任務完了!

結論
この記事では、asyncio が IO 集中型のタスクを同時に実行できるにもかかわらず、同時タスクの大規模なバッチを実行すると予想よりも時間がかかる理由を説明しました。
これは、asyncio コードの従来の実装スキームでは、イベント ループは 1 つのコアでのみタスクを実行でき、他のコアはアイドル状態にあるためです。
そこで、複数のコアで各イベント ループを個別に呼び出して同時タスクを並行して実行するためのソリューションを実装しました。そして最後に、コードのパフォーマンスが大幅に向上しました。
私の能力には限界があるため、この記事の解決策には必然的に不完全な点が含まれます。コメントや議論を歓迎します。積極的にお答えさせていただきます。

![とにかく、リンクリストとは何ですか?[パート1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































