Perché pagare di più per l'apprendimento automatico?

Accelera i tuoi carichi di lavoro di apprendimento sbilanciati con l'estensione Intel per Scikit-learn
Ethan Glaser, Nikolay Petrov, Henry Gabb e Jui Mhatre, Intel Corporation
Un recente blog NVIDIA ha attirato la nostra attenzione con i suoi risultati fuorvianti . Qual è il punto di confrontare una GPU A100 con una CPU di nove anni (l'Intel Xeon E5–2698 è stato lanciato nel 2014 e da allora è stato interrotto) o confrontare il codice CUDA ottimizzato (la libreria RAPIDS cuML) con un non ottimizzato, a thread singolo Codice Python (stock scikit-learn con la libreria di apprendimento sbilanciato ) a meno che tu non stia deliberatamente cercando di aumentare la velocità della GPU rispetto alla CPU? La libreria di apprendimento sbilanciato supporta stimatori compatibili con scikit-learn, quindi hanno utilizzato stimatori cuML per l'accelerazione. Possiamo utilizzare gli stimatori ottimizzati in Intel Extension per Scikit-learn semplicemente aggiungendo una chiamata a patch_sklearn():
from sklearnex import patch_sklearn
patch_sklearn()
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.neighbors import NearestNeighbors
...
nn = NearestNeighbors(n_neighbors=4, n_jobs=-1)
X_resampled, y_resampled = EditedNearestNeighbours(n_neighbors=nn).fit_resample(X, y)

Confronto delle prestazioni
L'estensione Intel per Scikit-learn offre accelerazioni su tutta la linea per gli stessi benchmark di Nvidia (Figura 1). Le accelerazioni vanno da ~2x fino a ~140x a seconda dell'algoritmo e dei parametri. Si noti che la libreria stock scikit-learn ha esaurito la memoria per i benchmark SMOTE e ADASYN "100 funzionalità, 5 classi". Se le prestazioni sono importanti, questi risultati dimostrano che l'estensione Intel per Scikit-learn offre una velocità significativa rispetto a scikit-learn di serie.

Come si confronta questo con i risultati A100 di Nvidia? Diamo un'occhiata ai due algoritmi in cui Nvidia ha ottenuto le accelerazioni più elevate rispetto a scikit-learn: SVMSMOTE e CondensedNearestNeighbours (Figura 2). Questi risultati mostrano che le nostre prestazioni sono di un ordine di grandezza simile a quelle di cuML quando vengono utilizzati per il confronto un processore più recente e scikit-learn ottimizzato. Intel Extension per Scikit-learn supera persino cuML in alcuni test. Parliamo ora del prezzo.


Confronto dei costi
Vale la pena notare che il costo orario di un'istanza A100 a2-highgpu-1g su GCP è superiore del 60% rispetto all'istanza n2-highcpu-64 (Tabella 1). Ciò significa che l'istanza A100 deve offrire una velocità di almeno 1,6 volte superiore rispetto all'istanza Xeon Gold 6268CL (n2-highcpu-64) per essere competitiva in termini di costi. (Un A100 consuma anche 1,7 volte e 1,2 volte in più di energia rispettivamente rispetto a Xeon E5–2696 v4 e Xeon Gold 6268CL, ma per ora lo metteremo da parte perché il consumo energetico è incluso nel costo dell'istanza.)
Confrontiamo i rapporti prezzo/prestazioni per i benchmark selezionati da Nvidia per vedere se l'istanza A100 giustifica il suo prezzo premium. Il costo totale (USD) di un'esecuzione di benchmark è semplicemente il costo dell'istanza all'ora (USD/ora) moltiplicato per il tempo di esecuzione (ora). Un confronto dettagliato dei costi mostra che l'esecuzione di questi benchmark sull'istanza Xeon è spesso l'opzione più conveniente (Figura 3). Nei grafici sottostanti, un valore maggiore di uno indica che il benchmark dato è più costoso sull'istanza A100. Ad esempio, un valore di 1,29 significa che l'istanza A100 è più costosa del 29% rispetto all'istanza Xeon.



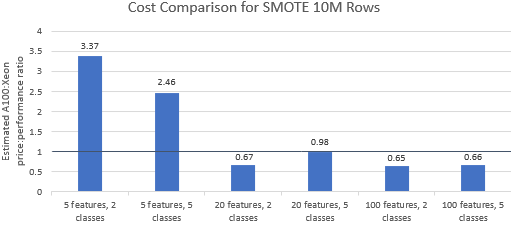
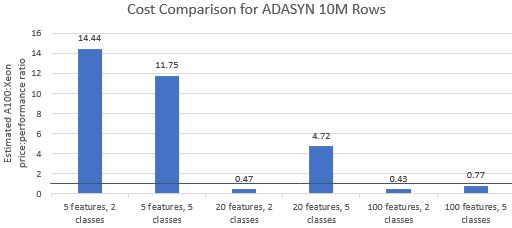
Il costo del benchmark varia a seconda dell'algoritmo e dei parametri utilizzati, ma i risultati generalmente favoriscono l'istanza Xeon: la media geometrica del costo è maggiore di uno per quattro dei cinque algoritmi e la media geometrica complessiva è 1,36 (Tabella 2).

Inoltre, le CPU offrono maggiore flessibilità nella selezione delle istanze, il che migliora ulteriormente l'efficienza. È più conveniente selezionare l'istanza Xeon più piccola in grado di gestire una determinata dimensione del problema soddisfacendo i requisiti di prestazioni e i vincoli di budget. La Figura 4 mostra uno di questi esempi per i due benchmark più piccoli. Questi risultati dimostrano che può essere notevolmente più economico eseguire sull'hardware che meglio si adatta alle esigenze della configurazione del modello. Ad esempio, l'esecuzione dei due benchmark ADASYN con Intel Extension for Scikit-learn su un'istanza e2-highcpu-8 rappresenta solo l'1,5% e il 2,1% del costo dell'esecuzione di cuML sull'istanza A100.

Conclusione
I risultati di cui sopra dimostrano che l' estensione Intel per Scikit-learn è in grado di migliorare notevolmente i risultati delle prestazioni rispetto a scikit-learn di serie ed è anche in grado di superare A100 in alcuni test. Se si considera il costo, i risultati di Intel Extension for Scikit-learn sono ancora più favorevoli perché le istanze Xeon sono molto più economiche dell'istanza A100. Gli utenti possono selezionare un'istanza Xeon che soddisfi i loro requisiti di prestazioni, potenza e prezzo.

![Che cos'è un elenco collegato, comunque? [Parte 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)













































