Makine Öğrenimi İçin Neden Daha Fazla Ödeyesiniz?

Scikit-learn için Intel Uzantısı ile Dengesiz Öğrenme İş Yüklerinizi Hızlandırın
Ethan Glaser, Nikolay Petrov, Henry Gabb ve Jui Mhatre, Intel Corporation
Yakın zamanda bir NVIDIA blogu yanıltıcı sonuçlarıyla dikkatimizi çekti . Bir A100 GPU ile dokuz yıllık bir CPU'yu (Intel Xeon E5–2698 2014'te piyasaya sürüldü ve o zamandan beri kullanımdan kaldırıldı) veya optimize edilmiş CUDA kodunu (RAPIDS cuML kitaplığı) optimize edilmemiş, tek iş parçacıklı kodla karşılaştırmanın ne anlamı var? GPU'yu CPU hızına karşı kasıtlı olarak şişirmeye çalışmadığınız sürece Python kodu ( dengesiz öğrenme kitaplığıyla stok scikit-öğrenme )? Dengesiz öğrenme kitaplığı, scikit-learn uyumlu tahmin edicileri destekler, bu nedenle hızlandırma için cuML tahmin edicileri kullandılar. Scikit-learn için Intel Extension'daki optimize edilmiş tahmincileri patch_sklearn()'e bir çağrı ekleyerek kullanabiliriz :
from sklearnex import patch_sklearn
patch_sklearn()
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.neighbors import NearestNeighbors
...
nn = NearestNeighbors(n_neighbors=4, n_jobs=-1)
X_resampled, y_resampled = EditedNearestNeighbours(n_neighbors=nn).fit_resample(X, y)

Performans karşılaştırması
Scikit-learn için Intel Uzantısı, Nvidia ile aynı kriterler için kart genelinde hızlanma sağlar (Şekil 1). Hızlandırmalar, algoritmaya ve parametrelere bağlı olarak ~2x ile ~140x arasında değişir. Stok scikit-learn kitaplığının SMOTE ve ADASYN "100 özellik, 5 sınıf" kıyaslamaları için belleğinin tükendiğini unutmayın. Performans önemliyse, bu sonuçlar, Scikit-learn için Intel Uzantısının, stok scikit-learn'e göre önemli bir hızlanma sağladığını gösterir.

Bu, Nvidia'nın A100 sonuçlarıyla nasıl karşılaştırılır? Nvidia'nın scikit-learn üzerinden en yüksek hızları elde ettiği iki algoritmaya bir göz atalım: SVMSMOTE ve CondensedNearestNeighbours (Şekil 2). Bu sonuçlar, karşılaştırma için daha yeni bir işlemci ve optimize edilmiş scikit-learn kullanıldığında performansımızın cuML ile benzer büyüklükte olduğunu gösteriyor. Scikit-learn için Intel Extension, bazı testlerde cuML'den bile daha iyi performans gösteriyor. Şimdi fiyat hakkında konuşalım.


Maliyet karşılaştırması
GCP'de a2-highgpu-1g A100 bulut sunucusunun saatlik maliyetinin, n2-highcpu-64 bulut sunucusuna göre %60 daha yüksek olduğunu belirtmek gerekir (Tablo 1). Bu, A100 bulut sunucusunun maliyet açısından rekabetçi olabilmesi için Xeon Gold 6268CL (n2-highcpu-64) bulut sunucusuna göre en az 1,6 kat hız sağlaması gerektiği anlamına gelir. (A100 ayrıca Xeon E5–2696 v4 ve Xeon Gold 6268CL'den sırasıyla 1,7 kat ve 1,2 kat daha fazla güç tüketir, ancak güç tüketimi bulut sunucusu maliyetine dahil edildiğinden bunu şimdilik bir kenara bırakacağız.)
A100 bulut sunucusunun birinci sınıf fiyatını hak edip etmediğini görmek için Nvidia tarafından seçilen kıyaslamalar için fiyat-performans oranlarını karşılaştıralım . Bir kıyaslama çalışmasının toplam maliyeti (USD), çalışma süresinin (sa) çarpı saat başına bulut sunucusu maliyetinin (USD/saat) çarpımıdır. Ayrıntılı bir maliyet karşılaştırması, bu karşılaştırmalı değerlendirmeleri Xeon bulut sunucusunda çalıştırmanın genellikle daha uygun maliyetli bir seçenek olduğunu göstermektedir (Şekil 3). Aşağıdaki grafiklerde, birden büyük bir değer, verilen kıyaslamanın A100 bulut sunucusunda daha pahalı olduğunu gösterir. Örneğin 1,29 değeri, A100 bulut sunucusunun Xeon bulut sunucusundan %29 daha pahalı olduğu anlamına gelir.



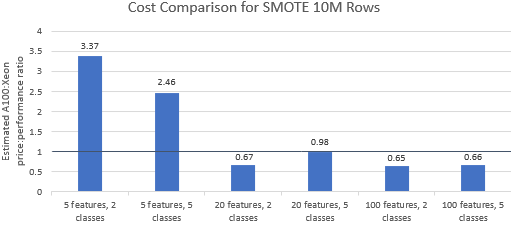
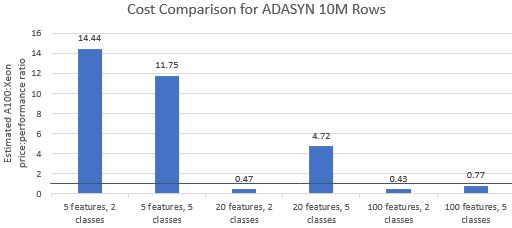
Kıyaslama maliyeti, kullanılan algoritmaya ve parametrelere bağlı olarak değişir, ancak sonuçlar genellikle Xeon örneğini destekler: maliyetin geometrik ortalaması, beş algoritmadan dördü için birden büyüktür ve genel geometrik ortalama 1,36'dır (Tablo 2).

Ek olarak, CPU'lar bulut sunucusu seçiminde daha fazla esneklik sunarak verimliliği daha da artırır. Performans gereksinimlerini ve bütçe kısıtlamalarını karşılarken belirli bir sorun boyutunun üstesinden gelebilecek en küçük yetenekli Xeon bulut sunucusunu seçmek daha uygun maliyetlidir. Şekil 4, en küçük iki kıyaslama için böyle bir örneği göstermektedir. Bu sonuçlar, model yapılandırmasının gereksinimlerine en uygun donanım üzerinde çalıştırmanın önemli ölçüde daha ucuz olabileceğini göstermektedir. Örneğin, bir e2-highcpu-8 bulut sunucusunda Intel Extension for Scikit-learn ile iki ADASYN kıyaslamasını çalıştırmak, A100 bulut sunucusunda cuML çalıştırmanın maliyetinin yalnızca %1,5'i ve %2,1'idir.

Çözüm
Yukarıdaki sonuçlar, Scikit-learn için Intel Uzantısının, stok scikit-learn'e kıyasla performans sonuçlarını önemli ölçüde iyileştirebildiğini ve ayrıca bazı testlerde A100'den daha iyi performans gösterebildiğini göstermektedir. Maliyet düşünüldüğünde, Xeon bulut sunucuları A100 bulut sunucularından çok daha ucuz olduğundan, Scikit-learn için Intel Uzantısı sonuçları daha da uygundur. Kullanıcılar performans, güç ve fiyat gereksinimlerini karşılayan bir Xeon örneği seçebilir.

![Bağlantılı Liste Nedir? [Bölüm 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































