Por que pagar mais pelo aprendizado de máquina?

Acelere suas cargas de trabalho de aprendizado desequilibradas com a extensão Intel para Scikit-learn
Ethan Glaser, Nikolay Petrov, Henry Gabb e Jui Mhatre, Intel Corporation
Um recente blog da NVIDIA chamou nossa atenção com seus resultados enganosos . Qual é o sentido de comparar uma GPU A100 com uma CPU de nove anos (o Intel Xeon E5–2698 foi lançado em 2014 e desde então foi descontinuado) ou comparar o código CUDA otimizado (a biblioteca RAPIDS cuML) para não otimizado, single-threaded Código Python (estoque scikit-learn com a biblioteca de aprendizado desbalanceado ), a menos que você esteja tentando deliberadamente inflar a GPU versus a aceleração da CPU? A biblioteca de aprendizado desequilibrado oferece suporte a estimadores compatíveis com scikit-learn, então eles usaram estimadores cuML para aceleração. Podemos usar os estimadores otimizados no Intel Extension para Scikit-learn apenas adicionando uma chamada a patch_sklearn():
from sklearnex import patch_sklearn
patch_sklearn()
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.neighbors import NearestNeighbors
...
nn = NearestNeighbors(n_neighbors=4, n_jobs=-1)
X_resampled, y_resampled = EditedNearestNeighbours(n_neighbors=nn).fit_resample(X, y)

Comparação de desempenho
A extensão Intel para Scikit-learn fornece aumentos de velocidade em todos os níveis para os mesmos benchmarks da Nvidia (Figura 1). Os aumentos de velocidade variam de ~2x até ~140x, dependendo do algoritmo e dos parâmetros. Observe que a biblioteca scikit-learn padrão ficou sem memória para os benchmarks SMOTE e ADASYN “100 recursos, 5 classes”. Se o desempenho é importante, esses resultados demonstram que o Intel Extension para Scikit-learn oferece uma aceleração significativa em relação ao scikit-learn padrão.

Como isso se compara aos resultados do A100 da Nvidia? Vamos dar uma olhada nos dois algoritmos em que a Nvidia obteve os maiores aumentos de velocidade em relação ao scikit-learn: SVMSMOTE e CondensedNearestNeighbours (Figura 2). Esses resultados mostram que nosso desempenho está em uma ordem de grandeza semelhante à do cuML quando um processador mais recente e um scikit-learn otimizado são usados para comparação. O Intel Extension para Scikit-learn supera até o cuML em alguns testes. Agora, vamos falar sobre preço.


Comparação de custos
É importante observar que o custo por hora de uma instância a2-highgpu-1g A100 no GCP é 60% maior do que a instância n2-highcpu-64 (Tabela 1). Isso significa que a instância A100 deve fornecer pelo menos 1,6x de aceleração em relação à instância Xeon Gold 6268CL (n2-highcpu-64) para ter um custo competitivo. (Um A100 também consome 1,7x e 1,2x mais energia do que o Xeon E5–2696 v4 e o Xeon Gold 6268CL, respectivamente, mas deixaremos isso de lado por enquanto porque o consumo de energia é embutido no custo da instância.)
Vamos comparar as relações preço/desempenho para os benchmarks selecionados pela Nvidia para ver se a instância A100 justifica seu preço premium. O custo total (USD) de uma execução de benchmark é simplesmente o custo da instância por hora (USD/hr) vezes o tempo de execução (hr). Uma comparação detalhada de custos mostra que a execução desses benchmarks na instância Xeon geralmente é a opção mais econômica (Figura 3). Nos gráficos abaixo, um valor maior que um indica que o benchmark fornecido é mais caro na instância A100. Por exemplo, um valor de 1,29 significa que a instância A100 é 29% mais cara que a instância Xeon.



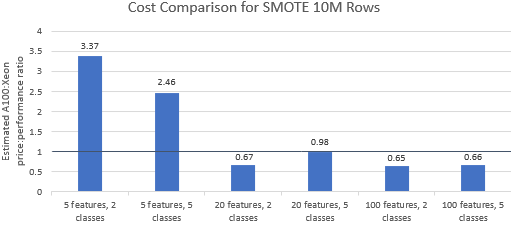
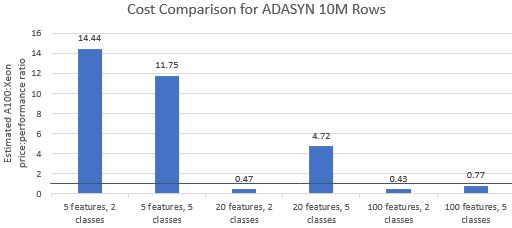
O custo do benchmark varia dependendo do algoritmo e dos parâmetros usados, mas os resultados geralmente favorecem a instância Xeon: a média geométrica do custo é maior que um para quatro dos cinco algoritmos e a média geométrica geral é 1,36 (Tabela 2).

Além disso, as CPUs oferecem mais flexibilidade na seleção de instâncias, o que melhora ainda mais a eficiência. É mais econômico selecionar a menor instância Xeon capaz que possa lidar com um determinado tamanho de problema e, ao mesmo tempo, satisfazer os requisitos de desempenho e as restrições orçamentárias. A Figura 4 mostra um desses exemplos para os dois menores benchmarks. Esses resultados demonstram que pode ser significativamente mais barato rodar no hardware que melhor atenda às necessidades da configuração do modelo. Por exemplo, executar os dois benchmarks ADASYN com Intel Extension para Scikit-learn em uma instância e2-highcpu-8 é de apenas 1,5% e 2,1% do custo de executar cuML na instância A100.

Conclusão
Os resultados acima demonstram que o Intel Extension para Scikit-learn é capaz de melhorar drasticamente os resultados de desempenho em comparação com o scikit-learn padrão e também é capaz de superar o A100 em alguns testes. Quando o custo é considerado, os resultados do Intel Extension para Scikit-learn são ainda mais favoráveis porque as instâncias Xeon são muito mais baratas do que a instância A100. Os usuários podem selecionar uma instância Xeon que atenda aos seus requisitos de desempenho, potência e preço.















































![O que é uma lista vinculada, afinal? [Parte 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)