Pourquoi payer plus pour l'apprentissage automatique ?

Accélérez vos charges de travail d'apprentissage déséquilibrées avec l'extension Intel pour Scikit-learn
Ethan Glaser, Nikolay Petrov, Henry Gabb et Jui Mhatre, Intel Corporation
Un récent blog de NVIDIA a attiré notre attention avec ses résultats trompeurs . Quel est l'intérêt de comparer un GPU A100 à un processeur vieux de neuf ans (l'Intel Xeon E5-2698 a été lancé en 2014 et a depuis été abandonné) ou de comparer le code CUDA optimisé (la bibliothèque RAPIDS cuML) à un code monothread non optimisé Code Python (stock scikit-learn avec la bibliothèque d'apprentissage déséquilibré ) à moins que vous n'essayiez délibérément de gonfler l'accélération du GPU par rapport au CPU ? La bibliothèque d'apprentissage déséquilibré prend en charge les estimateurs compatibles scikit-learn, ils ont donc utilisé des estimateurs cuML pour l'accélération. Nous pouvons utiliser les estimateurs optimisés dans Intel Extension pour Scikit-learn simplement en ajoutant un appel à patch_sklearn() :
from sklearnex import patch_sklearn
patch_sklearn()
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.neighbors import NearestNeighbors
...
nn = NearestNeighbors(n_neighbors=4, n_jobs=-1)
X_resampled, y_resampled = EditedNearestNeighbours(n_neighbors=nn).fit_resample(X, y)

Comparaison des performances
L'extension Intel pour Scikit-learn donne des accélérations à tous les niveaux pour les mêmes références que Nvidia (Figure 1). Les accélérations vont de ~2x à ~140x selon l'algorithme et les paramètres. Notez que la bibliothèque stock scikit-learn a manqué de mémoire pour les benchmarks SMOTE et ADASYN "100 fonctionnalités, 5 classes". Si les performances comptent, ces résultats démontrent qu'Intel Extension pour Scikit-learn offre une accélération significative par rapport à scikit-learn.

Comment cela se compare-t-il aux résultats A100 de Nvidia ? Examinons les deux algorithmes où Nvidia a obtenu les accélérations les plus élevées par rapport à scikit-learn : SVMSMOTE et CondensedNearestNeighbours (Figure 2). Ces résultats montrent que nos performances sont du même ordre de grandeur que cuML lorsqu'un processeur plus récent et un scikit-learn optimisé sont utilisés à des fins de comparaison. L'extension Intel pour Scikit-learn surpasse même cuML dans certains tests. Parlons maintenant du prix.


Comparaison des coûts
Il convient de noter que le coût horaire d'une instance A100 a2-highgpu-1g sur GCP est supérieur de 60 % à celui de l'instance n2-highcpu-64 (tableau 1). Cela signifie que l'instance A100 doit fournir une accélération d'au moins 1,6 fois par rapport à l'instance Xeon Gold 6268CL (n2-highcpu-64) pour être compétitive. (Un A100 consomme également 1,7x et 1,2x plus d'énergie que Xeon E5–2696 v4 et Xeon Gold 6268CL, respectivement, mais nous allons mettre cela de côté pour l'instant car la consommation d'énergie est intégrée au coût de l'instance.)
Comparons les rapports prix/performances des benchmarks sélectionnés par Nvidia pour voir si l'instance A100 justifie son prix premium. Le coût total (USD) d'une exécution de référence correspond simplement au coût de l'instance par heure (USD/h) multiplié par la durée d'exécution (h). Une comparaison détaillée des coûts montre que l'exécution de ces benchmarks sur l'instance Xeon est souvent l'option la plus rentable (Figure 3). Dans les graphiques ci-dessous, une valeur supérieure à un indique que le benchmark donné est plus cher sur l'instance A100. Par exemple, une valeur de 1,29 signifie que l'instance A100 est 29 % plus chère que l'instance Xeon.



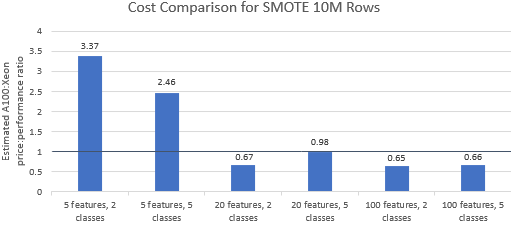
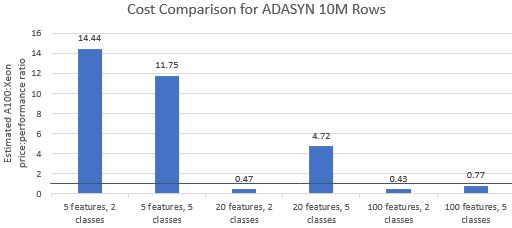
Le coût de référence varie selon l'algorithme et les paramètres utilisés, mais les résultats sont généralement favorables à l'instance Xeon : la moyenne géométrique des coûts est supérieure à un pour quatre des cinq algorithmes et la moyenne géométrique globale est de 1,36 (tableau 2).

De plus, les processeurs offrent plus de flexibilité dans la sélection des instances, ce qui améliore encore l'efficacité. Il est plus rentable de sélectionner la plus petite instance Xeon capable de gérer une taille de problème donnée tout en satisfaisant aux exigences de performances et aux contraintes budgétaires. La figure 4 montre un exemple de ce type pour les deux plus petits repères. Ces résultats démontrent qu'il peut être beaucoup moins cher d'utiliser le matériel qui correspond le mieux aux besoins de la configuration du modèle. Par exemple, l'exécution des deux benchmarks ADASYN avec l'extension Intel pour Scikit-learn sur une instance e2-highcpu-8 ne représente que 1,5 % et 2,1 % du coût d'exécution de cuML sur l'instance A100.

Conclusion
Les résultats ci-dessus démontrent que l' extension Intel pour Scikit-learn est capable d'améliorer considérablement les performances par rapport à scikit-learn et est également capable de surpasser A100 dans certains tests. Lorsque le coût est pris en compte, les résultats de l'extension Intel pour Scikit-learn sont encore plus favorables car les instances Xeon sont beaucoup moins chères que l'instance A100. Les utilisateurs peuvent sélectionner une instance Xeon qui répond à leurs exigences de performances, de puissance et de prix.
![Qu'est-ce qu'une liste liée, de toute façon? [Partie 1]](https://post.nghiatu.com/assets/images/m/max/724/1*Xokk6XOjWyIGCBujkJsCzQ.jpeg)














































