วิศวกรรมข้อมูลทำได้ง่าย — แนบสคริปต์ Python เพื่อเริ่มต้นงาน ETL ของคุณ
ภาพรวม:
รับหน้าที่เป็นวิศวกรข้อมูล ดึงข้อมูลจากแหล่งต่างๆ ของรูปแบบไฟล์ แปลงเป็นประเภทข้อมูลเฉพาะ และโหลดลงในแหล่งเดียวสำหรับการวิเคราะห์ หลังจากอ่านบทความนี้ไม่นาน ด้วยความช่วยเหลือจากตัวอย่างที่ใช้ได้จริงหลายๆ ตัวอย่าง คุณจะสามารถทดสอบทักษะของคุณได้โดยการใช้การขูดเว็บและการดึงข้อมูลด้วย API ด้วย Python และวิศวกรรมข้อมูล คุณจะสามารถเริ่มรวบรวมชุดข้อมูลขนาดใหญ่จากหลายแหล่ง และแปลงเป็นแหล่งข้อมูลหลักแหล่งเดียว หรือเริ่มการขูดเว็บเพื่อรับข้อมูลเชิงลึกทางธุรกิจที่เป็นประโยชน์

เรื่องย่อ:
- เหตุใดวิศวกรรมข้อมูลจึงมีความน่าเชื่อถือมากกว่า
- กระบวนการของวงจร ETL
- ทีละขั้นตอนแยก, แปลง, ฟังก์ชันโหลด
- เกี่ยวกับวิศวกรรมข้อมูล
- บทสรุป
เป็นอาชีพด้านเทคโนโลยีที่น่าเชื่อถือและเติบโตเร็วที่สุดในยุคปัจจุบัน เนื่องจากมุ่งเน้นที่การขูดเว็บและการรวบรวมข้อมูลชุดข้อมูลมากขึ้น
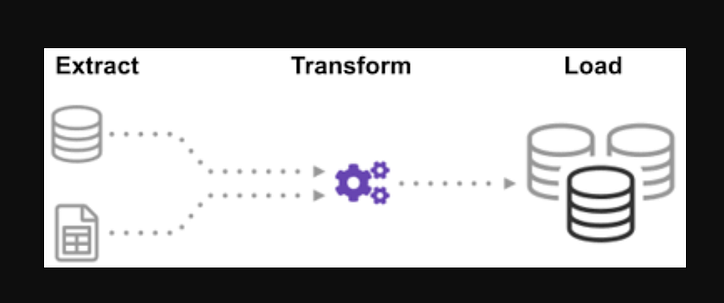
กระบวนการ (ETL Cycle):
คุณเคยสงสัยหรือไม่ว่าข้อมูลจากหลายแหล่งถูกรวมเข้าด้วยกันเพื่อสร้างแหล่งข้อมูลเดียวได้อย่างไร การประมวลผลแบบกลุ่มเป็นการรวบรวมข้อมูลประเภทหนึ่ง และเรียนรู้เพิ่มเติมเกี่ยวกับ "วิธีสำรวจประเภทการประมวลผลแบบกลุ่ม" ที่เรียกว่า Extract, Transform และ Load

ETL เป็นกระบวนการแยกข้อมูลปริมาณมหาศาลจากแหล่งที่มาและรูปแบบต่างๆ แล้วแปลงเป็นรูปแบบเดียวก่อนที่จะใส่ลงในฐานข้อมูลหรือไฟล์ปลายทาง
ข้อมูลบางส่วนของคุณจัดเก็บไว้ในไฟล์ CSV ในขณะที่ข้อมูลอื่นๆ ถูกจัดเก็บไว้ในไฟล์ JSON คุณต้องรวบรวมข้อมูลทั้งหมดนี้เป็นไฟล์เดียวเพื่อให้ AI อ่าน เนื่องจากข้อมูลของคุณอยู่ในหน่วยอิมพีเรียล แต่ AI ต้องการหน่วยเมตริก คุณจึงต้องแปลงข้อมูลนั้น เนื่องจาก AI สามารถอ่านข้อมูล CSV ได้ในไฟล์ขนาดใหญ่เพียงไฟล์เดียว คุณต้องโหลดข้อมูลดังกล่าวก่อน หากข้อมูลอยู่ในรูปแบบ CSV ให้ใส่ ETL ต่อไปนี้ด้วย python และดูขั้นตอนการแยกด้วยตัวอย่างง่ายๆ
โดยดูที่รายการไฟล์ .json และ .csv นามสกุลไฟล์ glob นำหน้าด้วยดาวและจุดในอินพุต รายการไฟล์ .csv จะถูกส่งกลับ ไฟล์ For.json เราสามารถทำสิ่งเดียวกันได้ เราอาจสร้างไฟล์ที่แยกชื่อ ส่วนสูง และน้ำหนักในรูปแบบ CSV ชื่อไฟล์ของไฟล์ .csv คืออินพุต และเอาต์พุตคือ data frame สำหรับรูปแบบ JSON เราสามารถทำได้เช่นเดียวกัน
ขั้นตอนที่ 1:
นำเข้าฟังก์ชันและโมดูลที่จำเป็น
import glob
import pandas as pd
import xml.etree.ElementTree as ET
from datetime import datetime
ไฟล์dealership_dataประกอบด้วยไฟล์ CSV, JSON และ XML สำหรับข้อมูลรถมือสองซึ่งมีคุณลักษณะชื่อcar_model, year_of_manufacture, , priceและ fuelดังนั้นเราจะแตกไฟล์จากข้อมูลดิบและแปลงเป็นไฟล์เป้าหมายและโหลดในเอาต์พุต
กำหนดเส้นทางสำหรับไฟล์เป้าหมาย:
tmpfile = "dealership_temp.tmp" # store all extracted data
logfile = "dealership_logfile.txt" # all event logs will be stored
targetfile = "dealership_transformed_data.csv" # transformed data is stored
ฟังก์ชันจะดึงข้อมูลจำนวนมากจากหลายแหล่งเป็นชุด โดยการเพิ่มฟังก์ชันนี้ ตอนนี้จะค้นพบและโหลดชื่อไฟล์ CSV ทั้งหมด และไฟล์ CSV จะถูกเพิ่มไปยังกรอบวันที่ด้วยการวนซ้ำแต่ละครั้ง โดยแนบการวนซ้ำครั้งแรกก่อน ตามด้วยการวนซ้ำครั้งที่สอง ส่งผลให้ ในรายการข้อมูลที่แยกออกมา หลังจากที่เรารวบรวมข้อมูลแล้ว เราจะไปที่ขั้นตอน "แปลงร่าง" ของกระบวนการ
หมายเหตุ: หากตั้งค่า "ignore index" เป็นจริง ลำดับของแต่ละแถวจะเหมือนกับลำดับที่ต่อท้ายแถวใน data frame
ฟังก์ชันแยก CSV
def extract_from_csv(file_to_process):
dataframe = pd.read_csv(file_to_process)
return dataframe
def extract_from_json(file_to_process):
dataframe = pd.read_json(file_to_process,lines=True)
return dataframe
def extract_from_xml(file_to_process):
dataframe = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
tree = ET.parse(file_to_process)
root = tree.getroot()
for person in root:
car_model = person.find("car_model").text
year_of_manufacture = int(person.find("year_of_manufacture").text)
price = float(person.find("price").text)
fuel = person.find("fuel").text
dataframe = dataframe.append({"car_model":car_model, "year_of_manufacture":year_of_manufacture, "price":price, "fuel":fuel}, ignore_index=True)
return dataframe
ตอนนี้เรียกฟังก์ชันแยกโดยใช้การเรียกใช้ฟังก์ชันสำหรับ CSV , JSON , XML
def extract():
extracted_data = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
#for csv files
for csvfile in glob.glob("dealership_data/*.csv"):
extracted_data = extracted_data.append(extract_from_csv(csvfile), ignore_index=True)
#for json files
for jsonfile in glob.glob("dealership_data/*.json"):
extracted_data = extracted_data.append(extract_from_json(jsonfile), ignore_index=True)
#for xml files
for xmlfile in glob.glob("dealership_data/*.xml"):
extracted_data = extracted_data.append(extract_from_xml(xmlfile), ignore_index=True)
return extracted_data
หลังจากที่เรารวบรวมข้อมูลแล้ว เราจะไปที่ขั้นตอน "การเปลี่ยนแปลง" ของกระบวนการ ฟังก์ชันนี้จะแปลงความสูงของคอลัมน์ซึ่งมีหน่วยเป็นนิ้วเป็นมิลลิเมตร และปอนด์ของคอลัมน์ซึ่งมีหน่วยเป็นปอนด์เป็นกิโลกรัม และส่งคืนผลลัพธ์ในข้อมูลตัวแปร ในกรอบข้อมูลอินพุต ความสูงของคอลัมน์มีหน่วยเป็นฟุต แปลงคอลัมน์เพื่อแปลงเป็นเมตรและปัดเศษเป็นทศนิยมสองตำแหน่ง
def transform(data):
data['price'] = round(data.price, 2)
return data
ได้เวลาโหลดข้อมูลลงในไฟล์เป้าหมายแล้ว หลังจากที่เราได้รวบรวมและระบุข้อมูลแล้ว เราบันทึก data frame ของ pandas เป็น CSV ในสถานการณ์นี้ ตอนนี้เราได้ผ่านขั้นตอนการแยก แปลง และโหลดข้อมูลจากแหล่งต่างๆ ลงในไฟล์เป้าหมายเดียว เราจำเป็นต้องสร้างรายการบันทึกก่อนที่เราจะสามารถทำงานให้เสร็จได้ เราจะทำสิ่งนี้ให้สำเร็จได้ด้วยการเขียนฟังก์ชันการบันทึก
โหลดฟังก์ชัน:
def load(targetfile,data_to_load):
data_to_load.to_csv(targetfile)
ข้อมูลทั้งหมดที่เขียนจะถูกผนวกเข้ากับข้อมูลปัจจุบันเมื่อมีการเพิ่ม "a" จากนั้น เราสามารถแนบการประทับเวลาในแต่ละขั้นตอนของกระบวนการ โดยระบุเวลาเริ่มต้นและเวลาสิ้นสุด โดยการสร้างรายการประเภทนี้ หลังจากที่เราได้กำหนดโค้ดทั้งหมดที่จำเป็นสำหรับการดำเนินการ ETL กับข้อมูลแล้ว ขั้นตอนสุดท้ายคือการเรียกใช้ฟังก์ชันทั้งหมด
def log(message):
timestamp_format = '%H:%M:%S-%h-%d-%Y'
#Hour-Minute-Second-MonthName-Day-Year
now = datetime.now() # get current timestamp
timestamp = now.strftime(timestamp_format)
with open("dealership_logfile.txt","a") as f: f.write(timestamp + ',' + message + 'n')
ก่อนอื่นเราเริ่มต้นด้วยการเรียกใช้ฟังก์ชัน extract_data ข้อมูลที่ได้รับจากขั้นตอนนี้จะถูกถ่ายโอนไปยังขั้นตอนที่สองของการแปลงข้อมูล หลังจากเสร็จสิ้น ข้อมูลจะถูกโหลดลงในไฟล์เป้าหมาย นอกจากนี้ โปรดทราบว่าก่อนและหลังทุกขั้นตอน เวลาและวันที่สำหรับการเริ่มต้นและสิ้นสุดได้ถูกเพิ่มเข้าไปแล้ว
บันทึกที่คุณได้เริ่มกระบวนการ ETL:
log("ETL Job Started")
log("Extract phase Started")
extracted_data = extract()
log("Extract phase Ended")
บันทึก (“เริ่มขั้นตอนการแปลงแล้ว”)
transform_data = แปลง (แยกข้อมูล)
log("Transform phase Ended")
log("Load phase Started")
load(targetfile,transformed_data)
log("Load phase Ended")
log("ETL Job Ended")
- การเขียน Extract Function อย่างง่าย
- วิธีเขียนฟังก์ชัน Transform อย่างง่าย
- วิธีเขียน Load function อย่างง่าย
- วิธีเขียนฟังก์ชันการบันทึกอย่างง่าย
อย่างมากที่สุด เราได้กล่าวถึงกระบวนการ ETL ทั้งหมดแล้ว มาดูกันต่อไปว่า ” งาน Data Engineer มีประโยชน์อย่างไร ”
เกี่ยวกับวิศวกรรมข้อมูล:
วิศวกรรมข้อมูลเป็นสาขาที่กว้างขวางและมีชื่อมากมาย อาจไม่มีชื่ออย่างเป็นทางการในหลายสถาบัน ด้วยเหตุนี้ โดยทั่วไปจะเป็นการดีกว่าหากเริ่มต้นด้วยการกำหนดจุดมุ่งหมายของงานด้านวิศวกรรมข้อมูลที่นำไปสู่ผลลัพธ์ที่คาดหวัง ผู้ใช้ที่พึ่งพาวิศวกรข้อมูลนั้นมีความหลากหลายพอๆ กับความสามารถและผลลัพธ์ของทีมวิศวกรรมข้อมูล ผู้บริโภคของคุณจะเป็นผู้กำหนดเสมอว่าปัญหาใดที่คุณจัดการและวิธีแก้ไขปัญหา โดยไม่คำนึงว่าคุณจะดำเนินการในภาคส่วนใด
บทสรุป:
ฉันหวังว่าคุณจะได้รับความช่วยเหลือในบทความและทำความเข้าใจเกี่ยวกับการใช้ Python กับ ETL เมื่อคุณเริ่มต้นการเดินทางเพื่อเรียนรู้วิศวกรรมข้อมูล รู้สึกอยากเรียนรู้เพิ่มเติมหรือไม่? ฉันขอแนะนำให้คุณอ่านบทความอื่นๆ ของฉันเกี่ยวกับวิธีที่คุณสามารถใช้คลาสไพธอนเพื่อปรับปรุงกระบวนการทางวิศวกรรมข้อมูล ฉันยังสาธิตวิธีการใช้pydanticเพื่อปรับปรุงการตรวจสอบข้อมูลของคุณที่หนึ่งในขั้นตอนแรกและสำคัญที่สุดของขั้นตอนข้อมูลของคุณ หากคุณสนใจการแสดงข้อมูลเป็นภาพ โปรดดูคำแนะนำทีละขั้นตอนนี้สำหรับการสร้างแผนภูมิแรกของคุณด้วย Apache Superset
เรียกร้องให้ดำเนินการ
หากคุณเห็นว่าคู่มือนี้มีประโยชน์ โปรดปรบมือและติดตามฉันได้ตามสบาย เข้าร่วมสื่อผ่านลิงก์นี้เพื่อเข้าถึงบทความพรีเมียมทั้งหมดจากฉันและนักเขียนที่ยอดเยี่ยมคนอื่นๆ ที่นี่บนสื่อ
เพิ่มระดับการเข้ารหัส
ขอบคุณที่เป็นส่วนหนึ่งของชุมชนของเรา! ก่อนที่คุณจะไป:
- ปรบมือให้กับเรื่องราวและติดตามผู้เขียน
- ดูเนื้อหาเพิ่มเติมในสิ่งพิมพ์ Level Up Coding
- ติดตามเรา: Twitter | LinkedIn | จดหมายข่าว















































![รายการที่เชื่อมโยงคืออะไร? [ส่วนที่ 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)