การรวมแพนด้า 101
- วิธีทำ (
INNER| (LEFT|RIGHT|FULL)OUTER)JOINกับหมีแพนด้า? - ฉันจะเพิ่ม NaN สำหรับแถวที่หายไปหลังจากผสานได้อย่างไร
- ฉันจะกำจัด NaN หลังจากการรวมได้อย่างไร
- ฉันสามารถรวมดัชนีได้หรือไม่
- เข้าร่วมกับแพนด้า?
- ฉันจะรวมหลาย DataFrames ได้อย่างไร?
mergeเหรอ?joinเหรอ?concatเหรอ?updateเหรอ? Who? อะไร? ทำไม?!
... และอื่น ๆ. ฉันเคยเห็นคำถามซ้ำ ๆ เหล่านี้ถามเกี่ยวกับแง่มุมต่างๆของฟังก์ชันการผสานแพนด้า ข้อมูลส่วนใหญ่เกี่ยวกับการผสานและกรณีการใช้งานที่หลากหลายในปัจจุบันถูกแยกส่วนออกจากโพสต์ที่ใช้คำไม่ดีและไม่สามารถค้นหาได้หลายสิบรายการ จุดมุ่งหมายคือเพื่อหาจุดที่สำคัญกว่าสำหรับลูกหลาน
QnA นี้มีไว้เพื่อเป็นภาคต่อไปในชุดคู่มือผู้ใช้ที่เป็นประโยชน์เกี่ยวกับสำนวนแพนด้าทั่วไป (ดูโพสต์นี้เกี่ยวกับการหมุนและโพสต์นี้เกี่ยวกับการเรียงต่อกันซึ่งฉันจะสัมผัสในภายหลัง)
โปรดทราบว่าโพสต์นี้ไม่ได้มีไว้เพื่อทดแทนเอกสารดังนั้นโปรดอ่านด้วย! ตัวอย่างบางส่วนนำมาจากที่นั่น
คำตอบ
โพสต์นี้มีจุดมุ่งหมายเพื่อให้ผู้อ่านทราบถึงไพรเมอร์เกี่ยวกับการผสาน SQL กับแพนด้าวิธีใช้และเวลาที่ไม่ควรใช้
โดยเฉพาะอย่างยิ่งนี่คือสิ่งที่โพสต์นี้จะกล่าวถึง:
พื้นฐาน - ประเภทของการรวม (ซ้าย, ขวา, ด้านนอก, ด้านใน)
- รวมกับชื่อคอลัมน์ที่แตกต่างกัน
- หลีกเลี่ยงการทำซ้ำคอลัมน์คีย์ผสานในเอาต์พุต
การรวมเข้ากับดัชนีภายใต้เงื่อนไขที่แตกต่างกัน
- อย่างมีประสิทธิภาพโดยใช้ดัชนีชื่อของคุณ
- ผสานคีย์เป็นดัชนีของคอลัมน์หนึ่งและอีกคอลัมน์หนึ่ง
Multiway ผสานในคอลัมน์และดัชนี (ไม่ซ้ำกันและไม่ซ้ำกัน)
ทางเลือกที่โดดเด่นสำหรับ
mergeและjoin
สิ่งที่โพสต์นี้จะไม่ผ่าน:
- การอภิปรายและการกำหนดเวลาที่เกี่ยวข้องกับประสิทธิภาพ (สำหรับตอนนี้) ส่วนใหญ่กล่าวถึงทางเลือกที่ดีกว่าตามความเหมาะสม
- การจัดการคำต่อท้ายการลบคอลัมน์พิเศษการเปลี่ยนชื่อเอาต์พุตและกรณีการใช้งานเฉพาะอื่น ๆ มีโพสต์อื่น ๆ (อ่าน: ดีกว่า) ที่จัดการกับสิ่งนั้นดังนั้นลองคิดดูสิ!
หมายเหตุ
ตัวอย่างส่วนใหญ่ดีฟอลต์เป็นการดำเนินการ INNER JOIN ในขณะที่สาธิตคุณสมบัติต่างๆเว้นแต่จะระบุไว้เป็นอย่างอื่นนอกจากนี้ DataFrames ทั้งหมดที่นี่ยังสามารถคัดลอกและจำลองเพื่อให้คุณสามารถเล่นกับมันได้ นอกจากนี้โปรดดูโพสต์นี้ เกี่ยวกับวิธีอ่าน DataFrames จากคลิปบอร์ดของคุณ
สุดท้ายนี้การแสดงภาพทั้งหมดของการดำเนินการ JOIN ได้รับการวาดด้วยมือโดยใช้ Google วาดเขียน แรงบันดาลใจจากที่นี่
พอคุยได้แค่แสดงวิธีใช้merge!
ติดตั้ง
np.random.seed(0)
left = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': np.random.randn(4)})
right = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': np.random.randn(4)})
left
key value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right
key value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
เพื่อความเรียบง่ายคอลัมน์สำคัญจึงมีชื่อเดียวกัน (สำหรับตอนนี้)
INNER JOINเป็นตัวแทนจาก
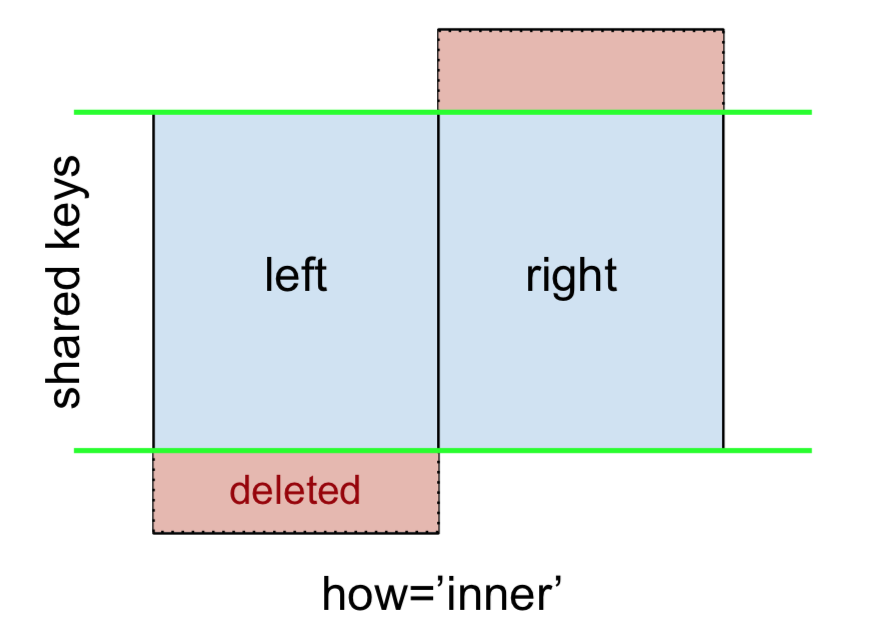
หมายเหตุ
สิ่งนี้พร้อมกับตัวเลขที่กำลังจะเกิดขึ้นทั้งหมดเป็นไปตามอนุสัญญานี้:
- สีน้ำเงินหมายถึงแถวที่มีอยู่ในผลการผสาน
- สีแดงหมายถึงแถวที่ไม่รวมอยู่ในผลลัพธ์ (เช่นลบออก)
- สีเขียวแสดงถึงค่าที่ขาดหายไปซึ่งถูกแทนที่ด้วย
NaNs ในผลลัพธ์
ในการดำเนินการ INNER JOIN ให้เรียกmergeDataFrame ทางซ้ายโดยระบุ DataFrame ที่ถูกต้องและคีย์การเข้าร่วม (อย่างน้อยที่สุด) เป็นอาร์กิวเมนต์
left.merge(right, on='key')
# Or, if you want to be explicit
# left.merge(right, on='key', how='inner')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
สิ่งนี้จะส่งคืนเฉพาะแถวจากleftและrightที่ใช้คีย์ร่วมกัน (ในตัวอย่างนี้ "B" และ "D)
ซ้าย OUTER JOINหรือ LEFT JOIN เป็นตัวแทนจาก
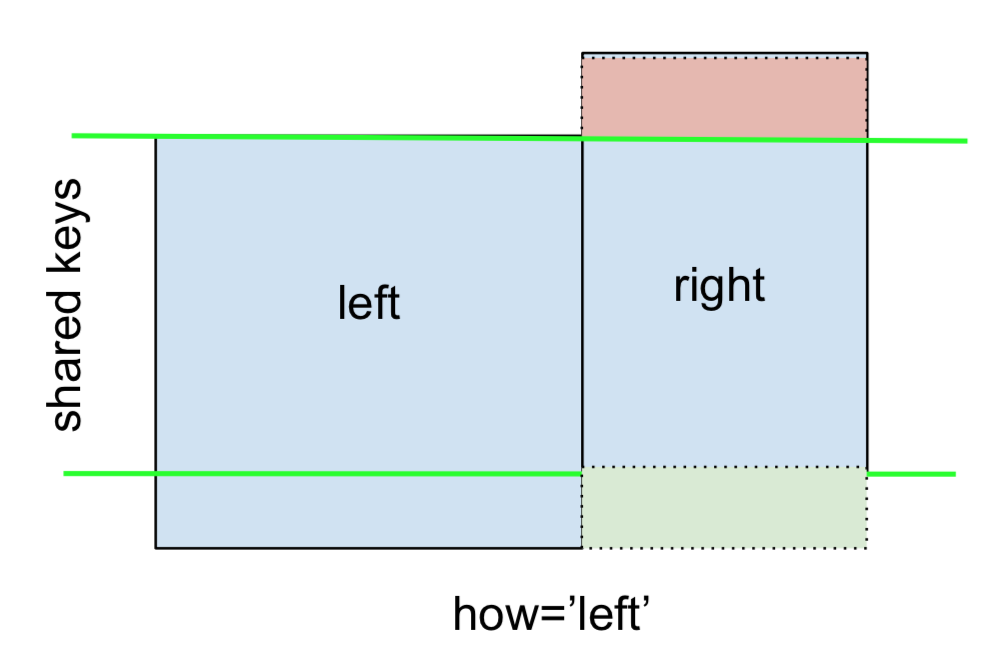
how='left'นี้สามารถทำได้โดยการระบุ
left.merge(right, on='key', how='left')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
สังเกตตำแหน่งของ NaN อย่างระมัดระวังที่นี่ หากคุณระบุจะใช้how='left'เฉพาะคีย์จากleftและข้อมูลที่หายไปจากrightจะถูกแทนที่ด้วย NaN
และในทำนองเดียวกันสำหรับRIGHT OUTER JOINหรือ RIGHT JOIN ซึ่งก็คือ ...
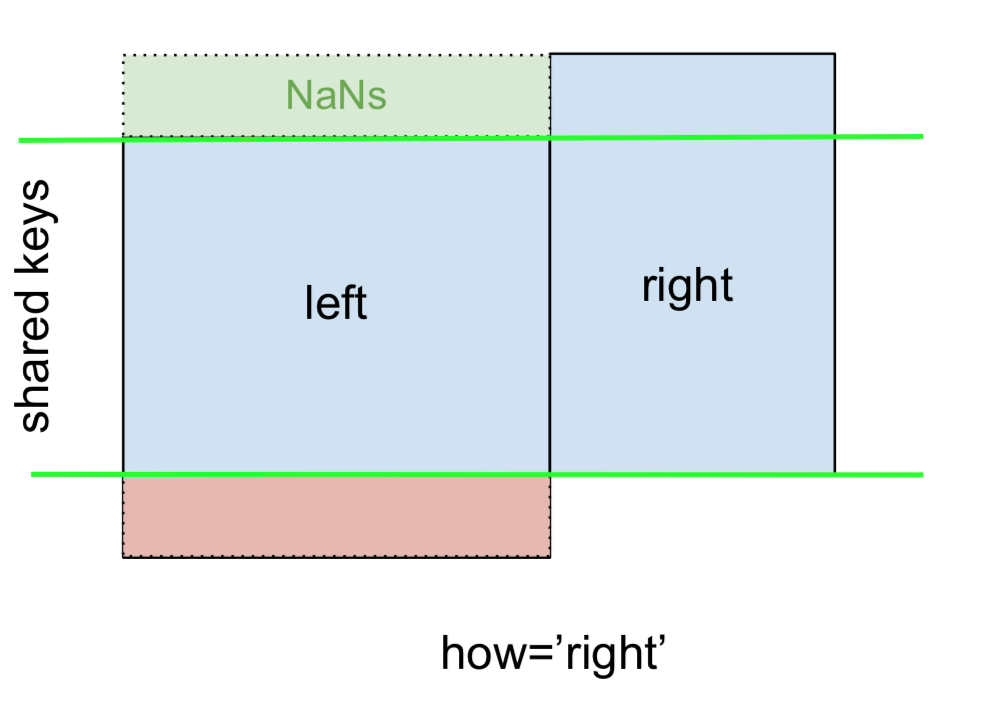
... ระบุhow='right':
left.merge(right, on='key', how='right')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
2 E NaN 0.950088
3 F NaN -0.151357
ที่นี่rightมีการใช้คีย์จากและข้อมูลที่ขาดหายไปleftจะถูกแทนที่ด้วย NaN
สุดท้ายสำหรับFULL OUTER JOINมอบให้โดย
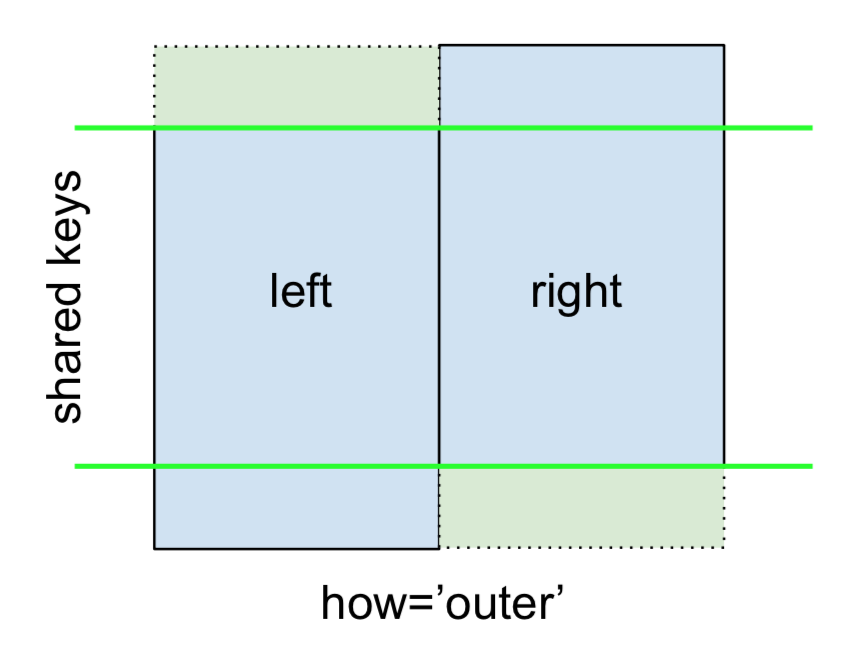
ระบุhow='outer'.
left.merge(right, on='key', how='outer')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
4 E NaN 0.950088
5 F NaN -0.151357
สิ่งนี้ใช้คีย์จากทั้งสองเฟรมและ NaN ถูกแทรกสำหรับแถวที่ขาดหายไปในทั้งสอง
เอกสารประกอบสรุปการผสานต่างๆเหล่านี้อย่างสวยงาม:

การเข้าร่วมอื่น ๆ - การยกเว้นด้านซ้าย, การยกเว้นด้านขวาและการไม่รวมแบบเต็ม / การต่อต้านการเข้าร่วม
หากคุณต้องการการเข้าร่วมแบบไม่รวมซ้ายและการไม่รวมสิทธิ์การเข้าร่วมในสองขั้นตอน
สำหรับ LEFT- ไม่รวม JOIN แสดงเป็น
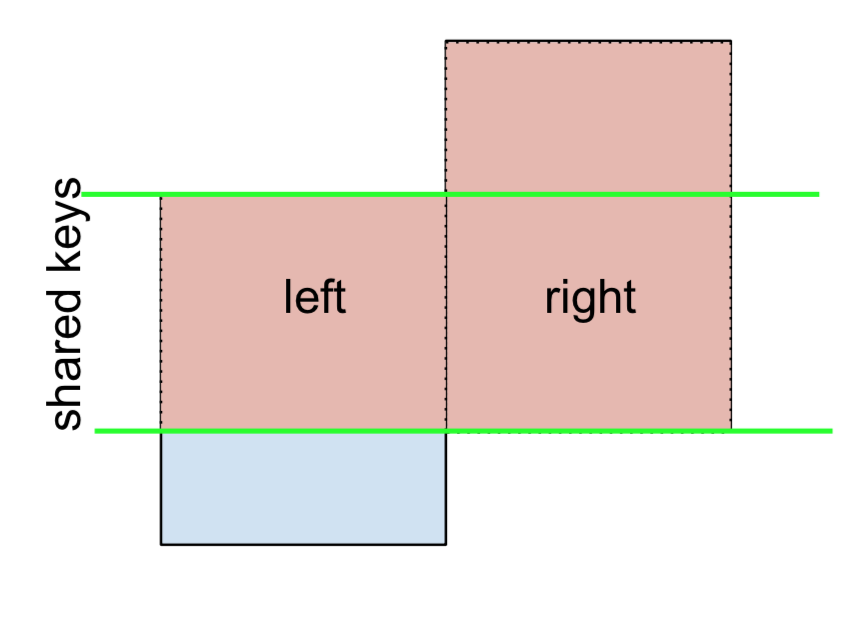
เริ่มต้นด้วยการดำเนินการ LEFT OUTER JOIN จากนั้นกรอง (ไม่รวม!) แถวที่มาจากleftเท่านั้น
(left.merge(right, on='key', how='left', indicator=True)
.query('_merge == "left_only"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
ที่ไหน
left.merge(right, on='key', how='left', indicator=True)
key value_x value_y _merge
0 A 1.764052 NaN left_only
1 B 0.400157 1.867558 both
2 C 0.978738 NaN left_only
3 D 2.240893 -0.977278 bothและในทำนองเดียวกันสำหรับการเข้าร่วมที่ไม่รวมสิทธิ์
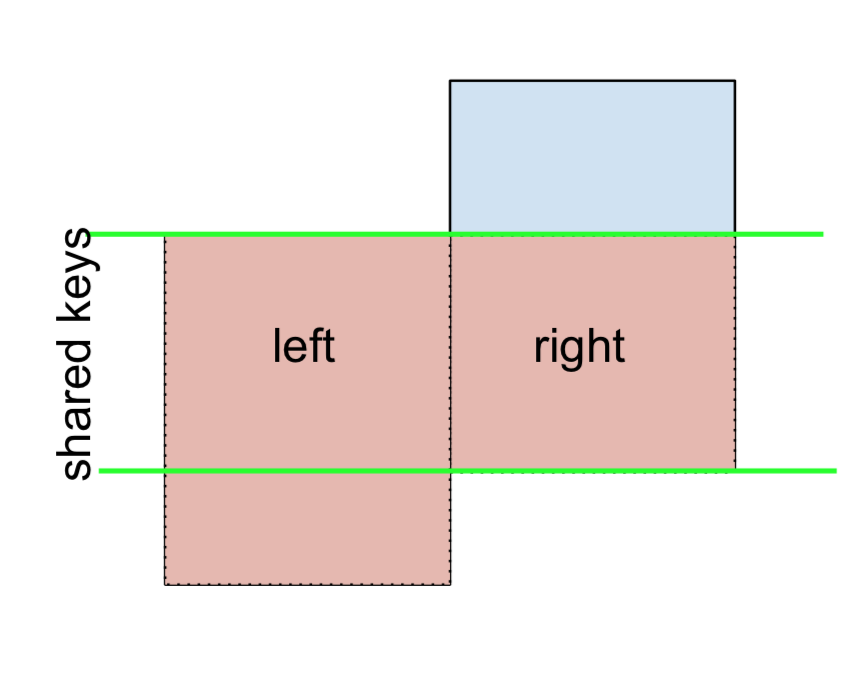
(left.merge(right, on='key', how='right', indicator=True)
.query('_merge == "right_only"')
.drop('_merge', 1))
key value_x value_y
2 E NaN 0.950088
3 F NaN -0.151357สุดท้ายนี้หากคุณจำเป็นต้องทำการผสานที่เก็บคีย์จากซ้ายหรือขวาเท่านั้น แต่ไม่ใช่ทั้งสองอย่าง (IOW ทำการANTI-JOIN )
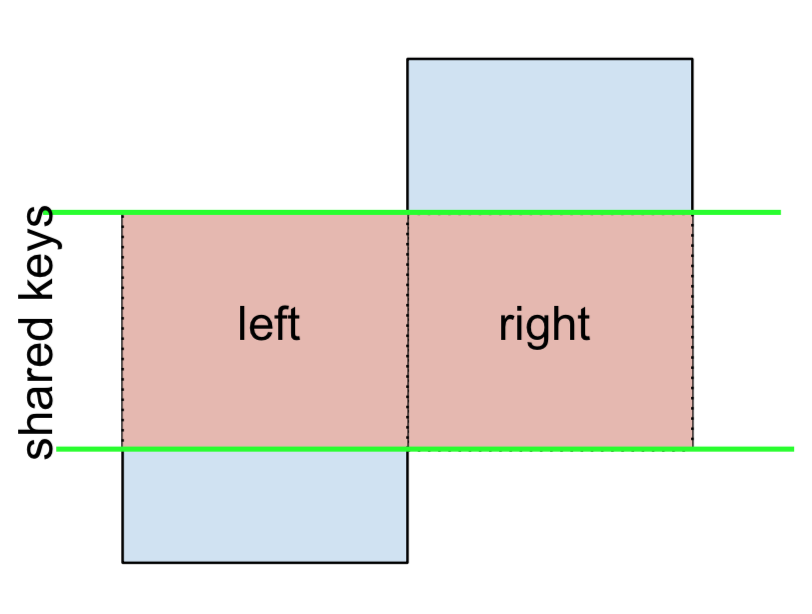
คุณสามารถทำได้ในรูปแบบที่คล้ายกัน -
(left.merge(right, on='key', how='outer', indicator=True)
.query('_merge != "both"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
4 E NaN 0.950088
5 F NaN -0.151357
ชื่อที่แตกต่างกันสำหรับคอลัมน์หลัก
หากคอลัมน์หลักตั้งชื่อแตกต่างกันเช่นlefthas keyLeftและrighthas keyRightแทนkey- จากนั้นคุณจะต้องระบุleft_onและright_onเป็นอาร์กิวเมนต์แทนon:
left2 = left.rename({'key':'keyLeft'}, axis=1)
right2 = right.rename({'key':'keyRight'}, axis=1)
left2
keyLeft value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right2
keyRight value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')
keyLeft value_x keyRight value_y
0 B 0.400157 B 1.867558
1 D 2.240893 D -0.977278
การหลีกเลี่ยงคอลัมน์คีย์ที่ซ้ำกันในเอาต์พุต
เมื่อรวมkeyLeftจากleftและkeyRightจากrightถ้าคุณต้องการเพียงอย่างใดอย่างหนึ่งkeyLeftหรือkeyRight(แต่ไม่ใช่ทั้งสองอย่าง) ในผลลัพธ์คุณสามารถเริ่มต้นด้วยการตั้งค่าดัชนีเป็นขั้นตอนเบื้องต้น
left3 = left2.set_index('keyLeft')
left3.merge(right2, left_index=True, right_on='keyRight')
value_x keyRight value_y
0 0.400157 B 1.867558
1 2.240893 D -0.977278
ตรงกันข้ามกับผลลัพธ์ของคำสั่งก่อนหน้านี้ (นั่นคือผลลัพธ์ของleft2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')) คุณจะสังเกตเห็นkeyLeftว่าหายไป คุณสามารถหาคอลัมน์ที่จะเก็บไว้โดยยึดตามดัชนีของเฟรมที่กำหนดเป็นคีย์ สิ่งนี้อาจมีความสำคัญเมื่อพูดถึงการดำเนินการ OUTER JOIN
การรวมคอลัมน์เดียวจากหนึ่งใน DataFrames
ตัวอย่างเช่นพิจารณา
right3 = right.assign(newcol=np.arange(len(right)))
right3
key value newcol
0 B 1.867558 0
1 D -0.977278 1
2 E 0.950088 2
3 F -0.151357 3
หากคุณจำเป็นต้องรวมเฉพาะ "new_val" (โดยไม่รวมคอลัมน์อื่น ๆ ) โดยปกติคุณสามารถเพียงแค่คอลัมน์ย่อยก่อนที่จะรวม:
left.merge(right3[['key', 'newcol']], on='key')
key value newcol
0 B 0.400157 0
1 D 2.240893 1
หากคุณกำลังทำการเข้าร่วมด้านนอกซ้ายโซลูชันที่มีประสิทธิภาพมากขึ้นจะเกี่ยวข้องกับmap:
# left['newcol'] = left['key'].map(right3.set_index('key')['newcol']))
left.assign(newcol=left['key'].map(right3.set_index('key')['newcol']))
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
ดังที่กล่าวมานี้คล้ายกับ แต่เร็วกว่า
left.merge(right3[['key', 'newcol']], on='key', how='left')
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
การรวมในหลายคอลัมน์
หากต้องการเข้าร่วมมากกว่าหนึ่งคอลัมน์ให้ระบุรายการสำหรับon(หรือleft_onและright_onตามความเหมาะสม)
left.merge(right, on=['key1', 'key2'] ...)
หรือในกรณีที่ชื่อแตกต่างกัน
left.merge(right, left_on=['lkey1', 'lkey2'], right_on=['rkey1', 'rkey2'])
merge*การดำเนินการและฟังก์ชันที่มีประโยชน์อื่น ๆ
การผสาน DataFrame กับ Series บนดัชนี : ดูคำตอบนี้
นอกจากนี้
merge,DataFrame.updateและDataFrame.combine_firstนอกจากนี้ยังใช้ในบางกรณีที่จะปรับปรุงหนึ่ง DataFrame อีกด้วยpd.merge_orderedเป็นฟังก์ชันที่มีประโยชน์สำหรับ JOIN ที่สั่งซื้อpd.merge_asof(อ่าน: merge_asOf) มีประโยชน์สำหรับการรวมโดยประมาณ
ส่วนนี้ครอบคลุมเฉพาะพื้นฐานเท่านั้นและออกแบบมาเพื่อกระตุ้นความอยากอาหารของคุณเท่านั้น สำหรับตัวอย่างเพิ่มเติมและกรณีให้ดูเอกสารเกี่ยวกับmerge, joinและconcatเช่นเดียวกับการเชื่อมโยงไปยังรายละเอียดฟังก์ชั่น
อิงดัชนี * -JOIN (+ ดัชนีคอลัมน์merges)
ติดตั้ง
np.random.seed([3, 14])
left = pd.DataFrame({'value': np.random.randn(4)}, index=['A', 'B', 'C', 'D'])
right = pd.DataFrame({'value': np.random.randn(4)}, index=['B', 'D', 'E', 'F'])
left.index.name = right.index.name = 'idxkey'
left
value
idxkey
A -0.602923
B -0.402655
C 0.302329
D -0.524349
right
value
idxkey
B 0.543843
D 0.013135
E -0.326498
F 1.385076
โดยทั่วไปการผสานดัชนีจะมีลักษณะดังนี้:
left.merge(right, left_index=True, right_index=True)
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
รองรับชื่อดัชนี
หากมีการตั้งชื่อดัชนีของคุณผู้ใช้ v0.23 ยังสามารถระบุชื่อระดับเป็นon(หรือleft_onและright_onตามความจำเป็น)
left.merge(right, on='idxkey')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
การรวมดัชนีของคอลัมน์หนึ่งคอลัมน์ของอีกคอลัมน์หนึ่ง
เป็นไปได้ (และค่อนข้างง่าย) ที่จะใช้ดัชนีของหนึ่งและคอลัมน์ของอีกคอลัมน์หนึ่งเพื่อทำการผสาน ตัวอย่างเช่น,
left.merge(right, left_on='key1', right_index=True)
หรือในทางกลับกัน ( right_on=...และleft_index=True)
right2 = right.reset_index().rename({'idxkey' : 'colkey'}, axis=1)
right2
colkey value
0 B 0.543843
1 D 0.013135
2 E -0.326498
3 F 1.385076
left.merge(right2, left_index=True, right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
ในกรณีพิเศษนี้ดัชนีสำหรับleftถูกตั้งชื่อดังนั้นคุณสามารถใช้ชื่อดัชนีด้วยleft_onเช่นนี้:
left.merge(right2, left_on='idxkey', right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
DataFrame.join
นอกจากนี้ยังมีอีกหนึ่งตัวเลือกที่รวบรัด คุณสามารถใช้DataFrame.joinค่าเริ่มต้นใดในการรวมเข้ากับดัชนี DataFrame.joinLEFT OUTER JOIN ตามค่าเริ่มต้นดังนั้นจึงhow='inner'จำเป็นที่นี่
left.join(right, how='inner', lsuffix='_x', rsuffix='_y')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
โปรดทราบว่าฉันจำเป็นต้องระบุlsuffixและrsuffixอาร์กิวเมนต์เนื่องจากjoinมิฉะนั้นจะผิดพลาด:
left.join(right)
ValueError: columns overlap but no suffix specified: Index(['value'], dtype='object')
เนื่องจากชื่อคอลัมน์เหมือนกัน นี่จะไม่เป็นปัญหาถ้าพวกเขาตั้งชื่อต่างกัน
left.rename(columns={'value':'leftvalue'}).join(right, how='inner')
leftvalue value
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
pd.concat
สุดท้ายนี้เป็นอีกทางเลือกหนึ่งสำหรับการรวมตามดัชนีคุณสามารถใช้pd.concat:
pd.concat([left, right], axis=1, sort=False, join='inner')
value value
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
ละเว้นjoin='inner'หากคุณต้องการเข้าร่วมเต็มรูปแบบภายนอก (ค่าเริ่มต้น):
pd.concat([left, right], axis=1, sort=False)
value value
A -0.602923 NaN
B -0.402655 0.543843
C 0.302329 NaN
D -0.524349 0.013135
E NaN -0.326498
F NaN 1.385076
สำหรับข้อมูลเพิ่มเติมโปรดดูที่โพสต์บัญญัตินี้pd.concatโดย @piRSquared
Generalizing: เข้าmergeสู่ DataFrames หลายรายการ
บ่อยครั้งสถานการณ์เกิดขึ้นเมื่อต้องรวม DataFrames หลายรายการเข้าด้วยกัน อย่างไร้เดียงสาสิ่งนี้สามารถทำได้โดยการผูกมัดการmergeโทร:
df1.merge(df2, ...).merge(df3, ...)
อย่างไรก็ตามสิ่งนี้ไม่สามารถใช้ได้อย่างรวดเร็วสำหรับ DataFrames จำนวนมาก นอกจากนี้อาจจำเป็นต้องสรุปสำหรับ DataFrames ที่ไม่ทราบจำนวน
ที่นี่ฉันแนะนำpd.concatสำหรับการรวมหลายทางบนคีย์ที่ไม่ซ้ำกันและDataFrame.joinสำหรับการรวมหลายทางบนคีย์ที่ไม่ซ้ำกัน ขั้นแรกการตั้งค่า
# Setup.
np.random.seed(0)
A = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'valueA': np.random.randn(4)})
B = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'valueB': np.random.randn(4)})
C = pd.DataFrame({'key': ['D', 'E', 'J', 'C'], 'valueC': np.ones(4)})
dfs = [A, B, C]
# Note, the "key" column values are unique, so the index is unique.
A2 = A.set_index('key')
B2 = B.set_index('key')
C2 = C.set_index('key')
dfs2 = [A2, B2, C2]
Multiway ผสานกับคีย์ที่ไม่ซ้ำกัน (หรือดัชนี)
หากคีย์ของคุณ (ในที่นี้คีย์อาจเป็นคอลัมน์หรือดัชนี) ไม่ซ้ำกันคุณสามารถpd.concatใช้ได้ โปรดทราบว่าpd.concatร่วม DataFrames ดัชนี
# merge on `key` column, you'll need to set the index before concatenating
pd.concat([
df.set_index('key') for df in dfs], axis=1, join='inner'
).reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# merge on `key` index
pd.concat(dfs2, axis=1, sort=False, join='inner')
valueA valueB valueC
key
D 2.240893 -0.977278 1.0
ละเว้นjoin='inner'การเข้าร่วมเต็มรูปแบบจากภายนอก โปรดทราบว่าคุณไม่สามารถระบุการรวม LEFT หรือ RIGHT OUTER ได้ (หากคุณต้องการสิ่งเหล่านี้ให้ใช้joinคำอธิบายด้านล่าง)
Multiway ผสานกับคีย์ที่ซ้ำกัน
concatรวดเร็ว แต่มีข้อบกพร่อง ไม่สามารถจัดการรายการที่ซ้ำกันได้
A3 = pd.DataFrame({'key': ['A', 'B', 'C', 'D', 'D'], 'valueA': np.random.randn(5)})
pd.concat([df.set_index('key') for df in [A3, B, C]], axis=1, join='inner')
ValueError: Shape of passed values is (3, 4), indices imply (3, 2)
ในสถานการณ์นี้เราสามารถใช้joinเนื่องจากสามารถจัดการคีย์ที่ไม่ซ้ำกันได้ (โปรดทราบว่าjoinรวม DataFrames บนดัชนีของพวกเขามันจะเรียกmergeภายใต้ประทุนและทำการ JOIN ด้านนอกด้านซ้ายเว้นแต่จะระบุไว้เป็นอย่างอื่น)
# join on `key` column, set as the index first
# For inner join. For left join, omit the "how" argument.
A.set_index('key').join(
[df.set_index('key') for df in (B, C)], how='inner').reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# join on `key` index
A3.set_index('key').join([B2, C2], how='inner')
valueA valueB valueC
key
D 1.454274 -0.977278 1.0
D 0.761038 -0.977278 1.0
มุมมองภาพเสริมของpd.concat([df0, df1], kwargs). โปรดสังเกตว่าความหมายของ kwarg axis=0หรือaxis=1ไม่เข้าใจง่ายเท่ากับdf.mean()หรือdf.apply(func)
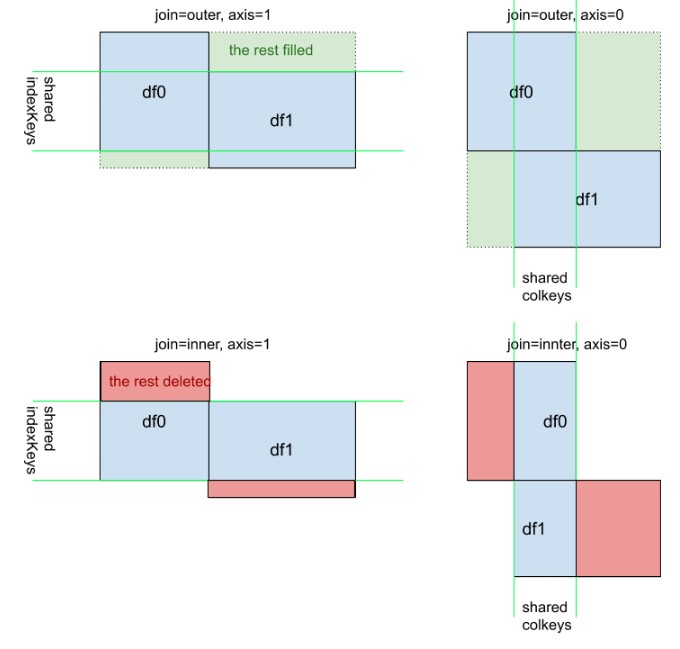
ในคำตอบนี้ฉันจะพิจารณาตัวอย่างที่ใช้ได้จริงของไฟล์pandas.concat.
พิจารณาสิ่งต่อไปนี้DataFramesด้วยชื่อคอลัมน์เดียวกัน:
Preco2018ขนาด (8784, 5)
Preco 2019ขนาด (8760, 5)
ที่มีชื่อคอลัมน์เหมือนกัน
คุณสามารถรวมเข้าด้วยกันโดยใช้pandas.concatเพียง
import pandas as pd
frames = [Preco2018, Preco2019]
df_merged = pd.concat(frames)
ซึ่งส่งผลให้ DataFrame มีขนาดต่อไปนี้ (17544, 5)

ถ้าคุณต้องการเห็นภาพมันจะทำงานในลักษณะนี้
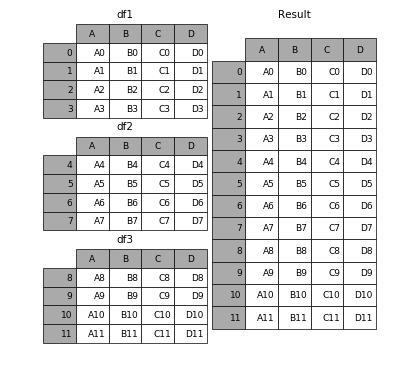
( ที่มา )