Pandy 101
- Jak wykonać (
INNER| (LEFT|RIGHT|FULL)OUTER)JOINz pandami? - Jak dodać numery NaN dla brakujących wierszy po scaleniu?
- Jak pozbyć się NaN po scaleniu?
- Czy mogę dołączyć do indeksu?
- Krzyżować się z pandami?
- Jak scalić wiele ramek DataFrame?
merge?join?concat?update? WHO? Co? Czemu?!
... i więcej. Widziałem te powtarzające się pytania dotyczące różnych aspektów funkcji scalania pand. Większość informacji dotyczących scalania i jego różnych przypadków użycia jest obecnie podzielona na dziesiątki źle sformułowanych, niemożliwych do przeszukania postów. Celem jest zebranie kilku ważniejszych punktów dla potomności.
Ta QnA ma być kolejną odsłoną serii pomocnych podręczników użytkownika na temat popularnych idiomów pandy (zobacz ten post o przestawianiu i ten post o konkatenacji , do którego będę się odnosić później).
Pamiętaj, że ten post nie ma na celu zastąpienia dokumentacji , więc przeczytaj go również! Stamtąd zaczerpnięto niektóre przykłady.
Odpowiedzi
Ten post ma na celu dać czytelnikom elementarz na temat łączenia się z pandami w języku SQL, jak go używać i kiedy nie używać.
W szczególności, oto, przez co przejdzie ten post:
Podstawy - rodzaje połączeń (LEWY, PRAWY, ZEWNĘTRZNY, WEWNĘTRZNY)
- scalanie z różnymi nazwami kolumn
- unikanie zduplikowanej kolumny klucza scalania w wynikach
Połączenie z indeksem w różnych warunkach
- efektywnie używając nazwanego indeksu
- scal klucz jako indeks jednej i kolumny drugiej
Wielostronne scalanie kolumn i indeksów (unikalne i nieunikalne)
Godne uwagi alternatywy dla
mergeijoin
Czego ten post nie przejdzie:
- Dyskusje i terminy związane z wydajnością (na razie). Przede wszystkim godne uwagi wzmianki o lepszych alternatywach, w stosownych przypadkach.
- Obsługa sufiksów, usuwanie dodatkowych kolumn, zmiana nazw danych wyjściowych i inne określone przypadki użycia. Istnieją inne (czytaj: lepsze) posty, które się tym zajmują, więc dowiedz się!
Uwaga
Większość przykładów domyślnie wykonuje operacje INNER JOIN podczas demonstrowania różnych funkcji, chyba że określono inaczej.Ponadto wszystkie ramki DataFrame mogą być kopiowane i replikowane, abyś mógł się nimi bawić. Zobacz również ten post o tym, jak czytać ramki danych ze schowka.
Na koniec cała wizualna reprezentacja operacji JOIN została wykonana ręcznie przy użyciu Rysunków Google. Inspiracja stąd .
Dość gadania, po prostu pokaż mi, jak używać merge!
Ustawiać
np.random.seed(0)
left = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': np.random.randn(4)})
right = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': np.random.randn(4)})
left
key value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right
key value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
Dla uproszczenia kolumna klucza ma taką samą nazwę (na razie).
INNER JOIN jest reprezentowany przez
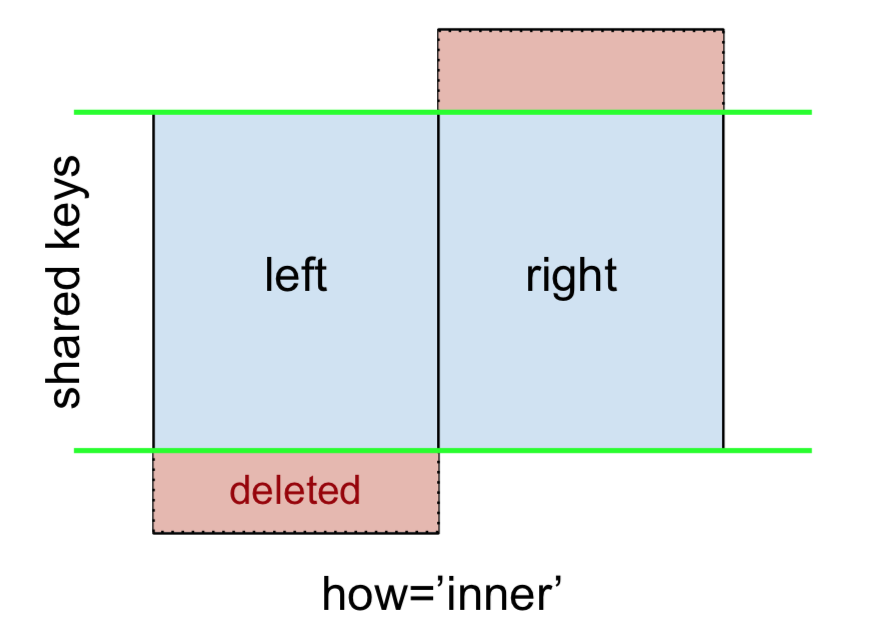
Uwaga
To, wraz z przyszłymi danymi, wszystkie są zgodne z tą konwencją:
- kolor niebieski oznacza wiersze obecne w wyniku scalania
- kolor czerwony oznacza wiersze wykluczone z wyniku (tj. usunięte)
- zielony oznacza brakujące wartości, które
NaNw wyniku są zastępowane przez s
Aby wykonać INNER JOIN, wywołaj mergelewą ramkę DataFrame, określając jako argumenty prawą ramkę DataFrame i klucz łączenia (przynajmniej).
left.merge(right, on='key')
# Or, if you want to be explicit
# left.merge(right, on='key', how='inner')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
Zwraca tylko wiersze z lefti rightmające wspólny klucz (w tym przykładzie „B” i „D).
LEWO ZEWNĘTRZNE Dołącz lub LEWO Dołącz jest reprezentowana przez
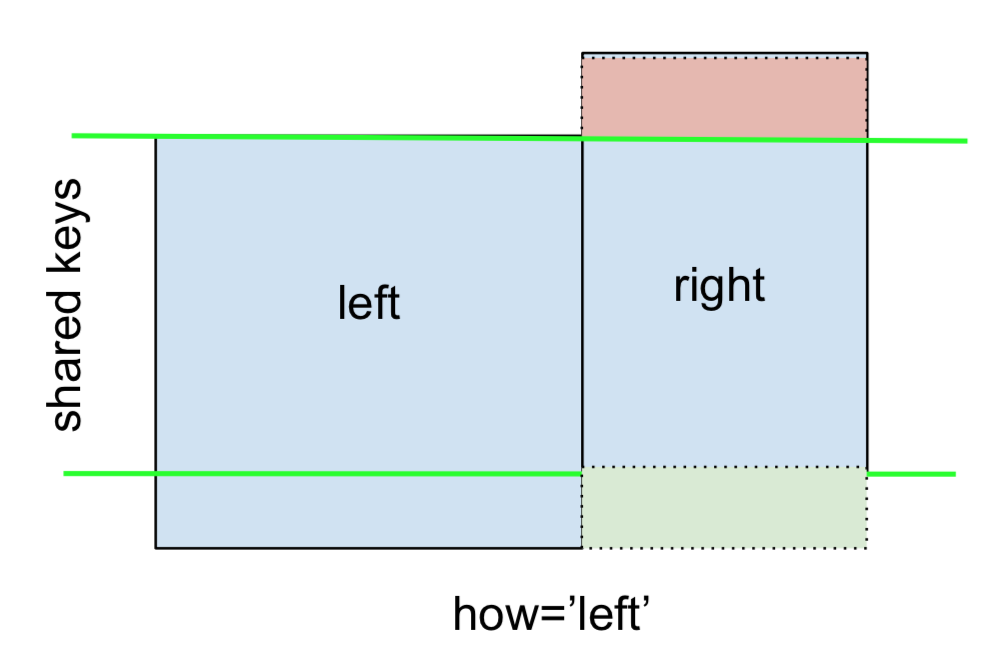
Można to zrobić, określając how='left'.
left.merge(right, on='key', how='left')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
Uważnie zanotuj tutaj rozmieszczenie NaN. Jeśli określisz how='left', leftużywane są tylko klucze od , a brakujące dane z rightsą zastępowane przez NaN.
I podobnie, dla RIGHT OUTER JOIN lub RIGHT JOIN, które jest ...
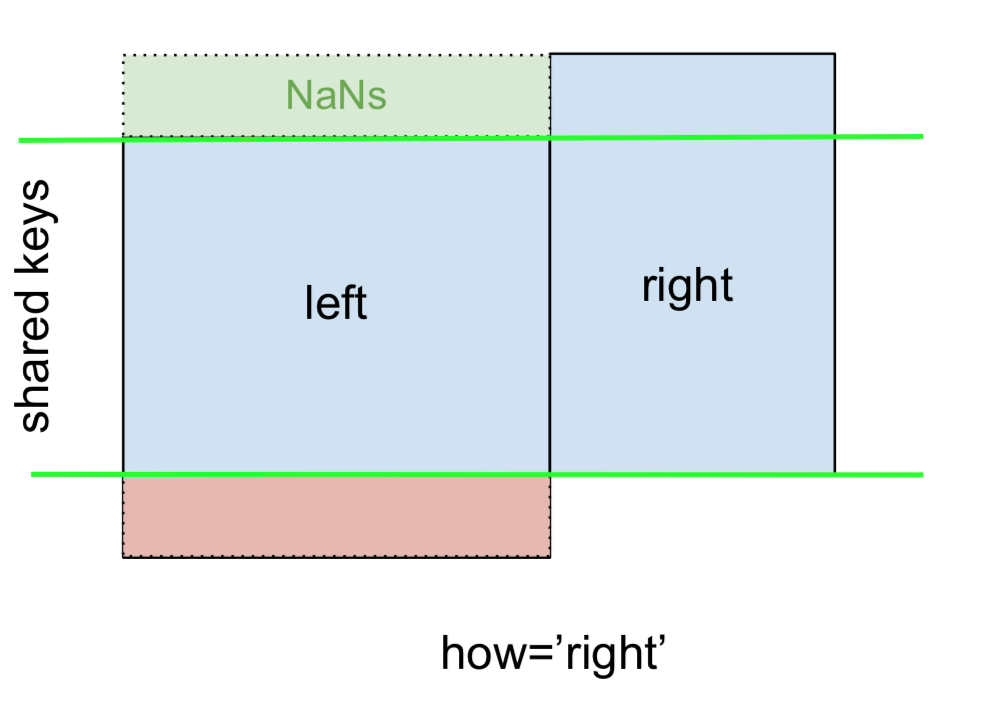
... określić how='right':
left.merge(right, on='key', how='right')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
2 E NaN 0.950088
3 F NaN -0.151357
Tutaj rightużywane są klucze z , a brakujące dane z leftsą zastępowane przez NaN.
Na koniec dla PEŁNEGO DOŁĄCZENIA ZEWNĘTRZNEGO , przyznanego przez
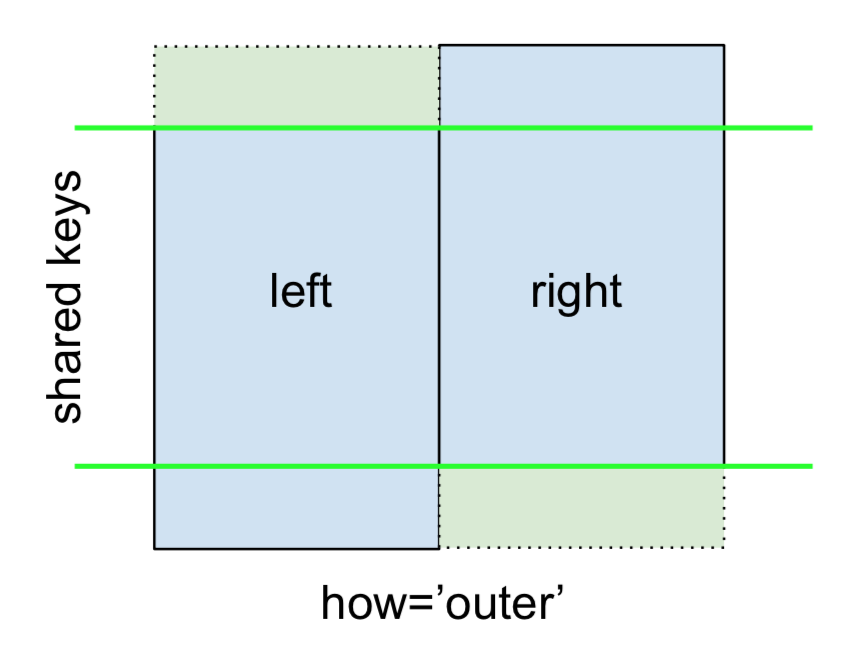
określić how='outer'.
left.merge(right, on='key', how='outer')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
4 E NaN 0.950088
5 F NaN -0.151357
To używa kluczy z obu ramek, a NaNs są wstawiane dla brakujących wierszy w obu.
Dokumentacja ładnie podsumowuje te różne połączenia:

Inne JOINs - LEFT-Exclusive, Right-Exclusive i CAŁKOWICIE-wykluczające / ANTI JOINs
Jeśli potrzebujesz LEFT-Exclusive JOINs i RIGHT-Exclusive JOINs w dwóch krokach.
W przypadku LEWEGO wyłączania JOIN, reprezentowane jako
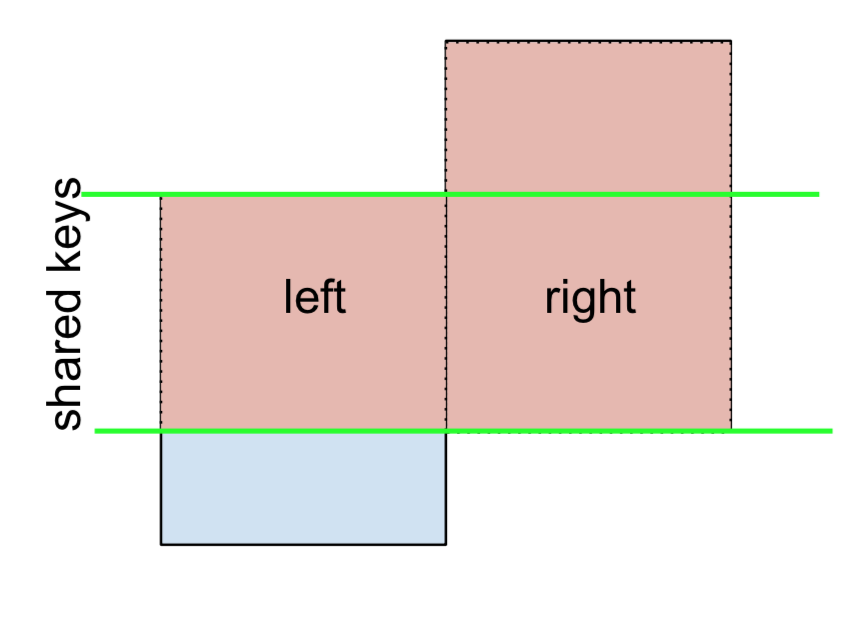
Zacznij od wykonania LEFT OUTER JOIN, a następnie przefiltruj (wyłączając!) Wiersze pochodzące lefttylko z ,
(left.merge(right, on='key', how='left', indicator=True)
.query('_merge == "left_only"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
Gdzie,
left.merge(right, on='key', how='left', indicator=True)
key value_x value_y _merge
0 A 1.764052 NaN left_only
1 B 0.400157 1.867558 both
2 C 0.978738 NaN left_only
3 D 2.240893 -0.977278 bothI podobnie, w przypadku PRAWEGO POŁĄCZENIA z wyłączeniem
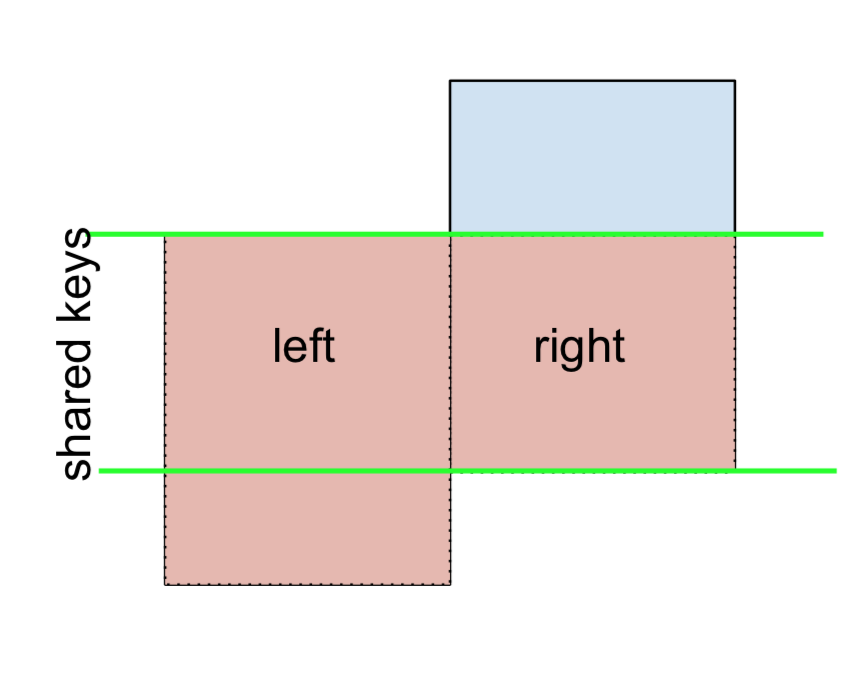
(left.merge(right, on='key', how='right', indicator=True)
.query('_merge == "right_only"')
.drop('_merge', 1))
key value_x value_y
2 E NaN 0.950088
3 F NaN -0.151357Wreszcie, jeśli musisz wykonać scalenie, które zachowuje tylko klucze z lewej lub prawej strony, ale nie z obu (IOW, wykonanie ANTI-JOIN ),
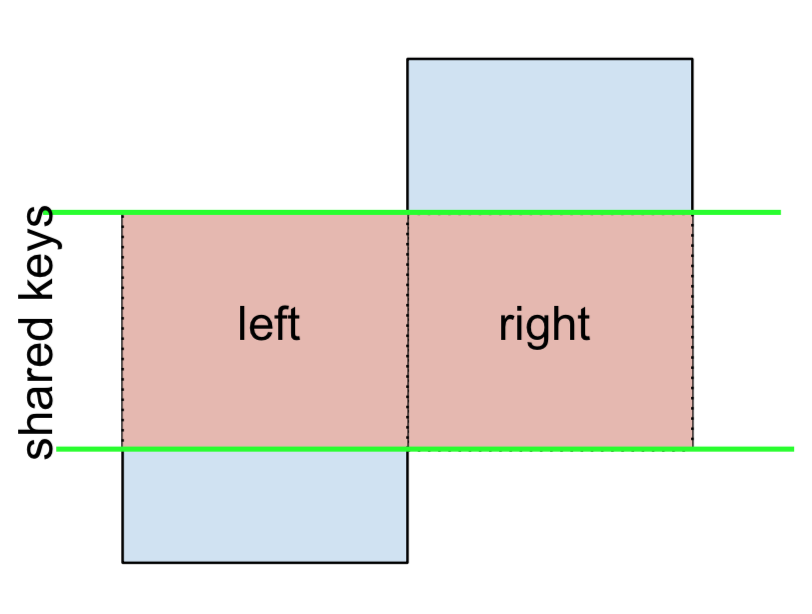
Możesz to zrobić w podobny sposób—
(left.merge(right, on='key', how='outer', indicator=True)
.query('_merge != "both"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
4 E NaN 0.950088
5 F NaN -0.151357
Różne nazwy kolumn kluczowych
Jeśli kolumny kluczy mają inne nazwy - na przykład leftma keyLefti rightma keyRightzamiast tego key- będziesz musiał określić left_oni right_onjako argumenty zamiast on:
left2 = left.rename({'key':'keyLeft'}, axis=1)
right2 = right.rename({'key':'keyRight'}, axis=1)
left2
keyLeft value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right2
keyRight value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')
keyLeft value_x keyRight value_y
0 B 0.400157 B 1.867558
1 D 2.240893 D -0.977278
Unikanie zduplikowanej kolumny klucza w wynikach
Podczas scalania keyLeftz lefti keyRightz right, jeśli chcesz tylko jeden z keyLeftlub keyRight(ale nie oba) w wyniku, możesz zacząć od ustawienia indeksu jako kroku wstępnego.
left3 = left2.set_index('keyLeft')
left3.merge(right2, left_index=True, right_on='keyRight')
value_x keyRight value_y
0 0.400157 B 1.867558
1 2.240893 D -0.977278
Porównaj to z wynikiem polecenia tuż przed (to jest wyjściem left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')), zauważysz, że keyLeftbrakuje. Możesz dowiedzieć się, którą kolumnę zachować, na podstawie indeksu ramki ustawionego jako klucz. Może to mieć znaczenie, gdy, powiedzmy, wykonujesz jakąś operację OUTER JOIN.
Scalanie tylko jednej kolumny z jednego z plików DataFrames
Weźmy na przykład pod uwagę
right3 = right.assign(newcol=np.arange(len(right)))
right3
key value newcol
0 B 1.867558 0
1 D -0.977278 1
2 E 0.950088 2
3 F -0.151357 3
Jeśli chcesz scalić tylko „new_val” (bez żadnej innej kolumny), zwykle możesz przed scaleniem tylko podzestaw kolumn:
left.merge(right3[['key', 'newcol']], on='key')
key value newcol
0 B 0.400157 0
1 D 2.240893 1
Jeśli wykonujesz LEFT OUTER JOIN, bardziej wydajne rozwiązanie obejmowałoby map:
# left['newcol'] = left['key'].map(right3.set_index('key')['newcol']))
left.assign(newcol=left['key'].map(right3.set_index('key')['newcol']))
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
Jak wspomniano, jest to podobne do, ale szybsze niż
left.merge(right3[['key', 'newcol']], on='key', how='left')
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
Scalanie na wielu kolumnach
Aby połączyć w więcej niż jednej kolumnie, określ listę dla on(lub left_oni right_onodpowiednio).
left.merge(right, on=['key1', 'key2'] ...)
Lub, jeśli nazwy są różne,
left.merge(right, left_on=['lkey1', 'lkey2'], right_on=['rkey1', 'rkey2'])
Inne przydatne merge*operacje i funkcje
Scalanie DataFrame z Series on index : Zobacz tę odpowiedź .
Poza tym
merge,DataFrame.updateiDataFrame.combine_firstsą również wykorzystywane w niektórych przypadkach, aby zaktualizować jeden DataFrame z innym.pd.merge_orderedjest użyteczną funkcją dla uporządkowanych SPRZĘŻEŃ.pd.merge_asof(czytaj: merge_asOf) jest przydatne do przybliżonych złączeń.
Ta sekcja obejmuje tylko podstawy i ma na celu jedynie zaostrzenie apetytu. Więcej przykładów i przypadków, zobacz dokumentację merge, joiniconcat jak również linki do specyfikacji funkcyjnych.
Oparte na indeksie * -JOIN (+ kolumny indeksowe merge)
Ustawiać
np.random.seed([3, 14])
left = pd.DataFrame({'value': np.random.randn(4)}, index=['A', 'B', 'C', 'D'])
right = pd.DataFrame({'value': np.random.randn(4)}, index=['B', 'D', 'E', 'F'])
left.index.name = right.index.name = 'idxkey'
left
value
idxkey
A -0.602923
B -0.402655
C 0.302329
D -0.524349
right
value
idxkey
B 0.543843
D 0.013135
E -0.326498
F 1.385076
Zazwyczaj scalenie indeksu wyglądałoby tak:
left.merge(right, left_index=True, right_index=True)
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Obsługa nazw indeksów
Jeśli twój indeks jest nazwany, użytkownicy v0.23 mogą również określić nazwę poziomu na on(lub left_oni right_onjeśli to konieczne).
left.merge(right, on='idxkey')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Scalanie według indeksu jednej kolumny (kolumn) innej
Możliwe jest (i całkiem proste) użycie indeksu jednego i kolumny drugiego do wykonania scalenia. Na przykład,
left.merge(right, left_on='key1', right_index=True)
Lub odwrotnie ( right_on=...i left_index=True).
right2 = right.reset_index().rename({'idxkey' : 'colkey'}, axis=1)
right2
colkey value
0 B 0.543843
1 D 0.013135
2 E -0.326498
3 F 1.385076
left.merge(right2, left_index=True, right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
W tym szczególnym przypadku indeks dla leftjest nazwany, więc możesz również użyć nazwy indeksu w left_onnastępujący sposób:
left.merge(right2, left_on='idxkey', right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
DataFrame.join
Poza tym jest jeszcze jedna zwięzła opcja. Możesz użyć DataFrame.joinwartości domyślnych, aby dołączyć do indeksu. DataFrame.joindomyślnie wykonuje LEFT OUTER JOIN, więc how='inner'jest tutaj konieczne.
left.join(right, how='inner', lsuffix='_x', rsuffix='_y')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Zauważ, że musiałem określić argumenty lsuffixi, rsuffixponieważ w joinprzeciwnym razie wystąpiłby błąd:
left.join(right)
ValueError: columns overlap but no suffix specified: Index(['value'], dtype='object')
Ponieważ nazwy kolumn są takie same. Nie stanowiłoby to problemu, gdyby miały inne nazwy.
left.rename(columns={'value':'leftvalue'}).join(right, how='inner')
leftvalue value
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
pd.concat
Wreszcie, jako alternatywa dla złączeń opartych na indeksach, możesz użyć pd.concat:
pd.concat([left, right], axis=1, sort=False, join='inner')
value value
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Pomiń, join='inner'jeśli potrzebujesz PEŁNEGO DOŁĄCZENIA ZEWNĘTRZNEGO (ustawienie domyślne):
pd.concat([left, right], axis=1, sort=False)
value value
A -0.602923 NaN
B -0.402655 0.543843
C 0.302329 NaN
D -0.524349 0.013135
E NaN -0.326498
F NaN 1.385076
Aby uzyskać więcej informacji, zobacz ten kanoniczny wpis opublikowany pd.concatprzez @piRSquared .
Uogólnianie: mergetworzenie wielu ramek danych
Często sytuacja ma miejsce, gdy wiele ramek DataFrame ma zostać połączonych razem. Naiwnie można to zrobić, łącząc mergewywołania:
df1.merge(df2, ...).merge(df3, ...)
Jednak w przypadku wielu ramek DataFrame to szybko wymyka się spod kontroli. Ponadto może być konieczne uogólnienie dla nieznanej liczby ramek DataFrames.
Tutaj przedstawiam pd.concatłączenie wielostronne na kluczach unikatowych oraz DataFrame.joinłączenie wielostronne na kluczach nieunikalnych . Najpierw konfiguracja.
# Setup.
np.random.seed(0)
A = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'valueA': np.random.randn(4)})
B = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'valueB': np.random.randn(4)})
C = pd.DataFrame({'key': ['D', 'E', 'J', 'C'], 'valueC': np.ones(4)})
dfs = [A, B, C]
# Note, the "key" column values are unique, so the index is unique.
A2 = A.set_index('key')
B2 = B.set_index('key')
C2 = C.set_index('key')
dfs2 = [A2, B2, C2]
Scalanie wielostronne na unikalnych kluczach (lub indeksie)
Jeśli twoje klucze (w tym przypadku klucz może być kolumną lub indeksem) są unikalne, możesz użyć pd.concat. Zauważ, że pd.concatłączy DataFrames w indeksie .
# merge on `key` column, you'll need to set the index before concatenating
pd.concat([
df.set_index('key') for df in dfs], axis=1, join='inner'
).reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# merge on `key` index
pd.concat(dfs2, axis=1, sort=False, join='inner')
valueA valueB valueC
key
D 2.240893 -0.977278 1.0
Pomiń join='inner'dla PEŁNEGO POŁĄCZENIA ZEWNĘTRZNEGO. Zauważ, że nie możesz określić złączeń LEFT lub RIGHT OUTER (jeśli ich potrzebujesz, użyj join, co opisano poniżej).
Wielostronne scalanie kluczy z duplikatami
concatjest szybki, ale ma swoje wady. Nie obsługuje duplikatów.
A3 = pd.DataFrame({'key': ['A', 'B', 'C', 'D', 'D'], 'valueA': np.random.randn(5)})
pd.concat([df.set_index('key') for df in [A3, B, C]], axis=1, join='inner')
ValueError: Shape of passed values is (3, 4), indices imply (3, 2)
W tej sytuacji możemy użyć, joinponieważ może obsługiwać nieunikalne klucze (zauważ, że joinłączy DataFrames na ich indeksie; wywołuje mergepod maską i wykonuje LEFT OUTER JOIN, chyba że określono inaczej).
# join on `key` column, set as the index first
# For inner join. For left join, omit the "how" argument.
A.set_index('key').join(
[df.set_index('key') for df in (B, C)], how='inner').reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# join on `key` index
A3.set_index('key').join([B2, C2], how='inner')
valueA valueB valueC
key
D 1.454274 -0.977278 1.0
D 0.761038 -0.977278 1.0
Uzupełniający widok wizualny pd.concat([df0, df1], kwargs). Zwróć uwagę, że znaczenie kwarg axis=0lub axis=1nie jest tak intuicyjne jak df.mean()lubdf.apply(func)
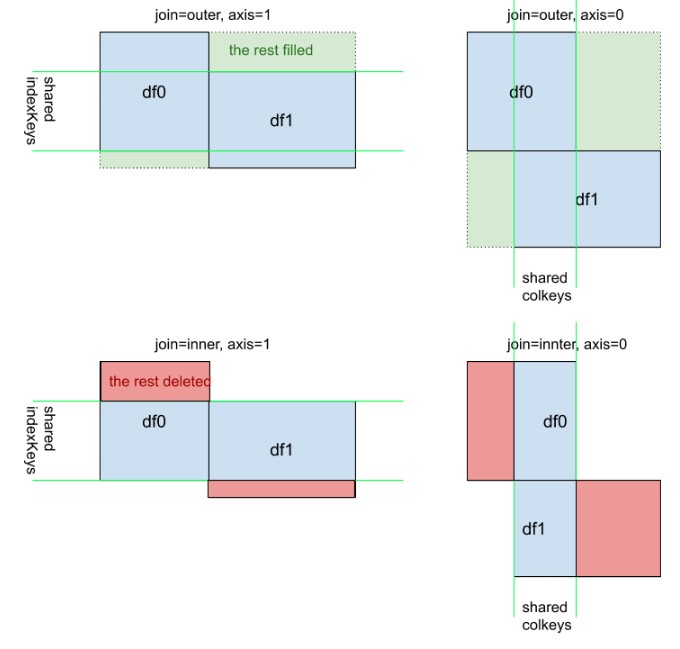
W tej odpowiedzi rozważę praktyczny przykład pandas.concat.
Biorąc pod uwagę następujące DataFramesz tymi samymi nazwami kolumn:
Preco2018 z rozmiarem (8784, 5)
Preco 2019 z rozmiarem (8760, 5)
Mają te same nazwy kolumn.
Możesz je łączyć używając pandas.concat, po prostu
import pandas as pd
frames = [Preco2018, Preco2019]
df_merged = pd.concat(frames)
W wyniku czego powstaje DataFrame o następującym rozmiarze (17544, 5)

Jeśli chcesz wizualizować, kończy się to w ten sposób
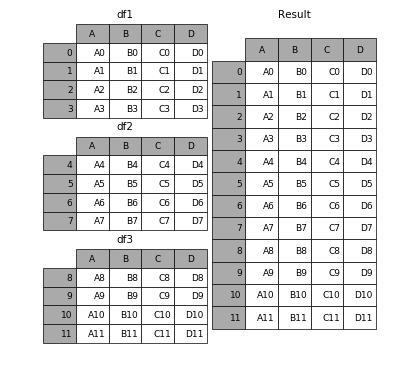
( Źródło )