なぜ機械学習にもっとお金を払うのでしょうか?

Scikit-learn 用インテル拡張機能で不均衡な学習ワークロードを加速する
イーサン・グレイザー、ニコライ・ペトロフ、ヘンリー・ガブ、ジュイ・マートル、インテル コーポレーション
最近の NVIDIA ブログが、誤解を招く結果で私たちの目に留まりました。A100 GPU を 9 年前の CPU (Intel Xeon E5–2698 は 2014 年に発売され、その後製造中止されました) と比較したり、最適化された CUDA コード (RAPIDS cuML ライブラリ) と最適化されていないシングルスレッドと比較したりすることに何の意味があるのでしょうか。意図的に GPU と CPU のスピードアップを高めようとしている場合を除き、Python コード (不均衡学習ライブラリを備えた標準のscikit-learn ) を使用しますか? 不均衡学習ライブラリは scikit-learn と互換性のある推定器をサポートしているため、高速化のために cuML 推定器を使用しました。patch_sklearn() への呼び出しを追加するだけで、インテル Extension for Scikit-learnの最適化された推定器を使用できます。
from sklearnex import patch_sklearn
patch_sklearn()
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.neighbors import NearestNeighbors
...
nn = NearestNeighbors(n_neighbors=4, n_jobs=-1)
X_resampled, y_resampled = EditedNearestNeighbours(n_neighbors=nn).fit_resample(X, y)

性能比較
Intel Extension for Scikit-learn は、Nvidia と同じベンチマークで全面的に高速化を実現します (図 1)。アルゴリズムとパラメータに応じて、高速化の範囲は最大 2 倍から最大 140 倍になります。SMOTE および ADASYN の「100 機能、5 クラス」ベンチマークでは、標準の scikit-learn ライブラリがメモリ不足になったことに注意してください。パフォーマンスが重要な場合、これらの結果は、インテル Extension for Scikit-learn が標準の scikit-learn よりも大幅な高速化を実現することを示しています。

これを Nvidia の A100 の結果と比較するとどうでしょうか? Nvidia が scikit-learn よりも最高の高速化を達成した 2 つのアルゴリズム、SVMSMOTE と CondensedNearestNeighbours を見てみましょう (図 2)。これらの結果は、新しいプロセッサと最適化された scikit-learn を比較に使用した場合、パフォーマンスが cuML と同程度であることを示しています。Intel Extension for Scikit-learn は、一部のテストでは cuML を上回るパフォーマンスを発揮します。さて、価格について話しましょう。


コスト比較
GCP 上の a2-highgpu-1g A100 インスタンスの時間あたりのコストは、n2-highcpu-64 インスタンスより 60% 高いことに注意してください (表 1)。つまり、コスト競争力を発揮するには、A100 インスタンスが Xeon Gold 6268CL (n2-highcpu-64) インスタンスと比較して少なくとも 1.6 倍の高速化を実現する必要があります。(A100 は、Xeon E5–2696 v4 と Xeon Gold 6268CL よりもそれぞれ 1.7 倍と 1.2 倍多くの電力を消費しますが、電力消費はインスタンスのコストに組み込まれているため、今は脇に置きます。)
Nvidia が選択したベンチマークの価格性能比を比較して、A100 インスタンスがそのプレミアム価格に見合うかどうかを確認してみましょう。ベンチマーク実行の総コスト (USD) は、単純に 1 時間あたりのインスタンス コスト (USD/hr) に実行時間 (hr) を掛けたものです。詳細なコストを比較すると、これらのベンチマークを Xeon インスタンスで実行する方が、多くの場合、よりコスト効率の高いオプションであることがわかります (図 3)。以下のグラフで、1 より大きい値は、指定されたベンチマークが A100 インスタンスでより高価であることを示します。たとえば、値 1.29 は、A100 インスタンスが Xeon インスタンスより 29% 高価であることを意味します。



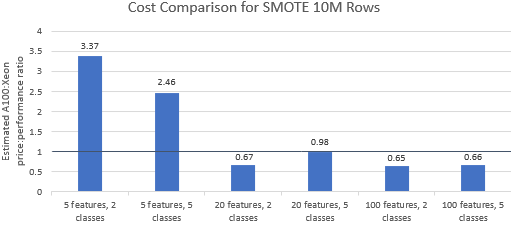
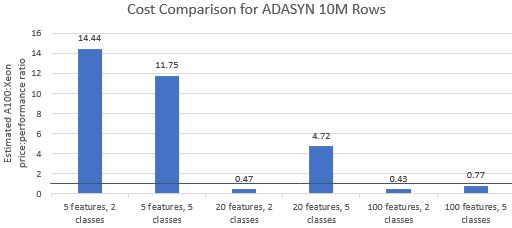
ベンチマーク コストは使用するアルゴリズムとパラメーターによって異なりますが、結果は一般に Xeon インスタンスに有利です。5 つのアルゴリズムのうち 4 つでコストの幾何平均が 1 より大きく、全体の幾何平均は 1.36 です (表 2)。

さらに、CPU によりインスタンスの選択がより柔軟になり、効率がさらに向上します。パフォーマンス要件と予算の制約を満たしながら、特定のサイズの問題を処理できる最小の対応 Xeon インスタンスを選択する方が、コスト効率が高くなります。図 4 は、2 つの最小ベンチマークの例の 1 つを示しています。これらの結果は、モデル構成のニーズに最も適合するハードウェアで実行すると大幅にコストが安くなる可能性があることを示しています。たとえば、e2-highcpu-8 インスタンスで Scikit-learn 用インテル拡張機能を使用して 2 つの ADASYN ベンチマークを実行するコストは、A100 インスタンスで cuML を実行するコストのわずか 1.5% と 2.1% です。

結論
上記の結果は、インテル Extension for Scikit-learn が標準の scikit-learn と比較してパフォーマンス結果を劇的に向上させることができ、一部のテストでは A100 を上回るパフォーマンスを発揮できることを示しています。コストを考慮すると、Xeon インスタンスは A100 インスタンスよりもはるかに安いため、Intel Extension for Scikit-learn の結果はさらに有利です。ユーザーは、パフォーマンス、電力、価格の要件を満たす Xeon インスタンスを選択できます。

![とにかく、リンクリストとは何ですか?[パート1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































